Hotspot 老年代GC源代码分析
来年代的回收可分为 标记-压缩回收 和 标记清理回收
前者会将存活对象在对象头中打标,回收的时候,把被打标的对象复制到一块,使得存活对象在内存上是连续分布的。
需要注意的是,这里说的连续分布,不是物理意义上的,因为JVM向操作系统申请老年代和年轻代这样的大块内存时,使用的是mmap系统调用,操作系统给出的物理页不一定是连续的。
GC分为前台GC和 后台GC
前台GC在 System.gc() 或者 内存分配失败时 由 VM_Thread 执行,VM_Thread是JVM本身的工作线程,前台GC也称为同步GC, 调用方会阻塞在该点,等待GC完成
在 使用CMS 收集器的情况下,由 CMSThread 执行后台 GC, 后台GC 会和 Java 线程 轮番执行,当 CMSThread 觉得自己应该让出 CPU 的时候,会 Yield,让出 CPU,让Java业务线程执行。
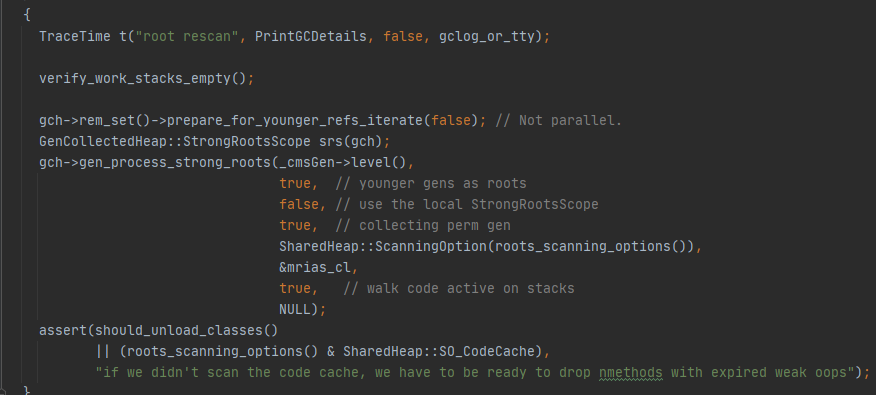
前台GC 的起点是 CMSCollector::acquire_control_and_collect

是否要压缩
mark_sweep_phase1: 将 普通根(Universe,JavaThread,JNI 引用的对象等,注意,没有以年轻代为起点) 做为 起点,对他们和他们引用的对象,以及他们引用的对象引用的对象...... 深度打标(标记栈),打标其实只是为对象头设置特殊值,如果必要,会把对象头保存下来(临时结构)
mark_sweep_phase2: 进行 老年代 和 年轻代 存活对象的地址计算,并且写入到对象头,具体计算方法很简单
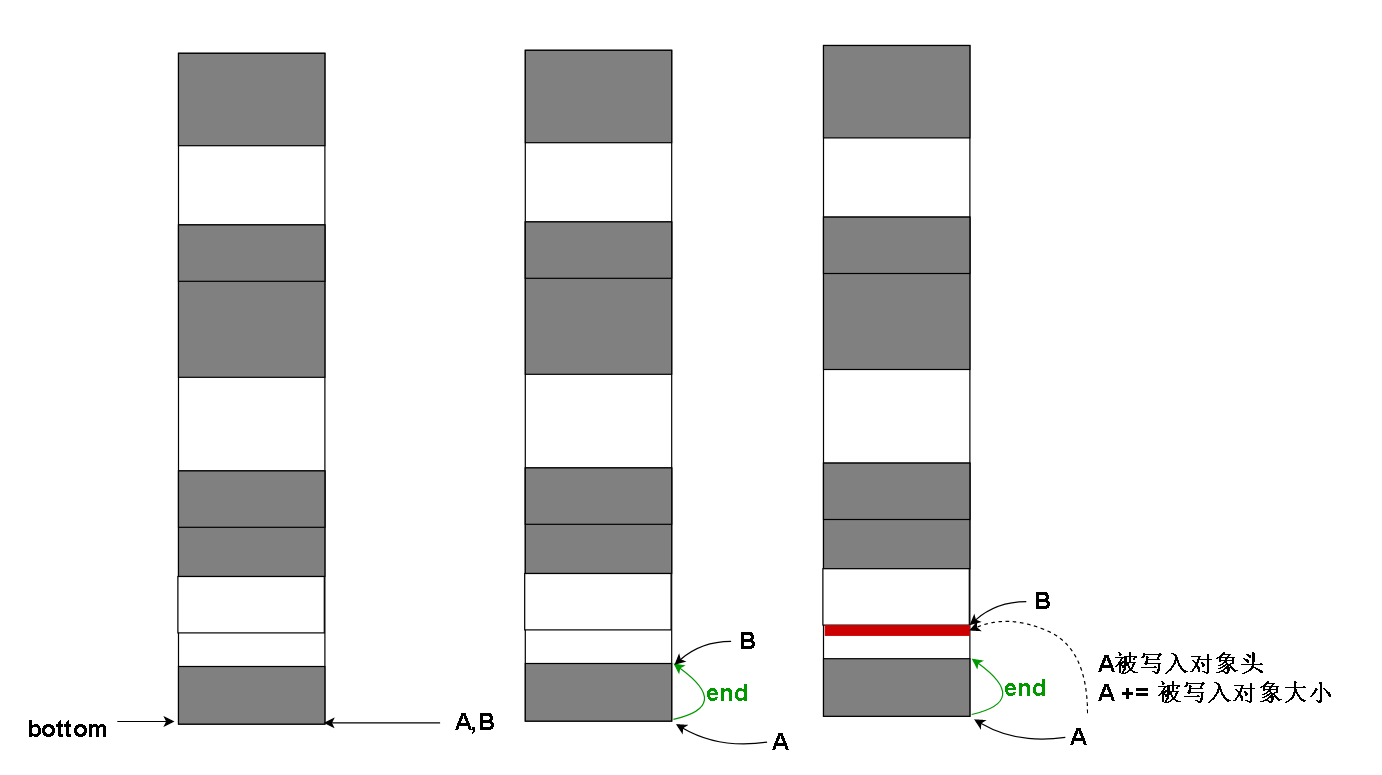
需要俩根指针 A,B。两者一开始都指向 当前代 的 内存空间的 bottom 地址。
假设A 是用来指向可写入地址,B是扫描指针。
B会从 bottom 一直向上扫描,知道扫到顶部为止,中途发现一个活对象,(活对象已在上一步被打标)则把 A 指向的地址(forwardee指针)写进这个对象的对象头。并且执行 A = A + 活对象大小。
如果不是活的,则会一直扫描直到找到存活对象,这样的话,B指针之前会累积一段 非存活对象空间,直接在这段非存活对象空间的起始处,记下本非存活空间的终止地址(也就是下一个存活空间的起始地址)
无论是不是存活对象,B指针都要执行 B = B + 当前对象大小,以便扫描下一个对象。
 ......后面还有,省略
......后面还有,省略
mark_sweep_phase3: 遍历所有space,也就是EdenSpace,CMSspcae,continguousSpace(from,to)然后调用每个space的adjust_pointers,这个方法会遍历一遍对应的space的所有对象,如果对象的引用类型指向的对象(oopDesc),的对象头被设置了 forwardee 指针,则把引用类型调整为
forwardee 指针。
mark_sweep_phase4: 遍历整个老年代和年轻代,将对象头中包含 forwardee 指针的 对象,复制到 forward 指针所指的内存区域
个人感觉 3 和 4 非常耗时,要扫描一遍 两个代的内存区,3是深度搜索,4要复制,都挺耗时。
do_mark_sweep_work 和 后台GC一起讲,因为大体步骤都一样
后台GC 的起点是 CMSCollector::collect_in_background,由 CMSThread 调用
值得注意的是,后台GC 貌似没有给出压缩的方式,而是按照中规中矩的 Mark - Sweep 把老年代垃圾清除掉
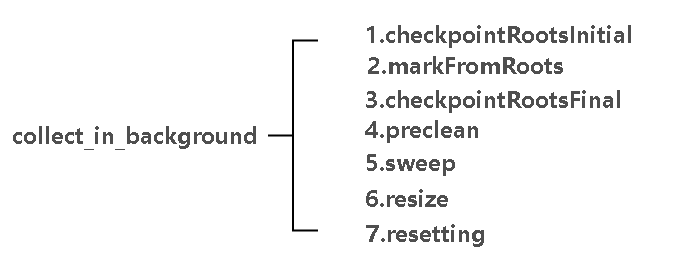
后台GC 是有中规中矩的步骤的,通过一个 while 循环,把这些状态逐个完成。
有一个遍历存储 当前状态,完成当前状态就往下一个状态转化。
伪代码:
while (true) { switch (state) { case initMark : checkPointRootsInitial(); state = nextState; case mark : markFromRoots();state = nextState;
case finalMark : checkpointRootsFinal();state = nextState;
......
}
}
下面的序号和 状态转化的顺序一致。
和年轻代差不多的操作,只不过这里是老年代和年轻代都压缩
需要注意的是,标记压缩标记对象是直接在对象头标记,判断对象是否标记直接 oop->mark()->isMark(); 这样判断就行
非压缩标记的话,需要使用一张 bit_map , 和卡表一样,都是以一个小得多的内存数组去标记某一块内存区域怎么样怎么样了的技巧。
只不过 bit_map 是给对象打标,而卡表标记某个引用关系发生变化的对象对应的内存区域。并且 bit_map 是使用 一位 去对应 shifter 个字(64位机器一个字是64位),而卡表是用一个字节去表示一张卡(一般512B)
粒度不一样
1.checkpointRootInitial : 此阶段需要托付给 VM_Thread 去执行,具体是做为一个 VM_Operation去执行,关于VM_Operation,具体操作和上述类似,但是加多了年轻代,也就是以 普通根 和 年轻代 为起点,浅度地对这些对象打标,也就是只是简单地把他们自己地址对应的位在bit_map 上打标,不会涉及到他们的引用
2.markFromRoots:遍历上一阶段的bit_map, 对bit_map中打标了的位对应的区域的对象(假设为对象集合T0),执行深度打标(打标T0集合中对象引用的对象,引用的对象引用的对象......具体是依赖栈来实现的)
具体操作是遍历 bit_map ,一位一位地遍历,对于脏的位对应的对象,就深度打标
3.checkpointRootsFinal : 此阶段和阶段1一样,也要托付给 VM_Thread,目的都是为了 STW(Stop the world),保持对象引用关系不变。此阶段做的有两件事:
checkpointRootsFinalWork-》do_remark(_non)_parallel
1.把脏卡表的脏内存信息复制到一个modUnionTable 中
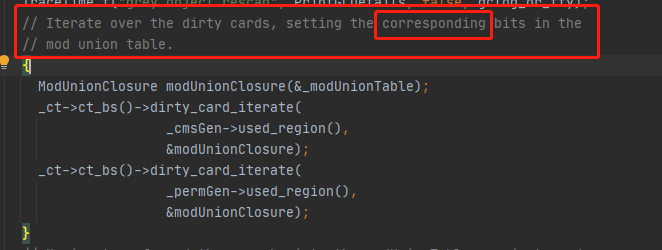
2.遍历脏卡表对应区域的对象,如果他们引用的对象是在老年代的,就给他们的引用打标(怎么保证脏卡表的老年代都是活的?)
![]()
3.遍历普通根对象,遍历年轻代对象,对这些对象进行深度打标,具体也是用栈实现
4.preclean:预清理,这个阶段主要是处理软应用,弱引用之类的 Java 提供的特别引用,个人感觉并不是什么清理的意思,因为实际上的操作会让存活对象多很多。首先是找到一些 referent 还可达的 Reference,把他们从 discoverList 上摘下来
discoverList上的对象 是会被放到 Reference 的 pending 队列的,最后会被 Reference Handler 线程处理。而且会把他们在 modUnionTable 中打标,并且会对 from(来的地方) 和 to 同样在 modUnionTable 中打标。
上面的压缩回收,连年轻代都压缩回收了,但是此处的后台回收,一般不回收年轻代,而且所谓的清理,貌似让更多的对象保留了下来。
5.sweep:这一步是真正的清理了,但是内存实际上不会归还操作系统,只是规还给了JVM c++层面管理来年代内存的 space 类,具体一般是 compatiableFreeListSpace, 是一种基于伙伴算法,用多级链表(每一级链表连接起了一种大小的内存块
一般大小是 2^0, 2^1, 2^2, 2^3 ......)来管理内存的类,这个类还持有一个 类似 map 的字典,键是内存块大小,值是具体内存块。一开始整个老年代是一整块大内存块,放在字典里,多级链表还是空的,当第一次被索要内存的时候,就会把字典里的这块大内存分出一部分填充到 多级链表中,之后如果链表内存不足的话,再向字典要
清理的过程中,也是线性扫描老年代的内存,从 bottom 开始扫描,遇到一个存活对象的时候,前面已经是一段空闲区域或死亡对象组合成的内存区间,这一段内存区间会被归还到compatiableFreeListSpace,而且还会看看是否能和空闲的内存块合成更大的内存块,归还到compatiableFreeListSpace中。
6.resize:重新计算老年代大小,如果需要增大大小就扩容,否则缩容
7 resetting:此步骤是清空之前用的 bit_map 之类的记录工具,以便下次继续GC

 浙公网安备 33010602011771号
浙公网安备 33010602011771号