
集合深入分析
List:
ArrayList:
-
底层是一个数组。
-
实现List接口,有序可重复。
-
是可变长度数组。扩容时变为原来的1.5倍。
-
三种初始化方法,无参构造函数时,默认数组大小为10,容量不够时扩为原来的1.5倍,若容量还不够,直接扩展为所需容量;2、当传入一个具体数值时,初始化数组的大小即为传进去的数据大小。3、可以传入一个集合。
LinkedList:
-
底层是一个双向链表。 双向链表意味着我们可以从头开始正向遍历,或者是从尾开始逆向遍历,并且可以针对头部和尾部进行相应的操作。
-
双向链表节点对应的类Node的实例,Node中包含成员变量:prev,next,item。其中,prev是该节点的上一个节点,next是该节点的下一个节点,item是该节点所包含的值。

-
举例:
-
List<Integer> lists = new LinkedList<Integer>(); lists.add(5); lists.add(6);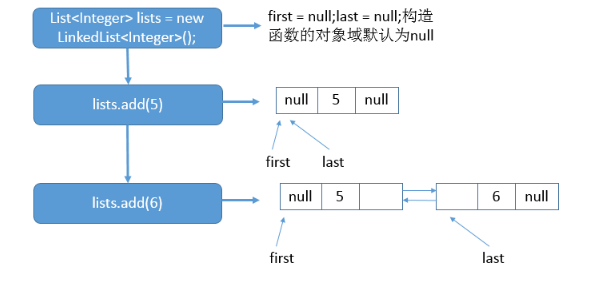
Map:
HashMap:
-
在JDK1.8之前,HashMap采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。 但是当hash值相等的元素较多时,通过key值依次查找的效率较低。
-
在JDK1.8中,HashMAp使用数组+链表+红黑树实现。当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
jdk1.8之前的hashmap结构:
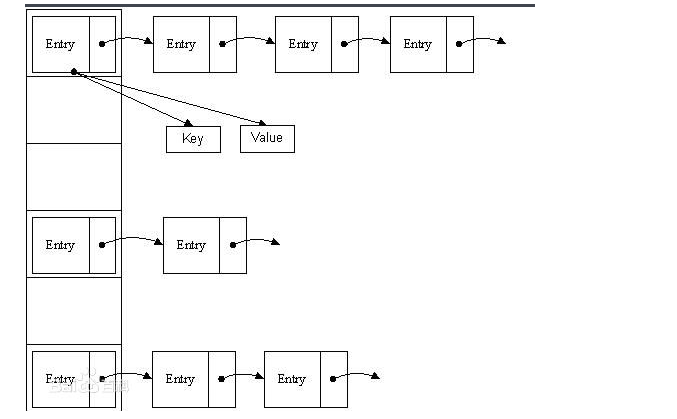
- 左边部分即代表哈希表,也称为哈希数组,数组的每个元素都是一个单链表的头节点,链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中。
- 当同一个hash值的节点数不小于8时,不再采用单链表形式存储,而是采用红黑树。
ConcurrentHashMap:
采用锁分段技术,即 将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。 有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。这里“按顺序”是很重要的,否则极有可能出现死锁,在ConcurrentHashMap内部,段数组是final的,并且其成员变量实际上也是final的,但是,仅仅是将数组声明为final的并不保证数组成员也是final的,这需要实现上的保证。这可以确保不会出现死锁,因为获得锁的顺序是固定的。
ConcurrentHashMap的主干是个Segment数组。
final Segment<K,V>[] segments;
Segment继承了ReentrantLock,所以它就是一种可重入锁(ReentrantLock)。在ConcurrentHashMap,一个Segment就是一个子哈希表,Segment里维护了一个HashEntry数组,并发环境下,对于不同Segment的数据进行操作是不用考虑锁竞争的。
transient volatile HashEntry<K,V>[] table;
HashEntry是目前我们提到的最小的逻辑处理单元了。一个ConcurrentHashMap维护一个Segment数组,一个Segment维护一个HashEntry数组。
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
//其他省略
}
ConcurrentHashMap的构造方法:
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
//MAX_SEGMENTS 为1<<16=65536,也就是最大并发数为65536
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
//2的sshif次方等于ssize,例:ssize=16,sshift=4;ssize=32,sshif=5
int sshift = 0;
//ssize 为segments数组长度,根据concurrentLevel计算得出
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
//segmentShift和segmentMask这两个变量在定位segment时会用到,后面会详细讲
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//计算cap的大小,即Segment中HashEntry的数组长度,cap也一定为2的n次方.
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
//创建segments数组并初始化第一个Segment,其余的Segment延迟初始化
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0);
this.segments = ss;
}
初始化方法有三个参数,如果用户不指定则会使用默认值,initialCapacity为16,loadFactor为0.75(负载因子,扩容时需要参考),concurrentLevel为16。
Segment数组的大小ssize是由concurrentLevel来决定的,但是却不一定等于concurrentLevel,ssize一定是大于或等于concurrentLevel的最小的2的次幂。比如:默认情况下concurrentLevel是16,则ssize为16;若concurrentLevel为14,ssize为16;若concurrentLevel为17,则ssize为32。为什么Segment的数组大小一定是2的次幂?其实主要是便于通过按位与的散列算法来定位Segment的index。
put方法:
put的主要逻辑也就两步:1.定位segment并确保定位的Segment已初始化 2.调用Segment的put方法。
public V put(K key, V value) {
Segment<K,V> s;
//concurrentHashMap不允许key/value为空
if (value == null)
throw new NullPointerException();
//hash函数对key的hashCode重新散列,避免差劲的不合理的hashcode,保证散列均匀
int hash = hash(key);
//返回的hash值无符号右移segmentShift位与段掩码进行位运算,定位segment
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
get方法:
get方法无需加锁,由于其中涉及到的共享变量都使用volatile修饰,volatile可以保证内存可见性,所以不会读取到过期数据。
public V get(Object key) {
Segment<K,V> s;
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
//先定位Segment,再定位HashEntry
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
Set:
HashSet:
无序,不可重复。底层是一个hashMap。从而达到散列存储的效果。也就是插入元素无序。
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
/*
这里变量用到transient修饰。这里顺便解释下该变量的含义和用法:
含义:
当某个类实现了Serilizable接口,这个类的所有属性和方法都会自动序列化。若我们有时需求是不需要某些属性进行序列化,如密码等敏感信息,为了安全起见,
不希望在网络操作 中被传输,这些信息对应的变量就可以加上transient关键字来修饰。即这个字段的生命周期仅存于调用者的内存中而不会写到磁盘里持久化。
用法:
首先将需要序列化的类实现 Serializable接口,然后将不需要序列化的属性前用transient变量修饰即可。
*/
private transient HashMap<E,Object> map;
// 构建了一个常量对象,后面会使用到
private static final Object PRESENT = new Object();
//初始化HashMap
public HashSet() {
map = new HashMap<>();
}
public Iterator<E> iterator() {
return map.keySet().iterator();
}
public int size() {
return map.size();
}
public boolean isEmpty() {
return map.isEmpty();
}
public boolean contains(Object o) {
return map.containsKey(o);
}
/**
*当我们使用add方法时,传入的元素做了HashMap的key,
*而前面定义的常量对象,则当做了一个没有意义的value,
*而这就是set不可重复的实现点,因为HashMap的key是不可重的。
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public void clear() {
map.clear();
}
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
}
}
TreeSet:
去重并排序,使用二叉树的原理进行排序。
有两种排序方式: 自然排序和定制排序。 TreeSet默认采用自然排序。
1.自然排序:
-
调用集合的compareTo(Object obj)方法来比较元素之间大小关系,然后将集合按升序排列。
-
java提供了一个Comparable接口,该接口里定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现该接口的类必须实现该方法,实现了该接口的类的对象就可以比较大小。当一个对象调用该方法与另一个对象进行比较,例如obj1.compareTo(obj2),如果该方法返回0,则表明这两个对象相等;如果返回一个正整数,则表明obj1大于obj2;如果该方法返回一个负整数,则表明obj1小于obj2。
-
已经实现了Comparable接口的常用类有: BigDecimal、 BigIneger等、Integer、 String、Date、Time。
-
若把自定义的对象添加到TreeSet中,那么该对象的类必须实现Comparable接口。否则会报错。
-
当把一个对象加入TreeSet集合中时,TreeSet调用该对象的compareTo(Object obj)方法与容器中的其他对象比较大小,然后根据红黑树算法决定它的存储位置。如果两个对象通过compareTo(Object obj)比较相等,TreeSet即认为它们存储同一位置。
-
对于TreeSet集合而言,它判断两个对象不相等的标准是:两个对象通过equals方法比较返回false,或通过compareTo(Object obj)比较没有返回0——即使两个对象时同一个对象,TreeSet也会把它们当成两个对象进行处理。
2.定制排序
-
TreeSet的自然排序是根据集合元素的大小,TreeSet将他们以升序排列。如果需要实现定制排序,例如降序,则可以使用Comparator接口。该接口里包含一个int compare(T o1, T o2)方法,该方法用于比较o1和o2的大小。
-
如果需要实现定制排序,则需要在创建TreeSet集合对象时,并提供一个Comparator对象与该TreeSet集合关联,由该Comparator对象负责集合元素的排序逻辑。
LinkedHashSet:
-
继承于HashSet,又基于LinkedHashMap来实现的。
-
底层用LinkedHashMap来保存所有元素,继承HashSet,所有的方法与HashSet相同。
-
既不能重复,又实现了有序。非同步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号