BUAA_OO_Unit1总结
一、前言
第一单元是对表达式拆括号和化简的基本联系。对我而言,这个过程的最大收获是在字符串处理过程中感受到了面向对象的强大力量(虽然自己面向过程居多)。在高任务量和迭代开发(不断重构)的过程中,对类之间交互的掌握也进一步加深。
回首自己三次作业的代码,由于完成第一次作业时还没有下发第一单元训练,因此并没有运用Parser和Lexer等教程推荐的解析方法,这就导致了顶层架构耦合度极高,且由于后两次作业在第一次作业的基础上顶层架构不需要大幅度修改,最终也就带着遗憾顶着“屎山”从头走到尾了,不过总体而言,这三次作业的完成还称得上顺利(除了最后挨了一刀)。
在代码化简的过程中,再次感觉到了自己码力的不足,化简过程也算的上是磕磕绊绊,且化简过程中也留下了不少遗憾,丢了不少的性能分。而且,由于能力有限,找到的化简方法复杂度极高,最终导致耦合度大幅度增加。
下面,是对三次作业的代码分析。
二、程序结构
2.1 核心思想
在表达式化简的整个过程中,本人的核心思想和推荐思路存在不小的差异,为了更好的架构底层的加减乘运算关系,我将所有的项全表达成了同一种形式,即无论是因子之间的相加、项之间的相加、表达式之间的相加,都可以视为项之间的相加;无论是因子之间的相乘、项之间的相乘、表达式之间的相乘,都可以视为项之间的相乘。这里的项,指的是对字符串进行处理后得到的项的集合。在这种架构下,底层的数据类型是唯一的,是一种可以因子和项的通用表达。这种处理方法有利有弊,一方面,在进行常数相乘、单项相加减等简单操作时,会带来一定时间的冗余,且底层的相加减,相乘操作实现起来难度极高;但另一方面,只要我们实现了底层的运算逻辑,我们就可以实现随意的对顶层解析的结果进行运算,而不必考虑运算时数据类型变化时产生的各种差异,这是何等的自由!
也因此,在本人的三次代码中,所建的类的数量相当有限(在这里也是对自己会引起大家高度不适的UML图做一个铺垫)
2.2 hw1
2.2.1 hw1总体分析
第一次作业由于写的很急,且做的时候感觉相对较好上手就没有参考往届博客(当时完全没想到后续要扩展三角函数),导致当时选择了用数组存多项式(这种架构扩展三角函数的难度可想而知),这直接导致第一次的底层架构在第二三次作业中成为了废纸,为第二周的作业完成增加了不小的难度。不过,就单次作业而言,以数组存储多项式简单,便捷,效率极高,且由于第一次作业的的答案指数不超过8,以ArrayList的形式存储多项式与HashMap相比,无论在代码的编写的难度、还是运行的效率上,都有着相当的优势。
2.2.2 hw1 UML图
hw1UML图如下:

可见,第一次的代码架构非常简略,也并没有接口和继承关系,有一点点面向对象的影子,但总体而言还是以面向过程为主。同时,也可以看出,存储结构的明显缺点。这即将导致hw2,hw3的底层重构,总体而言,尽管类图还有不完善的地方,但其实自己对这次作业还算得上满意。
2.2.3 hw1 方法及类复杂度分析
hw1高复杂度方法如下图所示:
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Term.sub(Term) | 1.0 | 1.0 | 2.0 | 2.0 |
| Term.put() | 42.0 | 6.0 | 12.0 | 22.0 |
| Term.mult(Term) | 6.0 | 1.0 | 4.0 | 4.0 |
| Term.getCoefficient() | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.constant(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.constant(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.add(Term) | 1.0 | 1.0 | 2.0 | 2.0 |
| MainClass.main(String[]) | 21.0 | 1.0 | 9.0 | 10.0 |
| MainClass.clear(String) | 15.0 | 1.0 | 8.0 | 9.0 |
| Expression.getTerm() | 0.0 | 1.0 | 1.0 | 1.0 |
| Expression.getOneTerm(String) | 5.0 | 1.0 | 4.0 | 4.0 |
| Expression.Expression(Term) | 0.0 | 1.0 | 1.0 | 1.0 |
| Expression.Expression(String) | 28.0 | 1.0 | 12.0 | 15.0 |
hw1类复杂度如下图所示:
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| Expression | 4.0 | 10.0 | 16.0 |
| MainClass | 6.5 | 7.0 | 13.0 |
| Term | 4.090909090909091 | 19.0 | 45.0 |
| Total | 74.0 | ||
| Average | 4.352941176470588 | 12.0 | 24.666666666666668 |
可以发现,有些类和方法的复杂度明显过高了。一方面,put函数是将储存多项式转化成String进行输出,但是第一次作业由于当时知识的不足,并没有采用StringBuilder来构建String,而是采用String的截取和拼接,这增加了相关部分的复杂度;另一方面,Expression类的init函数既在顶层将字符串转化成多项式,又在底层被带括号的因子重复调用,这无疑带来了相对较重的复杂度代价。
2.3 hw2
2.3.1 hw2总体分析
hw2压力最大的部分应该是底层储存逻辑的架构。一方面,在引入三角函数后,hw1中的数组存储多项式的方式完全报废,底层逻辑需要全部推到重写;另一方面,三角函数本身的复杂性又带来了相当大的压力(当时完全没想到后续还会在内部重复嵌套,不过歪打正着扩展性也不是很差),内外指数如何存储,内部的幂函数和常数还在用暴力判别法进行区分(第三次作业将内指数和底数直接合成了factor)。
最终和几位同学考虑后,最终产生的架构如下:
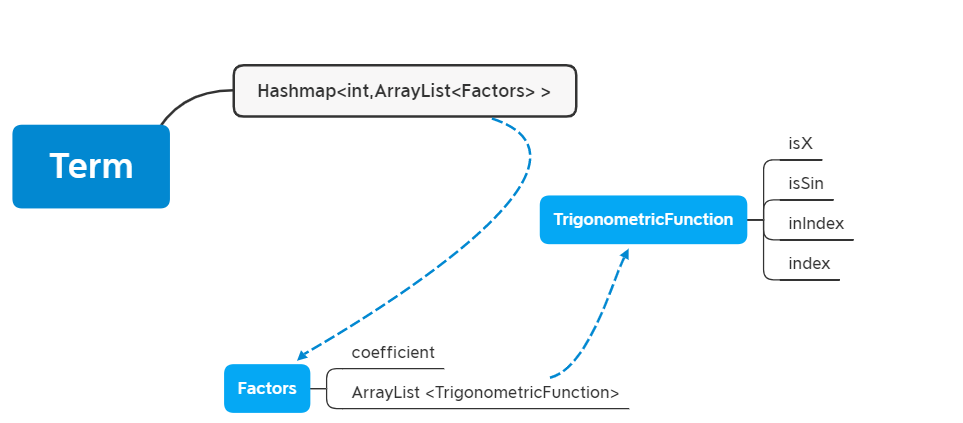
从下向上看,在三角函数级中,isX和isSin是对三角函数性质的判断,index和inIndex判断内外指数(若不是幂函数内指数代表常数值),这种方式可以很好地表示第二次作业的三角函数级;在因子级中,储存的不是传统意义的因子,而是一个常数和若干个TrigonometricFunction的乘积,对幂函数而言,把它从这一级分离的原因是:将三角函数集中在一级以便利三角函数的合并化简。然后,在项一级中,储存的不是传统的项,而是已经处理好的全部项的储存在以幂函数指数为key值对应的数组中,因为在运算过程中我们始终将它视作一个整体,因此,可以将这一级看成是一个特殊的“项”,操作起来也更加直观。在这个架构中幂函数与其他部分是完全分离的,一方面便利了乘法操作,一方面也简化了化简难度。
2.3.2 hw2 UML图
由于hw3和hw2的架构基本相同,代码也仅差不到200行,因此,hw2的UML图与hw3基本相同。为了避免图片冗余,在这里就不过多展示了,hw3UML图可以在2.4.2小节中查看。
2.3.3 hw2 方法及类复杂度分析
hw2高复杂度方法如下图所示:
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Term.sub(Term) | 21.0 | 6.0 | 8.0 | 8.0 |
| Term.mult(Term) | 29.0 | 7.0 | 9.0 | 9.0 |
| Term.die() | 21.0 | 1.0 | 9.0 | 10.0 |
| Term.cos(boolean, BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.coefficient(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.add(Term) | 22.0 | 6.0 | 8.0 | 8.0 |
| Main.clear(String) | 13.0 | 1.0 | 7.0 | 7.0 |
| Factor.simplificate(Factor) | 18.0 | 7.0 | 5.0 | 8.0 |
| Expression.monatomic(String) | 18.0 | 1.0 | 14.0 | 14.0 |
| Expression.getTerm() | 0.0 | 1.0 | 1.0 | 1.0 |
| Expression.getOneTerm(String) | 5.0 | 1.0 | 4.0 | 4.0 |
| Expression.Expression(Term) | 0.0 | 1.0 | 1.0 | 1.0 |
| Expression.Expression(String) | 28.0 | 1.0 | 12.0 | 15.0 |
| Expression.Expression() | 0.0 | 1.0 | 1.0 | 1.0 |
| Expression.cos(Term) | 10.0 | 1.0 | 6.0 | 6.0 |
| Custom.Custom(String) | 3.0 | 1.0 | 4.0 | 4.0 |
| Custom.bringIn(String) | 3.0 | 1.0 | 4.0 | 4.0 |
| Total | 273.0 | 96.0 | 181.0 | 212.0 |
| Average | 4.789 | 1.684 | 3.175438596491228 | 3.71929 |
类复杂度如下图:
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| Sum | 2.0 | 2.0 | 2.0 |
| Custom | 4.0 | 4.0 | 8.0 |
| Main | 4.0 | 5.0 | 16.0 |
| TrigonometricFunction | 1.8666666666666667 | 7.0 | 28.0 |
| Factor | 3.0 | 9.0 | 39.0 |
| Expression | 5.25 | 13.0 | 42.0 |
| Term | 3.7142857142857144 | 10.0 | 52.0 |
可以发现,项之间的加减乘操作的复杂度非常高,这是底层储存结构的复杂程度决定的。应用于化简的的die()(把化简函数起名“作死”真的是一语成谶)和.simplificate()复杂度过高是化简方法本身的复杂性导致的。最顶层的init方法复杂度高是因为沿用hw1的顶层架构导致的。
2.4 hw3
2.4.1 hw3总体分析
hw3和hw2相比,顶层和底层变化都不大。只是更换了最底层三角函数级内部为Term,Factor和Term级增加了compareTo方法和equal方法(为了方便同类型的合并),整体而言实现方面更改不大,但是由于底层定义的递归调用,时间复杂度的开销大幅增大。
化简方面,额外处理了二倍角(好像无测试点,哭死),怕超时设定阈值超过6秒停止化简直接开始输出(被同学的神仙数据吓怂)。
2.4.2 hw3 UML图
hw3UML图如下:

和大多数同学相比,或许运用的类的数量不算很多,不过已经基本有了面向对象的基本结构。通过Trigonmetric、Factor、Term之间的相互调用,已建立起了相对完善的底层逻辑关系。每个类实现的功能虽然不少但是逻辑也还算清晰。(应该吧。。。)总而言之,第二单元的架构还要改进(捂脸)。
2.4.3 hw3 方法及类复杂度分析
hw3高复杂度方法如下图所示:
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Custom.bringIn(String) | 8.0 | 1.0 | 7.0 | 7.0 |
| Main.nextMatchBrace(String, int) | 8.0 | 4.0 | 2.0 | 5.0 |
| Factor.output(int) | 10.0 | 2.0 | 10.0 | 11.0 |
| Term.clear2() | 12.0 | 1.0 | 9.0 | 9.0 |
| Factor.smash() | 13.0 | 5.0 | 7.0 | 9.0 |
| Main.clear(String) | 13.0 | 1.0 | 7.0 | 7.0 |
| Factor.sin2() | 14.0 | 2.0 | 10.0 | 11.0 |
| Main.stringToOutput(String) | 14.0 | 4.0 | 8.0 | 8.0 |
| Term.compareTo(Term) | 14.0 | 7.0 | 11.0 | 11.0 |
| Term.getSum() | 15.0 | 3.0 | 8.0 | 12.0 |
| Factor.simplificate(Factor) | 18.0 | 7.0 | 5.0 | 8.0 |
| Expression.monatomic(String) | 19.0 | 2.0 | 15.0 | 15.0 |
| Term.sub(Term) | 21.0 | 6.0 | 8.0 | 8.0 |
| Term.add(Term) | 22.0 | 6.0 | 8.0 | 8.0 |
| Expression.Expression(String) | 29.0 | 2.0 | 13.0 | 16.0 |
| Term.mult(Term) | 29.0 | 7.0 | 9.0 | 9.0 |
| Term.die() | 38.0 | 5.0 | 10.0 | 13.0 |
| Total | 376.0 | 139.0 | 249.0 | 284.0 |
| Average | 5.150 | 1.930 | 3.458 | 3.94 |
类复杂度如下表:
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| Sum | 5.0 | 5.0 | 5.0 |
| Custom | 5.5 | 7.0 | 11.0 |
| Main | 3.4285714285714284 | 8.0 | 24.0 |
| TrigonometricFunction | 1.6 | 5.0 | 24.0 |
| Expression | 4.875 | 14.0 | 39.0 |
| Factor | 3.210526315789474 | 9.0 | 61.0 |
| Term | 4.285714285714286 | 13.0 | 90.0 |
可见,除了化简方法的复杂度进一步提高,其余方法的复杂度与第二次相比差别不大。
2.5细节处理
2.5.1顶层的处理和化简
事实上,顶层的字符串替换可以为程序实现以及化简都提供相当大的便利,比如说:
解析前的预处理:
public static String clear(String s) {
String str = s;
str = str.replace(" ", "");
str = str.replace("\t", "");
str = str.replace("**", "^");
for (int i = 0; i < str.length() - 1; i++) {//对连续加减号的处理
if (str.charAt(i) == '+' || str.charAt(i) == '-') {
while (str.charAt(i + 1) == '+' || str.charAt(i + 1) == '-') {
if (str.charAt(i) == str.charAt(i + 1)) {
str = str.substring(0, i) + "+" + str.substring(i + 2);
} else {
str = str.substring(0, i) + "-" + str.substring(i + 2);
}
}
}
}
str = str.replace("sum", "T");
str = str.replace("sin", "S");
str = str.replace("cos", "C");
str = str.replace("^+", "^");
return str;
}
这样,关键字都变为单个大写字母,无必要的“+”,“-”,空格都被清理,便于进一步解析。
将一些底层不好处理的化简置于顶层:
str = str.replace("-1*", "-");
str = str.replace("+1*", "+");
str = str.replace("*1*", "*");
str = str.replace("*1-", "-");
str = str.replace("*1+", "+");
str = str.replace("(+", "(");
str = str.replace("(x*x)", "(x**2)");
if (str.charAt(0) == '+') {
str = str.substring(1);
}
这样,有效处理了+-1的问题和sin/cos(x*x)非法的问题。
但是,这种替换会使一些可能出错的情况变得模糊,可能产生一些意想不到的bug(比如sum中出现连续-+但是由于顶层已替换掉这种情况而未过多考虑)。
2.5.2 底层的处理
广泛使用clone:
优点:避免直接赋值所产生的的引用问题。
缺点:盲目应用clone导致程序时间开销过大。
ArrayList嵌套使用:
优点:数据便于有序化处理;加减乘操作非常简便。
缺点:反复sort时间开销极大;提取数据时所需代码。
三、优化策略
3.1优化总结
对三次作业的总体情况而言,优化效果没有达到最好,每次都因优化不足扣掉了少许分数,也可以算得上是这一单元的少许遗憾,也让我看到了和真正强者之间的差距(赶快去抱大腿)。
具体的失误情况如下:
第一次作业:若第一项为负数时将第一个正项挪至第一项(如果存在),但是未考虑挪过来的项的系数是1应该省略的情况,某一测试点比最优解多输出“1*”。
第二次作业:形如 \(cos{x}^3+sin{x}^2cos{x}\) 的数学形式,以为自己化简了,但实际化简出了锅(还好正确性没寄);对形如 $1-sin{x}^2 , 1-cos{x}^2 $ 的数据,由于相信在随机构造数据的可能下几乎不会出现,就没管(然后寄了);
第三次作业: 优化了一些奇奇怪怪的东西(二倍角怎么没有测试点!),然后再一次把 $1-sin{x}^2 , 1-cos{x}^2 $忘掉了(寄*2)。。。
3.2优化清单
第一次作业:
-
x**2—x*x -
正项提前
-
简单的同类项合并
第二次作业:
1.sin(-x) — -sin(x),cos(-x) — cos(x)
2.sin(0) — 0 , cos(0) —1
3.简单的同类项合并
4.简单平方和优化,及含有其他相同乘积的平方和优化(小锅,自身是奇数次方的寄掉了)
第三次作业:
1-4.同上(补了锅)
5.sin/cos(expression) 和 sin/cos(-expression)的归一化处理
6.二倍角公式
3.3优化中的问题与解决办法
主要问题来源于平方和公式:
由于在化简前肯定会进行同类型和并:因此直接抓取 平方项会错过 \(cos{x}^3+sin{x}^2cos{x}\) 等相似结构。因此在化简前会先进行对因子的拆分成幂指数不超过2的因子并排序,如将 \(cos{x}^5\) 拆解成 \(cos{x}*cos{x}^2*cos{x}^2\)等,这样,通过合理的排序后(hw2中直接用底层排序出锅了),能够合并的两个数组之间长度相等,且仅有一位不同并为相反的平方项(不难理解),然后O(\(n^2\))枚举合并,合并完成后将上文的拆分过程重新合并。重复上述过程直至不产生合并为止。
但是,这种方式的代价就是,时间复杂度的极度膨胀,以至于第三次作业不得不进行取舍针对运行时间进行分治处理。
其他小问题:二倍角怎样优化才不会产生负优化,合并同类项时的效率问题……(与上文相比,确实都是小问题)
一些可能存在但只是敢想一想的优化:积化和差、和差化积…...(实现难度过高,优化效果有限,我爬了)
四、bug修复与互测hack
4.1bug测试和修复
在本三次作业的互测和强测中,只有第三次互测挨了一刀(其实是hw2的sum的bug,但是当时互测不允许sum且强测不强,逃过一劫),万幸强测没出大事,不过也应该好好反思。
bug测试分为三个阶段:
1.基础功能测试:测试好简单的基础功能,能通过上次的强测数据和本次中测中可显示的测试点(找已经过关的同学贴贴),然后简单的debug后提交通过中测。
2.优化功能测试:每写好一个优化模块就进行测试,多和同学讨论数据构造,找到足够强的数据完善自己的代码,优化过的地方一定要着重测试。
3.极限数据测试:大常数和0常数的测试,sum上下界的测试,极限数据运行时间的测试。。。
bug修复:
说起来其实也算是自己自食恶果了,在sum和自定义函数中使用了不推荐的暴力替换方式,结果没有想到i**n合法然后i没加负号,然后可想而知:-1**2和(-1)**2显然不是一个东西,最后寄了(大哭)。
然后通过把Sum类中代码某一行Main.clear(ss) 改为“(” + Main.clear(ss) + “)”就过了,最根本原因还是没仔细看指导书,但形式化定义那段真的读起来体感太差(我啥也没说,溜了)。
4.2互测hack
其实还是蛮混的,也就是跟同学谈论讨论感觉什么数据可能能hack到人就地毯式轰炸了。
主要hack到的问题有:
大常数re(hw1),优化时正负号处理异常(hw1,hw2),优化tle(hw3),总体而言,互测算是小赚一笔。
五、心得体会
1.好的底层逻辑非常重要,好的扩展性强的底层逻辑有极强的扩展性。
2.要注意阅读指导书,注意边界条件的判定。
3.要积极构造数据,有些bug是干想想不出来的。(哭死)
4.互测要和同学广泛交流(说不定你刀的那个人你认识,预防线下hack),好的hack数据积极分享。
5.要注意面向对象编程。(第二单元一定!!!)
六、总结
总而言之,第一单元给我带来了很大收获,尽管程序还存在明显缺陷,但是通过本次学习,我对面向对象编程有了更深的了解,对OO课程机制的认识更加明确,希望第二单元继续加油!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号