2023腾讯游戏安全mobile端初赛wp
绕过一些简单的检测
-
绕过端口检测。
app对 27042 与23946端口有检测。frida换个启动端口即可。./frida-server-16.1.10-android-arm64 -l 0.0.0.0:1234 adb forward tcp:1234 tcp:1234IDA也换个调试端口./android_server64 -p 23947 adb forward tcp:23947 tcp:23947 -
绕过
ida_server的检测。app会检测/data/local/tmp目录下有无android_server64等文件。我们直接把
android_server64换个位置即可。
Il2CppDumper dump
https://github.com/Perfare/Il2CppDumper
正常情况下 运行下面命令即可
Il2CppDumper.exe .\libil2cpp.so .\global-metadata.dat <output-directory>
但对于这道题目,我们没有dump到相关文件
查看 global-metadata.dat的16进制内容,可以发现,内容很正常,没用被加密的迹象
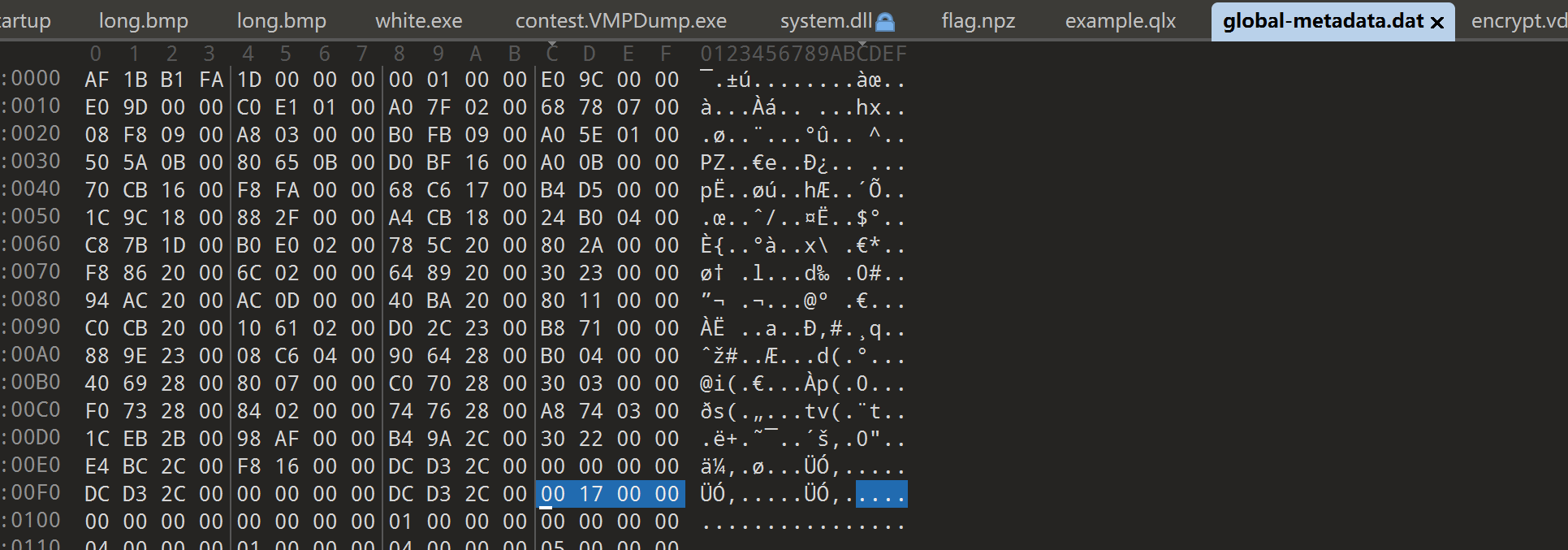
再看一下 libil2cpp.so的反汇编,可以发现libil2cpp.so中大部分逻辑被加密了,这也是为什么我们用 Il2CppDumper.exe dump不出来 相关文件的原因。
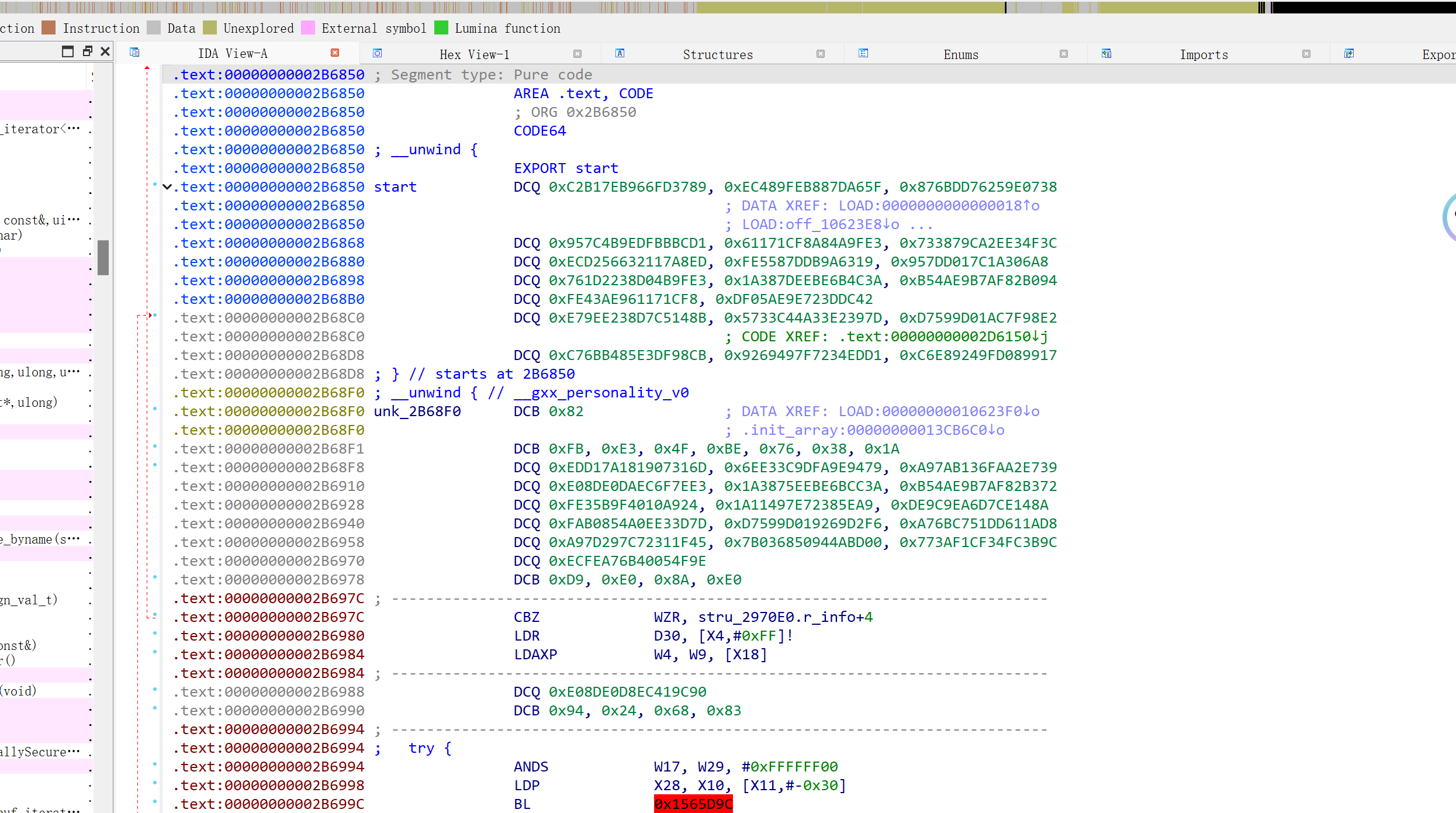
libil2cpp.so文件势必会在app运行时被解密,我们用frida在内存中抓取 libil2cpp.so即可。
frida抓取脚本:
let dump_so_name = "libil2cpp.so"
function dumpso(){
try{
let modu=Process.getModuleByName(dump_so_name)
var base_addr = modu.base
var base_size = modu.size
if (modu){
console.log("name: " +modu.name);
console.log("base: " +base_addr);
console.log("size: " +"0x"+base_size.toString(16));
// filter unmaping range
// filter addr between base,base+size
var file_path = "/data/data/com.com.sec2023.rocketmouse.mouse/" + modu.name + "_" + modu.base + ".so";
var all_size = 0
var range_arry = Process.enumerateRanges("r")
var file_handle = new File(file_path, "wb");
range_arry.forEach(range => {
if ( (parseInt(range.base,16) >= parseInt(base_addr)) && (parseInt(range.base,16) <= parseInt(base_addr) + base_size )){
// console.log
all_size += range.size
var libso_buffer = ptr(range.base).readByteArray(range.size);
file_handle.write(libso_buffer);
file_handle.flush();
console.log(`[+] ${range.base}-${"0x" + range.size.toString(16)}-${range.protection}`)
}
})
file_handle.close();
console.log("[dump_size]:", "0x" + all_size.toString(16));
console.log("[dump]:", file_path);
}else{
console.log('[x] ' + dump_so_name +'not found');
}
}catch(e){
console.log("dump so error \t" + e)
}
}
function hook_dlopen() {
var dlopen = Module.findExportByName(null, "dlopen");
Interceptor.attach(dlopen, {
onEnter: function (args) {
this.call_hook = false;
var so_name = ptr(args[0]).readCString();
if (so_name.indexOf(dump_so_name) >= 0) {
console.log("dlopen:", ptr(args[0]).readCString());
this.call_hook = true;
}
}, onLeave: function (retval) {
if (this.call_hook) {
dumpso();
}
}
});
}
hook_dlopen();
抓取之后,可以看到.so文件已经被解密了。
不过由于dump出来的.so文件没有分段,我们直接把 dump出来的.so patch到被加密的 .so文件中。
idapython脚本如下:
# import idc
# begin = 0x0000000002B6850
# end = 0x0000000013CB778
# data = idc.get_bytes(begin,end-begin)
# fp = open(r"D:\tlsn\BTools\RE\APK Easy Tool v1.60 Portable\1-Decompiled APKs\mouse_pre.aligned.signed\assets\bin\Data\Managed\Metadata\get_data","wb")
# fp.write(data)
# fp.close()
# print("finish")
import idc
import ida_bytes
begin = 0x0000000002B6850
end = 0x0000000013CB778
fp = open(r"D:\tlsn\BTools\RE\APK Easy Tool v1.60 Portable\1-Decompiled APKs\mouse_pre.aligned.signed\assets\bin\Data\Managed\Metadata\get_data","rb")
data = fp.read()
# for i in range(begin,end):
# idc.patch_byte(i,data[i-begin])
ida_bytes.patch_bytes(begin,data)
print("finish")
import idc
import idaapi
def upc(begin,end):
for i in range(begin,end):
idc.del_items(i)
for i in range(begin,end):
idc.create_insn(i)
for i in range(begin,end):
idaapi.add_func(i)
print("Finish!!!")
begin = 0x0000000002B6850
end = 0x000000000C4E42C
upc(begin,end)
接下来,使用Il2CppDumper可以直接dump出相关文件
Il2CppDumper.exe .\libil2cpp.so .\global-metadata.dat <output-directory>
全部导入ida中,即可恢复libil2cpp.so的大部分符号
逆向分析 libil2cpp.so 文件
在dump.cs中搜索 Assembly-CSharp.dll,即可找到所有关键逻辑的类与相关地址偏移。
dump.cs中直接搜 coin ,可以直接定位到这个函数:

一看就是在比较金币的数量
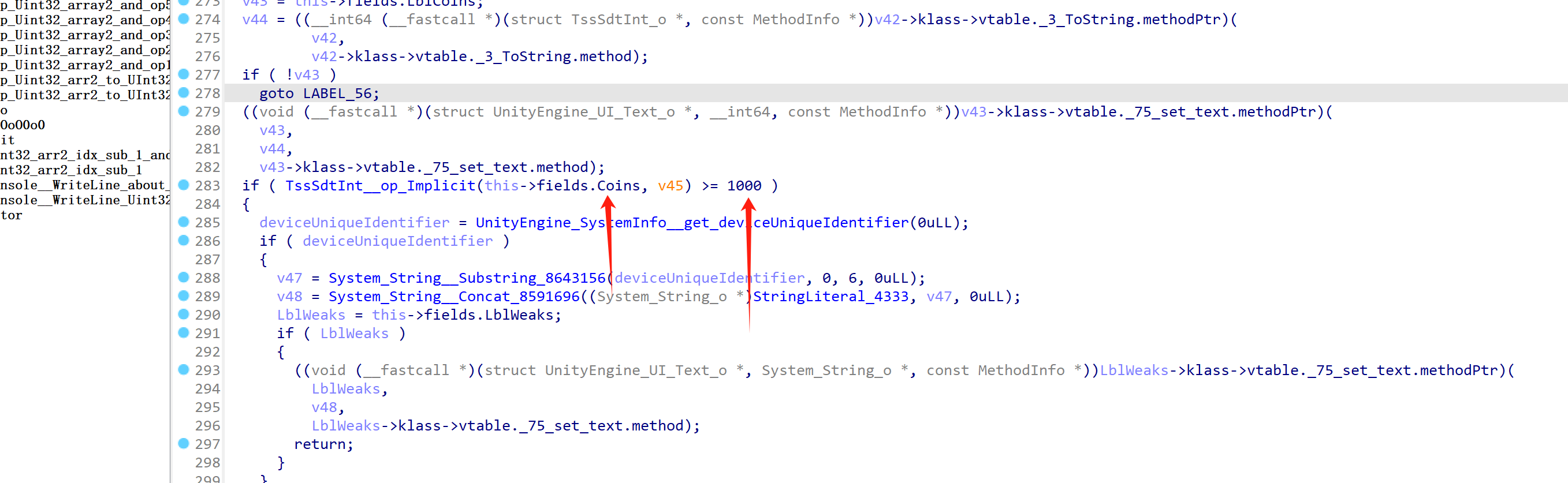
我们直接 hook 内存,修改以下金币数目,即可那道flag:
frda脚本如下:
// 0x0000000004653CC: cmp 1000
var offset = 0x0000000004653C8
var baseAddr = Module.findBaseAddress("libil2cpp.so")
console.log(baseAddr)
Interceptor.attach(ptr(baseAddr).add(offset), {
onEnter: function(args){
var TssSdtInt = this.context.x0 // TssSdtInt Coins;
var m_slot = TssSdtInt.add(0x10).readPointer() // private TssSdtIntSlot m_slot; // 0x10
var m_value = m_slot.add(0x10).readPointer() // private Int32[] m_value; // 0x10 // System_Int32_array
var m_xor_key = m_slot.add(0x10+8).readU32() // private Int32 m_xor_key; // 0x18
var m_index = m_slot.add(0x10+0xc).readU32() // private Int32 m_index; // 0x1c
console.log("````````````````````````````````````````````````")
// console.log(m_value)
// console.log(m_xor_key)
// console.log(m_index)
// return this->fields.m_xor_key ^ m_value->m_Items[m_index];
var m_idx_val = m_value.add(0x20 + m_index * 4).readU32()
var real_val = m_idx_val ^ m_xor_key
console.log(real_val)
// change m_value->m_Items[m_index];
var m_idx_val_addr = m_value.add(0x20 + m_index * 4)
var new_val = 1000
var enc_new_val = new_val ^ m_xor_key
ptr(m_idx_val_addr).writeU32(enc_new_val)
},
onLeave: function(retval){
}
});
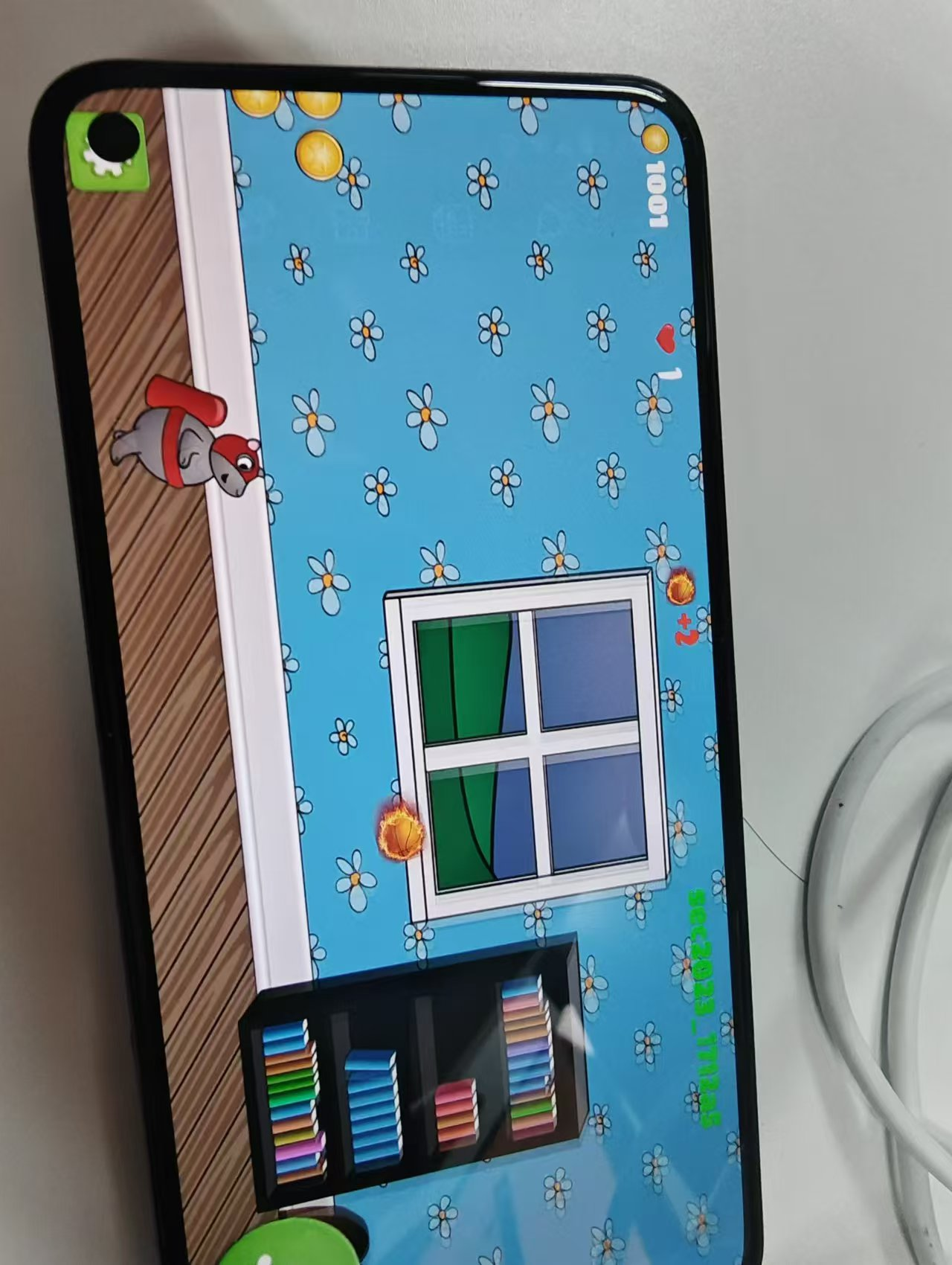
继续逆向,可以找到一个叫做 SmallKeyboard的类:

用frida hook SmallKeyboard类的相关函数,通过解析结构体参数,可以得到以下相关信息:
iI1Ii函数会在按键抬起的时候触发。iI1Ii函数会在按键按下的时候触发。iI1Ii函数会在我们按下 ok 后触发,猜测是check函数。oO0oOo0函数功能是生成token。oO0oOoO函数的功能是获取token的值。oO0o0o0字段保存的是token的值。iIIIi字段保存的是我们所有的输入。
frida hook 脚本如下:
let dump_so_name = "libil2cpp.so"
var baseAddr = Module.findBaseAddress("libil2cpp.so")
console.log("libil2cpp_base_addr: " + baseAddr)
/*
struct System_String_o
{
System_String_c *klass;
void *monitor;
System_String_Fields fields;
};
struct System_String_Fields
{
int32_t _stringLength;
uint16_t _firstChar;
};
*/
function parseSystemString(addr){
try{
var _stringLength = ptr(addr).add(0x10).readU32();
var string_real_addr = ptr(addr).add(0x10+4)
var string_val = string_real_addr.readUtf16String(_stringLength)
return string_val
}catch(e){
console.log("parseSystemString throw:\t" + e)
}
}
function parse_iII1i(addr){
var KeyType = ptr(addr).add(0x18).readPointer()
var SValue = ptr(addr).add(0x20).readPointer()
// console.log(SValue)
var RSvalue = parseSystemString(SValue)
return RSvalue
}
function hook_SmallKeyboard(){
try{ // hook_list[0]处理up、[1]处理press、[2]处理 ok
var hook_list = [0x465880,0x465fdc,0x465e90] // 0 => up // 1=>press // 2 -> ok
for(var i = 0;i<hook_list.length;i++){
var addr = hook_list[i]
const idx = i
Interceptor.attach(ptr(addr).add(baseAddr), {
onEnter: function(args){
// console.log(idx)
if (idx == 0){ // key board
console.log("###############################")
// var _info = args[1] // iII1i _info
// var RSvalue = parse_iII1i(_info)
// console.log("iII1i\t" + RSvalue)
var SmallKeyboard_this = args[0]
var strInput = SmallKeyboard_this.add(0x18).readPointer()
var oO0o0o0 = SmallKeyboard_this.add(0x38).readPointer()
var iIIIi = SmallKeyboard_this.add(0x40).readPointer()
var real_strInput = parseSystemString(strInput)
var real_oO0o0o0 = parseSystemString(oO0o0o0)
console.log(iIIIi)
var real_iIIIi = parseSystemString(iIIIi)
console.log("strInput:\t" + real_strInput)
console.log("oO0o0o0:\t" + real_oO0o0o0) // 这个实际上就是生成的token值
console.log("iIIIi:\t" + real_iIIIi) // 这个实际上是我们已经输入的值
}else if(idx == 2){ // 这个函数是我们键入 ok 后调用的
var SmallKeyboard_this = args[0]
var uint64_t_i1I = args[1]
console.log(uint64_t_i1I)
}
},
onLeave: function(retval){
}
});
}
}catch(e){
console.log("hook_SmallKeyboard throw:\t" + e)
}
}
function parse_Int32(addr){
var m_value = ptr(addr).add(0x10).readU32()
return m_value
}
function hook_generate_token(){
try{
// var offset = 0x000000000465F58 // hook x0
// Interceptor.attach(ptr(baseAddr).add(offset), {
// onEnter: function(args){
// var token_int = this.context.x0 // TssSdtInt Coins;
// var m_value = parse_Int32(token_int)
// console.log("````````````````````````````````````````````````")
// console.log(m_value)
// },
// onLeave: function(retval){
// }
// });
/*
var offset = 0x000000000831950 // 挂钩System_String__Concat_8591696函数
Interceptor.attach(ptr(baseAddr).add(offset), {
onEnter: function(args){
this.token = args[0]
this.str1 = args[1]
},
onLeave: function(retval){
console.log(`${parseSystemString(this.token)} +Connect+ ${parseSystemString(this.str1)} ==> ${parseSystemString(retval)}`)
}
});
// sResult = +Connect+ 1253 ==> sResult = 1253
// +Connect+ 2 ==> 2
// 2 +Connect+ 2 ==> 22
// 22 +Connect+ 7 ==> 227
// 227 +Connect+ 3 ==> 2273
// 2273 +Connect+ 7 ==> 22737
// 22737 +Connect+ 7 ==> 227377
// 227377 +Connect+ 2 ==> 2273772
// 2273772 +Connect+ 4 ==> 22737724
// TOKEN: +Connect+ 22737724 ==> TOKEN: 22737724
*/
}catch(e){
console.log(e)
}
}
hook_SmallKeyboard()
hook_generate_token()
挂钩 0x000000000465F4C处的地址,hook x9寄存器,可以得到 generate token的核心代码,实际上是 0x934510 地址处的随机数生成函数。
function hook_6_Next_vatble_addr(){
try{
var offset = 0x000000000465F4C // 挂钩 v5->klass->vtable._6_Next.methodPtr ==> 0x6f3654d510 - 0x6f35c19000 => 0x934510
Interceptor.attach(ptr(baseAddr).add(offset), {
onEnter: function(args){
var addr_ = this.context.x9
console.log(addr_)
},
onLeave: function(retval){
}
});
}catch(e){
console.log("hook_6_Next_vatble_addr throw:\t" + e)
}
}
在分析 SmallKeyboard的check函数的时候,可以分析,其跳转到了代码数据0的地方,很神奇,猜测是程序在运行时才动态填充这个代码段数据。暂时不管。

下面hook这个类
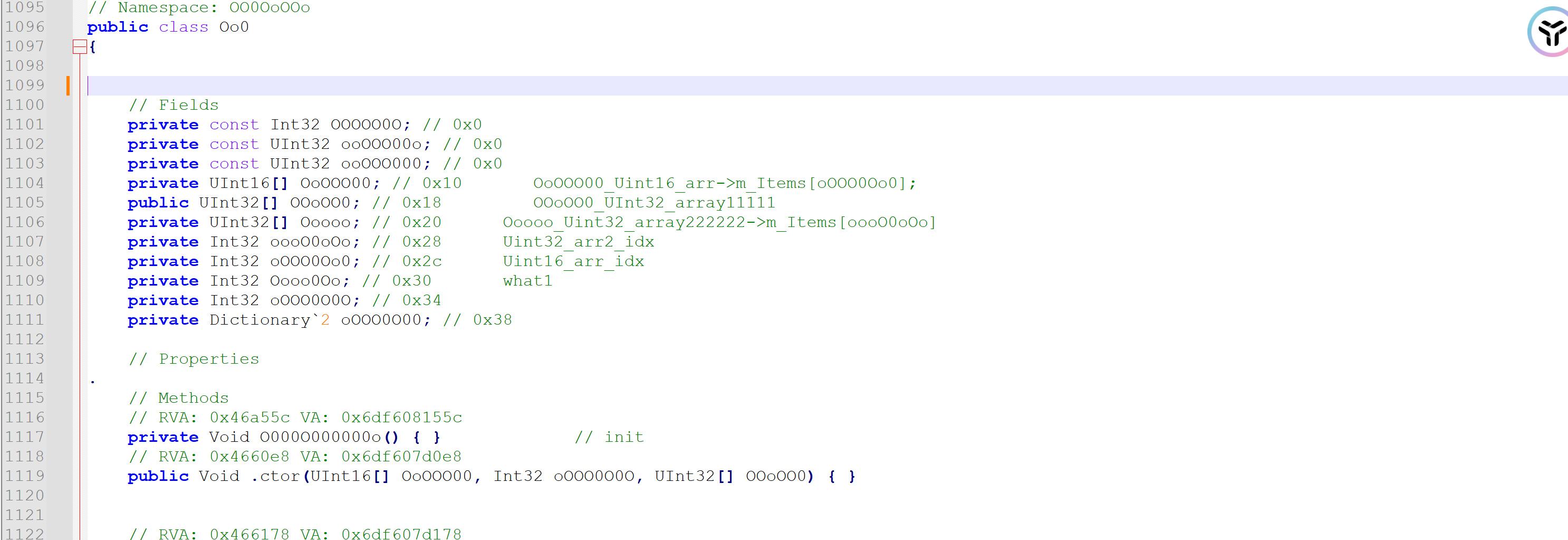
钩住其所有函数,然后栈回溯,事实上能跟到 这个函数:0x000000000465AB4
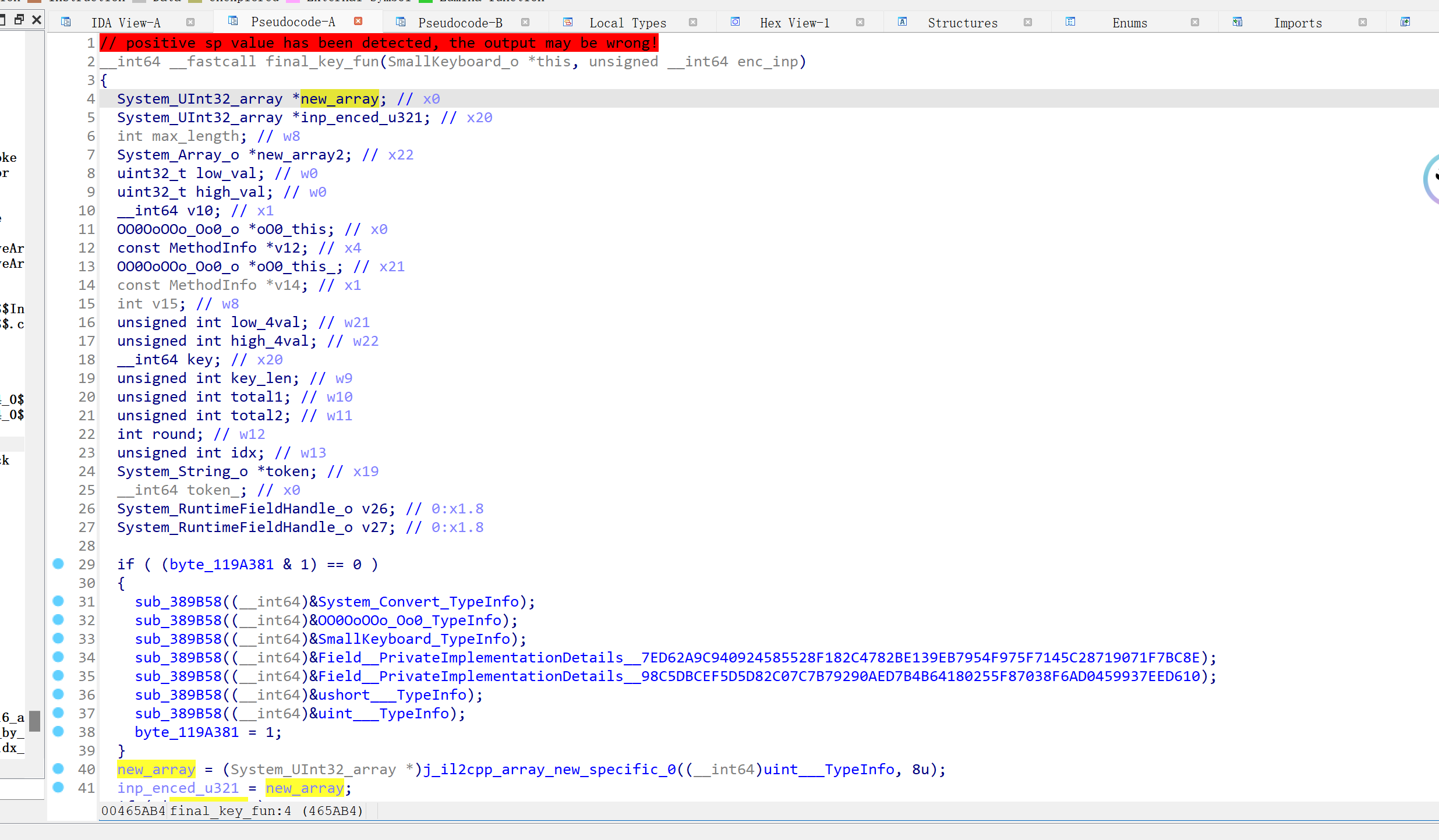
/*
struct System_UInt16_array
{
Il2CppObject obj;
Il2CppArrayBounds *bounds;
il2cpp_array_size_t max_length;
uint16_t m_Items[65535];
};
*/
function parse_System_UInt16_array(addr){
var m_item_addr = ptr(addr).add(0x20)
console.log(hexdump(m_item_addr, { offset: 0, length: 0x50, header: true, ansi: true }));
}
function parse_System_UInt32_array(addr){
var m_item_addr = ptr(addr).add(0x20)
console.log(hexdump(m_item_addr, { offset: 0, length: 0x50, header: true, ansi: true }));
}
function stack_backstace(your_this){
console.log('stack backtrace:\n' +
Thread.backtrace(your_this.context, Backtracer.ACCURATE)
.map(DebugSymbol.fromAddress).join('\n') + '\n');
}
function hook_Oo0(){
var hook_list = [
0x46a55c,0x4660e8,0x466178,0x46ad44,0x46ae50,0x46aecc,0x46af44,0x46afc4,0x46b040,0x46b0bc,0x46b13c,0x46b1c4,
0x46b228,0x46b28c,0x46b2c4,0x46b32c,0x46b394,0x46b3f8,0x46b478,0x46b4e8,0x46b568,0x46b578,0x46b5dc,0x46b664
]
for(var i = 0;i<hook_list.length;i++){
const addr = hook_list[i]
const idx = i
Interceptor.attach(ptr(baseAddr).add(addr),{
onEnter: function(args){
// console.log("``````````````````````````````````````````````````````")
// console.log(`Enter: ${idx} ==> ${"0x" + addr.toString(16)}`)
// hook all fields
// var this_Oo0 = args[0]
// var OoOOO00_Uint16_array = this_Oo0.add(0x10).readPointer()
// var OOoOO0_UInt32_array11111 = this_Oo0.add(0x18).readPointer()
// var Ooooo_Uint32_array222222 = this_Oo0.add(0x20).readPointer()
// var Uint32_arr2_idx = this_Oo0.add(0x28).readU32()
// var Uint16_arr_idx = this_Oo0.add(0x2c).readU32()
// var Oooo0Oo_Int32 = this_Oo0.add(0x30).readU32()
// var oOOO0O0O_Int32 = this_Oo0.add(0x34).readU32()
stack_backstace(this)
// if (addr == 0x4660e8){
// var OoOOO00_Uint16 = args[1]
// var what1 = args[2]
// var OOoOO0_UInt32_array1 = args[3]
// parse_System_UInt16_array(OoOOO00_Uint16)
// console.log(what1)
// parse_System_UInt32_array(OOoOO0_UInt32_array1) // fa 17 d8 10 e4 17 af 93
// }
// if(addr == 0x000000000465998){
// var our_inp = this.context.x1
// var X0_this = this.context.x0
// console.log("our_inp:\t" + our_inp)
// console.log("X0_this:\t" + X0_this)
// }
// if(addr == 0x000000000465AB4){
// var arg1 = args[0]
// var arg2 = args[1]
// // guess string and uint64
// // var str1 = parseSystemString(arg1);
// var big_int = arg2
// console.log("arg1:\t"+ arg1) // 这是this指针,x0寄存器
// console.log("arg2:\t"+ big_int) // 这是 加密后的big_int,x1寄存器
// var x1_val = this.context.x1
// console.log("x1_val:\t" + x1_val)
// }
},
onLeave: function(retval){
// console.log(`Leave : ${idx} ==> ${"0x" + addr.toString(16)}`)
}
})
}
}
再栈回溯这个函数 (0x000000000465AB4) 可以跟到这样的调用链:
libil2cpp.so+0x46599C
==> libsec2023.so+0x0311A0
==> libil2cpp.so+0x0465AB4
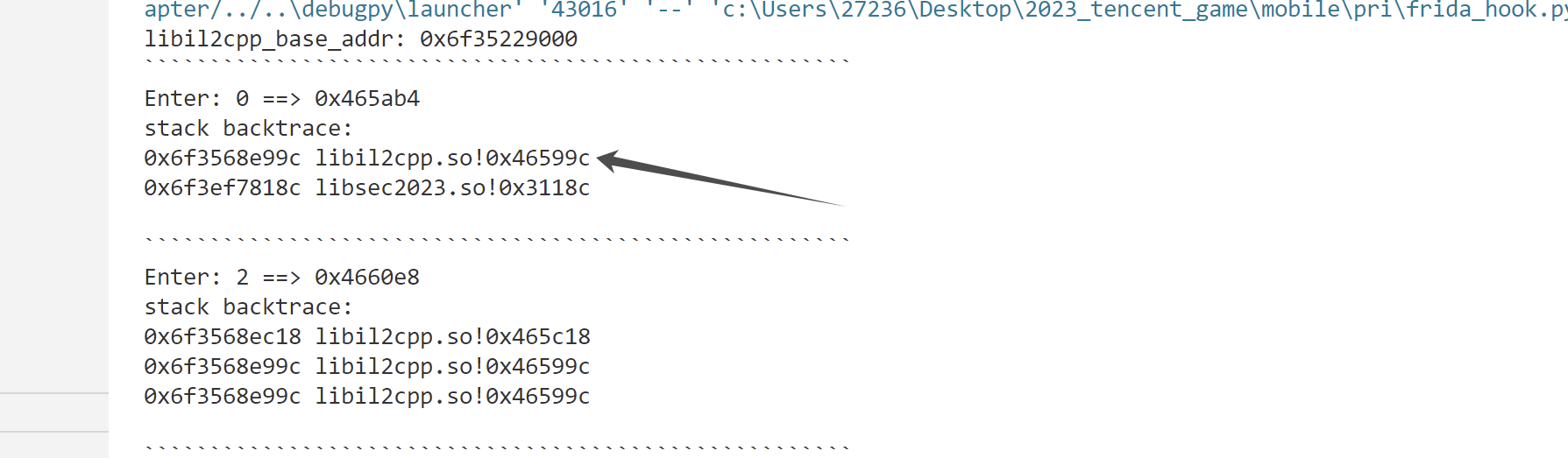
这其实就是check函数的执行流程,如果你能手动改一下参数类型,就能在 libil2cpp.so+0x0465AB4 的函数中看到最后的比较

逆向分析 libil2cpp.so 的算法
vm算法
前面hook了 Oo0 类中的函数,实际上 Oo0类自己实现了一个虚拟机,用来加密输入。
就像这样:
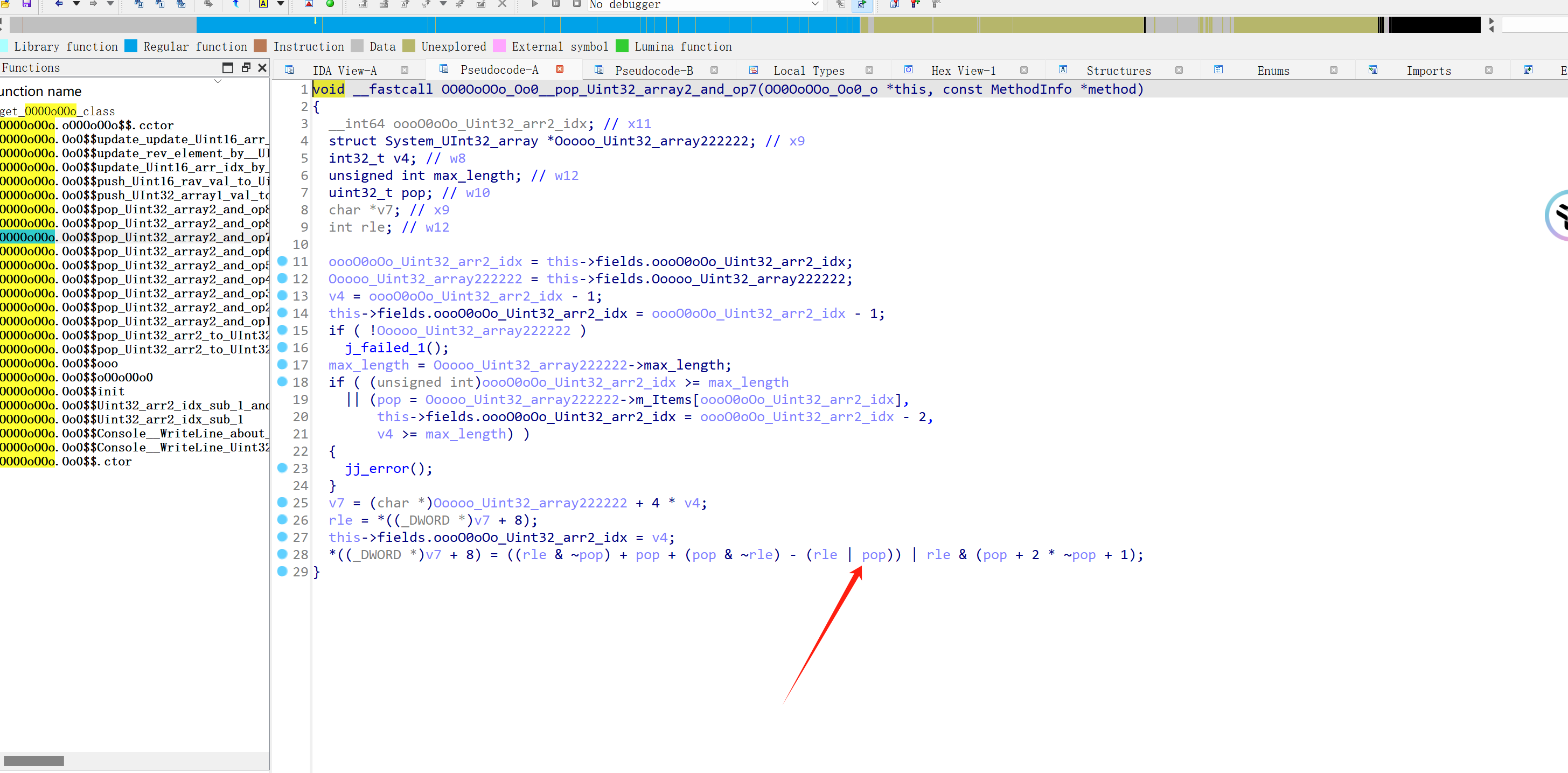
事实上通过分析可以发现,这些不过都是些指令混淆
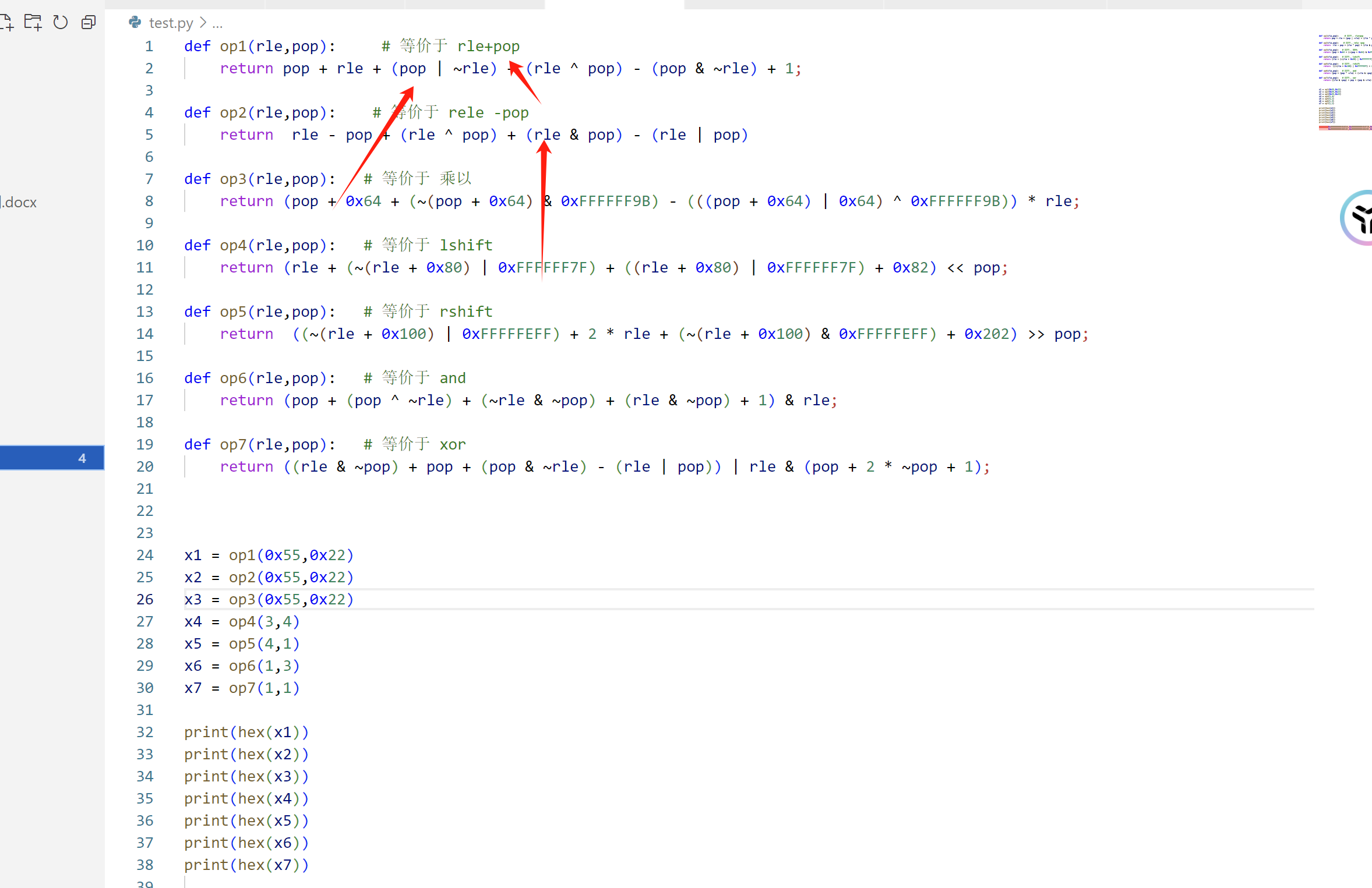
下面给出 frida hook vm虚拟机的脚本:
function hook_vm(){
var offset = 0x000000000465AB4
var vm_list = [
0x00000000046AEA4,0x00000000046AF20,0x00000000046AF94,0x00000000046B01C,0x00000000046B088,0x00000000046B110,
0x00000000046B18C,0x00000000046B20C,0x00000000046B270
]
for(var i = 0;i<vm_list.length;i++){
const addr = vm_list[i]
const idx = i
Interceptor.attach(ptr(baseAddr).add(addr),{
onEnter: function(args){
if(addr == 0x00000000046AEA4){
var pop = this.context.x11.and(0xffffffff)
var rle = this.context.x10.and(0xffffffff)
console.log("rle:\t" + rle)
console.log("pop:\t" + pop)
var new_rle = ptr(rle).add(pop)
console.log("new_\t" + new_rle)
console.log(`new_rel = rel + pop;`)
}
if(addr == 0x00000000046AF20){
var pop = this.context.x11.and(0xffffffff)
var rle = this.context.x10.and(0xffffffff)
var new_rle = ptr(rle).sub(pop)
console.log("rle:\t" + rle)
console.log("pop:\t" + pop)
console.log("new_\t" + new_rle)
console.log(`new_rel = rel - pop;`)
}
if(addr == 0x00000000046AF94){
var pop = this.context.x11.and(0xffffffff)
var rle = this.context.x10.and(0xffffffff)
var new_rle = ptr(pop.toInt32() * rle.toInt32())
console.log("rle:\t" + rle)
console.log("pop:\t" + pop)
console.log("new_\t" + new_rle)
console.log(`new_rel = rel * pop;`)
}
if(addr == 0x00000000046B01C){
var pop = this.context.x11.and(0xffffffff)
var rle = this.context.x10.and(0xffffffff)
var new_rle = ptr(rle).shl(pop)
console.log("rle:\t" + rle)
console.log("pop:\t" + pop)
console.log("new_\t" + new_rle)
console.log(`new_rel = rel << pop;`)
}
if(addr == 0x00000000046B088){
var pop = this.context.x11.and(0xffffffff)
var rle = this.context.x10.and(0xffffffff)
var new_rle = ptr(rle).shr(pop)
console.log("rle:\t" + rle)
console.log("pop:\t" + pop)
console.log("new_\t" + new_rle)
console.log(`new_rel = rel >> pop;`)
}
if(addr == 0x00000000046B110){
var pop = this.context.x11.and(0xffffffff)
var rle = this.context.x10.and(0xffffffff)
var new_rle = ptr(rle).and(pop)
console.log("rle:\t" + rle)
console.log("pop:\t" + pop)
console.log("new_\t" + new_rle)
console.log(`new_rel = rel & pop;`)
}
if(addr == 0x00000000046B18C){
var pop = this.context.x10.and(0xffffffff)
var rle = this.context.x12.and(0xffffffff)
var new_rle = ptr(rle).xor(pop)
console.log("rle:\t" + rle)
console.log("pop:\t" + pop)
console.log("new_\t" + new_rle)
console.log(`new_rel = rel ^ pop;`)
}
if(addr == 0x00000000046B20C){
var pop = this.context.x11.and(0xffffffff)
var rle = this.context.x10.and(0xffffffff)
console.log("pop:\t" + pop)
console.log("rle:\t" + rle)
console.log(`new_rel = rle < pop;`)
}
if(addr == 0x00000000046B270){
var pop = this.context.x11.and(0xffffffff)
var rle = this.context.x10.and(0xffffffff)
console.log("pop:\t" + pop)
console.log("rle:\t" + rle)
console.log(`new_rel = rle == pop;`)
}
},
onLeave: function(retval){
// console.log(`Leave : ${idx} ==> ${"0x" + addr.toString(16)}`)
}
})
}
}
可以得到这些数据:
ps:我在游戏中的输入是 "1433223",在进入 libil2cpp.so+0x0465AB4处的函数的时候,1433223就已经被加密成 0x93af17e410d817fa 了,这里的vm也是从 0x93af17e410d817fa 开始加密的。(从1433223到0x93af17e410d817fa 这段加密操作在后面我们会讲)
1433223: 0x93af17e410d817fa
part1 = 0x10d817fa
part2 = 0x93af17e4
rle: 0x10d817fa
pop: 0x18
new_ 0x10
new_rel = rel >> pop // 高8位 ,inp4 = part2 >> 24
rle: 0x10
pop: 0xff
new_ 0x10
new_rel = rel & pop // inp4 &= 0xff =====> 0x10
rle: 0x18
pop: 0x8
new_ 0x10
new_rel = rel - pop //
pop: 0x0
rle: 0x10
new_rel = rle < pop //
rle: 0x10d817fa
pop: 0x10
new_ 0x10d8
new_rel = rel >> pop // inp3 = part2 >> 16
rle: 0x10d8
pop: 0xff
new_ 0xd8
new_rel = rel & pop // inp3 &= 0xff =====> 0xd8
rle: 0x10
pop: 0x8
new_ 0x8
new_rel = rel - pop //
pop: 0x0
rle: 0x8
new_rel = rle < pop
rle: 0x10d817fa
pop: 0x8
new_ 0x10d817
new_rel = rel >> pop // inp2 = part2 >> 8
rle: 0x10d817
pop: 0xff
new_ 0x17
new_rel = rel & pop // inp2 &= 0xff ====> 0x17
rle: 0x8
pop: 0x8
new_ 0x0
new_rel = rel - pop
pop: 0x0
rle: 0x0
new_rel = rle < pop
rle: 0x10d817fa
pop: 0x0
new_ 0x10d817fa
new_rel = rel >> pop // inp1 = part2 >> 0
rle: 0x10d817fa
pop: 0xff
new_ 0xfa
new_rel = rel & pop // inp1 &= 0xff ====> 0xfa
rle: 0x0
pop: 0x8
new_ 0xfffffffffffffff8
new_rel = rel - pop
pop: 0x0
rle: 0xfffffff8
new_rel = rle < pop
rle: 0xfa
pop: 0x1b
new_ 0xdf
new_rel = rel - pop // inp1 - 0x1b --> 0xdf
rle: 0x17
pop: 0xc2
new_ 0xd5
new_rel = rel ^ pop // inp2 ^ 0xc2 ---> 0xd5
rle: 0xd8
pop: 0xa8
new_ 0x180
new_rel = rel + pop // inp3 + 0xa8 ---> 0x180
rle: 0x10
pop: 0x36
new_ 0x26
new_rel = rel ^ pop // inp4 ^ 0x36 ---> 0x26
rle: 0xdf
pop: 0x0
new_ 0xdf
new_rel = rel ^ pop // new_inp1 ^ 0 --> 0xdf
rle: 0xdf
pop: 0x0
new_ 0xdf
new_rel = rel << pop // new_inp1 <<0 = --> 0xdf
rle: 0xff
pop: 0x0
new_ 0xff
new_rel = rel << pop //
rle: 0xdf
pop: 0xff
new_ 0xdf
new_rel = rel & pop // new_inp1 & 0xff --> 0xdf
rle: 0xdf
pop: 0x0
new_ 0xdf
new_rel = rel + pop // new_inp1 + 0 --> 0xdf
rle: 0x4
pop: 0x1
new_ 0x5
new_rel = rel + pop // 4+1 --> 5
rle: 0x0
pop: 0x8
new_ 0x8
new_rel = rel + pop
pop: 0x19
rle: 0x8
new_rel = rle < pop
rle: 0xd5
pop: 0x8
new_ 0xdd
new_rel = rel ^ pop // new_inp2 ^= 0x8 --> 0xdd
rle: 0xdd
pop: 0x8
new_ 0xdd00
new_rel = rel << pop // new_inp2 <<= 0x8 --> 0xdd00
rle: 0xff
pop: 0x8
new_ 0xff00
new_rel = rel << pop
rle: 0xdd00
pop: 0xff00
new_ 0xdd00
new_rel = rel & pop // new_inp2 &= 0xff00
rle: 0xdd00
pop: 0xdf
new_ 0xdddf
new_rel = rel + pop // sum += new_inp2
rle: 0x5
pop: 0x1
new_ 0x6
new_rel = rel + pop
rle: 0x8
pop: 0x8
new_ 0x10
new_rel = rel + pop
pop: 0x19
rle: 0x10
new_rel = rle < pop
rle: 0x180
pop: 0x10
new_ 0x190
new_rel = rel ^ pop // new_inp3 ^= 0x10 --> 0x190
rle: 0x190
pop: 0x10
new_ 0x1900000
new_rel = rel << pop // new_inp3 <<= 0x10
rle: 0xff
pop: 0x10
new_ 0xff0000
new_rel = rel << pop
rle: 0x1900000
pop: 0xff0000
new_ 0x900000
new_rel = rel & pop // new_inp3 &= 0xff0000
rle: 0x900000
pop: 0xdddf
new_ 0x90dddf
new_rel = rel + pop // sum += new_inp3
rle: 0x6
pop: 0x1
new_ 0x7
new_rel = rel + pop
rle: 0x10
pop: 0x8
new_ 0x18
new_rel = rel + pop
pop: 0x19
rle: 0x18
new_rel = rle < pop
rle: 0x26
pop: 0x18
new_ 0x3e
new_rel = rel ^ pop // new_inp4 ^= 0x18
rle: 0x3e
pop: 0x18
new_ 0x3e000000
new_rel = rel << pop // new_inp4 <<= 0x18
rle: 0xff
pop: 0x18
new_ 0xff000000
new_rel = rel << pop
rle: 0x3e000000
pop: 0xff000000
new_ 0x3e000000
new_rel = rel & pop // new_inp4 &= 0xff000000
rle: 0x3e000000
pop: 0x90dddf
new_ 0x3e90dddf
new_rel = rel + pop // sum += new_inp4
rle: 0x7
pop: 0x1
new_ 0x8
new_rel = rel + pop
rle: 0x18
pop: 0x8
new_ 0x20
new_rel = rel + pop
pop: 0x19
rle: 0x20
new_rel = rle < pop
rle: 0x93af17e4
pop: 0x18
new_ 0x93
new_rel = rel >> pop // inp4 = part2 >> 0x18 --> 0x93
rle: 0x93
pop: 0xff
new_ 0x93
new_rel = rel & pop
rle: 0x18
pop: 0x8
new_ 0x10
new_rel = rel - pop
pop: 0x0
rle: 0x10
new_rel = rle < pop
rle: 0x93af17e4
pop: 0x10
new_ 0x93af
new_rel = rel >> pop
rle: 0x93af
pop: 0xff
new_ 0xaf
new_rel = rel & pop // inp3 = (part2 >> 0x10) & 0xff --> 0xaf
rle: 0x10
pop: 0x8
new_ 0x8
new_rel = rel - pop
pop: 0x0
rle: 0x8
new_rel = rle < pop
rle: 0x93af17e4
pop: 0x8
new_ 0x93af17
new_rel = rel >> pop
rle: 0x93af17
pop: 0xff
new_ 0x17
new_rel = rel & pop // inp2 = (part2 >> 0x8) & 0xff --> 0x17
rle: 0x8
pop: 0x8
new_ 0x0
new_rel = rel - pop
pop: 0x0
rle: 0x0
new_rel = rle < pop
rle: 0x93af17e4
pop: 0x0
new_ 0x93af17e4
new_rel = rel >> pop
rle: 0x93af17e4
pop: 0xff
new_ 0xe4
new_rel = rel & pop // inp1 = (part2 >> 0) & 0xff --> 0xe4
rle: 0x0
pop: 0x8
new_ 0xfffffffffffffff8
new_rel = rel - pop
pop: 0x0
rle: 0xfffffff8
new_rel = rle < pop
rle: 0xe4
pop: 0x2f
new_ 0xb5
new_rel = rel - pop // inp1 -= 0x2f
rle: 0x17
pop: 0xb6
new_ 0xa1
new_rel = rel ^ pop // inp2 ^= 0xb6
rle: 0xaf
pop: 0x37
new_ 0xe6
new_rel = rel + pop // inp3 += 0x37
rle: 0x93
pop: 0x98
new_ 0xb
new_rel = rel ^ pop // inp4 ^= 0x98
rle: 0xb5
pop: 0x0
new_ 0xb5
new_rel = rel + pop // inp1 += 0
rle: 0xb5
pop: 0x0
new_ 0xb5
new_rel = rel << pop // inp1 << 0
rle: 0xff
pop: 0x0
new_ 0xff
new_rel = rel << pop
rle: 0xb5
pop: 0xff
new_ 0xb5
new_rel = rel & pop // inp1 & 0xff
rle: 0xb5
pop: 0x0
new_ 0xb5
new_rel = rel + pop // sum += inp1
rle: 0x4
pop: 0x1
new_ 0x5
new_rel = rel + pop
rle: 0x0
pop: 0x8
new_ 0x8
new_rel = rel + pop
pop: 0x19
rle: 0x8
new_rel = rle < pop
rle: 0xa1
pop: 0x8
new_ 0xa9
new_rel = rel + pop // inp2 += 0x8
rle: 0xa9
pop: 0x8
new_ 0xa900
new_rel = rel << pop // inp2 << 0x8
rle: 0xff
pop: 0x8
new_ 0xff00
new_rel = rel << pop
rle: 0xa900
pop: 0xff00
new_ 0xa900
new_rel = rel & pop
rle: 0xa900
pop: 0xb5
new_ 0xa9b5
new_rel = rel + pop
rle: 0x5
pop: 0x1
new_ 0x6
new_rel = rel + pop
rle: 0x8
pop: 0x8
new_ 0x10
new_rel = rel + pop
pop: 0x19
rle: 0x10
new_rel = rle < pop
rle: 0xe6
pop: 0x10
new_ 0xf6
new_rel = rel + pop //
rle: 0xf6
pop: 0x10
new_ 0xf60000
new_rel = rel << pop
rle: 0xff
pop: 0x10
new_ 0xff0000
new_rel = rel << pop
rle: 0xf60000
pop: 0xff0000
new_ 0xf60000
new_rel = rel & pop
rle: 0xf60000
pop: 0xa9b5
new_ 0xf6a9b5
new_rel = rel + pop
rle: 0x6
pop: 0x1
new_ 0x7
new_rel = rel + pop
rle: 0x10
pop: 0x8
new_ 0x18
new_rel = rel + pop
pop: 0x19
rle: 0x18
new_rel = rle < pop
rle: 0xb
pop: 0x18
new_ 0x23
new_rel = rel + pop
rle: 0x23
pop: 0x18
new_ 0x23000000
new_rel = rel << pop
rle: 0xff
pop: 0x18
new_ 0xff000000
new_rel = rel << pop
rle: 0x23000000
pop: 0xff000000
new_ 0x23000000
new_rel = rel & pop
rle: 0x23000000
pop: 0xf6a9b5
new_ 0x23f6a9b5
new_rel = rel + pop
rle: 0x7
pop: 0x1
new_ 0x8
new_rel = rel + pop
rle: 0x18
pop: 0x8
new_ 0x20
new_rel = rel + pop
pop: 0x19
rle: 0x20
new_rel = rle < pop
low_4val: 0x3e90dddf high_4val: 0x23f6a9b5
还原算法:
def vmenc(inp):
part1 = inp & 0xffffffff
part2 = (inp >> 32) & 0xffffffff
p1_inp1 = part1 & 0xff
p1_inp2 = (part1 >> 8) & 0xff
p1_inp3 = (part1 >> 16) & 0xff
p1_inp4 = (part1 >> 24) & 0xff
p1_inp1 -= 0x1b
p1_inp2 ^= 0xc2
p1_inp3 += 0xa8
p1_inp4 ^= 0x36
p1_inp1 = ((p1_inp1 ^ 0) << 0) & 0xff
p1_inp2 = ((p1_inp2 ^ 0x8) << 0x8) &0xff00
p1_inp3 = ((p1_inp3 ^ 0x10) << 0x10) & 0xff0000
p1_inp4 = ((p1_inp4 ^ 0x18) << 0x18) & 0xff000000
p1_sum = p1_inp1 + p1_inp2 + p1_inp3 + p1_inp4
p2_inp1 = part2 & 0xff
p2_inp2 = (part2 >> 8) & 0xff
p2_inp3 = (part2 >> 16) & 0xff
p2_inp4 = (part2 >> 24) & 0xff
p2_inp1 -= 0x2f
p2_inp2 ^= 0xb6
p2_inp3 += 0x37
p2_inp4 ^= 0x98
p2_inp1 = ((p2_inp1 + 0) << 0) & 0xff
p2_inp2 = ((p2_inp2 + 0x8) << 0x8) & 0xff00
p2_inp3 = ((p2_inp3 + 0x10) << 0x10) & 0xff0000
p2_inp4 = ((p2_inp4 + 0x18) << 0x18) & 0xff000000
p2_sum = p2_inp1 + p2_inp2 + p2_inp3 + p2_inp4
return p1_sum,p2_sum
def conver(m):
if m < 0:
return 0x100 + m
return m
def vmdec(p1_sum,p2_sum):
p2_inp1 = (p2_sum & 0xff)
p2_inp2 = ((p2_sum & 0xff00) >> 0x8) - 0x8
p2_inp3 = ((p2_sum & 0xff0000) >> 0x10) - 0x10
p2_inp4 = ((p2_sum & 0xff000000) >> 0x18) - 0x18
p2_inp1 += 0x2f
p2_inp2 ^= 0xb6
p2_inp3 -= 0x37
p2_inp4 ^= 0x98
p2_inp1 = conver(p2_inp1)
p2_inp2 = conver(p2_inp2)
p2_inp3 = conver(p2_inp3)
p2_inp4 = conver(p2_inp4)
part2 = (p2_inp1 & 0xff) + ((p2_inp2 & 0xff) << 8) + ((p2_inp3 & 0xff) << 0x10) + ((p2_inp4 & 0xff) << 0x18)
p1_inp1 = (p1_sum & 0xff) ^ 0x0
p1_inp2 = ((p1_sum & 0xff00) >> 0x8) ^ 0x8
p1_inp3 = ((p1_sum & 0xff0000) >> 0x10) ^ 0x10
p1_inp4 = ((p1_sum & 0xff000000) >> 0x18) ^ 0x18
p1_inp1 += 0x1b
p1_inp2 ^= 0xc2
p1_inp3 -= 0xa8
p1_inp4 ^= 0x36
p1_inp1 = conver(p1_inp1)
p1_inp2 = conver(p1_inp2)
p1_inp3 = conver(p1_inp3)
p1_inp4 = conver(p1_inp4)
part1 = (p1_inp1 & 0xff) + ((p1_inp2 & 0xff) << 8) + ((p1_inp3 & 0xff) << 0x10) + ((p1_inp4 & 0xff) << 0x18)
return part1 + (part2 << 32)
enc = 0x93af17e410d817fa
enc1,enc2 = vmenc(enc)
assert enc1 == 0x3e90dddf and enc2 == 0x23f6a9b5
dec = vmdec(enc1,enc2)
assert dec == 0x93af17e410d817fa
这是四段加密中其中一段的加密。算法还原进度 1/4
魔改xtea算法
继续向下分析可以看到一个魔改 xtea加密算法,算法还原如下
# magical xtea
# vmlater: low_4val: 0x3e90dddf high_4val: 0x23f6a9b5
# ===>
# tealater: low_4val: 0x7dd89904 high_4val: 0xc6ff408e
from ctypes import *
from struct import pack,unpack
def encrypt(v, key):
v0, v1 = c_uint32(v[0]), c_uint32(v[1])
delta = 0x21524111
total1 = c_uint32(0xBEEFBEEF)
total2 = c_uint32(0x9D9D7DDE)
for i in range(64):
v0.value += (((v1.value << 7) ^ (v1.value >> 8)) + v1.value) ^ (total1.value - key[total1.value & 3])
total1.value -= delta
v1.value += (((v0.value << 8) ^ (v0.value >> 7)) - v0.value) ^ (total2.value + key[(total2.value>>13) & 3])
total2.value -= delta
return v0.value, v1.value
def decrypt(v, key):
v0, v1 = c_uint32(v[0]), c_uint32(v[1])
delta = 0x21524111
total1 = c_uint32(0xBEEFBEEF - 64 * delta)
total2 = c_uint32(0x9D9D7DDE - 64 * delta)
for i in range(64):
total2.value += delta
v1.value -= (((v0.value << 8) ^ (v0.value >> 7)) - v0.value) ^ (total2.value + key[(total2.value>>13) & 3])
total1.value += delta
v0.value -= (((v1.value << 7) ^ (v1.value >> 8)) + v1.value) ^ (total1.value - key[total1.value & 3])
return v0.value, v1.value
def enxtea(inp:bytes,key:bytes):
from struct import pack,unpack
k = unpack("<4I",key)
inp_len = len(inp) // 4
value = unpack(f"<{inp_len}I",inp)
res = b""
for i in range(0,inp_len,2):
v = [value[i],value[i+1]]
x = encrypt(v,k)
# x = decrypt(v,k)
res += pack("<2I",*x)
return res
def dextea(inp:bytes,key:bytes):
from struct import pack,unpack
k = unpack("<4I",key)
inp_len = len(inp) // 4
value = unpack(f"<{inp_len}I",inp)
res = b""
for i in range(0,inp_len,2):
v = [value[i],value[i+1]]
x = decrypt(v,k)
res += pack("<2I",*x)
return res
def xtea_enc(low_4val =0x3e90dddf,high_4val = 0x23f6a9b5 ):
# enc
# low_4val = 0x3e90dddf
# high_4val = 0x23f6a9b5
inp = pack("<I",low_4val) + pack("<I",high_4val)
key = [2071428195,3312413682,728170800,1990973438]
key = pack("<I",key[0]) + pack("<I",key[1]) + pack("<I",key[2]) + pack("<I",key[3])
ret = enxtea(inp,key)
xtea_enc1 = unpack("<I",ret[0:4])[0]
xtea_enc2 = unpack("<I",ret[4:8])[0]
# assert xtea_enc1 == 0x7dd89904 and xtea_enc2 == 0xc6ff408e
return xtea_enc1,xtea_enc2
def xtea_dec(xtea_enc1 = 0x7dd89904,xtea_enc2 = 0xc6ff408e):
# dec
key = [2071428195,3312413682,728170800,1990973438]
key = pack("<I",key[0]) + pack("<I",key[1]) + pack("<I",key[2]) + pack("<I",key[3])
# xtea_enc1 = 0x7dd89904
# xtea_enc2 = 0xc6ff408e
inp = pack("<I",xtea_enc1) + pack("<I",xtea_enc2)
ret = dextea(inp,key)
xtea_dec1 = unpack("<I",ret[0:4])[0]
xtea_dec2 = unpack("<I",ret[4:8])[0]
# assert xtea_dec1 == 0x3e90dddf and xtea_dec2 == 0x23f6a9b5
return xtea_dec1,xtea_dec2
算法还原进度 2/4
下面就剩 libsec2023.so中的算法了。
逆向分析 libsec2023.so的算法
splited 片段算法
在 0x00000000003B8FC偏移处是 libsec2023.so中的 第一个加密算法。
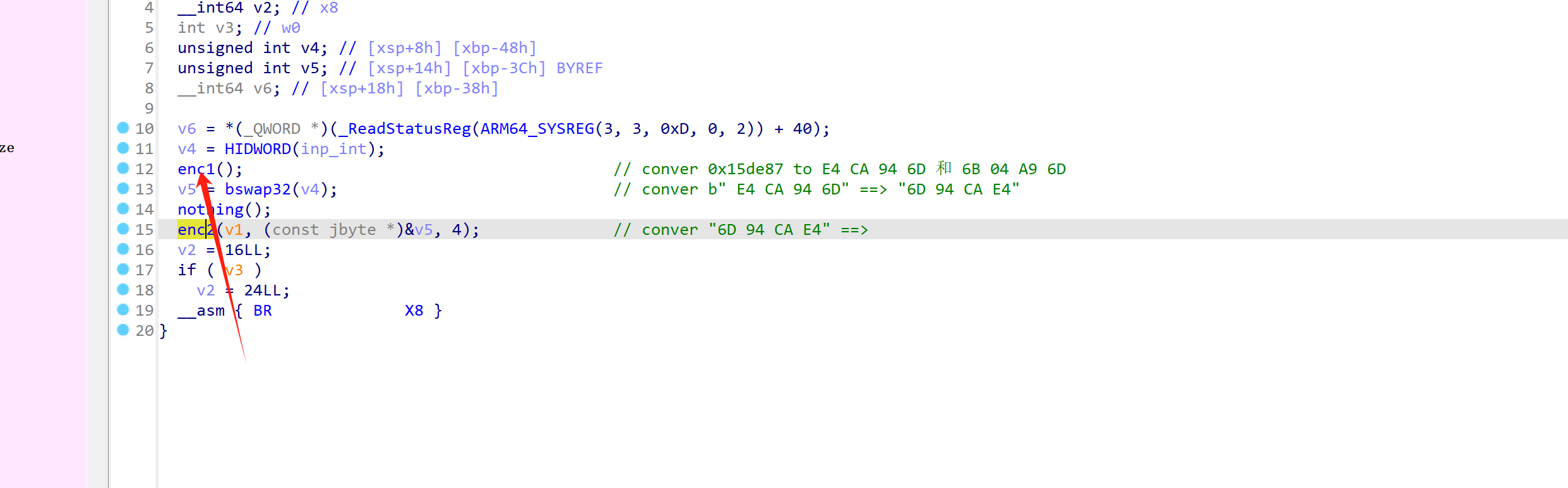
但是这个函数内部全是一个一个BR跳转形成的小片段,静态完全不能逆。
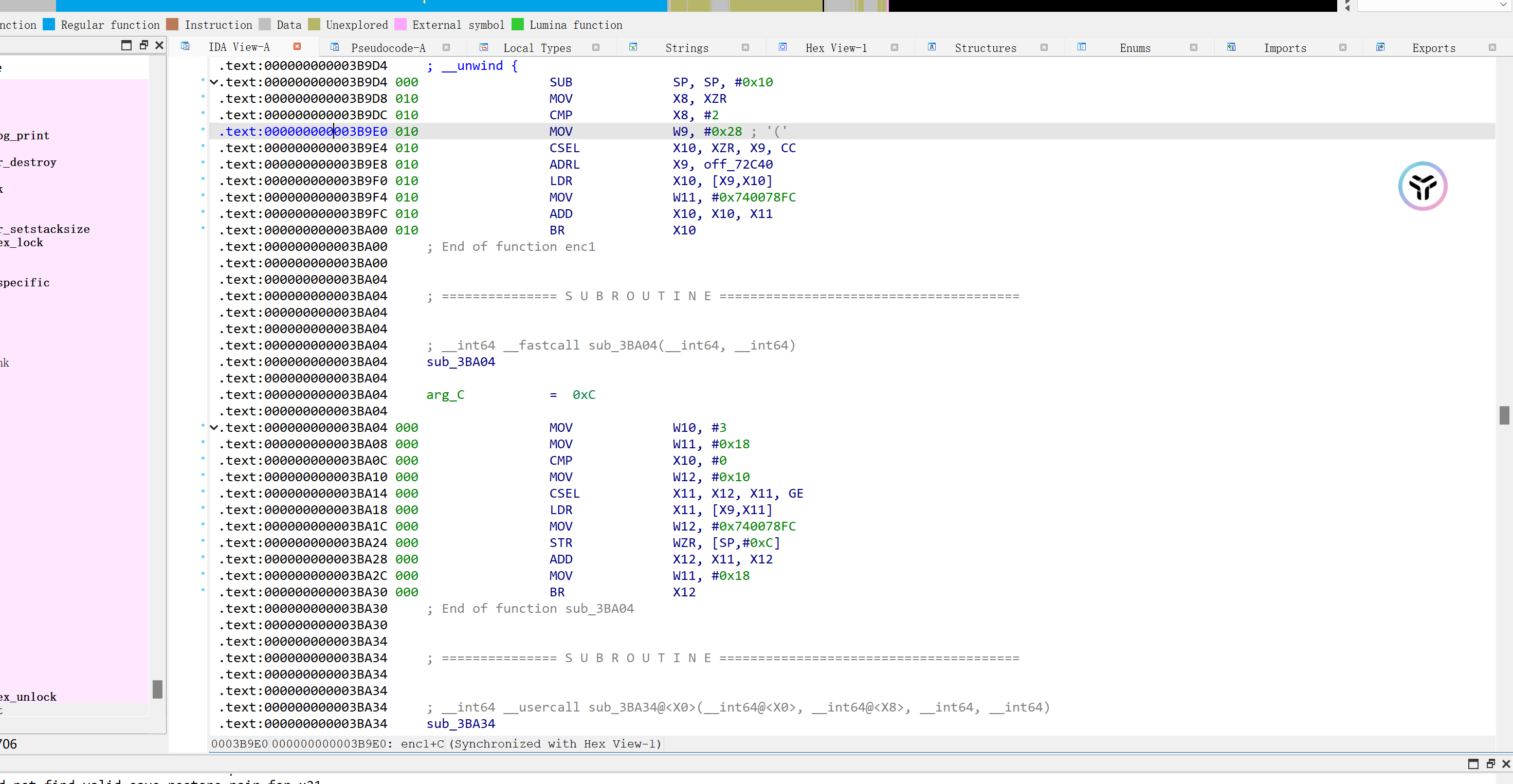
我们尝试用frida 勾住所有的 BR跳转的目的地址,分析规律:
function hook_libsec2023(){
var libsec2023_base = Module.findBaseAddress("libsec2023.so") // GetStaticMethodID
console.log("libsec2023_base: \t" + libsec2023_base)
var hook_list = [
// enc1
0x00000000003BA00,0x00000000003BA30,0x00000000003BA70,0x00000000003BADC,0x00000000003BB28,0x00000000003BB4C,
0x00000000003BB54,
// enc2
// 0x00000000003A08C,0x00000000003A0C8,0x00000000003A0F8,
// enc3
// fin
//0x00000000003B950,0x00000000003B990,0x00000000003B9CC,
//0x00000000003B9B0
]
for(var i =0;i<hook_list.length;i++){
const haddr = hook_list[i]
const idx = i
Interceptor.attach(ptr(libsec2023_base).add(haddr),{
onEnter: function(args){
if(haddr == 0x00000000003B9CC){
var next_addr = this.context.lr
console.log(`${idx}:\t${"0x" + haddr.toString(16)} =>\t${ptr(next_addr).sub(libsec2023_base)}(${ptr(next_addr)})`)
}
// 这里 hook到了: low_32: 0x10d817fa ; high_32: 0x93af17e4, 也就是分析 .so文件的最后一个地方
if(haddr == 0x00000000003B9B0){
var low_32 = this.context.x19
var high_32 = this.context.x8
console.log("low_32:\t" + low_32)
console.log("high_32:\t" + high_32)
}
if(haddr == 0x00000000003B950){
var next_addr = this.context.x8
console.log(`${idx}:\t${"0x" + haddr.toString(16)} =>\t${ptr(next_addr).sub(libsec2023_base)}(${ptr(next_addr)})`)
}
if(haddr == 0x00000000003B990){
var next_addr = this.context.x8
console.log(`${idx}:\t${"0x" + haddr.toString(16)} =>\t${ptr(next_addr).sub(libsec2023_base)}(${ptr(next_addr)})`)
}
if(haddr == 0x00000000003BA30 || haddr ==0x00000000003BA70 ){
var next_addr = this.context.x12
console.log(`${idx}:\t${"0x" + haddr.toString(16)} =>\t${ptr(next_addr).sub(libsec2023_base)}(${ptr(next_addr)})`)
}
if(haddr == 0x00000000003BADC || haddr == 0x00000000003BB28){
var next_addr = this.context.x13
console.log(`${idx}:\t${"0x" + haddr.toString(16)} =>\t${ptr(next_addr).sub(libsec2023_base)}(${ptr(next_addr)})`)
}
if(haddr == 0x00000000003BB4C || haddr == 0x00000000003BA00){
var next_addr = this.context.x10
console.log(`${idx}:\t${"0x" + haddr.toString(16)} =>\t${ptr(next_addr).sub(libsec2023_base)}(${ptr(next_addr)})`)
}
if(haddr == 0x00000000003BB54){
// stack_backstace(this)
var next_addr = this.context.lr
console.log(`${idx}:\t${"0x" + haddr.toString(16)} =>\t${ptr(next_addr).sub(libsec2023_base)}(${ptr(next_addr)})`)
}
},
onLeave: function(retval){
}
})
}
}
大致如下:
0: 0x3ba00 => 0x3ba04(0x6d8d506a04)
1: 0x3ba30 => 0x3ba34(0x6d8d506a34)
2: 0x3ba70 => 0x3ba34(0x6d8d506a34)
2: 0x3ba70 => 0x3ba34(0x6d8d506a34)
2: 0x3ba70 => 0x3ba34(0x6d8d506a34)
2: 0x3ba70 => 0x3ba74(0x6d8d506a74)
5: 0x3bb4c => 0x3ba04(0x6d8d506a04)
1: 0x3ba30 => 0x3ba34(0x6d8d506a34)
2: 0x3ba70 => 0x3ba34(0x6d8d506a34)
2: 0x3ba70 => 0x3ba34(0x6d8d506a34)
2: 0x3ba70 => 0x3ba34(0x6d8d506a34)
2: 0x3ba70 => 0x3ba74(0x6d8d506a74)
3: 0x3badc => 0x3bae0(0x6d8d506ae0)
4: 0x3bb28 => 0x3bae0(0x6d8d506ae0)
4: 0x3bb28 => 0x3bae0(0x6d8d506ae0)
4: 0x3bb28 => 0x3bae0(0x6d8d506ae0)
4: 0x3bb28 => 0x3bb2c(0x6d8d506b2c)
5: 0x3bb4c => 0x3bb50(0x6d8d506b50)
6: 0x3bb54 => 0xfffffffffad3650c(0x6d8820150c)
可以发现大部分跳转都是四个四个出现的。
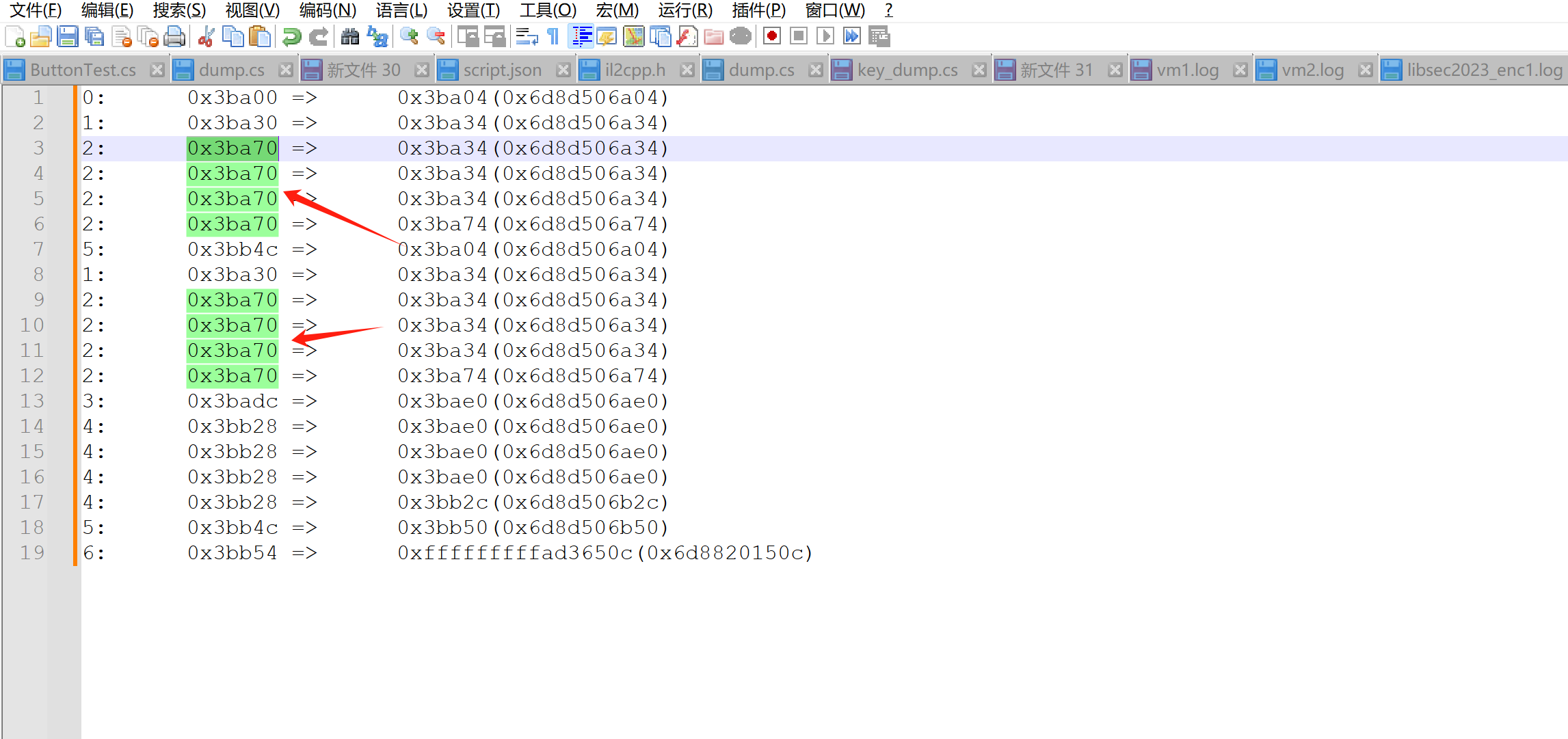
盲猜是对输入的四字节数据的逐字节加密。这样一想,关键函数片段其实也就三四个,完全能逆。
我这里结合unidbg来进行的分析,边调边逆,大致log如下:
0: 0x3ba00 => 0x3ba04(0x6d8d506a04)
1: 0x3ba30 => 0x3ba34(0x6d8d506a34)
2: 0x3ba70 => 0x3ba34(0x6d8d506a34)
2: 0x3ba70 => 0x3ba34(0x6d8d506a34)
2: 0x3ba70 => 0x3ba34(0x6d8d506a34)
2: 0x3ba70 => 0x3ba74(0x6d8d506a74)
part2_ori 为高四位 :0
part1_ori 为低四位
part2 = part2_ori
idx = 3
part2 >>= 0x18
part2 ^= idx
*0xbffff6af = part2 & 0xff
idx -=1
part2 = part2_ori
part2 >>= 0x10
part2 ^= idx
idx -=1
*0xbffff6ae = part2 & 0xff
part2 = part2_ori
part2 >>= 0x8
part2 ^= idx
idx -=1
*0xbffff6ad = part2 & 0xff
part2 = part2_ori
part2 >>= 0
part2 ^= idx(0)
idx -=1
*0xbffff6ac = part2 & 0xff
===========> *0xbffff6ac ==> 00 01 02 03
0x3ba74:
3: 0x3badc => 0x3bae0(0x6d8d506ae0)
// 以后 0xbffff6ac 简称 mem
mem[0] -= 0x1c
mem[1] ^= 0xd3
mem[2] -= 0x5e
mem[3] ^= 0x86
===========> 0xbffff6ac ==> E4 D2 A4 85 !!!!
4: 0x3bb28 => 0x3bae0(0x6d8d506ae0)
4: 0x3bb28 => 0x3bae0(0x6d8d506ae0)
4: 0x3bb28 => 0x3bae0(0x6d8d506ae0)
4: 0x3bb28 => 0x3bb2c(0x6d8d506b2c)
r1:
W14 = mem[3] (0x85)
w14 -= 0x18 (0x6d)
mem[3] = w14
w14 &= 0xff
w14 <<= 0x18 ==> 0x6d000000
w10 = 0
w10 += w14
#define 0xbffff6b8 Dmem
*(DWORD)0xbffff6b8 = w10
r2:
W14 = mem[2] (0xa4)
W14 -= 0x10
mem[2] = w14
w14 &= 0xff
w14 <<= 0x10 ==> 0x940000
w10 += w14
*(DWORD)0xbffff6b8 = w10 (0x6d940000)
得到: 0xbffff6b8: ===> E4 CA 94 6D
和: 0xbffff6ac: ===> E4 CA 94 6D
不过后面 0xbffff6ac被清空了,用于下一轮的工作
都是指向这俩地方
5: 0x3bb4c => 0x3ba04(0x6d8d506a04)
1: 0x3ba30 => 0x3ba34(0x6d8d506a34)
2: 0x3ba70 => 0x3ba34(0x6d8d506a34)
2: 0x3ba70 => 0x3ba34(0x6d8d506a34)
2: 0x3ba70 => 0x3ba34(0x6d8d506a34)
2: 0x3ba70 => 0x3ba74(0x6d8d506a74)
3: 0x3badc => 0x3bae0(0x6d8d506ae0)
4: 0x3bb28 => 0x3bae0(0x6d8d506ae0)
4: 0x3bb28 => 0x3bae0(0x6d8d506ae0)
4: 0x3bb28 => 0x3bae0(0x6d8d506ae0)
4: 0x3bb28 => 0x3bb2c(0x6d8d506b2c)
5: 0x3bb4c => 0x3bb50(0x6d8d506b50)
6: 0x3bb54 => 0xfffffffffad3650c(0x6d8820150c)
// 这次是 0x15de87走这一遭
得到了: 0xbffff6bc: 6B 04 A9 6D
------>
总结:
从: 0x00000000 0x0015de89 ===> E4 CA 94 6D 6B 04 A9 6D
===> 0x6d94cae4 0x6da9046b
----> swap()---> 6d 94 ca e4 与 6d a9 04 6b
unidbg脚本如下;
package com.Tencent_game;
import com.github.unidbg.Emulator;
import com.github.unidbg.AndroidEmulator;
import com.github.unidbg.Module;
import com.github.unidbg.debugger.BreakPointCallback;
import com.github.unidbg.debugger.DebuggerType;
import com.github.unidbg.linux.android.AndroidEmulatorBuilder;
import com.github.unidbg.linux.android.AndroidResolver;
import com.github.unidbg.linux.android.dvm.*;
import com.github.unidbg.memory.Memory;
import com.github.unidbg.virtualmodule.android.AndroidModule;
import java.io.File;
import com.github.unidbg.arm.context.Arm64RegisterContext;
public class qua_2023 {
public final AndroidEmulator emulator;
public final VM vm;
public final Memory memory;
public final Module module;
DvmClass cNative;
public qua_2023(){
emulator = AndroidEmulatorBuilder.for64Bit().build();
memory = emulator.getMemory();
memory.setLibraryResolver(new AndroidResolver(23));
emulator.getSyscallHandler().setEnableThreadDispatcher(true);
vm = emulator.createDalvikVM();
// vm.setVerbose(true);
new AndroidModule(emulator,vm).register(memory);
DalvikModule dalvikModule = vm.loadLibrary(new File("D:\\tlsn\\BTools\\RE\\APK Easy Tool v1.60 Portable\\1-Decompiled APKs\\mouse_pre.aligned.signed\\lib\\arm64-v8a\\libsec2023.so"), true);
module = dalvikModule.getModule();
vm.callJNI_OnLoad(emulator,module);
}
public static void main(String[] args){
qua_2023 mainActivity = new qua_2023();
mainActivity.debugger();
}
private void debugger() {
emulator.attach(DebuggerType.CONSOLE).addBreakPoint(module.base+ 0x00000000003B8CC);
// emulator.traceRead(0xbffff6bc,0xbffff6c0);
module.callFunction(emulator,0x00000000003B8CC,0x15de87);
}
}
算法还原:
# .so enc1
def so_enc1(inp):
part1 = inp & 0xffffffff
part2 = (inp >> 32) & 0xffffffff
p1_inp1 = (part1 & 0xff) ^ 0
p1_inp2 = ((part1 >> 0x8) & 0xff) ^ 1
p1_inp3 = ((part1 >> 0x10) & 0xff) ^ 2
p1_inp4 = ((part1 >> 0x18) & 0xff) ^ 3
p1_inp1 -= 0x1c
p1_inp2 ^= 0xd3
p1_inp3 -= 0x5e
p1_inp4 ^= 0x86
p1_inp1 -= 0
p1_inp2 -= 0x8
p1_inp3 -= 0x10
p1_inp4 -= 0x18
p1_inp1 = conver(p1_inp1)
p1_inp2 = conver(p1_inp2)
p1_inp3 = conver(p1_inp3)
p1_inp4 = conver(p1_inp4)
p1_sum = p1_inp1 + (p1_inp2 << 8) + (p1_inp3 << 16) + (p1_inp4 << 24)
p2_inp1 = (part2 & 0xff) ^ 0
p2_inp2 = ((part2 >> 0x8) & 0xff) ^ 1
p2_inp3 = ((part2 >> 0x10) & 0xff) ^ 2
p2_inp4 = ((part2 >> 0x18) & 0xff) ^ 3
p2_inp1 -= 0x1c
p2_inp2 ^= 0xd3
p2_inp3 -= 0x5e
p2_inp4 ^= 0x86
p2_inp1 -= 0
p2_inp2 -= 0x8
p2_inp3 -= 0x10
p2_inp4 -= 0x18
p2_inp1 = conver(p2_inp1)
p2_inp2 = conver(p2_inp2)
p2_inp3 = conver(p2_inp3)
p2_inp4 = conver(p2_inp4)
p2_sum = p2_inp1 + (p2_inp2 << 8) + (p2_inp3 << 0x10) + (p2_inp4 << 0x18)
return p1_sum,p2_sum
def so_dec1(p1_sum,p2_sum):
p1_inp1 = p1_sum & 0xff
p1_inp2 = (p1_sum >> 8) & 0xff
p1_inp3 = (p1_sum >> 0x10) & 0xff
p1_inp4 = (p1_sum >> 0x18) & 0xff
p1_inp1 += 0
p1_inp2 += 0x8
p1_inp3 += 0x10
p1_inp4 += 0x18
p1_inp1 += 0x1c
p1_inp2 ^= 0xd3
p1_inp3 += 0x5e
p1_inp4 ^= 0x86
p1_inp1 &= 0xff
p1_inp2 &= 0xff
p1_inp3 &= 0xff
p1_inp4 &= 0xff
p1_inp1 ^= 0
p1_inp2 ^= 1
p1_inp3 ^= 2
p1_inp4 ^= 3
part1 = p1_inp1 + (p1_inp2 << 8) + (p1_inp3 << 0x10) + (p1_inp4 << 0x18)
p2_inp1 = p2_sum & 0xff
p2_inp2 = (p2_sum >> 8) & 0xff
p2_inp3 = (p2_sum >> 0x10) & 0xff
p2_inp4 = (p2_sum >> 0x18) & 0xff
p2_inp1 += 0
p2_inp2 += 0x8
p2_inp3 += 0x10
p2_inp4 += 0x18
p2_inp1 += 0x1c
p2_inp2 ^= 0xd3
p2_inp3 += 0x5e
p2_inp4 ^= 0x86
p2_inp1 &= 0xff
p2_inp2 &= 0xff
p2_inp3 &= 0xff
p2_inp4 &= 0xff
p2_inp1 ^= 0
p2_inp2 ^= 1
p2_inp3 ^= 2
p2_inp4 ^= 3
part2 = p2_inp1 + (p2_inp2 << 8) + (p2_inp3 << 0x10) + (p2_inp4 << 0x18)
return part1 + (part2 << 32)
ming = 0x15de87
enc1,enc2 = so_enc1(ming)
assert enc1 == 0x6da9046b and enc2 == 0x6d94cae4
enc1 = 0x6da9046b
enc2 = 0x6d94cae4
ming = so_dec1(enc1,enc2)
assert ming == 0x15de87
算法还原进度 3/4
loadclass 加载外部类中的算法
下面继续逆向
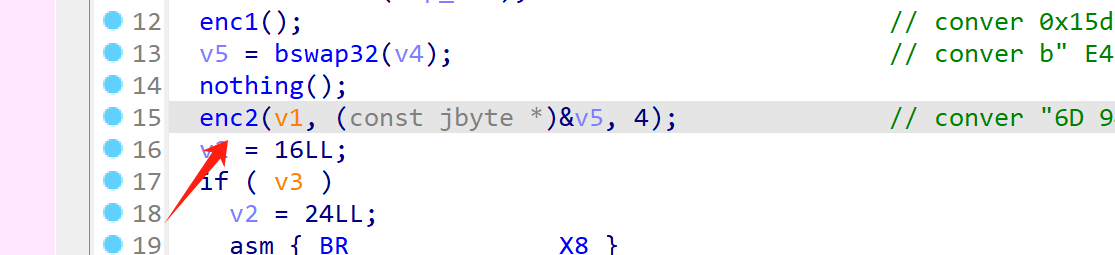

hook这个 GetStaticMethodID jni函数,可以发现其调用了java层的 encry函数,但是我们目前反编译app的java层代码中是不包含encry函数的,猜测app在运行的时候 主动调用了 loadclass函数来加载外部 类,事实上也确实如此。
hook住loadclass函数是能发现程序调用了这样一个外部类的:

猜测 GetStaticMethodID函数调用的 encry 方法也来自这个类中。
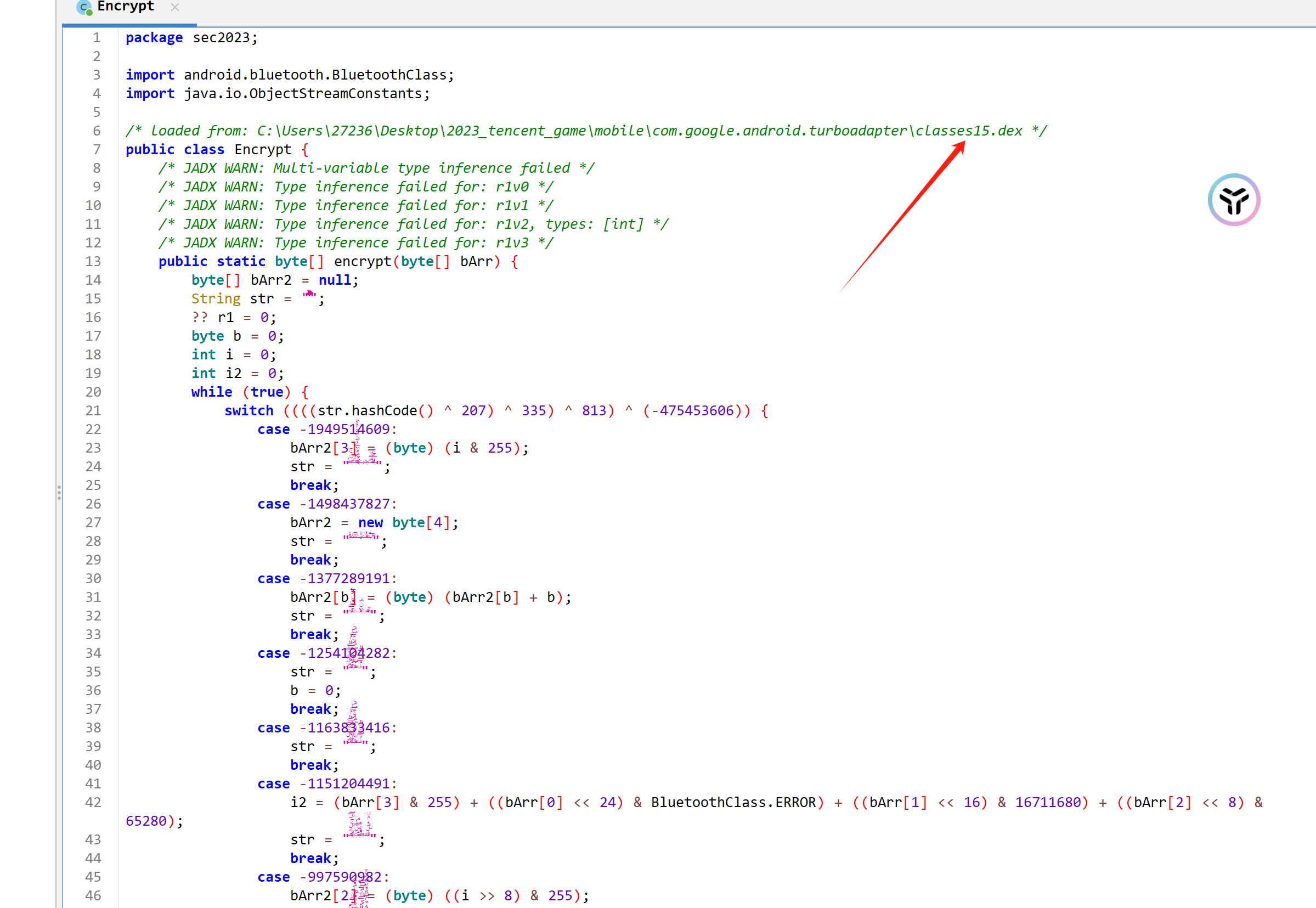
后面我尝试了多种方法去 找sec2023.Encrypt这个类,比如 hook open函数,找dex的位置,也确实找到了一些蛛丝马迹,比如程序在运行的时候会在 /data/user/0/com.com.sec2023.rocketmouse.mouse/files目录下生成一个 encry.dex,并删除掉。我尝试在encry.dex落地的时候 抓取到它,但没成功,不知道是不是分析有误。
后来,我尝试使用frida-dexdump 成功dump出了所有的dex(回头可以学一下它的hook方法)

用jadx打开后看到了 控制流平坦化,不急,高版本 jeb自带反混淆
大体加密逻辑如下:
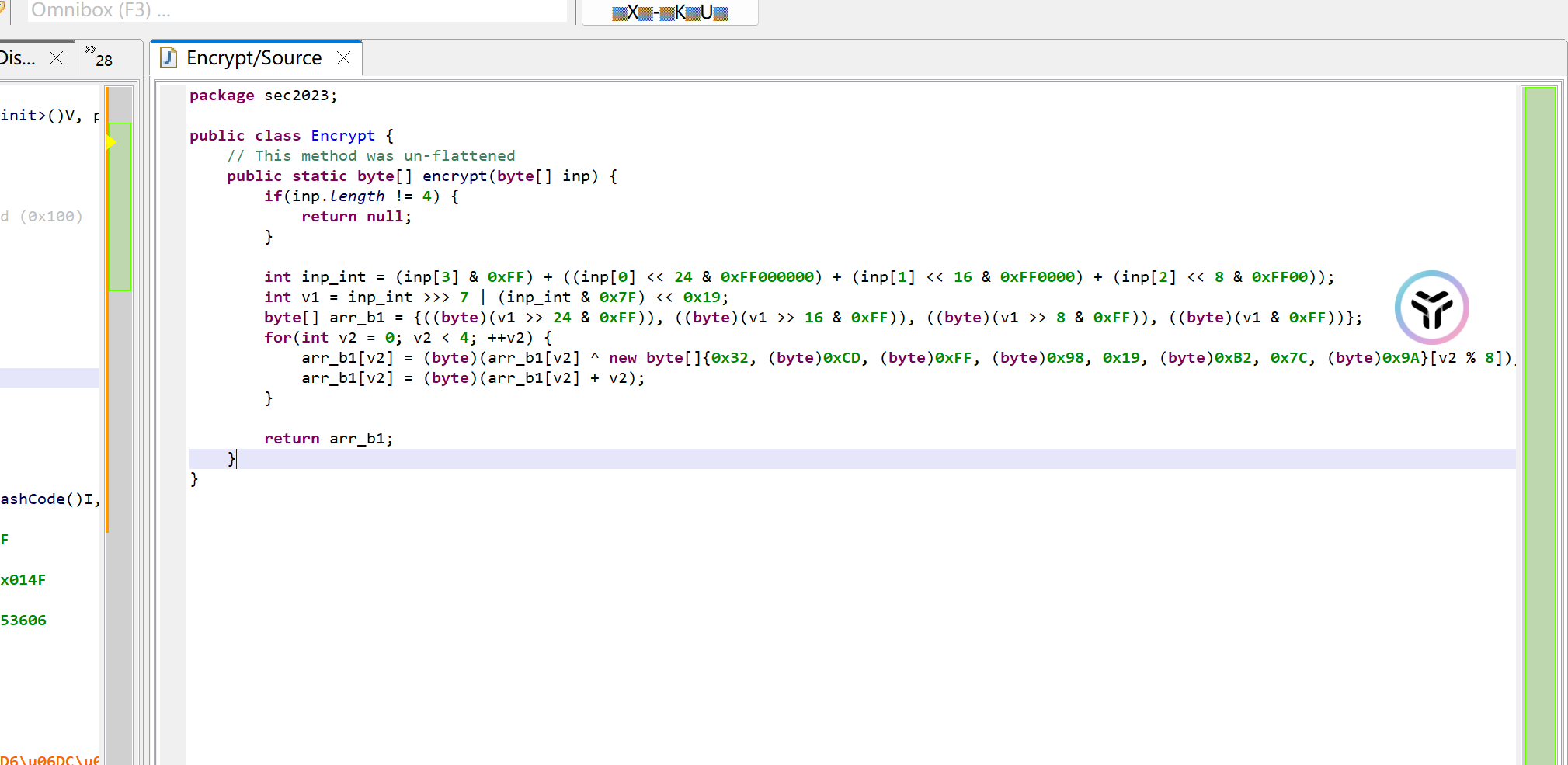
还原算法:
def ror(m,round):
return (m >> round ) | (m << (32-round))
def so_enc2(inp):
inp_int = (inp[0] << 24) + (inp[1] << 16) + (inp[2] << 8) + inp[3]
v1 = ror(inp_int,7)
new_arr = [(v1 >> 24) & 0xff,(v1 >> 16) & 0xff,(v1 >> 8) & 0xff,v1 & 0xff ]
key = [0x32, 0xCD, 0xFF, 0x98, 0x19, 0xB2, 0x7C, 0x9A]
for i in range(4):
new_arr[i] = new_arr[i] ^ key[i % 8]
new_arr[i] = new_arr[i] + i
new_arr[i] &= 0xff
return new_arr
def so_dec2(new_arr):
key = [0x32, 0xCD, 0xFF, 0x98, 0x19, 0xB2, 0x7C, 0x9A]
for i in range(4):
new_arr[i] = new_arr[i] - i
new_arr[i] = conver(new_arr[i])
new_arr[i] = new_arr[i] ^ key[i % 8]
v1 = (new_arr[0] << 24) + (new_arr[1] << 16) + (new_arr[2] << 8) + new_arr[3]
inp_int = ror(v1,32-7)
inp = [(inp_int >> 24) & 0xff, (inp_int >> 16) & 0xff, (inp_int >> 8) & 0xff, inp_int & 0xff ]
return inp
ming1 = [0x6d,0x94, 0xca, 0xe4]
ming2 = [0x6d,0xa9, 0x04, 0x6b]
res1 = so_enc2(ming1)
res2 = so_enc2(ming2)
res1_int = res1[0] + (res1[1] << 8) + (res1[2] << 16) + (res1[3] << 24)
res2_int = res2[0] + (res2[1] << 8) + (res2[2] << 16) + (res2[3] << 24)
assert res1_int == 0x10d817fa and res2_int == 0x93af17e4
m1 = so_dec2(res1)
m2 = so_dec2(res2)
assert m1 == ming1 and m2 == ming2
算法还原进度 4/4
完整注册机
def vmenc(inp):
part1 = inp & 0xffffffff
part2 = (inp >> 32) & 0xffffffff
p1_inp1 = part1 & 0xff
p1_inp2 = (part1 >> 8) & 0xff
p1_inp3 = (part1 >> 16) & 0xff
p1_inp4 = (part1 >> 24) & 0xff
p1_inp1 -= 0x1b
p1_inp2 ^= 0xc2
p1_inp3 += 0xa8
p1_inp4 ^= 0x36
p1_inp1 = ((p1_inp1 ^ 0) << 0) & 0xff
p1_inp2 = ((p1_inp2 ^ 0x8) << 0x8) &0xff00
p1_inp3 = ((p1_inp3 ^ 0x10) << 0x10) & 0xff0000
p1_inp4 = ((p1_inp4 ^ 0x18) << 0x18) & 0xff000000
p1_sum = p1_inp1 + p1_inp2 + p1_inp3 + p1_inp4
p2_inp1 = part2 & 0xff
p2_inp2 = (part2 >> 8) & 0xff
p2_inp3 = (part2 >> 16) & 0xff
p2_inp4 = (part2 >> 24) & 0xff
p2_inp1 -= 0x2f
p2_inp2 ^= 0xb6
p2_inp3 += 0x37
p2_inp4 ^= 0x98
p2_inp1 = ((p2_inp1 + 0) << 0) & 0xff
p2_inp2 = ((p2_inp2 + 0x8) << 0x8) & 0xff00
p2_inp3 = ((p2_inp3 + 0x10) << 0x10) & 0xff0000
p2_inp4 = ((p2_inp4 + 0x18) << 0x18) & 0xff000000
p2_sum = p2_inp1 + p2_inp2 + p2_inp3 + p2_inp4
return p1_sum,p2_sum
def conver(m):
if m < 0:
return 0x100 + m
return m
def vmdec(p1_sum,p2_sum):
p2_inp1 = (p2_sum & 0xff)
p2_inp2 = ((p2_sum & 0xff00) >> 0x8) - 0x8
p2_inp3 = ((p2_sum & 0xff0000) >> 0x10) - 0x10
p2_inp4 = ((p2_sum & 0xff000000) >> 0x18) - 0x18
p2_inp1 += 0x2f
p2_inp2 ^= 0xb6
p2_inp3 -= 0x37
p2_inp4 ^= 0x98
p2_inp1 = conver(p2_inp1)
p2_inp2 = conver(p2_inp2)
p2_inp3 = conver(p2_inp3)
p2_inp4 = conver(p2_inp4)
part2 = (p2_inp1 & 0xff) + ((p2_inp2 & 0xff) << 8) + ((p2_inp3 & 0xff) << 0x10) + ((p2_inp4 & 0xff) << 0x18)
p1_inp1 = (p1_sum & 0xff) ^ 0x0
p1_inp2 = ((p1_sum & 0xff00) >> 0x8) ^ 0x8
p1_inp3 = ((p1_sum & 0xff0000) >> 0x10) ^ 0x10
p1_inp4 = ((p1_sum & 0xff000000) >> 0x18) ^ 0x18
p1_inp1 += 0x1b
p1_inp2 ^= 0xc2
p1_inp3 -= 0xa8
p1_inp4 ^= 0x36
p1_inp1 = conver(p1_inp1)
p1_inp2 = conver(p1_inp2)
p1_inp3 = conver(p1_inp3)
p1_inp4 = conver(p1_inp4)
part1 = (p1_inp1 & 0xff) + ((p1_inp2 & 0xff) << 8) + ((p1_inp3 & 0xff) << 0x10) + ((p1_inp4 & 0xff) << 0x18)
return part1 + (part2 << 32)
enc = 0x93af17e410d817fa
enc1,enc2 = vmenc(enc)
assert enc1 == 0x3e90dddf and enc2 == 0x23f6a9b5
dec = vmdec(enc1,enc2)
assert dec == 0x93af17e410d817fa
# magical xtea
# vmlater: low_4val: 0x3e90dddf high_4val: 0x23f6a9b5
# ===>
# tealater: low_4val: 0x7dd89904 high_4val: 0xc6ff408e
from ctypes import *
from struct import pack,unpack
def encrypt(v, key):
v0, v1 = c_uint32(v[0]), c_uint32(v[1])
delta = 0x21524111
total1 = c_uint32(0xBEEFBEEF)
total2 = c_uint32(0x9D9D7DDE)
for i in range(64):
v0.value += (((v1.value << 7) ^ (v1.value >> 8)) + v1.value) ^ (total1.value - key[total1.value & 3])
total1.value -= delta
v1.value += (((v0.value << 8) ^ (v0.value >> 7)) - v0.value) ^ (total2.value + key[(total2.value>>13) & 3])
total2.value -= delta
return v0.value, v1.value
def decrypt(v, key):
v0, v1 = c_uint32(v[0]), c_uint32(v[1])
delta = 0x21524111
total1 = c_uint32(0xBEEFBEEF - 64 * delta)
total2 = c_uint32(0x9D9D7DDE - 64 * delta)
for i in range(64):
total2.value += delta
v1.value -= (((v0.value << 8) ^ (v0.value >> 7)) - v0.value) ^ (total2.value + key[(total2.value>>13) & 3])
total1.value += delta
v0.value -= (((v1.value << 7) ^ (v1.value >> 8)) + v1.value) ^ (total1.value - key[total1.value & 3])
return v0.value, v1.value
def enxtea(inp:bytes,key:bytes):
from struct import pack,unpack
k = unpack("<4I",key)
inp_len = len(inp) // 4
value = unpack(f"<{inp_len}I",inp)
res = b""
for i in range(0,inp_len,2):
v = [value[i],value[i+1]]
x = encrypt(v,k)
# x = decrypt(v,k)
res += pack("<2I",*x)
return res
def dextea(inp:bytes,key:bytes):
from struct import pack,unpack
k = unpack("<4I",key)
inp_len = len(inp) // 4
value = unpack(f"<{inp_len}I",inp)
res = b""
for i in range(0,inp_len,2):
v = [value[i],value[i+1]]
x = decrypt(v,k)
res += pack("<2I",*x)
return res
def xtea_enc(low_4val =0x3e90dddf,high_4val = 0x23f6a9b5 ):
# enc
# low_4val = 0x3e90dddf
# high_4val = 0x23f6a9b5
inp = pack("<I",low_4val) + pack("<I",high_4val)
key = [2071428195,3312413682,728170800,1990973438]
key = pack("<I",key[0]) + pack("<I",key[1]) + pack("<I",key[2]) + pack("<I",key[3])
ret = enxtea(inp,key)
xtea_enc1 = unpack("<I",ret[0:4])[0]
xtea_enc2 = unpack("<I",ret[4:8])[0]
# assert xtea_enc1 == 0x7dd89904 and xtea_enc2 == 0xc6ff408e
return xtea_enc1,xtea_enc2
def xtea_dec(xtea_enc1 = 0x7dd89904,xtea_enc2 = 0xc6ff408e):
# dec
key = [2071428195,3312413682,728170800,1990973438]
key = pack("<I",key[0]) + pack("<I",key[1]) + pack("<I",key[2]) + pack("<I",key[3])
# xtea_enc1 = 0x7dd89904
# xtea_enc2 = 0xc6ff408e
inp = pack("<I",xtea_enc1) + pack("<I",xtea_enc2)
ret = dextea(inp,key)
xtea_dec1 = unpack("<I",ret[0:4])[0]
xtea_dec2 = unpack("<I",ret[4:8])[0]
# assert xtea_dec1 == 0x3e90dddf and xtea_dec2 == 0x23f6a9b5
return xtea_dec1,xtea_dec2
# .so enc1
def so_enc1(inp):
part1 = inp & 0xffffffff
part2 = (inp >> 32) & 0xffffffff
p1_inp1 = (part1 & 0xff) ^ 0
p1_inp2 = ((part1 >> 0x8) & 0xff) ^ 1
p1_inp3 = ((part1 >> 0x10) & 0xff) ^ 2
p1_inp4 = ((part1 >> 0x18) & 0xff) ^ 3
p1_inp1 -= 0x1c
p1_inp2 ^= 0xd3
p1_inp3 -= 0x5e
p1_inp4 ^= 0x86
p1_inp1 -= 0
p1_inp2 -= 0x8
p1_inp3 -= 0x10
p1_inp4 -= 0x18
p1_inp1 = conver(p1_inp1)
p1_inp2 = conver(p1_inp2)
p1_inp3 = conver(p1_inp3)
p1_inp4 = conver(p1_inp4)
p1_sum = p1_inp1 + (p1_inp2 << 8) + (p1_inp3 << 16) + (p1_inp4 << 24)
p2_inp1 = (part2 & 0xff) ^ 0
p2_inp2 = ((part2 >> 0x8) & 0xff) ^ 1
p2_inp3 = ((part2 >> 0x10) & 0xff) ^ 2
p2_inp4 = ((part2 >> 0x18) & 0xff) ^ 3
p2_inp1 -= 0x1c
p2_inp2 ^= 0xd3
p2_inp3 -= 0x5e
p2_inp4 ^= 0x86
p2_inp1 -= 0
p2_inp2 -= 0x8
p2_inp3 -= 0x10
p2_inp4 -= 0x18
p2_inp1 = conver(p2_inp1)
p2_inp2 = conver(p2_inp2)
p2_inp3 = conver(p2_inp3)
p2_inp4 = conver(p2_inp4)
p2_sum = p2_inp1 + (p2_inp2 << 8) + (p2_inp3 << 0x10) + (p2_inp4 << 0x18)
return p1_sum,p2_sum
def so_dec1(p1_sum,p2_sum):
p1_inp1 = p1_sum & 0xff
p1_inp2 = (p1_sum >> 8) & 0xff
p1_inp3 = (p1_sum >> 0x10) & 0xff
p1_inp4 = (p1_sum >> 0x18) & 0xff
p1_inp1 += 0
p1_inp2 += 0x8
p1_inp3 += 0x10
p1_inp4 += 0x18
p1_inp1 += 0x1c
p1_inp2 ^= 0xd3
p1_inp3 += 0x5e
p1_inp4 ^= 0x86
p1_inp1 &= 0xff
p1_inp2 &= 0xff
p1_inp3 &= 0xff
p1_inp4 &= 0xff
p1_inp1 ^= 0
p1_inp2 ^= 1
p1_inp3 ^= 2
p1_inp4 ^= 3
part1 = p1_inp1 + (p1_inp2 << 8) + (p1_inp3 << 0x10) + (p1_inp4 << 0x18)
p2_inp1 = p2_sum & 0xff
p2_inp2 = (p2_sum >> 8) & 0xff
p2_inp3 = (p2_sum >> 0x10) & 0xff
p2_inp4 = (p2_sum >> 0x18) & 0xff
p2_inp1 += 0
p2_inp2 += 0x8
p2_inp3 += 0x10
p2_inp4 += 0x18
p2_inp1 += 0x1c
p2_inp2 ^= 0xd3
p2_inp3 += 0x5e
p2_inp4 ^= 0x86
p2_inp1 &= 0xff
p2_inp2 &= 0xff
p2_inp3 &= 0xff
p2_inp4 &= 0xff
p2_inp1 ^= 0
p2_inp2 ^= 1
p2_inp3 ^= 2
p2_inp4 ^= 3
part2 = p2_inp1 + (p2_inp2 << 8) + (p2_inp3 << 0x10) + (p2_inp4 << 0x18)
return part1 + (part2 << 32)
ming = 0x15de87
enc1,enc2 = so_enc1(ming)
assert enc1 == 0x6da9046b and enc2 == 0x6d94cae4
enc1 = 0x6da9046b
enc2 = 0x6d94cae4
ming = so_dec1(enc1,enc2)
assert ming == 0x15de87
def ror(m,round):
return (m >> round ) | (m << (32-round))
def so_enc2(inp):
inp_int = (inp[0] << 24) + (inp[1] << 16) + (inp[2] << 8) + inp[3]
v1 = ror(inp_int,7)
new_arr = [(v1 >> 24) & 0xff,(v1 >> 16) & 0xff,(v1 >> 8) & 0xff,v1 & 0xff ]
key = [0x32, 0xCD, 0xFF, 0x98, 0x19, 0xB2, 0x7C, 0x9A]
for i in range(4):
new_arr[i] = new_arr[i] ^ key[i % 8]
new_arr[i] = new_arr[i] + i
new_arr[i] &= 0xff
return new_arr
def so_dec2(new_arr):
key = [0x32, 0xCD, 0xFF, 0x98, 0x19, 0xB2, 0x7C, 0x9A]
for i in range(4):
new_arr[i] = new_arr[i] - i
new_arr[i] = conver(new_arr[i])
new_arr[i] = new_arr[i] ^ key[i % 8]
v1 = (new_arr[0] << 24) + (new_arr[1] << 16) + (new_arr[2] << 8) + new_arr[3]
inp_int = ror(v1,32-7)
inp = [(inp_int >> 24) & 0xff, (inp_int >> 16) & 0xff, (inp_int >> 8) & 0xff, inp_int & 0xff ]
return inp
ming1 = [0x6d,0x94, 0xca, 0xe4]
ming2 = [0x6d,0xa9, 0x04, 0x6b]
res1 = so_enc2(ming1)
res2 = so_enc2(ming2)
res1_int = res1[0] + (res1[1] << 8) + (res1[2] << 16) + (res1[3] << 24)
res2_int = res2[0] + (res2[1] << 8) + (res2[2] << 16) + (res2[3] << 24)
assert res1_int == 0x10d817fa and res2_int == 0x93af17e4
m1 = so_dec2(res1)
m2 = so_dec2(res2)
assert m1 == ming1 and m2 == ming2
# generate cheat by token
def all_enc(token:int):
enc1_part1,enc1_part2 = so_enc1(token)
enc1_part1_list = [(enc1_part1 >> 0x18) & 0xff,(enc1_part1 >> 0x10) & 0xff,(enc1_part1 >> 8) & 0xff,enc1_part1 & 0xff]
enc1_part2_list = [(enc1_part2 >> 0x18) & 0xff,(enc1_part2 >> 0x10) & 0xff,(enc1_part2 >> 8) & 0xff,enc1_part2 & 0xff]
enc2_part1_list = so_enc2(enc1_part1_list)
enc2_part2_list = so_enc2(enc1_part2_list)
enc2_part1 = enc2_part1_list[0] + (enc2_part1_list[1] << 8) + (enc2_part1_list[2] << 16) + (enc2_part1_list[3] << 24)
enc2_part2 = enc2_part2_list[0] + (enc2_part2_list[1] << 8) + (enc2_part2_list[2] << 16) + (enc2_part2_list[3] << 24)
enc2 = enc2_part2 + (enc2_part1 << 32) #
vmenc3_part1,vmenc3_part2 = vmenc(enc2)
enc4_low4,enc4_high4 = xtea_enc(vmenc3_part1,vmenc3_part2)
return enc4_low4,enc4_high4
input_ = 1433223
cheat1,cheat2 = all_enc(input_)
assert cheat1 == 0x7dd89904 and cheat2 == 0xc6ff408e
def generate_cheat_by_token(enc4_low4,enc4_high4=0):
vmenc3_part1,vmenc3_part2 = xtea_dec(enc4_low4,enc4_high4)
enc2 = vmdec(vmenc3_part1,vmenc3_part2)
enc2_part2 = enc2 & 0xffffffff
enc2_part1 = (enc2 >> 32) & 0xffffffff
enc2_part1_list = [enc2_part1 & 0xff,(enc2_part1 >> 8) & 0xff , (enc2_part1 >> 0x10) & 0xff,(enc2_part1 >> 0x18) & 0xff]
enc2_part2_list = [enc2_part2 & 0xff,(enc2_part2 >> 8) & 0xff , (enc2_part2 >> 0x10) & 0xff,(enc2_part2 >> 0x18) & 0xff]
enc1_part1_list = so_dec2(enc2_part1_list)
enc1_part2_list = so_dec2(enc2_part2_list)
enc1_part1 = (enc1_part1_list[0] << 0x18) + (enc1_part1_list[1] << 0x10) + (enc1_part1_list[2] << 0x8) + enc1_part1_list[3]
enc1_part2 = (enc1_part2_list[0] << 0x18) + (enc1_part2_list[1] << 0x10) + (enc1_part2_list[2] << 0x8) + enc1_part2_list[3]
cheat = so_dec1(enc1_part1,enc1_part2)
return cheat
input_ = generate_cheat_by_token(cheat1,cheat2)
assert input_ == 1433223
token = 80820328 # 这里输入token
cheat = generate_cheat_by_token(token)
print(f"token: {token} ===> cheat: {cheat}") # 小键盘中输入 生成的cheat码即可实现作弊(加速、无敌、吸金币)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号