dynamodb
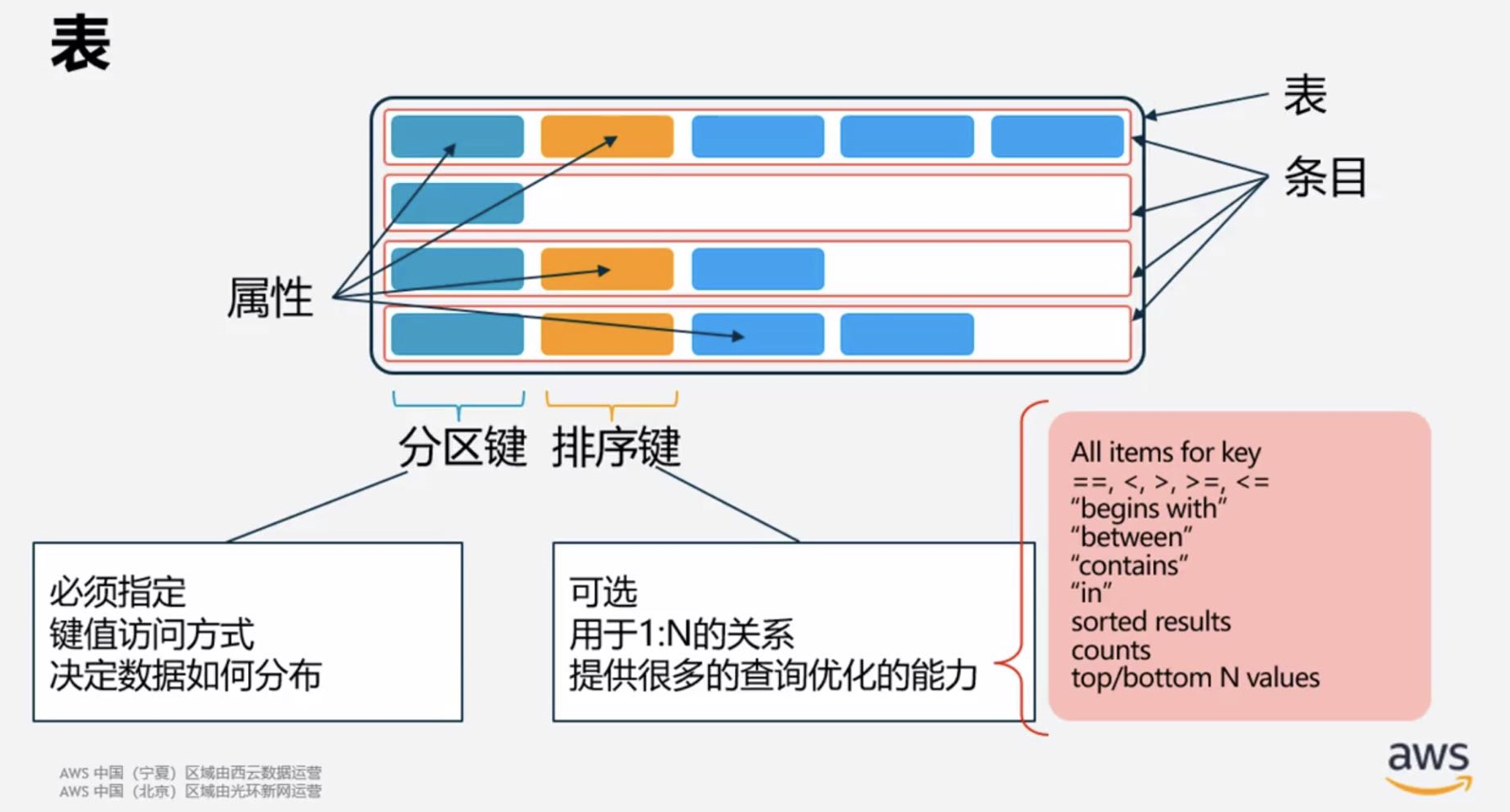
分区键,决定数据怎么分布 ,类似不同的桶(必须指定),指定可以节省查询时间 ,随着数据量增大,可以很好的扩展
排序建,当设计该键的排序的时候,可以优化查询能力,(非必须)
1、表的分区字段 2、表的排序字段
1写容量单位 1kb/s
1读容量单位 4kb/s 如果设为最终一致性, 按 8KB/s
总的容量单位是均分到各个分区的
索引的意义
全局二级索引
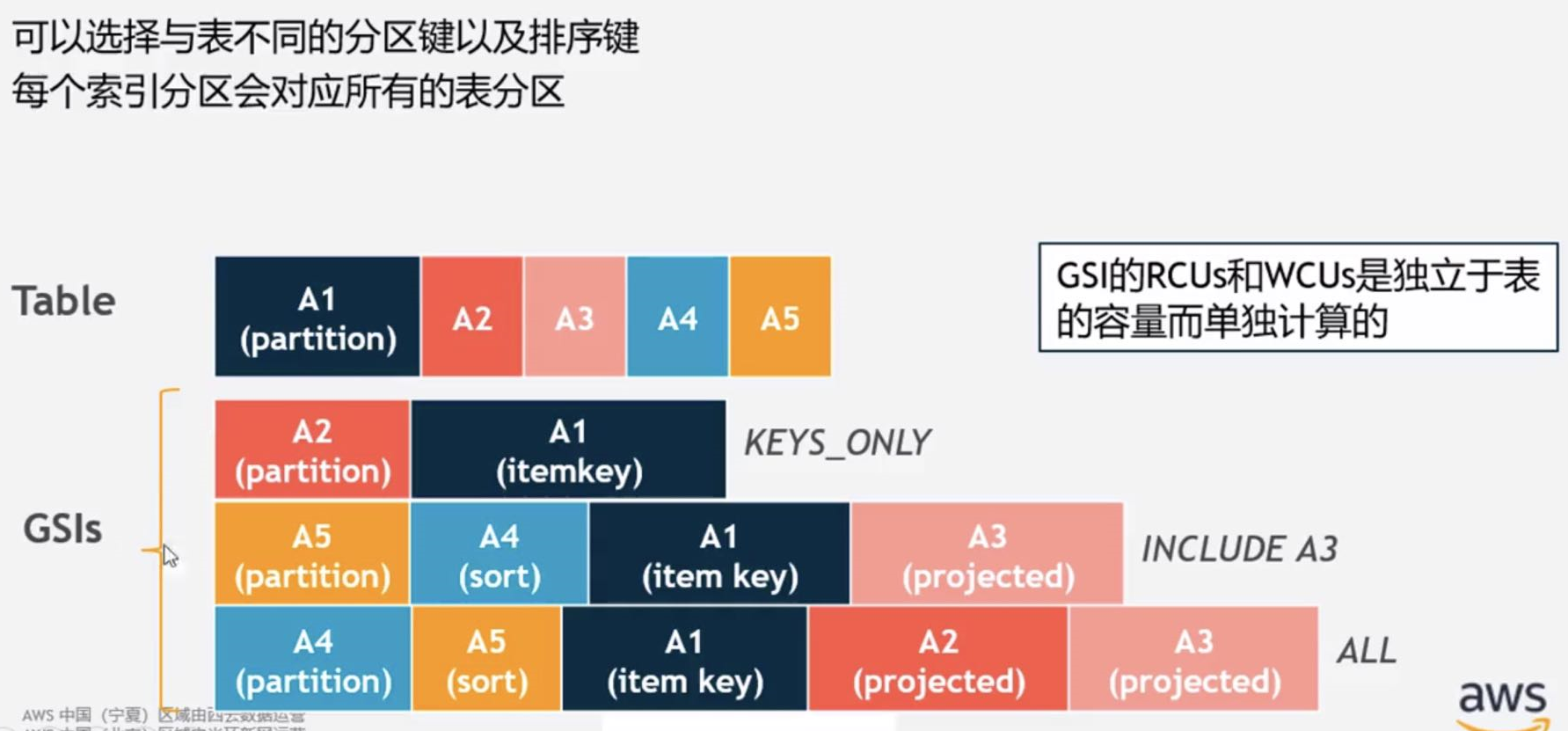
索引数据 独立于表
异步进行更新,如果更新速度达到阈值,表的读写会受到限流
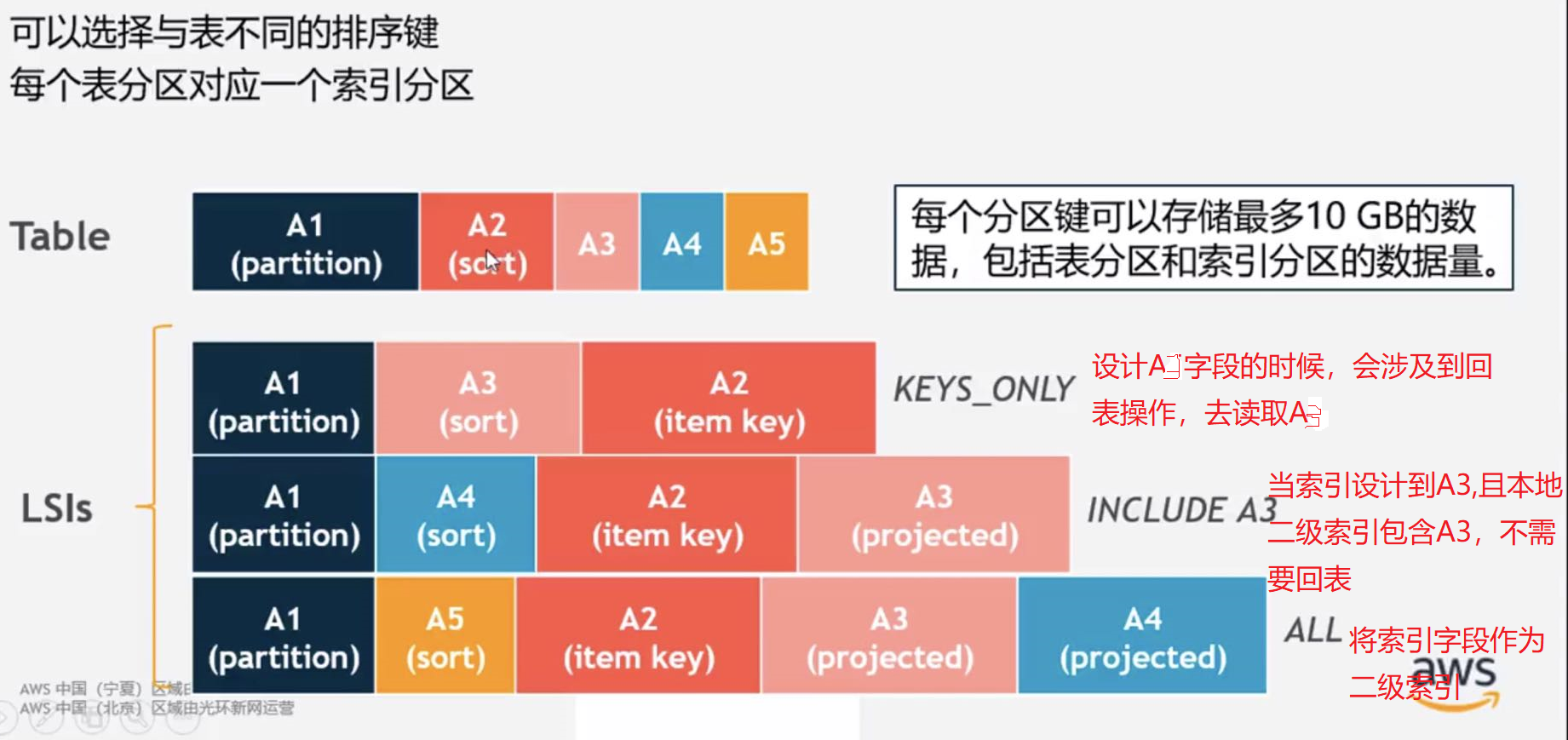
本地二级索引(分区索引 LSIs)
分区键 肯定是一个索引键
另外可以用其他的属性
分区计算
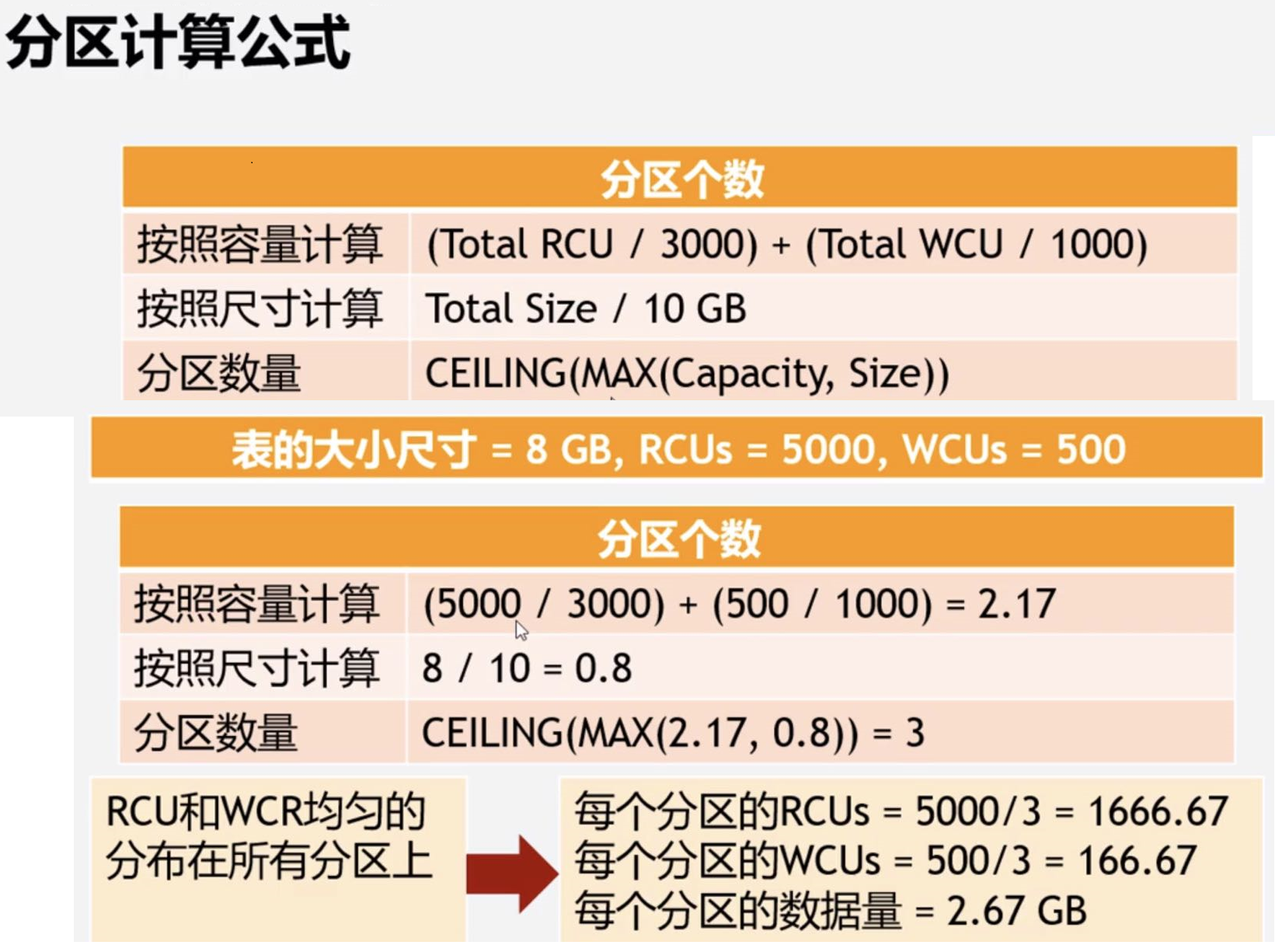
计算表或者索引的容量

自动伸缩
最佳案例:降低RCU、WRU
1、大数据量内容 单独存一张表,或者存S3的链接
2、时序性, 定期将新的数据 分新的表, (分配给冷数据区的RCU、用不上)
预先创建每天,每周或者每月的表格,对当前表格配置需要的吞吐量,新的数据写入当前表格,降低历史数据表格的吞吐量
3、多条件查询
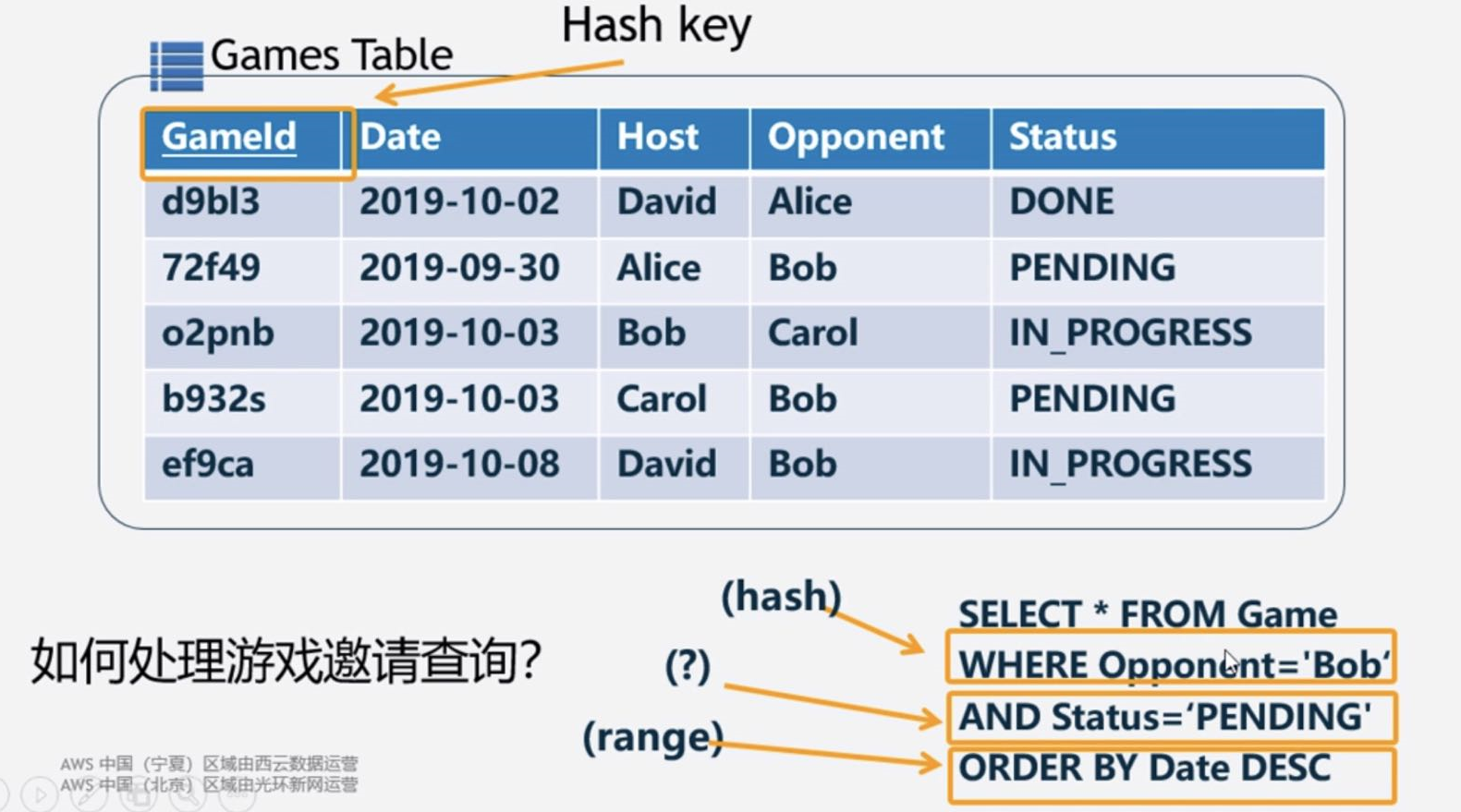
全局
GameId 做全局索引
日期 做排序字段
本地二级
Opponent 做分区字段
Status 做排序字段
假如 有过滤条件status=Pending,那么就会导致 查询出的数据有一部分没有用到;浪费了一部分RCU
解决方法 合并字段 StartDate : Pending_2019-09-30
AND StartDate BEGINS_WITH 'pending' 没有浪费
流复制
类似 日志
1、针对表里的数据变化的顺序记录
2、针对表的变化的记录只会出现一次
3、记录的顺序与操作记录一致
4、只保存24小时
5、可以把表的数据被更新前的值以及更新后的值都写到流里
6、流里的数据通过API进行消费
四种流格式 1、KEYS_ONLY 只有分区键和排序键的数据被写入流 2、NEW_IMAGE 修改后的整条记录都被写入流 3、OLD_IMAGE 修改前的整条记录都被写入流 4、NEW_AND_OLD_IMAGES 修改前后的整条记录都会写入流
表之间的数据复制
触发器
容灾和多区域复制
数据汇总
数据安全和通知


 浙公网安备 33010602011771号
浙公网安备 33010602011771号