

17、match_phrase query 短语匹配搜索
实现两个需求:
- java spark,就靠在一起,中间不能插入任何其他字符,就要搜索出来这种doc
- java spark,但是要求,java和spark两个单词靠的越近,doc的分数越高,排名越靠前
要实现上述两个需求,用match做全文检索,是不行的,必须得用proximity match,近似匹配
phrase match:短语匹配
proximity match:近似匹配
match phrase query,就是要去将多个term作为一个短语,一起去搜索,只有包含这个短语的doc才会作为结果返回
添加数据
POST /forum/_update/5 { "doc":{ "articleID" : "XHDK-A-1293-#fJ3", "userID" : 1, "hidden": false, "postDate": "2017-01-01", "content":"spark is best big data solution based on scala ,an programming language similar to java spark" } }
短语查询
GET /forum/_search { "query":{ "match_phrase": { "content": "java spark" } } }
term position
分词后,每个单词就是一个term,分词后 , es还记录了 每个field的位置。
举个例子 两个doc 如下:
hello world, java spark doc1
hi, spark java doc2
建立倒排索引后
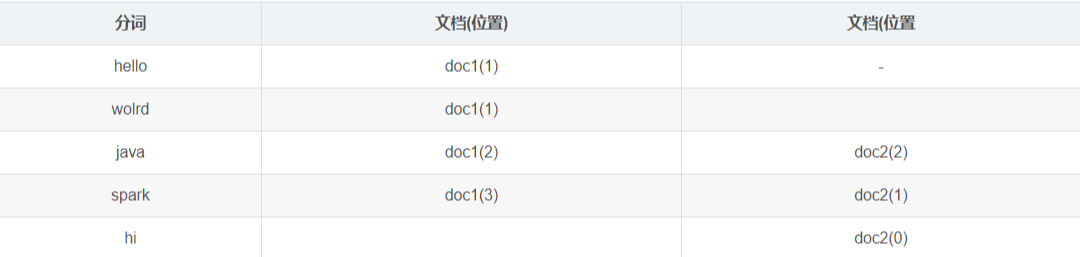
通过如下API来看下
GET _analyze { "text": "hello world, java spark", "analyzer": "standard" }
返回
{ "tokens": [ { "token": "hello", "start_offset": 0, "end_offset": 5, "type": "<ALPHANUM>", "position": 0 }, { "token": "world", "start_offset": 6, "end_offset": 11, "type": "<ALPHANUM>", "position": 1 }, { "token": "java", "start_offset": 13, "end_offset": 17, "type": "<ALPHANUM>", "position": 2 }, { "token": "spark", "start_offset": 18, "end_offset": 23, "type": "<ALPHANUM>", "position": 3 } ] }
match phrase的原理
首先 java spark 被拆成 java和spark ,分别取索引中查找
java 出现在 doc1(2) doc2(2)
spark 出现在 doc1(3) doc2(1)
每个term都在的一个共有的那些doc,就是要求一个doc,必须包含每个term,才能拿出来继续计算
doc1 --> java和spark --> spark position恰巧比java大1 --> java的position是2,spark的position是3,恰好满足条件
doc1符合条件
doc2 --> java和spark --> java position是2,spark position是1,spark position比java position小1,而不是大1 --> 光是position就不满足,那么doc2不匹配 .
立志如山 静心求实

 浙公网安备 33010602011771号
浙公网安备 33010602011771号