



Mybatis介绍之缓存
Mybatis介绍之缓存
Mybatis中有一级缓存和二级缓存,默认情况下一级缓存是开启的,而且是不能关闭的。一级缓存是指SqlSession级别的缓存,当在同一个SqlSession中进行相同的SQL语句查询时,第二次以后的查询不会从数据库查询,而是直接从缓存中获取,一级缓存最多缓存1024条SQL。二级缓存是指可以跨SqlSession的缓存。
Mybatis中进行SQL查询是通过org.apache.ibatis.executor.Executor接口进行的,总体来讲,一共有两类实现,一类是BaseExecutor,一类是CachingExecutor。前者是非启用二级缓存时使用的,而后者是采用的装饰器模式,在启用二级缓存时使用,当二级缓存没有命中时,底层还是通过BaseExecutor来实现的。
一级缓存
一级缓存的工作原理:
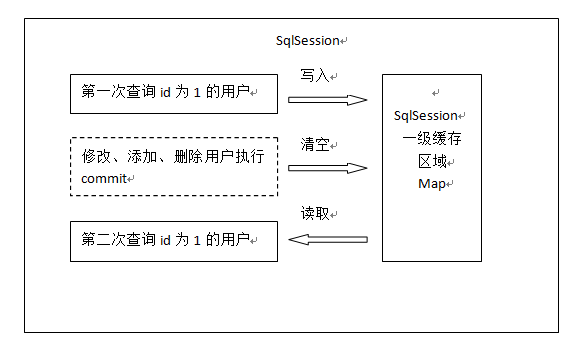
一级缓存是默认启用的,在BaseExecutor的query()方法中实现,底层默认使用的是PerpetualCache实现,PerpetualCache采用HashMap存储数据。一级缓存会在进行增、删、改操作时进行清除。
一级缓存的范围有SESSION和STATEMENT两种,默认是SESSION,如果不需要使用一级缓存,那么可以把一级缓存的范围指定为STATEMENT,每次执行完一个Mapper语句后,都会将一级缓存清除。如果只是需要对某一条select语句禁用一级缓存,则可以在对应的select元素上加上flushCache="true"。如果需要更改一级缓存的范围,请在Mybatis的配置文件中,在<settings>下通过localCacheScope指定。
<setting name="localCacheScope" value="SESSION"/>
在testCache1中,通过同一个SqlSession查询了两次一样的SQL,第二次不会发送SQL。在testCache2中,也是查询了两次一样的SQL,但是它们是不同的SqlSession,结果会发送两次SQL请求。需要注意的是当Mybatis整合Spring后,直接通过Spring注入Mapper的形式,如果不是在同一个事务中每个Mapper的每次查询操作都对应一个全新的SqlSession实例,这个时候就不会有一级缓存的命中,如有需要可以启用二级缓存。而在同一个事务中时,共用的就是同一个SqlSession。
/** * 默认是有一级缓存的,一级缓存只针对于使用同一个SqlSession的情况。<br/> * 注意:当使用Spring整合后的Mybatis,不在同一个事务中的Mapper接口对应的操作是没有一级缓存的,因为它们是对应不同的SqlSession。在本示例中如需要下面的第二个语句可使
用一级缓存,需要testCache()方法在一个事务中,使用@Transactional标注。 */ @Test public void testCache() { PersonMapper mapper = session.getMapper(PersonMapper.class); mapper.findById(5L); mapper.findById(5L); } @Test public void testCache2() { SqlSession session1 = this.sessionFactory.openSession(); SqlSession session2 = this.sessionFactory.openSession(); session1.getMapper(PersonMapper.class).findById(5L); session2.getMapper(PersonMapper.class).findById(5L); }
二级缓存
mybatis中的二级缓存是mapper级别的缓存,值得注意的是,不同的mapper都有一个二级缓存,也就是说,不同的mapper之间的二级缓存是互不影响的。
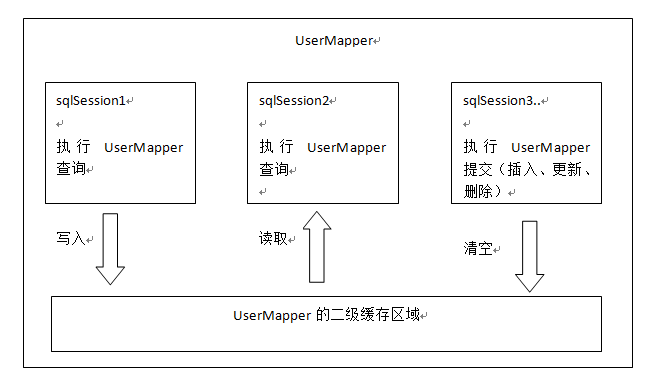
多个sqlSession可以共享一个mapper中的二级缓存区域。mybatis是如何区分不同mapper的二级缓存区域呢?是按照不同mapper有不同的namespace来区分的,如果两个mapper的namespace相同,即使是两个mapper,那么这两个mapper中执行sql查询到的数据也将存在相同的二级缓存区域中。
二级缓存是默认启用的,如想取消,则可以通过Mybatis配置文件中的<settings>元素下的子元素<setting>来指定cacheEnabled为false。
<settings>
<setting name="cacheEnabled" value="false" />
</settings>
cacheEnabled默认是启用的,只有在该值为true的时候,底层使用的Executor才是支持二级缓存的CachingExecutor。具体核心配置类org.apache.ibatis.session.Configuration的newExecutor方法实现。
public Executor newExecutor(Transaction transaction, ExecutorType executorType) { executorType = executorType == null ? defaultExecutorType : executorType; executorType = executorType == null ? ExecutorType.SIMPLE : executorType; Executor executor; if (ExecutorType.BATCH == executorType) { executor = new BatchExecutor(this, transaction); } else if (ExecutorType.REUSE == executorType) { executor = new ReuseExecutor(this, transaction); } else { executor = new SimpleExecutor(this, transaction); } if (cacheEnabled) { executor = new CachingExecutor(executor); } executor = (Executor) interceptorChain.pluginAll(executor); return executor; }
要使用二级缓存除上面一个配置外,还需要在对应的Mapper.xml文件中定义需要使用的cache

默认情况下所有select语句的useCache都是true,如果在启用二级缓存后,有某个查询语句是不想缓存的,则可以通过指定其useCache为false来达到对应的效果。
<select id="findOrderListResultMap" resultMap="ordersUserMap" useCache="false">
@Override public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { Cache cache = ms.getCache(); if (cache != null) { flushCacheIfRequired(ms); if (ms.isUseCache() && resultHandler == null) { ensureNoOutParams(ms, parameterObject, boundSql); @SuppressWarnings("unchecked") List<E> list = (List<E>) tcm.getObject(cache, key); if (list == null) { list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); tcm.putObject(cache, key, list); // issue #578 and #116 } return list; } } return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); }
在mapper的同一个namespace中,如果有其它insert、update、delete操作数据后需要刷新缓存,如果不执行刷新缓存会出现脏读。 设置statement配置中的flushCache=”true” 属性,默认情况下为true,即刷新缓存,如果改成false则不会刷新。使用缓存时如果手动修改数据库表中的查询数据会出现脏读。
<insert id="insertUser" parameterType="cn.itcast.mybatis.po.User" flushCache="true">
一般下执行完commit操作都需要刷新缓存,flushCache=true表示刷新缓存,这样可以避免数据库脏读。所以默认即可
cache定义
想使用二级缓存,是需要在对应的Mapper.xml文件中,定义其中的查询语句需要使用哪个cache来缓存数据的。这有两种方式可以定义,一种是通过cache元素定义,一种是通过cache-ref元素来定义。但是需要注意的是对于同一个Mapper来讲,只能使用一个Cache,当同时使用<cache>和<cache-ref>时,使用<cache>定义的优先级更高。Mapper使用的Cache是与我们的Mapper对应的namespace绑定的,一个namespace最多只会有一个Cache与其绑定。
cache元素定义
使用cache元素来定义使用的Cache时,最简单的做法是直接在对应的Mapper.xml文件中指定一个空的<cache/>元素,这个时候Mybatis会按照默认配置创建一个Cache对象,准备的说是PerpetualCache对象,更准确的说是LruCache对象(底层用了装饰器模式)。具体可以参考XMLMapperBuilder中的cacheElement()方法中解析cache元素的逻辑。空cache元素定义会生成一个采用最近最少使用算法最多只能存储1024个元素的缓存,而且是可读写的缓存,即该缓存是全局共享的,任何一个线程在拿到缓存结果后对数据的修改都将影响其它线程获取的缓存结果,因为它们是共享的,同一个对象。
cache元素可指定如下属性,每种属性的指定都是针对底层Cache的一种装饰,采用的是装饰器的模式。
- blocking:默认为false,当指定为true时将采用BlockingCache进行封装,blocking,阻塞的意思,使用BlockingCache会在查询缓存时,锁住对应的Key,如果缓存命中则会释放对应的锁,否则会在查询数据库以后再释放锁,这样可以阻止并发情况下多个线程同时查询数据,详情可参考BlockingCache的源码。
- eviction:eviction,驱逐的意思。也就是元素驱逐算法,默认是LRU,对应的就是LruCache,其默认只保存1024个Key,超出时按照最近最少使用算法进行驱逐,详情请参考LruCache的源码。如果想使用自己的算法,则可以将该值指定为自己的驱逐算法实现类,只需要自己的类实现Mybatis的Cache接口即可。除了LRU以外,系统还提供FIFO(先进先出,对应FifoCache)、SOFT(采用软引用存储Value,便于垃圾回收,对应SoftCache)和WEAK(采用弱引用存储Value,便于垃圾回收,对应WeakCache)这三种策略。
- flushInterval:清空缓存的时间间隔,单位是毫秒,默认是不会清空的。当指定该值时会再用ScheduleCache包装一次,其会在每次对缓存进行操作时,判断距离最近一次清空缓存的时间是否超过了flushInterval指定的时间,如果超出了,则清空当前的缓存,详情可参考ScheduleCache的实现。
- readOnly:是否只读,默认为false。当指定为false时,底层会用SerializedCache包装一次,其会在写缓存的时候,将缓存对象进行序列化,然后在读缓存的时候进行反序列化,这样每次读到的都将是一个新的对象,即使你更改了读取到的结果,也不会影响原来缓存的对象,即非只读,你每次拿到这个缓存结果都可以进行修改,而不会影响原来的缓存结果;当指定为true时那就是每次获取的都是同一个引用,对其修改会影响后续的缓存数据获取,这种情况下是不建议对获取到的缓存结果进行更改,意为只读。这是Mybatis二级缓存读写和只读的定义,可能与我们通常情况下的只读和读写意义有点不同。每次都进行序列化和反序列化无疑会影响性能,但是这样的缓存结果更安全,不会被随意更改,具体可根据实际情况进行选择。详情可参考SerializedCache的源码。
- size:用来指定缓存中最多保存的Key的数量。其是针对LruCache而言的,LruCache默认只存储最多1024个Key,可通过该属性来改变默认值,当然,如果你通过eviction指定自己的驱逐算法,同时自己的实现里面也有setSize方法,那么也可以通过cache的size属性给自定义的驱逐算法里面的size赋值。
- type:type属性用来指定当前底层缓存实现类,默认是PerpetualCache,如果我们想使用自定义的Cache,则可以通过该属性来指定,对应的值是我们自定义的Cache的全路径名称。
cache-ref元素定义
cache-ref元素可以用来指定其它Mapper.xml中定义的Cache,有的时候可能多个不同的Mapper需要共享同一个缓存的,是希望在MapperA中缓存的内容在MapperB中可以直接命中的,这个时候就可以考虑使用cache-ref,这种场景只需要保证它们的缓存的Key是一致的即可命中,二级缓存的Key是通过Executor接口的createCacheKey()方法生成的,其实现基本都是BaseExecutor,源码如下。
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) { if (closed) { throw new ExecutorException("Executor was closed."); } CacheKey cacheKey = new CacheKey(); cacheKey.update(ms.getId()); cacheKey.update(Integer.valueOf(rowBounds.getOffset())); cacheKey.update(Integer.valueOf(rowBounds.getLimit())); cacheKey.update(boundSql.getSql()); List<ParameterMapping> parameterMappings = boundSql.getParameterMappings(); TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry(); // mimic DefaultParameterHandler logic for (int i = 0; i < parameterMappings.size(); i++) { ParameterMapping parameterMapping = parameterMappings.get(i); if (parameterMapping.getMode() != ParameterMode.OUT) { Object value; String propertyName = parameterMapping.getProperty(); if (boundSql.hasAdditionalParameter(propertyName)) { value = boundSql.getAdditionalParameter(propertyName); } else if (parameterObject == null) { value = null; } else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) { value = parameterObject; } else { MetaObject metaObject = configuration.newMetaObject(parameterObject); value = metaObject.getValue(propertyName); } cacheKey.update(value); } } if (configuration.getEnvironment() != null) { // issue #176 cacheKey.update(configuration.getEnvironment().getId()); } return cacheKey; }
想在PersonMapper.xml中的查询都使用在UserMapper.xml中定义的Cache,则可以通过cache-ref元素的namespace属性指定需要引用的Cache所在的namespace,即UserMapper.xml中的定义的namespace,假设在UserMapper.xml中定义的namespace是mybatis.dao.UserMapper,则在PersonMapper.xml的cache-ref应该定义如下。
<cache-ref namespace=".mybatis.dao.UserMapper"/>
自定义cache
前面提到Mybatis的Cache默认会使用PerpetualCache存储数据,如果想使用其它缓存框架来实现,比如使用Ehcache、Redis等,这个时候我们就可以使用自己的Cache实现,Mybatis是给我们留有对应的接口,允许进行自定义的。要想实现自定义的Cache必须定义一个自己的类来实现Mybatis提供的Cache接口,实现对应的接口方法。注意,自定义的Cache必须包含一个接收一个String参数的构造方法,这个参数就是Cache的ID,详情请参考Mybatis初始化Cache的过程,对应XMLMapperBuilder的cacheElement()方法。以下是一个简单的MyCache的实现。
publicclass MyCache implements Cache { private String id; private String name;//Name,故意加这么一个属性,以方便演示给自定义Cache的属性设值 private Map<Object, Object> cache = new HashMap<Object, Object>(); /** * 构造方法。自定义的Cache实现一定要有一个id参数 * @param id */ public MyCache(String id) { this.id = id; } @Override public String getId() { return this.id; } @Override public void putObject(Object key, Object value) { this.cache.put(key, value); } @Override public Object getObject(Object key) { return this.cache.get(key); } @Override public Object removeObject(Object key) { return this.cache.remove(key); } @Override public void clear() { this.cache.clear(); } @Override public int getSize() { return this.cache.size(); } @Override public ReadWriteLock getReadWriteLock() { return null; } /** * @return the name */ public String getName() { return name; } /** * @param name the name to set */ public void setName(String name) { this.name = name; } }
定义了自己的Cache实现类后,就可以在需要使用它的Mapper.xml文件中通过<cache>标签的type属性来指定需要使用的Cache。如果自定义Cache是需要指定参数的,则可以通过<cache>标签的子标签<property>来指定对应的参数,Mybatis在解析的时候会调用指定属性对应的set方法。针对于上面的自定义Cache,我们的配置如下。
<cache type="mybatis.cache.MyCache">
<property name="name" value="调用setName()方法需要传递的参数值"/>
</cache>
注意:自定义cache,那么cache标签例如size、eviction都不会对它起作用
缓存的清除
二级缓存默认是会在执行update、insert和delete语句时进行清空的,具体可以参考CachingExecutor的update()实现。如果不希望在执行某一条更新语句时,清空对应的二级缓存,那么可以在对应的语句上指定flushCache属性等于false。如果只是某一条select语句不希望使用二级缓存和一级缓存,则也可以在对应的select元素上加上flushCache="true"。
<insert id="delete" parameterType="java.lang.Long" flushCache="false"> delete t_person where id=#{id} </insert>
操作Cache
Mybatis中创建的二级缓存都会交给Configuration进行管理,Configuration类是Mybatis的核心类,里面包含各种Mybatis资源的管理,其可以很方便的通过SqlSession、SqlSessionFactory获取,如有需要可以直接通过它来操作我们的Cache。
@Test public void testGetCache() { Configuration configuration = this.session.getConfiguration(); // this.sessionFactory.getConfiguration(); Collection<Cache> caches = configuration.getCaches(); System.out.println(caches); }
测试
针对二级缓存进行以下测试,获取两个不同的SqlSession执行两条相同的SQL,在未指定Cache时Mybatis将查询两次数据库,在指定了Cache时Mybatis只查询了一次数据库,第二次是从缓存中拿的。
@Test public void testCache2() { SqlSession session1 = this.sessionFactory.openSession(); SqlSession session2 = this.sessionFactory.openSession(); session1.getMapper(PersonMapper.class).findById(5L); session1.commit(); session2.getMapper(PersonMapper.class).findById(5L); }
注意在上面的代码中,在session1执行完对应的SQL后调用了session1的commit()方法,即提交它的事务,这样在第二次查询的时候才会缓存命中,才不会查询数据库,否则就会连着查询两次数据库。这是因为在CachingExecutor中Mybatis在查询的过程中,又在原来Cache的基础上包装TransactionalCache,这个Cache只会在事务提交后才真正的写入缓存,所以在上面的示例中,如果session1执行完SQL后没有马上commit就紧接着用session2执行SQL,虽然session1查询时没有缓存命中,但是此时写入缓存操作还没有进行,session2再查询的时候也就不会缓存命中。
二级缓存的应用场景和局限性
对于访问多的查询请求且用户对查询结果实时性要求不高,此时可采用mybatis二级缓存技术降低数据库访问量,提高访问速度,业务场景比如:耗时较高的统计分析sql、电话账单查询sql等。实现方法如下:通过设置刷新间隔时间,由mybatis每隔一段时间自动清空缓存,根据数据变化频率设置缓存刷新间隔flushInterval,比如设置为30分钟、60分钟、24小时等,根据需求而定。
mybatis二级缓存对细粒度的数据级别的缓存实现不好,比如如下需求:对商品信息进行缓存,由于商品信息查询访问量大,但是要求用户每次都能查询最新的商品信息,此时如果使用mybatis的二级缓存就无法实现当一个商品变化时只刷新该商品的缓存信息而不刷新其它商品的信息,因为mybaits的二级缓存区域以mapper为单位划分的,当一个商品信息变化会将所有商品信息的缓存数据全部清空。解决此类问题可能需要在业务层根据需求对数据有针对性缓存。
参考:
http://elim.iteye.com/blog/2356956


 浙公网安备 33010602011771号
浙公网安备 33010602011771号