

腾讯云的TDSQL-H LibraDB,底层是Clickhouse
一. java版本引用方式通过jdbc
可参考腾讯文档https://cloud.tencent.com/document/product/1488/79810
<dependency> <groupId>ru.yandex.clickhouse</groupId> <artifactId>clickhouse-jdbc</artifactId> <version>0.3.2</version> </dependency>
驱动:
Class.forName("ru.yandex.clickhouse.ClickHouseDriver");
url:
connectionStr:格式为jdbc:clickhouse://" + url + ":8123。其中,url 为前提条件获取的 JDBC 连接 TDSQL-H LibraDB 实例时的主机地址。
二. 两种建表方式
第一种: 通过配置CDC,将源数据库(如 mysql,mysql-c)数据同步到引擎库
可设置忽略同步(如DDL中的delete Drop等),同步类型为表结构 + 全量数据 + 增量数据,默认建立副本引擎表(ReplicatedMergeTree),本地表(on cluster)和分布表(基于本地表)
String createTableDDL = "create table test_table_local on cluster default_cluster " + "(id UInt32, " + "dt_str String, " + "dt_col DateTime) " + "engine=ReplicatedMergeTree('/clickhouse/tables/{database}/{table}/{shard}', '{replica}')" + "partition by toYYYYMM(dt_col)" + "order by (id)" + "primary key (id)" + "sample by (id)" + "settings index_granularity = 8192;"; stmt.execute(createTableDDL); System.out.println("create local table done."); } { String createTableDDL = "create table test_table on cluster default_cluster " + "as default.test_table_local " + "engine=Distributed(default_cluster, default, test_table_local, rand());"; stmt.execute(createTableDDL); System.out.println("create distributed table done");
第二种: 可手动建立各种引擎库和引擎表
其中 轻量级删除只针对MVCC的CDC同步的表,手动建的表加上增加 allow_fast_delete_column = 1 参数也不行
参考 https://cloud.tencent.com/document/product/1488/77418
三.基本的语法 (https://clickhouse.com/docs/zh)
1. Clickhouse 不支持常规的 update/delete/replace into等
2. alter delete 删除副本引擎表式,需删本地表并且指定集群 on cluster cluster_name
3. Clickhouse 不支持事务(如 @Transactional)
4. 一行转多列的group by ,如 arrayJoin(splitByString (',', `dept_ids`)) as deptId group by deptId
5.JSON 语法,可参考文档,最基本的取key, visitParamExtractInt 替换 json_extract
6. 内嵌sql问题,select的字段不能参入到计算公式中
错误的sql: select c sum(a) as a case when sum(b) = 0 then 0 else sum(a) / sum(b) as ab from ( select c,d sum(a) as a, sum(b) as b from table group by c,d ) a group by c 正确的sql: select c sum(a_temp) as a case when sum(b_temp) = 0 then 0 else sum(a_temp / sum(b_temp) end as ab from ( select c,d sum(a) as a_temp, sum(b) as b_temp from table group by c,d ) a group by c
7. formatDateTime(dateTime, '%H:%M'), '%H:%M'这里需要时常量,不能是case when 这类判断
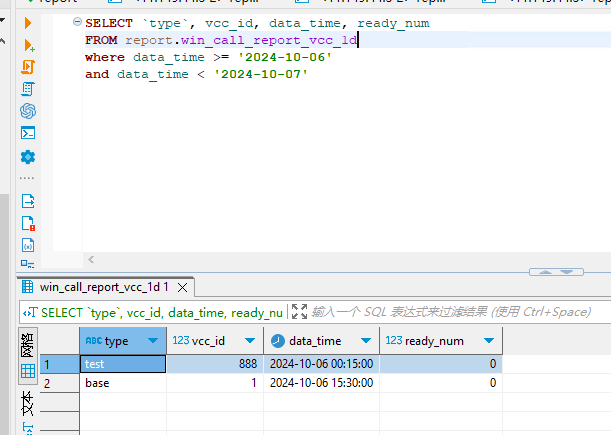
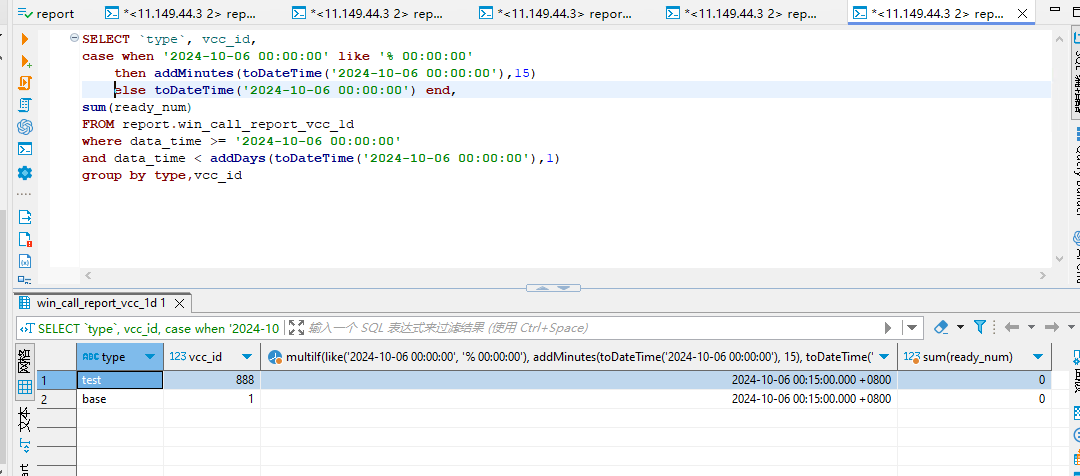
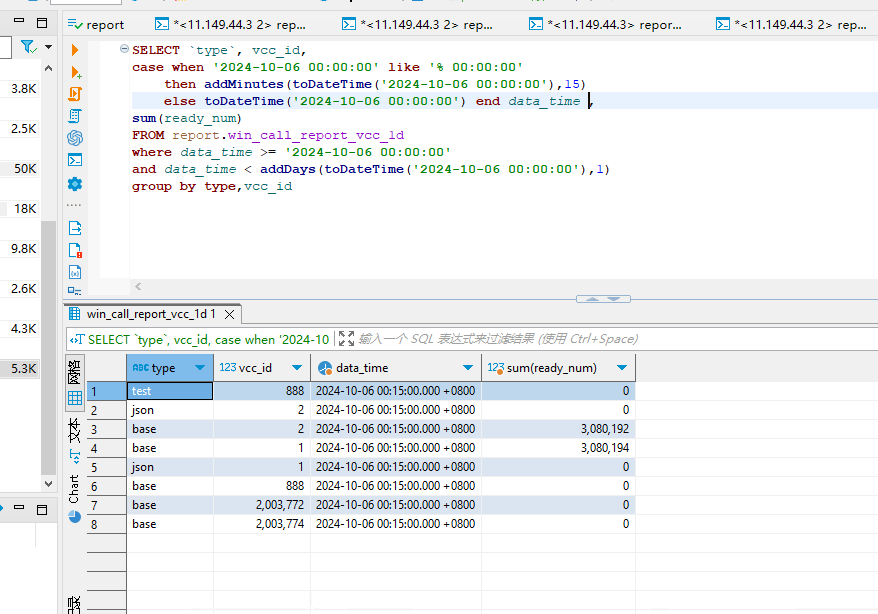
8. 一个很有疑问的查询,如按照时间分区的副本表,按照下面两种方式查询,结果就完全不一样
本来只是想按照查询起始时间来给一列动态赋值,结果赋值列别名用的表中的时间字段,并且字段还在查询条件中,导致查询出来的数据已经错乱,where条件中的dateTime,
和前面嵌套查询一样,需要规范处理
四.常用的Clickhouse语法
查delete等操作执行情况 SELECT database, table, mutation_id, command, create_time, is_done FROM system.mutations where database = 'test' and table = 'test' ; 杀掉delete某个进程 KILL MUTATION WHERE database = 'test' ASYNC; 查看表情况 SELECT * FROM system.parts WHERE table = 'test'; 查看正在执行的sql SELECT query_id, user, address, query FROM system.processes ORDER BY query_id ASC create DATABASE report ON CLUSTER default_cluster; DROP DATABASE report ON CLUSTER default_cluster SYNC; ALTER TABLE test ON CLUSTER default_cluster DELETE WHERE data_time >= '2024-10-01 15:30:00' and data_time < '2024-10-01 16:00:00' ; OPTIMIZE TABLE test;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号