
RabbitMQ集群
RabbitMQ这款消息队列中间件产品本身是基于Erlang编写,Erlang语言天生具备分布式特性(通过同步Erlang集群各节点的magic cookie来实现)。因此,RabbitMQ天然支持Clustering。这使得RabbitMQ本身不需要像ActiveMQ、Kafka那样通过ZooKeeper分别来实现HA方案和保存集群的元数据。集群是保证可靠性的一种方式,同时可以通过水平扩展以达到增加消息吞吐量能力的目的。 RabbitMQ集群的整体方案:
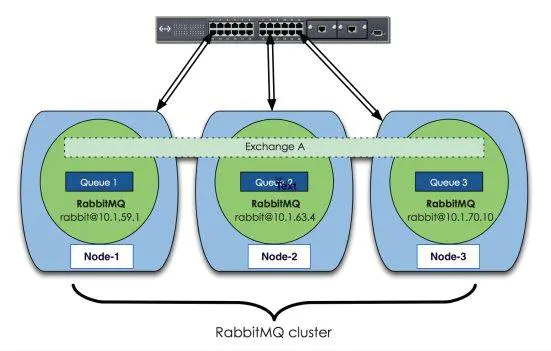
采用三个节点组成了一个RabbitMQ的集群,Exchange A(交换器)的元数据信息在所有节点上是一致的,而Queue(存放消息的队列)的完整数据则只会存在于它所创建的那个节点上。,其他节点只知道这个queue的metadata信息和一个指向queue的owner node的指针。
RabbitMQ集群元数据的同步
RabbitMQ集群会始终同步四种类型的内部元数据(类似索引):
a.队列元数据:队列名称和它的属性;
b.交换器元数据:交换器名称、类型和属性;
c.绑定元数据:一张简单的表格展示如何将消息路由到队列;
d.vhost元数据:为vhost内的队列、交换器和绑定提供命名空间和安全属性;
因此,当用户访问其中任何一个RabbitMQ节点时,通过rabbitmqctl查询到的queue/user/exchange/vhost等信息都是相同的。
为何RabbitMQ集群仅采用元数据同步的方式
实现HA方案,将RabbitMQ集群中的所有Queue的完整数据在所有节点上都保存一份不就可以了么?(可以类似MySQL的主主模式嘛)这样子,任何一个节点出现故障或者宕机不可用时,那么使用者的客户端只要能连接至其他节点能够照常完成消息的发布和订阅嘛。
RabbitMQ的作者这么设计主要还是基于集群本身的性能和存储空间上来考虑。第一,存储空间,如果每个集群节点都拥有所有Queue的完全数据拷贝,那么每个节点的存储空间会非常大,集群的消息积压能力会非常弱(无法通过集群节点的扩容提高消息积压能力);第二,性能,消息的发布者需要将消息复制到每一个集群节点,对于持久化消息,网络和磁盘同步复制的开销都会明显增加。
RabbitMQ集群发送/订阅消息的基本原理
RabbitMQ集群的工作原理图如下:
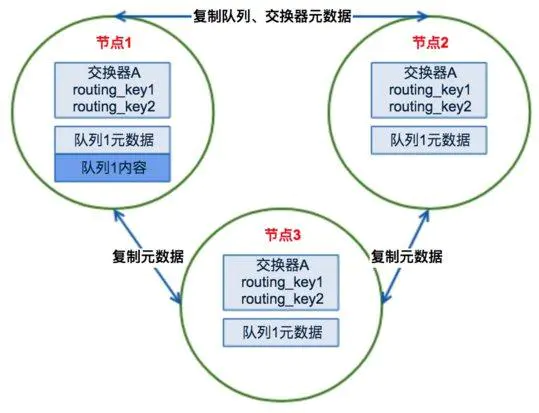
场景1、客户端直接连接队列所在节点
如果有一个消息生产者或者消息消费者通过amqp-client的客户端连接至节点1进行消息的发布或者订阅,此时的集群中的消息收发只与节点1相关,这个没有任何问题;如果客户端相连的是节点2或者节点3(队列1数据不在该节点上),那么情况又会是怎么样呢?
场景2、客户端连接的是非队列数据所在节点
如果消息生产者所连接的是节点2或者节点3,此时队列1的完整数据不在该两个节点上,那么在发送消息过程中这两个节点主要起了一个路由转发作用,根据这两个节点上的元数据(也就是上文提到的:指向queue的owner node的指针)转发至节点1上,最终发送的消息还是会存储至节点1的队列1上。
同样,如果消息消费者所连接的节点2或者节点3,那这两个节点也会作为路由节点起到转发作用,将会从节点1的队列1中拉取消息进行消费。
RabbitMQ集群的搭建
a.编辑每台RabbitMQ的cookie文件,以确保各个节点的cookie文件使用的是同一个值,可以scp其中一台机器上的cookie至其他各个节点,cookie的默认路径为/var/lib/rabbitmq/.erlang.cookie或者$HOME/.erlang.cookie,节点之间通过cookie确定相互是否可通信。
192.168.21.128 node_master 192.168.21.120 node_slave 192.168.21.29 node_slave
c.逐个节点启动RabbitMQ服务
rabbitmq-server -detached
d.查看各个节点和集群的工作运行状态
rabbitmqctl status, rabbitmqctl cluster_status
e.以node_master为主节点,在node_slave上:
rabbitmqctl stop_app rabbitmqctl reset rabbitmqctl join_cluster rabbit@rmq-broker-test-2 rabbitmqctl start_app
d.在RabbitMQ集群中的节点只有两种类型:内存节点/磁盘节点,单节点系统只运行磁盘类型的节点。而在集群中,可以选择配置部分节点为内存节点
#加入时候设置节点为内存节点(默认加入的为磁盘节点) [root@mq-testvm1 ~]# rabbitmqctl join_cluster rabbit@rmq-broker-test-1 --ram
#也通过下面方式修改的节点的类型
[root@mq-testvm1 ~]# rabbitmqctl changeclusternode_type disc | ram镜像模式
任意rabbit节点输入命令,将所有队列,同步到所有节点中
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
abbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority] -p Vhost: 可选参数,针对指定vhost下的queue进行设置 Name: policy的名称 Pattern: queue的匹配模式(正则表达式) ^my:为匹配符,只有一个^代表匹配所有,^abc为匹配名称以abc开头的queue或exchange; Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes all:表示在集群中所有的节点上进行镜像 exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定 nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定 ha-params:ha-mode模式需要用到的参数 ha-sync-mode:进行队列中消息的同步方式,有效值为automatic和manual priority:可选参数,policy的优先级 # ha-mode:为同步模式,一共3种模式: # ①all-所有(所有的节点都同步消息), # ②exctly-指定节点的数目(需配置ha-params参数,此参数为int类型比如2,在集群中随机抽取2个节点同步消息) # ③nodes-指定具体节点(需配置ha-params参数,此参数为数组类型比如["rabbit@rabbitmq1","rabbit@rabbitmq2"],明确指定在这两个节点上同步消息)。
配置HAProxy
HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。根据官方数据,其最高极限支持10G的并发。HAProxy支持从4层至7层的网络交换,即覆盖所有的TCP协议。就是说,Haproxy 甚至还支持 Mysql 的均衡负载。为了实现RabbitMQ集群的软负载均衡,这里可以选择HAProxy。
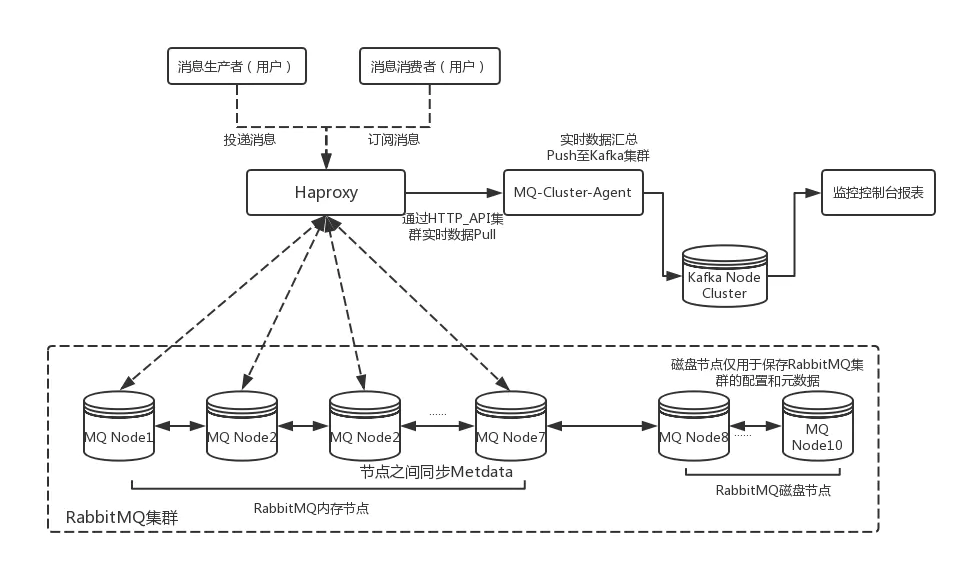
RabbitMQ节点集群搭建和HAProxy软弹性负载均衡配置后即可组建一个中小规模的RabbitMQ集群,然而为了能够在实际的生产环境使用还需要根据实际的业务需求对集群中的各个实例进行一些性能参数指标的监控,从性能、吞吐量和消息堆积能力等角度考虑,可以选择Kafka来作为RabbitMQ集群的监控队列使用。因此,先给出了一个中小规模RabbitMQ集群架构设计图:
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号