

ThreadLocal原理
实现思路:
Thread类有一个类型为ThreadLocal.ThreadLocalMap的实例变量threadLocals,即每个线程有一个自己的ThreadLocalMap。ThreadLocalMap有自己的独立实现,可以简单地将它的key视作ThreadLocal,value为代码中放入的值(实际上key并不是ThreadLocal本身,而是它的一个弱引用)。每个线程在往某个ThreadLocal里塞值的时候,都会往自己的ThreadLocalMap里存,读也是以某个ThreadLocal作为引用,在自己的map里找对应的key,从而实现了线程隔离。
ThreadLocal类中维护一个Map,用于存储每一个线程的变量副本,Map中元素的键为threadLocal的弱引用,而值为对应线程的变量副本。
从线程的角度看,每个线程都保持一个对其线程局部变量副本的隐式引用,只要线程是活动的并且 ThreadLocal 实例是可访问的;在线程消失之后,其线程局部实例的所有副本都会被垃圾回收(除非存在对这些副本的其他引用)
ThreadLocalMap
ThreadLocalMap提供了一种为ThreadLocal定制的高效实现,并且自带一种基于弱引用的垃圾清理机制。 Entry便是ThreadLocalMap里定义的节点,继承WeakReference类,定义一个类型为Object的value,用于存放塞到ThreadLocal里的值。
static class Entry extends WeakReference<ThreadLocal<?>> { /** The value associated with this ThreadLocal. */ Object value; Entry(ThreadLocal<?> k, Object v) { super(k); value = v; } }
为什么要弱引用?
使用普通的key-value形式来定义存储结构,实质上就会造成节点的生命周期与线程强绑定,只要线程没有销毁,那么节点在GC分析中一直处于可达状态,没办法被回收,而程序本身也无法判断是否可以清理节点。当某个ThreadLocal已经没有强引用可达,则随着它被垃圾回收,在ThreadLocalMap里对应的Entry的键值会失效,这为ThreadLocalMap本身的垃圾清理提供便利。
类成员变量与相应方法
/** * The initial capacity -- MUST be a power of two. */ private static final int INITIAL_CAPACITY = 16; /** * The table, resized as necessary. table.length MUST always be a power of two.
表的长度必须是2的幂 */ private Entry[] table; /** * The number of entries in the table. */ private int size = 0; /** * The next size value at which to resize.
//重新分配大小的阈值 */ private int threshold; // Default to 0 /** * Set the resize threshold to maintain at worst a 2/3 load factor.
设置resize阈值以维持最坏2/3的装载因子 */ private void setThreshold(int len) { threshold = len * 2 / 3; }
ThreadLocalMap维护一个Entry表或者说Entry数组,并且要求表的大小必须为2的幂,同时记录表里面entry的个数以及下一次需要扩容的阈值。
/** * Increment i modulo len.
环形意义的下一个索引 */ private static int nextIndex(int i, int len) { return ((i + 1 < len) ? i + 1 : 0); } /** * Decrement i modulo len.
环形意义的上一个索引 */ private static int prevIndex(int i, int len) { return ((i - 1 >= 0) ? i - 1 : len - 1); }
由于ThreadLocalMap使用线性探测法来解决散列冲突,所以实际上Entry[]数组在程序逻辑上是作为一个环形存在的。
勾勒出ThreadLocalMap的内部存储结构。下面是我绘制的示意图。虚线表示弱引用,实线表示强引用。
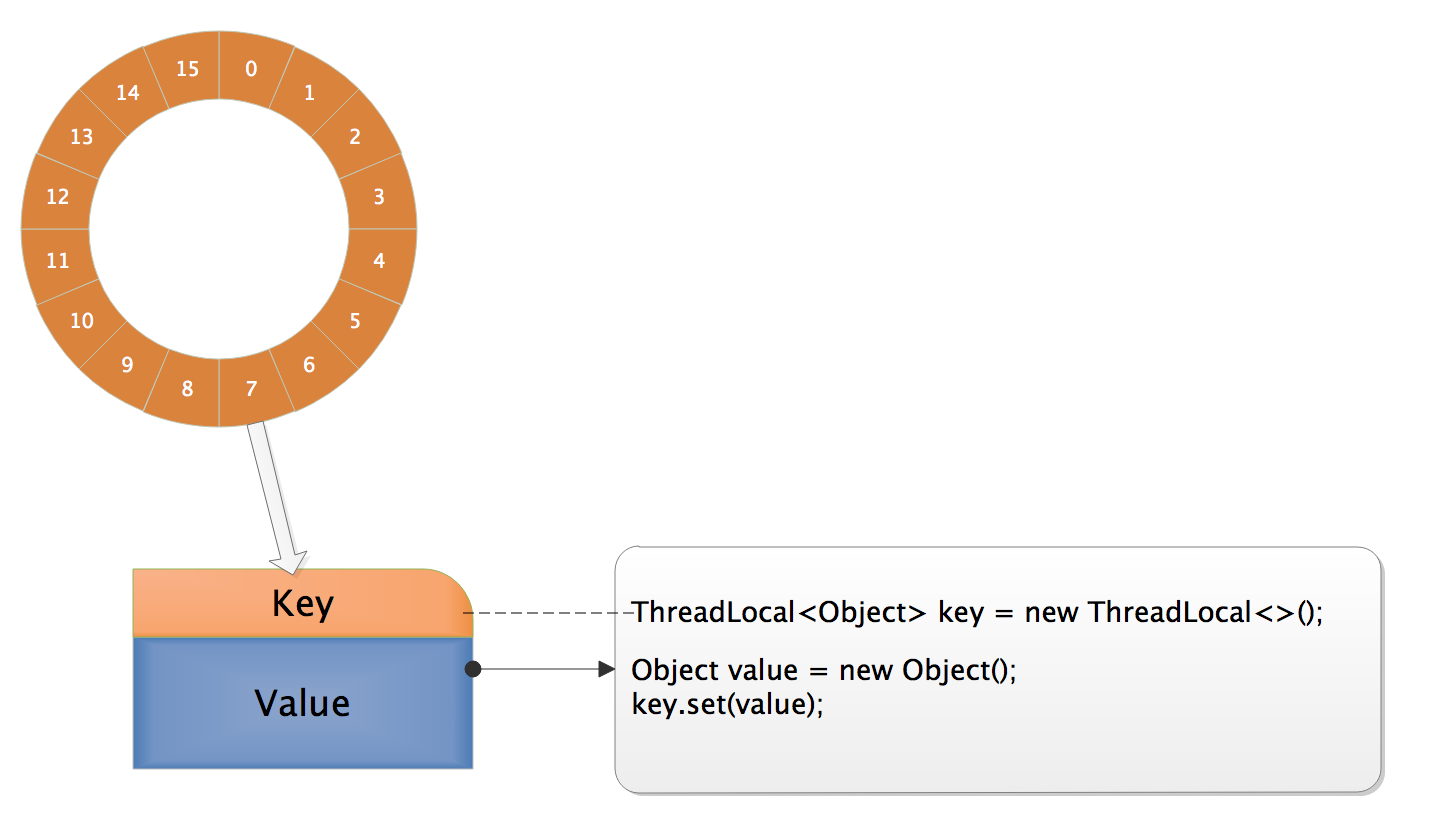
ThreadLocalMap维护了Entry环形数组,数组中元素Entry的逻辑上的key为某个ThreadLocal对象(实际上是指向该ThreadLocal对象的弱引用),value为代码中该线程往该ThreadLocal变量实际塞入的值。
构造函数
ThreadLocalMap的一个构造函数
/** * Construct a new map initially containing (firstKey, firstValue). * ThreadLocalMaps are constructed lazily, so we only create * one when we have at least one entry to put in it. */ ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) { table = new Entry[INITIAL_CAPACITY];
//用firstKey的threadLocalHashCode与初始大小16取模得到哈希值 int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1); table[i] = new Entry(firstKey, firstValue); size = 1; setThreshold(INITIAL_CAPACITY); }
构造函数在set和get的时候都可能会被间接调用以初始化线程的ThreadLocalMap。
哈希函数
构造函数中的int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
ThreadLocal类中有一个被final修饰的类型为int的threadLocalHashCode,在该ThreadLocal被构造的时候就会生成,相当于一个ThreadLocal的ID
/** * The difference between successively generated hash codes - turns * implicit sequential thread-local IDs into near-optimally spread * multiplicative hash values for power-of-two-sized tables. */ private static final int HASH_INCREMENT = 0x61c88647;
生成hash code间隙为这个魔数,可以让生成出来的值或者说ThreadLocal的ID较为均匀地分布在2的幂大小的数组中。
/** * Returns the next hash code. */ private static int nextHashCode() { return nextHashCode.getAndAdd(HASH_INCREMENT); }
在上一个被构造出的ThreadLocal的ID/threadLocalHashCode的基础上加上一个魔数0x61c88647的。这个魔数的选取与斐波那契散列有关,0x61c88647对应的十进制为1640531527。斐波那契散列的乘数可以用(long) ((1L << 31) * (Math.sqrt(5) - 1))可以得到2654435769,如果把这个值给转为带符号的int,则会得到-1640531527。换句话说
(1L << 32) - (long) ((1L << 31) * (Math.sqrt(5) - 1))得到的结果就是1640531527也就是0x61c88647。通过理论与实践,当我们用0x61c88647作为魔数累加为每个ThreadLocal分配各自的ID也就是threadLocalHashCode再与2的幂取模,得到的结果分布很均匀。
ThreadLocalMap使用的是线性探测法,均匀分布的好处在于很快就能探测到下一个临近的可用slot,从而保证效率。这就回答了上文抛出的为什么大小要为2的幂的问题。为了优化效率。
对于& (INITIAL_CAPACITY - 1),对于2的幂作为模数取模,可以用&(2^n-1)来替代%2^n,位运算比取模效率高很多。至于为什么,因为对2^n取模,只要不是低n位对结果的贡献显然都是0,会影响结果的只能是低n位。
在ThreadLocalMap中,形如key.threadLocalHashCode & (table.length - 1)(其中key为一个ThreadLocal实例)这样的代码片段实质上就是在求一个ThreadLocal实例的哈希值,只是在源码实现中没有将其抽为一个公用函数。
getEntry方法
方法会被ThreadLocal的get方法直接调用,用于获取map中某个ThreadLocal存放的值。
private Entry getEntry(ThreadLocal<?> key) { int i = key.threadLocalHashCode & (table.length - 1); // 根据key这个ThreadLocal的ID来获取索引,也即哈希值 Entry e = table[i]; if (e != null && e.get() == key) // 对应的entry存在且未失效且弱引用指向的ThreadLocal就是key,则命中返回 return e; else return getEntryAfterMiss(key, i, e); // 因为用的是线性探测,所以往后找还是有可能能够找到目标Entry的。 } private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) { Entry[] tab = table; int len = tab.length; while (e != null) { // 基于线性探测法不断向后探测直到遇到空entry。 ThreadLocal<?> k = e.get(); if (k == key) return e; if (k == null) // 该entry对应的ThreadLocal已经被回收,调用expungeStaleEntry来清理无效的entry expungeStaleEntry(i); else i = nextIndex(i, len); // 环形意义下往后面走 e = tab[i]; } return null; }
就是从staleSlot开始遍历,将无效(弱引用指向对象被回收)清理,即对应entry中的value置为null,将指向这个entry的table[i]置为null,直到扫到空entry。
* 在过程中还会对非空的entry作rehash。
private int expungeStaleEntry(int staleSlot) { Entry[] tab = table; int len = tab.length; // expunge entry at staleSlot tab[staleSlot].value = null; // 因为entry对应的ThreadLocal已经被回收,value设为null,显式断开强引用 tab[staleSlot] = null; // 显式设置该entry为null,以便垃圾回收 size--; // Rehash until we encounter null Entry e; int i; for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal<?> k = e.get(); if (k == null) { e.value = null; tab[i] = null; size--; } else {
/**
* 如果对应的ThreadLocal的ID对len取模出来的索引h不为当前位置i,
* 则从h向后线性探测到第一个空的slot,把当前的entry给挪过去。
*/ int h = k.threadLocalHashCode & (len - 1); if (h != i) { tab[i] = null; // Unlike Knuth 6.4 Algorithm R, we must scan until // null because multiple entries could have been stale. while (tab[h] != null) h = nextIndex(h, len); tab[h] = e; } } } return i; }
根据入参threadLocal的threadLocalHashCode对表容量取模得到index
- 如果index对应的slot就是要读的threadLocal,则直接返回结果
- 调用getEntryAfterMiss线性探测,过程中每碰到无效slot,调用expungeStaleEntry进行段清理;如果找到了key,则返回结果entry
- 没有找到key,返回null
set方法
/** * Set the value associated with key. * * @param key the thread local object * @param value the value to be set */ private void set(ThreadLocal<?> key, Object value) { // We don't use a fast path as with get() because it is at // least as common to use set() to create new entries as // it is to replace existing ones, in which case, a fast // path would fail more often than not. Entry[] tab = table; int len = tab.length; int i = key.threadLocalHashCode & (len-1); for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { ThreadLocal<?> k = e.get(); if (k == key) { e.value = value; return; } if (k == null) { //替换原来的值 replaceStaleEntry(key, value, i); return; } } tab[i] = new Entry(key, value); int sz = ++size; if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash(); }
/** * Replace a stale entry encountered during a set operation * with an entry for the specified key. The value passed in * the value parameter is stored in the entry, whether or not * an entry already exists for the specified key. * * As a side effect, this method expunges all stale entries in the * "run" containing the stale entry. (A run is a sequence of entries * between two null slots.) * * @param key the key * @param value the value to be associated with key * @param staleSlot index of the first stale entry encountered while * searching for key. */ private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) { Entry[] tab = table; int len = tab.length; Entry e; // Back up to check for prior stale entry in current run. // We clean out whole runs at a time to avoid continual // incremental rehashing due to garbage collector freeing // up refs in bunches (i.e., whenever the collector runs). int slotToExpunge = staleSlot; // 向前扫描,查找最前的一个无效slot for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len)) if (e.get() == null) slotToExpunge = i; // Find either the key or trailing null slot of run, whichever occurs first for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal<?> k = e.get(); // If we find key, then we need to swap it // with the stale entry to maintain hash table order. // The newly stale slot, or any other stale slot // encountered above it, can then be sent to expungeStaleEntry // to remove or rehash all of the other entries in run. if (k == key) { e.value = value; tab[i] = tab[staleSlot]; tab[staleSlot] = e;
/* * 如果在整个扫描过程中(包括函数一开始的向前扫描与i之前的向后扫描)
* 找到了之前的无效slot则以那个位置作为清理的起点,
* 否则则以当前的i作为清理起点 */
// Start expunge at preceding stale entry if it exists if (slotToExpunge == staleSlot) slotToExpunge = i;
// 从slotToExpunge开始做一次连续段的清理,再做一次启发式清理 cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); return; } // If we didn't find stale entry on backward scan, the // first stale entry seen while scanning for key is the // first still present in the run. if (k == null && slotToExpunge == staleSlot) slotToExpunge = i; } // If key not found, put new entry in stale slot tab[staleSlot].value = null; tab[staleSlot] = new Entry(key, value); // If there are any other stale entries in run, expunge them if (slotToExpunge != staleSlot) cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); }
/** * Heuristically scan some cells looking for stale entries. * This is invoked when either a new element is added, or * another stale one has been expunged. It performs a * logarithmic number of scans, as a balance between no * scanning (fast but retains garbage) and a number of scans * proportional to number of elements, that would find all * garbage but would cause some insertions to take O(n) time. * * @param i a position known NOT to hold a stale entry. The * scan starts at the element after i. * * @param n scan control: {@code log2(n)} cells are scanned, * unless a stale entry is found, in which case * {@code log2(table.length)-1} additional cells are scanned. * When called from insertions, this parameter is the number * of elements, but when from replaceStaleEntry, it is the * table length. (Note: all this could be changed to be either * more or less aggressive by weighting n instead of just * using straight log n. But this version is simple, fast, and * seems to work well.) * * @return true if any stale entries have been removed. */
/** * 启发式地清理slot,
* i对应entry是非无效(指向的ThreadLocal没被回收,或者entry本身为空)
* n是用于控制控制扫描次数的 * 正常情况下如果log n次扫描没有发现无效slot,函数就结束了
* 但是如果发现了无效的slot,将n置为table的长度len,做一次连续段的清理
* 再从下一个空的slot开始继续扫描
* * 这个函数有两处地方会被调用,一处是插入的时候可能会被调用,另外个是在替换无效slot的时候可能会被调用,
* 区别是前者传入的n为元素个数,后者为table的容量 */
private boolean cleanSomeSlots(int i, int n) { boolean removed = false; Entry[] tab = table; int len = tab.length; do { i = nextIndex(i, len); Entry e = tab[i]; if (e != null && e.get() == null) { n = len; removed = true; i = expungeStaleEntry(i); } } while ( (n >>>= 1) != 0); return removed; }
回顾一下ThreadLocal的set方法可能会有的情况
- 探测过程中slot都不无效,并且顺利找到key所在的slot,直接替换即可
- 探测过程中发现有无效slot,调用replaceStaleEntry,效果是最终一定会把key和value放在这个slot,并且会尽可能清理无效slot
- 在replaceStaleEntry过程中,如果找到了key,则做一个swap把它放到那个无效slot中,value置为新值
- 在replaceStaleEntry过程中,没有找到key,直接在无效slot原地放entry
- 探测没有发现key,则在连续段末尾的后一个空位置放上entry,这也是线性探测法的一部分。放完后,做一次启发式清理,如果没清理出去key,并且当前table大小已经超过阈值了,则做一次rehash,rehash函数会调用一次全量清理slot方法也即expungeStaleEntries,如果完了之后table大小超过了threshold - threshold / 4,则进行扩容2倍
remove方法
/** * Remove the entry for key. */ private void remove(ThreadLocal<?> key) { Entry[] tab = table; int len = tab.length; int i = key.threadLocalHashCode & (len-1); for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { if (e.get() == key) { e.clear();// 显式断开弱引用 expungeStaleEntry(i); return; } } }
remove方法相对于getEntry和set方法比较简单,直接在table中找key,如果找到了,把弱引用断了做一次段清理。
参考:
https://blog.csdn.net/v123411739/article/details/78698834
https://www.cnblogs.com/dennyzhangdd/p/7978455.html#top
https://www.cnblogs.com/micrari/p/6790229.html(推荐)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号