




底层存储
RocketMQ 存储的文件主要包括 Commitlog 文件、ConsumeQueue 文件、Index 文件。
RocketMQ 将所有主题的消息存储在同一个文件中,确保消息发送时按顺序写文件,尽最大能力确保消息发送的高可用性与高吞吐量。
消息中间件一般都是基于主题的订阅与发布模式,消息消费时必须按照主题进行帅选消息,显然从 Commitlog 文件中按照 topic 去筛选消息会变得及其低效,为了提高根据主题检索消息的效率,RocketMQ 引入了 ConsumeQueue 文件,俗成消费队列文件。
RocketMQ 提供了基于消息属性的检索能力,底层的核心设计理念是为 Commitlog 文件建立哈希索引,并存储在 Index 文件中。
在 RocketMQ 中顺序写入到 Commitlog 文件后,ConsumeQueue 与 Index 文件都是异步构建的,其数据流向图如下:
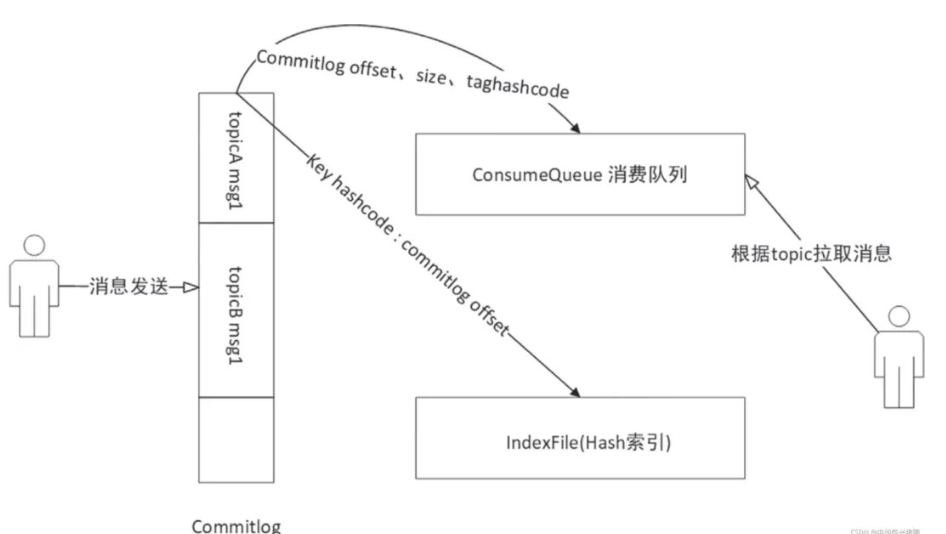
RocketMQ 在消息写入过程中追求极致的磁盘顺序写。所有主题的消息全部写入一个文件,即 Commitlog 文件。所有消息按抵达顺序依次追加到文件中,消息一旦写入,不支持修改。Commitlog 文件的具体布局如下图所示:
一条一条消息存入文件 Commitlog 后,该如何查找呢?在基于文件编程的模型中,也会为一条消息引入一个身份标志:消息物理偏移量,即消息存储在文件的起始位置。
Commitlog 的文件名命名也是极具技巧性,使用了存储在该文件的第一条消息在整个 Commitlog 文件组中的偏移量来命名,例如第一个 Commitlog 文件为0000000000000000000,第二个文件为00000000001073741824,然后依次类推。
好处是给出任意一个消息的物理偏移量,例如消息偏移量为 73741824,可以通过二分法进行查找,快速定位这个文件在第一个文件中,然后用消息的物理偏移量减去该文件的名称所得到的差值,就是在该文件中的绝对地址。
Commitlog 文件的设计理念是追求极致的消息写,但我们知道消息消费模型是基于主题的订阅机制,即一个消费组是消费特定主题的消息。如果根据主题从 commitlog 文件中检索消息,我们会发现这绝不是一个好主意,只能从文件的第一条消息逐条检索,其性能可想而知,故为了解决基于 topic 的消息检索问题,RocketMQ 引入了 consumequeue 文件,consumequeue 的结构如下图所示

ConsumeQueue 文件是消息消费队列文件,是 Commitlog 文件基于 Topic 的索引文件,主要用于消费者根据 Topic 消费消息,其组织方式为/topic/queue,同一个队列中存在多个文件。每个条目长度固定(8 字节 commitlog 物理偏移量、4 字节消息长度、8 字节 tag hashcode)。
不是存储 tag 的原始字符串,而选择存储 hashcode,目的就是确保每个条目的长度固定,可以使用访问类似数组下标的方式快速定位条目,极大地提高了 ConsumeQueue 文件的读取性能。
消息消费者根据 topic、消息消费进度(consumeuqe 逻辑偏移量),即第几个 Consumeque 条目,这样的消费进度去访问消息的方法为使用逻辑偏移量 logicOffset * 20 即可找到该条目的起始偏移量(consumequeue 文件中的偏移量),然后读取该偏移量后 20 个字节即得到一个条目,无须遍历 consumequeue 文件。
RocketMQ 引入了 Index 索引文件,实现基于文件的哈希索引。IndexFile 的文件存储结构如下图所示:
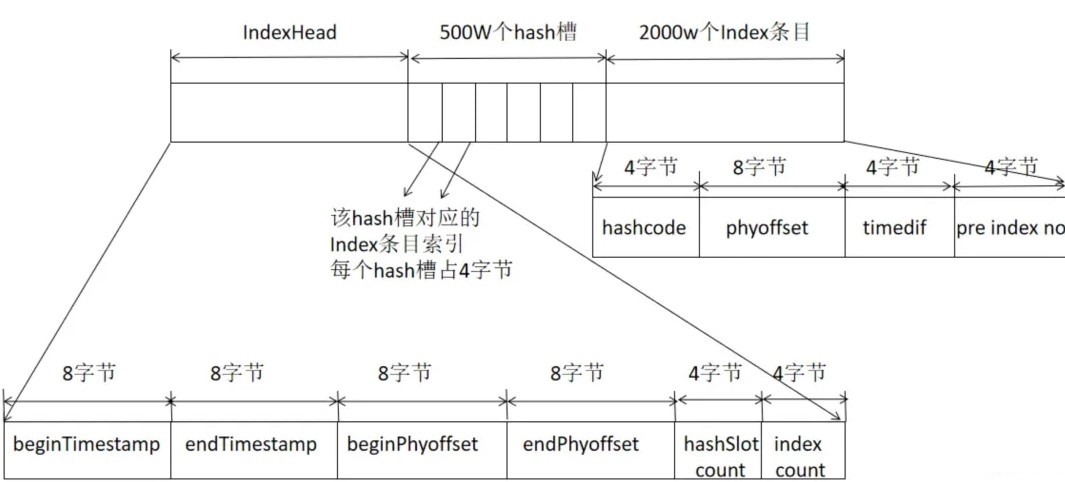
IndexFile 文件基于物理磁盘文件实现 Hash 索引。其文件由 40 字节的文件头、500万 个 Hash 槽,每个 Hash 槽 4 个字节,最后由 2000万 个 Index 条目,每个条目由 20个 字节构成,分别为 4 字节索引 key 的 hashcode、8 字节消息物理偏移量、4 字节时间戳、4 字节的前一个 Index 条目(Hash 冲突的链表结构)。
建立了索引 Key 的 hashcode 与物理偏移量的映射关系,根据 key 先快速定义到 commitlog 文件。
顺序写
提高其写入性能的另外一个设计原理是磁盘顺序写
内存映射机制
Linux 操作系统中的内存使用策略时会尽可能地利用机器的物理内存,并常驻内存中,就是所谓的页缓存。在操作系统的内存不够的情况下,采用缓存置换算法,例如 LRU 将不常用的页缓存回收,即操作系统会自动管理这部分内存。
如果 RocketMQ Broker 进程异常退出,存储在页缓存中的数据并不会丢失,操作系统会定时将页缓存中的数据持久化到磁盘,做到数据安全可靠。
刷盘策略
RocketMQ 提供了多种策略:同步刷盘、异步刷盘。
同步刷盘在 RocketMQ 的实现中成为组提交,并不是每一条消息都必须刷盘。其设计理念如图所示:
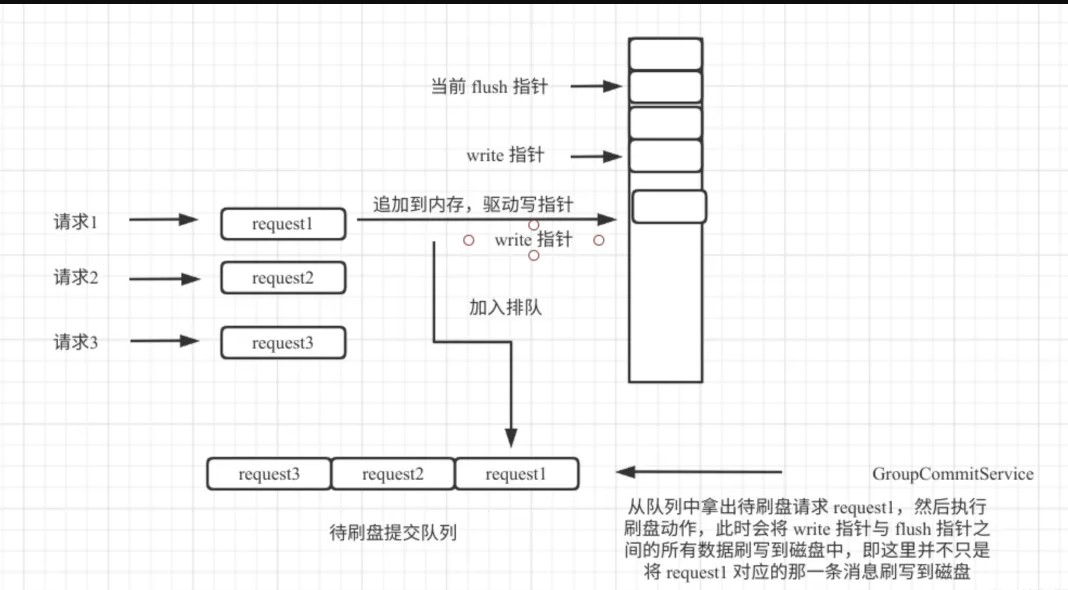
同步刷盘,每一个线程将数据追到到内存后,并向刷盘线程提交刷盘请求,然后会阻塞;刷盘线程从任务队列中获取一个任务,然后触发一次刷盘,但并不只刷与请求相关的消息,而是会直接将内存中待刷盘的所有消息一次批量刷盘,然后就可以唤醒一组请求线程,实现组刷盘。
异步刷盘
同步刷盘的优点是能保证消息不丢失,即向客户端返回成功就代表这条消息已被持久化到磁盘,即消息非常可靠,但这是以牺牲写入响应延迟性能为代价的,由于 RocketMQ 的消息是先写入 pagecache,故消息丢失的可能性较小,如果能容忍一定几率的消息丢失,可以考虑使用异步刷盘。
异步刷盘指的是 broker 将消息存储到 pagecache 后就立即返回成功,然后开启一个异步线程定时执行 FileChannel 的 forece 方法,将内存中的数据定时刷写到磁盘,默认间隔为 500ms.
内存级读写分离
RocketMQ 为了降低 pagecache 的使用压力引入了 transientStorePoolEnable 机制,即内存级别的读写分离机制。
默认情况下 RocketMQ 将消息写入 pagecache,消息消费时从 pagecache 中读取,这样在高并发时 pagecache 的压力会比较大,容易出现瞬时 broker busy,故 RocketMQ 还引入了 transientStorePoolEnable,将消息先写入堆外内存并立即返回,然后异步将堆外内存中的数据提交到 pagecache,再异步刷盘到磁盘中。其工作机制如下图所示:
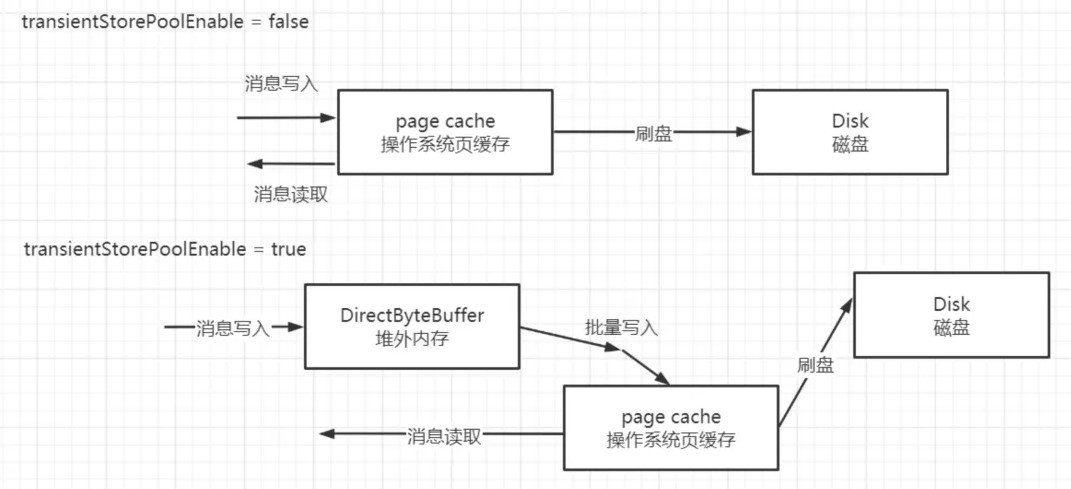
消息在消费读取时不会尝试从堆外内存中读,而是从 pagecache 中读取,这样就形成了内存级别的读写分离,即消息写入时主要面对堆外内存,而读消息时主要面对 pagecache。
该方案的优点是消息是直接写入堆外内存,然后异步写入 pagecache。相比每条消息追加直接写入 pagechae,其最大的优势是将消息写入 pagecache 操作批量化。
该方案的缺点是如果由于某些意外操作导致 Broker 进程异常退出,那么存储在堆外内存的数据会丢失,但如果是放入 pagecache,broke r异常退出并不会丢失消息。
参考:
https://developer.aliyun.com/article/799550


 浙公网安备 33010602011771号
浙公网安备 33010602011771号