第七周学习
BAM: Bottleneck Attention Module
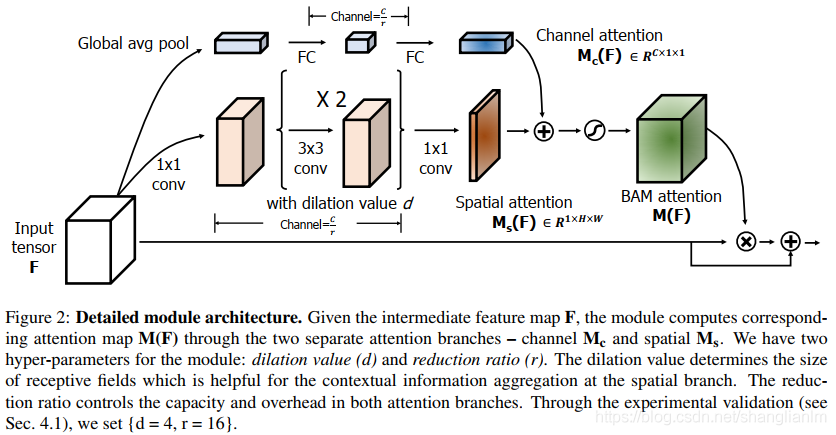
BAM 主要是通过 Channel attention 和 Spatial attention 两部分并行获取注意力。将两部分得到的输出通过广播机制进行相加并通过一个 sigmoid 函数,获取最终的注意力。作者将该模块放在两个 block 之间,构成最终的网络图。
Dual Attention Network for Scene Segmentation
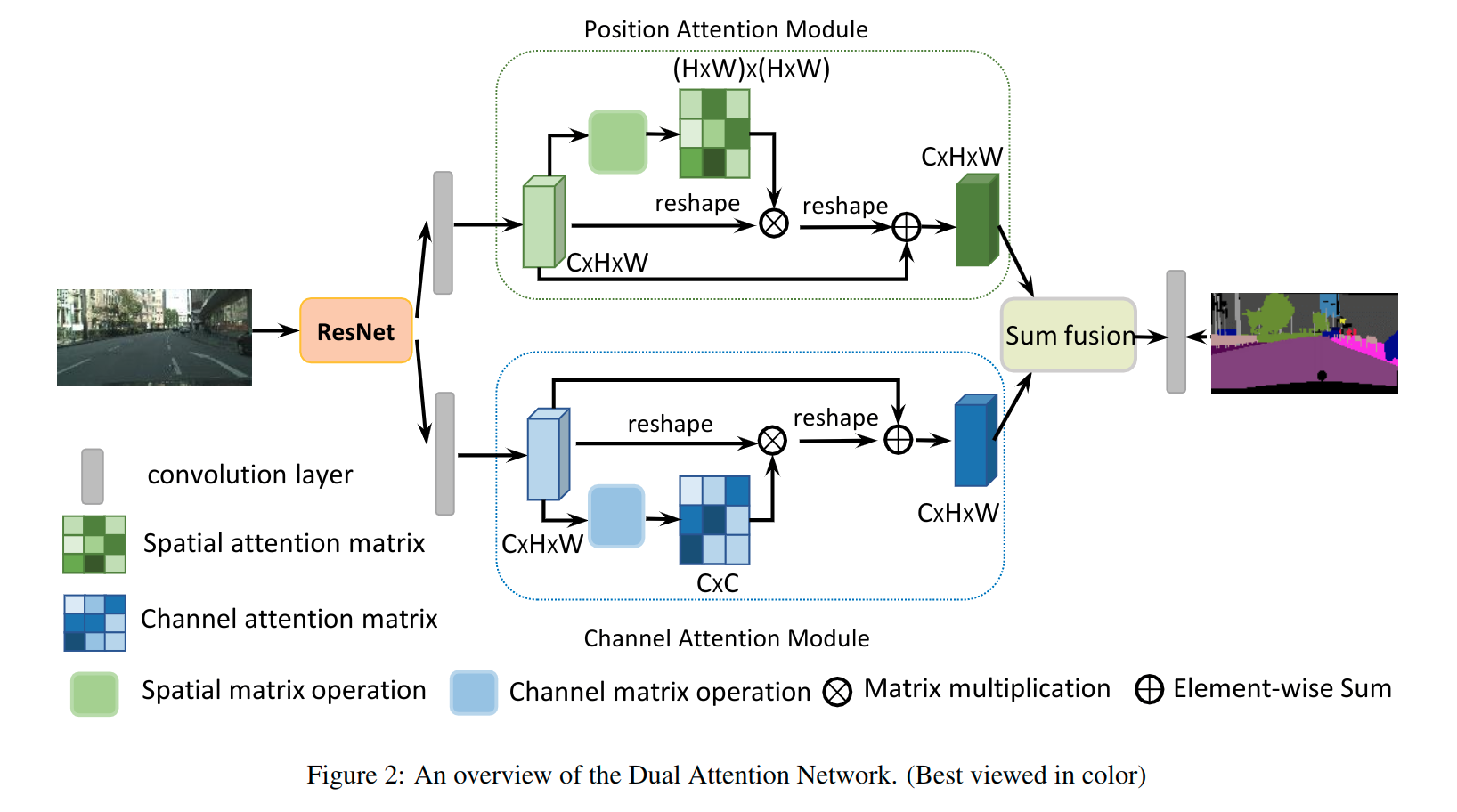
本文提出了 Dual Attention Networks (DANet) 在 spatial 和 channle 维度来捕获全局特征依赖,提出 position attention module 去学习空间特征的相关性,提出 channel attention module 去建模 channle 的相关性。

Position Attention Module
先将特征图 A 通过三个 \(3 \times 3\) 的卷积,得到 B、C、D 三个新的特征图,然后将他们 reshape 为 \(C \times N, N=H\times W\),将 B 转置与 C 相乘并通过一个 softmax 得到注意力 S (\(N \times N\)),将得到的特征与 D 相乘,再 reshape 成 \(C \times H \times W\) 与 特征图 A 相加,就得到了最终的输出 E。
Channel Attention Module
先将特征图 A 做 reshape 和 reshape & transpose 操作,并将两个结果相乘后通过一个 softmax 得到注意力 X (\(C \times C\)),将得到的特征与 A 相乘,再 reshape 成 \(C \times H \times W\) 与 特征图 A 相加,就得到了最终的输出 E。
ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
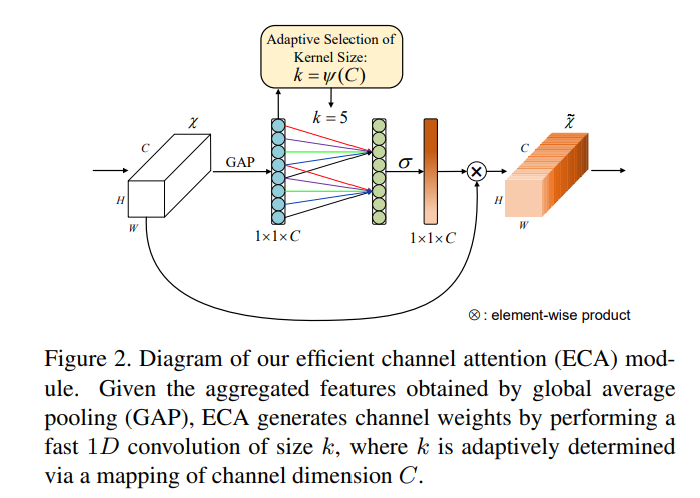
该模块首先自适应地确定核大小,然后执行 1D 卷积,然后执行 Sigmoid 函数得到注意力,最后作用到原图上。其中 \(k = \psi(C) = |\frac{\log_2(C)}{\gamma} + \frac{b}{\gamma}|\).
Improving Convolutional Networks with Self-Calibrated Convolutions
本文主要是提出了一种自校准卷积,自校准卷积与组卷积类似,不同点是过滤器的每个部分都没有得到同等对待,而是负责特定的功能。
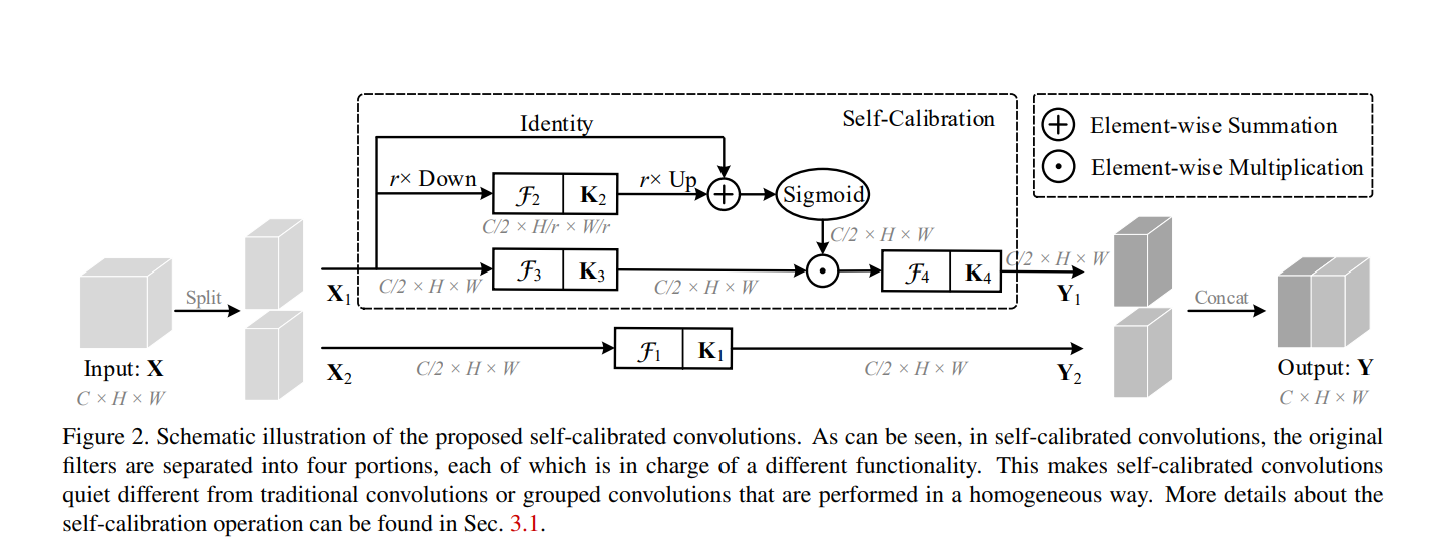
-
输入 X 为 $ C \times H \times W$ 大小,拆分为两个 \(C/2 \times H \times W\) 大小的 \(X_1, X_2\);
-
卷积核 K 的维度为 \(C \times C \times H times W\),将 K 分为4个部分,分别为 \(K_1, K_2, K_3, K_4\),其维度均为 \(C/2 \times C/2 \times H \times W\);
-
自校准尺度空间:
\[T_1 = AvgPool_r(x_1)\\ X_1' = Up(F_2(T_1)) = Up(T_1*K_2)\\ Y_1' = F_3(X_1) \cdot \sigma(X_1 + X_1')\\ Y_1 = F_4(Y_1') = Y_1' * K_4\\ \] -
原尺度特征空间:对特征 \(X_2\) 经过 \(K_1\) 卷积提取得到特征 \(Y_2\);
-
对两个尺度空间输出特征 \(Y_1, Y_2\) 进行拼接操作,得到最终输出特征 Y。
Pyramid Split Attention
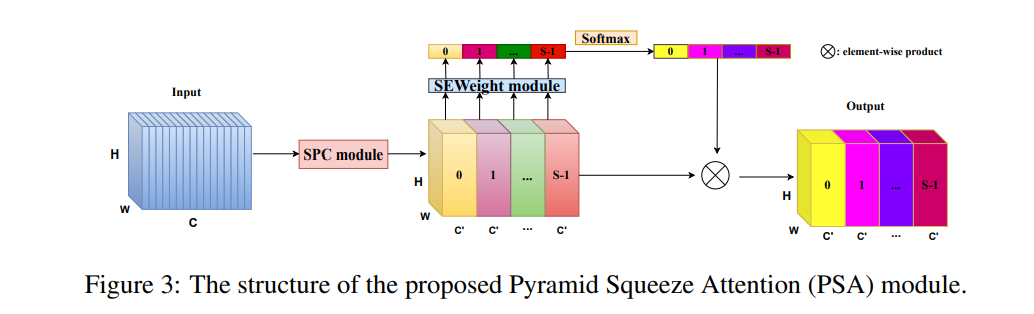
该网络首先通过一个 SPC 模块提取特征,然后经过 SENet 中的 SEWeight 模块来获取通道注意力,将获取的注意力经过 softmax 操作后,与 经过 SPC 模块提取到的特征相乘,得到最终的输出特征。
Split and Concat module
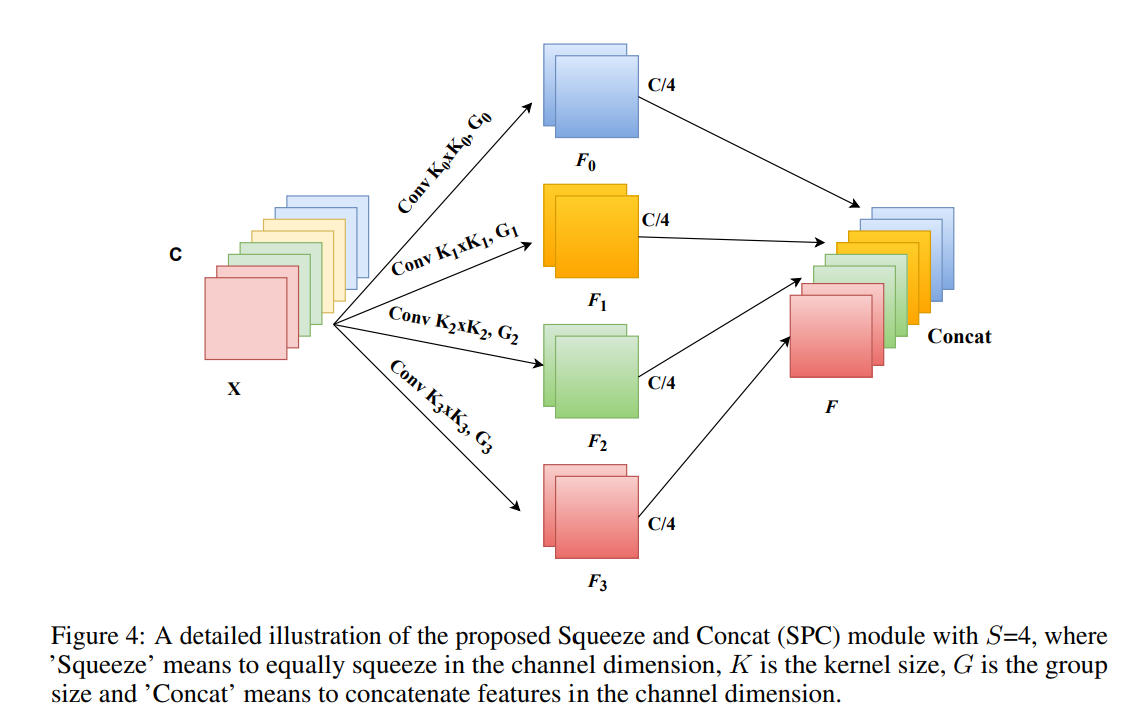
该模块主要是采用不同的卷积核提前多尺度的目标特征,\(k_0, k_1, k_2, k_3\) 是不同卷积核参数,\(G_0, G_1, G_2, G_3\)是分组卷积的参数,最后将提取到的特征通过 Concat 操作进行拼接。
ResT: An Efficient Transformer for Visual Recognition
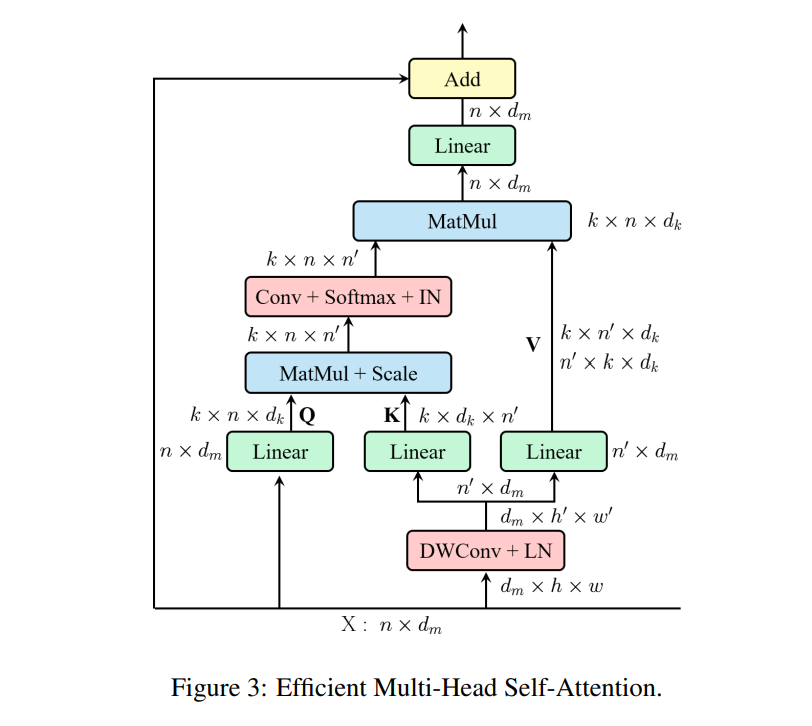
- 与 MSA 类似,EMSA 首先采用一组线性投影来获得 Q;
- 采用 Depth-Wise Conv 和线性投影获取 K 和 V;
- 将 Q 和 K 通过公式 $ EMSA(Q, K, V)=IN(Softmax(Conv(\frac{QK^T}{\sqrt{d_k}}))V$
- 最后,将每个头部的输出值进行拼接和线性投影,形成最终输出。
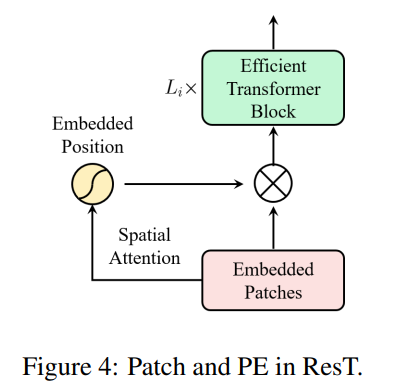
位置编码采用公式 \(\hat{x} = PA(x) = x * \sigma(DWConv(x))\)
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks
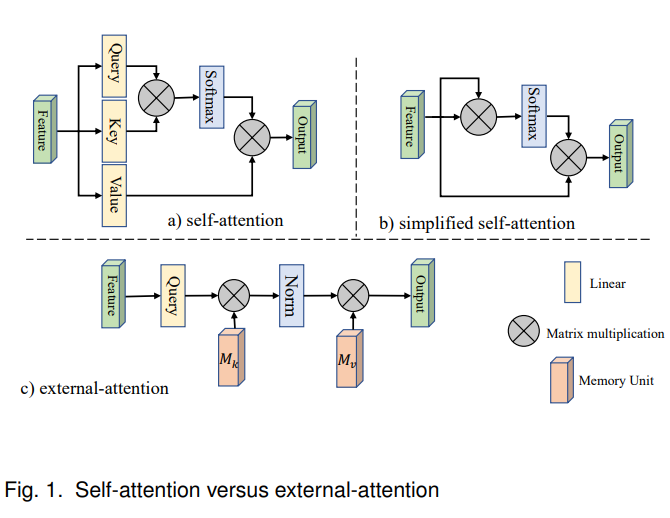
外部注意力模块主要是使用两个级联的线性层以及归一化层实现。
总体来说,计算的是输入和外部记忆单元之间的注意力,记忆单元记为 \(M \in R^{S \times d}\) ,可以表述为:
此处的 \((\alpha)_{i, j}\) 表示第 i 个元素和 M 的第 j 行之间的相似性,记忆单元是一个独立于输入的参数,作为整个训练数据集的记忆。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号