基于 FederatedScope 的双机 CIFAR-10 联邦学习
注:我的双机:本地是windows11家庭版,云服务器的Ubuntu20.04(算力和内存较弱)
任务 : 在 CIFAR-10 数据集上训练一个 ResNet8 模型
客户端:
云服务器(Aggregator + Client_0)
本地 Windows 机器(Client_1)
数据:
将 CIFAR-10 训练集按 30%:70% 划分
data/client_0.pkl(云端,≈15 000 张)
data/client_1.pkl(本地,≈35 000 张)
聚合算法:FedAvg
训练配置(config_cifar10_hetero_3_7.yaml):
总轮数 total_round_num=50
每轮参与客户端数 client_num=2, client_num_per_round=2
本地更新步数 local_update_steps=5
优化器:SGD(lr=0.05, momentum=0.9)
客户端异构超参:
云端(Client_0):batch_size=16
本地(Client_1):batch_size=64
1.联邦学习
-
联邦学习(Federated Learning)是一种分布式机器学习范式,其核心理念是:
-
数据不出本地:各参与方(客户端)保留并本地使用自己的私有数据进行模型训练;
-
模型参数通信:客户端只将训练得到的模型参数(或梯度)发送到中心服务器;
-
安全聚合:中心服务器对各客户端上传的参数按一定策略(如 FedAvg)聚合,形成新的全局模型;
-
迭代更新:全局模型再下发给客户端,重复本地训练–参数上传–模型聚合的迭代过程,直至收敛。
-
-
本实验的主要知识点:
- 异构环境模拟:资源差异:云服务器仅 2 vCPU + 2 GiB 内存,本地机器具备 GPU 及更多内存
- FedAvg 聚合算法:加权平均:每轮根据各客户端样本数对本地模型参数加权,然后求和得到全局模型;超参数协同:在异构场景下,为不同客户端指定不同 batch_size(云端 16、本地 64),观察其对聚合效果的影响。
- 数据本地化:全程未传输任何原始图像,避免敏感数据泄露
2.配置windows 环境
注:我的环境有问题:
版本问题,不同的版本问题太大
YAML 配置文件的格式错误
分布式训练中的 libuv 支持问题
配置键名不兼容问题
环境变量设置错误
最终配置文件的调整
注:winows系统下(我的是windows11家庭版)
(1).创建虚拟环境:
-
在任意盘 :打开cmd
mkdir FederatedScope
cd FederatedScope -
然后创建虚拟环境:
(我的是python,有些可能要python3)
python -m venv venv
-
激活虚拟环境:
venv\Scripts\activate.bat -
查看包:
pip list -
我的是:
![]()
-
升级pip:
python -m pip install --upgrade pip -
安装依赖federatedscope:(federatedscope:联邦学习框架)
pip install federatedscope
pip list查看
![]()
-
安装 torch 和 torchvision:用于模型构建和数据预处理
pip install torch torchvision
pip list查看
![]()
-
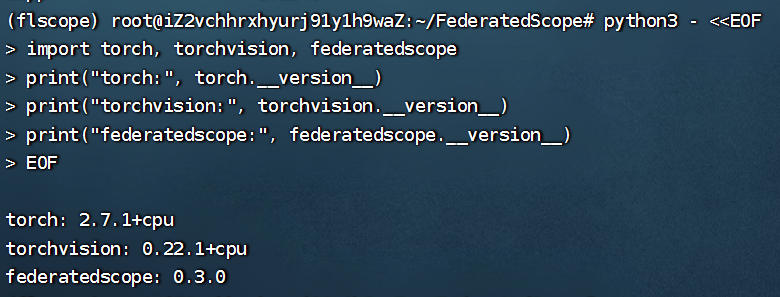
再次验证一下:
python -c "import torch, torchvision, federatedscope; print(torch.__version__, torchvision.__version__, federatedscope.__version__)"
可以正确打印版本号就是正确的:
![]()



3.Ubuntu的环境配置(要求python的版本3.9以上)
创建目录FederatedScope
mkdir FederatedScope
进入目录:
cd FederatedScope/
创建虚拟环境:
python3 -m venv venv
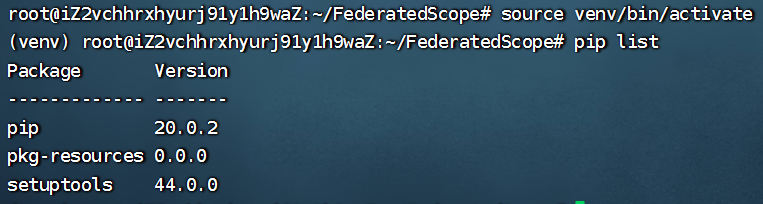
激活虚拟环境:
source venv/bin/activate
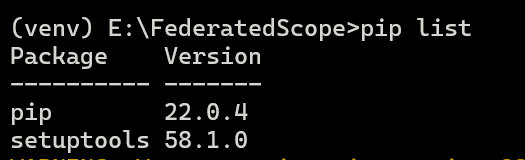
查看包:
pip list
因为:federatedscope 尚未在 PyPI 发布,我们直接用源码安装:
从 GitHub 克隆 FederatedScope 的源代码到当前目录下的src文件夹中:
git clone https://github.com/alibaba/FederatedScope.git src
cd src
把 FederatedScope 源码“装”进虚拟环境,并保持与源码的实时同步,方便后续对框架代码做定制或调试
pip install -e .
但是我报错了:
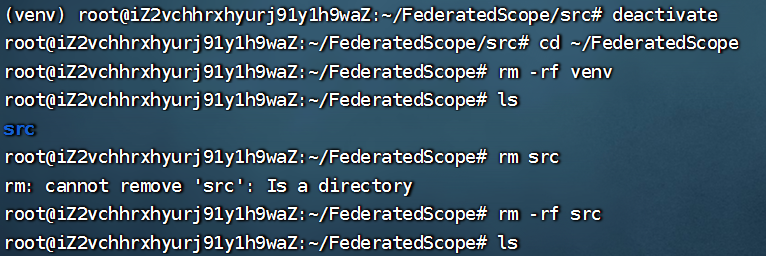
要求python3.9以上,而我的版本低了
如图,删除虚拟环境
以下是我配置3.9版本的记录,一般来说直接升版本再创建虚拟环境就行了,但是我Ubuntu里面创建的虚拟环境有点多,担心升级之后报其他的错误,所以我:使用 micromamba。它只有几十 MB,能创建独立环境,不动全局,也不会像完整 Conda 那样占用太多内存。

安装micromamba
wget -qO- https://micromamba.snakepit.net/api/micromamba/linux-64/latest | tar -xvj bin/micromamba结果:

16M 版本是2.3.0
然后:
创建micromamba目录
mkdir micromamba
移动 micromamba 可执行文件
mv /root/bin/micromamba /root/micromamba/
把 micromamba 加入 PATH(写入 ~/.bashrc)
echo 'export PATH=/root/micromamba:$PATH' >> /root/.bashrc
立即生效
export PATH=/root/micromamba:$PATH
输入:
which micromamba
应该输出:/root/micromamba/micromamba

然后
cd FederatedScope
创建 Python3.9 环境
micromamba create -n flscope python=3.9 -y
激活环境:
micromamba activate flscope
注,如果Shell 不支持 micromamba activate
初始化当前 bash Shell(只需执行一次)
eval "$(micromamba shell hook --shell bash)"

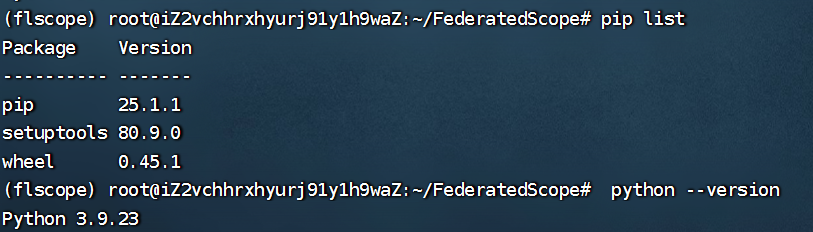
查看包和python版本:
pip list
python --version
在虚拟环境下:
- 从 GitHub 安装 FederatedScope
pip install git+https://github.com/alibaba/FederatedScope.git@master
然后pip list
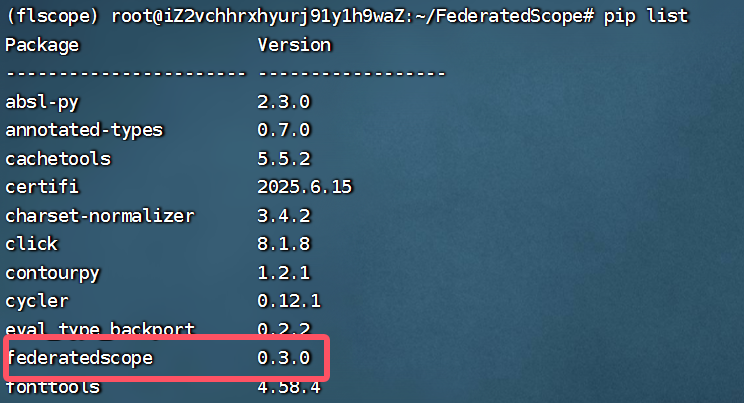
下载:PyTorch 和 torchvision(用 pip 安装 CPU 版)
pip install --index-url https://download.pytorch.org/whl/cpu \
torch torchvision
pip list查看
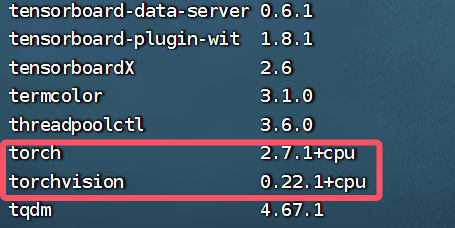
也可以验证一下:
点击查看代码
python3 - <<EOF import torch, torchvision, federatedscope print("torch:", torch.__version__) print("torchvision:", torchvision.__version__) print("federatedscope:", federatedscope.__version__) EOF
</details>
在Windows系统下,下载数据
在目录下激活虚拟环境:
venv\Scripts\activate.bat
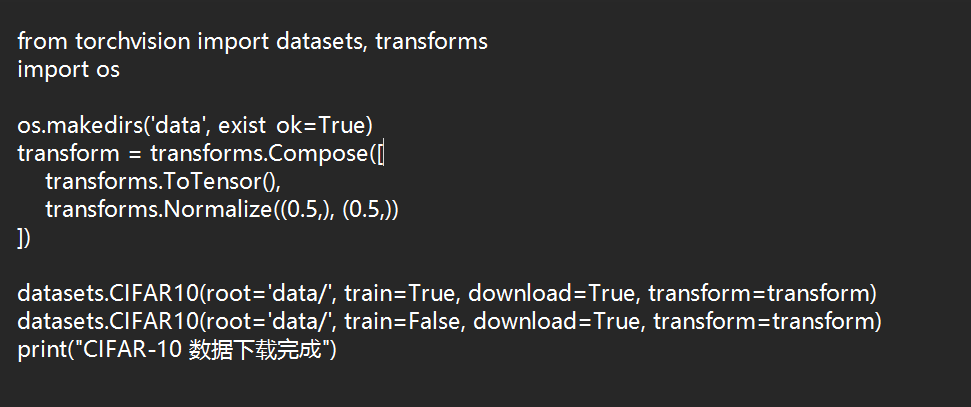
用记事本创建文件download_cifar.py
点击查看代码
from torchvision import datasets, transforms
import os
os.makedirs('data', exist_ok=True)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
datasets.CIFAR10(root='data/', train=True, download=True, transform=transform)
datasets.CIFAR10(root='data/', train=False, download=True, transform=transform)
print("CIFAR-10 数据下载完成")
结果类似:
运行脚本:
python download_cifar.py

下载完成之后应该可以在当前目录下看到data
在FederatedScope目录下:
用记事本创建split_cifar10_hetero.py用来分隔数据
点击查看代码
import torch, pickle, os
from torchvision import datasets, transforms
# 确保 data 目录存在
os.makedirs('data', exist_ok=True)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 只切训练集,本地 client_1 拿 70%
trainset = datasets.CIFAR10(root='data/', train=True, download=False, transform=transform)
total = len(trainset)
cnt0 = int(0.3 * total) # 云端 30%
cnt1 = total - cnt0 # 本地 70%
# 本地是 client_1
idx1 = list(range(cnt0, cnt0 + cnt1))
subset1 = torch.utils.data.Subset(trainset, idx1)
with open('data/client_1.pkl', 'wb') as f:
pickle.dump(subset1, f)
print(f"本地 client_1 切分完成,共 {cnt1} 张样本")
运行:
python split_cifar10_hetero.py
结果:

在FederatedScope目录下
创建文件:config_cifar10_hetero_3_7.yaml
notepad config_cifar10_hetero_3_7.yaml
点击查看代码
federate:
backend: torch
method: FedAvg
total_round_num: 50
client_num: 2
client_num_per_round: 2
data:
type: cifar10
path: ./data/
client_data_dict:
type: local-idx
data_splits:
client_0: data/client_0.pkl # 云端数据(服务器上)
client_1: data/client_1.pkl # 本地数据
model:
type: resnet8
num_classes: 10
optimizer:
type: SGD
lr: 0.05
momentum: 0.9
train:
client_0:
batch_size: 16
local_update_steps: 5
client_1:
batch_size: 64
local_update_steps: 5
logging:
use_tensorboard: True
log_dir: ./runs/cifar10_3_7
distributed:
master_addr: "47.109.149.251" #我的公网ip
master_port: 6000
world_size: 2
在Ubuntu下也一样的流程:
在虚拟环境,FederatedScope目录下
nano config_cifar10_hetero_3_7.yaml
然后把和windows一样的代码复制进去
类似:
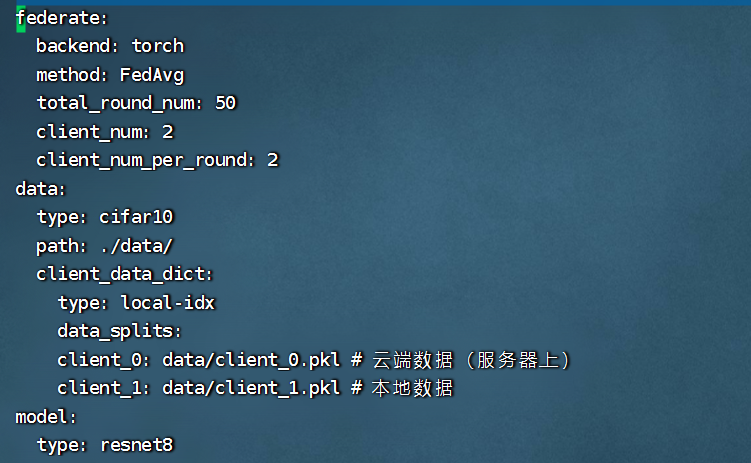
注:关于格式不对,我找不到改格式的包,我的尝试都失败了,只能手动调整格式了
注:记得在云服务器开启端口6000


 浙公网安备 33010602011771号
浙公网安备 33010602011771号