

ThreadPoolExecutor详解
线程资源必须通过线程池提供,不允许在应用中自行显示创建线程。为什么呢?
使用线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源开销,解决资源不足的问题。
如果不使用线程池,有可能会造成系统创建大量同类线程而导致消耗完内存或者“过度切换”的问题。
对线程进行一些维护和管理,比如定时开始,周期执行,并发数控制等等
提高响应速度:任务到达时不需要等待线程创建就可以立即执行
线程池理解为"存放一定数量线程的一个线程集合。线程池允许若个线程同时运行,允许同时运行的线程数量就是线程池的容量;当添加的到 线程池中的线程超过它的容量时,会有一部分线程阻塞等待。线程池会通过相应的调度策略和拒绝策略,对添加到线程池中的线程进行管理。
数据在ThreadPoolExecutor.java中的定义如下:
// 阻塞队列。 private final BlockingQueue<Runnable> workQueue; // 互斥锁 private final ReentrantLock mainLock = new ReentrantLock(); // 线程集合。一个Worker对应一个线程。 private final HashSet<Worker> workers = new HashSet<Worker>(); // “终止条件”,与“mainLock”绑定。 private final Condition termination = mainLock.newCondition(); // 线程池中线程数量曾经达到过的最大值。 private int largestPoolSize; // 已完成任务数量 private long completedTaskCount; // ThreadFactory对象,用于创建线程。 private volatile ThreadFactory threadFactory; // 拒绝策略的处理句柄。 private volatile RejectedExecutionHandler handler; // 保持线程存活时间。 private volatile long keepAliveTime; private volatile boolean allowCoreThreadTimeOut; // 核心池大小 private volatile int corePoolSize; // 最大池大小 private volatile int maximumPoolSize;
获取单个结果
submit()向线程池提交任务后会返回一个Future,调用V Future.get()方法能够阻塞等待执行结果,V get(long timeout, TimeUnit unit)方法可以指定等待的超时时间。
获取多个结果
使用ExecutorCompletionService,该类的take()方法总是阻塞等待某一个任务完成,然后返回该任务的Future对象。向CompletionService批量提交任务后,只需调用相同次数的CompletionService.take()方法,就能获取所有任务的执行结果,获取顺序是任意的,取决于任务的完成顺序:
void solve(Executor executor, Collection<Callable<Result>> solvers) throws InterruptedException, ExecutionException { CompletionService<Result> ecs = new ExecutorCompletionService<Result>(executor);// 构造器 for (Callable<Result> s : solvers)// 提交所有任务 ecs.submit(s); int n = solvers.size(); for (int i = 0; i < n; ++i) {// 获取每一个完成的任务 Result r = ecs.take().get(); if (r != null) use(r); } }
多个任务的超时时间
等待多个任务完成,并设置最大等待时间,可以通过CountDownLatch完成:
public void testLatch(ExecutorService executorService, List<Runnable> tasks) throws InterruptedException{ CountDownLatch latch = new CountDownLatch(tasks.size()); for(Runnable r : tasks){ executorService.submit(new Runnable() { @Override public void run() { try{ r.run(); }finally { latch.countDown();// countDown } } }); } latch.await(10, TimeUnit.SECONDS); // 指定超时时间 }
RejectedExecutionHandler:RejectedExecutionHandler也是一个接口,只有一个方法
AbortPolicy:当任务添加到线程池中被拒绝时,将抛出RejectedExecutionException异常。
CallerRunsPolicy:当任务添加到线程池被拒绝时,会使用调用线程池的Thread线程对象处理被拒绝的任务
DiscardOldestPolicy:当任务添加到线程池被拒绝时,线程池会放弃等待队列中最旧的未处理任务,然后将拒绝的任务添加到等待队列
DiscardPolicy:当任务添加到线程池中被拒绝时,线程池将丢弃被拒绝的任务
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable var1, ThreadPoolExecutor var2);
}
线程池规则:
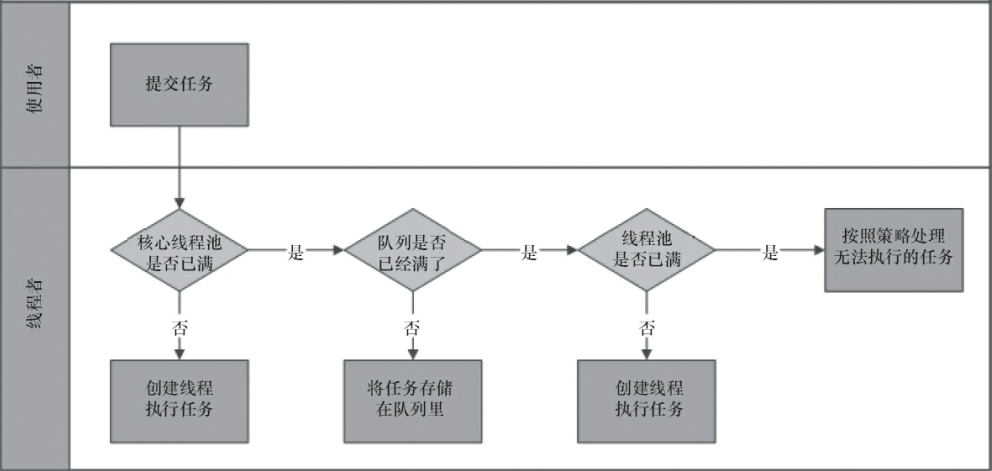
如何正确使用线程池
避免使用无界队列
不要使用Executors.newXXXThreadPool()快捷方法创建线程池,因为这种方式会使用无界的任务队列,为避免OOM,应该使用ThreadPoolExecutor的构造方法手动指定队列的最大长度:
ExecutorService executorService = new ThreadPoolExecutor(2, 2, 0, TimeUnit.SECONDS, new ArrayBlockingQueue<>(512), // 使用有界队列,避免OOM new ThreadPoolExecutor.DiscardPolicy());
定制阻塞线程池:
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.RejectedExecutionHandler;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
public class CustomerThreadPoolExecutor {
private ThreadPoolExecutor pool;
private void init() {
pool=new ThreadPoolExecutor(3, 5, 30, TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(5),
new CustomerThreadFactory(),
new CustomerRejectExecutorHandler());
}
private class CustomerThreadFactory implements ThreadFactory{
private AtomicInteger count=new AtomicInteger(0);
@Override
public Thread newThread(Runnable r) {
// TODO Auto-generated method stub
Thread thread = new Thread(r);
String threadName="Thread "+count.getAndIncrement();
thread.setName(threadName);
return thread;
}
}
private class CustomerRejectExecutorHandler implements RejectedExecutionHandler{
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// TODO Auto-generated method stub
try {
executor.getQueue().put(r);
// 核心改造点,由blockingqueue的offer(非阻塞)改成put阻塞方法
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
public ThreadPoolExecutor getPool() {
return pool;
}
public void setPool(ThreadPoolExecutor pool) {
this.pool = pool;
}
public void destory() {
if(pool!=null)
pool.shutdownNow();
}
public static void main(String[] args) {
CustomerThreadPoolExecutor poolExecutor = new CustomerThreadPoolExecutor();
poolExecutor.init();
ThreadPoolExecutor threadPoolExecutor = poolExecutor.getPool();
for(int i=0;i<100;i++) {
System.out.println("提交线程"+i);
threadPoolExecutor.execute(new Runnable() {
@Override
public void run() {
// TODO Auto-generated method stub
try {
TimeUnit.SECONDS.sleep(10);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
});
}
}
}
1、用ThreadPoolExecutor自定义线程池,如果任务量不大,可以用无界队列,如果任务量非常大,要用有界队列,防止OOM
2、如果任务量很大,还要求每个任务都处理成功,要对提交的任务进行阻塞提交,重写拒绝机制,改为阻塞提交。保证不抛弃一个任务
3、最大线程数一般设为2N+1最好,N是CPU核数
4、核心线程数,看应用,如果是任务,一天跑一次,设置为0,合适,因为跑完就停掉了,如果是常用线程池,看任务量,是保留一个核心还是几个核心线程数
5、如果要获取任务执行结果,用CompletionService,获取任务的结果要重新开一个线程获取,如果在主线程获取,就要等任务都提交后才获取,就会阻塞大量任务结果,队列过大OOM,所以最好异步开个线程获取结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号