
python (2)xpath与定向爬虫
内容来自:极客学院,教学视频;
写在前面:
提取Item
选择器介绍
我们有很多方法从网站中提取数据。Scrapy 使用一种叫做 XPath selectors的机制,它基于 XPath表达式。
这是一些XPath表达式的例子和他们的含义
- /html/head/title: 选择HTML文档<head>元素下面的<title> 标签。
- /html/head/title/text(): 选择前面提到的<title> 元素下面的文本内容
- //td: 选择所有 <td> 元素
- //div[@class="mine"]: 选择所有包含 class="mine" 属性的div 标签元素
这只是几个使用XPath的简单例子,但是实际上XPath非常强大。
为了方便使用XPaths,Scrapy提供XPathSelector 类, 有两种口味可以选择, HtmlXPathSelector
(HTML数据解析) 和XmlXPathSelector (XML数据解析)。 为了使用他们你必须通过一个 Response
对象对他们进行实例化操作。你会发现Selector对象展示了文档的节点结构。因此,第一个实例化的selector必与根节点或者是整个目录有关
。
Selectors 有三种方法
- select():返回selectors列表, 每一个select表示一个xpath参数表达式选择的节点.
- extract():返回一个unicode字符串,该字符串为XPath选择器返回的数据
- re(): 返回unicode字符串列表,字符串作为参数由正则表达式提取出来
一.xpath与定向爬虫
知识点:(话说秒杀 正则表达式啊)
// 定位根节点
/往下层寻找
/text()获取标签中的内容
/@xxxx提取属性的内容
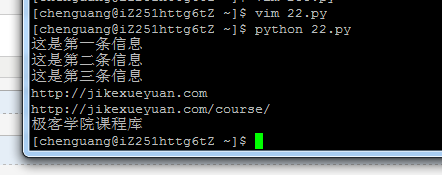
1 #-*-coding:utf8-*- 2 from lxml import etree 3 html = ''' 4 <!DOCTYPE html> 5 <html> 6 <head lang="en"> 7 <meta charset="UTF-8"> 8 <title>测试-常规用法</title> 9 </head> 10 <body> 11 <div id="content"> 12 <ul id="useful"> 13 <li>这是第一条信息</li> 14 <li>这是第二条信息</li> 15 <li>这是第三条信息</li> 16 </ul> 17 <ul id="useless"> 18 <li>不需要的信息1</li> 19 <li>不需要的信息2</li> 20 <li>不需要的信息3</li> 21 </ul> 22 23 <div id="url"> 24 <a href="http://jikexueyuan.com">极客学院</a> 25 <a href="http://jikexueyuan.com/course/" title="极客学院课程库">点我打开课程库</a> 26 </div> 27 </div> 28 29 </body> 30 </html> 31 ''' 32 33 selector = etree.HTML(html) 34 35 #提取文本 36 content = selector.xpath('//ul[@id="useful"]/li/text()')#提取li标签里的内容 37 for each in content: 38 print each 39 40 #提取属性 41 link = selector.xpath('//a/@href')#提取标签里面的链接 42 for each in link: 43 print each 44 45 title = selector.xpath('//a/@title') 46 print title[0]
运行结果:
二. xpath的特殊用法
例如:1. start-with(@属性名称,属性地址相同的部分)
2.string(.)
1 #-*-coding:utf8-*- 2 from lxml import etree 3 4 html1 = ''' 5 <!DOCTYPE html> 6 <html> 7 <head lang="en"> 8 <meta charset="UTF-8"> 9 <title></title> 10 </head> 11 <body> 12 <div id="test-1">需要的内容1</div> 13 <div id="test-2">需要的内容2</div> 14 <div id="testfault">需要的内容3</div> 15 </body> 16 </html> 17 ''' 18 19 html2 = ''' 20 <!DOCTYPE html> 21 <html> 22 <head lang="en"> 23 <meta charset="UTF-8"> 24 <title></title> 25 </head> 26 <body> 27 <div id="test3"> 28 我左青龙, 29 <span id="tiger"> 30 右白虎, 31 <ul>上朱雀, 32 <li>下玄武。</li> 33 </ul> 34 老牛在当中, 35 </span> 36 龙头在胸口。 37 </div> 38 </body> 39 </html> 40 ''' 41 42 selector = etree.HTML(html1) 43 content = selector.xpath('//div[starts-with(@id,"test")]/text()') 44 for each in content: 45 print each 46 47 selector = etree.HTML(html2) 48 content_1 = selector.xpath('//div[@id="test3"]/text()') 49 for each in content_1: 50 print each 51 52 53 data = selector.xpath('//div[@id="test3"]')[0] 54 info = data.xpath('string(.)') 55 content_2 = info.replace('\n','').replace(' ','') 56 print content_2
运行结果:

三:实战演练 百度贴吧
1 #-*-coding:utf8-*- 2 from lxml import etree 3 from multiprocessing.dummy import Pool as ThreadPool 4 import requests 5 import json 6 import sys 7 8 reload(sys) 9 10 sys.setdefaultencoding('utf-8') 11 12 '''重新运行之前请删除content.txt,因为文件操作使用追加方式,会导致内容太多。''' 13 14 def towrite(contentdict): 15 f.writelines(u'回帖时间:' + str(contentdict['topic_reply_time']) + '\n') 16 f.writelines(u'回帖内容:' + unicode(contentdict['topic_reply_content']) + '\n') 17 f.writelines(u'回帖人:' + contentdict['user_name'] + '\n\n') 18 19 def spider(url): 20 html = requests.get(url) 21 selector = etree.HTML(html.text) 22 content_field = selector.xpath('//div[@class="l_post l_post_bright "]') 23 item = {} 24 for each in content_field: 25 reply_info = json.loads(each.xpath('@data-field')[0].replace('"','')) 26 author = reply_info['author']['user_name'] 27 content = each.xpath('div[@class="d_post_content_main"]/div/cc/div[@class="d_post_content j_d_post_content "]/text()')[0] 28 reply_time = reply_info['content']['date'] 29 print content 30 print reply_time 31 print author 32 item['user_name'] = author 33 item['topic_reply_content'] = content 34 item['topic_reply_time'] = reply_time 35 towrite(item) 36 37 if __name__ == '__main__': 38 pool = ThreadPool(4) 39 f = open('content.txt','a') 40 page = [] 41 for i in range(1,21): 42 newpage = 'http://tieba.baidu.com/p/3522395718?pn=' + str(i) 43 page.append(newpage) 44 45 results = pool.map(spider, page) 46 pool.close() 47 pool.join() 48 f.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号