Hadoop|Spark
谷歌三驾马车 1、GFS 开源实现HDFS、
2、MapReduce 开源实现MapReduce 统称Hadoop
3、Bigtable 开源实现为 HBase
spark-SQL前身shark 以前spark依托于hive
Hadoop2
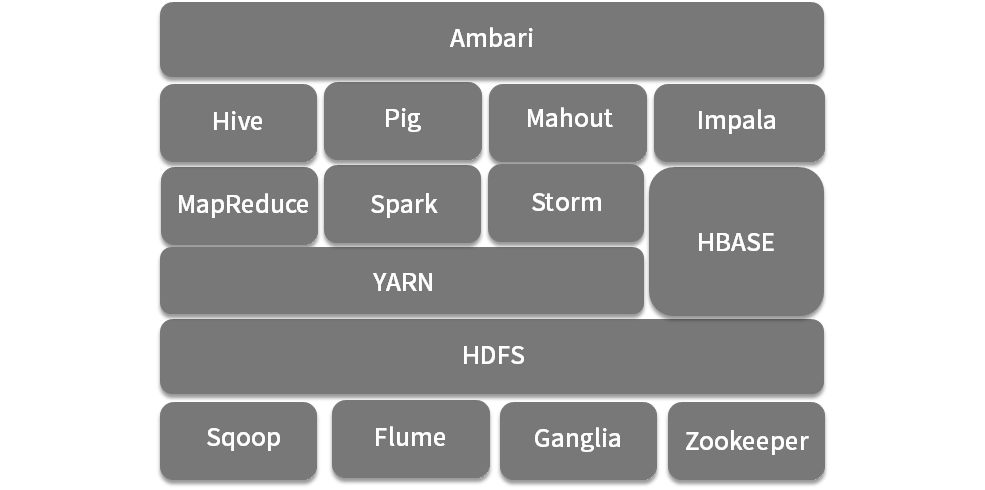
负责批量数据抽取的 Sqoop,
负责流式数据传输的 Flume,
集群监控的 ganglia
负责分布式一致性的 Zookeeper
资源管理与调度系统 YARN(Yet Another Resource Negotiator 内存、CPU)
计算框架,如支持SQL 的 Hive、Impala,以及 Pig、Spark、Storm 、MapReduce等。还有些工具类的组件
负责部署的 Ambari
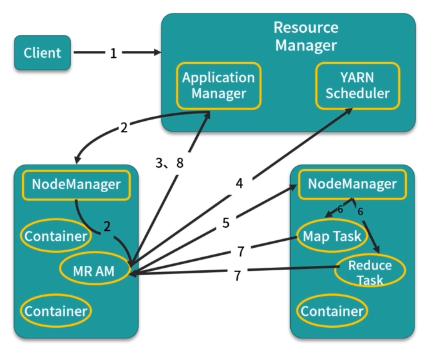
YARN 两次调度
集中式调度器 全局只有一个中央调度器
计算框架的资源申请全部提交给中央调度器来满足
所有的调度逻辑都由中央调度器来实现
集中式调度器的实现是Hadoop MapReduce 的JobTracker实际的资源利用率只有70%左右,甚至更低
双层调度器 将整个调度工作划分为两层:中央调度器 和框架调度器
中央调度器管理集群中所有资源的状态,他拥有集群所有的资源信息
按照一定策略将资源粗粒度地分配给框架调度器 ,各个框架调度器收到资源后再根据应用申请细粒度将资源分配给容器执行具体的计算任务
悲观并发。
状态共享调度器 是由Google的Omega调度系统所提出的一种新范型
只保存一份资源使用情况信息
严重弱化了中央调度器;每个框架内部都会不断地从主调度器更新集群信息并保存一份
而框架对资源的申请则会在该信息上进行
一旦框架做出决策,就会将该信息同步到主调度
资源竞争过程是通过事务进行的,从而保证了操作的原子性
由于决策是在自己的私有数据上做出的
并通过原子事务提交,系统保证只有一个胜出者
这是一种类似于MVCC的乐观并发机制
可以增加系统的整体并发性能,但是调度功能公平性有所不足
简单讲:
乐观并发就是写数据库的时候假设不会发生冲突,然后在碰到冲突的时候才进行处理
悲观并发就是写数据库的时候假设错误始终会发生,因此,更新前要做字段值的比对工作。
详细讲:
乐观并发:在乐观并发控制中,用户读数据时不锁定数据。在执行更新时,系统进行检查,查看另一个用户读过数据后是否更改了数据。如果另一个用户更新了数据,将产生一个错误。一般情况下,接收错误信息的用户将回滚事务并重新开始。该方法主要用在数据争夺少的环境内,以及偶尔回滚事务的成本超过读数据时锁定数据的成本的环境内,因此称该方法为乐观并发控制。
悲观并发:锁定系统阻止用户以影响其它用户的方式修改数据。如果用户执行的操作导致应用了某个锁,则直到这个锁的所有者释放该锁,其它用户才能执行与该锁冲突的操作。该方法主要用在数据争夺激烈的环境中,以及出现并发冲突时用锁保护数据的成本比回滚事务的成本低的环境中,因此称该方法为悲观并发控制。
spark

编程接口
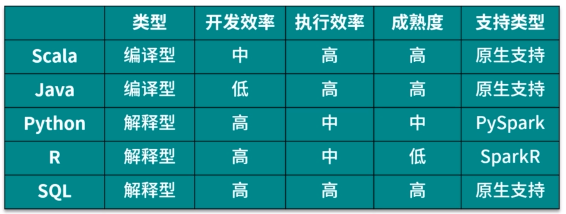
Spark 由Scala开发而成,对于Java、Scala编程接口来说
在执行计算任务时,由集群中的每个节点的JVM(Scala也是JVM语言)完成
部署
Spark支持的统一资源管理与调度系统
Spark standalone
YARN
Mesos
Kubernets
本地操作系统
# pip install pyspark # pip install pyspark-stubs from pyspark.sql import SparkSession from pyspark.sql.functions import col # 初始化 spark = SparkSession.builder.master("local[*]").appName('Test').getOrCreate() # 0+1+2+3+4 spark.range(0, 5).select(col("id").cast("double")).agg({"id": "sum"}).show() # 关闭 spark.stop()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号