rCore_Lab4
OS知识点
VPN : 虚拟页号
PPN : 物理页号
1、静态分配与动态内存分配
静态分配 : 在编译器编译程序时已经知道这些变量所占的字节大小,于是给它们分配一块固定的内存将它们存储其中,这样变量在栈帧/数据段中的位置就被固定了下来。
动态内存分配: 分配可变大小的空间
2、内碎片与外碎片
内存碎片是指无法被分配和使用的空闲内存空间。可进一步细分为内碎片和外碎片:
- 内碎片:已被分配出去(属于某个在运行的应用)内存区域,占有这些区域的应用并不使用这块区域,操作系统也无法利用这块区域。
- 外碎片:还没被分配出去(不属于任何在运行的应用)内存空闲区域,由于太小而无法分配给提出申请内存空间的应用
(死去的记忆开始攻击我..)
头甲龙
实现堆动态分配
- 初始时能提供一块大内存空间作为初始的“堆”。在没有分页机制情况下,这块空间是物理内存空间,否则就是虚拟内存空间。
- 提供在堆上分配和释放内存的函数接口。这样函数调用方通过分配内存函数接口得到地址连续的空闲内存块进行读写,也能通过释放内存函数接口回收内存,以备后续的内存分配请求。
- 提供空闲空间管理的连续内存分配算法。相关算法能动态地维护一系列空闲和已分配的内存块,从而有效地管理空闲块。
- (可选)提供建立在堆上的数据结构和操作。有了上述基本的内存分配与释放函数接口,就可以实现类似动态数组,动态字典等空间灵活可变的堆数据结构,提高编程的灵活性。
这里作者为了简便处理,使用了现成的伙伴分配器
之后我们就
1、实例化全局堆分配器
这里我们把伙伴分配器提供的LockedHeap实例化为全局变量,来作为我们的全局堆分配器
static HEAP_ALLOCATOR: LockedHeap = LockedHeap::empty();
2、提供一块大内存空间作为初始的“堆”
调用init函数,为全局堆分配器提供一个大小为0x30_0000字节的可分配空间
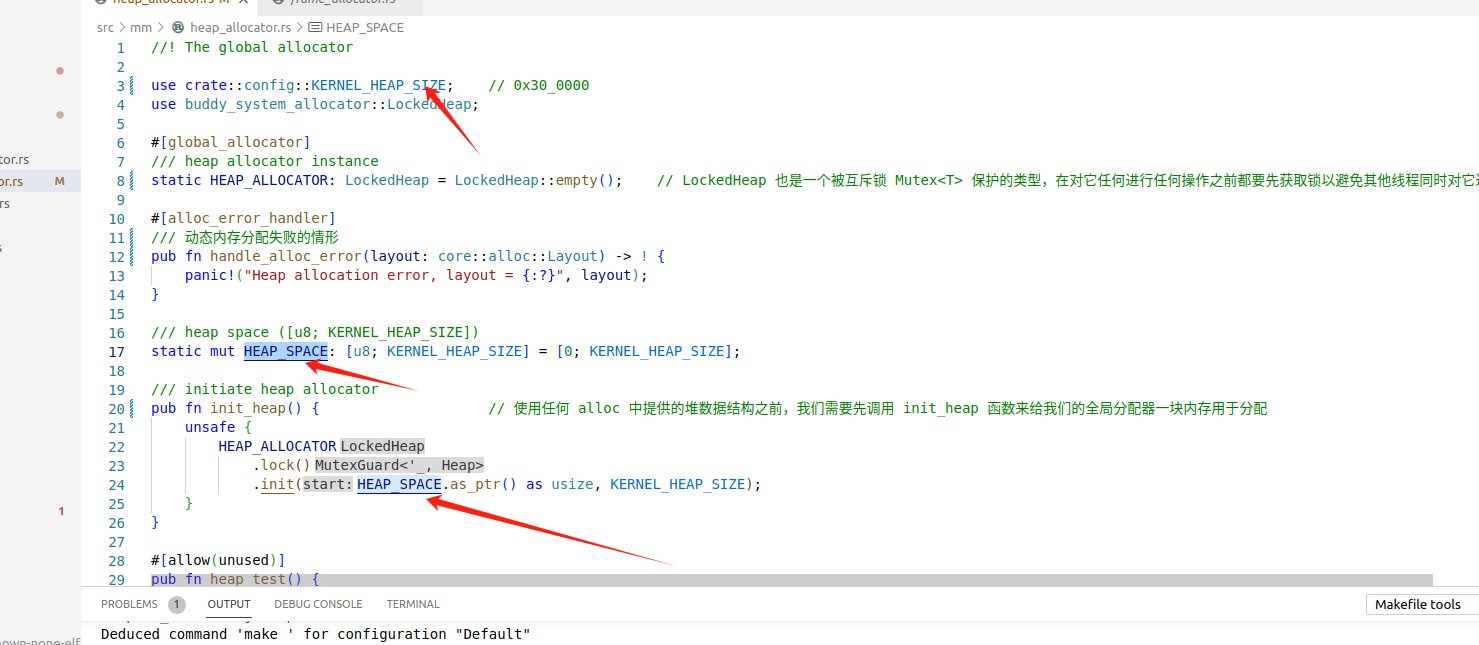
3、设置分配失败的panic
分页
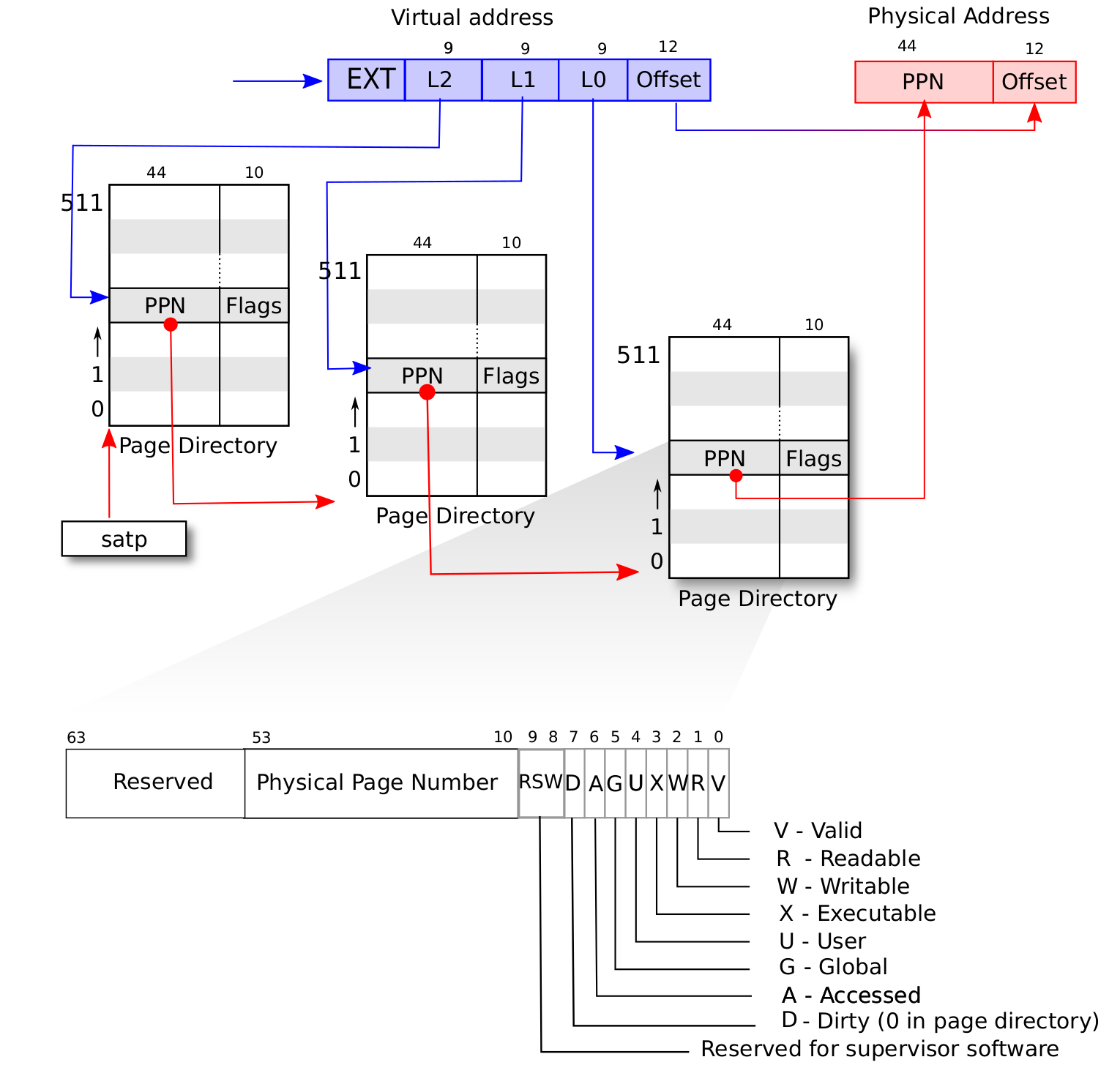
1、RISC-V采取的是SV39 分页硬件机制,是三级页表
2、默认情况下 MMU 未被使能(启用),此时无论 CPU 位于哪个特权级,访存的地址都会作为一个物理地址交给对应的内存控制单元来直接访问物理内存。
我们可以通过修改 S 特权级的一个名为 satp 的 CSR 来启用分页模式,在这之后 S 和 U 特权级的访存地址会被视为一个虚拟地址,它需要经过 MMU 的地址转换变为一个物理地址,再通过它来访问物理内存;
stap寄存器如下:

上图是 RISC-V 64 架构下 satp 的字段分布,含义如下:
-
MODE 控制 CPU 使用哪种页表实现;
-
ASID 表示地址空间标识符,这里还没有涉及到进程的概念,我们不需要管这个地方;
-
PPN 存的是根页表所在的物理页号。这样,给定一个虚拟页号,CPU 就可以从三级页表的根页表开始一步步的将其映射到一个物理页号。
当 MODE 设置为 0 的时候,代表所有访存都被视为物理地址;
而设置为 8 的时候,SV39 分页机制被启用,所有 S/U 特权级的访存被视为一个 39 位的虚拟地址,它们需要先经过 MMU 的地址转换流程,如果顺利的话,则会变成一个 56 位的物理地址来访问物理内存;否则则会触发异常,这体现了分页机制的内存保护能力。
这个东西...让我想起了x86下的cr3寄存器,感觉有异曲同工之妙
3、地址格式组成

地址转换是以页为单位进行的,在地址转换的前后地址的页内偏移部分不变。可以认为 MMU 只是从虚拟地址中取出 27 位虚拟页号,在页表中查到其对应的物理页号(如果存在的话),最后将得到的44位的物理页号与虚拟地址的12位页内偏移依序拼接到一起就变成了56位的物理地址。
4、RISC-V 64 架构中虚拟地址只有 39 位的原因

也就是说RISC-V的虚拟地址只能是 低于256G或高于0xffff_ffc0_0000_0000
即高256G与低256G
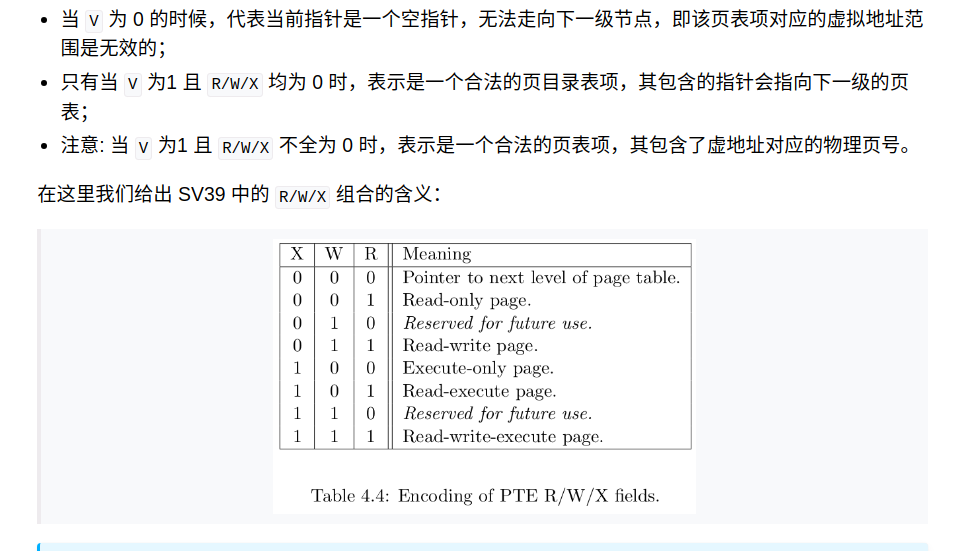
5、页表项
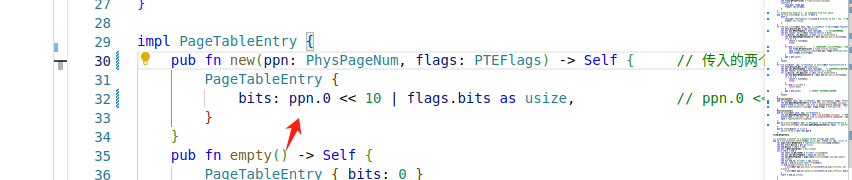
物理页号和全部的标志位以某种固定的格式保存在一个结构体中,它被称为 页表项 (PTE, Page Table Entry)
页表项其实就是页表中指向物理地址的8字节单元


PPN是物理页号
V(Valid):仅当位 V 为 1 时,页表项才是合法的;
R(Read)/W(Write)/X(eXecute):分别控制索引到这个页表项的对应虚拟页面是否允许读/写/执行;
U(User):控制索引到这个页表项的对应虚拟页面是否在 CPU 处于 U 特权级的情况下是否被允许访问;
A(Accessed):处理器记录自从页表项上的这一位被清零之后,页表项的对应虚拟页面是否被访问过;
D(Dirty):处理器记录自从页表项上的这一位被清零之后,页表项的对应虚拟页面是否被修改过。
除了 G 外的上述位可以被操作系统设置,只有 A 位和 D 位会被处理器动态地直接设置为 1 ,表示对应的页被访问过或修过( 注:A 位和 D 位能否被处理器硬件直接修改,取决于处理器的具体实现)
非叶节点(页目录表,非末级页表):

6、多级页表
在这种三级页表的树结构中,自上而下分为三种不同的节点:一级/二级/三级页表节点。树的根节点被称为一级页表节点;一级页表节点可以通过一级页索引找到二级页表节点;二级页表节点可以通过二级页索引找到三级页表节点;三级页表节点是树的叶节点,通过三级页索引可以找到一个页表项。
大页的概念:
大页就是将 4kb的页扩展到2MB甚至1GB,本质上就是用一级或者几级的页表索引为代价换取页表大小
7、SV39地址转换过程
8、快表
我们知道,物理内存的访问速度要比 CPU 的运行速度慢很多。如果我们按照页表机制循规蹈矩的一步步走,将一个虚拟地址转化为物理地址需要访问 3 次物理内存,得到物理地址后还需要再访问一次物理内存,才能完成访存。这无疑很大程度上降低了系统执行效率。
实践表明绝大部分应用程序的虚拟地址访问过程具有时间局部性和空间局部性的特点。因此,在 CPU 内部,我们使用MMU中的 快表(TLB, Translation Lookaside Buffer) 来作为虚拟页号到物理页号的映射的页表缓存。当我们要进行一个地址转换时,会有很大可能对应的地址映射在近期已被完成过,所以我们可以先到 TLB 缓存里面去查一下,如果有的话我们就可以直接完成映射,而不用访问那么多次内存了。

byd,考研的时候那张卷子上关于MMU与TLB的知识点就选错了,如今终于彻底明白了,可惜明白的太晚了,哭了
9、按需分配
页表的一种最简单的实现是线性表,也就是按照地址从低到高、输入的虚拟页号从0开始递增的顺序依次在内存中(我们之前提到过页表的容量过大无法保存在 CPU 中)放置每个虚拟页号对应的页表项.
由于每个页表项的大小是8字节,我们只要知道第一个页表项(对应虚页号为0)被放在的物理地址base_addr,就能直接计算出每个输入虚拟页号对应页表项所在位置
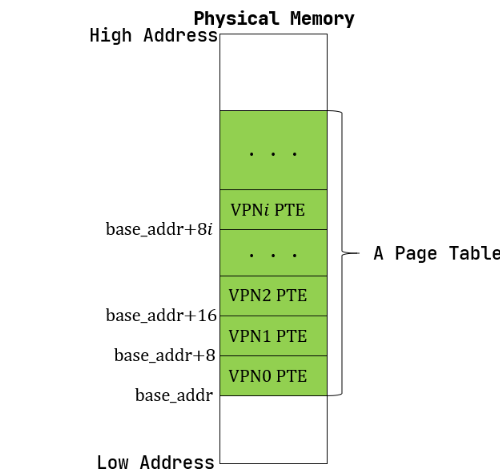
但如果这样分配的话,将远远超出我们的内存限制由于虚拟页号有 \(2^{27}\)种,每个虚拟页号对应一个
8字节的页表项,则每个页表都需要消耗掉1GB内存!
而实际能用到的空间大概只有几十MB甚至几十KB,这就导致剩下的空间被浪费了(因为如果我们采取这种方法的话,页表的存储必须是整块整块的空间,中间不能穿插着数据)
我们可以采取按需分配来优化,有多少合法的虚拟页号,我们就维护一个多大的映射,并为此使用多大的内存用来保存映射
物理页帧管理
首先初始化,获取可用物理地址的范围
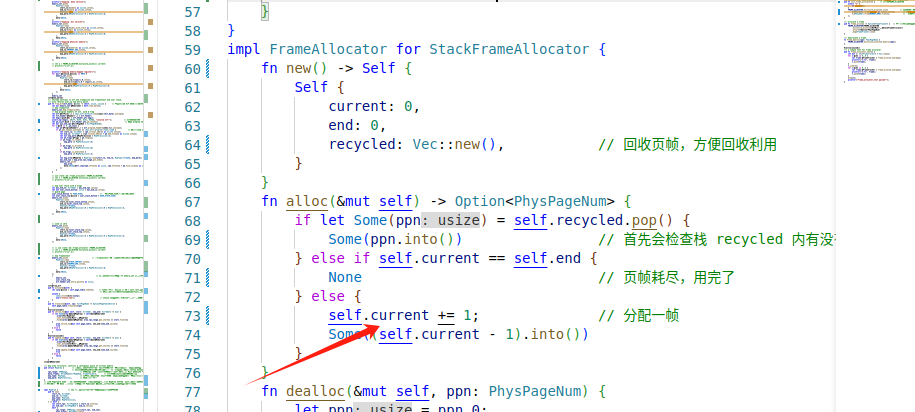
分配物理页帧的时候
- 首先会检查栈 recycled 内有没有之前回收的物理页帧,如果有的话直接弹出栈顶并返回物理页号
- 若没有之前回收的,则看剩余的物理页帧有没有分配完,若没有分配完,则分配一帧,若分配完了,返回None,分配页帧失败
回收物理页帧的时候
- 首先检测合法性
- 该页面之前一定被分配出去过,因此它的物理页号一定小于current
- 该页面没有正处在回收状态,即它的物理页号不能在栈 recycled 中找到。
- 回收
虚拟页表的初始地址
user程序的访存地址会被视为一个当前地址空间( satp CSR 给出当前多级页表根节点的物理页号)中的一个虚拟地址,需要 MMU 查相应的多级页表完成地址转换变为物理地址
lab4的物理页帧分配方式
物理页帧分配具有两种方式
(1)、Identical
Identical是虚拟页号映射相同的物理页号
(2)、famed
framed是虚拟页号映射随机的虚拟页号
使用famed分配时,会有一个计数器(这个计数器指向的就是物理页号)加一
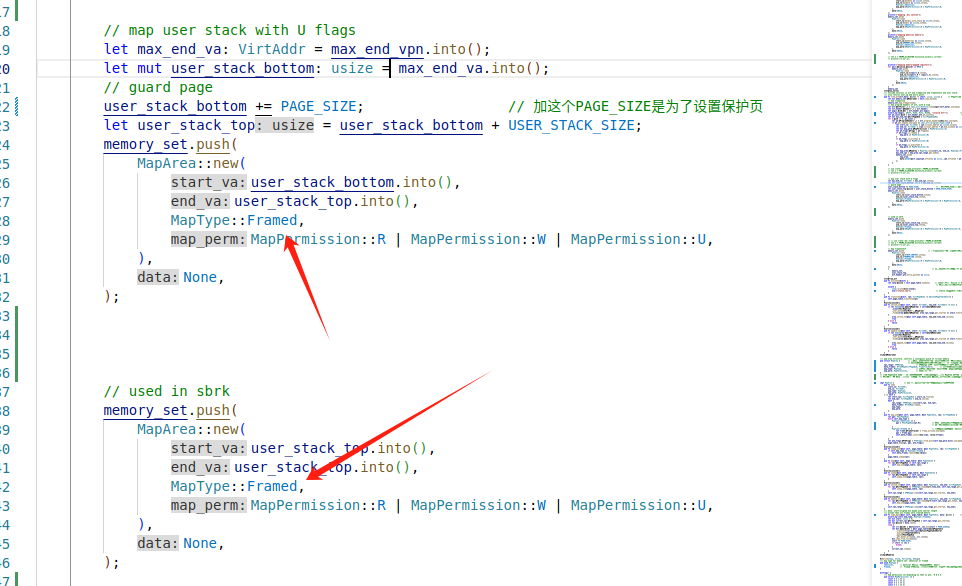
使用Identical分配时,虚页号与物理页号相同
1、famed物理页帧的全局分配器以ekernel为起始页号,0x80800000为结束页号

2、分配user时使用的是framed

3、分配kernel的时候使用的是Identical
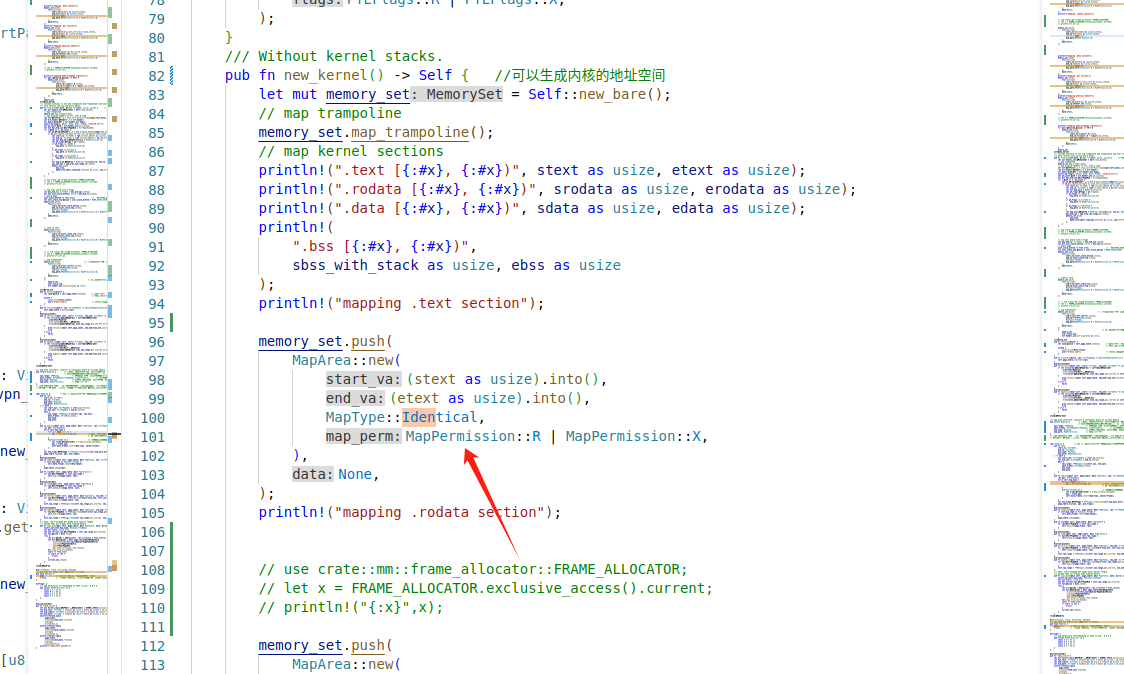
这也是为什么分配framed的alloc的计数器范围在ekernel ~ Maxend之间了
映射方法
作者采用的是最简单的恒等映射方式,还有一种非常著名的映射方式是页表自映射,之前用windbg调试winxp内核的时候,其内部就是使用的页表自映射
关于页表自映射的理解,可以看这篇: https://zhuanlan.zhihu.com/p/452598045
大体上就是想给一级目录表、二级目录表等目录表分配一个虚拟地址来让用户访问
但是,按照一般的方法,一以级页表为例,其页表内保存的是二级页表的地址,如果拿出一个页表项来存一级页表的地址,那会占用本来存放的二级页表地址的一个单元,于是,人们想到了这样巧妙的方法:
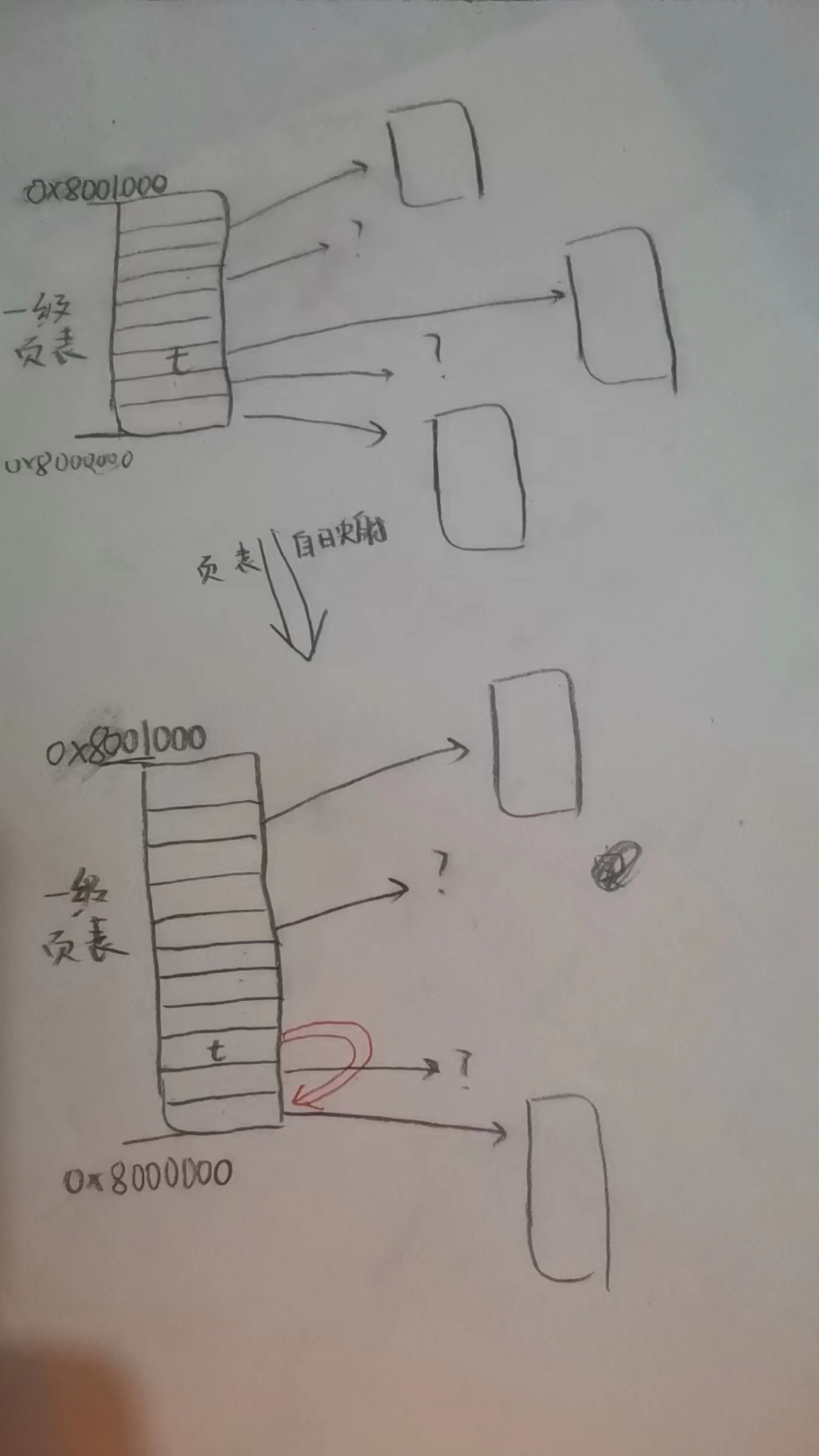
事实上,图中t所在地址一般就是0x8000000,即一级页表的物理地址
unmap与map实现机理
他们都依赖于一个很重要的过程,即在多级页表中找到一个虚拟地址对应的页表项。
找到之后,只要修改页表项的内容即可完成键值对的插入和删除。
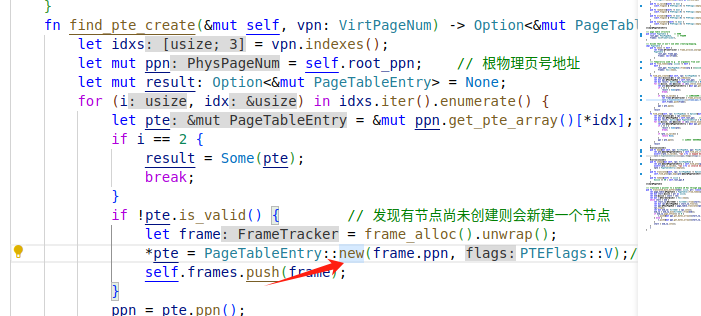
在寻找页表项的时候,可能出现页表的中间级节点还未被创建的情况,这个时候我们需要手动分配一个物理页帧来存放这个节点,并将这个节点接入到当前的多级页表的某级中。
map流程:
map函数传入虚拟页号和页标志
- 把27位的虚拟页号根据三级分页机制划分为3个9位的页内下标
- 根据页内下标顺序一次寻找一级页表中对应的页表项,二级页表对应的页表项、三级页表对应的页表项
- 如果在寻找途中发现中间经过的某页表还未分配,则调用frame_alloc函数进行分配
- 最后找到对应的物理页,判断该页是否被分配过
- 若没有被分配过,则分配该页(赋予有效位与传入的符号位)
这样一看,map的核心就是改一下虚页对应物理页的有效位,同时分配一下中间页表。需要注意的是,其并没有为页帧执行frame_alloc函数分配堆,而仅仅标记了一下,也是,还没有要求分配内存呢
并且我们还能看到,页表项里的PPN,是在map的时候写入的:
unmap
unmap的实现与上面一样,唯一的不同就是中间页表没有未被分配的了(除非给的是错误的虚拟地址)
map物理页的两种方式
第一种是恒等映射方式,这里,提供的虚拟页号就是我们要map的物理页号
另一种叫framed,这里,os会调用frame_alloc函数通过vpn来分配一个随机地址的物理页
我们需要给s层内核也套上一层虚拟地址
如何让用户地址空间与内核地址空间进行平滑的切换
1、user在trap,进入内核时,需要修改satp,来切换根页表,但刚切换完毕之后,其虚拟地址对应的物理地址被改变(虚拟地址到物理地址映射方式改变了),那相邻的指令对应的物理地址也发生了变化
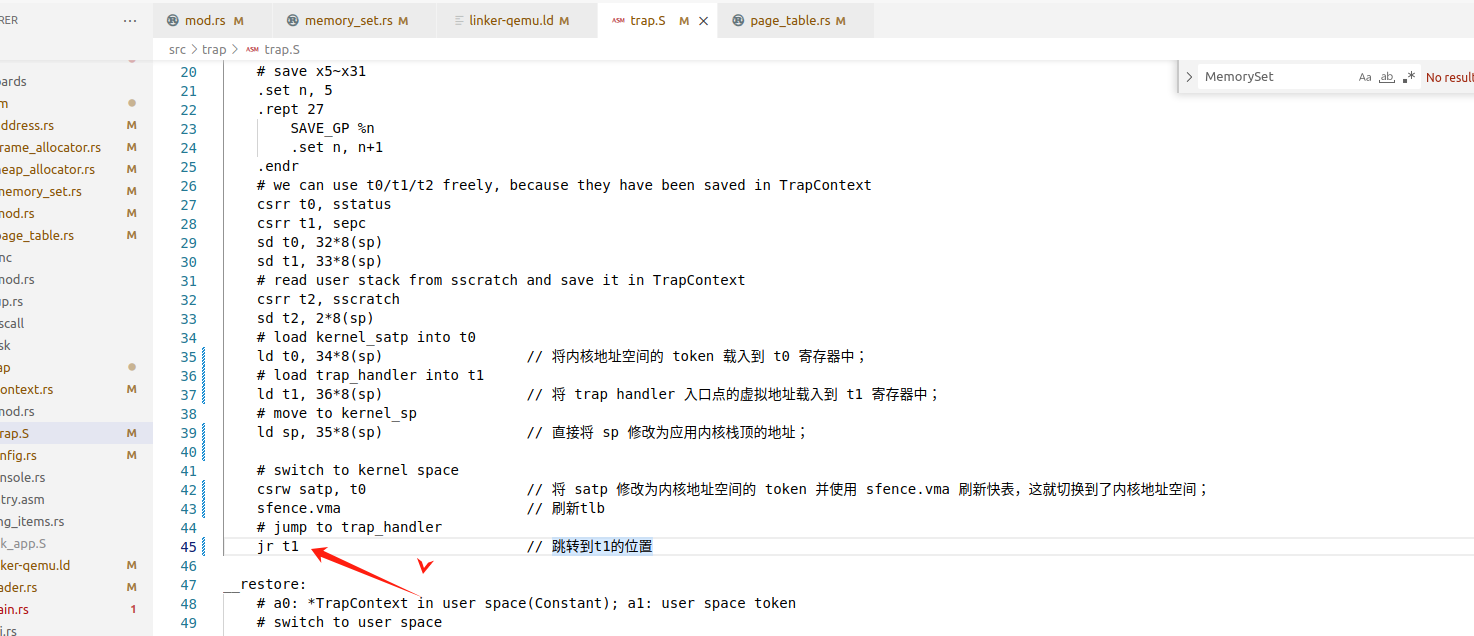
比如说这里,已经切换了页目录地址,为何这条指令还生效呢,并且为什么就能笃定切换根页表后t1指向的位置不变呢
事实上,无论在os还是在用户操作系统上,我们都选择把trap.S汇编所在位置的虚拟地址放到最高点,而把trap_hander函数所在位置的虚拟地址放在次高点



并且,由于我们采取的是恒等映射,应用的用户态虚拟地址空间和操作系统内核的内核态虚拟地址空间对切换地址空间的指令所在页的映射方式均是相同的,这就说明了这段切换地址空间的指令控制流仍是可以连续执行的。
2、为什么使用jr指令而不用call指令呢:

看的不是特别明白
rust知识点
对于c++里面一般的指针,比如malloc得到的指针,如果我们不free释放掉,就算指针离开作用域被销毁,其指向的堆空间也不会被释放
1、一些智能指针
Box
看一下 std::unique_ptr 的特点
unique_ptr 不共享它的指针。它无法复制到其他 unique_ptr,无法通过值传递到函数,也无法用于需要副本的任何标准模板库 (STL) 算法。只能移动unique_ptr
拷贝一个std::unique_ptr将不被允许,因为如果你拷贝一个std::unique_ptr,那么拷贝结束后,这两个std::unique_ptr都会指向相同的资源,它们都认为自己拥有这块资源(所以都会企图释放)。因此std::unique_ptr是一个仅能移动(move_only)的类型。当指针析构时,它所拥有的资源也被销毁。
unique_ptr 会在栈上分配,然后在离开作用域之后进行释放,删除里面持有的 Resource 对象。
Arc
可以将 Mutex<T> 看成 RefCell<T> 的多线程版本, 因为 RefCell<T> 是只能在单线程上使用的。而且 RefCell<T> 并不会在堆上分配内存,它仅用于基于数据段的静态内存 分配。
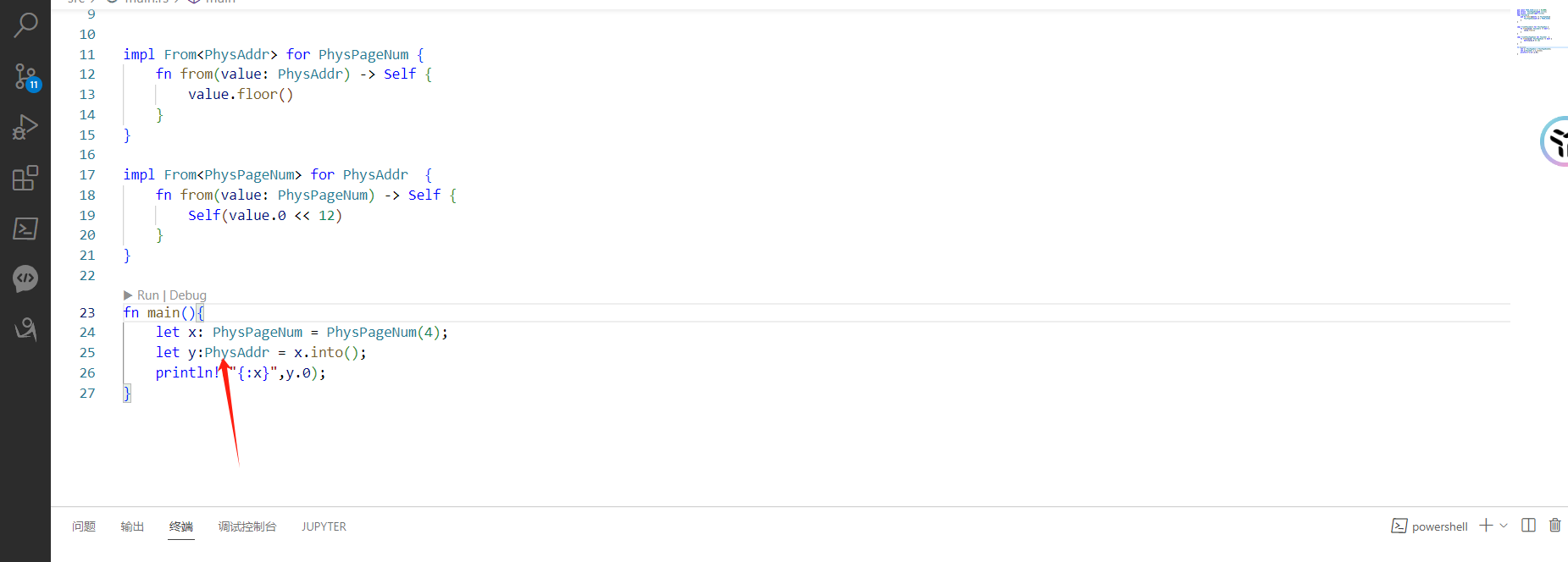
2、From / to
一般而言,当我们为类型 U 实现了 From<T> Trait 之后,可以使用 U::from(_: T) 来从一个 T 类型的实例来构造一个 U 类型的实例;而当我们为类型 U 实现了 Into
当我们为 U 实现了 From<T> 之后,Rust 会自动为 T 实现 Into<U> Trait,因为它们两个本来就是在做相同的事情。因此我们只需相互实现 From 就可以相互 From/Into 了。
最常见的例子就是这样了:
String就是实现了from 函数,可以从&str类型转化为String类型
let my_str = "hello";
let my_string = String::from(my_str);
比我我们顶定义一个结构体,来实现from函数:
这里我们为Number结构体实现from函数,能从int类型转化
use std::convert::From;
#[derive(Debug)]
struct Number {
value: i32,
}
impl From<i32> for Number {
fn from(item: i32) -> Self {
Number { value: item }
}
}
fn main() {
let num = Number::from(30);
println!("My number is {:?}", num);
}
into的话就是反过来:
use std::convert::From;
#[derive(Debug)]
struct Number {
value: i32,
}
impl From<i32> for Number {
fn from(item: i32) -> Self {
Number { value: item }
}
}
fn main() {
let int = 5;
// 试试删除类型说明
let num: Number = int.into();
println!("My number is {:?}", num);
}
不过反过来的时候,使用.into函数需要 显式 指出目标类型,要不然你实现了这么多的into,编译器该怎么区别呢
3、bitflags
bitflags 是一个 Rust 中常用来比特标志位的 crate。它提供了一个 bitflags! 宏,可以将一个 u8 封装成一个标志位的集合类型,支持一些常见的集合运算。
use bitflags::*;
bitflags! { // 页表项中的标志位 PTEFlags
/// page table entry flags
pub struct PTEFlags: u8 {
const V = 1 << 0;
const R = 1 << 1;
const W = 1 << 2;
const X = 1 << 3;
const U = 1 << 4;
const G = 1 << 5;
const A = 1 << 6;
const D = 1 << 7;
}
}
fn main(){
let x = PTEFlags::V | PTEFlags::R | PTEFlags::W;
println!("{}",x.bits as u8);
let y = PTEFlags::from_bits(127);
println!("{:?}",y);
}

4、if let 用法
在一些场合下,用 match 匹配枚举类型并不优雅
let optional = Some(7);
match optional {
Some(i) => {
println!("This is a really long string and `{:?}`", i);
},
_ => {},
};
if let 在这样的场合要简洁得多
if let 结构读作:若 let 将 number 解构成 Some(i),则执行{}
fn main() {
let number = Some(7);
let letter: Option<i32> = None;
let emoticon: Option<i32> = None;
// `if let` 结构读作:若 `let` 将 `number` 解构成 `Some(i)`,则执行
if let Some(i) = number {
println!("Matched {:?}!", i);
}
// 如果要指明失败情形,就使用 else:
if let Some(i) = letter {
println!("Matched {:?}!", i);
} else {
// 解构失败。切换到失败情形。
println!("Didn't match a number. Let's go with a letter!");
};
}
RAII
参考 https://vegarden.github.io/2016/09/25/rust-1/
什么是RAII
RAII全称是Resource Acquisition Is Initialization 资源获取是初始化
RAID: Resource Reclamation Is Destruction 资源回收就是析构
RAII提倡把内存尽量分配到栈上
简单来讲,一般我们说的RAII就是,在定义对象的时候实现一个析构函数负责释放资源,在变量作用域结束的时候,编译器会自动帮我们加上对析构函数的调用,我们使用这样的对象时,就不需要手动释放资源,从而实现了资源的自动释放。
举一个RAII发挥作用的例子:
use std::sync::Mutex;
fn locked_func(m: &Mutex<()>) {
let _lock = m.lock().unwrap();
}
fn main() {
let lock = Mutex::new(());
locked_func(&lock);
let _lock = lock.lock().unwrap();
println!("Shouldn't reach here if RAII doesn't work.");
}
这个程序有一个互斥锁,locked_func函数和main函数都要获取它,如果在locked_func结束时互斥锁没有被释放,则main函数会在获取锁那里被阻塞,程序不会结束,也不会有输出。而实际的行为是相反的,程序会一直执行结束,这说明locked_func结束时互斥锁被释放了
GC与RC
GC是garbage collection(垃圾回收)的全称,从广义上来讲包含tracing garbage collection和reference counting。
其中tracing garbage collection是我们一般见到的GC,从一些引用根开始遍历,标记遍历到的对象,然后将没有标记的释放;而reference counting每新建一个引用,就将对象的引用计数加1,每有一个引用消失,就将计数见减1,引用计数为0时,对象被释放。
不过一般我们说GC的时候,是狭义地指tracing garbage collection,也是最常见的GC;而对于reference counting,一般称之为RC。没有特殊指出的话,本文就按照一般的习惯用法,按照狭义理解,分别叫它们GC和RC。
RAII的优缺点
RAII相对与GC的优势之一显然是性能和实时性更高,消耗更小
RAII能够管理所有种类的资源,而GC只能管理内存
对于内存外的管理,GC的手段:

RAII的缺陷在于,有些数据的生命周期更加动态,在运行时才能确定,RAII就不太好对它们进行有效的管理。因为运行时才能确定的动态生命周期,要管理它们,必然需要运行时的开销,而RAII没有运行时开销,什么时候释放内存都在编译时决定了。
结合lab4的FrameTracker了解RAII
作者说,这里使用了RAII的思想,作者使用RAII思想对栈资源(或者说栈物理页帧)进行了管理

本来fram_alloc函数应该返回一个PhysPageNum变量,但作者把这个变量又套了一层FrameTracker。
实际上FramTracker结构体/类被实现了drop析构函数,这样当fram_alloc得到的变量被销毁时,程序会自动调用drop析构函数,之后调用fram_dealloc函数释放分配的物理帧,依此实现自动资源释放

ps:这里的alloc的实现只是简单的计数加减,因此叫资源分配与释放有些牵强

所有权的转移
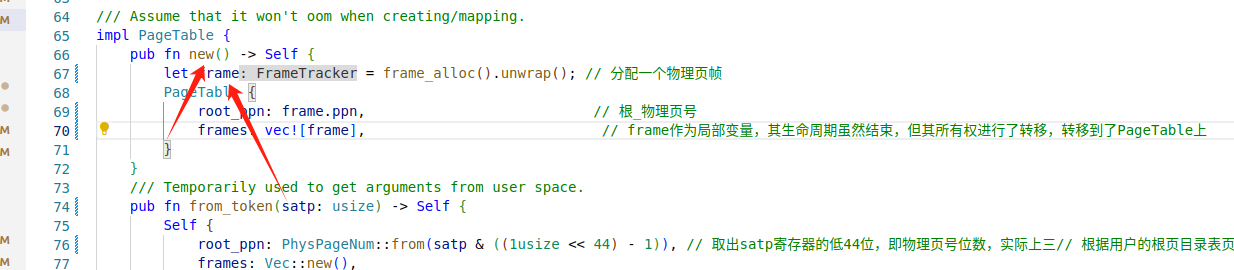
可以注意到,随着new函数的结束,frame会被销毁,但是所有权被转移到了PageTable上
课后练习
编程题
1、使用sbrk,mmap,munmap,mprotect内存相关系统调用的linux应用程序。
sbrk函数
#include <unistd.h>
#include <stdio.h>
int main() {
void* initial_brk = sbrk(0); // 获取当前的 break 点
printf("Initial break: %p\n", initial_brk);
int increment = 1024; // 增加数据段的大小
void* new_brk = sbrk(increment);
if (new_brk == (void*)-1) {
perror("sbrk failed");
return -1;
}
void* current_brk = sbrk(0); // 再次获取当前的 break 点
printf("New break: %p\n", current_brk);
// 使用新分配的内存...
// 回退到原来的 break 点
sbrk(-increment);
return 0;
}
mmap函数
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main() {
// 打开文件
int fd = open("ttt.txt", O_RDWR);
if (fd == -1) {
perror("Error opening file");
return 1;
}
// 获取文件的大小
struct stat sb;
if (fstat(fd, &sb) == -1) {
perror("Error getting file size");
return 1;
}
// 执行内存映射
char *mapped = (char *)mmap(NULL, sb.st_size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (mapped == MAP_FAILED) {
perror("Error mapping file");
return 1;
}
// 现在可以通过映射区域来访问文件内容了
// 例如,修改文件的一个字符
mapped[0] = 'J';
// 同步映射区域到文件
if (msync(mapped, sb.st_size, MS_SYNC) == -1) {
perror("Error syncing file");
}
// 解除映射
if (munmap(mapped, sb.st_size) == -1) {
perror("Error un-mapping file");
}
// 关闭文件
close(fd);
return 0;
}
munmap函数
同上
mprotect函数
#include <sys/mman.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main() {
// 分配一块内存
size_t pageSize = getpagesize();
void *mem = mmap(NULL, pageSize, PROT_READ | PROT_WRITE, MAP_ANONYMOUS | MAP_PRIVATE, -1, 0);
strcpy((char *)mem,"Hello");
if (mem == MAP_FAILED) {
perror("mmap");
return 1;
}
// 修改这块内存的保护属性为只读
if (mprotect(mem, pageSize, PROT_READ) == -1) {
perror("mprotect");
return 1;
}
// 尝试写入这块内存(会导致程序
strcpy((char *)mem, "world"); // 这一行会导致段错误(segmentation fault)
// 清理资源
if (munmap(mem, pageSize) == -1) {
perror("munmap");
return 1;
}
return 0;
}
下面四个编程题先跳了,感觉每一个都是堪比实验练习的工作量
2、修改本章操作系统内核,实现任务和操作系统内核共用同一张页表的单页表机制。
3、扩展内核,支持基于缺页异常机制,具有Lazy 策略的按需分页机制。
4、扩展内核,支持基于缺页异常的COW机制。(初始时,两个任务共享一个只读物理页。当一个任务执行写操作后,两个任务拥有各自的可写物理页)
5、扩展内核,实现swap in/out机制,并实现Clock置换算法或二次机会置换算法。
6、扩展内核,实现自映射机制。
问答题
1、在使用高级语言编写用户程序的时候,手动用嵌入汇编的方法随机访问一个不在当前程序逻辑地址范围内的地址,比如向该地址读/写数据。该用户程序执行的时候可能会生什么?
安装lab4的设计思路
触发越界访问异常(内中断) ---> trap进内核处理异常--->把程序标记为exit,切换为next进程
之后os就不会管被标记为exit程序的事了,就在那让他停着
2、用户程序在运行的过程中,看到的地址是逻辑地址还是物理地址?从用户程序访问某一个地址,到实际内存中的对应单元被读/写,会经过什么样的过程,这个过程中操作系统有什么作用?(站在学过计算机组成原理的角度)
逻辑地址
操作系统的作用: 完成地址虚拟地址到物理地址的映射
3、覆盖、交换和虚拟存储有何异同,虚拟存储的优势和挑战体现在什么地方?
相同点: 都是为了提高内存空间的利用率
不同点: 覆盖需要程序员自己写程序来确定覆盖的顺序与位置,并且是程序内的覆盖
交换是由os完成的,是程序间的交换,换出旧进程,运行新进程,不过在换出的时候依赖I/O速度
虚拟存储是由os完成的,核心思想是按需分配
优势: 允许程序员编写不受物理内存大小限制的程序,程序编程简单,隔离性与安全性强,内存利用率高
挑战: 页面置换依赖于I/O速度、选择恰当的页面置换算法
4、什么是局部性原理?为何很多程序具有局部性?局部性原理总是正确的吗?为何局部性原理为虚拟存储提供了性能的理论保证?
(1)、什么是局部性原理?
局部性分为时间局部性与空间局部性
-
时间局部性
如果一个数据项被访问,那么它在不久的将来可能再次被访问。这是因为循环和频繁的数据访问模式导致的。
-
空间局部性
如果一个数据项被访问,那么存储在其附近地址的数据项很快也可能被访问。这通常是由于数据结构的顺序存储(如数组)和编程中的顺序执行造成的。
(2)、为何很多程序具有局部性
-
这是由编程语言决定的
编程语言里面包含了大量的循环语句
-
常用的连续存储的数据结构
比如数组之类的
(3)、局部性原理一定是正确的吗?
在大多数情况下是正确的,但也有可能不生效,比如大量的goto语句跳转可能会导致局部性原理失效
(4)、为何局部性原理为虚拟存储提供了性能的理论保证?
当程序的地址被访问后,其或者其旁边的地址很有可能会被再次访问,而这些地址访问通常频繁的落在一页或几页上,这就导致OS不需要经常的进行页面置换,以此提高了效率
5、一条load指令,最多导致多少次页访问异常?尝试考虑较多情况。
这里我和答案想的不一样,一级页表常驻内存怎么,一级页表怎么会缺页呢
6、如果在页访问异常中断服务例程执行时,再次出现页访问异常,这时计算机系统(软件或硬件)会如何处理?这种情况可能出现吗?
我们实验的os在此时不支持内核的异常中断,因此此时会直接panic掉,并且这种情况在我们的os中这种情况不可能出现。像linux系统,也不会出现嵌套的page fault。
7、全局和局部置换算法有何不同?分别有哪些算法?
全局置换算法会在所有任务中进行页面置换,而局部置换算法只会在该任务内部进行页面置换
全局页面置换算法: 工作集置换算法,缺页率置换算法。
局部页面置换算法: 最优置换算法、FIFO置换算法、LRU置换算法、Clock置换算法。
8、简单描述OPT、FIFO、LRU、Clock、LFU的工作过程和特点 (不用写太多字,简明扼要即可)
OPT:选择一个应用程序在随后最长时间内不会被访问的虚拟页进行换出。性能最佳但无法实现。
FIFO:由操作系统维护一个所有当前在内存中的虚拟页的链表,从交换区最新换入的虚拟页放在表尾,最久换入的虚拟页放在表头。当发生缺页中断时,淘汰/换出表头的虚拟页并把从交换区新换入的虚拟页加到表尾。实现简单,对页访问的局部性感知不够。
LRU:替换的是最近最少使用的虚拟页。实现相对复杂,但考虑了访存的局部性,效果接近最优置换算法。
Clock:将所有有效页放在一个环形循环列表中,指针根据页表项的使用位(0或1)寻找被替换的页面。考虑历史访问,性能略差于但接近LRU。
LFU:当发生缺页中断时,替换访问次数最少的页面。只考虑访问频率,不考虑程序动态运行。
9、综合考虑置换算法的收益和开销,综合评判在哪种程序执行环境下使用何种算法比较合适?
还真不太会
FIFO算法:在内存较小的系统中,FIFO 算法可能是一个不错的选择,因为它的实现简单,开销较小,但是会存在 Belady 异常。
LRU算法:在内存容量较大、应用程序具有较强的局部性时,LRU 算法可能是更好的选择,因为它可以充分利用页面的访问局部性,且具有较好的性能。
Clock算法:当应用程序中存在一些特殊的内存访问模式时,例如存在循环引用或者访问模式具有周期性时,Clock 算法可能会比较适用,因为它能够处理页面的访问频率。
LFU算法:对于一些需要对内存访问进行优先级调度的应用程序,例如多媒体应用程序,LFU 算法可能是更好的选择,因为它可以充分考虑页面的访问频率,对重要性较高的页面进行保护,但是实现比较复杂。
10、Clock算法仅仅能够记录近期是否访问过这一信息,对于访问的频度几乎没有记录,如何改进这一点?
可以添加一个计数器
11、哪些算法有belady现象?思考belady现象的成因,尝试给出说明OPT和LRU等为何没有belady现象。
FIFO,CLOCK
OPT和LRU等为何没有belady现象?
不会...
页面调度算法可分为堆栈式和非堆栈式,LRU、LFU、OPT均为堆栈类算法,FIFO、Clock为非堆栈类算法,只有非堆栈类才会出现Belady现象。

12、什么是工作集?什么是常驻集?简单描述工作集算法的工作过程。

落在工作集内的页面需要调入驻留集中,而落在工作集外的页面可从驻留集中换出。
实际应用中,工作集窗口会设置得很大,即对于局部性好的程序,工作集大小一般会比工作集窗口小很多。工作集反映了进程在接下来的一段时间内很有可能会频繁访问的页面集合
分配给进程的物理块数(即驻留集大小)要大于工作集大小
13、请列举 SV39 页* 页表项的组成,结合课堂内容,描述其中的标志位有何作用/潜在作用?
标志位可以决定页/页表项是否是合法的
以页面置换为例,被换出的页面就把标志位设置为0,依此来表示该页面已经不合法
14、请问一个任务处理 10G 连续的内存页面,需要操作的页表实际大致占用多少内存(给出数量级即可)?
\((10 * 2^{30}) / 2^{12} * 8 = 20M\)
15、缺页指的是进程访问页面时页面不在页表中或在页表中无效的现象,此时 MMU 将会返回一个中断,告知操作系统:该进程内存访问出了问题。然后操作系统可选择填补页表并重新执行异常指令或者杀死进程。操作系统基于缺页异常进行优化的两个常见策略中,其一是 Lazy 策略,也就是直到内存页面被访问才实际进行页表操作。比如,一个程序被执行时,进程的代码段理论上需要从磁盘加载到内存。但是 操作系统并不会马上这样做,而是会保存 .text 段在磁盘的位置信息,在这些代码第一次被执行时才完成从磁盘的加载操作。 另一个常见策略是 swap 页置换策略,也就是内存页面可能被换到磁盘上了,导致对应页面失效,操作系统在任务访问到该页产生异常时,再把数据从磁盘加载到内存。
-
哪些异常可能是缺页导致的?发生缺页时,描述与缺页相关的CSR寄存器的值及其含义。
mcause 寄存器中会保存发生中断异常的原因,其中 Exception Code 为 12 时发生指令缺页异常,为 15 时发生 store/AMO 缺页异常,为 13 时发生 load 缺页异常
CSR:
scause: 中断/异常发生时, CSR 寄存器 scause 中会记录其信息, Interrupt 位记录是中断还是异常, Exception Code 记录中断/异常的种类。 sstatus: 记录处理器当前状态,其中 SPP 段记录当前特权等级。 stvec: 记录处理 trap 的入口地址,现有两种模式 Direct 和 Vectored 。 sscratch: 其中的值是指向hart相关的S态上下文的指针,比如内核栈的指针。 sepc: trap 发生时会将当前指令的下一条指令地址写入其中,用于 trap 处理完成后返回。 stval: trap 发生进入S态时会将异常信息写入,用于帮助处理 trap ,其中会保存导致缺页异常的虚拟地址。 -
Lazy 策略有哪些好处?请描述大致如何实现Lazy策略?
Lazy策略会提升性能,因为可能会有些页面被加载后并没有进行访问就被释放或替代了,这样可以避免很多无用的加载。分配内存时暂时不进行分配,只是将记录下来,访问缺页时会触发缺页异常,在
trap handler中处理相应的异常,在此时将内存加载或分配即可。 -
swap 页置换策略有哪些好处?此时页面失效如何表现在页表项(PTE)上?请描述大致如何实现swap策略?
可以提供大量的内存空间,将页面标志位为0的页面放入磁盘,使用时再从磁盘取出
16、为了防范侧信道攻击,本章的操作系统使用了双页表。但是传统的操作系统设计一般采用单页表,也就是说,任务和操作系统内核共用同一张页表,只不过内核对应的地址只允许在内核态访问。(备注:这里的单/双的说法仅为自创的通俗说法,并无这个名词概念,详情见 KPTI )
-
单页表情况下,如何控制用户态无法访问内核页面?
地址范围检查将内核页面的 pte 的
U标志位设置为0。 -
相对于双页表,单页表有何优势?
不需要跳板,不用经常更换satp,节省了一定的效率,并且编写os时候简单一些
-
请描述:在单页表和双页表模式下,分别在哪个时机,如何切换页表?
单页表: 不同用户线程切换时需要更换页表
双页表: 用户进入内核时(如系统调用,trap异常)
实验作业
重写sys_get_time与实现mmap 和 munmap 匿名映射
不知道为啥sys_get_time要重写...
https://github.com/TL-SN/rCore/tree/lab4
linux下的一些库函数
sbrk函数
函数简介
Linux 系统中,sbrk 函数用于调整程序的数据段大小,通常用于动态内存分配。它会增加或减少数据段的大小,并返回一个指向新数据段开始处的指针。不过要注意,sbrk 函数现在已经不是动态内存分配的首选方法(通常使用 malloc 和 free),因为它不是线程安全的,也不够灵活。
sbrk函数与brk函数
#include <unistd.h>
int brk(boid *addr);
addr:把内存末尾指针设置为addr.返回值:0表示成功,非0表示失败
void *sbrk(intptr_t increment);
increment:把内存的末尾指针移动increment个字节。返回值:上次调用sbrk/brk的内存末尾指针。
这俩都是管理堆的
mmap函数
函数简介
mmap 函数是一种内存映射文件的方法,它提供了一种将文件内容映射到进程的地址空间的机制。这种方法允许程序像访问普通内存一样访问文件内容,从而可以提高文件读写的效率。mmap 函数通常用于大文件的读写,特别是在需要频繁访问文件的不同部分时。以下是 mmap 函数的基本概念和使用方法:

函数说明
void* mmap(void* start,size_t length,int prot,int flags,int fd,off_t offset);
- 地址(start):建议映射的起始地址。通常设置为 NULL,由操作系统选择地址。
- 长度(length):要映射的文件区域的长度。
- 保护(prot):指定内存区域的访问权限,如可读(
PROT_READ)、可写(PROT_WRITE)等。 - 标志(flags):控制映射的特性,如共享映射(
MAP_SHARED)、私有映射(MAP_PRIVATE)等。 - 文件描述符(fd):要映射的文件的文件描述符。
- 偏移(offset):文件中的偏移量,从哪里开始映射。
- 返回值 ,返回映射的虚拟地址
munmap函数
函数介绍
munmap 函数是用于撤销内存映射的系统调用。当你通过 mmap 函数将文件或设备的一部分映射到内存中后,可以使用 munmap 来释放这块内存区域。这是内存映射生命周期的重要组成部分,确保资源得到正确释放,防止内存泄漏。
函数定义
#include <sys/mman.h>
int munmap(void *addr, size_t length);
- addr:这是一个指针,指向你想要释放的内存映射区域的起始地址。通常,这是之前
mmap调用返回的地址。 - length:这个参数指定了要释放的内存区域的大小,单位是字节。这应该与原始
mmap调用中指定的大小相匹配。
返回值
- 成功时:返回
0。 - 失败时:返回
-1,并设置errno以指示错误原因。
当使用 munmap 释放通过 mmap 映射的内存时,释放的长度必须与在调用 mmap 时映射的长度一致
mprotect函数
函数介绍
mprotect 函数是一个系统调用,用于改变已经映射到进程地址空间中的内存区域的保护属性。这个调用允许你动态地更改内存区域的权限,例如将某个内存区域设置为只读或可执行。这对于实现诸如堆栈溢出保护、防止程序数据被恶意修改等安全措施非常有用。
函数说明
#include <sys/mman.h>
int mprotect(void *addr, size_t len, int prot);
参数
- addr:指向要修改保护属性的内存区域的起始地址。这个地址必须是系统分页大小的整数倍。
- len:要修改的内存区域的长度,单位是字节。
- prot:新的保护属性。这个参数是以下几个常量的按位或(OR):
PROT_NONE:内存页不能被访问。PROT_READ:内存页可以被读取。PROT_WRITE:内存页可以被写入。PROT_EXEC:内存页可以被执行。
返回值
- 成功时:返回
0。 - 失败时:返回
-1,并设置errno以指示错误原因。
#include <sys/mman.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main() {
// 分配一块内存
size_t pageSize = getpagesize();
void *mem = mmap(NULL, pageSize, PROT_READ | PROT_WRITE, MAP_ANONYMOUS | MAP_PRIVATE, -1, 0);
strcpy((char *)mem,"Hello");
if (mem == MAP_FAILED) {
perror("mmap");
return 1;
}
// 修改这块内存的保护属性为只读
if (mprotect(mem, pageSize, PROT_READ) == -1) {
perror("mprotect");
return 1;
}
// 尝试写入这块内存(会导致程序
strcpy((char *)mem, "world"); // 这一行会导致段错误(segmentation fault)
// 清理资源
if (munmap(mem, pageSize) == -1) {
perror("munmap");
return 1;
}
return 0;
}
一些git命令
1、查看当前关联的仓库
git remote -v
2、移除现有的远程仓库
如果你要更换的远程仓库别名是 origin(这是最常见的情况),可以使用命令 git remote remove origin 来移除它。
git remote remove origin
3、添加新的远程仓库
git remote add origin 新仓库的URL
4、验证一下是否关联成功
git remote -v
git登录
今天git push的时候一直连不到github,气得我搞了个细粒度token,在ubuntu上上传的

其他步骤都一样,就是得需要输入Username与Password
Username就是github上的用户名,Password则是创建的细粒度token
这个token最长使用期是一年

 浙公网安备 33010602011771号
浙公网安备 33010602011771号