

crawlspider 创建项目| crawlspider 图片保存 | 使用session | 代理ip 的使用 | cookies 获取方法 | 不同 item 传递参数
1. crawlspider 创建项目
scrapy genspider -t crawl 项目名称 要爬取网址
scrapy genspider -t crawl xiao xiao.com
2. crawlspider 图片保存
2.1 下载方式一 pipeline文件
from scrapy.pipelines.images import ImagesPipeline
''' 实现图片基础下载''' class ImagePipeline(ImagesPipeline): def get_media_requests(self, item, info): yield scrapy.Request(item['image_urls'])
2.2下载方式二 pipeline文件
import scrapy from itemadapter import ItemAdapter from scrapy.exceptions import DropItem from scrapy.pipelines.images import ImagesPipeline class MyImagesPipeline(ImagesPipeline): def get_media_requests(self, item, info): for image_url in item['image_urls']: yield scrapy.Request(image_url) def item_completed(self, results, item, info): image_paths = [x['path'] for ok, x in results if ok] if not image_paths: raise DropItem("Item contains no images") adapter = ItemAdapter(item) adapter['image_paths'] = image_paths return item
3. 使用session 来请求

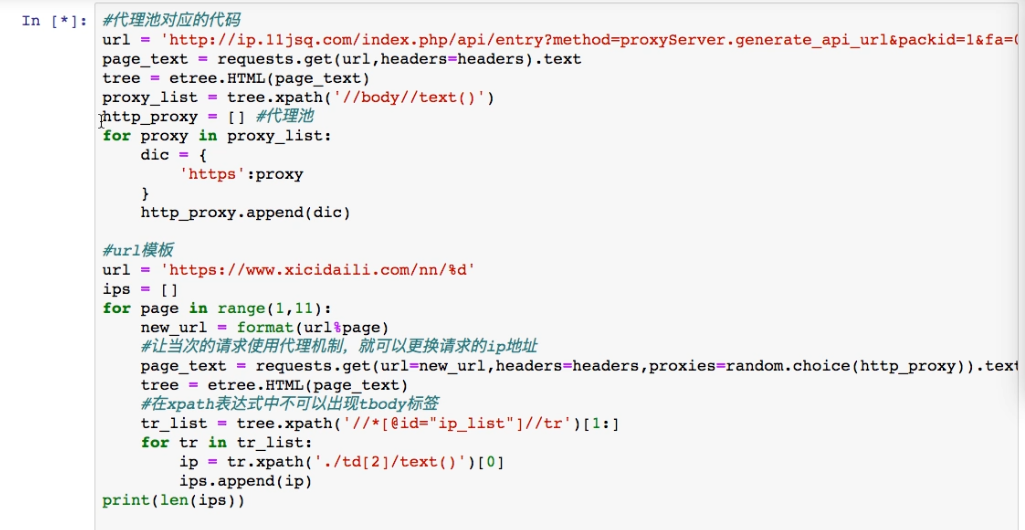
4. 代理ip 的使用
5. cookies 获取方法
temp = '' cookies = {data.split('=')[0]:data.split('=')[1] for data in temp.split(';')}
6. 接受不同 item 传递参数
6.1 方式一
if item.__class__.__name__ == 'name'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号