

1.注册中国大学MOOC
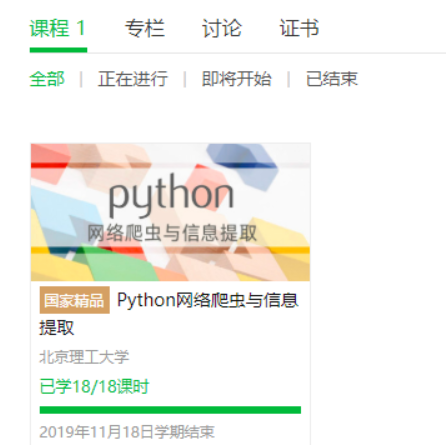
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
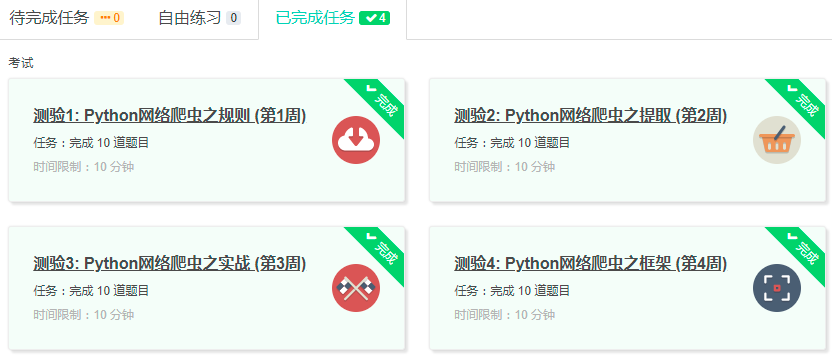
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
学习笔记:
大三刚接触到python这门课的时候,对于网络爬虫了解算是止于皮毛,只明白了爬虫是一种按照一定的规则,可以自动地抓取万维网信息的程序或者脚本,被广泛用于互联网搜索引擎,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。这次通过鄂大伟老师的推荐,学习了《Python网络爬虫与信息提取》这门网络课程,让我体会到了python第三方库的强大,也让我对网络爬虫有了更深的认识。
这门课程介绍Python计算生态中最优秀的网络数据爬取和解析技术,具体讲授构建网络爬虫功能的两条重要技术路线:requests-bs4-re和Scrapy,课程内容是进入大数据处理、数据挖掘、以数据为中心人工智能领域的必备实践基础。教学内容包括:Python第三方库Requests,讲解通过HTTP/HTTPS协议自动从互联网获取数据并向其提交请求的方法;Python第三方库Beautiful Soup,讲解从所爬取HTML页面中解析完整Web信息的方法;Python标准库Re,讲解从所爬取HTML页面中提取关键信息的方法;python第三方库Scrapy,介绍通过网络爬虫框架构造专业网络爬虫的基本方法。
在网络爬虫之提取中,Beautiful Soup库是解析、遍历、维护“标签树”的功能库,bs4提供了5种基本元素和3种遍历功能。标记后的信息可形成信息组织结构,增加信息维度,可用于用于通信、存储,更利于程序的理解和运用。信息标记有XML、JSON、YAML三种形式,。介绍了信息提取的一般方法:1.完整解析信息的标记形式,在提取关键信息。2.无视标记形式,直接搜索关键信息。融合方法:结合形式解析与搜索方法,提取关键信息。在网络爬虫之实战中,学习了正则表达式,是用来简洁表达一组字符串的表达式。认识了正则表达式的常用操作符。Re库是python的标准库,主要用于字符串匹配。Re库的函数调用有两种方式,一种是直接加上方法名调用,还有一种是先将函数编译成正则表达式对象,再用正则表达式对象调用函数。Re库的Match对象,是一次匹配的结果,包含匹配的很多信息。在网络爬虫之框架中,认识到爬虫框架是实现爬虫功能的一个软件结构和功能组件集合,爬虫框架是一个半成品,能够帮助用户实现专业文理爬虫,包括了“5+2”结构。学习到了Scrapy命令行的使用。Scrapy与requests比较,Scrapy是网站级爬虫,并发性好,性能较高,重点在于爬虫结构,但入门稍难。
嵩天老师的教学方法是先给学生讲授概念性的知识,再通过实战演练让我们加深记忆。让我留下深刻印象的是学习正则表达式的时候,因为需要记忆知识点有点多,所以我遇见了一些问题。正则表达式语法由字符和操作符组成,我自己写了一些例子,在开始的时候多次碰到关于“/”与“\”写错了的事情,这一方面是自己键盘使用习惯问题,一方面也是自己对这两个符号的理解不够透彻。经过摸索学习我总结了以下内容:“/”是分隔符号,/一般用于正则表达的开始和结束,“\”用于在中途使用,起转义作用;并且如果一个“\”后出现一个字符,并且不是可以转义的字符,那么“\”及其后面的字符不会被转义。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号