祥云杯复盘 machine go语言+vm栈混淆
比赛的时候,vm解析器写的有些问题,导致这道题做了大半天没做出来
解题思路
一、获取vm的opcode
IDA载入题目,可以发现大量的未被解析的伪代码
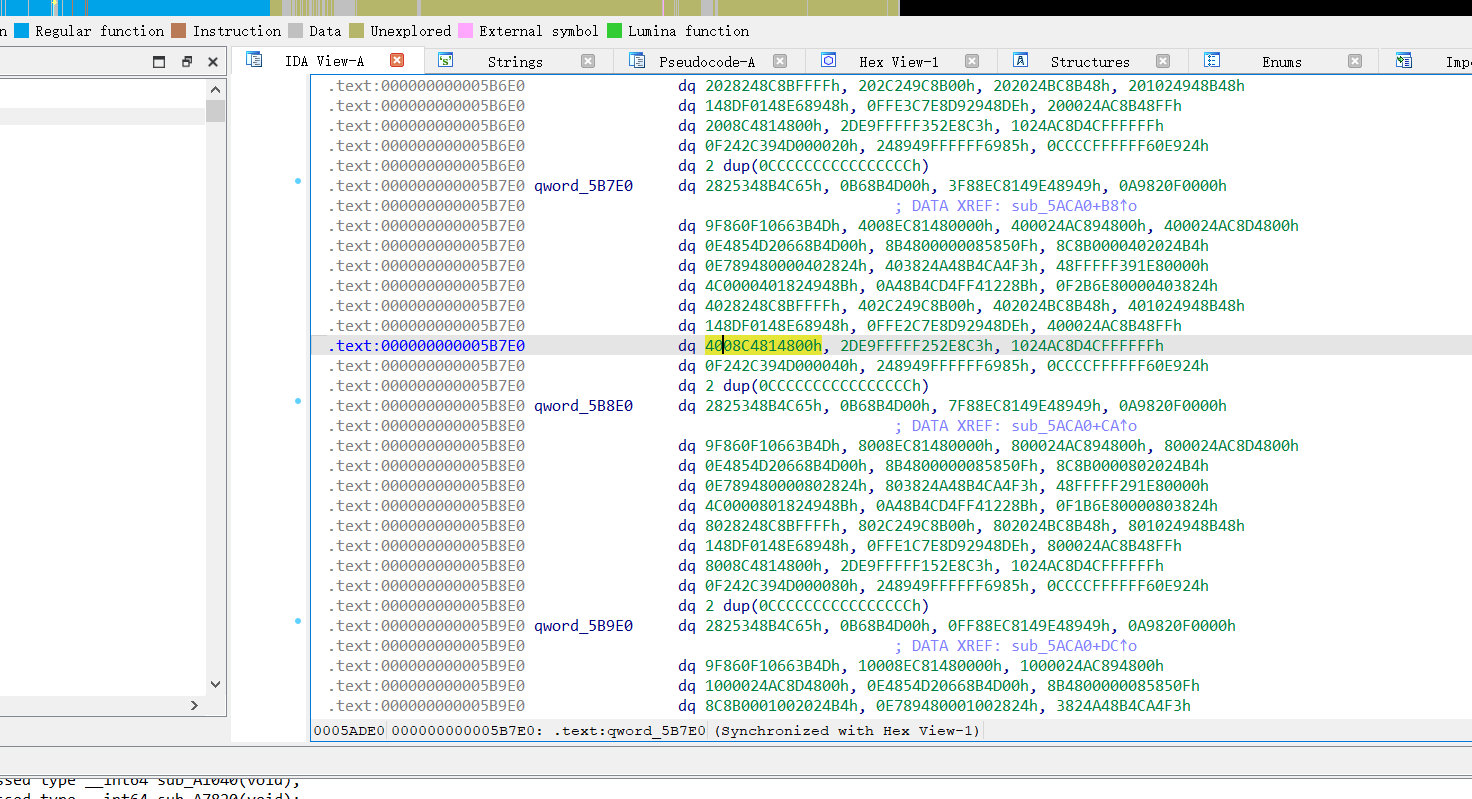
使用IDAPython脚本 恢复代码块
import idc import idaapi def upc(begin,end): for i in range(begin,end): idc.del_items(i) for i in range(begin,end): idc.create_insn(i) for i in range(begin,end): idaapi.add_func(i) print("Finish!!!") begin = 0x00000000007A760 end = 0x0000000000C6ED8 upc(begin,end)
之后字符串搜索 code.bin ,定位到关键函数
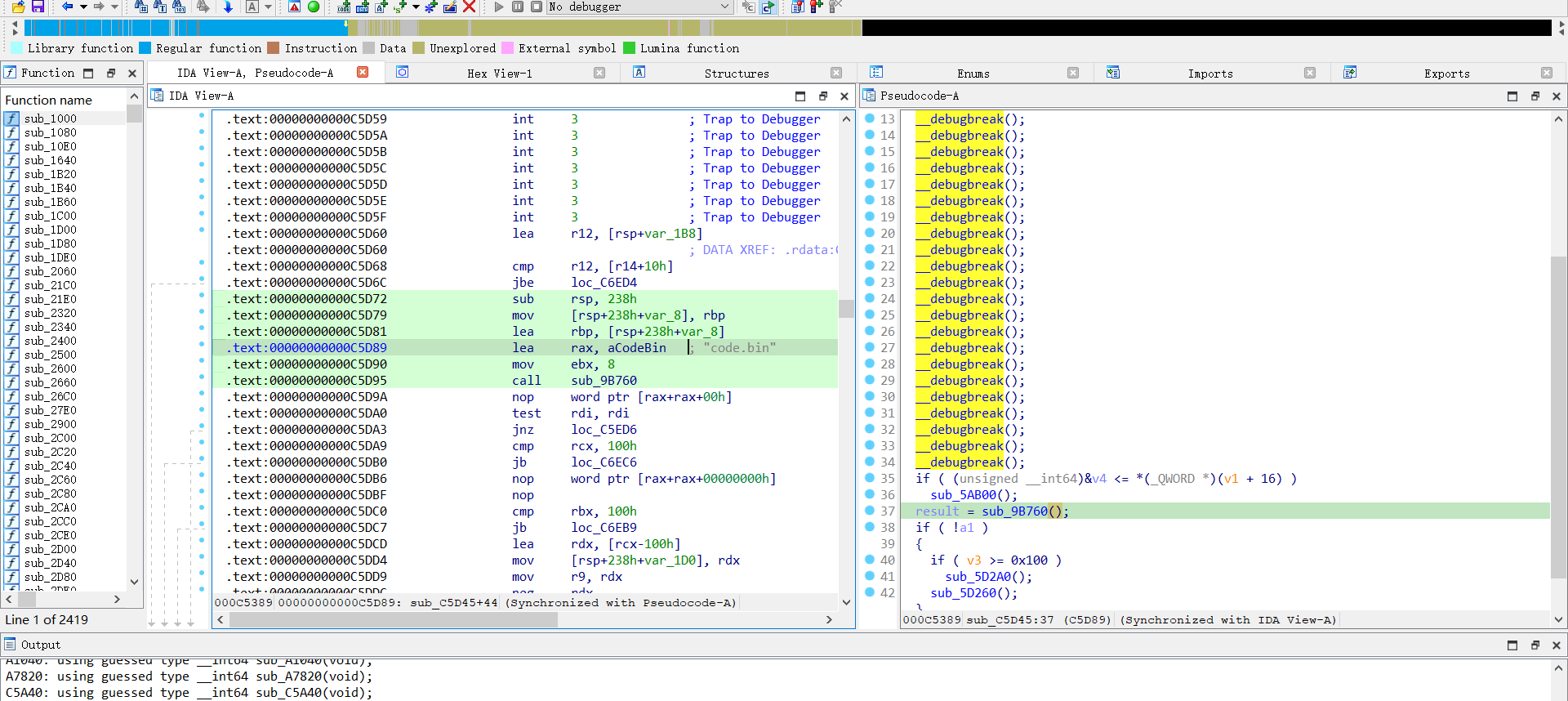
发现这个函数的汇编没有被正常解析为伪代码,尝试patch掉一些代码,看能否显示出伪代码
经过尝试,是这一句jcc指令影响了IDA的跳转
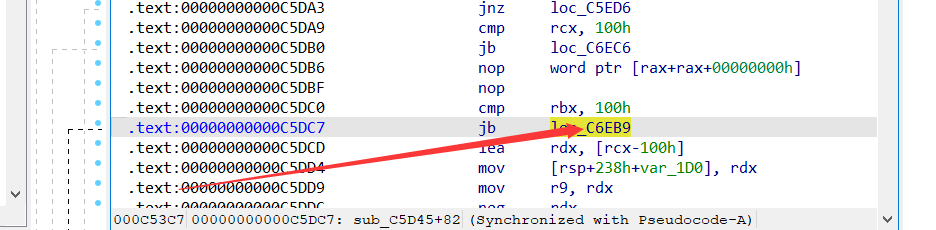
patch掉之后,即可看到所有需要被解析的伪代码
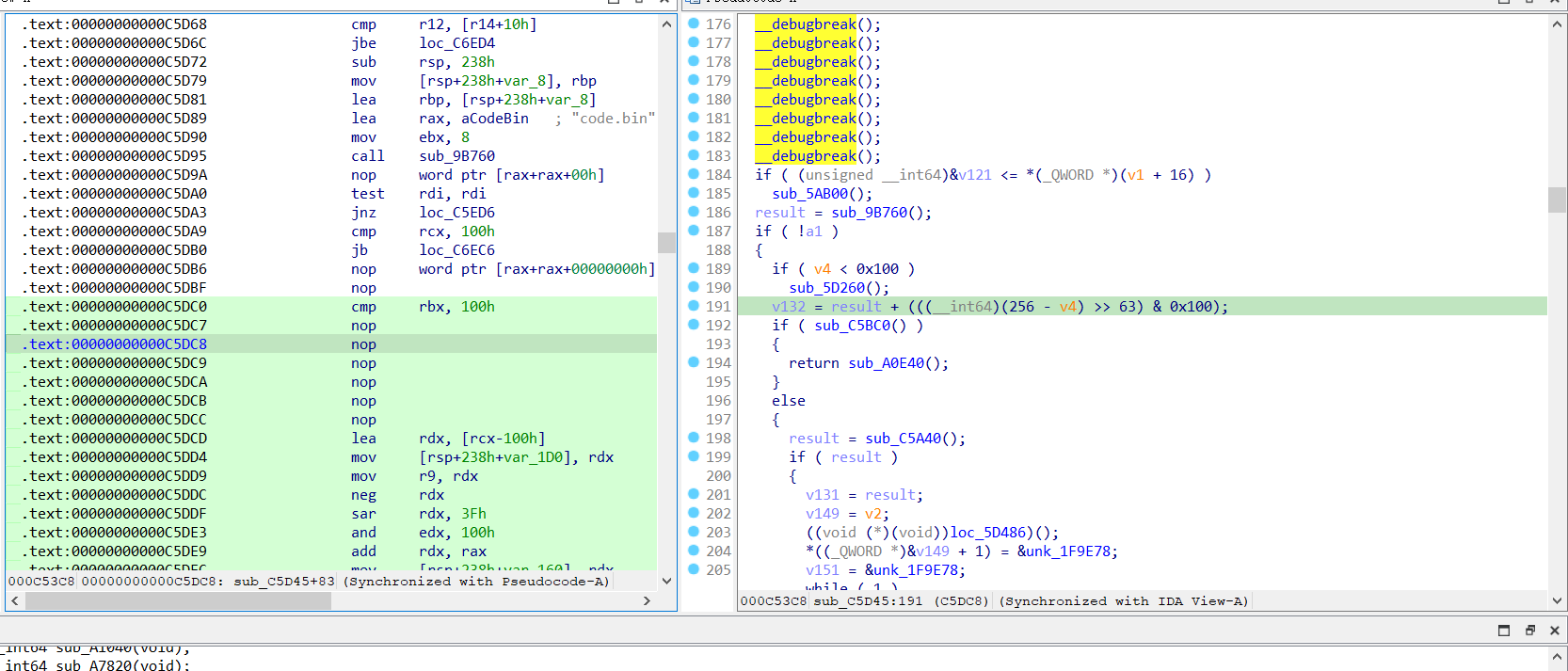
很显然,这是一个vm混淆题目,里面有很多未知的函数,使用IDA自带的Lumina插件可以恢复大部分符号
题目流程
程序首先加载 code.bin 文件,取出文件的前0x100字节,使用sha256加密和RSA加密进行了一个校验(不用管这部分)
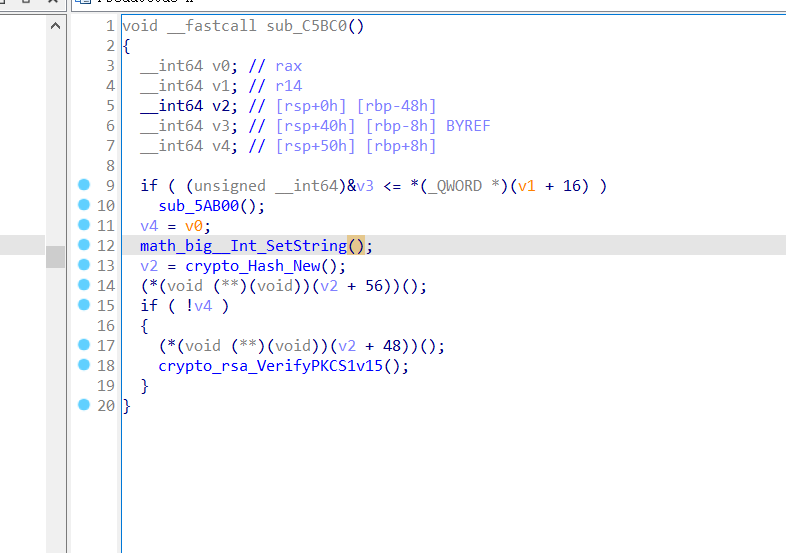
之后解压 code.bin文件
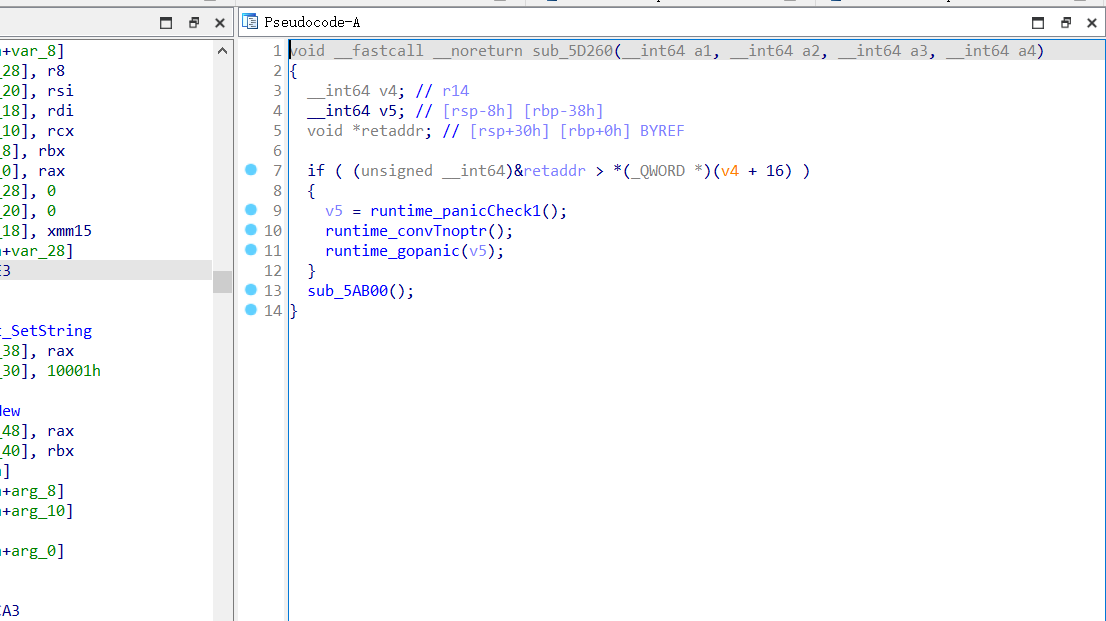
解压缩后的code.bin文件在后面就所为vm的opcode执行代码,我们直接dump出来即可
二、第一种vm解析器编写思路
一般vm解析器会把代码解析成可读的伪代码或汇编
先说一下我使用的方法,我是把代码解析成了可执行的c语言伪代码
针对于该vm混淆,我记录下来所有关于寄存器以及栈的代码信息,之后用gcc 开O3优化进行处理,观察加密算法
经过尝试,可以发现程序每次检查8字节字符(最后一次是10字节),我们可以每次求出8字节,如此重复四次,即可得到flag
vm提取脚本总如下:(这里只贴最后一次
finn = ''' if (arr_v163[0] !=0) printf("error\\n"); else printf("continue\\n"); ''' vm_hander = [] fp = open(r"C:\Users\Administrator\Desktop\Data","r") Rd = fp.readlines() for i in range(len(Rd)): vm_hander.append(int(Rd[i])) # print(Rd[i],end = "") fps = open(r"C:\Users\Administrator\Desktop\opreattttttttttt","w") def p(pt): global fps fps.write(pt+";"+"\n") # print(pt) arr_v163 = [0] * 10000 len_v163 = 0 v172 = [0] * 10000 Anss =0 scanf_ans = 0 #记录scanf的序列 # flag = "1111111111111111111111111111111111111" # flag = "734f1698_12345678911111111111111111111" # flag = "734f1698a5775ec2_12345671111111111111" # flag = "734f1698a5775ec26cd2e11e_23456781\n" flag = "734f1698a5775ec26cd2e11ed4791e77\r\n" S1 = 0 S2 = 0 pc = 0 p("unsigned long long int arr_v163[100] = {0};\nunsigned long long int v172[10] = {0};") while pc < len(vm_hander): opcode = vm_hander[pc] if opcode == 0: v24 = len_v163; v13 = len_v163 + 1; len_v163 = v24 + 1; arr_v163[v24] = vm_hander[pc+1] # print(arr_v163[v24]) # assert 0 p(f"arr_v163[{v24}] = {arr_v163[v24]}") pc += 2 elif opcode == 0x1: # v26.append(vm_hander[pc+1]]) v30 = len_v163; v13 = len_v163 + 1; v28 = vm_hander[pc+1] v29 = v172[v28]; len_v163 = v30 + 1; arr_v163[v30] = v29; p(f"arr_v163[{v30}] = v172[{v28}]") pc += 2 elif opcode == 0x2: v34 = vm_hander[pc+1] ans_len = len_v163 - 1 v35 = arr_v163[len_v163 - 1] len_v163 -= 1 v172[v34] = v35 p(f"v172[{v34}] = arr_v163[{ans_len}]") pc += 2 elif opcode == 0x3: # 0x18 #len = 2 v36 = len_v163 v37 = len_v163 - 1 len_v163 -= 1 ans_len = len_v163 v38 = arr_v163[len_v163] v39 = v36 - 2 v40 = arr_v163[v36 - 2] + v38 len_v163 = v39 + 1 arr_v163[v39] = v40 p(f"arr_v163[{v39}] = arr_v163[{v36 - 2}] + arr_v163[{ans_len}]") pc += 1 elif opcode == 0x4: v44 = len_v163; v45 = len_v163 - 1; ans_len = len_v163 - 1 v46 = arr_v163[len_v163-1]; len_v163 -= 1 v47 = v44 - 2; v48 = v46 - arr_v163[v44 - 2]; len_v163 = v44 - 2; len_v163 = v47 + 1; arr_v163[v47] = v48; p(f"arr_v163[{v47}] = arr_v163[{ans_len}] - arr_v163[{v44 - 2}]") pc += 1 # ? elif opcode == 0x5: v52 = len_v163; v53 = len_v163 - 1; ans_len = len_v163 - 1 v54 = arr_v163[len_v163 - 1]; len_v163 -= 1 v55 = v52 - 2; v56 = arr_v163[v52 - 2]; len_v163 = v52 - 2; v57 = v56 * v54; len_v163 = v55 + 1; arr_v163[v55] = v57; p(f"arr_v163[{v55}] = arr_v163[{v52 - 2}] * arr_v163[{ans_len}]") pc += 1 elif opcode == 0x6: # 写 v61 = len_v163; v62 = len_v163 - 1 ans_len = len_v163 - 1 v63 = arr_v163[len_v163-1]; len_v163 -= 1 v64 = v61 - 2; v65 = arr_v163[v61 - 2]; len_v163 = v61 - 2; v66 = v62; v67 = v63 // v65; len_v163 = v64 + 1; arr_v163[v64] = v67; p(f"arr_v163[{v64}] = arr_v163[{ans_len}] // arr_v163[{v61 - 2}]") assert 0 pc += 1 elif opcode == 0x7: # len = 3 v71 = len_v163; v72 = len_v163 - 1; ans_len = len_v163-1 v73 = arr_v163[len_v163-1]; len_v163 -= 1 v74 = v71 - 2; v75 = arr_v163[v71 - 2] ^ v73; len_v163 = v71 - 2; len_v163 = v74 + 1; arr_v163[v74] = v75; p(f"arr_v163[{v74}] = arr_v163[{v71 - 2}] ^ arr_v163[{ans_len}]") pc += 1 elif opcode == 0x8: # len = 3 v79 = len_v163; v80 = len_v163 - 1; len_v163 -= 1 ans_len = len_v163 v81 = arr_v163[len_v163]; v82 = v79 - 2; v83 = arr_v163[v79 - 2]; len_v163 = v82; v84 = -(v83 < 0x40) & (v81 << v83); len_v163 = v82 + 1; arr_v163[v82] = v84; p(f"arr_v163[{v82}] = -(arr_v163[{v79 - 2}] < 0x40) & (arr_v163[{ans_len}] << arr_v163[{v79 - 2}])") pc += 1 elif opcode == 0x9: v88 = len_v163; v89 = len_v163 - 1; ans_len = len_v163 - 1 v90 = arr_v163[len_v163-1]; len_v163 -= 1 v91 = v88 - 2; v92 = arr_v163[v88 - 2]; len_v163 = v91; v93 = -(v92 < 0x40) & (v90 >> v92); len_v163 = v91 + 1; arr_v163[v91] = v93; p(f"arr_v163[{v91}] = -(arr_v163[{v88 - 2}] < 0x40) & (arr_v163[{ans_len}] >> arr_v163[{v88 - 2}])") pc += 1 elif opcode == 0xa: # 2 v97 = len_v163 v98 = len_v163 - 1 ans_len = len_v163-1 v99 = arr_v163[len_v163-1] len_v163 -= 1 len_v163 = v98 + 1 arr_v163[v98] = ~v99 p(f"arr_v163[{v98}] = ~arr_v163[{ans_len}]") pc += 1 elif opcode == 0xb: v104 = len_v163 v105 = len_v163 - 1 ans_len = len_v163-1 v106 = arr_v163[len_v163-1] len_v163 -= 1 v107 = v104 - 2 v108 = arr_v163[v104 - 2] & v106; len_v163 = v104 - 2; len_v163 = v107 + 1 arr_v163[v107] = v108 p(f"arr_v163[{v107}] = arr_v163[{v104 - 2}] & arr_v163[{ans_len}]") pc += 1 elif opcode == 0xc: # v26.append(scanf) if flag[scanf_ans] == "\n": # 事实 + 检验发现,最后一个 '\n' 字符是在arr_v163[2]的位置被读取的 arr_v163[2] = ord(flag[scanf_ans]) scanf_ans += 1 p(f"arr_v163[2] = 0") p(f"scanf(\"%c\",&arr_v163[2])") else: arr_v163[0] = ord(flag[scanf_ans]) scanf_ans += 1 p(f"arr_v163[0] = 0") p(f"scanf(\"%c\",&arr_v163[0])") # p(f"if (arr_v163[0] < 0x20 || arr_v163[0] >= 0x7f )\n\tFun_Exit(0)") S1 += 1 len_v163 += 1 pc += 1 elif opcode == 0xd: try: p(f"//p --> {chr(vm_hander[pc+1])}") except: print(hex(pc)) pc += 2 elif opcode == 0xe: len_v163 -= 1 # p(f"//Pan arr_v163[{len_v163}] == 0") Pan = f'''if (arr_v163[{len_v163}])\n\tFun_Exit(0)''' p(Pan) # if arr_v163[len_v163] & 0xffffffffffffffff: # p(f"//errorrrrrr") # p("//-------------------------------------------------------------------------------------------------#") # fps.close() # exit() pc +=1 elif opcode == 0xcc: print("what???") assert 0 else: assert 0 fps.close()
提取出的代码如下:

19000行代码,人工很难分辨出加密算法
修改成c语言代码后直接开O3优化

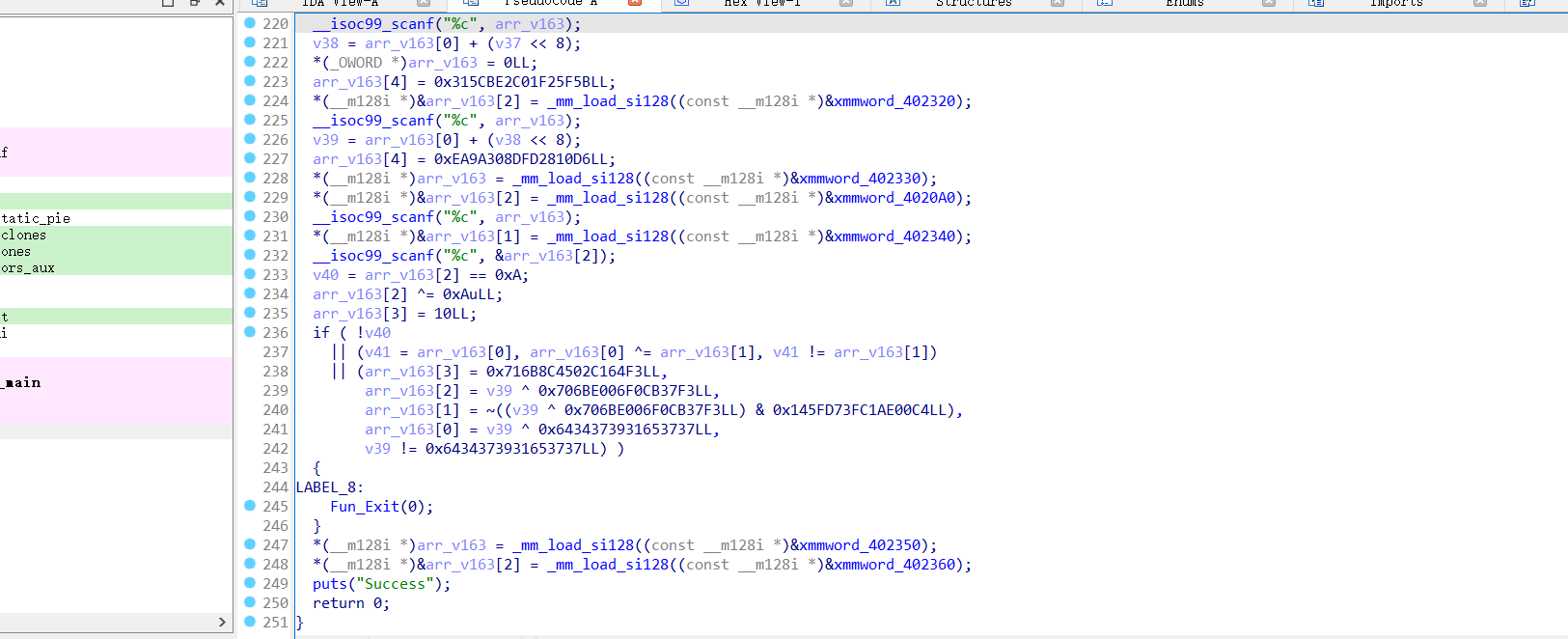
可以发现程序被优化到了250行代码,发现加密逻辑比较简单,只是很少简单的逻辑操作,对此,直接angr一把梭
import angr import sys, time def found(simgr): if simgr.found: solution_state = simgr.found[0] correct_input = solution_state.posix.dumps(sys.stdin.fileno()) print(correct_input) else: raise Exception('not solution') def main(argv): path_to_binary = argv[1] p = angr.Project(path_to_binary) initial_state = p.factory.entry_state( add_options={angr.options.SYMBOL_FILL_UNCONSTRAINED_MEMORY, angr.options.SYMBOL_FILL_UNCONSTRAINED_REGISTERS} ) simgr = p.factory.simulation_manager(initial_state) # good_address = 0x000000000401360 #加上 0x400000 基质 # again_address = (0x000000000401378) # good_address = 0x00000000040162F # again_address = 0x000000000401649 # good_address = 0x000000000401932 # again_address = 0x00000000040194C good_address = 0x000000000401A99 again_address = 0x000000000401AB0 simgr.explore(find=good_address, avoid=again_address) found(simgr) if __name__ == '__main__': start = time.time() main(sys.argv) end = time.time() total = end - start print(total)

即可直接得到flag
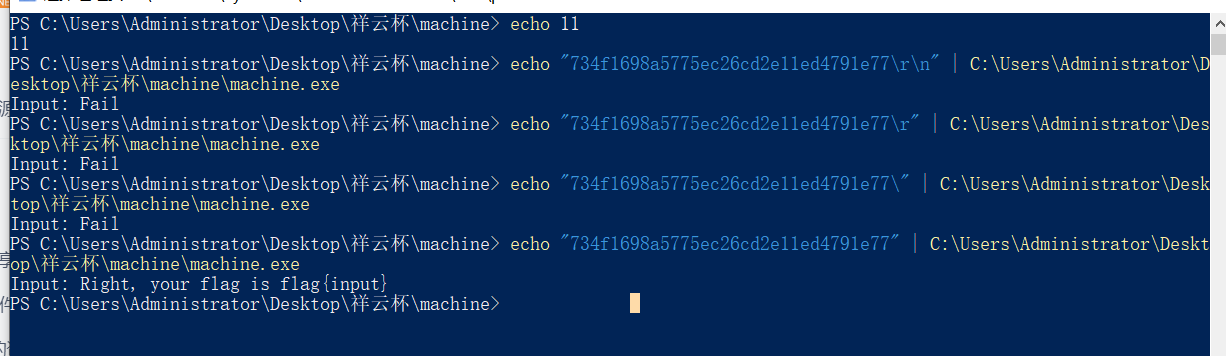
734f1698a5775ec26cd2e11ed4791e77
这个方法不用考虑,栈啊,寄存器那一堆乱七八糟的关系,在python上就是一个列表的事,十分方便
但也有一些问题,有意这个方法依赖于gcc O3优化以及angr约束求解,我们的vm解析器脚本不允许出现一点问题,不然就GG。angr也解不了一些复杂逻辑的加密算法
三、第二种vm解析器编写思路
用栈和寄存器的形式提取vm混淆代码,这个方法是普遍使用率高同时也是效果最好的方式,我见更多大佬选择这种方式,我们需要先标志好寄存器,栈之类的东西,再提取它们来代表vm的执行
参考山海关战队wp:

但是他们并没有从提取出的代码中找到加密算法的规律(因为提取出的数据太多了...),而是黑盒爆破猜到了规律..
这种方法直击vm混淆的本质,但需要人工去分析加密算法,比较淦
不管怎么样,这两种解析方法都是不错的方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号