

逻辑回归---sklearn
前言:
在利用了自己编写的函数之后,希望能用一种更加简洁的方法来实现逻辑回归,因此就期待sklearn的表现了!
正文:
#老朋友
import matplotlib.pyplot as plt
import numpy as np
#判断数据的各种率,来检验这个模型的好坏程度
from sklearn.metrics import classification_report
from sklearn import preprocessing
from sklearn import linear_model
#数据是否需要标准化
scale = False
#载入数据
data = np.genfromtxt("LR-testSet.csv",delimiter=",")
#切割数据
x_data = data[:,:-1]
y_data = data[:,-1]
#定义画图函数,和上一篇博客的内容一致
#可以参考上一篇,注释的很详细
def plot():
x0 = []
x1 = []
y0 = []
y1 = []
#切分不同类别的数据
for i in range(len(x_data)):
if y_data[i]==0:
x0.append(x_data[i,0])
y0.append(x_data[i,1])
else:
x1.append(x_data[i,0])
y1.append(x_data[i,1])
#画图
scatter0 = plt.scatter(x0,y0,c='b',marker='o')
scatter1 = plt.scatter(x1,y1,c='r',marker='x')
#画图例
plt.legend(handles=[scatter0,scatter1],labels=['label0','label1'],loc='best')
plot()
plt.show()
图片展示如下:
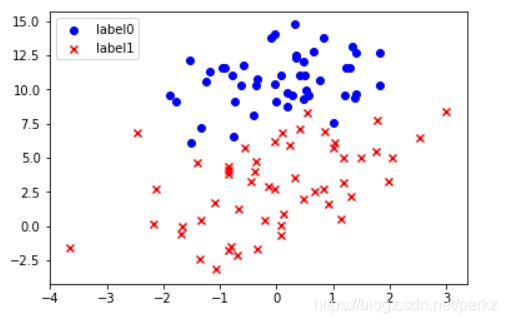
#开始创建逻辑回归模型
logistic = linear_model.LogisticRegression()
#适配模型的参数
logistic.fit(x_data,y_data)
#打印一下逻辑回归的两个参数值(theta1和theta2)
logistic.coef_
#数值成功显示
array([[ 0.44732445, -0.58003724]])
#不做数据标准化
if scale ==False:
#画图决策边界
#调用画图函数
plot()
#将x范围设为-4,3
x_test = np.array([[-4],[3]])
#y的值则直接调用逻辑回归模型的各种参数即可,非常方便
#intercept_就是我们通常所指的截距
#coef_就是我们通常所指的参数值,[0][0]是theta1,[0][1]是theta2
y_test = (-logistic.intercept_ - x_test*logistic.coef_[0][0])/logistic.coef_[0][1]
plt.plot(x_test,y_test,'k')
plt.show()
#直接调用函数来检查一下召回率和正确率
predictions = logistic.predict(x_data)
print(classification_report(y_data,predictions))
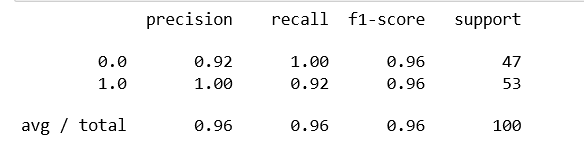
总结:
可以发现调用sklearn库要比自己写要简单的多,但是手写函数是一种加深理解
的过程,用时则用sklearn,究其本质时还需要手写函数来进行验证。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号