
LinkedHashMap
LinkedHashMap 继承 HashMap,在 HashMap 基础上,通过维护一条双向链表,解决 HashMap 不能随时保持遍历顺序和插入顺序一致的问题。
LinkedHashMap的成员变量
private static final long serialVersionUID = 3801124242820219131L; // 用于指向双向链表的头部 transient LinkedHashMap.Entry<K,V> head; //用于指向双向链表的尾部 transient LinkedHashMap.Entry<K,V> tail; /** * 用来指定LinkedHashMap的迭代顺序, * true则表示按照基于访问的顺序来排列,就是最近使用的entry,放在链表的最末尾 * false则表示按照插入顺序来 */ final boolean accessOrder;
LinkedHashMap添加了前面提到的accessOrder,默认赋值为false——按照插入顺序来排列,注意:accessOrder的final关键字,说明要在构造方法里给它初始化。
//多了一个 accessOrder的参数,用来指定按照LRU排列方式还是顺序插入的排序方式 public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; }
LinkedHashMap 增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。其结构可能如下图:
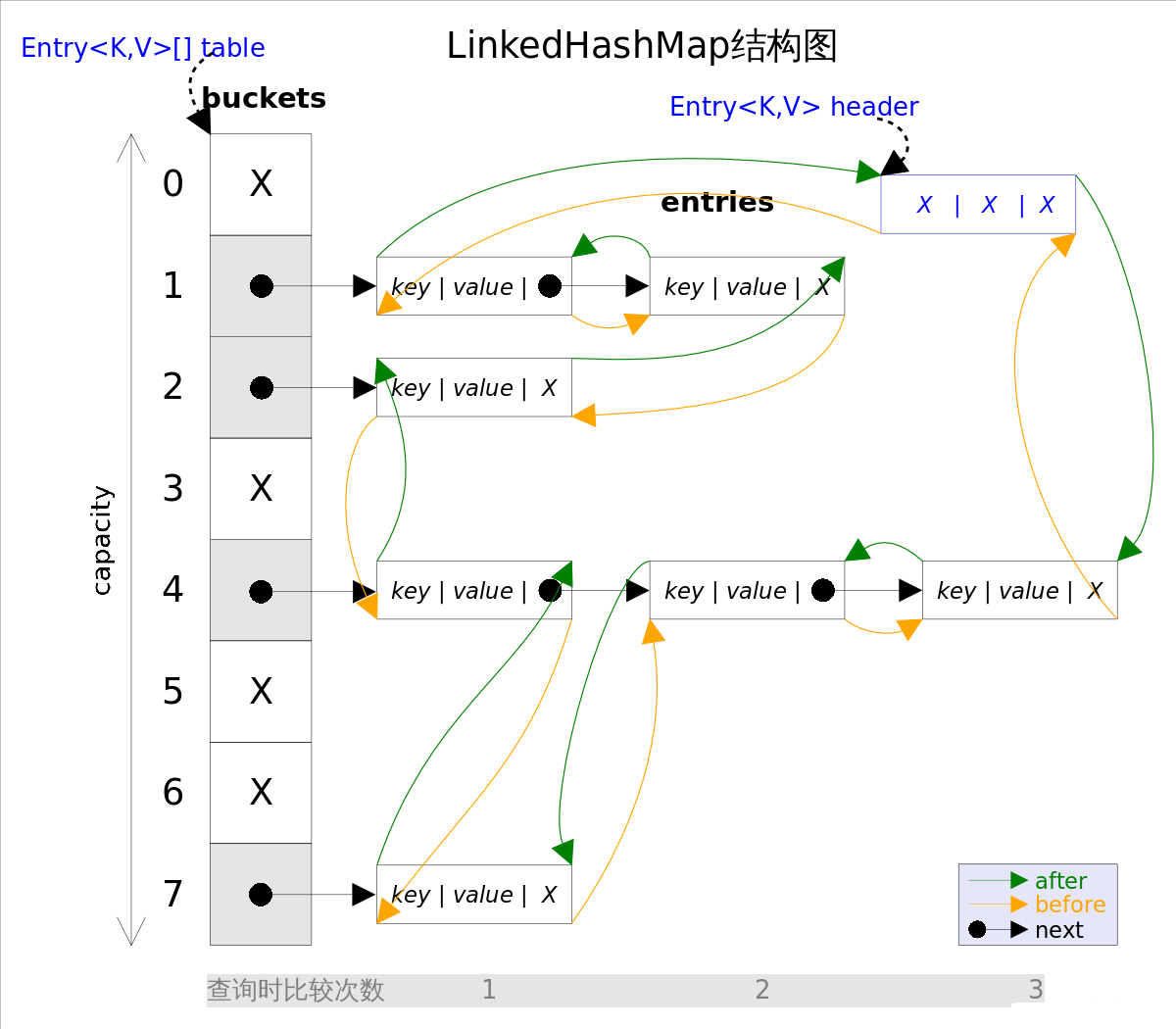
- 每当有新键值对节点插入,新节点最终会接在 tail 引用指向的节点后面。而 tail 引用则会移动到新的节点上,这样一个双向链表就建立起来了
- LinkedHashMap主体部分跟HashMap完全一样,多了header指向双向链表的头部(是一个哑元),该双向链表的迭代顺序就是entry的插入顺序
- 迭代LinkedHashMap时不需要像HashMap那样遍历整个table,而只需要直接遍历header指向的双向链表即可,也就是说LinkedHashMap的迭代时间就只跟entry的个数相关,而跟table的大小无关
-
有两个参数可以影响LinkedHashMap的性能: 初始容量(inital capacity)和负载系数(load factor)。初始容量指定了初始table的大小,负载系数用来指定自动扩容的临界值。当entry的数量超过capacity*load_factor时,容器将自动扩容并重新哈希。对于插入元素较多的场景,将初始容量设大可以减少重新哈希的次数
-
将对象放入到LinkedHashMap中时,有两个方法需要特别关心: hashCode()和equals()。hashCode()方法决定了对象会被放到哪个bucket里,当多个对象的哈希值冲突时,equals()方法决定了这些对象是否是“同一个对象”。所以,如果要将自定义的对象放入到LinkedHashMap或LinkedHashSet中,需要重写 hashCode()和equals()方法
- LinkedHashMap是非同步的(not synchronized),如果需要在多线程环境使用,通过如下方式将
LinkedHashMap包装成(wrapped)同步的:
Map m = Collections.synchronizedMap(new LinkedHashMap(...));
链表的建立过程
链表的建立过程是在插入键值对节点时开始的,初始情况下,让 LinkedHashMap 的 head 和 tail 引用同时指向新节点,链表就算建立起来。随后不断有新节点插入,通过将新节点接在 tail 引用指向节点的后面,即可实现链表的更新。
// HashMap 中实现
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// HashMap 中实现
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0) {...}
// 通过节点 hash 定位节点所在的桶位置,并检测桶中是否包含节点引用
if ((p = tab[i = (n - 1) & hash]) == null) {...}
else {
Node<K,V> e; K k;
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode) {...}
else {
// 遍历链表,并统计链表长度
for (int binCount = 0; ; ++binCount) {
// 未在单链表中找到要插入的节点,将新节点接在单链表的后面
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) {...}
break;
}
// 插入的节点已经存在于单链表中
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) {...}
afterNodeAccess(e); // 回调方法,后续说明
return oldValue;
}
}
++modCount;
if (++size > threshold) {...}
afterNodeInsertion(evict); // 回调方法,后续说明
return null;
}
// HashMap 中实现
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
// LinkedHashMap 中覆写
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// 将 Entry 接在双向链表的尾部
linkNodeLast(p);
return p;
}
//把TreeNode的重写也加了进来,因为putTreeVal里有调用了这个
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
linkNodeLast(p); return p;
}
// LinkedHashMap 中实现
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
// last 为 null,表明链表还未建立
if (last == null)
head = p;
else {
// 将新节点 p 接在链表尾部
p.before = last;
last.after = p;
}
}
插入双重含义:
- 从table的角度看,新的entry需要插入到对应的bucket里,当有哈希冲突时,采用头插法将新的entry插入到冲突链表的头部。
- 从header的角度看,新的entry需要插入到双向链表的尾部。
链表节点的删除过程
LinkedHashMap 删除操作是直接用父类的实现。在删除节点时,父类的删除逻辑并不会修复 LinkedHashMap 所维护的双向链表,那么删除及节点后,被删除的节点该如何从双链表中移除呢?在删除及节点后,回调方法 afterNodeRemoval 会被调用。LinkedHashMap 覆写该方法,并在该方法中完成了移除被删除节点的操作。相关源码如下:
// HashMap 中实现 public V remove(Object key) { Node<K,V> e; return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value; } // HashMap 中实现 final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) { Node<K,V> node = null, e; K k; V v; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) node = p; else if ((e = p.next) != null) { if (p instanceof TreeNode) {...} else { // 遍历单链表,寻找要删除的节点,并赋值给 node 变量 do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break; } p = e; } while ((e = e.next) != null); } } if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { if (node instanceof TreeNode) {...} // 将要删除的节点从单链表中移除 else if (node == p) tab[index] = node.next; else p.next = node.next; ++modCount; --size; afterNodeRemoval(node); // 调用删除回调方法进行后续操作 return node; } } return null; } // LinkedHashMap 中覆写 void afterNodeRemoval(Node<K,V> e) { // unlink LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; // 将 p 节点的前驱后后继引用置空 p.before = p.after = null; // b 为 null,表明 p 是头节点 if (b == null) head = a; else b.after = a; // a 为 null,表明 p 是尾节点 if (a == null) tail = b; else a.before = b; }
删除的过程并不复杂,上面这么多代码其实就做了三件事:
- 根据 hash 定位到桶位置
- 遍历链表或调用红黑树相关的删除方法
- 从 LinkedHashMap 维护的双链表中移除要删除的节点
访问顺序的维护过程
默认情况下,LinkedHashMap 是按插入顺序维护链表。不过可以在初始化 LinkedHashMap,指定 accessOrder 参数为 true,即可让它按访问顺序维护链表。访问顺序的原理上并不复杂,当我们调用get/getOrDefault/replace等方法时,只需要将这些方法访问的节点移动到链表的尾部即可。相应的源码如下:
// LinkedHashMap 中覆写 public V get(Object key) { Node<K,V> e; if ((e = getNode(hash(key), key)) == null)//调用hashmap中的getNode方法 return null; // 如果 accessOrder 为 true,则调用 afterNodeAccess 将被访问节点移动到链表最后 if (accessOrder) afterNodeAccess(e); return e.value; } // LinkedHashMap 中覆写:将最近使用的Node放在链表的最末尾 void afterNodeAccess(Node<K,V> e) { // move node to last LinkedHashMap.Entry<K,V> last;
//仅当按照LRU且e不在最末尾,才执行修改链表,将e移动到链表的最末尾 if (accessOrder && (last = tail) != e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.after = null; // 如果 b 为 null,表明 p 为头节点 if (b == null) head = a; else b.after = a; if (a != null) a.before = b;//p为尾部节点 else last = b; if (last == null) head = p; //链表只有一个p节点 else { // 将 p 接在链表的最后 p.before = last; last.after = p; } tail = p; ++modCount; } }
特别说明一下,显示链表的修改后指针的情况,实际上在桶里面的位置是不变的,只是前后的指针指向的对象变
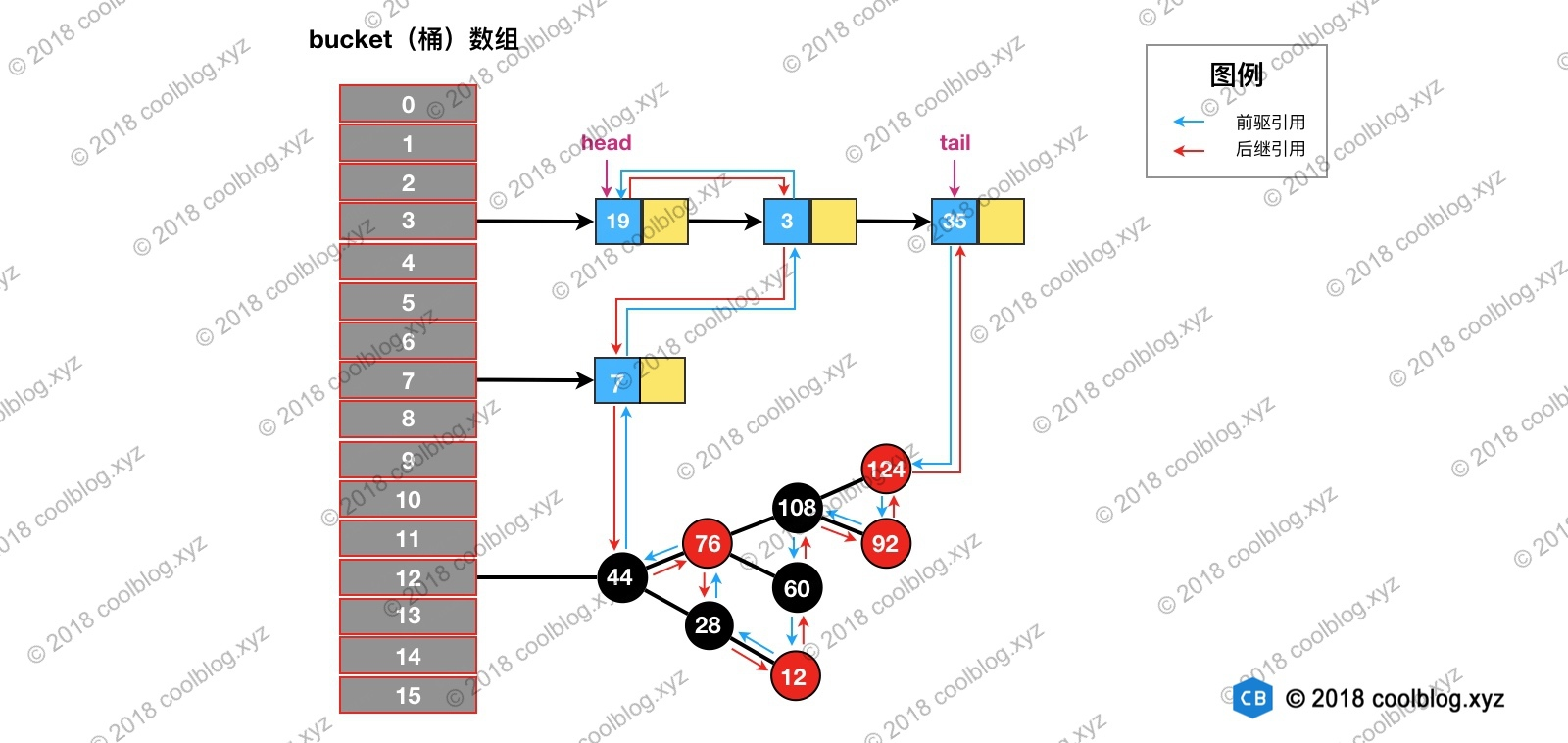
访问下图键值为3的节点,访问前结构为:
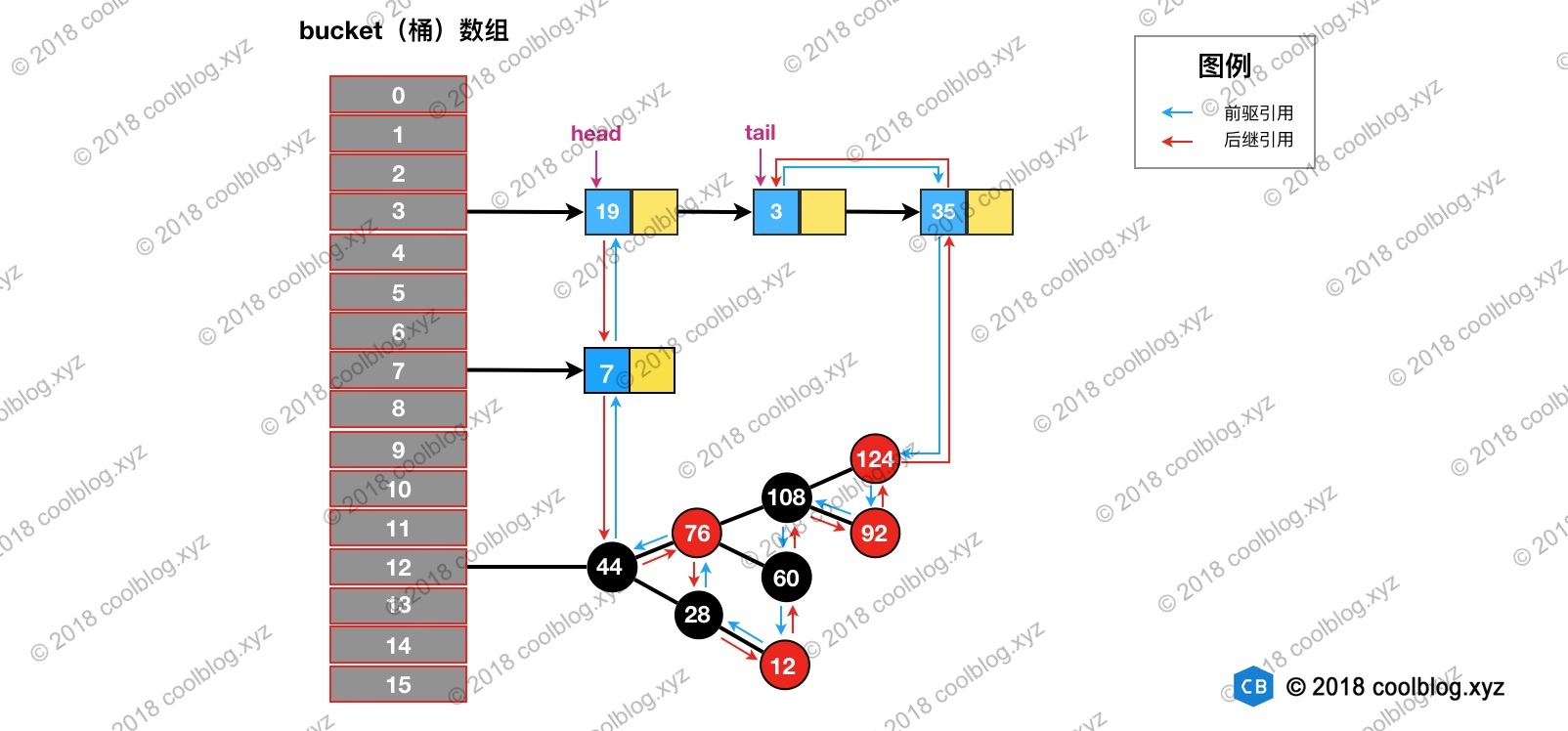
访问后,键值为3的节点将会被移动到双向链表的最后位置,其前驱和后继也会跟着更新。访问后的结构如下
通过继承 LinkedHashMap 实现了一个简单的 LRU 策略的缓存:
当基于 LinkedHashMap 实现缓存时,通过覆写removeEldestEntry方法可以实现自定义策略的 LRU 缓存。比如可以根据节点数量判断是否移除最近最少被访问的节点或者根据节点的存活时间判断是否移除该节点等。实现的缓存是基于判断节点数量是否超限的策略。在构造缓存对象时,传入最大节点数。当插入的节点数超过最大节点数时,移除最近最少被访问的节点。实现代码如下:
先看源码吧:
void afterNodeInsertion(boolean evict) { // possibly remove eldest LinkedHashMap.Entry<K,V> first; // 根据条件判断是否移除最近最少被访问的节点 if (evict && (first = head) != null && removeEldestEntry(first)) { K key = first.key; removeNode(hash(key), key, null, false, true); } } // 移除最近最少被访问条件之一,通过覆盖此方法可实现不同策略的缓存 protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { return false; }
当基于 LinkedHashMap 实现缓存时,通过覆写removeEldestEntry方法可以实现自定义策略的 LRU 缓存。比如可以根据节点数量判断是否移除最近最少被访问的节点,或者根据节点的存活时间判断是否移除该节点等。所实现的缓存是基于判断节点数量是否超限的策略。在构造缓存对象时,传入最大节点数。当插入的节点数超过最大节点数时,移除最近最少被访问的节点。实现代码如下:
public class SimpleCache<K, V> extends LinkedHashMap<K, V> { private static final int MAX_NODE_NUM = 100; private int limit; public SimpleCache() { this(MAX_NODE_NUM); } public SimpleCache(int limit) { super(limit, 0.75f, true); this.limit = limit; } public V save(K key, V val) { return put(key, val); } public V getOne(K key) { return get(key); } public boolean exists(K key) { return containsKey(key); } /** * 判断节点数是否超限 * @param eldest * @return 超限返回 true,否则返回 false */ @Override protected boolean removeEldestEntry(Map.Entry<K, V> eldest) { return size() > limit; } }
测试代码如下:
public class SimpleCacheTest { @Test public void test() throws Exception { SimpleCache<Integer, Integer> cache = new SimpleCache<>(3); for (int i = 0; i < 10; i++) { cache.save(i, i * i); } System.out.println("插入10个键值对后,缓存内容:"); System.out.println(cache + "\n"); System.out.println("访问键值为7的节点后,缓存内容:"); cache.getOne(7); System.out.println(cache + "\n"); System.out.println("插入键值为1的键值对后,缓存内容:"); cache.save(1, 1); System.out.println(cache); } }
LinkedHashMap的迭代器
abstract class LinkedHashIterator { //记录下一个Entry LinkedHashMap.Entry<K,V> next; //记录当前的Entry LinkedHashMap.Entry<K,V> current; //记录是否发生了迭代过程中的修改 int expectedModCount; LinkedHashIterator() { //初始化的时候把head给next next = head; expectedModCount = modCount; current = null; } public final boolean hasNext() { return next != null; } //这里采用的是链表方式的遍历方式,有兴趣的园友可以去上一章看看HashMap的遍历方式 final LinkedHashMap.Entry<K,V> nextNode() { LinkedHashMap.Entry<K,V> e = next; if (modCount != expectedModCount) throw new ConcurrentModificationException(); if (e == null) throw new NoSuchElementException(); //记录当前的Entry current = e; //直接拿after给next next = e.after; return e; } public final void remove() { Node<K,V> p = current; if (p == null) throw new IllegalStateException(); if (modCount != expectedModCount) throw new ConcurrentModificationException(); current = null; K key = p.key; removeNode(hash(key), key, null, false, false); expectedModCount = modCount; } }
参考:
https://segmentfault.com/a/1190000012964859
https://www.cnblogs.com/joemsu/p/7787043.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号