

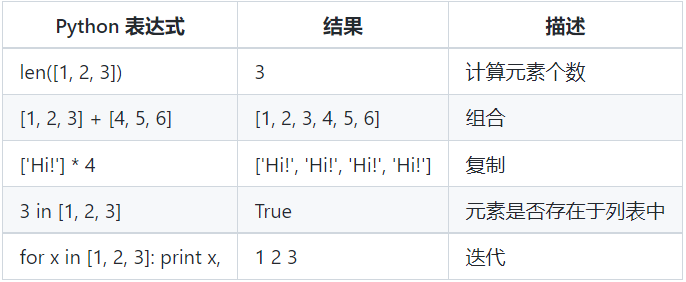
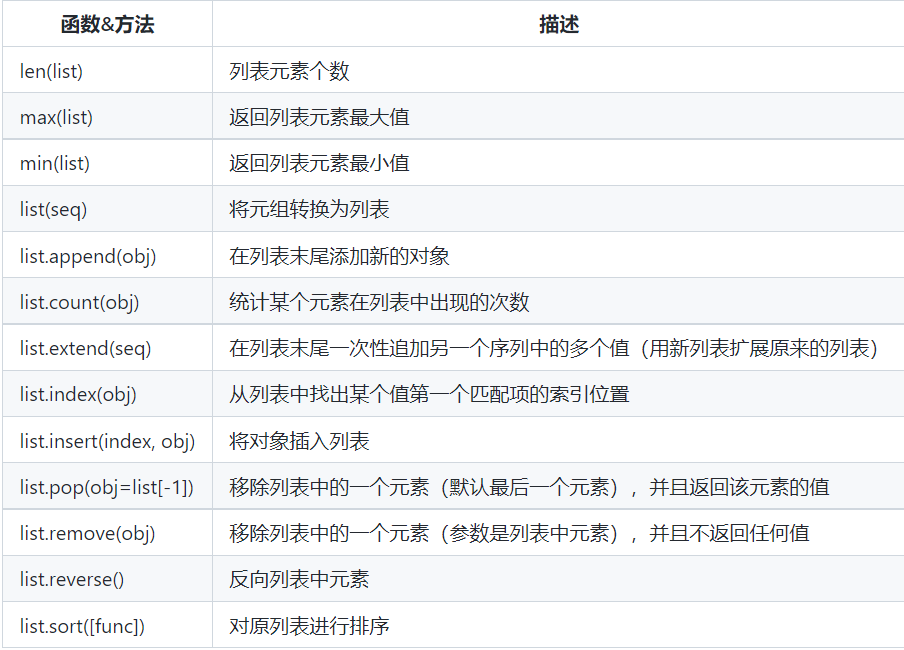
list、tuple、列表解析
List
list 生成式的语法为:
[expr for iter_var in iterable] [expr for iter_var in iterable if cond_expr]
第一种语法:首先迭代 iterable 里所有内容,每一次迭代,都把 iterable 里相应内容放到iter_var 中,再在表达式中应用该 iter_var 的内容,最后用表达式的计算值生成一个列表。
第二种语法:加入判断语句,只有满足条件的内容才把 iterable 里相应内容放到 iter_var 中,再在表达式中应用该 iter_var 的内容,最后用表达式的计算值生成一个列表。
list_double = [x * x for x in range(1, 11)] print(list_double)
for 循环里面也嵌套 for 循环
list_test = [(x + 1, y + 1) for x in range(3) for y in range(5)] print(list_test) -------------------------------------- [(1, 1), (1, 2), (1, 3), (1, 4), (1, 5), (2, 1), (2, 2), (2, 3), (2, 4), (2, 5), (3, 1), (3, 2), (3, 3), (3, 4), (3, 5)]
list是一种有序的集合,可以随时添加和删除其中的元素。用索引来访问list中每一个位置的元素,记得索引是从0开始的。
列表就是用中括号 [] 括起来的数据,里面的每一个数据就叫做元素。每个元素之间使用逗号分隔,而且列表的数据元素不一定是相同的数据类型。
>>> classmates=['jim','tom','lucy'] >>> classmates ['jim', 'tom', 'lucy'] >>> len(classmates) 3
如果要取最后一个元素,除了计算索引位置外,还可以用-1做索引,直接获取最后一个元素:
>>> classmates[-1] 'lucy'
list是一个可变的有序表,所以,可以往list中追加元素到末尾,可以把元素插入到指定的位置,比如索引号为1的位置。
>>> classmates.append('admin') >>> classmates ['jim', 'tom', 'lucy', 'admin'] >>> classmates.insert(1,'wang') >>> classmates ['jim', 'wang', 'tom', 'lucy', 'admin']
要删除list末尾的元素,用pop()方法,删除指定位置的元素,用pop(i)方法,其中i是索引位置:
>>> classmates ['jim', 'wang', 'tom', 'lucy', 'admin'] >>> classmates.pop() 'admin' >>> classmates.pop(1) 'wang'
把某个元素替换成别的元素,可以直接赋值给对应的索引位置,list里面的元素的数据类型也可以不同
>>> classmates ['jim', 'tom', 'lucy'] >>> classmates[1]=123 #通过索引对列表的数据项进行修改或更新
>>> classmates ['jim', 123, 'lucy']
list元素也可以是另一个list,拿到'php'可以写p[1]或者s[2][1],因此s可以看成是一个二维数组
>>> s=['python','java',['asp','php'],'R'] >>> s[2][1] 'php'
List(列表)运算符
+ 号用于组合列表,* 号用于重复列表
列表中出现数值的次数
data = [randint(0, 20) for _ in range(30)] c = dict.fromkeys(data, 0) for x in data: c[x] += 1 print(c) c1 = Counter(data) print(c1) print(c1.most_common(3))
tuple
tuple一旦初始化就不能修改,代码更安全,如果要定义一个空的tuple,可以写成():
元组创建只需要在括号中添加元素,并使用逗号隔开即可
>>> t=() >>> t () >>> t=(1) >>> t 1
元组中只包含一个元素时,需要在元素后面添加逗号,如果不加逗号,创建出来的就不是 元组(tuple),而是指 123 这个数
tuple4=(123,)
看一个“可变的”tuple:
>>> t=('a','b',['A','B']) >>> t[2][0]='X' >>> t[2][1]='Y' >>> t ('a', 'b', ['X', 'Y'])
tuple定义的时候有3个元素,分别是'a','b'和一个list。不是说tuple一旦定义后就不可变了吗?
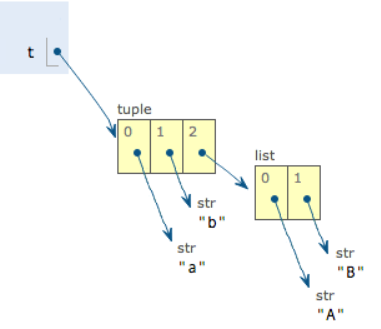
把list的元素'A'和'B'修改为'X'和'Y'后,tuple变为:
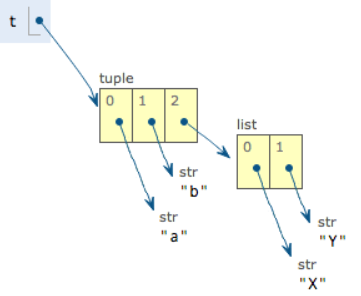
tuple的元素确实变了,但其实变的不是tuple的元素,而是list的元素
使用 + 号和 * 号进行运算
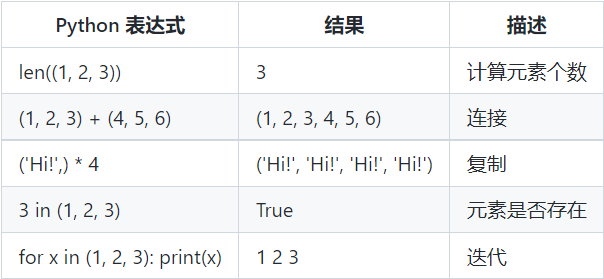
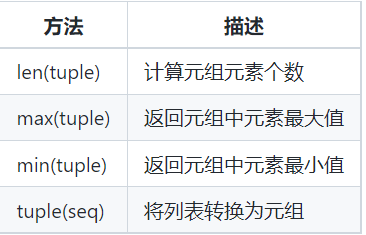
元组元素命名
NAME, AGE, SEX, EMAIL = range(4) student = ("jim", 16, "male", "123@qq.com") print(student[NAME], student[AGE], student[SEX], student[EMAIL])
from collections import namedtuple Student = namedtuple('Student', ['name', 'age', 'sex', 'email']) s = Student('jim', 16, 'male', 'abc@qq.com') print(s.name) print(s.age) print(s.email)
集合
集合的操作符和位操作符有交集,创建一个 set,需要提供一个 list 作为输入集合
def col_op(): a = set([1, 2, 3, 4]) b = {3, 4, 5, 6} c = set([1, 1, 2, 2, 3, 3]) print(c) print(a | b) print(a & b) print(a - b) print(a ^ b) ------------------------------------- {1, 2, 3} {1, 2, 3, 4, 5, 6} {3, 4} {1, 2} {1, 2, 5, 6}
通过 remove(key) 方法可以删除 set 中的元素
set1=set([123,456,789]) print(set1) set1.remove(456) print(set1)
字典
常见的“键-值”(key-value)映射结构,键无重复,一个键不能对应多个值,不过多个键可以指向一个值
a = {'Tom': 8, 'Jerry': 7}
print(a['Tom'])
if 'Tom' in a:
print(a['Tom'])
print(a.get('Jerry'))
a['Jerry'] = 10
print(a.keys(), a.values())
for
for iterating_var in sequence: statements(s)
def if_op(): pets = ['dog', 'cat', 'droid', 'fly'] for pet in pets: if pet == 'dog': food = 'steak' elif pet == 'cat': food = 'milk' elif pet == 'droid': food = 'oil' elif pet == 'fly': food = 'shirt' else: pass print(food)
count = 1 sum = 0 while (count <= 100): sum = sum + count if ( sum > 1000): #当 sum 大于 1000 的时候退出循环 break count = count + 1 print(sum)
列表解析
列表解析(list comprehension)提供一种优雅的生成列表的方法,能用一行代码代替十几行代码,而且不损失任何可读性。而且,性能还快很多
a = [x for x in range(100) if x % 2 == 0]
获取文本中所有单词的第1个字符
text = "My house is full of flowers" a = [word[0] for word in text.split()]
获取两个列表对应位的乘积,zip将a,b对应位打包起来,返回[[2,3][3,4][4,5][5,6]]
a = [2, 3, 4, 5] b = [3, 4, 5, 6] r = [i * j for i, j in zip(a, b)]
带if else的列表解析
a = ['1', '2', '3', 'i', '8'] b = [int(i) if i.isdigit() else None for i in a]
字典的列表解析
a = {x: randint(60, 100) for x in range(1, 21)}
b = {k: v for k, v in a.items() if v > 90}
集合列表解析
data = [2, 3, -6, 9, 12, 1, 5, 7] b = set(data) c = {x for x in b if x % 3 == 0}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号