自然语言处理3-3:文本表示之tf-idf
传统的count-base representation有什么问题呢,可以看下图

观察句式2,其对应的向量中he所在位置的元素值是2,因为he在原句中出现了2次。可是,he在这一句中,并不算是关键词,事实上,denied和lied才是句子2的关键词,但是他们只出现了一次,所以在向量中对应位置的元素值是1。这么看来,count-base representation生成的向量并不能很好的反映关键词信息,这也会给句子计算相似度造成误判。毕竟数值越大,对相似度的计算产生的作用就越大。那么,有什么方法,可以把关键词给反映出来呢?
其实仔细一想,he之所以不能算作关键词,是因为he这个词语太常用了,基本上每篇文章都会遇到。而对应的,denied和lied就没有he这么常用。所以,我们可以在原来的向量的基础上乘以一个数,这个数可以反映该单词的常用程度。如果该单词非常常用,那么数值就很小,如果不常用,说明他是句子中的关键词,那么数值就很大。这样,就有了下面的公式。其中tf(d,w)就是count-base representation,其反映的是某个单词在文本(句子)中出现的次数。而idf(w)反映的就是该单词的常用程度,N是文本总数,N(w)是包含单词w的文本数。这样的话,若单词越常用,则N(w)越大,那么idf(w)就会越小。
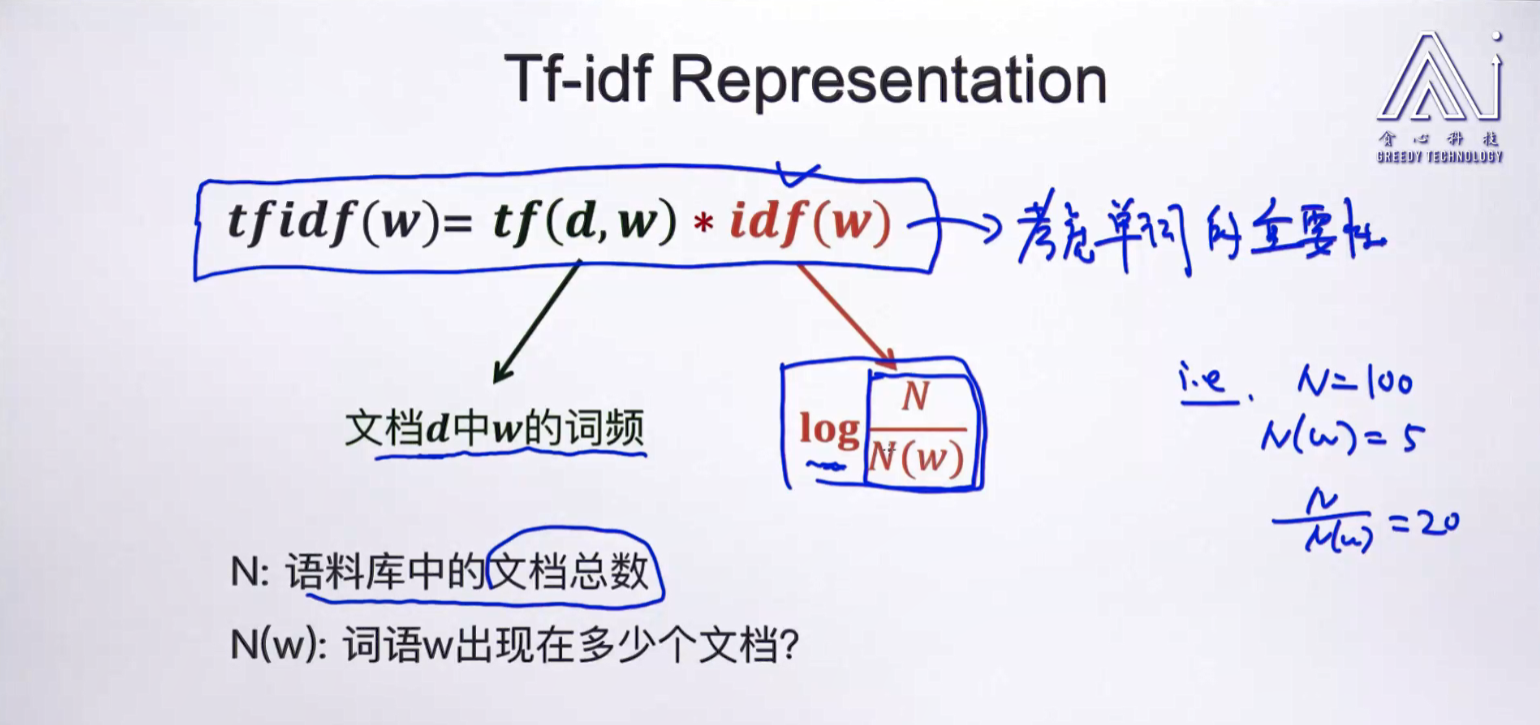
下面是一个例子


 浙公网安备 33010602011771号
浙公网安备 33010602011771号