




预分区与自动分区
Region自动拆分
HBase 中,表会被划分为1...n 个 Region,被托管在 RegionServer 中。
Region 重要的属性:StartKey 与 EndKey 表示这个 Region 维护的 RowKey 范围,当读/写数据时,如果 RowKey 落在某个 start-end key 范围内,就会定位到目标region并且读/写到相关的数据。
默认,HBase 在创建表的时候,会自动为表分配一个 Region,start-end key 无边界,所有 RowKey 都往这个 Region里分配。
当数据越来越多,Region 的 size 越来越大时,达到默认的阈值时(根据不同的拆分策略有不同的阈值),HBase 中该 Region 将会进行 split,会找到一个 MidKey 将 Region 一分为二,成为 2 个 Region。而 MidKey 则为这二个 Region 的临界,左为 N 无下界,右为 M 无上界。< MidKey 被分配到 N 区,> MidKey 则会被分配到 M 区。
随着数据量进一步扩大,分裂的两个 Region 达到临界后将重复前面的过程,分裂出更多的 Region。
自动拆分策略
Region 分割操作是不可见的,Master 不会参与其中。RegionServer 拆分 Region的步骤是:先将该 Region 下线,然后拆分,将其子 Region 加入到 META 元信息中,再将他们加入到原本的 RegionServer 中,最后汇报 Master。执行 split 的线程是 CompactSplitThread。
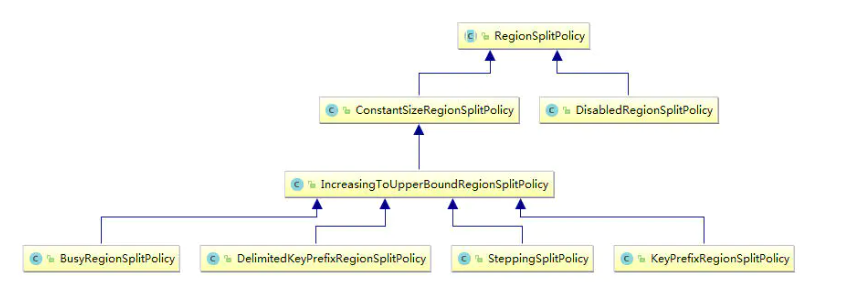
有三种配置方法:
在 hbase-site.xml 中配置,例如:
<property> <name>hbase.regionserver.region.split.policy</name> <value>org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy</value> </property>
在 HBase Configuration中配置:
private static Configuration conf = HBaseConfiguration.create(); conf.set("hbase.regionserver.region.split.policy", "org.apache.hadoop.hbase.regionserver.SteppingSplitPolicy");
在创建表的时候配置:Region 的拆分策略需要根据表的属性来合理的配置, 所以在建表的时候不建议用前两种方式配置,而是针对不同的表设置不同的策略
ConstantSizeRegionSplitPolicy
只要 Region 中的任何一个 StoreFile 的大小达到了hbase.hregion.max.filesize 所定义的大小,就进行拆分。
参数:hbase.hregion.max.filesize
default: 10737418240 (10GB) description: 当一个 Region 的任何一个 StoreFile 容量达到这个配置定义的大小后,就会拆分 Region
拆分的阈值大小可在创建表的时候设置,如果没有设置,就取hbase.hregion.max.filesize 这个配置定义的值,如果这个配置也没有定义,取默认值 10G。
@Override protected void configureForRegion(HRegion region) { super.configureForRegion(region); Configuration conf = getConf(); TableDescriptor desc = region.getTableDescriptor(); if (desc != null) { // 如果用户在建表时指定了该表的单个Region的上限, 取用户定义的这个值 this.desiredMaxFileSize = desc.getMaxFileSize(); } if (this.desiredMaxFileSize <= 0) { // 如果用户没有定义, 取'hbase.hregion.max.filesize'这个配置定义的值, 如果这个配置没有定义, 取默认值 10G this.desiredMaxFileSize = conf.getLong(HConstants.HREGION_MAX_FILESIZE, HConstants.DEFAULT_MAX_FILE_SIZE); } ... } // 判断是否进行拆分 @Override protected boolean shouldSplit() { boolean force = region.shouldForceSplit(); boolean foundABigStore = false; for (HStore store : region.getStores()) { // If any of the stores are unable to split (eg they contain reference files) // then don't split if ((!store.canSplit())) { return false; } // Mark if any store is big enough if (store.getSize() > desiredMaxFileSize) { foundABigStore = true; } } return foundABigStore || force; }
拆分效果
经过这种策略的拆分后,Region 的大小是均匀的,例如一个 10G 的Region,拆分为两个 Region 后,这两个新的 Region 的大小是相差不大的,理想状态是每个都是5G。
ConstantSizeRegionSplitPolicy **切分策略对于大表和小表没有明显的区分,阈值(hbase.hregion.max.filesize):
- 设置较大对大表比较友好,但是小表就有可能不会触发分裂,极端情况下可能就1个,这对业务来说并不是什么好事;
- 设置较小则对小表友好,但大表就会在整个集群产生大量的 Region,这对于集群的管理、资源使用、failover 来说都不是一件好事。
Connection conn = ConnectionFactory.createConnection(conf); // 创建一个数据库管理员 Admin admin = conn.getAdmin(); TableName tn = TableName.valueOf(tableName); // 新建一个表描述,指定拆分策略和最大 StoreFile Size TableDescriptorBuilder tableBuilder = TableDescriptorBuilder.newBuilder(tn) .setRegionSplitPolicyClassName(ConstantSizeRegionSplitPolicy.class.getName()) .setMaxFileSize(1048576000); // 在表描述里添加列族 for (String columnFamily : columnFamilys) { tableBuilder.setColumnFamily(ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily)).build()); } // 根据配置好的表描述建表 admin.createTable(tableBuilder.build());
IncreasingToUpperBoundRegionSplitPolicy
策略优化原来 ConstantSizeRegionSplitPolicy 只是单一按照 Region 文件大小的拆分策略,增加了对当前表的分片数作为判断因子。当Region中某个 Store Size 达到 sizeToCheck 阀值时进行拆分,sizeToCheck 计算如下:
protected long getSizeToCheck(final int tableRegionsCount) { // safety check for 100 to avoid numerical overflow in extreme cases return tableRegionsCount == 0 || tableRegionsCount > 100 ? getDesiredMaxFileSize() : Math.min(getDesiredMaxFileSize(), initialSize * tableRegionsCount * tableRegionsCount * tableRegionsCount); }
如果表的分片数为 0 或者大于 100,则切分大小还是以设置的单一 Region 文件大小为标准。如果分片数在 1~99 之间,则由 min(单一 Region 大小, Region 增加策略的初始化大小 * 当前 Table Region 数的3次方) 决定。
protected void configureForRegion(HRegion region) { super.configureForRegion(region); Configuration conf = getConf(); initialSize = conf.getLong("hbase.increasing.policy.initial.size", -1); if (initialSize > 0) { return; } TableDescriptor desc = region.getTableDescriptor(); if (desc != null) { initialSize = 2 * desc.getMemStoreFlushSize(); } if (initialSize <= 0) { initialSize = 2 * conf.getLong(HConstants.HREGION_MEMSTORE_FLUSH_SIZE, TableDescriptorBuilder.DEFAULT_MEMSTORE_FLUSH_SIZE); } }
1)相关参数:
hbase.hregion.max.filesize
- default: 10737418240 (10GB)
- description: 当一个 Region 的任何一个 StoreFile 容量达到这个配置定义的大小后,就会拆分 Region,该策略下并不会一开始就以该值作为拆分阈值
hbase.increasing.policy.initial.size
- default: none
- description: IncreasingToUpperBoundRegionSplitPolicy 拆分策略下用于计算 Region 阈值的一个初始值
hbase.hregion.memstore.flush.size
- default: 134217728 (128MB)
- description: 如果 Memstore 的大小超过这个字节数,它将被刷新到磁盘
tableRegionsCount = 1 initialSize = 2 * 128M = 256M getDesiredMaxFileSize() = 10G sizeToCheck = min(getDesiredMaxFileSize(), initialSize * tableRegionsCount * tableRegionsCount * tableRegionsCount) = min(10G, 256M) = 256M
- 拆分后这张表有两个 Region,当 Region 大小达到 2GB 时开始拆分:
tableRegionsCount = 2 initialSize = 2 * 128M = 256M getDesiredMaxFileSize() = 10G sizeToCheck = min(getDesiredMaxFileSize(), initialSize * tableRegionsCount * tableRegionsCount * tableRegionsCount) = min(10G, 2 * 2 * 2 * 256M) = min(10G, 2G) = 2G
- 以此类推,当表有3个 Region 的时候,Region 的最大容量为 6.75G
- 当表有4个Region的时候,计算出来的结果大于10GB,所以使用10GB 作为以后的拆分上限
IncreasingToUpperBoundRegionSplitPolicy 切分策略弥补了ConstantSizeRegionSplitPolicy 的短板,能够自适应大表和小表,并且在大集群条件下对于很多大表来说表现很优秀。但并不完美,这种策略下很多小表会在大集群中产生大量小 Region,分散在整个集群中。而且在发生 Region 迁移时也可能会触发 Region 分裂。
Connection conn = ConnectionFactory.createConnection(conf); // 创建一个数据库管理员 Admin admin = conn.getAdmin(); TableName tn = TableName.valueOf(tableName); // 新建一个表描述,指定拆分策略和最大 StoreFile Size TableDescriptorBuilder tableBuilder = TableDescriptorBuilder.newBuilder(tn) .setRegionSplitPolicyClassName(IncreasingToUpperBoundRegionSplitPolicy.class.getName()) .setMaxFileSize(1048576000) .setValue("hbase.increasing.policy.initial.size", "134217728"); // 在表描述里添加列族 for (String columnFamily : columnFamilys) { tableBuilder.setColumnFamily(ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily)).build()); } // 根据配置好的表描述建表 admin.createTable(tableBuilder.build());
SteppingSplitPolicy
SteppingSplitPolicy 是IncreasingToUpperBoundRegionSplitPolicy 子类,对 Region 拆分文件大小做了优化,如果只有1个 Region 的情况下,那第1次的拆分就是 256M,后续则按配置的拆分文件大小(10G)做为拆分标准。
@Override protected long getSizeToCheck(final int tableRegionsCount) { return tableRegionsCount == 1 ? this.initialSize : getDesiredMaxFileSize(); }
在 IncreasingToUpperBoundRegionSplitPolicy 策略中,针对大表的拆分表现很不错,但是针对小表会产生过多的 Region,SteppingSplitPolicy 则将小表的 Region 控制在一个合理的范围,对大表的拆分也不影响。
Connection conn = ConnectionFactory.createConnection(conf); // 创建一个数据库管理员 Admin admin = conn.getAdmin(); TableName tn = TableName.valueOf(tableName); // 新建一个表描述,指定拆分策略和最大 StoreFile Size TableDescriptorBuilder tableBuilder = TableDescriptorBuilder.newBuilder(tn) .setRegionSplitPolicyClassName(SteppingSplitPolicy.class.getName()) .setMaxFileSize(1048576000) .setValue("hbase.increasing.policy.initial.size", "134217728"); // 在表描述里添加列族 for (String columnFamily : columnFamilys) { tableBuilder.setColumnFamily(ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily)).build()); } // 根据配置好的表描述建表 admin.createTable(tableBuilder.build());
预分区方法
数据的 RowKey 是如何分布的,然后根据 RowKey 的特点规划要分成多少 Region,每个 Region 的 startKey 和 endKey 是多少,接着就可以预分区了。RowKey 的前几位字符串都是从 0001~0010 的数字,这样可以分成10个Region:
0001| 0002| 0003| 0004| 0005| 0006| 0007| 0008| 0009|
第一行为第一个 Region 的 stopKey。为什么后面会跟着一个"|",是因为在ASCII码中,"|"的值是124,大于所有的数字和字母等符号。
shell中建分区表
create 'test', {NAME => 'cf', VERSIONS => 3, BLOCKCACHE => false}, SPLITS => ['10','20','30']
通过指定 SPLITS_FILE 的值指定分区文件,从文件中读取分区值,文件格式如上述例子所示:
create 'test', {NAME =>'cf', COMPRESSION => 'SNAPPY'}, {SPLITS_FILE =>'region_split_info.txt'}
HBase API 建预分区表
byte[][] splitKeys = { Bytes.toBytes("10"), Bytes.toBytes("20"), Bytes.toBytes("30") }; // 创建数据库表 public static void createTable(String tableName, byte[][] splitKeys, String... columnFamilys) throws IOException { // 建立一个数据库的连接 Connection conn = getCon(); // 创建一个数据库管理员 Admin admin = conn.getAdmin(); TableName tn = TableName.valueOf(tableName); TableDescriptorBuilder tableBuilder = TableDescriptorBuilder.newBuilder(tn) .setRegionSplitPolicyClassName(IncreasingToUpperBoundRegionSplitPolicy.class.getName()) .setValue("hbase.increasing.policy.initial.size", "134217728"); // 在表描述里添加列族 for (String columnFamily : columnFamilys) { tableBuilder.setColumnFamily(ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily)).build()); } // 根据配置好的表描述建表 admin.createTable(tableBuilder.build(), splitKeys); } conn.close(); }
随机散列与预分区
为防止热点问题,同时避免 Region Split 后,部分 Region 不再写数据或者很少写数据。也为了得到更好的并行性,希望有好的 load blance,让每个节点提供的请求处理都是均等的,并且 Region 不要经常 split,因为 split 会使 server 有一段时间的停顿,随机散列加上预分区是比较好的解决方式。
long currentId = 1L; byte [] rowkey = Bytes.add(MD5Hash.getMD5AsHex(Bytes.toBytes(currentId)).substring(0, 8).getBytes(), Bytes.toBytes(currentId));
方式RowKey 设计,如何去进行预分区?
- 先取样,先随机生成一定数量的 RowKey ,将取样数据按升序排序放到一个集合里;
- 根据预分区的 Region 个数,对整个集合平均分割,得到相关的 splitKeys;
- 再创建表时将步骤2得到的 splitKeys 传入即可。
partition + 预分区
将区域用长整数作为分区号,每个 Region 管理着相应的区域数据,在 RowKey 生成时,将 id 取模后,然后拼上 id 整体作为 RowKey 。
long currentId = 1L; long partitionId = currentId % partition; byte[] rowkey = Bytes.add(Bytes.toBytes(partitionId), Bytes.toBytes(currentId));


 浙公网安备 33010602011771号
浙公网安备 33010602011771号