

WaterMark
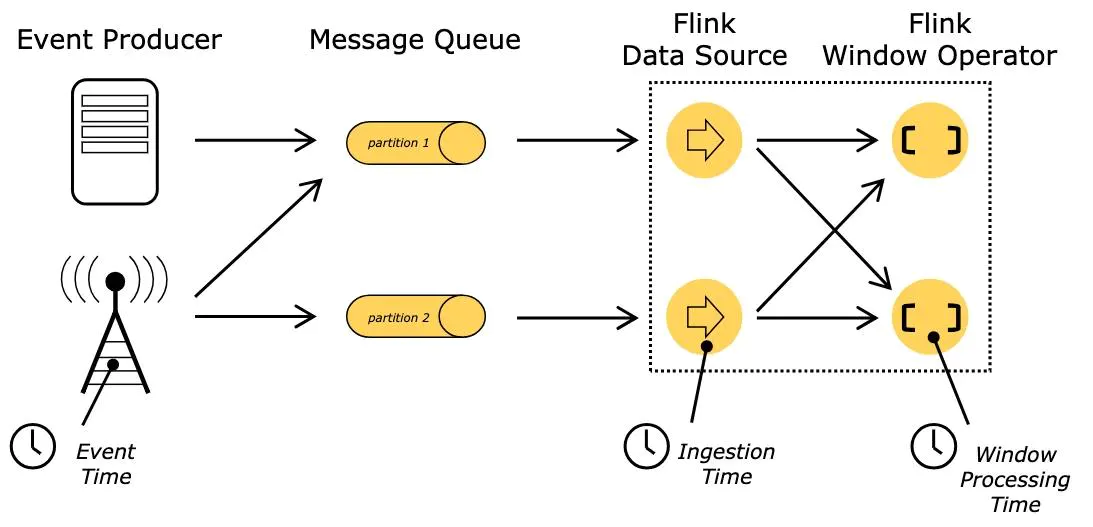
EventTime: 事件发生时间,事件发生所在设备的当地时间,比如一个点击事件的时间发生时间,即用户点击操作所在的手机或电脑的时间
IngestionTime:事件摄入时间,事件进入Flink的时间
processTime:事件处理时间,事件被处理的时间,就是由机器的系统时间来决定
水位线:支持事件时间的流处理器需要一种衡量事件时间进度的方法,使用事件时间必须要使用注册水位线,而水位线也是事件时间专用的。怎么衡量时间到了没?所以Flink中用于衡量事件时间进度的机制是水位线。
并不是每条数据都会生成水位线。水位线也是一条数据,是流数据的一部分,watermark是一个全局的值,不是某一个key下的值,所以即使不是同一个key的数据,其warmark也会增加。
水位线还有一个重要作用,就是处理延迟数据,我们在文章开头的部分也提到了,数据乱序怎么处理,那么有些数据因为网络的原因,延迟了几秒,所以也可以「把水位线看作是窗口最后的执行时间」。
规定滚动窗口为5秒,也就是[5-10),同时我们预测数据一般可能延迟3秒,所以我们希望窗口是当10s的数据到达后,继续等待3秒,看这3秒内,还是否有原本是[5-10)中的数据,一起归并到这个窗口中,等到出现了时间为大于等于13s的数据时,就会触发[5-10)这个窗口的数据执行。这就是延迟处理。
Event Time的使用一定要指定数据源中的时间戳。否则程序无法知道事件的事件时间是什么(数据源里的数据没有时间戳的话,就只能使用Processing Time。
生成WaterMark
造成数据的乱序与延迟,可以设置WaterMark等待一定时间而且会在下一个窗口触发前,计算好上一个延迟的窗口。WaterMark设定方法有两种:
-
Punctuated Watermark : 数据流中每一个递增的EventTime会产生一个Watermark。在实际的生产中用Punctuated方式,在TPS很高的场景下,会产生大量的Watermark,在一定程度上造成了对下游算子造成压力。只有在实时性要求非常高的场景才会选择Punctuated的方式
-
Periodic Watermark : 默认200毫秒为一周期(或达到一定的记录条数)产生一个Watermark。在实际的生产中使用Periodic的方式必须结合时间和积累条数两个维度,周期性的产生Watermark,否则在极端情况下会有很大的延时
在 Flink 的 DataStream API 中 , 有 一 个 单 独 用 于 生 成 水 位 线 的 方法:.assignTimestampsAndWatermarks(),主要用来为流中的数据分配时间戳,并生成水位线来指示事件时间
source.assignTimestampsAndWatermarks(<watermark strategy>)
.assignTimestampsAndWatermarks()方法需要传入一个 WatermarkStrategy 作为参数,就是 “ 水位线生成策略 ” 。WatermarkStrategy中包含 一 个 “时间戳分配器”TimestampAssigner 和一个“水位线生成器”WatermarkGenerator。
- TimestampAssigner:主要负责从流中数据元素的某个字段中提取时间戳并分配给元素。时间戳的分配是生成水位线的基础。
- WatermarkGenerator: 主要负责按照既定的方式, 基于时间戳生成水位线。在WatermarkGenerator 接口中,主要又有两个方法:onEvent()和onPeriodicEmit()。
- onEvent:每个事件(数据)到来都会调用的方法,参数有当前事件、时间戳以及允许发出水位线的一个 WatermarkOutput,可以基于事件做各种操作
- onPeriodicEmit:周期性调用的方法,可以由 WatermarkOutput 发出水位线。周期时间为处理时间,可以调用环境配置的.setAutoWatermarkInterval()方法来设置,默认为200ms。
Flink 内置水位线生成器
WatermarkStrategy接口是一个生成水位线策略抽象,可以灵活地实现自己的需求,在 Flink 提供了内置的水位线生成器(WatermarkGenerator),不仅开箱即用简化了编程,而且也自定义水位线策略提供了模板。
这两个生成器可以通过调用 WatermarkStrategy 的静态辅助方法来创建。它们都是周期性生成水位线的,分别对应着处理有序流和乱序流的场景。
有序流
对于有序流,特点就是时间戳单调增长(Monotonously Increasing Timestamps),所以永远不会出现迟到数据的问题。这是周期性生成水位线的最简单的场景, 直接调用WatermarkStrategy.forMonotonousTimestamps()方法就可以实现。简单来说,就是直接拿当前最大的时间戳作为水位线就可以了。
// 有序流 SingleOutputStreamOperator<Event> timestampsAndWatermarks = source.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps() .withTimestampAssigner(new SerializableTimestampAssigner<Event>() { @Override public long extractTimestamp(Event element, long recordTimestamp) { return element.timestamp; } }));
注意的是,时间戳和水位线的单位,必须都是毫秒。
乱序流
乱序流需要等待迟到数据到齐,必须设置一个固定量延迟时间( Fixed Amount of Lateness)。生成水位线时间戳,就是当前数据流中最大的时间戳减去延迟的结果,相当于把表调慢,当前时钟会滞后于数据的最大时间戳。调用 WatermarkStrategy. forBoundedOutOfOrderness()方法就可以实现。方法需要传入一个 maxOutOfOrderness 参数,表示“最大乱序程度”,表示数据流中乱序数据时间戳的最大差值;如果能确定乱序程度,设置对应时间长度的延迟,就可以等到所有的乱序数据。
// 乱序流 SingleOutputStreamOperator<Event> timestampsAndWatermarks = source.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5L)) .withTimestampAssigner(new SerializableTimestampAssigner<Event>() { @Override public long extractTimestamp(Event element, long recordTimestamp) { return element.timestamp; } }));
同样提取了 timestamp 字段作为时间戳,并且以 5 秒的延迟时间创建了处理乱序流的水位线生成器
有序流的水位线生成器本质上和乱序流是一样的,相当于延迟设为 0 的乱序流水位线生成器,两者完全等同:
WatermarkStrategy.forMonotonousTimestamps()
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(0))
乱序流中生成的水位线真正的时间戳,其实是 当前最大时间戳 – 延迟时间 – 1,单位是毫秒。为什么要减 1 毫秒呢?我们可以回想一下水位线的特点:时间戳为 t 的水位线,表示时间戳≤t 的数据全部到齐,不会再来了。如果考虑有序流,也就是延迟时间为 0 的情况,那么时间戳为 7 秒的数据到来时,之后其实是还有可能继续来 7 秒的数据的;所以生成的水位线不是 7 秒,而是 6 秒 999 毫秒,7 秒的数据还可以继续来。
自定义水位线
在WatermarkStrategy 中,时间戳分配器 TimestampAssigner指定字段提取时间戳就可以;不同策略的关键就在于 WatermarkGenerator 的实现。Flink有两种不同的生成水位线的方式:一种是周期性的(Periodic),另一种是断点式的(Punctuated)。WatermarkGenerator 接口onEvent()和onPeriodicEmit(),前者是在每个事件到来时调用,而后者由框架周期性调用。
周期性水位线生成器(Periodic Generator)
周期性生成器一般是通过 onEvent()观察判断输入的事件,而在 onPeriodicEmit()里发出水位线。
自定义水位生成
public class MyWaterGenerator implements WatermarkGenerator<Event> { /** * 延迟时间 */ private Long delayTime = 5000L; /** * 观察到的最大时间戳 */ private Long maxTs = Long.MIN_VALUE + delayTime + 1L; @Override public void onEvent(Event event, long eventTimestamp, WatermarkOutput output) { /** * 来一条数据就调用一次,更新最大时间戳 */ maxTs = Math.max(event.getTimestamp(), maxTs); } @Override public void onPeriodicEmit(WatermarkOutput output) { /** * 发射水位线,默认200ms调用一次 */ output.emitWatermark(new Watermark(maxTs - delayTime - 1L)); } }
自定义水位生成策略
public class MyWaterStrategy implements WatermarkStrategy<Event> { @Override public TimestampAssigner<Event> createTimestampAssigner(TimestampAssignerSupplier.Context context) { return new SerializableTimestampAssigner<Event>() { @Override public long extractTimestamp(Event element, long recordTimestamp) { return element.getTimestamp(); } }; } @Override public WatermarkGenerator<Event> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) { return new MyWaterGenerator(); } }
断点式水位线生成器(Punctuated Generator)
断点式生成器会不停地检测 onEvent()中的事件,当发现带有水位线信息的特殊事件时, 就立即发出水位线。一般来说,断点式生成器不会通过onPeriodicEmit()发出水位线。自定义的断点式水位线生成器代码如下:
@Override public void onEvent(Event r, long eventTimestamp, WatermarkOutput output) { // 只有在遇到特定的 itemId 时,才发出水位线 if (r.user.equals("Mary")) { output.emitWatermark(new Watermark(r.timestamp - 1)); } } @Override public void onPeriodicEmit(WatermarkOutput output) { // 不需要做任何事情,因为我们在 onEvent 方法中发射了水位线 }
自定义数据源中发送水位线
在自定义的数据源中抽取事件时间,然后发送水位线。要注意的是,在自定义数据源中发送水位线以后,就不能再在程序中使用assignTimestampsAndWatermarks 方法 来 生 成 水 位 线 。 在 自 定 义 数 据 源 中 生 成 水 位 线 和 在 程 序 中 使 用assignTimestampsAndWatermarks 方法生成水位线二者只能取其一。
/** * createMyWater2 */ @Test public void createMyWater2() { SingleOutputStreamOperator<Event> timestampsAndWatermarks = env.addSource(new createMyWaterSource()); } class createMyWaterSource implements SourceFunction<Event> { private boolean running = true; public void run(SourceContext<Event> sourceContext) throws Exception { Random random = new Random(); String[] userArr = {"Mary", "Bob", "Alice"}; String[] urlArr = {"./home", "./cart", "./prod?id=1"}; while (running) { long currTs = Calendar.getInstance().getTimeInMillis(); // 毫秒间戳 String username = userArr[random.nextInt(userArr.length)]; String url = urlArr[random.nextInt(urlArr.length)]; Event event = new Event(username, url, currTs); // 使用 collectWithTimestamp 方法将数据发送出去,并指明数据中的时间戳的字段 sourceContext.collectWithTimestamp(event, event.timestamp); // 发送水位线 sourceContext.emitWatermark(new Watermark(event.timestamp - 1L)); Thread.sleep(1000L); } } @Override public void cancel() { running = false; } }
水位线传递
水位线是数据流中插入的一个标记,用来表示事件时间的进展,会随着数据一起在任务间传递。如果只是直通式(forward)的传输,数据和水位线都是按照本身的顺序依次传递、依次处理的;一旦水位线到达了算子任务, 那么这个任务就会将它内部的时钟设为这个水位线的时间戳。
“任务的时钟”其实仍然是各自为政的,并没有统一的时钟。实际应用中往往上下游都有多个并行子任务,为了统一推进事件时间的进展,我们要求上游任务处理完水位线、时钟改变之后,要把当前的水位线再次发出,广播给所有的下游子任务。这样,后续任务就不需要依赖原始数据中的时间戳
还有另外一个问题,那就是在“重分区”(redistributing)的传输模式下,一个任务有可能会收到来自不同分区上游子任务的数据。而不同分区的子任务时钟并不同步,所以同一时刻发给下游任务的水位线可能并不相同。这时下游任务又该听谁的呢?
如果一个任务收到了来自上游并行任务的不同的水位线,说明上游各个分区处理得有快有慢,进度各不相同比如上游有两个并行子任务都发来了水位线,一个是 5 秒,一个是 7 秒;这代表第一个并行任务已经处理完 5 秒之前的所有数据,而第二个并行任务处理到了 7 秒。那这时自己的时钟怎么确定呢?当然也要以“这之前的数据全部到齐”为标准。如果我们以较大的水位线 7 秒作为当前时间,那就表示“7 秒前的数据都已经处理完”,这显然不是事实——第一个上游分区才处理到 5 秒,5~7 秒的数据还会不停地发来;而如果以最小的水位线 5 秒作为当前时钟就不会有这个问题了,因为确实所有上游分区都已经处理完,不会再发 5 秒前的数据了
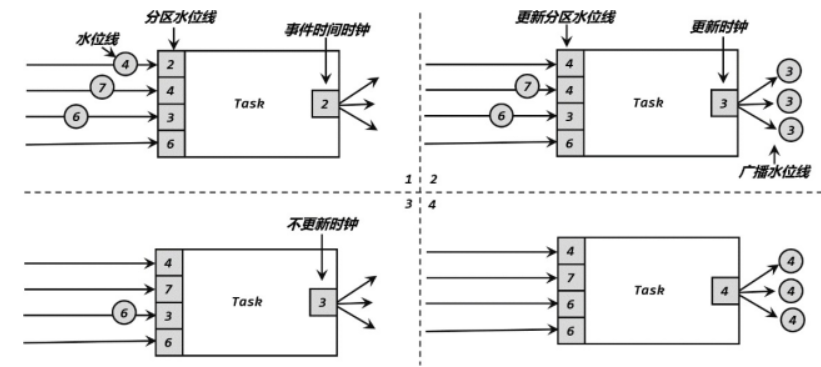
当前任务的上游,有四个并行子任务,所以会接收到来自四个分区的水位线;而下游有三个并行子任务,所以会向三个分区发出水位线。具体过程如下:上游并行子任务发来不同的水位线,当前任务会为每一个分区设置一个“分区水位线”(Partition Watermark),这是一个分区时钟;而当前任务自己的时钟,就是所有分区时钟里最小的那个。
当有一个新的水位线(第一分区的 4)从上游传来时,当前任务会首先更新对应的分区时钟;然后再次判断所有分区时钟中的最小值,如果比之前大,说明事件时间有了进展,当前任务的时钟也就可以更新了。这里要注意,更新后的任务时钟,并不一定是新来的那个分区水位线,比如这里改变的是第一分区的时钟,但最小的分区时钟是第三分区的 3,于是当前任务时钟就推进到了 3。当时钟有进展时,当前任务就会将自己的时钟以水位线的形式,广播给下游所有子任务。再次收到新的水位线(第二分区的 7)后,执行同样的处理流程。首先将第二个分区时钟更新为 7,然后比较所有分区时钟;发现最小值没有变化,那么当前任务的时钟也不变,也不会向下游任务发出水位线。同样道理,当又一次收到新的水位线(第三分区的 6)之后,第三个分区时钟更新为6,同时所有分区时钟最小值变成了第一分区的 4,所以当前任务的时钟推进到 4,并发出时间戳为 4 的水位线,广播到下游各个分区任务。 水位线在上下游任务之间的传递,非常巧妙地避免了分布式系统中没有统一时钟的问题, 每个任务都以“处理完之前所有数据”为标准来确定自己的时钟,就可以保证窗口处理的结果总是正确的。
水位线的默认计算公式:水位线 = 观察到的最大事件时间 – 最大延迟时间 – 1 毫秒
这里涉及到一个问题,就是不同的算子看到的水位线的大小可能是不一样的。因为下游的算子可能并未接收到来自上游算子的水位线,导致下游算子的时钟要落后于上游算子的时钟。比如 map->reduce 这样的操作,如果在 map 中编写了非常耗时间的代码,将会阻塞水位线的向下传播,因为水位线也是数据流中的一个事件,位于水位线前面的数据如果没有处理完毕,那么水位线不可能弯道超车绕过前面的数据向下游传播,也就是说会被前面的数据阻塞。这样就会影响到下游算子的聚合计算,因为下游算子中无论由窗口聚合还是定时器的操作,都需要水位线才能触发执行。这也就告诉了我们,在编写 Flink 程序时,一定要谨慎的编写每一个算子的计算逻辑,尽量避免大量计算或者是大量的 IO 操作,这样才不会阻塞水位线的向下传递。
在数据流开始之前,Flink 会插入一个大小是负无穷大(在 Java 中是-Long.MAX_VALUE) 的水位线,而在数据流结束时,Flink 会插入一个正无穷大(Long.MAX_VALUE)的水位线,保证所有的窗口闭合以及所有的定时器都被触发。
对于离线数据集,Flink 也会将其作为流读入,也就是一条数据一条数据的读取。在这种情况下,Flink 对于离线数据集,只会插入两次水位线,也就是在最开始处插入负无穷大的水位线,在结束位置插入一个正无穷大的水位线。因为只需要插入两次水位线,就可以保证计算的正确,无需在数据流的中间插入水位线了。
参考:
https://liudongdong.top/archives/flinker-shi-flink-chuang-jian-shui-wei-xian-watermark

 浙公网安备 33010602011771号
浙公网安备 33010602011771号