




索引设计
1、PB 级别的大索引如何设计?
一个索引很大,数据写入和查询性能都会变差。高效检索体现在:基于日期的检索可以直接检索对应日期的索引,无形中缩减很大的数据规模。
2、分片数和副本数如何设计?
数据切分分片的主要目的:
(1)水平分割/缩放内容量 。
(2)跨分片(可能在多个节点上)分布和并行化操作,提高性能/吞吐量。
注意:分片一旦创建,不可以修改大小。副本:在分片/节点出现故障时提供高可用性
副本的好处:因为可以在所有副本上并行执行搜索——因此扩展了搜索量/吞吐量。注意:副本分片与主分片存储在集群中不同的节点。副本的大小可以通过:number_of_replicas动态修改。
2.1、索引设置多少分片?
Shard 大小官方推荐值为 20-40GB,一个分片就是一个 Lucene 的库,一个 Lucene 目录里面包含很多 Segment,每个 Segment 有文档数的上限,Segment 内部的文档 ID 目前使用的是 Java 的整型,也就是 2 的 31 次方,所以 能够表示的总的文档数为Integer.MAXVALUE - 128 = 2^31 - 128 = 2147483647 - 1 = 2,147,483,519,也就是21.4亿条。同样,如果你不 forcemerge 成一个 Segment,单个 shard 的文档数能超过这个数。单个 Lucene 越大,索引会越大,查询的操作成本自然要越高,IO 压力越大,自然会影响查询体验。具体一个分片多少数据合适,还是需要结合实际的业务数据和实际的查询来进行测试以进行评估。
- 第一步:预估一下数据量的规模。一共要存储多久的数据,每天新增多少数据?两者的乘积就是总数据量。
- 第二步:预估分多少个索引存储。索引的划分可以根据业务需要。
- 第三步:考虑和衡量可扩展性,预估需要搭建几台机器的集群。存储主要看磁盘空间,假设每台机器2TB,可用:2TB0.85(磁盘实际利用率)0.85(ES 警戒水位线)。
- 第四步:单分片的大小建议最大设置为 30GB。此处如果是增量索引,可以结合大索引的设计部分的实现一起规划。
前三步能得出一个索引的大小。分片数考虑维度:
- 1)分片数 = 索引大小/分片大小经验值 30GB 。
- 2)分片数建议和节点数一致。设计的时候1)、2)两者权衡考虑+rollover 动态更新索引结合。
Mapping
ES 支持增加字段 //新增字段
PUT new_index { "mappings": { "_doc": { "properties": { "status_code": { "type": "keyword" } } } } }
- ES 不支持直接删除字段
- ES 不支持直接修改字段
- ES 不支持直接修改字段类型 如果非要做灵活设计,ES 有其他方案可以替换,借助reindex。但是数据量大会有性能问题,建议设计阶段综合权衡考虑。
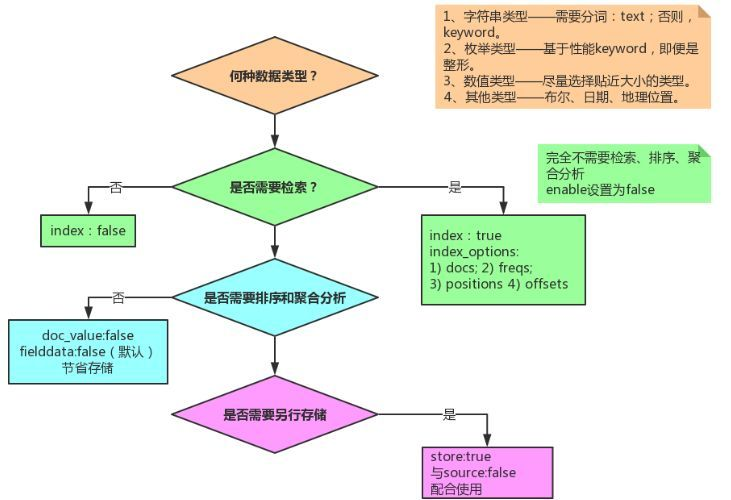
设置字段的时候,主要关注点:
- 数据类型选型;
- 是否需要检索;
- 是否需要排序+聚合分析;
- 是否需要另行存储。
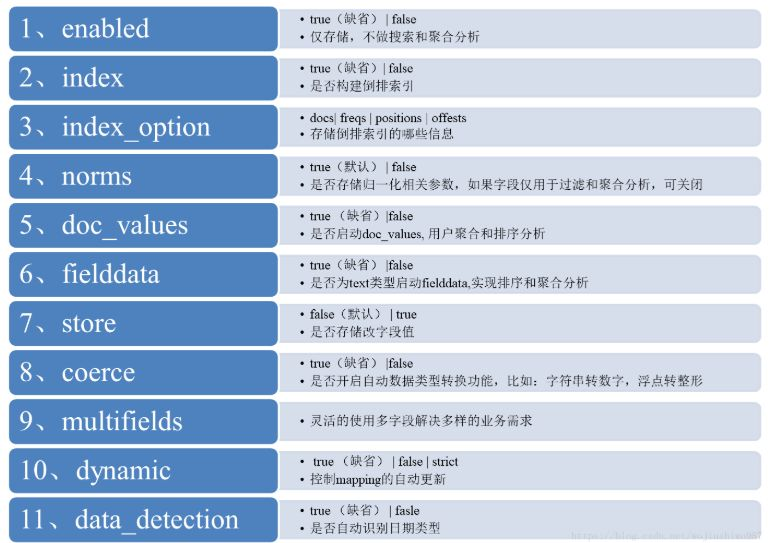
核心参数的含义,梳理如下:
索引 Templates——索引模板允许定义在创建新索引时自动应用的模板。模板包括settings和Mappings以及控制是否应将模板应用于新索引。注意:模板仅在索引创建时应用。更改模板不会对现有索引产生影响。针对大索引,使用模板是必须的。核心需要设置的setting
index.numberofreplicas 每个主分片具有的副本数。默认为 1;index.maxresultwindow 深度分页 rom + size 的最大值—— 默认为 10000;index.refresh_interval 默认 1s:代表最快 1s 搜索可见;包含 Mapping 的 template 设计万能模板
PUT _template/test_template { "index_patterns": [ "test_index_*", "test_*" ], "settings": { "number_of_shards": 1, "number_of_replicas": 1, "max_result_window": 100000, "refresh_interval": "30s" }, "mappings": { "properties": { "id": { "type": "long" }, "title": { "type": "keyword" }, "content": { "analyzer": "ik_max_word", "type": "text", "fields": { "keyword": { "ignore_above": 256, "type": "keyword" } } }, "available": { "type": "boolean" }, "review": { "type": "nested", "properties": { "nickname": { "type": "text" }, "text": { "type": "text" }, "stars": { "type": "integer" } } }, "publish_time": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" }, "expected_attendees": { "type": "integer_range" }, "ip_addr": { "type": "ip" }, "suggest": { "type": "completion" } } } }
分词的选型
ik_maxword 细粒度匹配,适用切分非常细的场景。ik_smart 粗粒度匹配,适用切分粗的场景。实际业务中:建议适用ik_max_word分词 + match_phrase短语检索。
原因:ik_smart有覆盖不全的情况,数据量大了以后,即便 reindex 能满足要求,但面对极大的索引的情况,reindex 的耗时我们承担不起。建议ik_max_word一步到位。
检索类型如何选型呢?
- text 类型作用:分词,将大段的文字根据分词器切分成独立的词或者词组,以便全文检索。
适用于:email 内容、某产品的描述等需要分词全文检索的字段;
不适用:排序或聚合(Significant Terms 聚合例外)
keyword 类型:无需分词、整段完整精确匹配
term 精确匹配
- 核心功能:不受到分词器的影响,属于完整的精确匹配。
- 应用场景:精确、精准匹配。
- 适用类型:keyword。
- 举例:term 最适合匹配的类型是 keyword,如下所示的精确完整匹配:
POST zz_test/_search { "query": { "term": { "title.keyword": "锤子加湿器官方致歉,难产后临时推迟一个月发货遭diss耍流氓" } } }
prefix 前缀匹配
- 核心功能:前缀匹配。
- 应用场景:前缀自动补全的业务场景。
- 适用类型:keyword。
如下能匹配到文档 id 为 1 的文章
POST zz_test/_search { "query": { "prefix": { "title.keyword": "锤子加湿器" } } }
wildcard 模糊匹配
- 核心功能:匹配具有匹配通配符表达式 keyword 类型的文档。支持的通配符:*,它匹配任何字符序列(包括空字符序列);?,它匹配任何单个字符。
- 应用场景:请注意,选型务必要慎重!此查询可能很慢多组关键次的情况下可能会导致宕机,因为它需要遍历多个术语。为了防止非常慢的通配符查询,通配符不能以任何一个通配符*或?开头。
- 适用类型:keyword。
如下匹配,类似 MySQL 中的通配符匹配,能匹配所有包含加湿器的文章。
POST zz_test/_search { "query": { "wildcard": { "title.keyword": "*加湿器*" } } }
match_phrase 短语匹配
- 核心功能:match_phrase 查询首先将查询字符串解析成一个词项列表,然后对这些词项进行搜索; 只保留那些包含 全部 搜索词项,且 位置"position" 与搜索词项相同的文档。
- 应用场景:业务开发中 90%+ 的全文检索都会使用 match_phrase 或者 query_string 类型,而不是 match。
- 适用类型:text
POST zz_test/_analyze
{
"text": "锤子加湿器",
"analyzer": "ik_max_word"
}
分词结果:锤子, 锤,子, 加湿器, 湿,器。如下的检索是匹配不到结果的。
POST zz_test/_search { "query": { "match_phrase": { "title": "锤子加湿器" } } }
query_string 类型
- 核心功能:支持与或非表达式+其他N多配置参数。
- 应用场景:业务系统需要支持自定义表达式检索。
- 适用类型:text。
POST zz_test/_search { "query": { "query_string": { "default_field": "title", "query": "(锤子 AND 加湿器) OR (官方 AND 道歉)" } } }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号