

深度学习笔记011DropOut丢弃法
丢弃法——一种效果比权重衰退更好的解决过拟合问题的方法,最早的深度学习随机化的一种算法
丢弃法的 动机:
一个好的模型需要对输入数据的扰动鲁棒。
使用有噪音的数据等价于Tikhonov正则。
丢弃法:不在输入加噪音,而是在层之间加入噪音

有p概率地把xi变成0,并将其他的元素放大1-p倍,最后期望仍然是xi。
通常将丢弃法作用在隐藏全连接层的输出上:
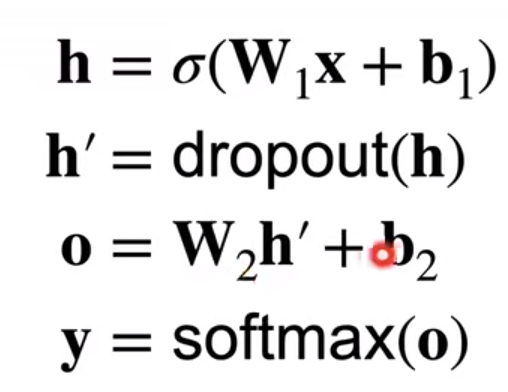
*推理中的dropout:h=dropout(h)
训练过程才使用dropout,它是一个正则项,只在训练的时候使用,只会对权重作出影响;所以在推理中不需要dropout,因为推理中不需要改变权重。

它很少用于CNN等网络。
p常常取值为0.1、0.9、0.5
Q&A:
1、神经网络中的可重复性非常难得,但是dropout还好,设好随机种子,就能保证dropout的重复性;但是一般来说,咱们不太需要可重复性,随机性不是个坏事情,高随机性往往代表着高稳定性。
2、改全连接层是一种方式,改标签也是一种方式。
3、dropout主要对全连接层使用;weight_decay在各种方面都可以用,但是相对来说dropout更好调参(0.1/0.5/0.9),比如dropout调为0.5,将层数翻倍,和之前的训练量差不多,但是很可能泛化能力会提升。
4、dropout的介入会造成参数收敛更慢,因为梯度更新变得不那么频繁了,但一般情况下,我们介入dropout不会调整lr。
1 import torch 2 from torch import nn 3 from d2l import torch as d2l 4 5 def dropout_layer(X,dropout): 6 assert 0<=dropout<=1 7 if dropout==1: 8 return torch.zeros_like(X) 9 if dropout==0: 10 return X 11 #mask=(torch.randn(X.shape)>dropout).float() 沐神手快敲错了 12 #rand和randn区别:https://blog.csdn.net/wangwangstone/article/details/89815661 13 mask = (torch.rand(X.shape) > dropout).float() 14 # 这里其实就相当于,在里面随机生成了一个矩阵,值为0-1的均匀分布,取里面大于dropout的值为1,在return中相乘就相当于保留下来,另外 15 # dropout概率的那部分会因为不满足“>”号取到false,也就是0,在return中相乘会直接舍去当时的值。 16 return mask*X/(1.0-dropout) 17 18 ''' 19 便于你理解dropout里面那段函数 20 A=torch.tensor([[1,2,3,4],[5,6,7,8],[9,10,11,12]]) 21 print(A) 22 B=torch.rand(A.shape) 23 print(B) 24 mask=(torch.rand(A.shape)>0.2).float() 25 print(mask) 26 ''' 27 28 # 测试dropout_layer 函数 29 def test_dropout_layer(): 30 X=torch.arange(16,dtype=torch.float32).reshape((2,8)) 31 print(X) 32 print(dropout_layer(X,0)) 33 print(dropout_layer(X, 0.5)) 34 print(dropout_layer(X, 1)) 35 36 test_dropout_layer() 37 38 39 num_inputs,num_outputs,num_hiddens1,num_hiddens2=784,10,256,256 40 dropout1,dropout2=0.2,0.5 41 42 class Net(nn.Module): 43 def __init__(self,num_inputs,num_outputs,num_hiddens1,num_hiddens2,is_training=True): 44 super(Net,self).__init__() 45 self.num_inputs=num_inputs 46 self.training=is_training 47 self.lin1=nn.Linear(num_inputs,num_hiddens1) 48 self.lin2=nn.Linear(num_hiddens1,num_hiddens2) 49 self.lin3=nn.Linear(num_hiddens2,num_outputs) 50 self.relu=nn.ReLU() 51 52 def forward(self,X): 53 H1=self.relu(self.lin1(X.reshape((-1,self.num_inputs)))) 54 if self.training==True: 55 H1=dropout_layer(H1,dropout1) 56 H2=self.relu(self.lin2(H1)) 57 if self.training==True: 58 H2=dropout_layer(H2,dropout2) 59 out=self.lin3(H2) 60 return out 61 62 # net=Net(num_inputs,num_outputs,num_hiddens1,num_hiddens2) 63 # 64 # num_epochs,lr,batch_size=10,0.5,256 65 # loss = nn.CrossEntropyLoss() 66 # train_iter,test_iter=d2l.load_data_fashion_mnist(batch_size) 67 # trainer=torch.optim.SGD(net.parameters(),lr=lr) 68 # d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,trainer) 69 # d2l.plt.show() 70 71 # 简洁实现 72 net=nn.Sequential(nn.Flatten(),nn.Linear(784,256),nn.ReLU(),nn.Dropout(dropout1),nn.Linear(256,256),nn.ReLU(),nn.Dropout(dropout2),nn.Linear(256,10)) 73 def init_weights(m): 74 if type(m)==nn.Linear: 75 nn.init.normal_(m.weight,std=0.01) 76 77 net.apply(init_weights) 78 79 num_epochs,lr,batch_size=10,0.5,256 80 loss = nn.CrossEntropyLoss() 81 train_iter,test_iter=d2l.load_data_fashion_mnist(batch_size) 82 trainer=torch.optim.SGD(net.parameters(),lr=lr) 83 d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,trainer) 84 d2l.plt.show()
Result
dropout的p取0.2和0.5,以及都取0的结果如下:
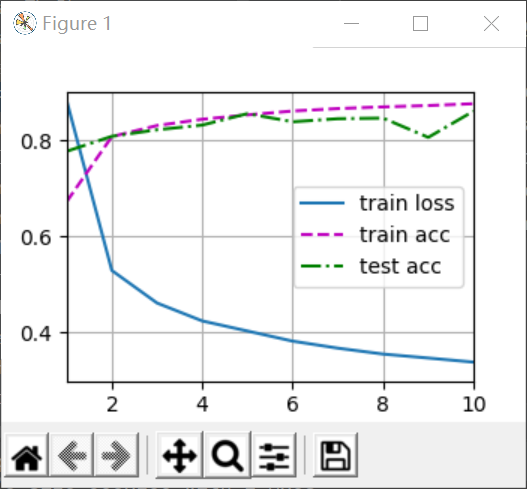
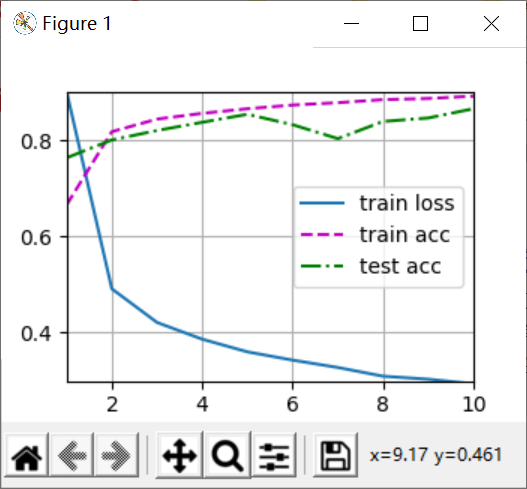
可以看到,左图有dropout的情况下,train acc变小了一小点,train loss变大了一些,这是过拟合问题得到一定缓解的现象;
test acc基本没有变化,说明这个dropout参数对模型的泛化能力提高的作用甚微。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号