spark本地调试--在linux系统上,使用ideal本地调试spark程序
本地程序调试步骤:
1、修改master参数为local[*]
*也可以是任何大于1的数,但不可以为1,因为spark执行时,需要至少2个线程。
2、配置本地程序参数
在idea上运行spark程序,需要配置部分如下
点击run->Edit configuration
·········![]()
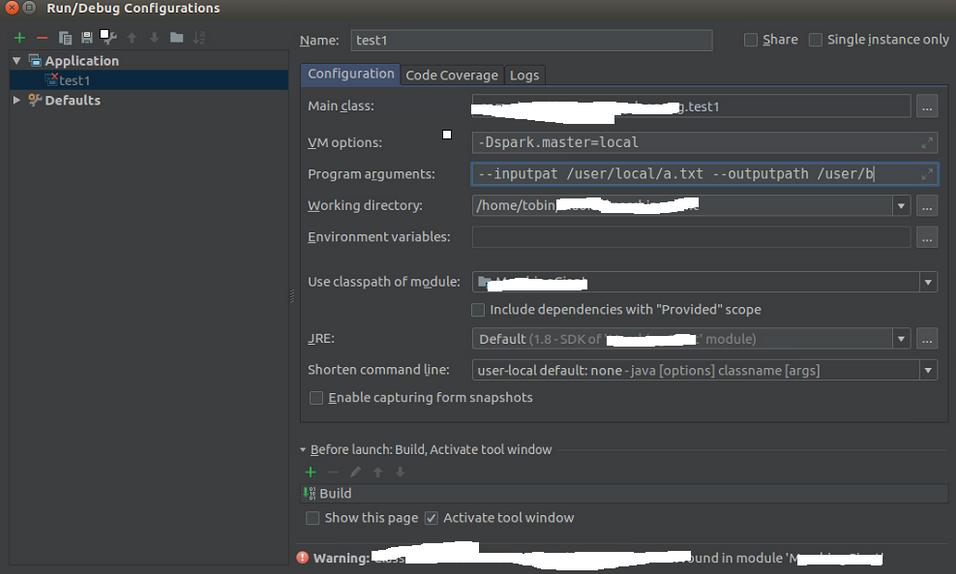
需要配置的地方:
Main class: 指定为本程序的main函数所在文件
Use classpath of module 主程序所在的文件夹
JRE 指定JDK
VM options 配置的是配置参数,规定了spark运行的一些配置
program arguments 配置的是输入的参数,要注意的是,输入变量和对应的值之间用空格分开,并且值不需要用引号括起来
由于实际应用中使用的是spark structed streaming所以,用不上参数。仅仅配置了VM options就完成了本地测试。
另外,由于使用的spark 的standalone模式,因此也没用上hadoop。如果是spark + hadoop代码,需要配置hadoop。(以后需要用到时,继续添加该部分内容)
3、配置好build.sbt
build.sbt中依赖包版本不对,往往会出现问题。
本地调试时遇到的问题:
1、本机的IP地址和机器名映射问题
WARN Utils: Service 'SparkDriver' could not bind on a random free port . you may check whether configuring an appropriate binding address.
问题原因:
经查名 hostname与ip之间对应关系存在问题:
本机的Hostname是xxxx.com
/etc/hosts下
127.0.0.1 localhost
添加以下内容:
127.0.0.1 xxxx.com
192.168.10.10 xxx.com
问题解决后,本地调试可以运行
2、build.sbt配置文件问题
如下所示的配置文件,是某次编写spark structed streaming时的配置文件,在刚开始编写时,由于sbt文件中spark-core的版本写成了2.4.6导致一直运行失败。将所有依赖库版本,参考spark源码内的版本,进行定制后,程序成功在本地运行。
name := "realvirus"
version := "0.1"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" % "spark-core_2.11" % "2.3.1"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.3.1"
libraryDependencies += "org.apache.spark" % "spark-sql-kafka-0-10_2.11" % "2.3.1"
libraryDependencies += "mysql" % "mysql-connector-java" % "8.0.21"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号