Reader
type Reader struct {
buf []byte //缓冲区。虽然它是切片类型的,但是其长度却会在初始化的时候指定,并在之后保持不变。
rd io.Reader //底层读取器。缓冲区中的数据就是从这里拷贝来的。
r int //对缓冲区进行下一次读取时的开始索引。我们可以称它为已读计数。
w int //缓冲区进行下一次写入时的开始索引。我们可以称之为已写计数。
err error //在从底层读取器获得数据时发生的错误
lastByte int //记录缓冲区中最后一个被读取的字节。读回退时会用到它的值。
lastRuneSize int //用于记录缓冲区中最后一个被读取的字节。读回退时会用到它的值。
}
const minReadBufferSize = 16
const maxConsecutiveEmptyReads = 100
func NewReaderSize(rd io.Reader, size int) *Reader {
b, ok := rd.(*Reader)
if ok && len(b.buf) >= size {
return b
}
if size < minReadBufferSize {
size = minReadBufferSize
}
r := new(Reader)
r.reset(make([]byte, size), rd)
return r
}
func NewReader(rd io.Reader) *Reader {
return NewReaderSize(rd, defaultBufSize)
}
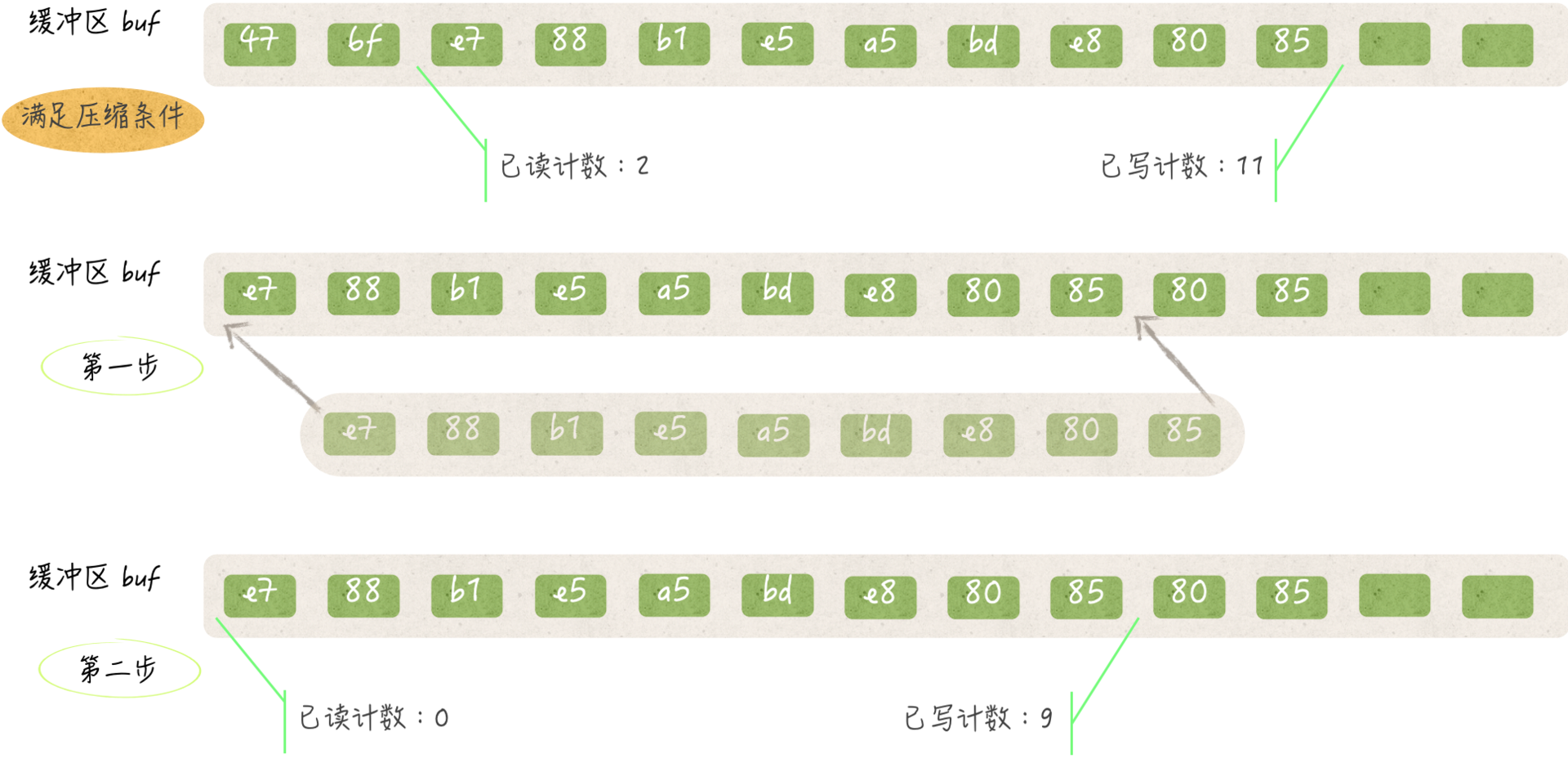
func (b *Reader) fill() {
if b.r > 0 {
copy(b.buf, b.buf[b.r:b.w])
b.w -= b.r
b.r = 0
}
if b.w >= len(b.buf) {
panic("bufio: tried to fill full buffer")
}
for i := maxConsecutiveEmptyReads; i > 0; i-- {
n, err := b.rd.Read(b.buf[b.w:])
if n < 0 {
panic(errNegativeRead)
}
b.w += n
if err != nil {
b.err = err
return
}
if n > 0 {
return
}
}
b.err = io.ErrNoProgress
}
//读取并返回其缓冲区中的n个未读字节,并且它会从已读计数代表的索引位置开始读。
//可以多次重复读,4KB以内
func (b *Reader) Peek(n int) ([]byte, error) {
if n < 0 {
return nil, ErrNegativeCount
}
b.lastByte = -1
b.lastRuneSize = -1
//在缓冲区未被填满,并且其中的未读字节的数量小于n的时候,且上次填充没有错误
for b.w-b.r < n && b.w-b.r < len(b.buf) && b.err == nil {
b.fill()
}
if n > len(b.buf) {
return b.buf[b.r:b.w], ErrBufferFull
//虽然缓冲区被压缩和填满了,但是仍然满足不了要求
}
var err error
if avail := b.w - b.r; avail < n {
n = avail
err = b.readErr()
if err == nil {
err = ErrBufferFull
}
}
//即使它读取了缓冲区中的数据,也不会更改已读计数的值。
return b.buf[b.r : b.r+n], err
}
//一次性读,大多数情况下,不会往缓冲区写
func (b *Reader) Read(p []byte) (n int, err error) {
n = len(p)
if n == 0 {
if b.Buffered() > 0 {
return 0, nil
}
return 0, b.readErr()
}
if b.r == b.w {
if b.err != nil {
return 0, b.readErr()
}
if len(p) >= len(b.buf) {
n, b.err = b.rd.Read(p)
if n < 0 {
panic(errNegativeRead)
}
if n > 0 {
b.lastByte = int(p[n-1])
b.lastRuneSize = -1
}
return n, b.readErr()
}
b.r = 0
b.w = 0
n, b.err = b.rd.Read(b.buf)
if n < 0 {
panic(errNegativeRead)
}
if n == 0 {
return 0, b.readErr()
}
b.w += n
}
n = copy(p, b.buf[b.r:b.w])
b.r += n
b.lastByte = int(b.buf[b.r-1])
b.lastRuneSize = -1
return n, nil
}
func (b *Reader) ReadByte() (byte, error) {
b.lastRuneSize = -1
for b.r == b.w {
if b.err != nil {
return 0, b.readErr()
}
b.fill()
}
c := b.buf[b.r]
b.r++
b.lastByte = int(c)
return c, nil
}
func (b *Reader) ReadRune() (r rune, size int, err error) {
for b.r+utf8.UTFMax > b.w && !utf8.FullRune(b.buf[b.r:b.w]) && b.err == nil && b.w-b.r < len(b.buf) {
b.fill()
}
b.lastRuneSize = -1
if b.r == b.w {
return 0, 0, b.readErr()
}
r, size = rune(b.buf[b.r]), 1
if r >= utf8.RuneSelf {
r, size = utf8.DecodeRune(b.buf[b.r:b.w])
}
b.r += size
b.lastByte = int(b.buf[b.r-1])
b.lastRuneSize = size
return r, size, nil
}
// 只会在buf中查找
func (b *Reader) ReadSlice(delim byte) (line []byte, err error) {
s := 0
for {
if i := bytes.IndexByte(b.buf[b.r+s:b.w], delim); i >= 0 {
i += s
line = b.buf[b.r : b.r+i+1]
b.r += i + 1
break
}
if b.err != nil {
line = b.buf[b.r:b.w]
b.r = b.w
err = b.readErr()
break
}
if b.Buffered() >= len(b.buf) {
b.r = b.w
line = b.buf
err = ErrBufferFull
break
}
s = b.w - b.r
b.fill()
}
if i := len(line) - 1; i >= 0 {
b.lastByte = int(line[i])
b.lastRuneSize = -1
}
return
}
// buf+底层读取器;最后返回完整的切片
func (b *Reader) ReadBytes(delim byte) ([]byte, error) {
var frag []byte
var full [][]byte
var err error
n := 0
for {
var e error
frag, e = b.ReadSlice(delim)
if e == nil {
break
}
if e != ErrBufferFull {
err = e
break
}
buf := make([]byte, len(frag))
copy(buf, frag)
full = append(full, buf)
n += len(buf)
}
n += len(frag)
buf := make([]byte, n)
n = 0
for i := range full {
n += copy(buf[n:], full[i])
}
copy(buf[n:], frag)
return buf, err
}
// 依赖ReadBytes
func (b *Reader) ReadString(delim byte) (string, error) {
bytes, err := b.ReadBytes(delim)
return string(bytes), err
}
安全性方面的问题需要注意。
Peek方法、
ReadSlice方法和
ReadLine方法都有可能会造成内容泄露。
这主要是因为它们在正常的情况下都会返回直接基于缓冲区的字节切片
Writer
type Writer struct {
err error //用于表示在向底层写入器写数据时发生的错误。
buf []byte //缓冲区。在初始化之后,它的长度会保持不变。
n int //对缓冲区进行下一次写入时的开始索引。我们可以称之为已写计数。
wr io.Writer //底层写入器。
}
func NewWriterSize(w io.Writer, size int) *Writer {
b, ok := w.(*Writer)
if ok && len(b.buf) >= size {
return b
}
if size <= 0 {
size = defaultBufSize
}
return &Writer{
buf: make([]byte, size),
wr: w,
}
}
func NewWriter(w io.Writer) *Writer {
return NewWriterSize(w, defaultBufSize)
}
//把相应缓冲区中暂存的所有数据,都写到底层写入器中。数据一旦被写进底层写入器,
// 该方法就会把它们从缓冲区中删除掉。(逻辑上,但是会妥当处置,并保证不会出现重写和漏写的情况)
// 与n有关
func (b *Writer) Flush() error {
if b.err != nil {
return b.err
}
if b.n == 0 {
return nil
}
n, err := b.wr.Write(b.buf[0:b.n])
if n < b.n && err == nil {
err = io.ErrShortWrite
}
if err != nil {
if n > 0 && n < b.n {
copy(b.buf[0:b.n-n], b.buf[n:b.n])
}
b.n -= n
b.err = err
return err
}
b.n = 0
return nil
}
//Write方法有时候会在把数据写进缓冲区之后,调用Flush方法,以便为后续的新数据腾出空间。
func (b *Writer) Write(p []byte) (nn int, err error) {
for len(p) > b.Available() && b.err == nil {
var n int
if b.Buffered() == 0 {
n, b.err = b.wr.Write(p)
} else {
n = copy(b.buf[b.n:], p)
b.n += n
b.Flush()
}
nn += n
p = p[n:]
}
if b.err != nil {
return nn, b.err
}
n := copy(b.buf[b.n:], p)
b.n += n
nn += n
return nn, nil
}
//会在发现缓冲区中的可写空间不足以容纳新的字节 调用Flush方法
func (b *Writer) WriteByte(c byte) error {
if b.err != nil {
return b.err
}
if b.Available() <= 0 && b.Flush() != nil {
return b.err
}
b.buf[b.n] = c
b.n++
return nil
}
//会在发现缓冲区中的可写空间不足以容纳新的 Unicode 字符的时候,调用Flush方法
func (b *Writer) WriteRune(r rune) (size int, err error) {
if r < utf8.RuneSelf {
err = b.WriteByte(byte(r))
if err != nil {
return 0, err
}
return 1, nil
}
if b.err != nil {
return 0, b.err
}
n := b.Available()
if n < utf8.UTFMax {
if b.Flush(); b.err != nil {
return 0, b.err
}
n = b.Available()
if n < utf8.UTFMax {
return b.WriteString(string(r))
}
}
size = utf8.EncodeRune(b.buf[b.n:], r)
b.n += size
return size, nil
}
//WriteString方法有时候会在把数据写进缓冲区之后,调用Flush方法,以便为后续的新数据腾出空间。
func (b *Writer) WriteString(s string) (int, error) {
nn := 0
for len(s) > b.Available() && b.err == nil {
n := copy(b.buf[b.n:], s)
b.n += n
nn += n
s = s[n:]
b.Flush()
}
if b.err != nil {
return nn, b.err
}
n := copy(b.buf[b.n:], s)
b.n += n
nn += n
return nn, nil
}
//总之,在通常情况下,只要缓冲区中的可写空间无法容纳需要写入的新数据,Flush方法就一定会被调用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号