

Physical Partitioning
一个transformation之后,Flink提供底层API以允许用户在必要时精确控制流分区,Physical partitioning(或operator partition)就是operator parallel instance即SubTask。

Shuffle (Random partitioning 随机)
Random partitioning randomly partitions data streams in an evenly(均匀) manner
Rebalancing partitioning(均匀 via round robin method)
This type of partitioning helps distribute the data evenly. It uses a round robin method for distribution. This type of partitioning is good when data is skewed.
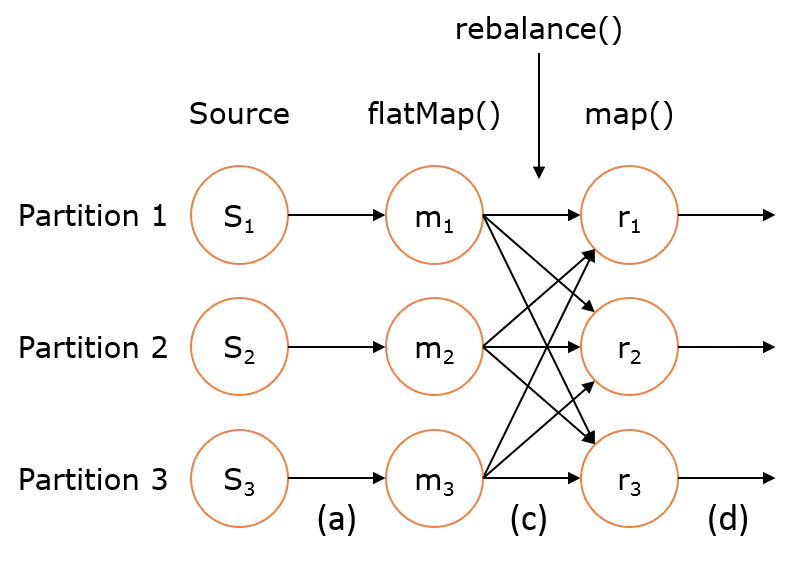
Rescaling
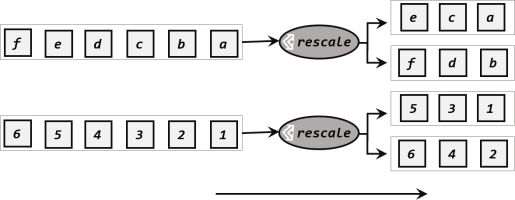
Rescaling is used to distribute the data across operations, perform transformations on sub-sets of data and combine them together. This rebalancing happens over a single node only, hence it does not require any data transfer across networks.
从source的每个并行实例分散到若干个mappers以负载均衡,但是不期望rebalacne()那样进行全局负载均衡。这将仅需要本地数据传输,而不是通过网络传输数据,具体取决于其他配置值,例如TaskManager的插槽数。
可伸缩分区 stream.rescale.flink根据资源使用情况动态调节同一作业的数据分布,根据物理实例部署时的资源共享情况动态调节数据分布,目的是让数据尽可能的在同一 solt 内流转,以减少网络开销。
例如 stream.setParallelism(4).rescale.print().setParallelism(2) 前面会4个分区,后面算子只有2个分区。那么前面4个分区会映射到后面的2个分区中。例如4中的0,1 映射到后面的 0 分区,2,3映射到后面1分区。反过来例如 stream.setParallelism(2).rescale.print().setParallelism(4) 前面有2个分区,后面算子有4个分区,那么前面的0号分区会选择后面的0,1分区发数据。 1号分区会选择后面的2,3号分区发数据。
总之不同于上面2种的是上游4个分区中的数据不会分到下游的多个分区中。这样做的好处是,尽量将数据计算本地化。
Broadcasting(动态规则更新)
Broadcasting distributes all records to each partition. This fans out each and every element to all partitions.
在调用时,方法需要传入两个参数,第一个是自定义分区器(Partitioner)对象,第二个是应用分区器的字段,指定方式与 keyBy 指定 key 基本一样:可以通过字段名称指定, 也可以通过字段位置索引来指定,还可以实现一个KeySelector。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号