代码问题汇总
代码问题汇总
不间断运行 Python 文件
nohup
nohup: 是 no hang up 的缩写,在 Linux 系统下启动一个不会随着终端关闭而终止的命令
使用场景:使用远程服务器运行程序,但是网络不稳定,一旦掉线运行就会终止,这时就需要使用
nohup命令。
# -u: 设置 Python 解释器的缓冲模式为无缓冲(unbuffered),这样可以实时尽快刷新输出缓冲区,方便实时查看输出结果
# > nohup.out:输出重定向
# 2>&1:将标准错误 2 重定向到标准输出 &1,标准输出 &1 再被重定向输入到 nohup.out 文件中
# &:将命令放入后台运行,终端退出后命令仍旧执行
nohup python -u python_file.py > nohup.out 2>&1 &
如果要停止运行,可以使用 ps 命令来查看 PID,然后使用 kill 命令删除:
# a: 显示所有程序
# u: 以用户为主的格式来显示
# x: 显示所有程序,不区分终端机
ps -aux | grep "python_file.py"
# 找到 PID 后,使用 kill 删除
# -9:表示该进程强制终止
kill -9 进程号PID
Tmux
Tmux:是 terminal multiplexer 的缩写,即终端复用器,可以启动一系列终端会话。通过一个终端登录主机并运行 tmux 后,我们可以开启多个控制台而无需浪费多余的终端来连接这台远程主机,而且终端关闭 shell 后里面的任务进程也不会中断。
参考:https://www.ruanyifeng.com/blog/2019/10/tmux.html
使用场景:
- 长时间运行任务:在运行需要长时间运行的任务时,例如备份操作、爬虫程序等,Tmux 可以保证即使在网络断开或突然断电的情况下,任务仍然可以在后台运行。
- 多人协作:Tmux 允许多个用户同时远程连接到同一会话中,这样就可以协同编辑文件、开发代码等。
# 在终端窗口运行 tmux,启动 tmux 伪窗口
tmux
# 启动命名 tmux
tmux new -s <name>
# 退出
exit or Ctrl + D
# 分离 session
tmux detach or Ctrl+b d # 退出当前 tmux 窗口,但是 session 和里面的进程仍然在后台运行
# 注意:tmux 有很多快捷键是通过前缀键触发的,一般为 ctrl+b,按下 ctrl+b 后需要松开键盘,然后再按下一个单独的功能键。
# 查看当前所有 session
tmux ls
# 重新进入 session
# 1. 使用 session 编号
tmux attach -t 0
# 2. 使用 session 名称
tmux attach -t <session-name>
# 杀死 session
tmux kill-session -t 0
tmux kill-session -t <session-name>
# 切换 session
tmux switch -t 0
tmux switch -t <session-name>
# 重命名 session
tmux rename-session -t 0 <new-name>
# 划分窗格
# 1. 划分上下两个窗格
tmux split-window
# 2. 划分左右两个窗格
tmux split-window -h
# 3. 关闭当前窗格
Ctrl+b x
最简操作流程如下:
# 1. 新建 session
tmux new -s my_session
# 2. 在 tmux 窗口运行所需程序
# 3. 分离 session
tmux detach
# 4. 下次使用时,重新连接到 session
tmux attach-session -t my_session
修改 docker image 默认的存储地址
sudo systemctl stop docker
sudo rsync -aP /var/lib/docker/ /home/lockegogo/data/docker
sudo mv /var/lib/docker /var/lib/docker.bak # 重命名旧目录(可选,用于备份)
# 修改默认地址
sudo gedit /etc/docker/daemon.json
{
"data-root": "/home/lockegogo/data/docker"
}
sudo systemctl start docker
docker images
如何在两个服务器之间设置 ssh 免密登陆
举个栗子,用户希望在 gpu4-1 上免密登陆 gpu4-2
gpu4-1 10.30.138.160 slots=4
gpu4-2 10.30.155.5 slots=4
- 在 gpu4-1 服务器生成一对公私钥,然后将公钥上传到 gpu4-2 服务器
ssh-keygen -t rsa
ssh-copy-id 10.30.155.5
# ssh 公钥会自动上传保存到 gpu4-2 的 .ssh/authorized_keys 中
- 修改 ssh 设置
vim /etc/ssh/sshd_config
# 修改如下设置,把前面的 # 删除
StrictModes no
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
# 修改完成之后按 ctrl+c,然后按 :wq 退出(需要改为英文输入法)
- 修改目录和文件的权限
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
- 重启 ssh 服务
service ssh restart
- 在 gpu4-1 上测试是否可以免密登陆 gpu4-2
ssh 10.30.155.5
# 成功!
- 避坑:在 gpu4-1 本机上也需要输入 ssh-copy-id,否则在本机上 ssh localhost 也需要输入密码!
ssh-copy-id 10.30.138.160
如何下载对应版本的 chromedriver?
- 找到谷歌浏览器对应的版本:chrome://settings/help
- 根据版本找到下载网址:Chrome for Testing availability
开发机容量告警?
du -h --max-depth=1 /
# 定期删除
du -sh /etc/Trash/*
rm -rf /etc/Trash/files/*
du -sh /opt/conda/*
rm -rf /root/.cache/*
如何获取 OpenAI 格式的 model_id ?
client = OpenAI(
api_key="token-abc123",
base_url="服务域名/v1",
)
models = client.models.list()
model_id = models.data[0].id
无法忽略警告?
试试把下面的代码放在 py 文件的最开头:
import warnings
warnings.filterwarnings("ignore")
TensorFlow Serving 部署的服务如何调用
- 从日志中找到 tensorflow 部署服务的名称
tensorflow_model_server --model_name=模型名称 --port=9000 --model_base_path=......
- 查看模型的
metadata,找到输入输出名称:curl -X GET 服务域名/v1/models/模型名称/metadata - 使用下面的模板进行服务可用性测试:
# tf-serving
import json
import requests
import random
"""
输入:segment_ids, input_word_ids, input_mask
输出:logits
"""
import json
import requests
import random
import time
def http_client(http_addr: str, model_name: str):
batch_size = 500
sequence_length = 128
instances = [
{
"segment_ids": [random.randint(0, 1) for _ in range(sequence_length)],
"input_word_ids": [random.randint(0, 5000) for _ in range(sequence_length)],
"input_mask": [random.randint(0, 1) for _ in range(sequence_length)],
}
for _ in range(batch_size)
]
data = json.dumps(
{
"signature_name": "serving_default",
"instances": instances,
}
)
headers = {
"content-type": "application/json",
}
http_url = "{}/v1/models/{}:predict".format(http_addr, model_name)
start_time = time.time()
response = requests.post(http_url, data=data, headers=headers)
end_time = time.time()
if response.status_code == 200:
predictions = response.json().get("predictions", [])
if predictions:
print(f"Prediction for instance 0: {predictions[0]}")
else:
print("No predictions found.")
else:
print(f"Request failed with status code {response.status_code}: {response.text}")
return end_time - start_time
def stress_test(http_addr: str, model_name: str, num_requests: int):
total_time = 0
for i in range(num_requests):
elapsed_time = http_client(http_addr, model_name)
total_time += elapsed_time
print(f"Request {i + 1}/{num_requests} took {elapsed_time:.2f} seconds")
avg_time = total_time / num_requests
print(f"Average response time: {avg_time:.2f} seconds") # 0.87s
if __name__ == "__main__":
model_name = "模型名称"
http_addr = "服务域名"
num_requests = 100 # 设置压测的请求次数
stress_test(http_addr, model_name, num_requests)
- 使用 grpc 调用:
# tf-serving
from tensorflow_serving.apis import model_pb2, get_model_status_pb2, model_service_pb2_grpc, predict_pb2, prediction_service_pb2_grpc
from grpc import insecure_channel, RpcError
from cloud_ml_sdk.utils.load_balance_dns_v2 import DnsLoadBanlance
from cloud_ml_sdk.utils.load_balance_dns import request_serving
import tensorflow as tf
import numpy as np
def grpc_client(dns_load: DnsLoadBanlance, model_name: str):
request = predict_pb2.PredictRequest()
request.model_spec.name = model_name
request.model_spec.signature_name = "serving_default"
sequence_length = 128
batch_size = 5
segment_ids = np.random.randint(0, 2, size=(batch_size, sequence_length)).tolist()
input_mask = np.random.randint(0, 2, size=(batch_size, sequence_length)).tolist()
input_ids = np.random.randint(0, 5000, size=(batch_size, sequence_length)).tolist()
targets = np.random.randint(0, 2, size=(batch_size, sequence_length)).tolist()
request.inputs["segment_ids"].CopyFrom(tf.make_tensor_proto(segment_ids, dtype=tf.int32))
request.inputs["input_mask"].CopyFrom(tf.make_tensor_proto(input_mask, dtype=tf.int32))
request.inputs["input_ids"].CopyFrom(tf.make_tensor_proto(input_ids, dtype=tf.int32))
request.inputs["Targets"].CopyFrom(tf.make_tensor_proto(targets, dtype=tf.int32))
try:
response = request_serving(dns_load, prediction_service_pb2_grpc.PredictionServiceStub, "Predict", request)
print(response)
except RpcError as e:
print(f"RPC failed: {e}")
if __name__ == '__main__':
dns_ip = "10.16.64.36"
model_name = "模型名称"
grpc_addr = "GRPC地址"
grpc_port = 9000
dns_load = DnsLoadBanlance(dns_ip, grpc_addr, grpc_port)
grpc_client(dns_load, model_name)
Ubuntu 硬盘挂载
[!WARNING]
注意,如果在 ubuntu 上挂载 NTFS 的盘,无法修改所属权 https://blog.idejie.com/2019/09/24/mount-linux-ntfs-disk/,这会导致拉取代码后无法查看和切换分支,可以运行如下代码解决:git config --global --add safe.directory "*",将所有目录添加为安全目录,忽略 git 对目录所有权的检查
- 点击工具中的磁盘,找到新加盘,编辑挂载选项
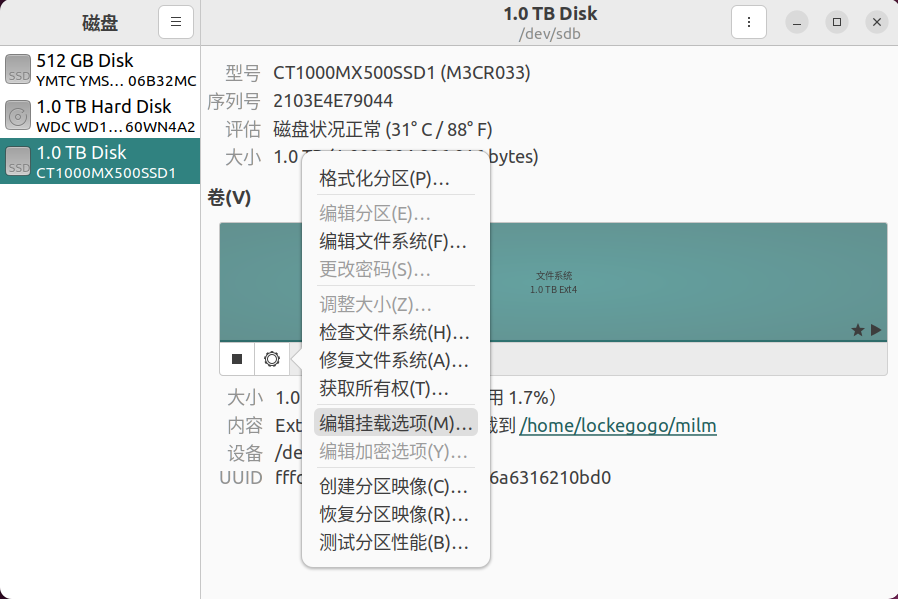
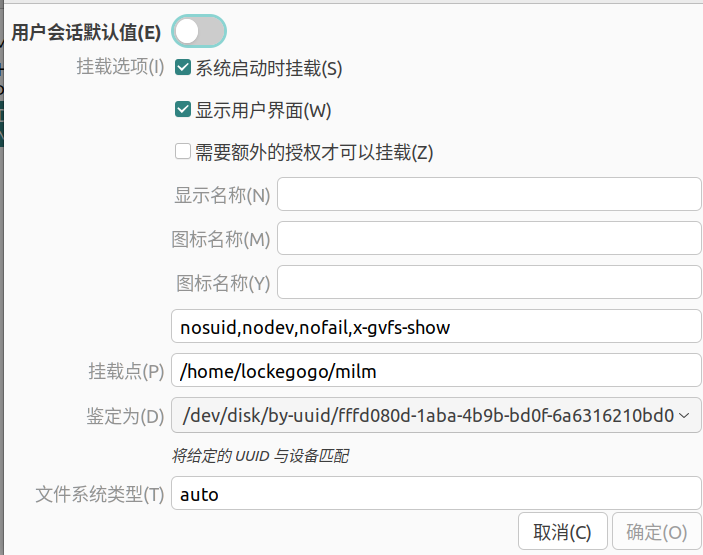
- 取消选中用户会话默认值,编辑挂载点,然后点击小三角符号,注意不要提前新建文件夹,挂载好之后会自动新建,可以看到挂载盘会多一个磁盘的小图标
Docker 使用主机的 VPN
docker 如果要使用主机的 vpn:需要使用 host 的网络模式,--network host
sudo docker build --network host -f Dockerfile_intel -t tgi-cpu .
使用 python 自带的虚拟环境
# 进入 wsl
sudo apt update
sudo apt upgrade
sudo apt install python3-pip
sudo apt install python3-venv
# sf 是虚拟环境的名字
python3 -m venv sf
source sf/bin/activate
使用 mamba 替换 conda
mamba 下载包时显示进度条,体验良好
# 1. 下载 micromamba
curl -Ls https://micro.mamba.pm/api/micromamba/linux-64/latest | tar -xvj bin/micromamba
# 2. 配置 shell 环境变量:bashrc & zshrc
./bin/micromamba shell init -s bash -p ~/micromamba
# 添加别名
alias conda=micromamba
# 3. 显示配置文件路径
conda info
# 4. 打开配置文件
sudo gedit /home/lockegogo/.mambarc
# 5. 添加如下配置源
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://pkgs.d.xiaomi.net/artifactory/conda-forge/
- https://pkgs.d.xiaomi.net/artifactory/anaconda-remote-repo/
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
# 新功能:查询软件依赖
mamba repoquery depends -t salmon
git push 代码提交失败的解决方案
一般情况下,代码 git push 失败都是因为 fatal: pack exceeds maximum allowed size,原因是之前 add 时忘记删除模型,导致模型被 git 管理,后面再删除也没用。可以尝试如下解决方案:
# 1. 从 master 新建一个分支
git checkout -b fake_detection_dev
# 2. 将原分支 merge 过来,带上 --squash 参数
git merge --squash fake_detection
# 3. 确认将模型及其他大文件如 build 文件夹删除之后再 add & commit
git add .
git commit -m "add lib_fakedetection"
# 4. 推送到远程仓库
git push origin fake_detection_dev
# 在提交之前查看所有将要提交的文件的大小
git ls-files | xargs -n1 -I{} git ls-tree -r HEAD {} | awk '{print $3, $4}' | sort -n -r | less
注意:--squash 参数的作用是将原来分支上的所有提交合并为一个单独的提交,而不是保留原有的多个提交记录,这样可以让合并的提交历史更加简洁。另外,使用 --squash 合并后,不会自动提交,也不会移动当前分支的 HEAD 指针。你需要手动将合并后的更改添加到暂存区(使用 git add),然后创建一个新的提交(使用 git commit),这样可以避免之前 git push 失败的问题。
如何 clone 指定 tag 的代码
git clone -b v0.5.0 https://github.com/vllm-project/vllm.git
Debug 时显示找不到文件
- 运行 \(\to\) 打开配置(launch,json)\(\to\) 增加一行:
"cwd": "${fileDirname}"
{
"version": "0.2.0",
"configurations": [
{
"name": "Python: 当前文件",
"type": "python",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal",
"justMyCode": true,
"cwd": "${fileDirname}"
}
]
}
debug前进入代码相应文件夹:
cd code\
- 增加代码,解决问题
import os,sys
os.chdir(sys.path[0]) #使用文件所在目录
自动生成项目的依赖清单
生成 requirements.txt 的步骤如下:
- 安装
pipreqs模块
pip install pipreqs
- 生成依赖清单:进入 python 项目的根目录,运行如下代码
pipreqs .
# 只列出主要依赖项(而不是包括依赖项的依赖项)
pipreqs . --no-pin
# 覆盖旧的清单文件
pipreqs . --force
这会扫描整个项目目录下的 python 文件,并根据导入信息生成一个名为 requirements.txt 的依赖清单文件,该清单将包括项目所依赖的所有第三方库及其版本号
- 安装依赖
pip install -r requirements.txt
生成目录树
- 在 Windows 命令行生成指定目录下的文件及其子目录的树形结构
# /F:在输出时包含文件名,而不仅仅是目录
tree /F your_pyfile_path > tree.txt
查找端口的进程信息
- Windows 系统:
# netstat:显示有关计算机网络连接和状态的信息
# -a:显示所有连接和侦听端口
# -o:显示与每个连接 / 端口关联的进程的 PID
# -n:使用数字表示 IP 地址和端口号
# findstr:文本查找工具,用于搜索包含特定字符串的行
netstat -aon | findstr “1080”
- Linux 系统:
sudo lsof -i :1080
创建 SpringBoot 项目报错
- 使用 IDEA 创建 SpringBoot 项目时,报错: "Initialization failed for 'https://start.spring.io",可以将服务器 URL 更换为:https://start.aliyun.com/
- 在 IDEA 中找到 Maven 的配置文件的地址,然后检查配置的远程仓库或者镜像有没有问题
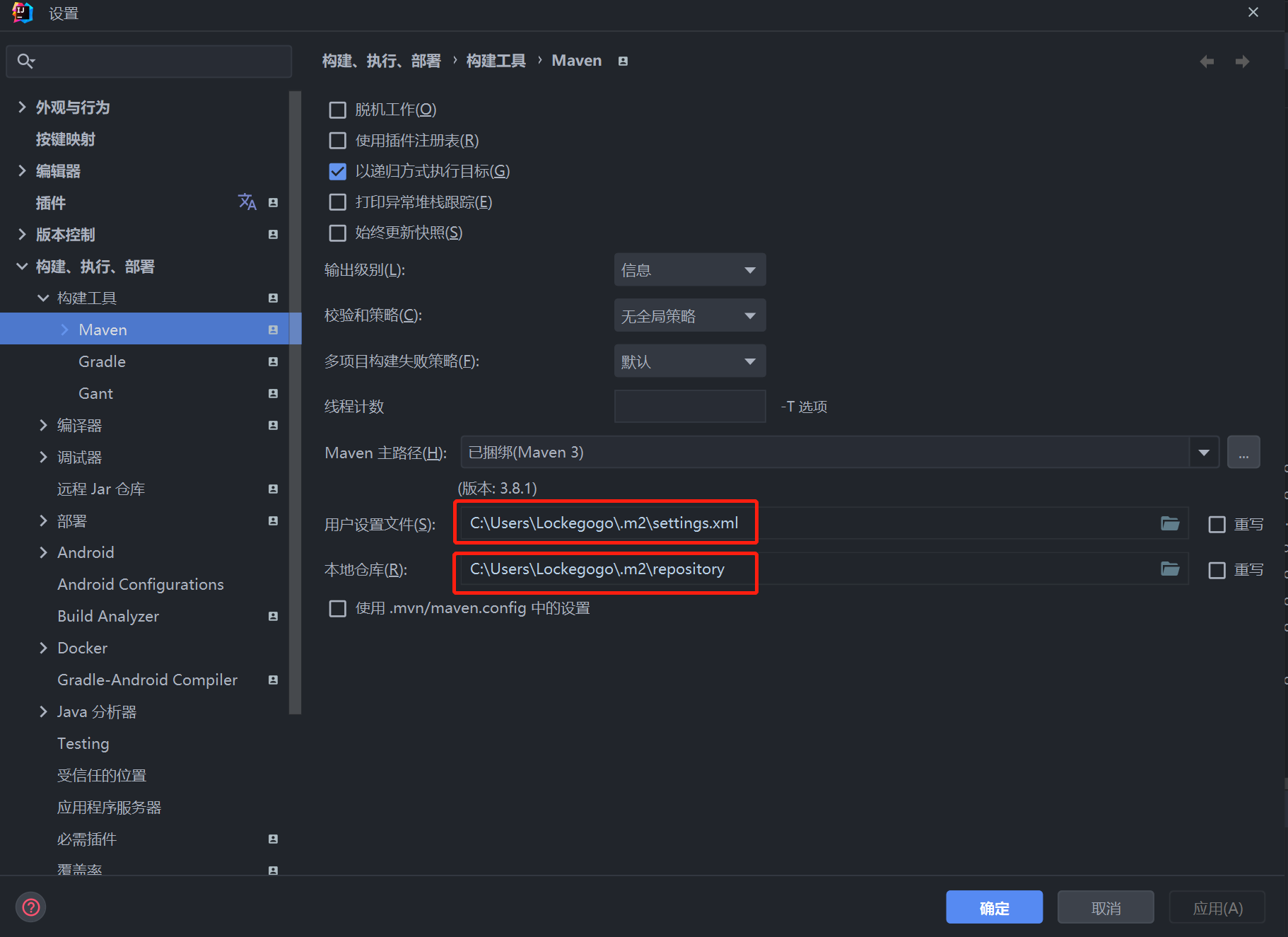
- 打开用户配置文件:
C:\Users\Lockegogo\.m2\settings.xml,配置阿里云仓库:
<!-- 配置阿里云仓库 -->
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
- 使用脚本删除 Maven 中的 lastUpdated 文件
@echo off
rem 这里写你的仓库路径
set REPOSITORY_PATH=C:\Users\Lockegogo\.m2\repository
rem 正在搜索...
for /f "delims=" %%i in ('dir /b /s "%REPOSITORY_PATH%\*lastUpdated*"') do (
del /s /q %%i
)
rem 搜索完毕
pause
- 如果依赖还是报错,继续尝试:
- 把
pom.xml中的对应的依赖先删除,然后刷新右侧,之后再把依赖粘贴到 pom.xml 中,再次刷新 - 从本地仓库中将对应的包删除掉,然后让 maven 重新下载
- 把
Github Copilot 无法连接
-
方法一
- 打开猫
- Pycharm 文件 \(\to\) 设置 \(\to\) 外观与行为 \(\to\) 系统设置 \(\to\) HTTP 代理
- 选手动代理配置,勾选 HTTP,主机名填 127.0.0.1,端口号填 7890(猫的端口号),点击确定
- 重启 pycharm,之后可以正常登录 copilot
-
方法二
- 打开猫
- 将代理端口改成与猫一样
set http_proxy=http://127.0.0.1:7890 set https_proxy=http://127.0.0.1:7890 # 若要重置 set http_proxy=- 以 vscode 为例:文件 \(\to\) 首选项 \(\to\) 设置 \(\to\) 搜索 proxy,找到 http.proxy,将其值改为
http://127.0.0.1:7890
使用 scp 上传文件
注意:要以绝对路径写清楚本地文件的位置
# 从服务器上下载文件
scp username@servername:/path/filename /tmp/local_destination
# 上传本地文件到服务器
scp /path/local_filename username@servername:/path
# 从服务器下载整个目录
scp -r username@servername:remote_dir/ /tmp/local_dir
# 上传目录到服务器
scp -r /tmp/local_dir username@servername:remote_dir
# 查看机器的用户名和 ip
query user
ifconfig
优雅地下载 huggingface 模型
可以使用 huggingface-cli 命令:
huggingface-cli download <模型名,如 deepseek-ai/deepseek-vl2> --local-dir <本地存储路径 dir>
Android 项目 sync 不成功
- 严格按照各版本配置:ndk 和 jdk
- 在
~/.bashrc中配置环境变量,路径可以在 AS 中直接查看
export NDK=/home/lockegogo/Android/Sdk/ndk/21.4.7075529
export PATH=$NDK:$PATH
#JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
JAVA_HOME=/home/lockegogo/.jdks/corretto-11.0.20
#JAVA_HOME=/home/lockegogo/.jdks/corretto-1.8.0_382
CLASSPATH=$JAVA_HOME/lib
PATH=$JAVA_HOME/bin:$PATH
export PATH JAVA_HOME CLASSPATH
- 在
local.properties文件中增加 ndk 路径
sdk.dir=/home/lockegogo/Android/Sdk
ndk.dir=/home/lockegogo/Android/Sdk/ndk/21.4.7075529
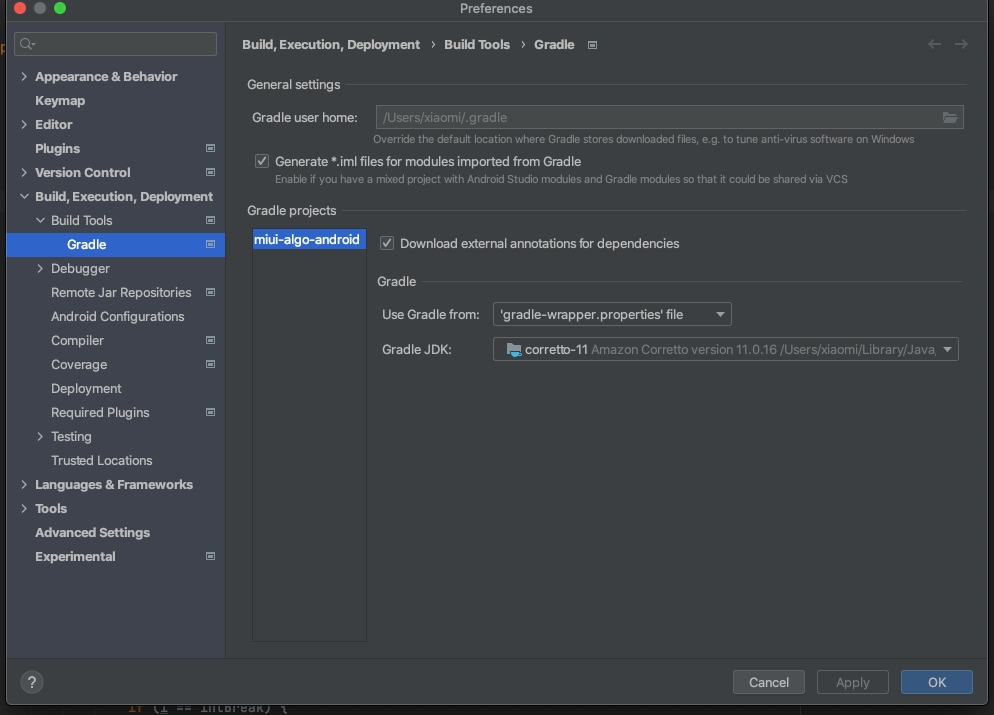
- 选择 Gradle JDK 版本:corretto-11
- 玄学步骤:https://segmentfault.com/q/1010000043160587
- 先按教程改
- 报错之后再该回来,就成功了
- 直接 File -> Invilidate caches 也可以达到不报错的目的
Android Studio 项目导包问题
问题描述:切换新分支后,导包飘红
解决方案:File -> Invalidata caches,然后重启一下就好了
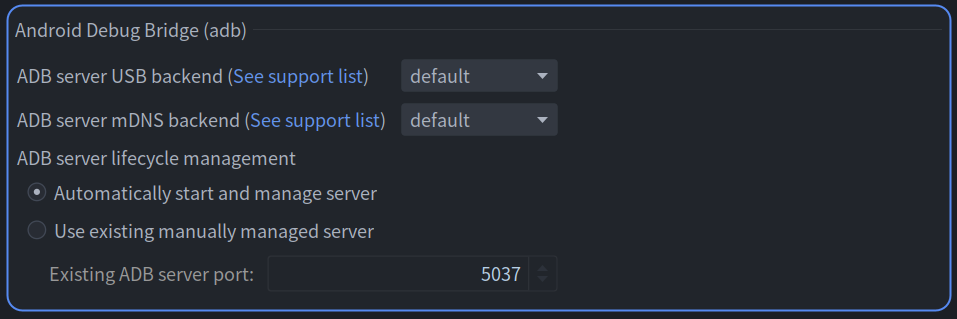
Android Studio 总是断连如何解决
搜索:Android Debug Bridge,将 ADB server mDNS backend 改为 default
Android Studio 如果卡在了 loading devices
# 1. 查找并杀死 adb 进程:
ps aux | grep adb
kill -9 进程号
# 2. 重启 adb 服务
adb start-server
# 3. 验证 adb 是否正常运行
adb devices
Vscode 导包找不到对应模块
方法一:在文件开头导入项目根目录
import sys
import os
# 获取当前脚本文件所在的目录路径
current_dir = os.getcwd()
# 获取项目根目录路径,根据实际情况调整级别
project_root = os.path.abspath(os.path.join(current_dir, "..", ".."))
# 将项目根目录添加到模块搜索路径中
if project_root not in sys.path:
sys.path.append(project_root)
# 检查模块搜索路径是否正确
print(sys.path)
方法二:将当前脚本所在的目录路径添加到 sys.path 列表中,以便 Python 解释器能够在该目录下查找和导入模块
import sys
import os
sys.path.append(os.path.dirname(__file__))
print(sys.path)
方法三:如果开源代码中使用类似于:from ..serialize import bytes_to_bit_arr这样的相对导入,可以使用 python -m 模块名 来运行
python -m module_name
# 例如:arr 是一个 py 文件
python -m psi.utils.arr
Vscode 加载 web 视图时出错
- 关闭 vscode
- 在 cmd 中输入:
code --no-sandbox
在开发环境中不能进入 conda
# 先运行
source activate
# 然后再进入对应的环境
conda activate env
jupyter 添加 conda 虚拟环境
source activate
conda create -n tf-sms python==3.7.13
conda activate tf-sms
# 安装 tensorflow
conda insatll pip
pip install tensorflow==2.8.0
# 测试 tensorflow 是否正常安装
python -c "import tensorflow as tf; print(tf.__version__)"
# 安装其他依赖
pip install -r requirements.txt
# 安装 ipykernel
conda install ipykernel
python -m ipykernel install --user --name=env_name
# 刷新 jupyter 界面,在界面的右上角就可以选择新的 kernel 了
# 如果需要删除该 kernel
jupyter kernelspec list
jupyter kernelspec uninstall env_name
Gradle 不显示 build
解决方案:
- File -> Setting -> Experimental,将 Gradle 下的 Configure all Gradle ... 勾选4
- File -> Sync Project with Gradle FIles
将 apk 文件安装到安卓手机上
方法 1:如果失败的话尝试方法 2
adb install samples-debug.apk
方法 2:
adb push samples-debug.apk /sdcard/samples-debug.apk
# 然后进入手机的文件 app,点击即可安装
ADB 版本不一致的问题
adb install 时报错:
adb server version (41) doesn't match this client (39); killing...
参考解决方案:adb server version (40) doesn't match this client (41); killing... On MacOS
cd /usr/bin
sudo rm adb
cd /home/lockegogo/Android/Sdk/platform-tools/
# Please check if there is an adb file inside your path
sudo cp adb /usr/bin
将项目的根目录加入 path
为了增强代码的鲁棒性,最好将项目的根目录加入 path,方法如下:
import sys
import os
# 获取当前脚本所在目录
project_root = os.path.dirname(os.path.abspath(__file__))
# 将项目根目录添加到 sys.path
sys.path.insert(0, project_root)
Keras 画模型的输入输出图
import pydot
from keras.utils.vis_utils import plot_model
model = load_model("model.h5")
plot_model(
model.model,
to_file=os.path.join("model", model_name, "model.png"),
show_shapes=True,
show_layer_names=True,
)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号