

深度学习笔记ModelChoosingWithUnderfittingAndOverfitting模型选择、欠拟合&过拟合
什么是训练误差和泛化误差?
数据不够怎么办?
K-折交叉验证
过拟合、欠拟合
模型容量、数据复杂度
VC维
(见代码注释部分)
此外,代码部分用比较简单的数据演示了欠拟合与过拟合,见result
1 ''' 2 训练误差:模型在训练集上的误差 3 泛化误差:模型在新的数据上的误差 4 我们更加关心泛化误差,因为在训练中表现得好,不代表未来数据中一定会好。 5 *验证数据集不能和训练数据混在一起(老手也经常犯得错误) 6 7 常态:数据不够多怎么办? 8 K-fold cross validation——K折交叉验证 9 将训练数据分割成K快,每次取第i块做验证数据集,其余作为训练数据集,报告K个验证集误差的平均。 10 常用:K=5或者10 11 非大数据集常使用K-折交叉验证 12 13 14 过拟合不算那么坏,首先模型要足够大,才能够证明这个模型能够拟合这个数据,之后再解决过拟合的问题即可; 15 但如果欠拟合,可能是模型容量不足,根本没有能力拟合这个数据。 16 17 18 模型容量低,在简单数据上正常,复杂数据上欠拟合; 19 模型容量高,在简单数据上过拟合,复杂数据上正常。 20 21 模型容量难以在不同种类的模型中进行比较 22 但是可以估算模型容量:参数的个数,与参数的选择范围 23 24 VC维 25 对于一个分类模型,VC维等价于一个最大的数据集的大小,不管如何给定标号,都存在一个模型对它进行完美分类 26 比如对于二维的线性感知机,我们可以区分开任意三个点,所以VC=3 27 而对于4个点,咱们就不能随意区分了,比如XOR问题。 28 支持N维输入的感知机的VC维是N+1 29 一些多层感知机的VC维是O(Nlog2(N)) 30 31 VC维能提供为什么一个模型好的依据——可以衡量训练误差和泛化误差之间的间隔 32 但是目前衡量恨不准确,计算深度学习的VC维很困难,因此深度学习中目前很少使用。 33 34 数据复杂度影响因素 35 样本个数 每个样本的元素个数 时间、空间结构 多样性(几分类) 36 37 ''' 38 import math 39 import numpy as np 40 import torch 41 from torch import nn 42 from d2l import torch as d2l 43 44 max_degree=20 45 n_train,n_test=100,100 46 true_w=np.zeros(max_degree) 47 print(true_w) 48 true_w[0:4]=np.array([5,1.2,-3.4,5.6]) 49 50 features=np.random.normal(size=(n_test+n_train,1)) 51 np.random.shuffle(features) 52 print(features) 53 poly_features=np.power(features,np.arange(max_degree).reshape(1,-1)) #power函数:https://www.jb51.net/article/207426.htm 54 print(poly_features) 55 for i in range(max_degree): 56 poly_features[:,i]/=math.gamma(i+1) #gamma函数是一个大问题,暂时在今天不展开 57 labels=np.dot(poly_features,true_w) 58 labels+=np.random.normal(scale=0.1,size=labels.shape) 59 60 true_w,features,poly_features,labels=[torch.tensor(x,dtype=torch.float32) 61 for x in [true_w,features,poly_features,labels]] 62 print(features[:2],"\n",poly_features[:2,:],"\n",labels[:2]) 63 64 def evaluate_loss(net, data_iter, loss): #@save 65 """评估给定数据集上模型的损失""" 66 metric = d2l.Accumulator(2) # 损失的总和,样本数量 67 for X, y in data_iter: 68 out = net(X) 69 y = y.reshape(out.shape) 70 l = loss(out, y) 71 metric.add(l.sum(), l.numel()) 72 return metric[0] / metric[1] 73 74 def train(train_features, test_features, train_labels, test_labels, 75 num_epochs=400): 76 loss = nn.MSELoss() 77 input_shape = train_features.shape[-1] 78 # 不设置偏置,因为我们已经在多项式中实现了它 79 net = nn.Sequential(nn.Linear(input_shape, 1, bias=False)) 80 batch_size = min(10, train_labels.shape[0]) 81 train_iter = d2l.load_array((train_features, train_labels.reshape(-1,1)), 82 batch_size) 83 test_iter = d2l.load_array((test_features, test_labels.reshape(-1,1)), 84 batch_size, is_train=False) 85 trainer = torch.optim.SGD(net.parameters(), lr=0.001) 86 animator = d2l.Animator(xlabel='epoch', ylabel='loss', yscale='log', 87 xlim=[1, num_epochs], ylim=[1e-3, 1e2], 88 legend=['train', 'test']) 89 for epoch in range(num_epochs): 90 d2l.train_epoch_ch3(net, train_iter, loss, trainer) 91 if epoch == 0 or (epoch + 1) % 20 == 0: 92 animator.add(epoch + 1, (evaluate_loss(net, train_iter, loss), 93 evaluate_loss(net, test_iter, loss))) 94 print('weight:', net[0].weight.data.numpy()) 95 d2l.plt.show() 96 97 98 #train(poly_features[:n_train, :4], poly_features[n_train:, :4], 99 # labels[:n_train], labels[n_train:]) 100 101 # train(poly_features[:n_train, :2], poly_features[n_train:, :2], 102 # labels[:n_train], labels[n_train:]) 103 104 train(poly_features[:n_train, :], poly_features[n_train:, :], 105 labels[:n_train], labels[n_train:])
结果
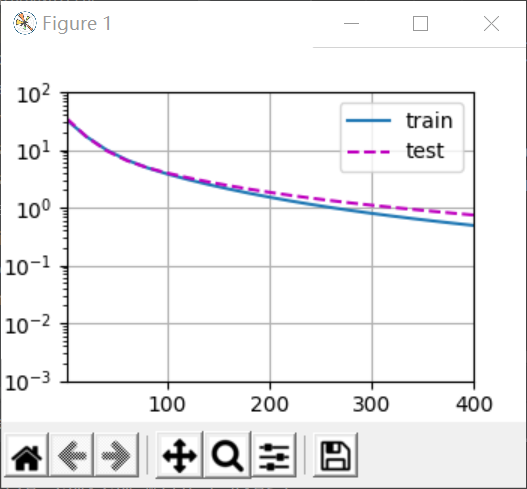
可以看到,当train取前四列(因为只有前4列有值)时,拟合效果不错,这是正常拟合,一般情况下test的损失肯定要比train高。
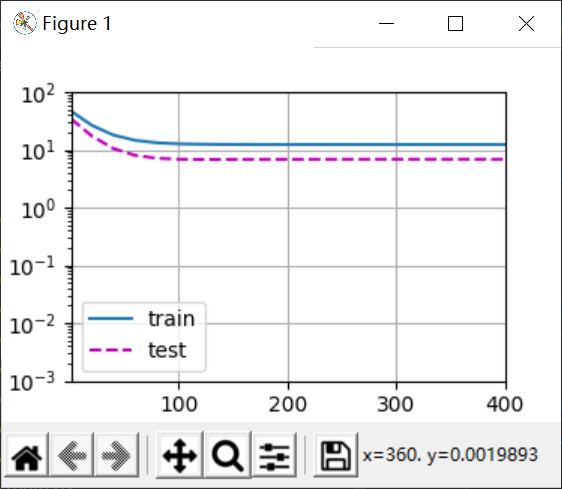
当train取前2列,这就是欠拟合,因为模型没能拟合出来,所以train的损失非常高。
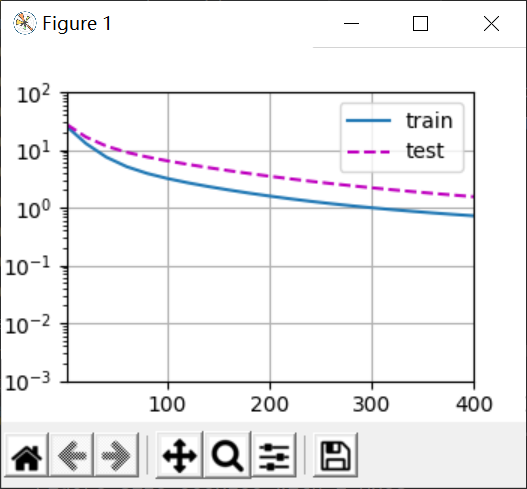
最后是过拟合,因为完全拟合了训练数据,所以train的loss远远低于test(我不知道为啥我用pycharm跑出来gap这么小,沐神在jpt上跑的离离原上谱了)
Q&A
1、SVM的可调的东西不多;SVM处理巨大数据时鸡肋;神经网络相对来说的优点——神经网络像是一门语言,每个layer都是一个小工具,我们可以对其进行很灵活的编程,可编程性非常强。
2、时间序列上的数据,常用最晚的数据作为验证集。
3、K-折交叉验证很少用于很大的数据集,所以深度学习基本不会用。
4、在分类问题中,类别严重不平衡,若数据集大那边无所谓,但是数据集小的话,验证集要尽量按1:1来算。
5、
这里的VC维和图片的维度、向量的维度不是一回事。
6、我们希望神经网络它是科学,但它其实是工程,同时他又是一门艺术。
work先出来,valid后出来,常常是常态。
7、优化、模型是两回事,集成学习的原理一定要区分开优化和模型。
8、数据集可以不平衡,但是我们应该通过加权使数据集平衡。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号