

20182324 2019-2020-1 《数据结构与面向对象程序设计》第9周学习总结
20182324 2019-2020-1 《数据结构与面向对象程序设计》第9周学习总结
教材学习内容总结
-
1、树 ( tree ) 由一组结点 ( node ) 及一组边 ( edge ) 构成,结点用来保存元素,边表示结点之间的连接。
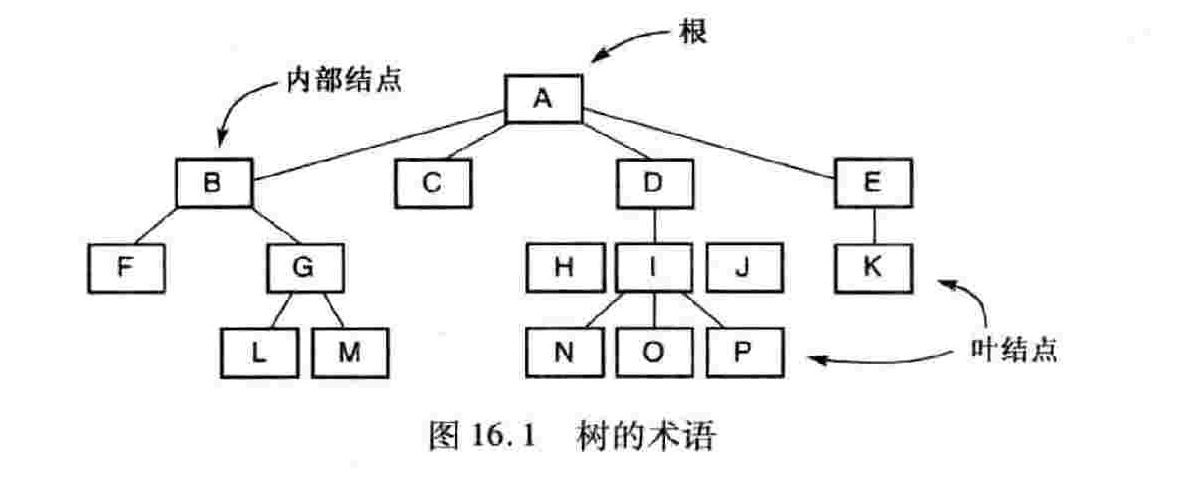
-
2、树的高度 ( height ) 或深度 ( depth ) 定义为树中从根到叶结点的最长路径的长度。有 m 个元素的平衡 n 叉树的高度为 log n m 。树的度 ( order ) 表示树中任意节点的最大子结点数。如果树的所有子结点都在同一层上,或彼此最多不超过一层,则认为树是平衡的 ( balanced )。
-
3、满 n 叉树 ( full ):树的所有叶结点都在同一层,并且每个非叶结点都正好有 n 个子结点。完全 n 叉树 ( complete ):树是满的,或一直到倒数第二层都是满的且最底层的所有叶结点都位于树的左侧。
-
4、树的遍历
- 先序遍历:从根结点开始,访问每一个结点及其孩子。
Visit node Traverse(left child) Traverse(right child)- 中序遍历:从根结点开始,访问结点的左侧孩子,然后是该结点,之后是剩余下结点。
Traverse(left child) Visit node Traverse(right child)- 后序遍历:从根结点开始,访问结点的孩子,然后是该结点。
Traverse(left child) Traverse(right child) Visit node- 层序遍历:从根节点开始,访问每一层的所有结点,一次一层。
先序遍历 preorder traversal 访问根,自左至右遍历子树 中序遍历 inorder traversal 遍历左子树,然后访问根,然后自左至右遍历余下的各个子树 后序遍历 postorder traversal 自左至右遍历各子树,然后访问根 层序遍历 level-order traversal 从树的顶层(根)到底层,从左至右,访问树中每层的每个结点 
-
5、二叉查找树是对二叉树定义的扩展,对于其中的每个结点,左子树上的元素小于父结点的值,而右子树上的元素大于等于父结点的值。最有效的二叉查找树是平衡的,所以每次比较时可以排除一半的元素。
操作 说明 addElement 往树中添加一个元素 removeElement 从树中删除一个元素 removeAllOccurrences 从树中删除所指定元素的任何存在 removeMin 删除树中最小的元素 removeMax 删除树中最大的元素 findMin 返回一个指向树中最小元素的引用 findMax 返回一个指向树中最大元素的引用 -
6、用链表 BinarySearchTreeList 实现二叉查找树。
操作 描述 LinkedList BinarySearchTreeList add 向有序列表中添加一个元素 O ( n ) O ( log n ) removeFirst 删除列表的首元素 O ( 1 ) O ( log n ) removeLast 删除列表的末元素 O ( n ) O ( log n ) remove 删除列表中的一个特定元素 O ( n ) O ( log n ) first 返回列表的首元素 O ( 1 ) O ( log n ) last 返回列表的末元素 O ( n ) O ( log n ) contains 判断列表是否含有一个特定元素 O ( n ) O ( log n ) isEmpty 判断列表是否为空 O ( 1 ) O ( log 1 ) size 判断列表中的元素数目 O ( 1 ) O ( log 1 ) -
7、平衡二叉查找树:可以对二叉查找树进行旋转以恢复平衡。
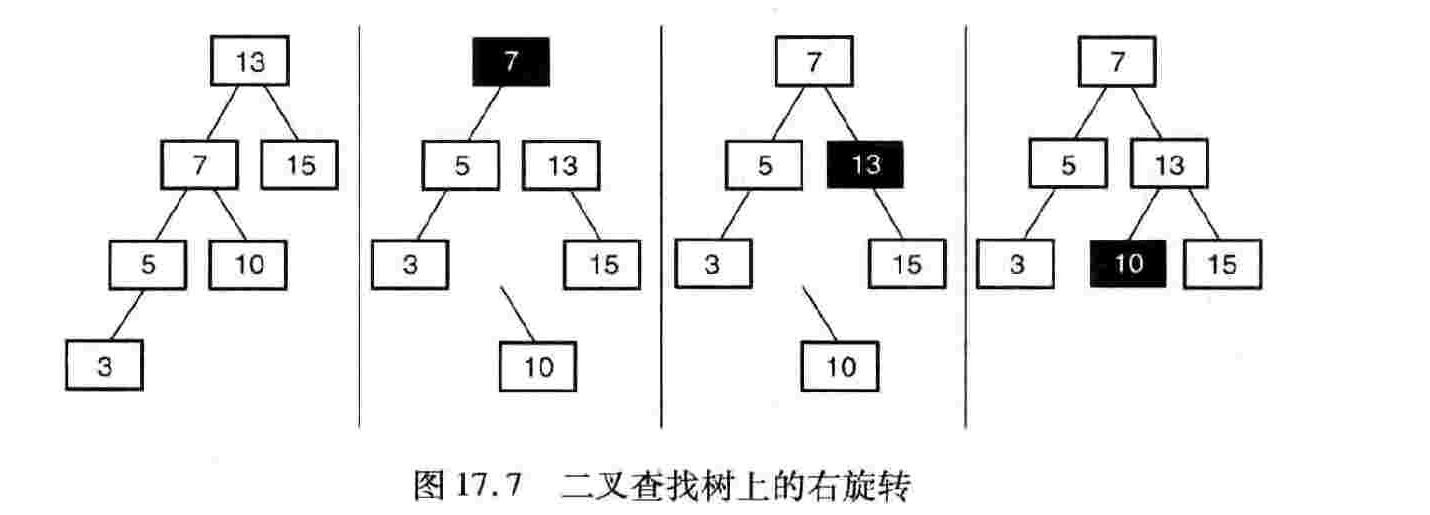
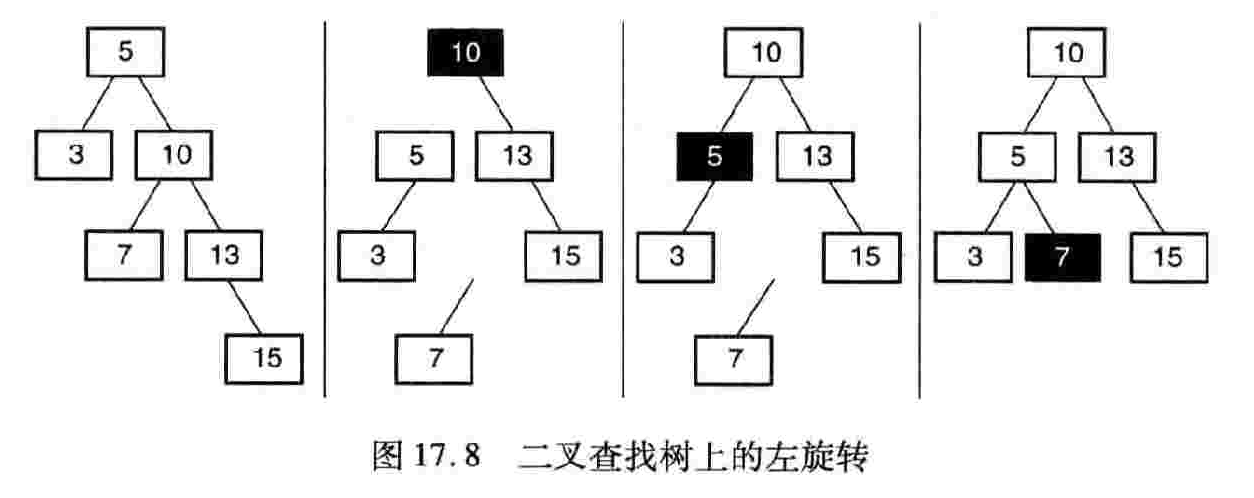
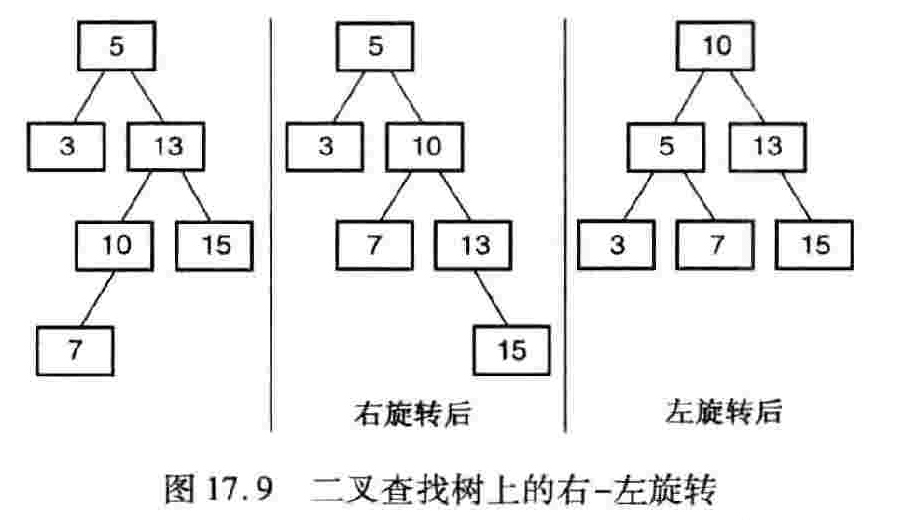

教材学习中的问题和解决过程
-
问题1:变量 modCount 是什么?
-
问题1解决方案:JDK 帮助文档对其释义如下:已从结构上修改 此列表的次数。从结构上修改是指更改列表的大小,或者打乱列表,从而使正在进行的迭代产生错误的结果。
此字段由 iterator 和 listIterator 方法返回的迭代器和列表迭代器实现使用。 -
问题2:完美 ( Perfect ) 二叉树 v.s. 完全 ( Complete ) 二叉树
-
问题2解决方案:一个深度为k ( >= -1 ) 且有 2^( k + 1 ) - 1 个结点的二叉树称为完美二叉树。 ( 国内数据结构教材大多翻译为“满二叉树”);完全二叉树从根结点到倒数第二层满足完美二叉树,最后一层可以不完全填充,其叶子结点都靠左对齐。
一棵完美 ( Perfect ) 二叉树看起来是这个样儿的:
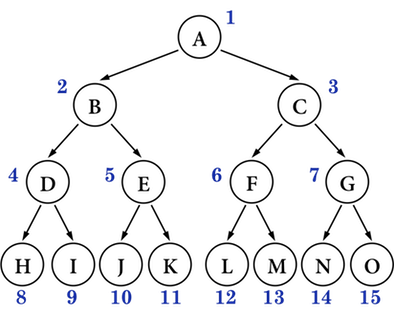
那么,将编号为15, 14, ..., 9的叶子结点从右到左依次拿掉或者拿掉部分,则是一棵完全 ( Complete ) 二叉树。例如,将上图中的编号为 15, 14, 13, 12, 11 叶子结点都拿掉 ( 从右到左的顺序 ) ,

下图就不是一棵完全 ( Complete ) 二叉树,如果将编号 11 ( K ) 结点从编号 6 ( E ) 的左儿子位置移动到编号 5 ( E ) 的右儿子位置,则变成一棵完全( Complete ) 二叉树。

综上所述:完美 ( Perfect ) 二叉树一定是完全( Complete ) 二叉树,但完全 ( Complete ) 二叉树不一定是完美 ( Perfect ) 二叉树。
代码调试中的问题和解决过程
- 问题:按照书上代码补充实现 LinkedBinaryTree,在 ArrayIterator 处报错。
- 问题解决方案:可用 ArrayList 代替,ArrayList 类的已实现接口中包含 Iterable<E> 。
代码托管
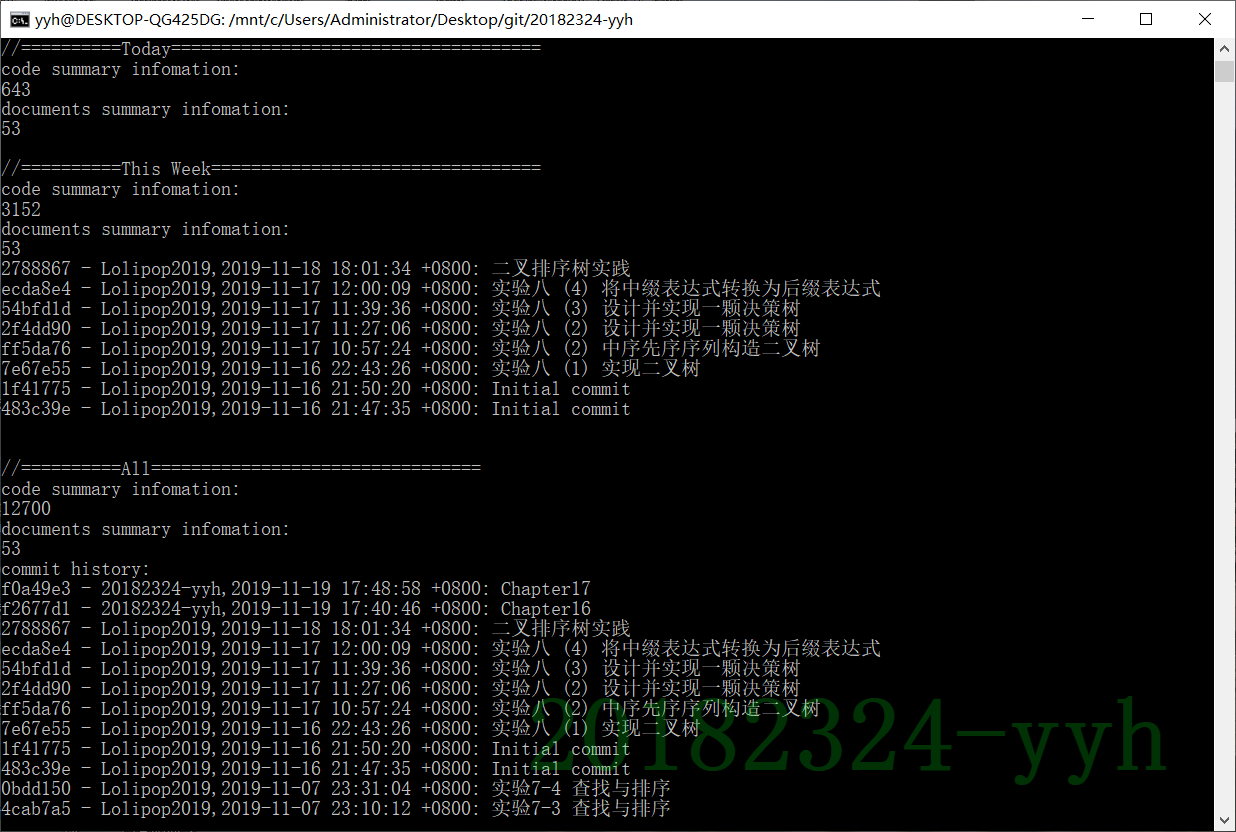
(statistics.sh脚本的运行结果截图)
上周考试错题总结
-
In an ideal implementations of a stack and a queue, all operations are ______________________ .
A. O( 1 )
B. O( n )
C. O( n log n )
D. O( n² )
E. it depends on the operation
解析:In good implementations of stacks and queues, all operations require a constant amount of time. -
In a array-based implementation of a queue that stores the front of the queue at index 0 in the array, the dequeue operation is ___________________.
A. impossible to implement
B. has several special cases
C. O( n )
D. O( n² )
E. none of the above
解析:It requires a linear amount of time to shift all elements of the queue down an index after a remove is applied. -
In a circular array-based implementation of a queue, the elements must all be shifted when the dequeue operation is called.
A. true
B. false
解析:A circular array-based implementation of a queue eliminates the need to shift elements, so all queue operations can be achieved in constant time. -
One of the uses of trees is to provide simpler implementations of other collections.
A. true
B. false -
Since a heap is a binary search tree, there is only one correct location for the insertion of a new node, and that is either the next open position from the left at level h or the first position on the left at level h+1 if level h is full.
A. true
B. false
结对及互评
点评:
-
博客中值得学习的或问题:
- 图文并茂,有参考资料
- markdown 格式运用较为熟练
-
代码中值得学习的或问题:
- 代码格式规范,合理使用空白,便于阅读
-
基于评分标准,我给本博客打分:14分。得分情况如下:
- 1、正确使用Markdown语法(加1分)
- 2、模板中的要素齐全(加1分)
- 3、教材学习中的问题和解决过程(2分)
- 4、代码调试中的问题和解决过程(1分)
- 5、本周有效代码超过300分行的(加2分)
- 6、其他加分:
- 感想,体会不假大空的加1分
- 进度条中记录学习时间与改进情况的加1分
- 有动手写新代码的加1分
- 代码Commit Message规范的加1分
- 错题学习深入的加1分
- 点评认真,能指出博客和代码中的问题的加1分
- 结对学习情况真实可信的加1分
点评过的同学博客和代码
- 本周结对学习情况
-
结对学习内容
- 创建 Node 的 ADT 接口,以及 Link 的 ADT 接口以适应树的建立。
- 学习理解二叉树、完全二叉树、满二叉树的概念。
- 学会使用树的先序遍历、中序遍历、后序遍历,来查找、建立二叉树。
- 学习二叉树的排序方法,并运用二叉树查找。
- 学习实现二叉排序树。
其他(感悟、思考等,可选)
二叉树是一种应用较为广泛的数据结构,它支持在多种情况下进行查找、决策与排序。在预备作业时我就提到,本学期实践 10000 行代码的负担不大,就目前而言已经是突破了这一目标,但由于还有其它学科的学习原因,要达到 30 篇博客和 400 小时学习时间的任务依旧很重。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 10000行 | 30篇 | 400小时 | |
| 第一周 | 109/109 | 2/2 | 28/28 | 学习了Java的基本语法格式,熟练使用 Linux Bash 命令 |
| 第二周 | 550/659 | 1/3 | 23/51 | 学习掌握JDB调试命令 |
| 第三周 | 1028/1687 | 2/5 | 30/81 | 学习类的编写与使用 |
| 第四周 | 542/2229 | 2/7 | 22/103 | 学习方法重载,类的继承、聚合等 |
| 第五周 | 1197/3426 | 2/9 | 15/118 | 学习 Java Socket ,了解加密算法 |
| 第六周 | 1344/4770 | 1/10 | 22/140 | 学习多态与异常处理 |
| 第七周 | 3190/7960 | 2/12 | 30/170 | 学习Android |
| 第八周 | 1588/9548 | 2/14 | 30/200 | 学习查找与排序 |
| 第九周 | 3152/12700 | 3/17 | 30/230 | 学习二叉树、二叉查找树和二叉排序树 |
-
计划学习时间:20小时
-
实际学习时间:30小时
-
改进情况:
(有空多看看现代软件工程 课件 软件工程师能力自我评价表)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号