
安装scrapy - 创建一个简单爬虫 ,去爬取百度 | 5.url拼接 | 6.scrapy re正则 | 7.使用m3u8插件解析m3u8文件 |
1. 安装scrapy
pip install scrapy
豆瓣镜像源
pip install scrapy -i https://pypi.douban.com/simple/
模块介绍 :

2 创建一个项目myspider
1. 创建一个scrapy 目录名称是spider
scrapy startproject mySpider
目录介绍
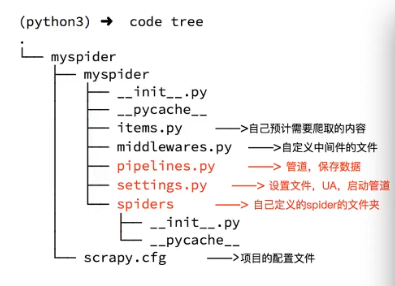
3 创建一个爬虫 baidu爬虫名字 baidu.com 是目标网站
1. cd mySpider
scrapy genspider baidu baidu.com
4 运行爬虫 scrapy crawl 爬虫名字
scrapy crawl baidu
scrapy crawl jd
5. url拼接方法
response.urljoin(url)
6. 正则 srcapy
response.selector.re()
7. m3u8 插件解析 m3u8文件
# 使用 m3u8 插件 解析数据 所有ts链接 m3u8_a_url 是第二层文件,
playlist = m3u8.load(uri=m3u8_a_url)
for seg in playlist.segments:
print(seg.uri)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号