
C语言指针面试题解析(万字超多题,每题都有详解)
目录
零.前言
最近刚完成一篇c语言指针的超详解,没看过的同学可以先看一看这篇(C语言指针这一篇够了(一万二千字,包含指针与数组,函数指针等详解))再做题,会有奇迹发生的,趁热打铁搞点面试题来做一做呀,并为大家解析一波,让我们刷出自信,刷出问题,刷出offer,刷出你刚吃的晚饭(狗头保命)。声明一下,本篇以32位机器为例,即指针的大小是4个字节。
1.整型数组
#include<stdio.h>
int main()
{
int a[] = { 1,2,3,4 };
printf("%d\n", sizeof(a));
printf("%d\n", sizeof(a + 0));
printf("%d\n", sizeof(*a));
printf("%d\n", sizeof(a + 1));
printf("%d\n", sizeof(a[1]));
printf("%d\n", sizeof(&a));
printf("%d\n", sizeof(*&a));
printf("%d\n", sizeof(&a + 1));
printf("%d\n", sizeof(&a[0]));
printf("%d\n", sizeof(&a[0] + 1));
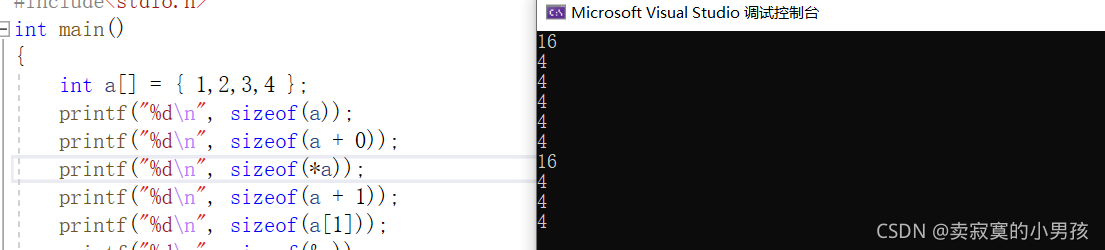
}先来看这一组题目:运行的结果是
下面来解析一下这段代码:
printf("%d\n", sizeof(a));//16 sizeof(数组名)表示的是整个数组所占的字节数,有四个元素都是整型,每个整型的大小是4个字节所以是16。
printf("%d\n", sizeof(a + 0));//4 只有当sizeof中只有数组名的时候,数组名才表示整个数组,这里加了一个0,所以数组名表示的是首元素地址,地址加0依然是首元素地址,大小为4个字节
printf("%d\n", sizeof(*a));//4 这里a依然表示首元素地址,解引用得到首元素的值,int型占四个字节。
printf("%d\n", sizeof(a + 1));//4 a是首元素地址,加一表示第二个元素的地址。是地址就是四个字节。
printf("%d\n", sizeof(a[1]));//4 表示数组第二个元素,是整型,占四个字节。
printf("%d\n", sizeof(&a));//4 虽然&a表示的是整个数组,但整个数组的地址和首元素地址是一样的,占四个字节,注意与第一个不同,这里的sizeof只是将地址认为是首元素地址(数组的地址),第一个中sizeof直接把a当成整个数组计算算的是总地址的大小。
printf("%d\n", sizeof(*&a));//16 &a代表了整个数组的地址(目前是首元素地址),然后对其解引用,表示的是整个数组的大小。
printf("%d\n", sizeof(&a + 1));//4 &a表示的是整个数组的地址,对其加一跳过整个数组,来到数组最后一个元素下一个元素的位置,该元素的地址仍然是四个字节,注意这里并不会报错,因为sizeof只关心类型,不会调用越界的地址。
printf("%d\n", sizeof(&a[0]));//4 表示的是第一个元素的地址,是地址就是4个字节。
printf("%d\n", sizeof(&a[0] + 1));//4 表示的是第二个元素的地址。
2.字符数组
1.strlen函数
首先看strlen函数,这是msdn的解释:
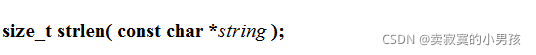
注意它的定义是传入一个指针string,strlen函数从string这个地址开始向后查找,直到找到‘\0’函数调用结束,算出有几个字符,最后的‘\0’,不算找到字符的个数。
下面我们要用strlen函数与sizeof对比,深入理解字符指针的变化。
2.arr[]={'a','b','c'....}型
1.sizeof()计算
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr + 0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr + 1));
printf("%d\n", sizeof(&arr[0] + 1));打印的结果是:

下面来解析这段代码:
printf("%d\n", sizeof(arr));//6 计算的是数组的大小,每个元素一个字节,一共有6个元素。
printf("%d\n", sizeof(arr + 0));//4 计算的是首元素地址的大小
printf("%d\n", sizeof(*arr));//1 计算的是首元素即字符型占1个字节
printf("%d\n", sizeof(arr[1]));//1 计算的是第二个元素占1个字节
printf("%d\n", sizeof(&arr));//4 计算的是整个数组的地址(首元素的地址)占四个字节
printf("%d\n", sizeof(&arr + 1));//4 计算的是数组最后一个元素之后的下一个元素的地址,占四个字节。
printf("%d\n", sizeof(&arr[0] + 1));//4 计算的是第二个元素的地址大小,是4个字节。
2.strlen()计算
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr+0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr+1));
printf("%d\n", strlen(&arr[0]+1)); 打印的结果是: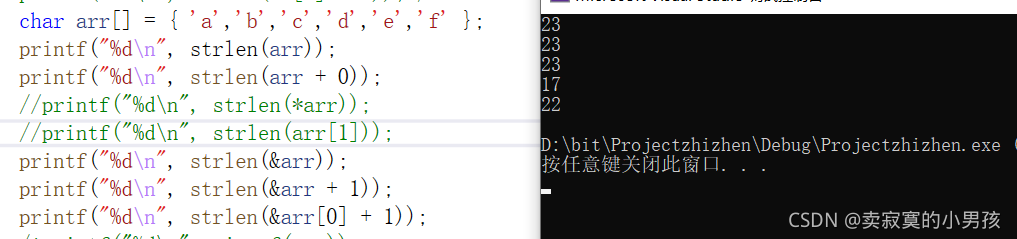
可以看到有两段代码是有问题的,我将他们屏蔽之后才能够打印出来。
下面来解析一下这段代码:
printf("%d\n", strlen(arr));//23 我们知道,strlen是以‘\0’作为自己的函数调用结束标志的,这样定义的数组中并没有定义函数名,所以strlen在查找到最后一个‘f’后,依然会沿着内存继续查找,直到找到‘\0’为止,因此打印出来的是一个随机数,随机数的大小就是这个函数从数组第一个地址开始,什么位置找到的'\0'。
printf("%d\n", strlen(arr+0));//23 和第一个是一样的+0之后没有区别。
printf("%d\n", strlen(*arr));// 这是一个错误的代码,strlen函数的参数是一个接收地址的指针,这里传入的是一个字符型数据,而不是地址。
printf("%d\n", strlen(arr[1]));// 这里也传入的是一个字符型数据,不是地址
printf("%d\n", strlen(&arr));//23 传入的是数组的地址(首元素的地址),向后查找23个后找到‘\0’。与第一个和第二个是对应的。
printf("%d\n", strlen(&arr+1));//17 从数组最后一个元素下一个元素开始查找,与第一个对应,比第一个少了6个元素。
printf("%d\n", strlen(&arr[0]+1));//22 从第二个元素开始查找,比第一个少了1个元素。
3.char arr[]="abcd..."型
这种类型与上一种的区别在于,这样定义字符串数组默认在数组后面加了一个‘\0’。
1.sizeof()计算
char arr[] = "abcdef";
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr+0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr+1));
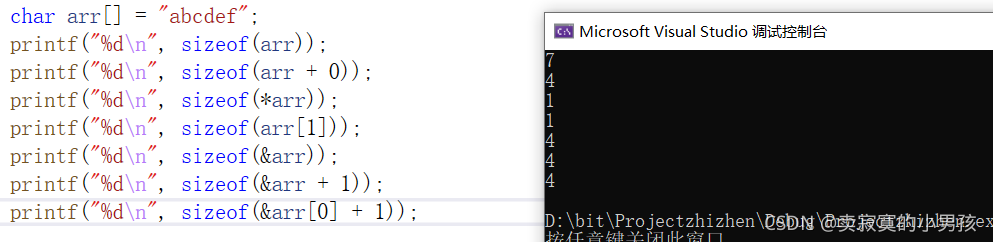
printf("%d\n", sizeof(&arr[0]+1));这段代码运行的结果是:
下面来解析一下这段代码:
printf("%d\n", sizeof(arr));//7 计算arr所占多少个字节,除了6个元素之外还有一个'\0'共7个字符型变量,共占7个字节。
printf("%d\n", sizeof(arr+0));//4 arr代表首元素地址,是地址大小就是四个字节。
printf("%d\n", sizeof(*arr));//1 对首元素地址解引用得到首元素,是字符型,所以占一个字节。
printf("%d\n", sizeof(arr[1]));//1 第二个元素占一个字节
printf("%d\n", sizeof(&arr));//4 &arr取出的是整个数组的地址(首元素的地址),占4个字节。
printf("%d\n", sizeof(&arr+1));//4 表示数组最后一个元素的下一个刚好越界元素的地址,四个字节。
printf("%d\n", sizeof(&arr[0]+1));//4 表示的是数组第二个元素的地址大小,是四个字节。
2.strlen()计算
char arr[] = "abcdef";
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr + 0));
//printf("%d\n", strlen(*arr));
//printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr + 1));
printf("%d\n", strlen(&arr[0] + 1));打印的结果是:
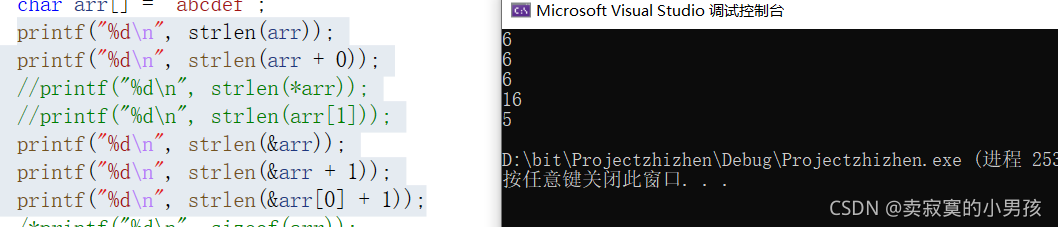
下面来解析一下这段代码:
printf("%d\n", strlen(arr));//6 由于默认录入了'\0'所以计算的字符个数就是传入的个数6。
printf("%d\n", strlen(arr + 0));//6 同理加0与第一个是等价的。
//printf("%d\n", strlen(*arr));// 错误代码,传入的是第一个元素,strlen函数的参数是一个地址。
//printf("%d\n", strlen(arr[1]));// 错误代码,传入的是第二个元素。
printf("%d\n", strlen(&arr));//6 传入的是整个数组的地址(首元素的地址),从这里开始直到找到'\0'为止,中间共有数组的六个字符。
printf("%d\n", strlen(&arr + 1));//16 是一个随机值,从数组最后一个元素‘\0’开始向后查找,直到找到‘\0’为止,中间有16个元素。
printf("%d\n", strlen(&arr[0] + 1)); //5 从第二个元素开始查找,比第一个例子少1一个字符,共找到5个数组中元素。
3.char *p="abcd..."型
1.sizeof()计算
char *p = "abcdef";
printf("%d\n", sizeof(p));
printf("%d\n", sizeof(p+1));
printf("%d\n", sizeof(*p));
printf("%d\n", sizeof(p[0]));
printf("%d\n", sizeof(&p));
printf("%d\n", sizeof(&p+1));
printf("%d\n", sizeof(&p[0]+1));打印的结果是:
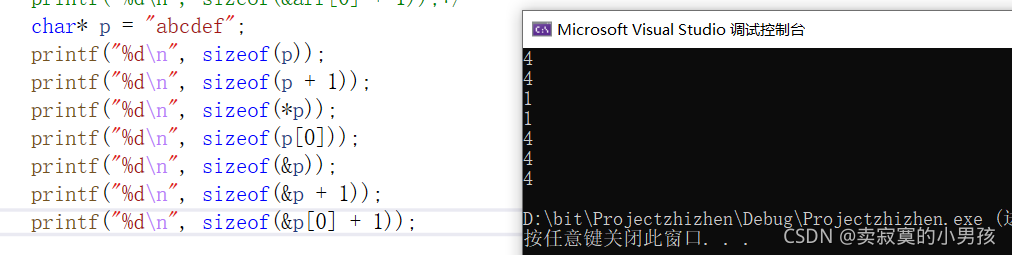 下面来解析一下这段代码:
下面来解析一下这段代码:
printf("%d\n", sizeof(p));//4 p存放的是第一个元素a的地址,是地址就是4个字节。
printf("%d\n", sizeof(p+1));//4 表示第二个元素的地址
printf("%d\n", sizeof(*p));//1 对第一个元素地址解引用得到a,占一个字节。
printf("%d\n", sizeof(p[0]));//1 第一个元素
printf("%d\n", sizeof(&p));//4 指针的地址也是一个地址,所以是四个字节。
printf("%d\n", sizeof(&p+1));//4 指针地址的下一个地址所以也是4个字节。
printf("%d\n", sizeof(&p[0]+1));//4 第二个元素b的地址。
2.strlen()计算
char* p = "abcdef";
printf("%d\n", strlen(p));
printf("%d\n", strlen(p+1));
printf("%d\n", strlen(*p));
printf("%d\n", strlen(p[0]));
printf("%d\n", strlen(&p));
printf("%d\n", strlen(&p+1));
printf("%d\n", strlen(&p[0]+1));打印的结果是:
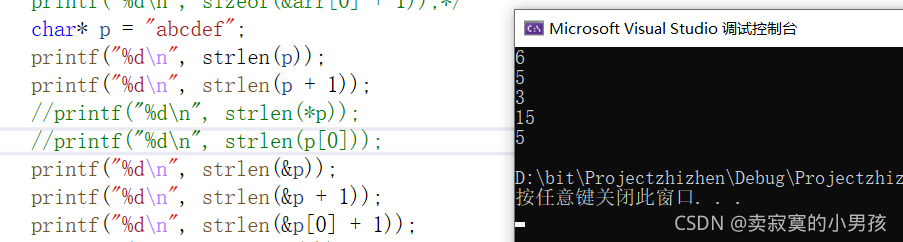
下面来解析一下这段代码:
printf("%d\n", strlen(p));//6 strlen函数只关心传入的首地址,之后就会依次向后排查,传入的首地址是a的地址,经过6个元素之后找到了'\0'。
printf("%d\n", strlen(p + 1));//5 从第二个元素开始排查,比第一个例子少了一个元素,所以是5个。
//printf("%d\n", strlen(*p));// 传入的是a这个字符,不是地址所以出错
//printf("%d\n", strlen(p[0]));// 传入的是字符,不是地址。
printf("%d\n", strlen(&p));//3 传入的是指针的地址,即从指针的地址开始向后查找‘\0’,而不是从数组首元素的地址开始查找,因此是一个随机值。
printf("%d\n", strlen(&p + 1));//15 和上一个一样,从存放首元素地址的指针的地址的下一个地址开始向后查找。所以是一个随机值,因为地址中不一定存的是字符,所以无法确实与上一个的关系。
printf("%d\n", strlen(&p[0] + 1)); //5从第二个元素的地址开始查找,共找到5个字符。
3.二维数组
int a[3][4] = { 0 };
printf("%d\n", sizeof(a));
printf("%d\n", sizeof(a[0][0]));
printf("%d\n", sizeof(a[0]));
printf("%d\n", sizeof(a[0] + 1));
printf("%d\n", sizeof(*(a[0] + 1)));
printf("%d\n", sizeof(a + 1));
printf("%d\n", sizeof(*(a + 1)));
printf("%d\n", sizeof(&a[0] + 1));
printf("%d\n", sizeof(*(&a[0] + 1)));
printf("%d\n", sizeof(*a));
printf("%d\n", sizeof(a[3]));这段代码打印出来的结果是这样的:
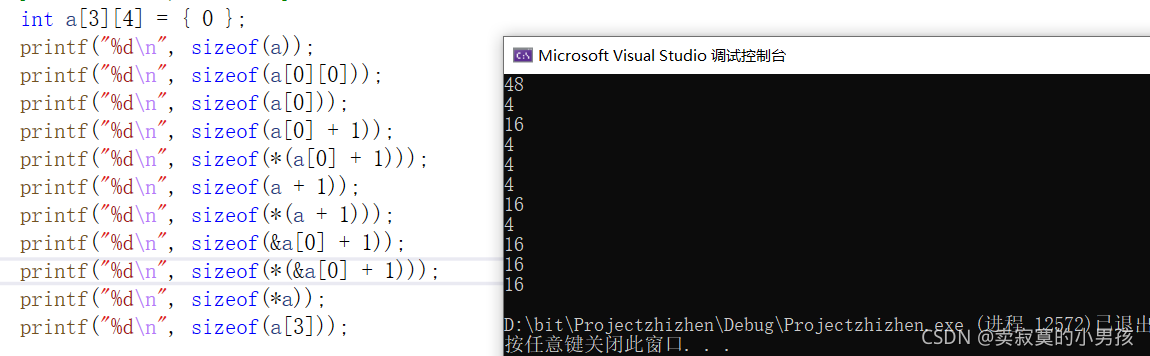
下面来解析一下这段代码:
printf("%d\n", sizeof(a));//48 sizeof(数组名)表示的是整个数组的大小,共有12个元素,每个元素占四个字节,所以共占48个字节。
printf("%d\n", sizeof(a[0][0]));//4 第一行第一个元素的大小是四个字节。
printf("%d\n", sizeof(a[0]));//16 二维数组中a[0]表示的是第一行的数组名,可以根据a[0]等价于*(a+0)理解,二维数组中数组名表示第一行地址,对第一行地址解引用得到的是第一行元素,即计算的是第一行元素共占空间的大小,是16个字节。
printf("%d\n", sizeof(a[0] + 1));//4 表示的是第二行首元素的地址大小,虽然a[0]是第一行的数组名,但是放入sizeof的还有+1这一内容,合起来sizeof计算的就是第二行的地址也就是第二行首元素的地址。
printf("%d\n", sizeof(*(a[0] + 1)));//4 *(a[0]+1)等价于a[0][1]计算的是第一行第二个元素的大小,为4。
printf("%d\n", sizeof(a + 1));//4 a表示的是第一行的地址,+1表示的是第二行的地址(第二行首元素的地址),大小是4个字节。
printf("%d\n", sizeof(*(a + 1)));//16 等价于a[1]表示的是第二行的数组名,sizeof(数组名)表示的是一行所有元素所占空间的大小,是16个字节。
printf("%d\n", sizeof(&a[0] + 1));//4 a[0]是第一行数组名,&a[0]表示整个第一行的地址,+1表示第二行的地址(第二行首元素的地址),占4个字节。
printf("%d\n", sizeof(*(&a[0] + 1)));//16 &a[0]表示的是第一行的地址,+1表示的是整个第二行的地址,再解引用表示的是整个第二行所占空间大小,是16个字节。
printf("%d\n", sizeof(*a));//16 对第一行元素解引用,计算的是第一行元素所占空间大小是16个字节。
printf("%d\n", sizeof(a[3]));//16 a[3]表示的是越界的一行所占的空间大小,是16个字节,由于sizeof不会真的去访问那段空间,所以也不会报错。
博主写崩溃了,放张图休息一下。。。。

4.判断程序运行结果大题
笔试题1:
int a[5] = { 1, 2, 3, 4, 5 };
int *ptr = (int *)(&a + 1);
printf( "%d,%d", *(a + 1), *(ptr - 1));打印出来的结果是啥嘞:

我们来分析一下:
首先*(a+1)等价于a[1],所以打印出来的是2。&a表示的是整个数组的地址,加一之后刚好指向数组最后一个元素的下一个元素的地址,对ptr减一,刚好指向数组的最后一个元素5,所以打印的是2和5.
笔试题2:
struct Test
{
int Num;
char* pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
//假设p 的值为0x000000。 如下表表达式的值分别为多少?
int main() {
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}打印的结果是:
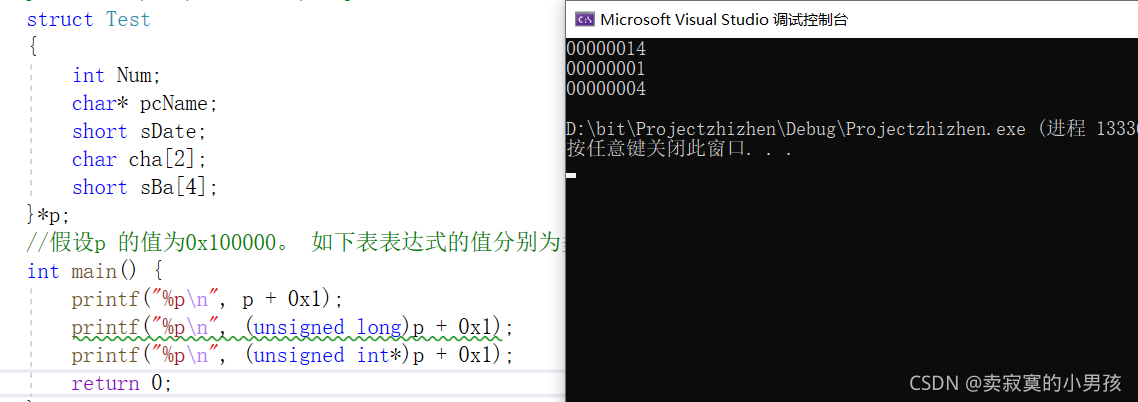
这里先告诉大家,这个结构体占的字节数是20个字节。
我们来解析一下:
首先p是一个指向结构体的指针,所指向的结构体占20个字节,指针加减整数和指针类型有关,所以指针加1之后,跳过20个字节,在16进制中20表示为0x00000014所以打印出来这个结果。
第二次打印先将p强行转化成long类型,加一就是加一,因为p不再是一个指针。
第三次打印将p强行转化成(int*)类型,加一跳过4个字节。
笔试题3:
int a[4] = { 1, 2, 3, 4 };
int* ptr1 = (int*)(&a + 1);
int* ptr2 = (int*)((int)a + 1);
printf("%x,%x", ptr1[-1], *ptr2);打印的结果是:
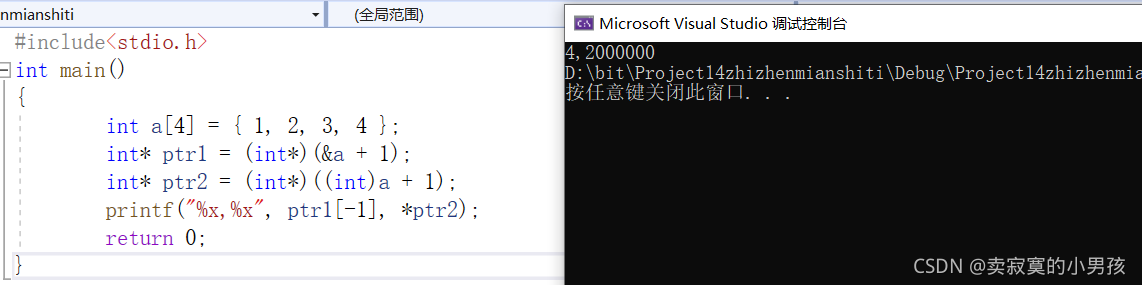
我们来分析一下:
首先分析ptr1,&a表示的是整个数组的地址,再+1表示的是跳过整个数组大小的内存,即此时(&a+1)表示的是数组a的最后一个元素的下一个元素,由于&a表示整个数组,所以此地址表示的是从该元素开始向后数,大小为a的大小的数组的地址。再将其强行转换为int*类型,得到的就是该元素的地址,要打印的是ptr[-1],等价于*(ptr-1),ptr-1指向的是数组a的最后一个元素,再对其进行解引用的到最后一个元素4。
然后分析ptr2,首先a代表首元素的地址,将它转换成int类型,即将首元素地址转化成了代表地址的二进制序列的那个数。
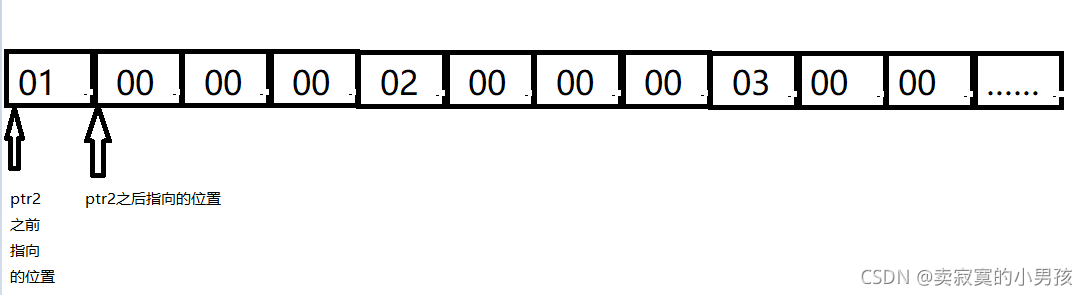
我们把每一个小方格看成一个字节,四个字节表示一个整型,前四个字节代表1这个数,前四个字节的读法为倒着读,写成16进制的1为00 00 00 01。
假设a的地址原来是1122ff33,那么a的地址整型化之后再加一,就得到1122ff34,我们知道每一个二进制序列代表一个字节,所以地址加一后代表a的首元素地址的下一个字节(看图更清晰呀!),在将这个数强行转化成int*型,即又将其转化成了一个地址,而ptr2就指向这个地址。找到了这个地址也就找到了ptr2。在根据是以整型的方式打印,所以从ptr2开始数4个字节,打印的就是这4个字节所代表的数。即00 00 00 02代表的16进制数是02 00 00 00,所以打印的是2000000。
笔试题4:
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int *p;
p = a[0];
printf( "%d", p[0]);
打印的结果是:

首先我们观察数组,里面放的是逗号表达式,逗号表达式的结果是最后一个表达式的值,所以数组中存放的内容是:
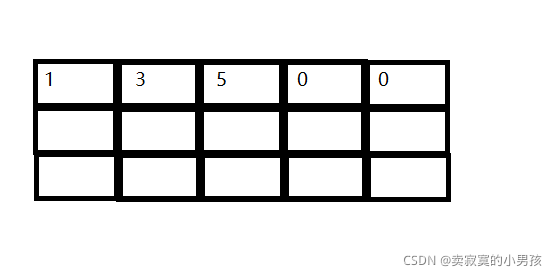
下面两行空白部分都是0。
a[0]代表的是第一行的数组名,即首元素地址,则p内存放的是首元素的地址,p[0]等价于*(p+0),所以得到的是首元素1。
笔试题5:
int a[5][5];
int(*p)[4];
p = a;
printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
打印的结果是:
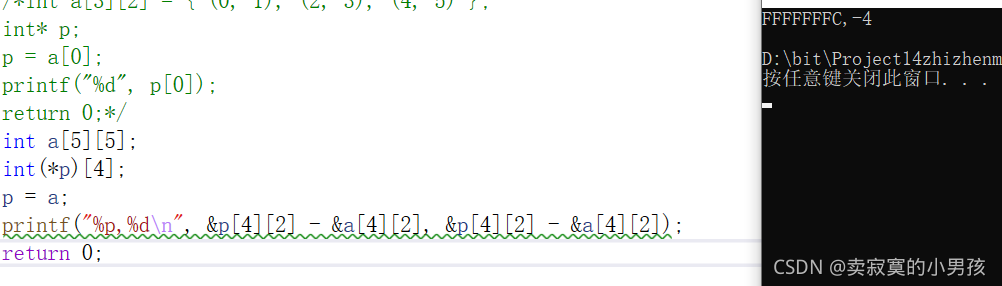
首先定义了一个二维数组,但没有涉及到数组内容,所以没初始化,定义了p是一个指向含有4个整型元素的指针,注意a数组一行是五个元素。此时让p指向a,效果是这样的:

我们知道二维数组也是一段连续的内存,首先p指向了首行的地址。
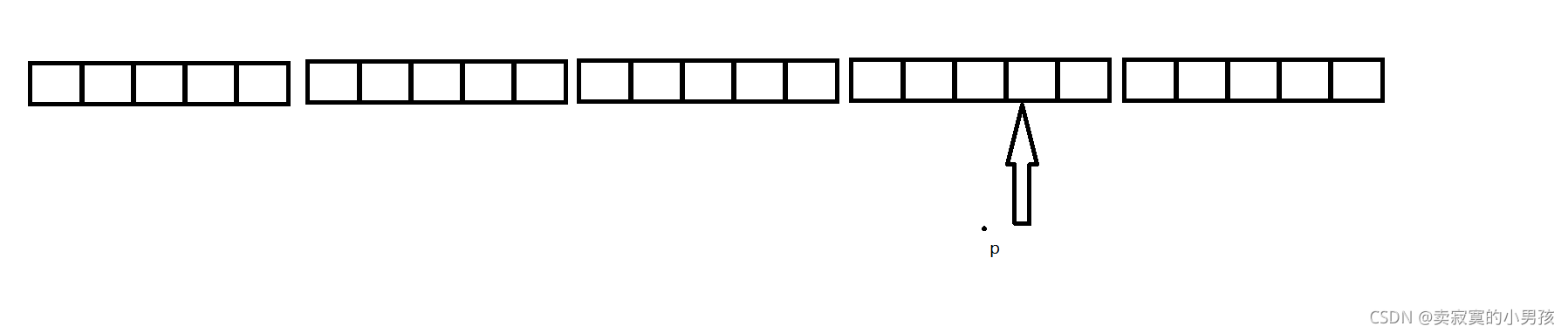
p[4][2]等价于*(*(p+4)+2),p是一个指向含有四个整型的指针,所以p+4表示的是跳过4*4个整型的元素,此时p的位置是:

现在对其进行解引用,p是一个指向数组的指针,所以它依然是指向一个含有四个整型的数组(从p开始向后数四个整型),对p+4解引用得到的是这个数组的数组名,即为首元素地址,即图中箭头所指位置的地址,再对首元素的地址加2,得到p[4][2]的地址。即为这个位置:
这个地址就是&p[4][2],同时我们也可以找到a[4][2]的位置:
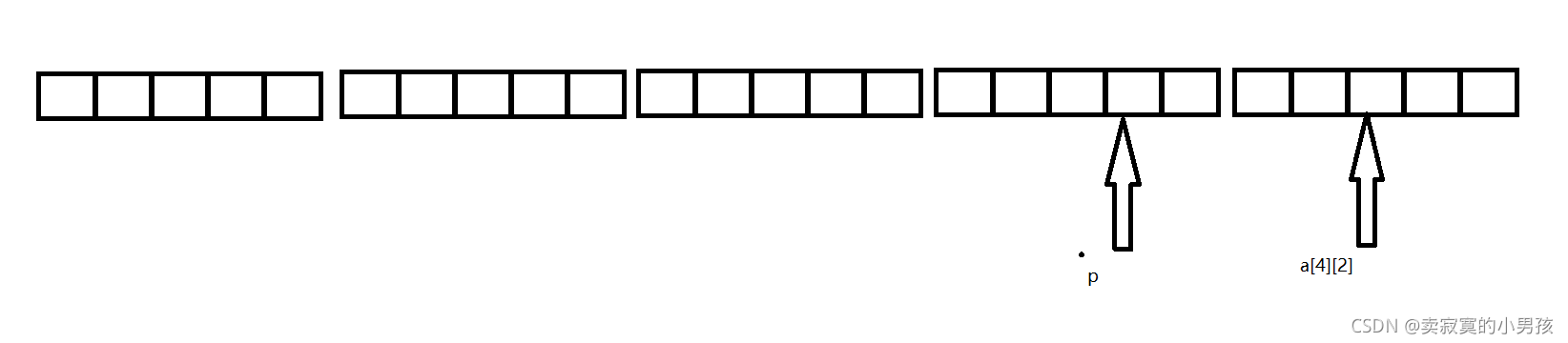
两个地址的差是两个地址间的元素个数,所以用%d打印的结果是-4,用%p打印的应该是一个地址,我们先看-4这个数在内存中的补码是:
11111111 111111111 11111111 11111100
转换成16进制就是FFFFFFFC。
笔试题6:
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int *ptr1 = (int *)(&aa + 1);
int *ptr2 = (int *)(*(aa + 1));
printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1));
打印的结果是:

下面我们来分析一下:
首先定义了一个二维数组,第一行元素是1,2,3,4,5 第二行元素是6,7,8,9,10
&aa拿到的是整个数组的地址,此时表示的是首元素的地址,+1拿到的是10之后的元素的地址(注意这个地址表示以该元素为起点,和aa数组一样大的数组的地址),强行转化成int*型才真正拿到10之后的那个越界元素的地址,即为ptr1的指向。在对其-1拿到的是10的地址,解引用打印出来的是10。
aa表示的是第一行的地址,+1表示的是第二行的地址,再解引用表示的是第二行的数组名即第二行首元素的地址,这里的强行转换是多余的。即ptr2指向的是6这个元素的地址,-1拿到5的地址,再解引用打印的是5。
笔试题7:
char* a[] = { "work","at","alibaba" };
char** pa = a;
pa++;
printf("%s\n", *pa);这段代码的运行结果是:

下面我们来分析一下:
首先定义了一个指针数组,每一个元素都是一个指针,共三个元素,存放的分别是w,a,a的地址,定义了一个二级指针pa,使它指向指针数组的首元素地址(首元素是一个指针),pa+1拿到的是指针数组第二个元素的地址,对其进行%s解引用打印,得到的就是at。
笔试题8:
char* c[] = { "ENTER","NEW","POINT","FIRST" };
char** cp[] = { c + 3,c + 2,c + 1,c };
char*** cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *-- * ++cpp + 3);
printf("%s\n", *cpp[-2] + 3);
printf("%s\n", cpp[-1][-1] + 1);打印的结果是这样的:
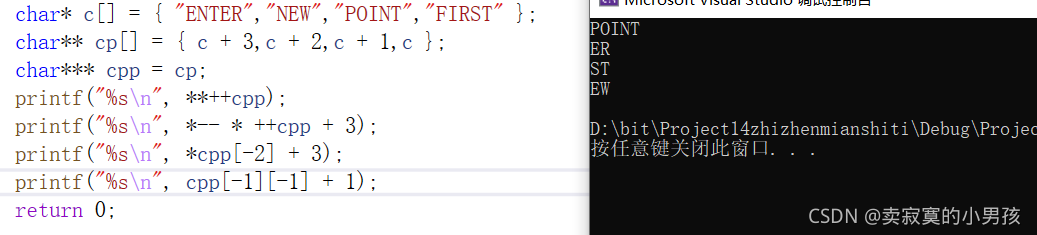
这段代码比较复杂,先根据代码画一张关系图:
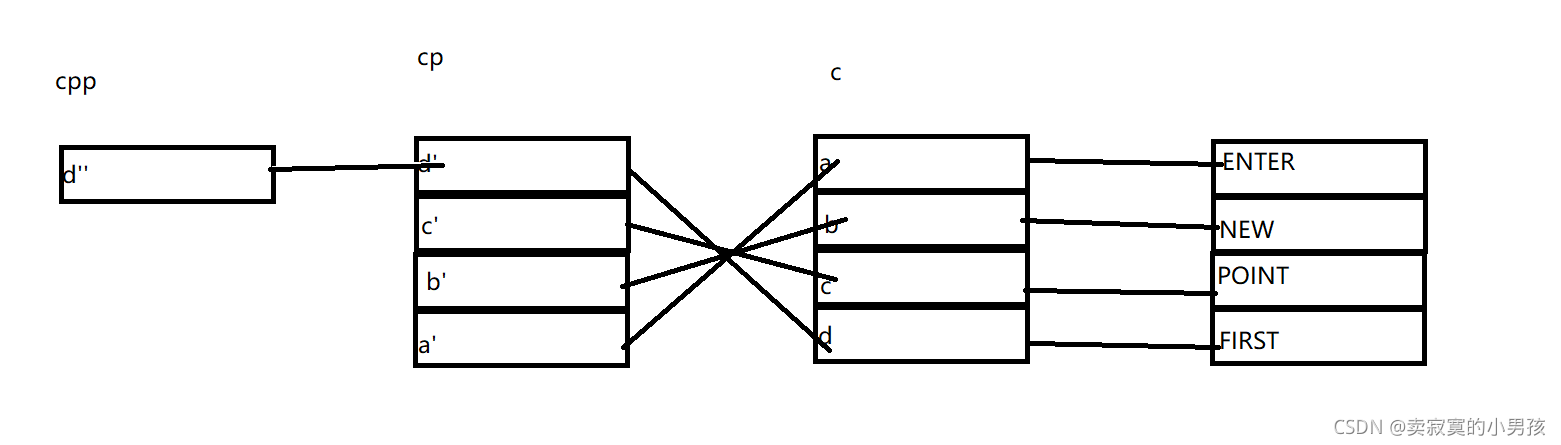
从左到右依次是指向关系,c数组中a元素指向ENTER,cp中a'指向a依次类推。
c,cp,cpp分别放的是一级指针,二级指针和三级指针。
注意前一步打印的结果对后一步打印的结果是有影响的,我们一步一步来。
首先分析**++cpp,对cpp++即cpp指向了c',对cpp解引用得到了c',再对c'进行解引用得到了c也就是P的地址,对其进行%s打印得到字符串POINT。
第一步运行完指针的指向是这样的:
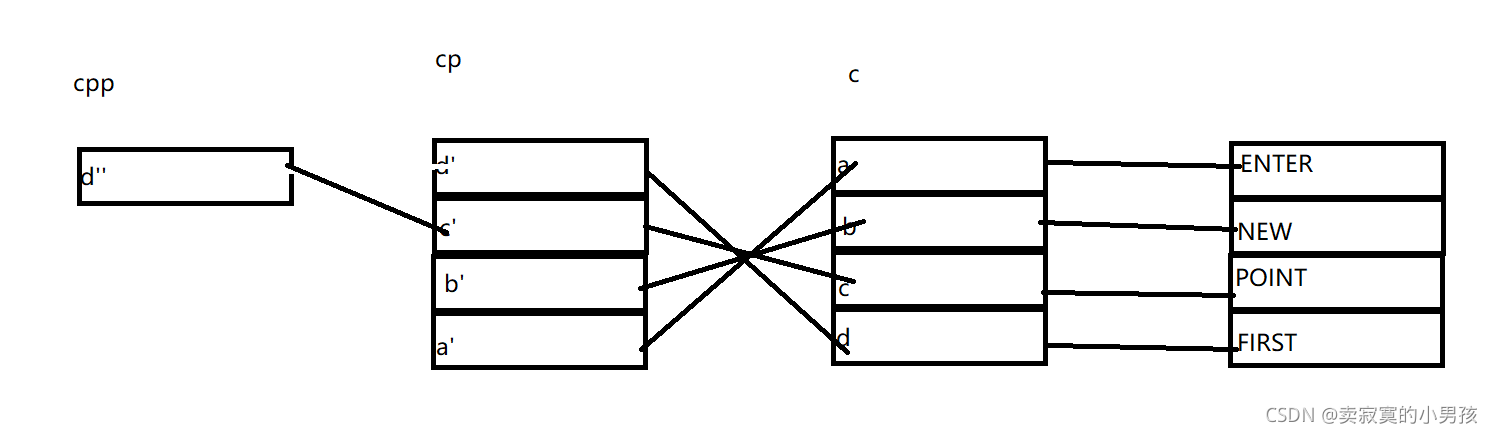
下面进行第二步:*--*++cpp+3,首先对cpp++使得cpp指向b'的地址,再解引用得到b',然后对b'这个值-1,注意这里是修改了b'的值,原来b'指向的是b对其减一就指向了a,再解引用拿到了a,a指向的是E的地址,+3指向了后面的E,所以打印出来是ER(每一个单词最后都有一个\0)。
第二步进行完关系是这个样子的。
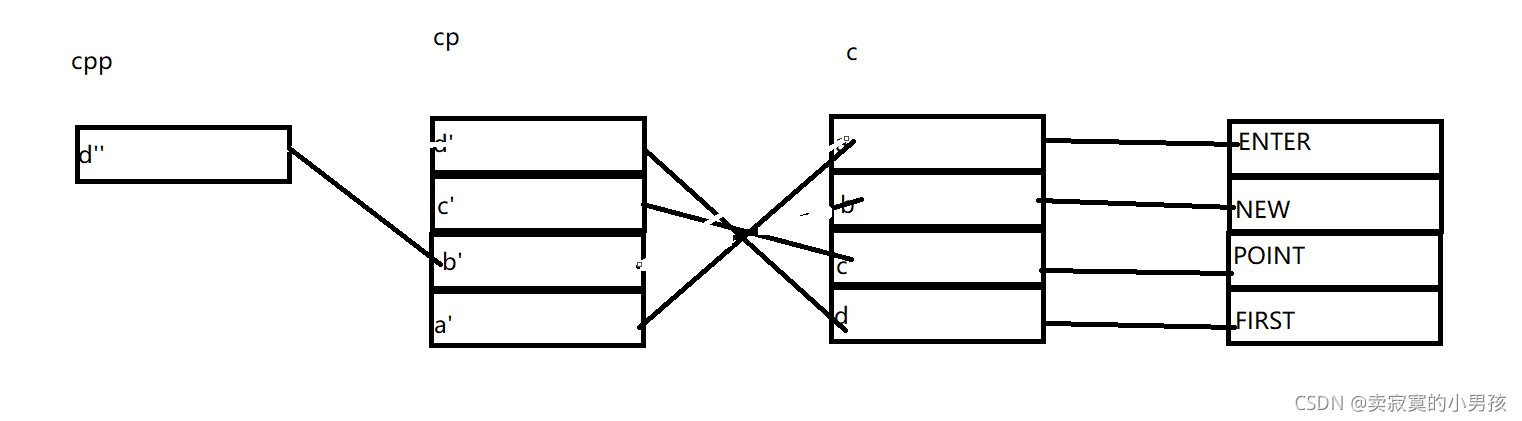
再来第三步: *cpp[-2] + 3,cpp[-2]等价于*(cpp-2),cpp-2找到了d'的地址,再解引用拿到了d',再解引用拿到的是d,即F的地址,再加3,拿到的是S的地址,%s打印出来的就是ST。
第三步没有改变指针指向,所以还是这张图。
最后进行第四步:cpp[-1][-1] + 1,cpp[-1][-1]等价于*(*(cpp-1)-1),cpp减1得到的是c'的地址,再解引用得到的是c',再减1,c'原来指向的是c减1后c'指向b,即N的地址,再加1a得到的是E的地址,所以打印的是EW。
5.总结
又肝完了一篇,又是一万多字,突然发现原来我可以这么细,不知道你们做完题之后又看见自己的晚饭没呀?都说C语言最难的部分是指针,如果你没看我的讲解就全做对了的话,,,,请留下你的联系方式,让我模一模大佬呀,这些题都是找工作时的面试题,都搞定了的话大厂的面试的C语言关就基本通过了,路漫漫其修远兮,让我们在编程中一起上下求索吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号