rCore_Lab6
本章任务
实现文件系统
霸王龙
持久存储设备
持久存储设备就是我们今天说的外存
文件系统数据结构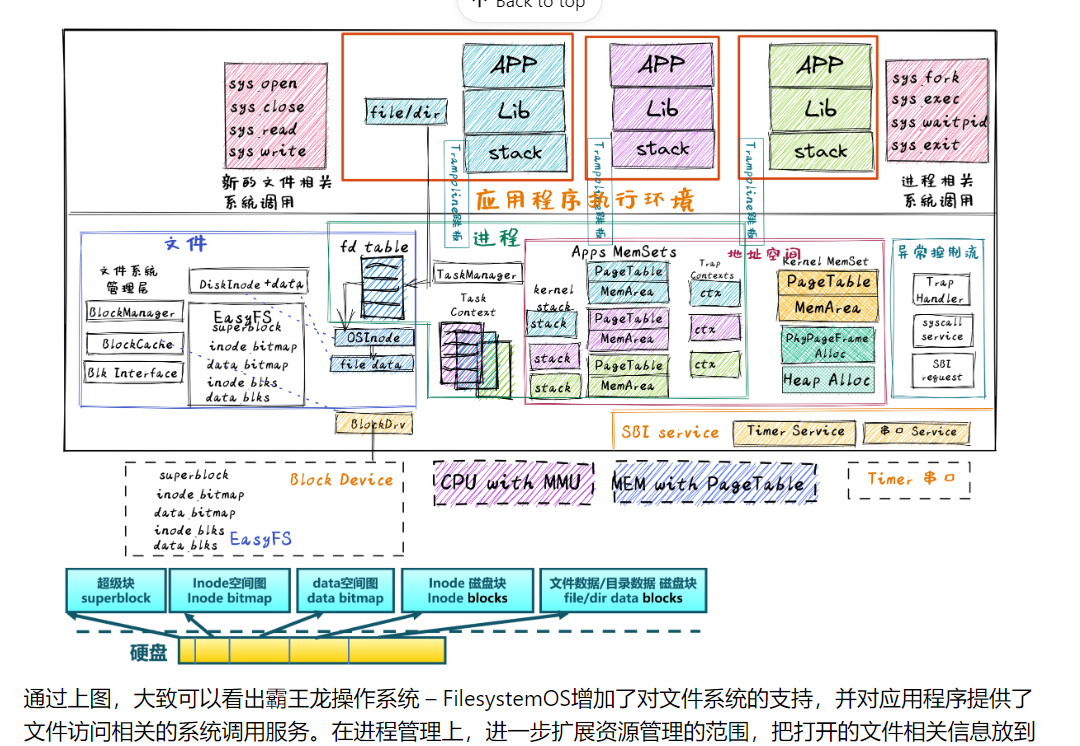
1、superblock: 超级块(super block),包含文件系统的所有关键信息,在计算机启动时,或者在该文件系统首次使用时,超级块会被载入内存。超级块中的典型信息包括分区的块的数量、块的大小、空闲块的数量和指针、空闲的FCB数量和FCB指针等。
2、inode bitmap: 表示存放inode磁盘块空闲情况的位图
3、data bitmap: 表示存放文件数据磁盘块空闲情况的位图
4、inode blks : 存放文件元数据的磁盘块
5、data blks : 存放文件数据的磁盘块
EasyFS中的块缓存管理器 BlockManager 在内存中管理有限个 BlockCache 磁盘块缓存,并通过Blk Interface(与块设备驱动对接的读写操作接口)与BlockDrv 块设备驱动程序进行互操作。
stat命令
在常规文件下各字段的含义
cd os/src/
stat main.rs
File: main.rs
Size: 940 Blocks: 8 IO Block: 4096 regular file
Device: 801h/2049d Inode: 4975 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 1000/ oslab) Gid: ( 1000/ oslab)
Access: 2021-02-28 23:32:50.289925450 +0800
Modify: 2021-02-28 23:32:50.133927136 +0800
Change: 2021-02-28 23:32:50.133927136 +0800
Birth:
- File 表明它的文件名为
main.rs。 - Size 表明它的字节大小为 940 字节。
- Blocks 表明它占据 8 个 块 (Block) 来存储。在文件系统中,文件的数据以块为单位进行存储。在 IO Block 可以看出,在 Linux操作系统中的Ext4文件系统的每个块的大小为 4096 字节。
- regular file 表明这个文件是一个常规文件。事实上,其他类型的文件也可以通过文件名来进行访问。
- 当文件是一个特殊文件(如块设备文件或者字符设备文件)的时候,Device 将指出该特殊文件的 major/minor ID 。对于一个常规文件,我们无需关心它。
- Inode 表示文件的底层编号。在文件系统的底层实现中,并不是直接通过文件名来索引文件,而是首先需要将文件名转化为文件的底层编号,再根据这个编号去索引文件。目前我们无需关心这一信息。
- Links 给出文件的硬链接数。同一个文件系统中如果两个文件(目录也是文件)具有相同的inode号码,那么就称它们是“硬链接”关系。这样links的值其实是一个文件的不同文件名的数量。(本章的练习需要你在文件系统中实现硬链接!)
- Uid 给出该文件的所属的用户 ID , Gid 给出该文件所属的用户组 ID 。Access 的其中一种表示是一个长度为 10 的字符串(这里是
-rw-r--r--),其中第 1 位给出该文件的类型,这个文件是一个常规文件,因此这第 1 位为-。后面的 9 位可以分为三组,分别表示该文件的所有者/在该文件所属的用户组内的其他用户以及剩下的所有用户能够读取/写入/将该文件作为一个可执行文件来执行。 - Access/Modify 分别给出该文件的最近一次访问/最近一次修改时间。
目录文件下各字段的含义
stat os
File: os
Size: 4096 Blocks: 8 IO Block: 4096 directory
Device: 801h/2049d Inode: 4982 Links: 5
Access: (0755/drwxr-xr-x) Uid: ( 1000/ oslab) Gid: ( 1000/ oslab)
Access: 2021-02-28 23:32:50.133927136 +0800
Modify: 2021-02-28 23:32:50.129927180 +0800
Change: 2021-02-28 23:32:50.129927180 +0800
Birth: -
对于目录而言, Access 的 rwx 含义有所不同:
r表示是否允许获取该目录下有哪些文件和子目录;w表示是否允许在该目录下创建/删除文件和子目录;x表示是否允许“通过”该目录。
easy-fs文件系统
1、easy-fs底层是轮询的方式访问 virtio_blk 虚拟磁盘设备,从而避免了设置访问外设中断的相关内核函数
2、easy-fs在设计中避免了直接访问进程相关的数据和函数,从而隔离了操作系统内核的进程管理。
3、easy-fs crate 自下而上大致可以分成五个不同的层次:
-
磁盘块设备接口层:定义了以块大小为单位对磁盘块设备进行读写的trait接口
-
块缓存层:在内存中缓存磁盘块的数据,避免频繁读写磁盘
-
磁盘数据结构层:磁盘上的超级块、位图、索引节点、数据块、目录项等核心数据结构和相关处理
-
磁盘块管理器层:合并了上述核心数据结构和磁盘布局所形成的磁盘文件系统数据结构,以及基于这些结构的创建/打开文件系统的相关处理和磁盘块的分配和回收处理
-
索引节点层:管理索引节点(即文件控制块)数据结构,并实现文件创建/文件打开/文件读写等成员函数来向上支持文件操作相关的系统调用
easy-fs文件系统---块设备接口层
主要就是提供了两个抽象函数
将编号为 block_id 的块从磁盘读入内存中的缓冲区 buf / 将内存中的缓冲区 buf 中的数据写入磁盘编号为 block_id 的块

easy-fs文件系统---块缓存层
由于操作系统频繁读写速度缓慢的磁盘块会极大降低系统性能,因此常见的手段是先通过 read_block 将一个块上的数据从磁盘读到内存中的一个缓冲区中,这个缓冲区中的内容是可以直接读写的,那么后续对这个数据块的大部分访问就可以在内存中完成了。如果缓冲区中的内容被修改了,那么后续还需要通过 write_block 将缓冲区中的内容写回到磁盘块中。
我们的做法是将缓冲区统一管理起来。当我们要读写一个块的时候,首先就是去全局管理器中查看这个块是否已被缓存到内存缓冲区中。如果是这样,则在一段连续时间内对于一个块进行的所有操作均是在同一个固定的缓冲区中进行的,这解决了同步性问题。此外,通过 read/write_block 进行块实际读写的时机完全交给块缓存层的全局管理器处理,上层子系统无需操心。全局管理器会尽可能将更多的块操作合并起来,并在必要的时机发起真正的块实际读写。
涉及到的数据结构
1、块缓存
pub const BLOCK_SZ: usize = 512;
// easy-fs/src/block_cache.rs
pub struct BlockCache {
cache: [u8; BLOCK_SZ],
block_id: usize,
block_device: Arc<dyn BlockDevice>,
modified: bool,
}
cache 是一个 512 字节的数组,表示位于内存中的缓冲区;
block_id 记录了这个块缓存来自于磁盘中的块的编号;
block_device 是一个底层块设备的引用,可通过它进行块读写;
modified 记录这个块从磁盘载入内存缓存之后,它有没有被修改过。
2、块缓存全局管理器
const BLOCK_CACHE_SIZE: usize = 16;
use alloc::collections::VecDeque;
pub struct BlockCacheManager {
queue: VecDeque<(usize, Arc<Mutex<BlockCache>>)>,
}
impl BlockCacheManager {
pub fn new() -> Self {
Self { queue: VecDeque::new() }
}
}
采用 类 FIFO 的简单缓存替换算法
接口:
get_block_cache 方法尝试从块缓存管理器中获取一个编号为 block_id 的块的块缓存,如果找不到,会从磁盘读取到内存中,还有可能会发生缓存替换:
easy-fs文件系统---磁盘数据结构层
超级块
SuperBlock 是一个磁盘上数据结构,它就存放在磁盘上编号为 0 的块的起始处。

-
最开始的区域的长度为一个块,其内容是 easy-fs 超级块 (Super Block)。超级块内以魔数的形式提供了文件系统合法性检查功能,同时还可以定位其他连续区域的位置。
-
第二个区域是一个索引节点位图,长度为若干个块。它记录了后面的索引节点区域中有哪些索引节点已经被分配出去使用了,而哪些还尚未被分配出去。
-
第三个区域是索引节点区域,长度为若干个块。其中的每个块都存储了若干个索引节点。
-
第四个区域是一个数据块位图,长度为若干个块。它记录了后面的数据块区域中有哪些数据块已经被分配出去使用了,而哪些还尚未被分配出去。
-
最后的区域则是数据块区域,顾名思义,其中的每一个已经分配出去的块保存了文件或目录中的具体数据内容。
相关数据结构
pub struct SuperBlock { // SuperBlock 是一个磁盘上数据结构,它就存放在磁盘上编号为 0 的块的起始处。
magic: u32, // magic 是一个用于文件系统合法性验证的魔数
pub total_blocks: u32, // total_block 给出文件系统的总块数,注意这并不等同于所在磁盘的总块数,因为文件系统很可能并没有占据整个磁盘
pub inode_bitmap_blocks: u32, // 索引节点位图所占块数
pub inode_area_blocks: u32, // 索引节点区域所占块数
pub data_bitmap_blocks: u32, // 数据块位图所占块数
pub data_area_blocks: u32, // 数据块区域所占块数
}
位图
存在两类不同的位图,分别对索引节点和数据块进行管理
每个位图都由若干个块组成,每个块大小为 512 bytes,即 4096 bits。每个 bit 都代表一个索引节点/数据块的分配状态, 0 意味着未分配,而 1 则意味着已经分配出去。
相关数据结构
pub struct Bitmap {
start_block_id: usize, // 区域的起始块编号
blocks: usize, // 区域长度
}
磁盘上索引节点
就是inode结点
const INODE_DIRECT_COUNT: usize = 28;
#[repr(C)]
pub struct DiskInode {
pub size: u32,
pub direct: [u32; INODE_DIRECT_COUNT],
pub indirect1: u32,
pub indirect2: u32,
type_: DiskInodeType,
}
#[derive(PartialEq)]
pub enum DiskInodeType {
File,
Directory,
}
数据块
作为一个文件而言,它的内容在文件系统看来没有任何既定的格式,都只是一个字节序列。因此每个保存内容的数据块都只是一个字节数组:
type DataBlock = [u8; BLOCK_SZ];
目录项
// easy-fs/src/layout.rs
const NAME_LENGTH_LIMIT: usize = 27;
#[repr(C)]
pub struct DirEntry {
name: [u8; NAME_LENGTH_LIMIT + 1],
inode_number: u32,
}
pub const DIRENT_SZ: usize = 32;
目录项只记录name与Inode结点编号
easy-fs文件系统---磁盘块管理器
将各段区域及上面的磁盘数据结构结构整合起来就是简易文件系统 EasyFileSystem 的职责
从这一层开始,所有的数据结构就都放在内存上了。
pub struct EasyFileSystem {
pub block_device: Arc<dyn BlockDevice>,
pub inode_bitmap: Bitmap,
pub data_bitmap: Bitmap,
inode_area_start_block: u32,
data_area_start_block: u32,
}
easy-fs文件系统---索引节点层
相关数据结构
pub struct Inode {
block_id: usize,
block_offset: usize,
fs: Arc<Mutex<EasyFileSystem>>,
block_device: Arc<dyn BlockDevice>,
}
block_id 和 block_offset 记录该 Inode 对应的 DiskInode 保存在磁盘上的具体位置方便我们后续对它进行访问。 fs 是指向 EasyFileSystem 的一个指针,因为对 Inode 的种种操作实际上都是要通过底层的文件系统来完成。
将应用打包为 easy-fs 镜像
在第六章中我们需要将所有的应用都链接到内核中,随后在应用管理器中通过应用名进行索引来找到应用的 ELF 数据。这样做有一个缺点,就是会造成内核体积过度膨胀。在 k210 平台上可以很明显的感觉到从第五章开始随着应用数量的增加,向开发板上烧写内核镜像的耗时显著增长。同时这也会浪费内存资源,因为未被执行的应用也占据了内存空间。
在实现了 easy-fs 文件系统之后,终于可以将这些应用打包到 easy-fs 镜像中放到磁盘中,当我们要执行应用的时候只需从文件系统中取出ELF 执行文件格式的应用 并加载到内存中执行即可,这样就避免了前面章节的存储开销等问题。
这里用到了clap库..
在内核中接入easy-fs
- 块设备驱动层:针对内核所要运行在的 qemu 或 k210 平台,我们需要将平台上的块设备驱动起来并实现
easy-fs所需的BlockDeviceTrait ,这样easy-fs才能将该块设备用作 easy-fs 镜像的载体。 easy-fs层:我们在上一节已经介绍了easy-fs文件系统内部的层次划分。这里是站在内核的角度,只需知道它接受一个块设备BlockDevice,并可以在上面打开文件系统EasyFileSystem,进而获取Inode核心数据结构,进行各种文件系统操作即可。- 内核索引节点层:在内核中需要将
easy-fs提供的Inode进一步封装成OSInode,以表示进程中一个打开的常规文件。由于有很多种不同的打开方式,因此在OSInode中要维护一些额外的信息。 - 文件描述符层:常规文件对应的
OSInode是文件的内核内部表示,因此需要为它实现FileTrait 从而能够可以将它放入到进程文件描述符表中并通过sys_read/write系统调用进行读写。 - 系统调用层:由于引入了常规文件这种文件类型,导致一些系统调用以及相关的内核机制需要进行一定的修改。
File接口
pub trait File : Send + Sync {
fn read(&self, buf: UserBuffer) -> usize;
fn write(&self, buf: UserBuffer) -> usize;
}
这个接口在内存和存储设备之间建立了数据交换的通道
read 指的是从文件中读取数据放到缓冲区中,最多将缓冲区填满(即读取缓冲区的长度那么多字节),并返回实际读取的字节数;而 write 指的是将缓冲区中的数据写入文件,最多将缓冲区中的数据全部写入,并返回直接写入的字节数。至于 read 和 write 的实现则与文件具体是哪种类型有关,它决定了数据如何被读取和写入。
UserBuffer的抽象
pub fn translated_byte_buffer(
token: usize,
ptr: *const u8,
len: usize
) -> Vec<&'static mut [u8]>;
pub struct UserBuffer {
pub buffers: Vec<&'static mut [u8]>,
}
impl UserBuffer {
pub fn new(buffers: Vec<&'static mut [u8]>) -> Self {
Self { buffers }
}
pub fn len(&self) -> usize {
let mut total: usize = 0;
for b in self.buffers.iter() {
total += b.len();
}
total
}
}
块设备驱动层
在启动 Qemu 模拟器的时候,我们可以配置参数来添加一块 VirtIO 块设备:
# os/Makefile
FS_IMG := ../user/target/$(TARGET)/$(MODE)/fs.img
run-inner: build
ifeq ($(BOARD),qemu)
@qemu-system-riscv64 \
-machine virt \
-nographic \
-bios $(BOOTLOADER) \
-device loader,file=$(KERNEL_BIN),addr=$(KERNEL_ENTRY_PA) \
-drive file=$(FS_IMG),if=none,format=raw,id=x0 \
-device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0
-
第 12 行,我们为虚拟机添加一块虚拟硬盘,内容为我们之前通过 easy-fs-fuse 工具打包的包含应用 ELF 的 easy-fs 镜像,并命名为 x0 。
-
第 13 行,我们将硬盘 x0 作为一个 VirtIO 总线中的一个块设备接入到虚拟机系统中。 virtio-mmio-bus.0 表示 VirtIO 总线通过 MMIO 进行控制,且该块设备在总线中的编号为 0 。
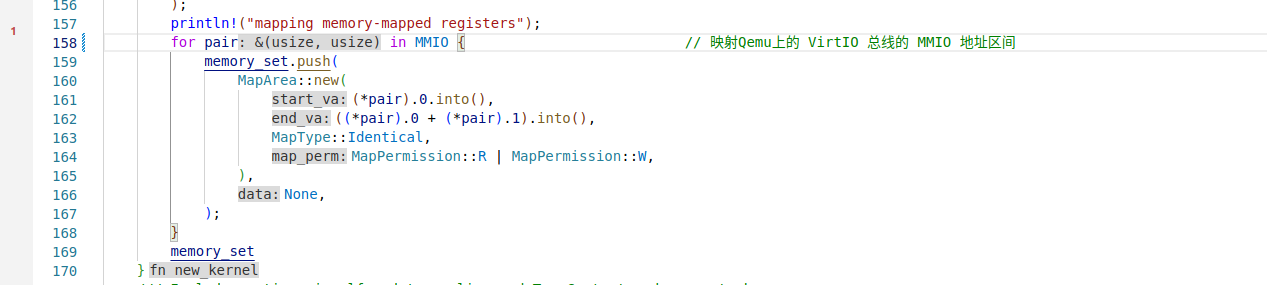
内存映射 I/O (MMIO, Memory-Mapped I/O) 指的是外设的设备寄存器可以通过特定的物理内存地址来访问,每个外设的设备寄存器都分布在没有交集的一个或数个物理地址区间中,不同外设的设备寄存器所占的物理地址空间也不会产生交集,且这些外设物理地址区间也不会和RAM的物理内存所在的区间存在交集
从Qemu for RISC-V 64 平台的 源码 中可以找到 VirtIO 外设总线的 MMIO 物理地址区间为从 0x10001000 开头的 4KiB 。为了能够在内核中访问 VirtIO 外设总线,我们就必须在内核地址空间中对特定内存区域提前进行映射:
// os/src/config.rs
#[cfg(feature = "board_qemu")]
pub const MMIO: &[(usize, usize)] = &[
(0x10001000, 0x1000),
];
如上面一段代码所示,在 config 子模块中我们硬编码 Qemu 上的 VirtIO 总线的 MMIO 地址区间(起始地址,长度)
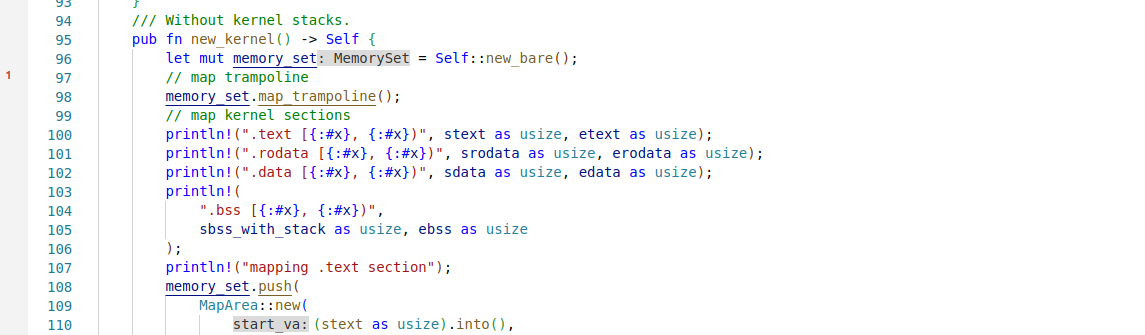
在new_kernel映射Qemu MMIO地址空间
内核索引结点层
OSInode 就表示进程中一个被打开的常规文件或目录
pub struct OSInode {
readable: bool,
writable: bool,
inner: Mutex<OSInodeInner>,
}
pub struct OSInodeInner {
offset: usize,
inode: Arc<Inode>,
}
impl OSInode {
pub fn new(
readable: bool,
writable: bool,
inode: Arc<Inode>,
) -> Self {
Self {
readable,
writable,
inner: Mutex::new(OSInodeInner {
offset: 0,
inode,
}),
}
}
}
文件描述符层
一个进程可以访问的多个文件,所以在操作系统中需要有一个管理进程访问的多个文件的结构,这就是 文件描述符表 (File Descriptor Table) ,其中的每个 文件描述符 (File Descriptor) 代表了一个特定读写属性的I/O资源。
为简化操作系统设计实现,可以让每个进程都带有一个线性的 文件描述符表 ,记录该进程请求内核打开并读写的那些文件集合
而 文件描述符 (File Descriptor) 则是一个非负整数,表示文件描述符表中一个打开的 文件描述符 所处的位置(可理解为数组下标)
进程通过文件描述符,可以在自身的文件描述符表中找到对应的文件记录信息,从而也就找到了对应的文件,并对文件进行读写.
因为 OSInode 也是一种要放到进程文件描述符表中文件,并可通过 sys_read/write 系统调用进行读写操作,因此我们也需要为它实现 File Trait :
impl File for OSInode {
fn readable(&self) -> bool { self.readable }
fn writable(&self) -> bool { self.writable }
fn read(&self, mut buf: UserBuffer) -> usize {
let mut inner = self.inner.lock();
let mut total_read_size = 0usize;
for slice in buf.buffers.iter_mut() {
let read_size = inner.inode.read_at(inner.offset, *slice);
if read_size == 0 {
break;
}
inner.offset += read_size;
total_read_size += read_size;
}
total_read_size
}
fn write(&self, buf: UserBuffer) -> usize {
let mut inner = self.inner.lock();
let mut total_write_size = 0usize;
for slice in buf.buffers.iter() {
let write_size = inner.inode.write_at(inner.offset, *slice);
assert_eq!(write_size, slice.len());
inner.offset += write_size;
total_write_size += write_size;
}
total_write_size
}
}
文件描述符表
为了支持进程对文件的管理,我们需要在进程控制块中加入文件描述符表的相应字段
pub struct TaskControlBlockInner {
pub trap_cx_ppn: PhysPageNum,
pub base_size: usize,
pub task_cx_ptr: usize,
pub task_status: TaskStatus,
pub memory_set: MemorySet,
pub parent: Option<Weak<TaskControlBlock>>,
pub children: Vec<Arc<TaskControlBlock>>,
pub exit_code: i32,
pub fd_table: Vec<Option<Arc<dyn File + Send + Sync>>>,
文件系统初始化
在上一小节我们介绍过,为了使用 easy-fs 提供的抽象和服务,我们需要进行一些初始化操作才能成功将 easy-fs 接入到我们的内核中。按照前面总结的步骤:
-
打开块设备。从本节前面可以看出,我们已经打开并可以访问装载有 easy-fs 文件系统镜像的块设备 BLOCK_DEVICE ;
-
从块设备 BLOCK_DEVICE 上打开文件系统;
-
从文件系统中获取根目录的 inode 。
rust
1、where的功能
// src/block_cache.rs
pub fn get_ref<T>(&self, offset: usize) -> &T
where
T: Sized,
{
let type_size = core::mem::size_of::<T>();
assert!(offset + type_size <= BLOCK_SZ);
let addr = self.addr_of_offset(offset);
unsafe { &*(addr as *const T) }
}
where 子句用于定义泛型函数的类型约束。这是 Rust 中泛型约束的一种表达方式,它允许函数或结构体指定其泛型参数必须满足的条件或特征。下面是这段代码中 where 子句的具体作用:
类型约束 T: Sized: 这里的 where 子句指定了 T 必须实现 Sized 特征。Sized 是 Rust 中的一个特殊特征,它表示类型的大小在编译时是已知的。几乎所有的 Rust 类型默认都实现了 Sized 特征,但有一些特殊情况(比如某些复杂的递归类型或者特定的特征对象)可能不满足这个条件。在这个函数中,由于需要计算类型 T 的大小(使用 core::mem::size_of::<T>()),因此这个约束是必要的。
总的来说,where 子句在这里用于确保泛型参数 T 是一个大小已知的类型,这对于函数的安全性和功能至关重要。
2、extern "rust-call"
extern "rust-call" 是一个函数调用约定(calling convention),用于定义函数或闭包如何接收参数和返回值。Rust 支持多种调用约定,每种调用约定规定了参数如何传递给函数,以及函数返回时如何处理返回值。不同的调用约定在不同的上下文中有不同的用途,比如与其他语言的互操作性或特定的优化。
extern "rust-call" 的用途
-
闭包的调用约定:
extern "rust-call"特别用于 Rust 的闭包。闭包可能捕获其环境中的变量,这导致它们的调用签名与普通函数略有不同。具体来说,当闭包捕获环境中的变量时,这些变量以一种特殊的方式传递给闭包。 -
对闭包的优化: 这种调用约定允许 Rust 对闭包调用进行优化。由于闭包可能捕获多个变量,使用
extern "rust-call"可以帮助编译器更有效地处理这些变量。 -
仅用于内部: 通常,
extern "rust-call"仅在 Rust 的内部实现中使用,不常在普通的 Rust 应用程序中直接使用。它是闭包实现的一部分,大多数情况下是隐藏的,开发者无需直接关心这个调用约定。
它通常是内部使用的,并且对于大多数 Rust 开发者来说是透明的。
如果你正在寻找如何与外部函数(如 C 语言函数)交互的例子,你可能会使用 extern "C" 调用约定,但这与 extern "rust-call" 的用途和上下文完全不同。在实际的 Rust 开发中,除非你在做底层的语言或编译器相关工作,否则你不太可能直接使用或遇到 extern "rust-call"。
3、Move关键字
fn main() {
let text = "Hello".to_string();
let say_hello = move || {
println!("{}", text);
};
// println!("{}", text); // 这行会导致编译错误
say_hello(); // 调用闭包
}
当闭包使用 move 关键字时,闭包会获取其使用的所有变量的所有权。这意味着这些变量的所有权会从它们原来的上下文转移到闭包本身。这对于线程间的数据传递或长期存储闭包时尤其有用。
4、FnOnce、FnMut、Fn的闭包
FnOnce类型的闭包
标准库中定义如下:
pub trait FnOnce<Args> {
type Output;//返回值类型
extern "rust-call" fn call_once(self, args: Args) -> Self::Output;
}
call_once函数第一个参数为self,也就是闭包自身。即是说,FnOnce闭包一旦被调用,闭包自身(看成一个结构体对象)的所有权被move到call_once函数内部。因此,外部可以调用FnOnce类型的闭包至多一次。
FnOnce闭包例子:
fn main() {
let text = "Hello".to_string();
let say_hello = move || {
println!("{}", text);
};
// println!("{}", text); // 这行会导致编译错误
say_hello(); // 调用闭包
}
FnOnce作为参数的闭包:
fn execute_once<F>(closure: F)
where
F: FnOnce(),
{
// 调用闭包
closure();
}
fn main() {
let greeting = String::from("Hello, Rust!");
// 使用 `move` 关键字,确保闭包拥有其捕获的环境
let print_greeting = move || {
println!("{}", greeting);
};
// 将闭包传递给函数
execute_once(print_greeting);
// 由于 `print_greeting` 是 `FnOnce` 类型的,它不能再次被调用
// 下面的代码将无法编译:
// execute_once(print_greeting); // 错误:值的所有权已经移动
}
FnMut闭包
pub trait FnMut<Args>: FnOnce<Args> {
extern "rust-call" fn call_mut(&mut self, args: Args) -> Self::Output;
}
FnMut闭中可以修改捕获的变量。
注意,FnMut trait“继承”了FnOnce trait,因此可以被当做FnOnce使用。call_mut()方法中传入的是引用&mut self,因此call_mut()可以被调用多次。
但是别忘了,如果将FnMut 当成FnOnce来使用,一旦调用了一次call_once()方法,就不能再调用其他方法了。
FnMut 闭包的例子
fn main() {
let mut name = String::from("hello");
// 捕获 &mut name,然后可以修改name
let mut c_mut = || {
name.push_str(" rust");
println!("c: {}", name);
};
c_mut();// c: hello rust
}
FnMut作为参数的闭包
fn execute_mutably<F>(mut closure: F)
where
F: FnMut(),
{
// 调用闭包
closure();
}
fn main() {
let mut count = 0;
// 创建一个 FnMut 类型的闭包
let mut increment = || {
count += 1;
println!("Count: {}", count);
};
// 多次调用闭包
execute_mutably(&mut increment);
execute_mutably(&mut increment);
execute_mutably(&mut increment);
// 注意:在这里,我们仍然可以使用 count 变量
println!("Final count: {}", count);
}
Fn闭包
pub trait Fn<Args>: FnMut<Args> {
extern "rust-call" fn call(&self, args: Args) -> Self::Output;
}
Fn trait“继承”了 FnMut trait,或者说FnMut 是 Fn 的 super trait。这也就意味着任何需要 FnOnce 或者 FnMut 的场合,都可以传入满足 Fn 的闭包。
如果只是调用Fn中的call()方法,这个call()可以被调用多次。
同样地,一旦调用了Fn中的call_once(),该闭包本身的所有权会被move走,就再也不能调用其他方法了。
在 Rust 中,Fn 特征代表那些可以被多次调用且不改变其捕获环境的闭包。这意味着闭包可以读取它所捕获的环境,但不能修改它。Fn 类型的闭包是最受限制的闭包类型,因为它们只能借用捕获的变量,无法修改它们。
Fn作为参数的闭包
fn execute_unchanged<F>(closure: F)
where
F: Fn(),
{
// 调用闭包
closure();
}
fn main() {
let value = 10;
// 创建一个 Fn 类型的闭包
let print_value = || {
println!("Value: {}", value);
};
// 多次调用闭包
execute_unchanged(print_value);
execute_unchanged(print_value);
execute_unchanged(print_value);
// 闭包外部仍可以使用 value 变量
println!("Outside the closure, value is still: {}", value);
}
5、u64 trailing_ones函数
返回尾数连续1的个数
fn main() {
let x = 0b010101101111111u64;
let y = x.trailing_ones();
println!("{:?}",y);
}
6、u32 min函数含义
fn main() {
let x = 0b010101101111111u32;
let y = x.min(5);
println!("{:?} => {:?}",x,y);
}
在 Rust 语言中,x.min(5) 表示调用 min 方法来比较 x 和 5,并返回它们中的最小值。
7、rust clap库
参考 : https://zhuanlan.zhihu.com/p/57966589
clap: 拍手,鼓掌
extern crate clap;
use clap::{Arg, App};
fn main() {
let matches = App::new("MayApp")
.version("0.1")
.author("kayryu")
.about("Learn use Rust Crate!")
.arg(Arg::with_name("verbose")
.short("v")
.multiple(true)
.help("verbosity level"))
.args_from_usage("-p, --path=[FILE] 'Target file you want to change'")
.get_matches();
if let Some(f) = matches.value_of("path") {
println!("path : {}", f);
}
}
1、我们使用version(),author()和 about()方法,提供程序的的一般信息。clap会自动添加两个参数:--help和--version(或他们的简短形式-h和-V)。
C:\Users\Administrator\Desktop\OS_RISC_V\rust_learn\test_code\target\debug>test_code.exe --help
MayApp 0.1
kayryu
Learn use Rust Crate!
USAGE:
test_code.exe [FLAGS] [OPTIONS]
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
-v verbosity level
OPTIONS:
-p, --path <FILE> Target file you want to change
2、通过Arg::with_name()调用创建一个简单的命名参数。
此结构有一些有用的方法,例如:
(1)、short(): 提供一个简短的单字母表格
(2)、required(): 指示参数是可选的还是必需的
(3)、takes_value() 和 default_value() 从--option=foo类似的参数读取值。*
(4)、multiple() 允许重复发生;
8、dyn关键字
在 Rust 中,dyn 是一个关键字,用于明确表示一个动态分发的特质对象(trait object)。
这是 Rust 中处理多态性的一种方式。使用 dyn 关键字可以使代码更清晰、更明确地表达意图,并有助于区分编译时多态(使用泛型)和运行时多态(使用特质对象)
trait Drawable {
fn draw(&self);
}
struct Circle {
radius: f64,
}
impl Drawable for Circle {
fn draw(&self) {
println!("Drawing a circle with radius: {}", self.radius);
}
}
struct Square {
side: f64,
}
impl Drawable for Square {
fn draw(&self) {
println!("Drawing a square with side: {}", self.side);
}
}
fn main() {
let shapes: Vec<Box<dyn Drawable>> = vec![
Box::new(Circle { radius: 1.0 }),
Box::new(Square { side: 2.0 }),
];
for shape in shapes {
shape.draw();
}
}
// Drawing a circle with radius: 1
// Drawing a square with side: 2
Circle和Square结构体都实现了Drawable特质。- 我们创建了一个
Drawable特质对象的Vec集合。使用dyn关键字表明Box<dyn Drawable>是一个特质对象。 - 在
main函数中,我们可以遍历这个集合并调用每个形状的draw方法。具体调用哪个实现是在运行时决定的。
这种方式的一个主要优点是它提供了一种灵活的方式来处理不同类型的对象,只要它们实现了相同的特质。这是实现多态的强大工具之一
#include <iostream>
// 基类 Shape
class Shape {
public:
virtual void draw() const {
std::cout << "Drawing a shape." << std::endl;
}
virtual ~Shape() {} // 虚析构函数
};
// 派生类 Circle
class Circle : public Shape {
public:
void draw() const override {
std::cout << "Drawing a circle." << std::endl;
}
};
// 派生类 Rectangle
class Rectangle : public Shape {
public:
void draw() const override {
std::cout << "Drawing a rectangle." << std::endl;
}
};
// 使用多态
int main() {
Shape* shapes[2];
shapes[0] = new Circle();
shapes[1] = new Rectangle();
// 循环遍历并调用 draw 方法
for (int i = 0; i < 2; ++i) {
shapes[i]->draw();
}
// 释放内存
for (int i = 0; i < 2; ++i) {
delete shapes[i];
}
return 0;
}
// Drawing a circle.
// Drawing a rectangle.
9、奇怪的错误
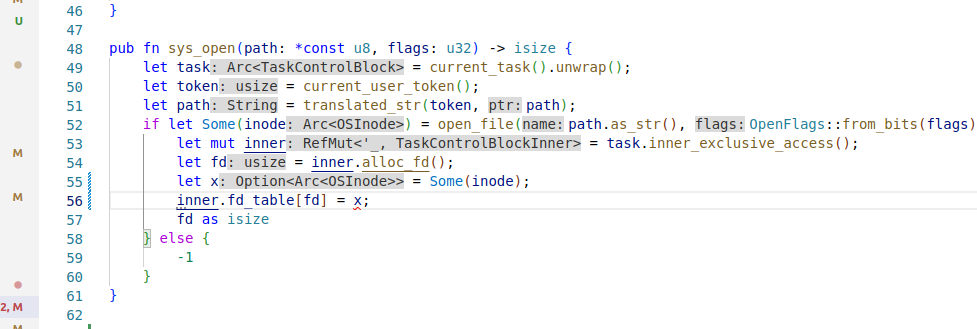
这样写正确
inner.fd_table[fd] = Some(inode);
这样写就错?
let x = Some(inode);
inner.fd_table[fd] = x;
而且也不是没有实现Copy trait的问题
课后练习
又一次跳过了编程题...
实验题
https://github.com/TL-SN/rCore/tree/lab6
实验题总是很耗费时间
在处理硬链接计数的时候,有些纠结,想到了这几种方法:
1、在DiskInode中添加nlink字段,但考虑作者追求128字节对齐,再添加一个字段无疑是对磁盘的一种浪费,故舍去了这种方法
2、在内存或者磁盘中维护一个全局BTreeMap,用来记录全局索引结点,但存储在内存中有点浪费内存,存放在磁盘中,每次读写开销比较大,比较纠结
3、每次获取nlink的时候都去遍历根目录,记录对应名字与InodeNumber的数目,但这样的话,如果文件很多,根目录下还包含很多目录的话,就不好处理了,每次遍历都会消耗很多时间
最后选择了第三种
问答题
1、 文件系统的功能是什么?
将数据以文件的形式持久化保存在存储设备上
2、目前的文件系统只有单级目录,假设想要支持多级文件目录,请描述你设想的实现方式,描述合理即可
允许创建目录即可
3、软链接和硬链接是干什么的?有什么区别?当删除一个软链接或硬链接时分别会发生什么?
软硬链接的作用都是给一个文件以”别名”,使得不同的多个路径可以指向同一个文件
软链接不会改变count计数的值,它本质就相当于一个快捷方式
硬链接会增加count计数的值,每链接一个文件count计数就会加1
每删除一个硬链接,count计数减一,当count计数减为0的时候就会被真正删除,磁盘空间被回收
之前有研究过:
https://www.cnblogs.com/lordtianqiyi/p/17545838.html
4、在有了多级目录之后,我们就也可以为一个目录增加硬链接了。在这种情况下,文件树中是否可能出现环路(软硬链接都可以,鼓励多尝试)?你认为应该如何解决?请在你喜欢的系统上实现一个环路,描述你的实现方式以及系统提示、实际测试结果。
为什么我的目录不能硬链接呢
5、目录是一类特殊的文件,存放的是什么内容?用户可以自己修改目录内容吗?
目录项(包含文件的Name与Inode位置)
用户可以修改目录内容
通常而言用户不能自己修改目录的内容,但是可以通过操作目录(如mv里面的文件)的方式间接修改。
6、在实际操作系统中,如Linux,为什么会存在大量的文件系统类型?
因为不同的文件系统有着不同的特性,比如对于特定种类的存储设备的优化,或是快照和多设备管理等高级特性,适用于不同的使用场景。
7、可以把文件控制块放到目录项中吗?这样做有什么优缺点?
可以,但如果文件控制块过大的话,会使目录项大小膨胀,导致检索时需要多次读取磁盘
8、为什么要同时维护进程的打开文件表和操作系统的打开文件表?这两个打开文件表有什么区别和联系?
方便对各进程关于文件的权限管理
操作系统的打开文件表的表项指向了操作系统的打开文件表
9、文件分配的三种方式是如何组织文件数据块的?各有什么特征(存储、文件读写、可靠性)?
(1)、连续分配
顺序存取速度快,但要求连续的存储空间,会产生外部碎片,不利于文件的扩充
(2)、链接分配
分为隐式链接分配与显式链接分配(FAT),这里只看隐式链接分配
可以动态处理文件大小,不会出现碎片,但只能按顺序访问文件的快,速度低
(3)、索引分配
隐式链接不能支持直接访问,又FAT需要占用较大内存,由此,提出了索引分配
索引分配的思想是让每一个文件都具有索引表,这样就可以某些必要的索引表调入内存,而不是把整个FAT调入内存
10、如果一个程序打开了一个文件,写入了一些数据,但是没有及时关闭,可能会有什么后果?如果打开文件后,又进一步发出了读文件的系统调用,操作系统中各个组件是如何相互协作完成整个读文件的系统调用的?
(若也没有flush的话)假如此时操作系统崩溃,尚处于内存缓冲区中未写入磁盘的数据将会丢失,同时也会占用文件描述符,造成资源的浪费。
系统调用 -> 设备独立性软件 -> 设备驱动程序
首先是系统调用处理的部分,将这一请求转发给文件系统子系统,文件系统子系统再将其转发给块设备子系统,最后再由块设备子系统转发给实际的磁盘驱动程序读取数据,最终返回给程序。
11、文件系统是一个操作系统必要的组件吗?是否可以将文件系统放到用户态?这样做有什么好处?操作系统需要提供哪些基本支持?
是
可以,但是一些访问权限不好设置
不是,如在本章之前的rCore就没有文件系统。
可以,如在Linux下就有FUSE这样的框架可以实现这一点。这样可以使得文件系统的实现更为灵活,开发与调试更为简便。操作系统需要提供一个注册用户态文件系统实现的机制,以及将收到的文件系统相关系统调用转发给注册的用户态进程的支持
一些思考
1、把app程序全部写入fs.img文件系统镜像
2、os好像没有实现文件描述符
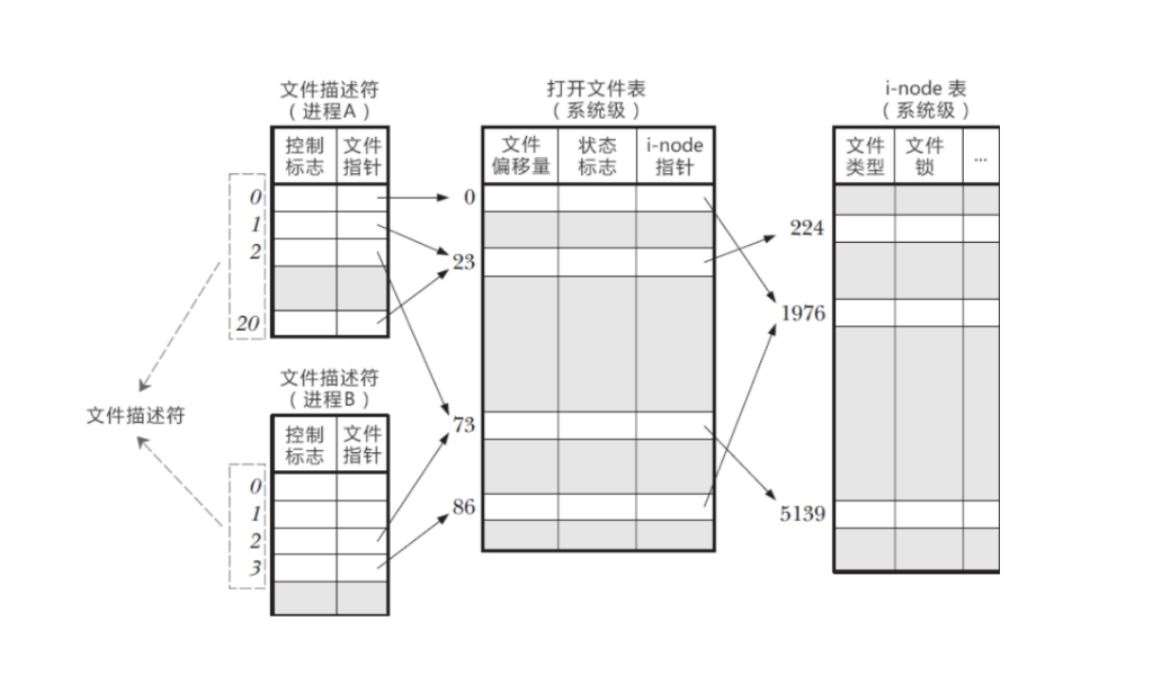
3、文件管理器采用松耦合模块化的设计思路,被单拎出来写
4、内存映射 I/O (MMIO, Memory-Mapped I/O)设置在 0x10001000 的物理地址位置上允许访问外设设备寄存器
5、重写sys_open、sys_write、sys_read函数,使其支持文件系统
write()=> sys_write => OSInode(trait File) => Inode(write_at) => DiskInode(write_at)
6、Inode与DiskInode
Inode对DiskInode进行了封装,Inode记录了其DiskInode的位置,DiskInode 放在磁盘块中比较固定的位置,而 Inode 是放在内存中的记录文件索引节点信息的数据结构。
DiskNode更底层,记录了数据块数目、大小、一级索引、二级索引,获取块次序、扩容,它才是真正管理底层资源的结点,并且inode号代表的也是DiskNode在磁盘的位置(inode结点中也记录了idx与offset)
Inode号与disknode的转化关系如下:
pub fn get_disk_inode_pos(&self, inode_id: u32) -> (u32, usize) { // 返回值1: inode_id对应的是该id的diskInode索引节点对应的该文件系统的block号(次序)
let inode_size = core::mem::size_of::<DiskInode>(); // 返回值2: 该diskinode索引节点在块中的偏移
let inodes_per_block = (BLOCK_SZ / inode_size) as u32; // 每个块占有的inode数
let block_id = self.inode_area_start_block + inode_id / inodes_per_block;
(
block_id,
(inode_id % inodes_per_block) as usize * inode_size,
)
}
pub fn get_inode_id_by_blockid_and_offset(&self, block_id: usize, offset: usize) -> usize {
let inode_size = core::mem::size_of::<DiskInode>();
let inodes_per_block = (BLOCK_SZ / inode_size) as usize;
return (block_id - self.inode_area_start_block as usize) * inodes_per_block + offset / inode_size;
}
而Inode更像是为了面向os 而对DiskInode进行的抽象,创建文件、显示目录下的所有文件,仅仅在内存中出现
OSNode是针对进程的,每个进程都会对应不同的OSNode
EasyFileSystem 实现了磁盘布局并能够将磁盘块有效的管理起来。但是对于文件系统的使用者而言,他们往往不关心磁盘布局是如何实现的,而是更希望能够直接看到目录树结构中逻辑上的文件和目录。为此需要设计索引节点 Inode 暴露给文件系统的使用者,让他们能够直接对文件和目录进行操作
DiskInode更接近我在408里学的索引结点
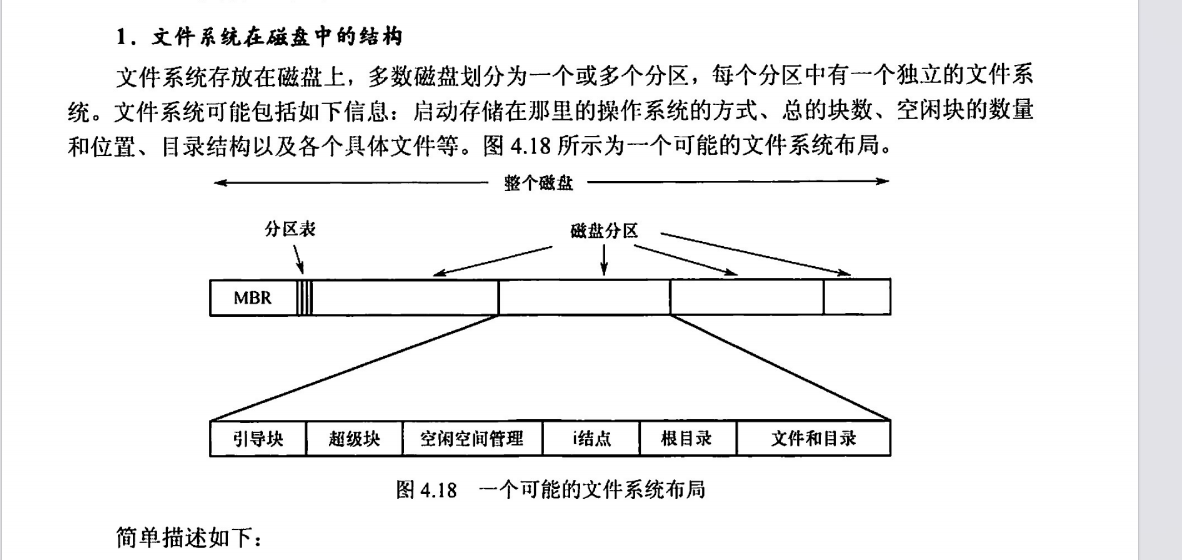
7、一个文件系统的布局

 浙公网安备 33010602011771号
浙公网安备 33010602011771号