

非对齐检查点算法
在Flink的检查点机制中,屏障(barrier)是划分快照(状态)的边界。在启用exactly once语义的条件下,当一个算子有多个输入流时,需要等待所有输入流中当前检查点N的屏障都到达其输入缓冲区,才能安全地触发检查点,否则检查点N的快照数据和检查点N + 1的快照数据就会混在一起。
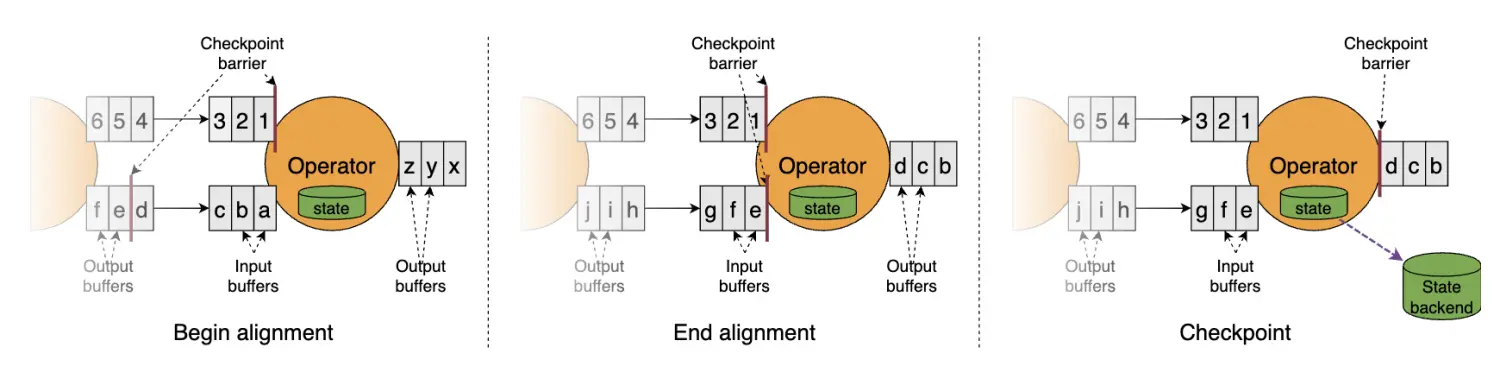
a) 当算子的所有输入流中的第一个屏障到达算子的输入缓冲区时,立即将这个屏障发往下游(输出缓冲区)
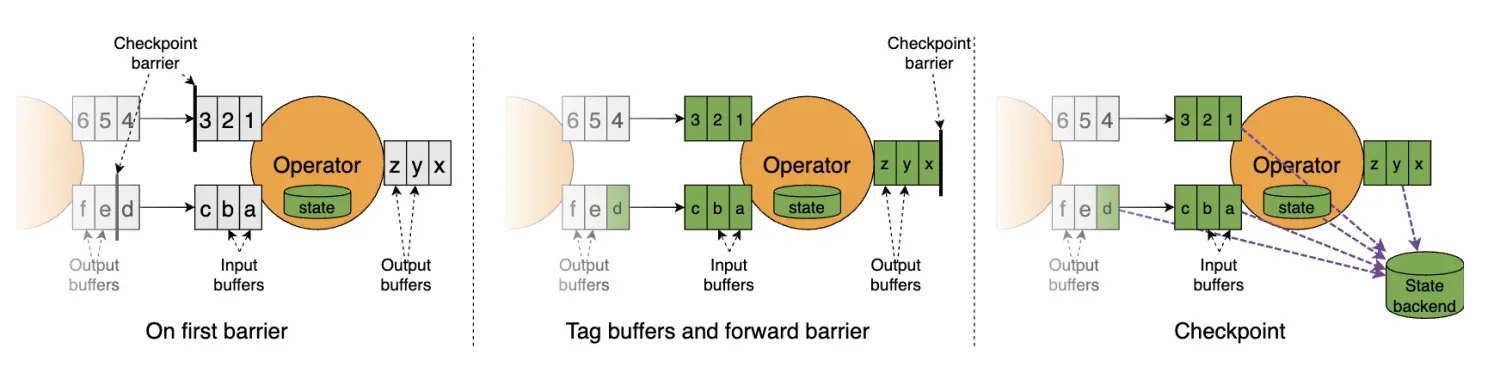
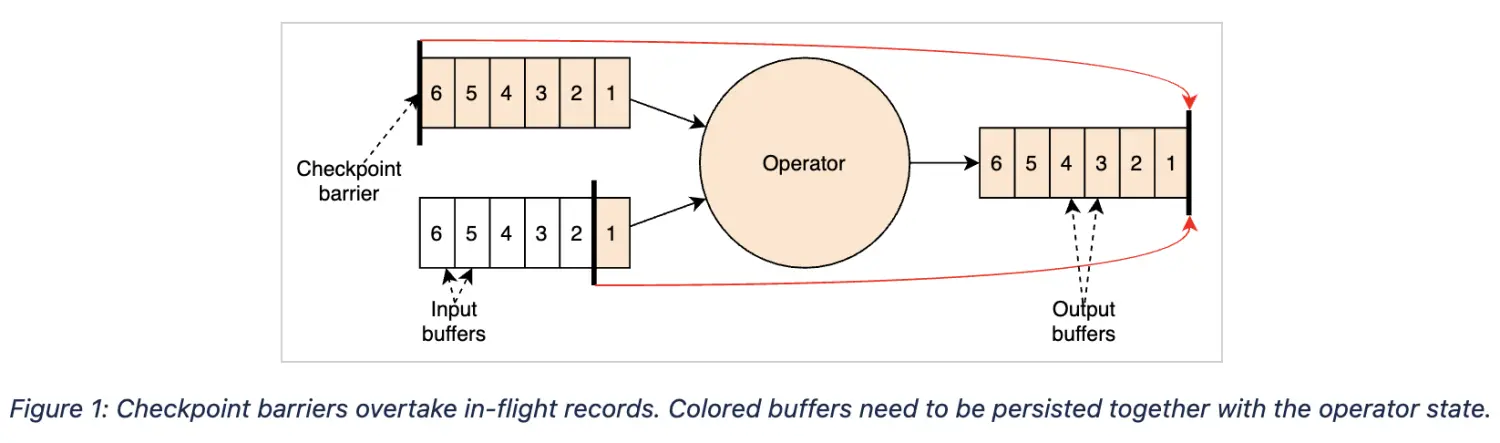
b) 由于第一个屏障没有被阻塞,它的步调会比较快,超过一部分缓冲区中的数据。算子会标记两部分数据:一是屏障首先到达的那条流中被超过的数据,二是其他流中位于当前检查点屏障之前的所有数据(当然也包括进入了输入缓冲区的数据),如下图中标黄的部分所示。
c) 将上述两部分数据连同算子的状态一起做异步快照。
与对齐检查点的区别主要有三:
对齐检查点在最后一个屏障到达算子时触发,非对齐检查点在第一个屏障到达算子时就触发。
对齐检查点在第一个屏障到最后一个屏障到达的区间内是阻塞的,而非对齐检查点不需要阻塞。
即使再考虑反压的情况,屏障也不会因为输入流速度变慢而堵在各个算子的入口处,而是能比较顺畅地由Source端直达Sink端,从而缓解检查点失败超时的现象。
- 对齐检查点能够保持快照N~N + 1之间的边界,但非对齐检查点模糊了这个边界。
不同检查点的数据都混在一起了,非对齐检查点还能保证exactly once语义吗?答案是肯定的。当任务从非对齐检查点恢复时,除了对齐检查点也会涉及到的Source端重放和算子的计算状态恢复之外,未对齐的流数据也会被恢复到各个链路,三者合并起来就是能够保证exactly once的完整现场了。
主要缺点有二:
-
需要额外保存数据流的现场,总的状态大小可能会有比较明显的膨胀(文档中说可能会达到a couple of GB per task),磁盘压力大。当集群本身就具有I/O bound的特点时,该缺点的影响更明显。
-
从状态恢复时也需要额外恢复数据流的现场,作业重新拉起的耗时可能会很长。特别地,如果第一次恢复失败,有可能触发death spiral(死亡螺旋)使得作业永远无法恢复。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号