
性能现象及分析
1.数据库Cpu过高预警,超过80%;
原因:a.慢SQL过多,导致很多链接时间过长,导致链接不释放.
解决方法:
1.通过show full processlist查看是否存在大量SLEEP的链接,并查看时间。
造成sleep的原因有:1.客户端程序在退出之前没有调用mysql_close().
2.客户端sleep的时间在wait_timeout或interactive_timeout规定的秒内没有发出任何请求到服务器.
3.客户端程序在结束之前向服务器发送了请求还没得到返回结果就结束掉了.
关于原因2建议通过语句:mysql> set global wait_timeout=10; mysql> show global variables like '%timeout'; 调整wait_timeout时间为一个钟或半个钟,让mysql更快的杀掉连接,减缓压力。
2.通过show full processlist查看是否存在状态为sending data,copying to tmp table,copying to tmp table on disk,sorting result,using filesort,locked,Creating sort index的连接。
a.sending data:sql正从表中查询数据:如果查询条件没有适当索引,会导致sql执行时间过长
b.copying to tmp table on disk:因临时结果集太大,超过数据库规定的临时内存大小,需要拷贝临时结果集到磁盘上
c.sorting result,using filesort:sql正在执行排序操作:排序操作会引起较多的cpu消耗,可以通过添加索引,或
减小排序结果集
d.Creating sort index:正在创建排序索引;
本质上还是要优化sql使sql返回速度更快并增大临时表内存tmp_table_size=1024M设定
2.查看Gc情况:jstat -gc 30996 3000
图中参数含义如下:
S0 — Heap上的 Survivorspace 0 区已使用空间的百分比
S1 — Heap上的 Survivorspace 1 区已使用空间的百分比
E — Heap上的 Eden space区已使用空间的百分比
O — Heap上的 Old space 区已使用空间的百分比
P — Perm space 区已使用空间的百分比
YGC — 从应用程序启动到采样时发生 YoungGC 的次数
YGCT –从应用程序启动到采样时 Young GC 所用的时间(单位秒)
FGC — 从应用程序启动到采样时发生 Full GC的次数
FGCT –从应用程序启动到采样时 Full GC 所用的时间(单位秒)
GCT — 从应用程序启动到采样时用于垃圾回收的总时间(单位秒)
主要看FGC次数和时间,如果FGC频繁并且时间超过1〜3 秒则需要优化。
YGC频繁是正常的。
另外看OLD区是否满100%,存在内存泄漏情况。
3.监控数据库服务器获取占用cpu高的数据库进程pid,
然后执行sql查看具体执行的sql,了解索引:
(oracle)select t3.sql_text from v$process t1 inner join v$session t2 on t1.addr=t2.paddr inner join v$sql t3 on t2.sql_id=t3.sql_id where t1.spid=5904;
(mysql) select * from information_schema.`PROCESSLIST` where info is not null;
或者执行show full processlist;
或者查看日志 ,但必须要有权限:SELECT * from mysql.general_log ORDER BY event_time DESC
4.查看线程死锁情况:
先查看下gc情况是否正常 ;
top命令或使用dstat -tcdlmnsygr查看cpu有没有压力;
再通过浏览器访问接口看有没有反应;
因为一般有死锁的话,gc应该是正常的,cpu也没有压力,浏览器访问接口应该是没返回的。
或者直接通过jvisualvm查看是否有死锁:
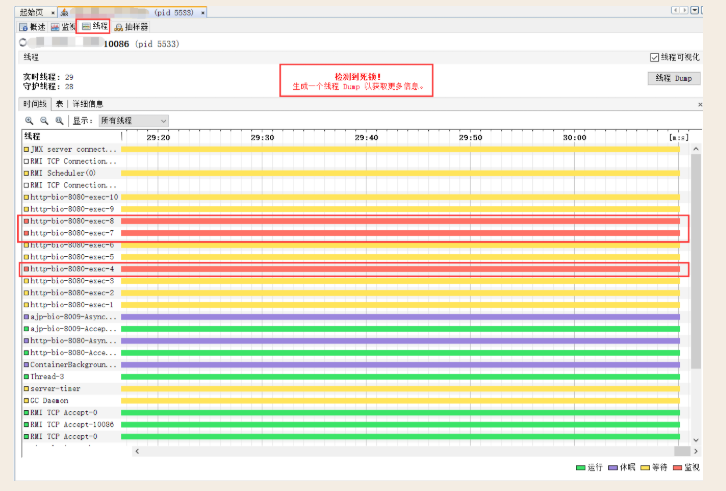
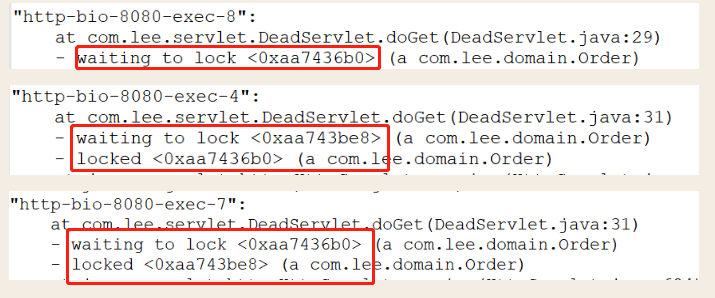
也可以通过jps -lv查看进程pid,然后jstack +pid > 123.txt 将堆栈日志打印出来 。如果有下面的语句说明有死锁:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号