基于实习僧招聘数据进行数据分析与处理
基于实习僧招聘数据进行数据分析与处理
一,选题背景
实习僧,专注实习,校招的校园招聘平台。为大学生提供国内外行业巨头在内的25万+企业实习、校园招聘岗位信息。助力大学生职业发展,帮助企业有效招聘,找实习校招就上实习僧。预取目标是找的实习公司是机器学习算法相关的工作,所以只对“数据挖掘”、“机器学习”、“算法”这三个关键字进行了爬取,以及公司相关的分析。
二,爬虫设计方案
1,爬虫名称:基于实习僧招聘数据进行数据分析与处理
2,数据特征分析
使用pandas进行数据处理和分析,结合seaborn和pyecharts包进行数据可视化
三,结构特征分析
1,页面结构与特征分析


2,Htmls页面解析
四,程序设计
1,数据爬取与采集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import pyecharts
plt.style.use('ggplot')
%matplotlib inline
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] #解决seaborn中文字体显示问题
plt.rc('figure', figsize=(10, 10)) #把plt默认的图片size调大一点
#把通过“数据挖掘”、“机器学习”和“算法”这3个关键词爬取到的3个csv文件数据导入为pandas DataFrame,再把他们concat起来 #把ignore_index设置成True让其可以重新索引 data_dm = pd.read_csv("datamining.csv") data_ml = pd.read_csv("machinelearning.csv") data_al = pd.read_csv("mlalgorithm.csv") data = pd.concat([data_dm, data_ml, data_al], ignore_index = True)
#随机抽取3个数据样本看数据是否导入正确 #查看数据基本信息,看数据的行列数、数据类型是否正确、是否有重复数据,以及首先对重复数据进行处理 data.sample(3)

data.loc[666]

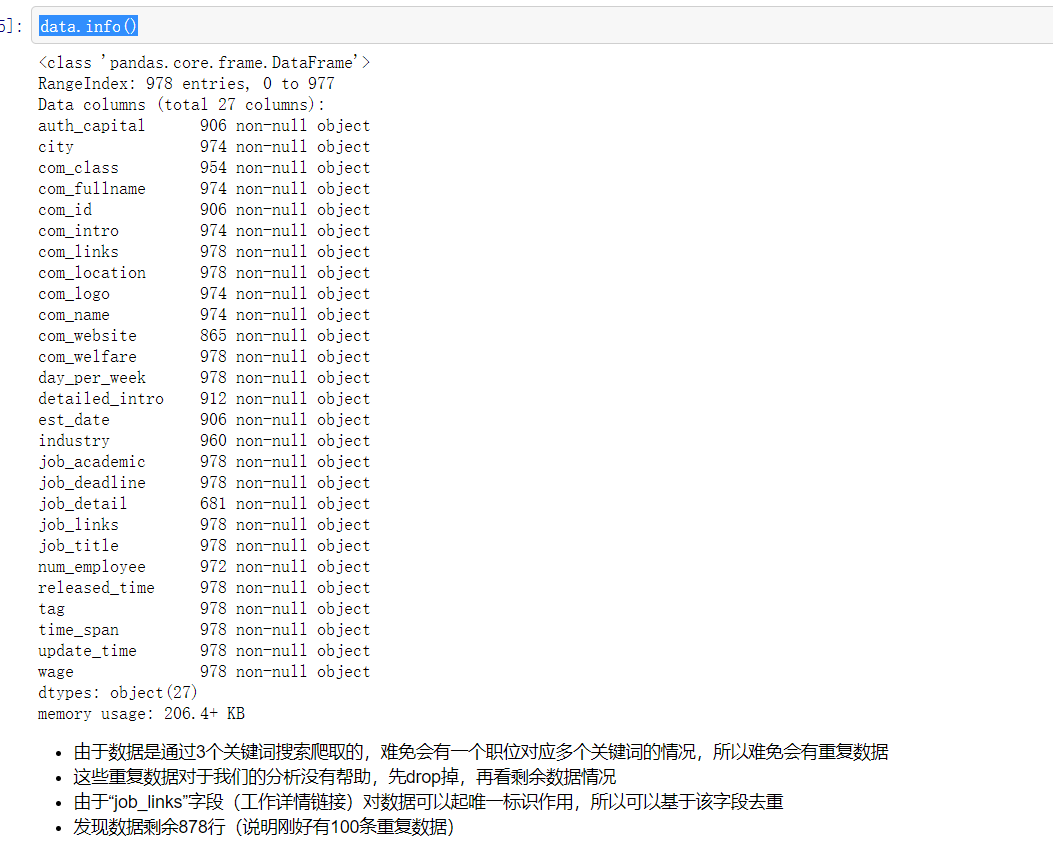
data.info()
data.drop_duplicates(subset='job_links', inplace=True) data.shape
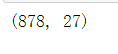
2,数据处理
#由上可见: #com_fullname、com_name、job_academic、job_links、tag不需要处理 #“auth_capital”(注册资本)、“day_per_week”(每周工作天数)、#“num_employee”(公司规模)、“time_span”(实习月数)、“wage”#(每天工资)等字段,都可以处理成数值型数据 #“est_date”(公司成立日期)、“job_deadline”(截止时间)、#“released_time”(发布时间)、“update_time”(更新时间)等字段,可#以处理成datetime类型数据 #“city”(城市)、“com_class”(公司类型)、“com_intro(公司简介)”、#“job_title”(职位名称)等字段可以进一步处理 #类似于“com_logo”(公司logo)、“industry”(行业)等字段,可以视情况处理 #com_id、com_links、com_location、com_website、com_welfare、#detailed_intro、job_detail在本次分析中用不上,不处理
#新建data_clean数据框 #新建data_clean数据框,数据处理在data_clean上进行 #data_clean用以保存处理好的数据,原数据data用以保存原始数据记录 #把本次分析中用不上的字段先drop掉
data_clean = data.drop(['com_id', 'com_links', 'com_location', 'com_website', 'com_welfare', 'detailed_intro', 'job_detail'], axis = 1)
#数值型数据处理 #包括“auth_capital”(注册资本)、“day_per_week”(每周工作天数)、“num_employee”(公司规模)、“time_span”(实习月数)、“wage”(每天工资)等字段
#“auth_capital”(注册资本) #随机抽取“auth_capital”,发现该字段的格式基本为:“注册资本:(数字)万|万元(币种)”,有少许的格式为:“注册资本:(币种)(数字)万|万元”, 或者“注册资本:无”,或者该字段为缺失值 #币种有人民币、美元、欧元、港元(港币)等 #这里的处理思路是先把“注册资本:”清理掉,再把数值型数据提取出来,然后根据各币种的汇率,把注册资本转换为“万元人民币”单位
data.auth_capital.sample(20)

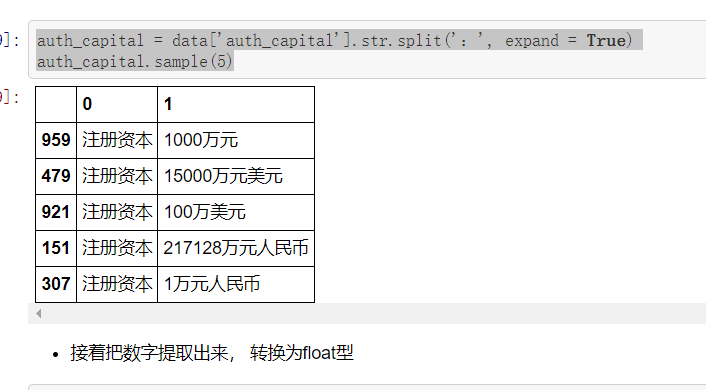
auth_capital = data['auth_capital'].str.split(':', expand = True) auth_capital.sample(5)
auth_capital['num'] = auth_capital[1].str.extract('([0-9.]+)', expand=False).astype('float') auth_capital.sample(5)

auth_capital[1].str.split('万', expand = True)[1].unique()

def get_ex_rate(string): if string == None: return np.nan if '人民币' in string: return 1.00 elif '港' in string: return 0.80 elif '美元' in string: return 6.29 elif '欧元' in string: return 7.73 elif '万' in string: return 1.00 else: return np.nan auth_capital['ex_rate'] = auth_capital[1].apply(get_ex_rate) auth_capital.sample(5)
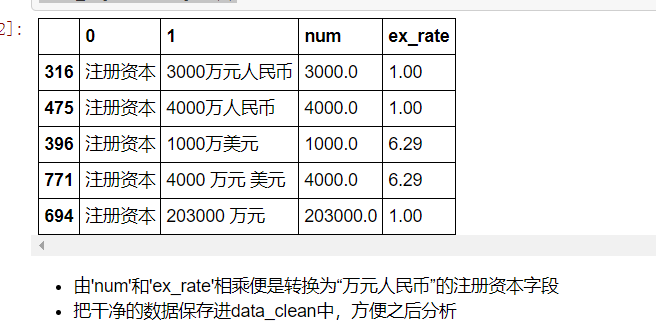
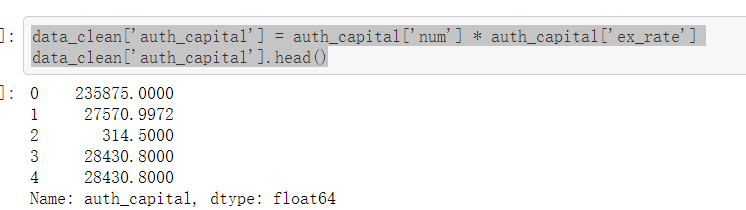
data_clean['auth_capital'] = auth_capital['num'] * auth_capital['ex_rate'] data_clean['auth_capital'].head()
#“day_per_week”(每周工作天数) #由下可见: #“day_per_week”字段没有缺失值,并且取值在“2-6天/周”之间 #可以采用直接赋值的方法处理该字段
data.day_per_week.unique()

data_clean.loc[data['day_per_week'] == '2天/周', 'day_per_week'] = 2 data_clean.loc[data['day_per_week'] == '3天/周', 'day_per_week'] = 3 data_clean.loc[data['day_per_week'] == '4天/周', 'day_per_week'] = 4 data_clean.loc[data['day_per_week'] == '5天/周', 'day_per_week'] = 5 data_clean.loc[data['day_per_week'] == '6天/周', 'day_per_week'] = 6
#“num_employee”(公司规模) #同样,由于“num_employee”字段取值在['2000人以上', '500-2000人', nan, '50-150人', '15-50人', '150-500人', '少于15人', '5000人以上'],可以采用跟“day_per_week”字段一样的处理方法 #'少于15人'、'15-50人'、'50-150人'都记为'小型企业','150-500人'、'500-2000人'记为'中型企业','2000人以上'、'5000人以上'记为大型企业
data.num_employee.unique()

data_clean.loc[data['num_employee'] == '少于15人', 'num_employee'] = '小型企业' data_clean.loc[data['num_employee'] == '15-50人', 'num_employee'] = '小型企业' data_clean.loc[data['num_employee'] == '50-150人', 'num_employee'] = '小型企业' data_clean.loc[data['num_employee'] == '150-500人', 'num_employee'] = '中型企业' data_clean.loc[data['num_employee'] == '500-2000人', 'num_employee'] = '中型企业' data_clean.loc[data['num_employee'] == '2000人以上', 'num_employee'] = '大型企业' data_clean.loc[data['num_employee'] == '5000人以上', 'num_employee'] = '大型企业' data_clean.loc[data['num_employee'].isna(), 'num_employee'] = np.nan
#“time_span”(实习月数) #由下可知: #“time_span”字段没有缺失值,由“1-18个月”组成 #当然,你也可以通过跟上面一样的处理方式来处理,但是,这种方式对于取值多的字段来说,第一比较繁琐,第二,其实这个赋值方式本身的运行速度很慢 #可以考虑构造一个字典,通过pd.Series.map() 也就是映射的方式来做,方便快捷
data.time_span.unique()

mapping = {} for i in range(1,19): mapping[str(i) + '个月'] = i print(mapping)

data_clean['time_span'] = data['time_span'].map(mapping) data_clean.head(3)

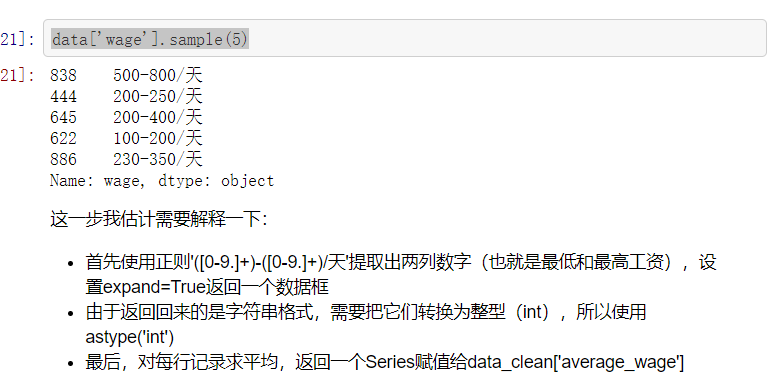
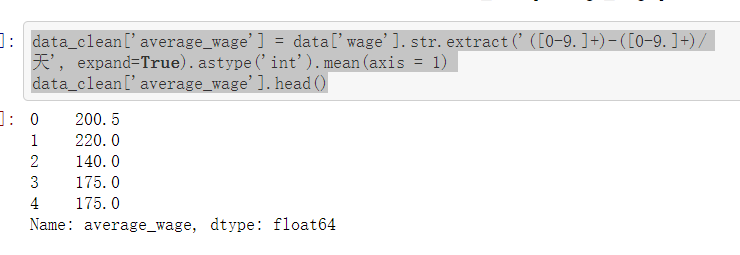
#“wage”(每天工资) #通过观察可知,该字段没有缺失值,并且格式全都为:xxx-xxx/天 #可以取一个最低工资,一个最高工资,再求一个平均工资 #这里,可以用之前的pd.Series.apply(function)来做,即定义一个函数提取每条记录中的工资最小和最大值 #不过,更加简便的方法肯定是正则提取啊
data['wage'].sample(5)
data_clean['average_wage'] = data['wage'].str.extract('([0-9.]+)-([0-9.]+)/天', expand=True).astype('int').mean(axis = 1) data_clean['average_wage'].head()
#时间数据处理 #包括“est_date”(公司成立日期)、“job_deadline”(截止时间)、“released_time”(发布时间)、“update_time”(更新时间)等字段
#“est_date”(公司成立日期) #随机抽取发现“est_date”这个字段的格式为:成立日期:xxxx-xx-xx #因此,直接正则提取,然后把它转换为datetime格式就可以了
data['est_date'].sample(5)
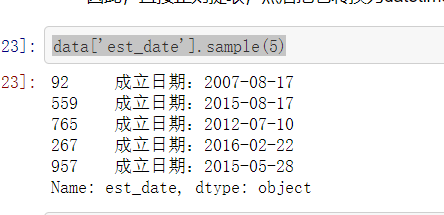
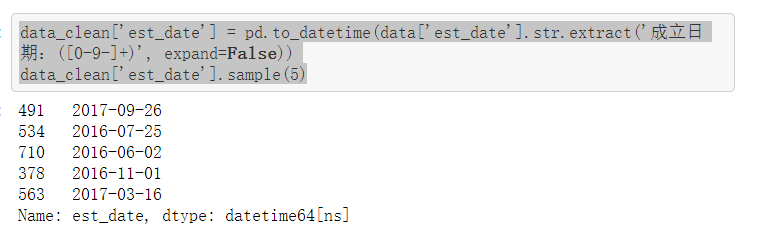
data_clean['est_date'] = pd.to_datetime(data['est_date'].str.extract('成立日期:([0-9-]+)', expand=False)) data_clean['est_date'].sample(5)
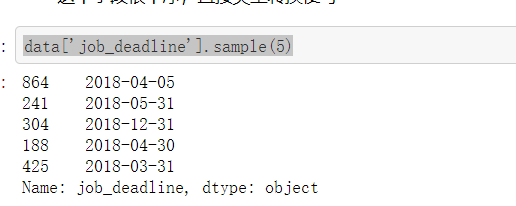
#“job_deadline”(截止时间) #这个字段很干净,直接类型转换便可
data['job_deadline'].sample(5)
data_clean['job_deadline'] = pd.to_datetime(data['job_deadline'])
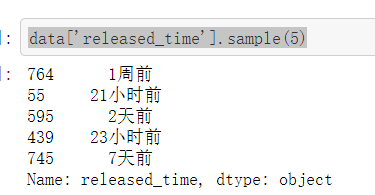
#“released_time”(发布时间) #观察数据发现,该字段1小时内的都以分钟表示、1小时-2天内的都以小时表示、2天-1周内的都以天表示,1周-1个月内的都以周表示,1个月以上的以月表示 #可以考虑清洗成:2天以内是最新的(newest),2天-1周是新的(new),1周-1个月是可以投简历的(acceptable),1个月以上的是旧的(old) #这个的处理方法很多,我的方法是先把每条记录中的分钟、小时、天、周、月提取出来,再定义一个映射map一下就可以了
data['released_time'].sample(5)
data_clean['released_time'] = data['released_time'].str.extract('[0-9-]+(\w+)前', expand=False).map( {'分钟':'newest', '小时':'newest', '天':'new', '周':'acceptable', '月':'old'}) data_clean['released_time'].sample(5)

#“update_time”(更新时间) #更新时间字段格式很工整,直接转换类型便可
data['update_time'].sample(5)
data_clean['update_time'] = pd.to_datetime(data['update_time'])
#字符型数据处理 #包括“city”(城市)、“com_class”(公司类型)、“com_intro(公司简介)”、“job_title”(职位名称)等字段
#“city”(城市)处理 #乍一看这个字段还挺整洁的,取唯一值看一下发现有些城市还是需要稍微处理一下 #比如说成都有“成都市”和“成都”,珠海有“珠海市”和“珠海”等 #直接赋值处理
data['city'].unique()

data_clean.loc[data_clean['city'] == '成都市', 'city'] = '成都' data_clean.loc[data_clean['city'].isin(['珠海市', '珠海 深圳', '珠海']), 'city'] = '珠海' data_clean.loc[data_clean['city'] == '上海漕河泾开发区', 'city'] = '上海'

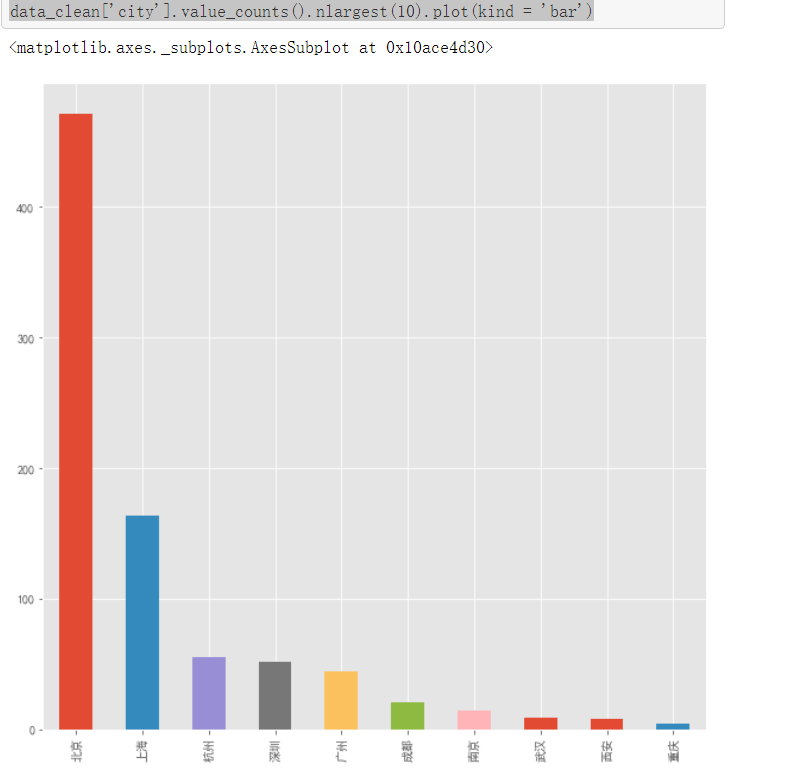
data_clean['city'].value_counts().nlargest(10).plot(kind = 'bar')
#“com_class”(公司和企业类型)处理 #类型有很多,可以按照组织形式可以分为独资企业、合伙企业、公司制企业,公司制企业又分为有限责任公司和股份有限公司等等 #这里主要把它分为‘股份有限公司(未上市)’、‘股份有限公司(上市)’、‘有限责任公司’、‘外商投资公司’、‘有限合伙企业’、‘国有企业’这6种 #处理方法跟上面币种的处理方法一致 #首先看看都有哪些公司(或企业)类型
list(data['com_class'].unique())

#定义一个函数处理这些类型,利用pd.Series.apply(function)方法 #把处理好的数据保存到data_clean中
def get_com_type(string): if string == None: return np.nan elif ('非上市' in string) or ('未上市' in string): return '股份有限公司(未上市)' elif '股份' in string: return '股份有限公司(上市)' elif '责任' in string: return '有限责任公司' elif '外商投资' in string: return '外商投资公司' elif '有限合伙' in string: return '有限合伙企业' elif '全民所有' in string: return '国有企业' else: return np.nan com_class = data['com_class'].str.split(':', expand = True) com_class['com_class'] = com_class[1].apply(get_com_type) com_class.sample(5)
data_clean['com_class'] = com_class['com_class']
#“com_intro”(公司简介)、“job_title”(职位名称)两个字段暂时不处理
# “com_logo”(公司logo)、“industry”(行业)也暂时不处理 #更改一下每列的顺序 #再把data_clean保存到本地
data_clean = data_clean.reindex(columns=['com_fullname', 'com_name', 'job_academic', 'job_links', 'tag','auth_capital', 'day_per_week', 'num_employee', 'time_span', 'average_wage', 'est_date', 'job_deadline', 'released_time', 'update_time', 'city', 'com_class', 'com_intro', 'job_title', 'com_logo', 'industry']) data_clean.to_csv('/Users/apple/Desktop/shixiseng/data_clean.csv', index = False)
数据分析
#进入数据分析的阶段。可以利用以上的城市、薪资、学历、行业、公司等相关字段,分析出目前国内公司对机器学习算法实习生的需求状况(仅基于实习僧网站),以及公司的相关情况 #首先,看看清洗完的数据的基本情况
数据基本情况
data_clean.sample(3)

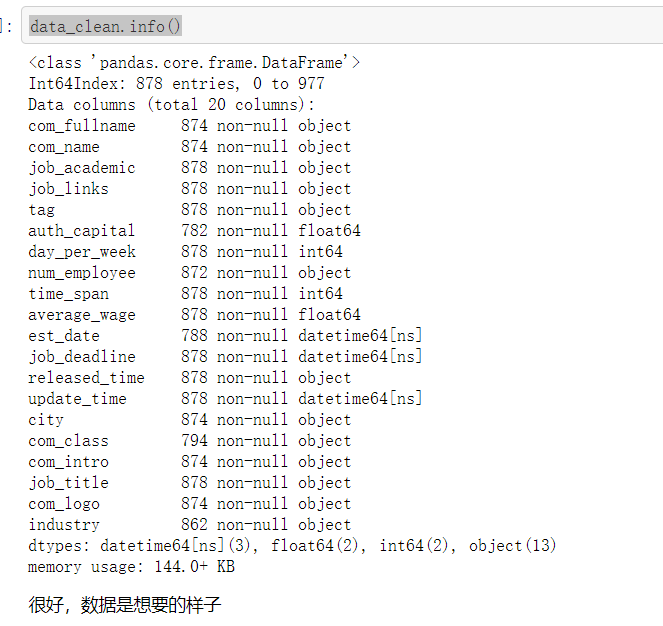
data_clean.info()
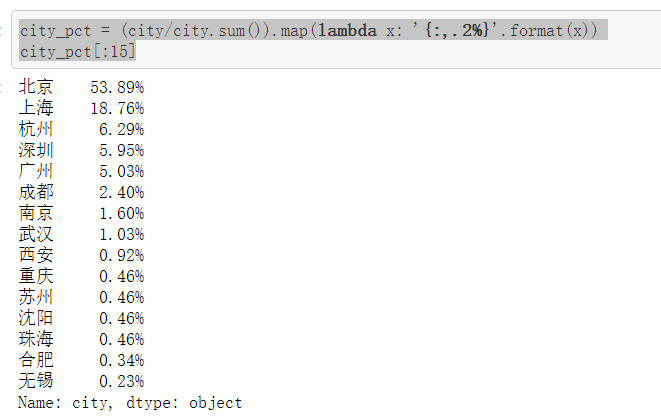
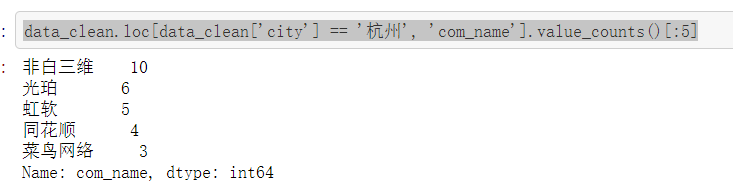
#城市与职位数量 #其实由上面已经知道了,北上广深杭这五个城市毫无疑问地占据了前五的位置,其中北京遥遥领先,有471个职位,占53.89%;上海有164个,占18.76%;北上广深杭这五个城市占了所有的89.93%(将近九成),说明这个职位还是集中在一线城市 #另外值得注意的是,杭州排到了第三,在广州和深圳的前面,说明杭州在这方面的发展还挺好的 #原以为杭州的职位都被阿里系霸占了,结果抽取数据出来一看发现并没有,其中一家叫“非白三维”的公司占了10个职位,这到底是一家什么样的公司?可以去了解一下
city = data_clean['city'].value_counts() city[:15]

bar = pyecharts.Bar('城市与职位数量') bar.add('', city[:15].index, city[:15].values, mark_point=["max"]) bar city_pct = (city/city.sum()).map(lambda x: '{:,.2%}'.format(x)) city_pct[:15]
(city/city.sum())[:5].sum()

data_clean.loc[data_clean['city'] == '杭州', 'com_name'].value_counts()[:5]
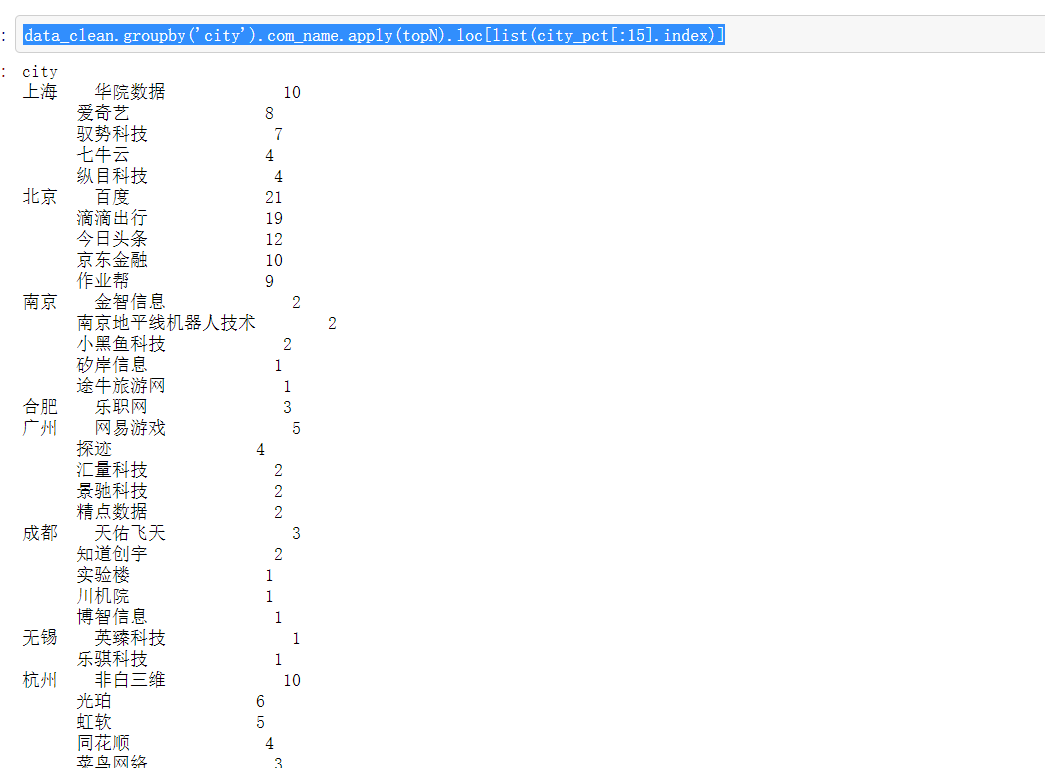
#再看看这15个个城市中,招聘职位数量前五的公司到底是哪些 #通过定义一个函数topN来实现
def topN(dataframe, n=5): counts = dataframe.value_counts() return counts[:n] data_clean.groupby('city').com_name.apply(topN).loc[list(city_pct[:15].index)]
薪资
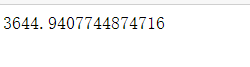
#平均薪资 #由于"average_wage"(薪资)一列的单位是每天,所以可以跟"day_per_week"(每周天数)结合起来算每月的工资(以一个月4周算) #另起一列“salary”(月工资)保存数据 #发现平均实习工资是3645元人民币,应该还是OK的噶?
data_clean['salary'] = data_clean['average_wage'] * data_clean['day_per_week'] * 4 data_clean['salary'].mean()
#薪资与城市 #以城市分组,看不同城市平均实习工资怎么样,发现薪资前五名中,北上广深杭只有杭州进入了前五,不过前五中其它四个城市的样本量都太小,数据不具有代表性 #看看职位需求前10的城市,平均实习薪资怎么样,发现杭州是最高的,突破了4000(还算可以的噶?),紧接着是北京3790(弱弱地问一句,够房租不?),然后是深圳、上海、南京、广州
salary_by_city = data_clean.groupby('city')['salary'].mean() salary_by_city.nlargest(10)
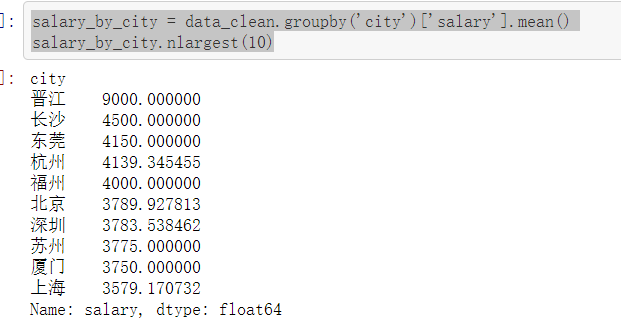
top10_city = salary_by_city[city_pct.index[:10]].sort_values(ascending=False)
top10_city

bar = pyecharts.Bar('北上广深杭等城市平均实习工资') bar.add('', top10_city.index, np.round(top10_city.values, 0), mark_point=["max"], is_convert=True) bar
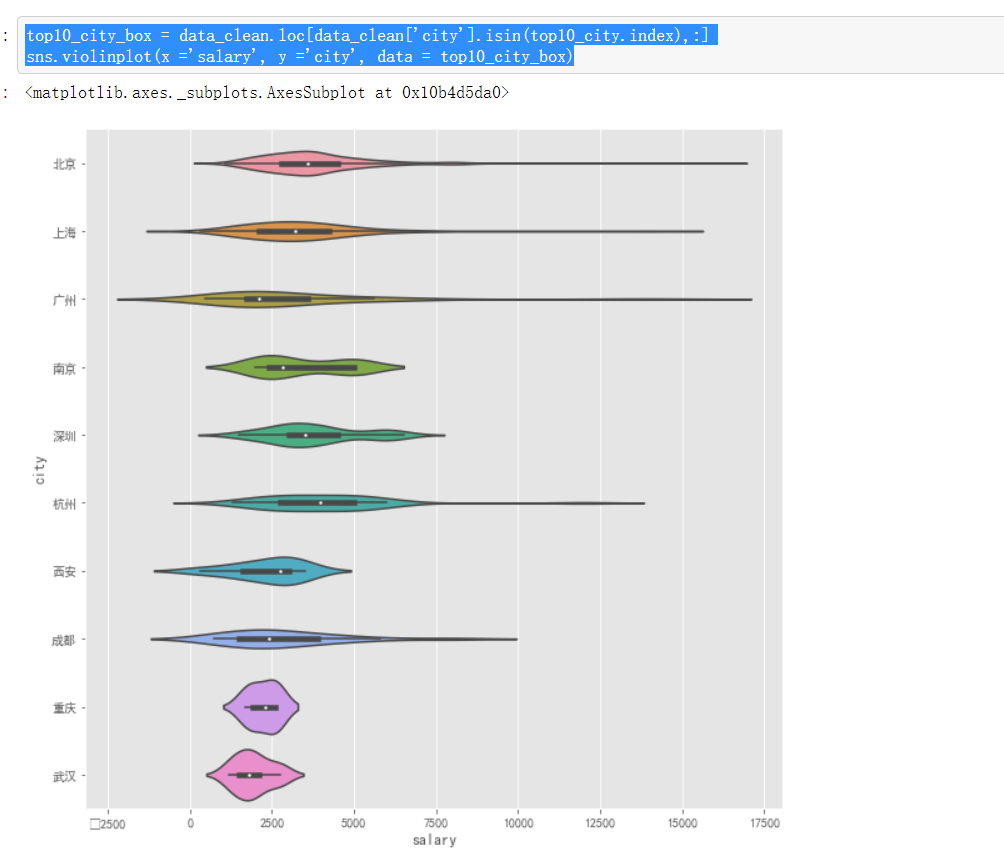
再看看这些城市实习薪资的分布怎么样
top10_city_box = data_clean.loc[data_clean['city'].isin(top10_city.index),:] sns.violinplot(x ='salary', y ='city', data = top10_city_box)
学历
数据挖掘、机器学习算法的学历要求
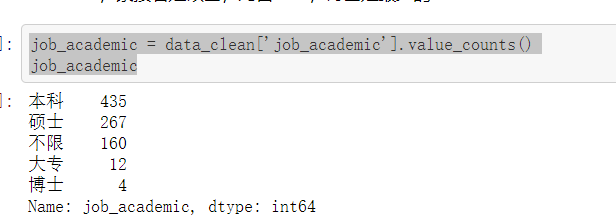
- 先看看总体来说,需要什么学历的最多,发现需求的本科生数量是最多的,约占50%,紧接着是硕士,约占30%,博士是最少的
job_academic = data_clean['job_academic'].value_counts() job_academic
pie = pyecharts.Pie("学历要求") pie.add('', job_academic.index, job_academic.values) pie
#学历与薪资 #再看看实习薪资和学历有什么关系。发现基本上是正相关的关系,博士最高,接着是硕士、本科、大专 #但是,本科和硕士的实习工资差别不大 #总体看起来实习工资都偏低一些(不知道大家的实习工资是多少呢?),就算是博士也不太高
data_clean.groupby(['job_academic'])['salary'].mean().sort_values()

sns.boxplot(x="job_academic", y="salary", data=data_clean)

行业
- 有一个好奇是,在现在的各行各业中,哪些行业对数据挖掘、机器学习算法的实习生需求更多,还有哪些行业现在也正在应用机器学习算法
- “industry”字段是前面还未处理的,先看看数据长什么样子,发现同一条记录可能对应着一个或者多个行业,格式为xxx/xxx或者xxx,xxx,或者xxx,xxx等
- 字段存在一定的缺失值
- 考虑把字段按照/,,分割,行业名称每出现一次,做一次记录,比如“计算机/互联网,金融”,既属于“计算机”行业、又属于“互联网”行业,也属于“金融行业”,因此这3个行业的记录加1
data_clean['industry'].sample(5)

industry = data_clean.industry.str.split('/|,|,', expand = True)
industry_top15 = industry.apply(pd.value_counts).sum(axis = 1).nlargest(15) bar = pyecharts.Bar('行业与职位数量') bar.add('', industry_top15.index, industry_top15.values, mark_point=["max","min","average"], xaxis_rotate=45) bar
公司
有很多跟公司相关的字段,很好奇哪些公司现在招的实习生职位数量最多、公司规模如何、这些公司都是什么时候成立的、是不是最近几年新成立的公司占的比例比较大、哪些公司给的实习薪资高一些、哪些公司比较看重学历
公司与职位数量、平均实习月薪
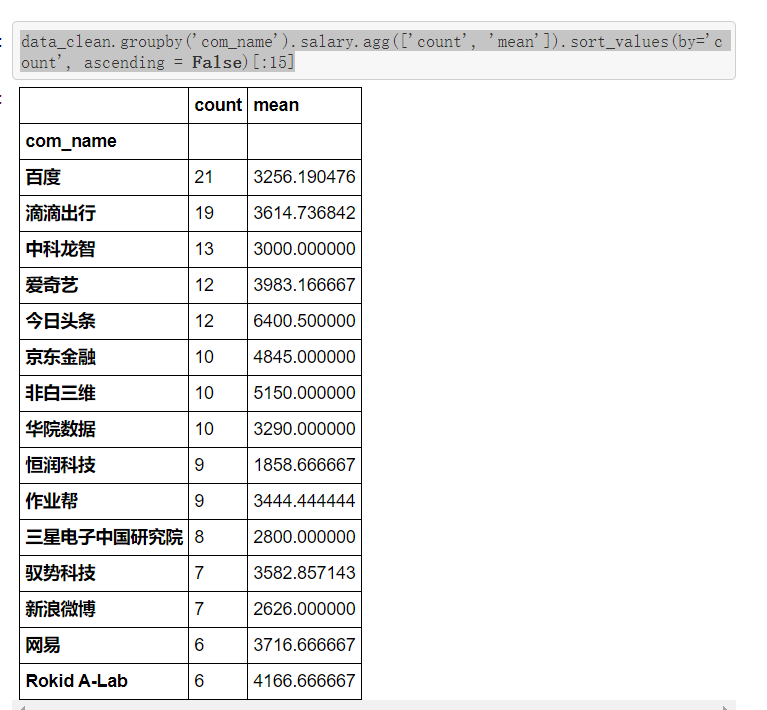
- 看看招聘职位数量前15名的公司都有哪些。发现了很多耳熟能详的大公司,比如说百度、滴滴、爱奇艺、头条、京东等
- 还有一些比较陌生的,比如中科龙智、华院数据、非白三维、恒润科技、驭势科技、Rokid A-Lab等,这些公司都值得去了解一下
- 这些公司中,今日头条的平均实习月薪最高,6400.5元,非白三维这家公司的实习月薪也不错,5150元,比某度好多了
data_clean.groupby('com_name').salary.agg(['count', 'mean']).sort_values(by='count', ascending = False)[:15]
公司规模与职位数量
- 数据挖掘、机器学习的实习生的需求,是否是以大型企业为主导呢?
- 发现并不是的,这方面的需求是以小中大型企业向下递减的,也间接说明了这个行业迅速发展的同时催生了很多中小企业吧
data_clean['num_employee'].value_counts()

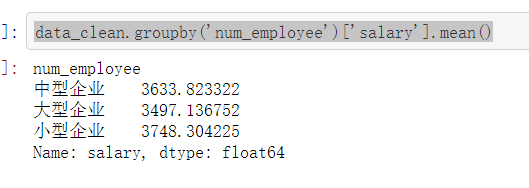
公司规模与实习月薪
- 我猜应该是大公司实习月薪高,小公司实习月薪低吧
- 发现:我还是太天真了,结果刚好相反,小公司给的高,大公司给的低
- 仔细想想好像也不无道理,大公司靠自己的名气吸引实习生,小公司没有名气,只能靠给更多的钱来吸引实习生了
data_clean.groupby('num_employee')['salary'].mean()
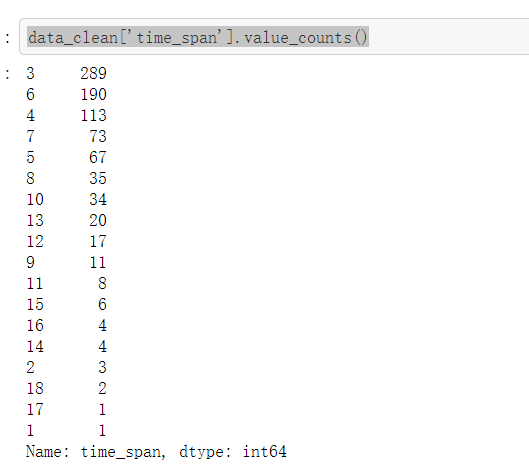
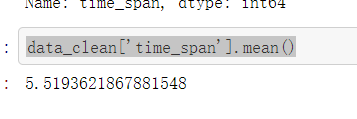
公司实习期长度
- 发现大多数公司要求的是实习3个月和6个月,基本上都是实习三个月起
- 平均实习期长度是五个半月
data_clean['time_span'].value_counts()
data_clean['time_span'].mean()
企业成立时间
刚好可以用企业成立时间验证一下猜想,也就是最近这个行业是否得到了迅速的成长,迅速成长的过程中,是否又催生了一大批的中小企业
- 首先,因为计算的是企业的数量而不是职位的数量,所以要先drop掉重复的企业
- 接着,把之前清理好的成立时间数据,再清理一下,以年做单位
- 然后,以年分组计算数量,便得到每年新成立的公司数量
- 发现:从2013年开始,公司呈现爆发式增长
est_date = data_clean.drop_duplicates(subset='com_name') import warnings warnings.filterwarnings('ignore') est_date['est_year'] = pd.DatetimeIndex(est_date['est_date']).year num_com_by_year = est_date.groupby('est_year')['com_name'].count() line = pyecharts.Line("每年新成立的公司数量变化") line.add("", num_com_by_year.index, num_com_by_year.values, mark_line=["max", "average"]) line
那新成立的企业中,企业规模怎么样?
- 把数据以企业规模和成立年份分组计数
- 发现2013年之后的爆发式增长中,主要以中小型企业为主
scale_VS_year = est_date.groupby(['num_employee', 'est_year'])['com_name'].count() scale_VS_year_s = scale_VS_year['小型企业'].reindex(num_com_by_year.index, fill_value=0) scale_VS_year_m = scale_VS_year['中型企业'].reindex(num_com_by_year.index, fill_value=0) scale_VS_year_l = scale_VS_year['大型企业'].reindex(num_com_by_year.index, fill_value=0) line = pyecharts.Line("新成立的企业与规模") line.add("小型企业", scale_VS_year_s.index, scale_VS_year_s.values, is_label_show=True) line.add("中型企业", scale_VS_year_m.index, scale_VS_year_m.values, is_label_show=True) line.add("大型企业", scale_VS_year_l.index, scale_VS_year_l.values, is_label_show=True) line
挑选实习公司
从以上的数据分析我们可以知道:
- 数据挖掘、机器学习算法岗位实习生的招聘,主要集中在“北上广深杭”这5个大城市
- 实习生的平均薪资为3644元人民币,“北上广深杭”这五个城市中,杭州的薪资最高,再者是北京、深圳
- 实习生学习以本科和硕士居多,并且这两者在实习薪资待遇上并没有太大的差别
- 互联网和计算机行业对于数据挖掘、机器学习算法岗位实习生需求是最多的,再者是金融、通信、电子行业
- 百度、滴滴、爱奇艺、头条、京东等大公司对该岗位的需求很多,另外还有中科龙智、华院数据、非白三维、恒润科技、驭势科技、Rokid A-Lab这些比较陌生的公司,对于该岗位的需求很多(应该是公司这方面的业务出于快速发展阶段)
- 大公司的实习薪资较少,小公司的薪资较多,不过差别不大
- 实习期以3个月或者6个月为主
- 从2013年开始,该行业的迅速发展催生了很多新的公司,主要以中小企业为主
这便是实习僧网站上,国内“机器学习算法实习生”岗位的一些基本情况。下面还有一个任务就是,挑选一些符合的公司,供投简历。 相关信息:
- 深圳人
- 硕士在读
- 只能实习3个月
- 薪资高于深圳平均实习薪资
- 要求是最新发布的职位
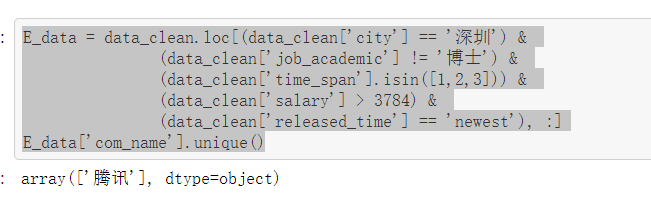
最后剩下......鹅厂...... 那就鹅厂吧,把鹅厂的这3条记录提取出来
E_data = data_clean.loc[(data_clean['city'] == '深圳') & (data_clean['job_academic'] != '博士') & (data_clean['time_span'].isin([1,2,3])) & (data_clean['salary'] > 3784) & (data_clean['released_time'] == 'newest'), :] E_data['com_name'].unique()
data.loc[E_data.index, ['job_title', 'job_links']]

完整代码:
1 import numpy as np 2 import pandas as pd 3 import matplotlib.pyplot as plt 4 import seaborn as sns 5 import pyecharts 6 plt.style.use('ggplot') 7 %matplotlib inline 8 9 from pylab import mpl 10 mpl.rcParams['font.sans-serif'] = ['SimHei'] #解决seaborn中文字体显示问题 11 plt.rc('figure', figsize=(10, 10)) #把plt默认的图片size调大一点 12 13 data_dm = pd.read_csv("datamining.csv") 14 data_ml = pd.read_csv("machinelearning.csv") 15 data_al = pd.read_csv("mlalgorithm.csv") 16 data = pd.concat([data_dm, data_ml, data_al], ignore_index = True) 17 18 data.sample(3) 19 20 data.loc[666] 21 22 data.info() 23 24 data.drop_duplicates(subset='job_links', inplace=True) 25 data.shape 26 27 data_clean = data.drop(['com_id', 'com_links', 'com_location', 'com_website', 28 'com_welfare', 'detailed_intro', 'job_detail'], axis = 1) 29 30 data.auth_capital.sample(20) 31 32 auth_capital = data['auth_capital'].str.split(':', expand = True) 33 auth_capital.sample(5) 34 35 auth_capital['num'] = auth_capital[1].str.extract('([0-9.]+)', expand=False).astype('float') 36 auth_capital.sample(5) 37 38 auth_capital[1].str.split('万', expand = True)[1].unique() 39 40 def get_ex_rate(string): 41 if string == None: 42 return np.nan 43 if '人民币' in string: 44 return 1.00 45 elif '港' in string: 46 return 0.80 47 elif '美元' in string: 48 return 6.29 49 elif '欧元' in string: 50 return 7.73 51 elif '万' in string: 52 return 1.00 53 else: 54 return np.nan 55 56 auth_capital['ex_rate'] = auth_capital[1].apply(get_ex_rate) 57 auth_capital.sample(5) 58 59 data_clean['auth_capital'] = auth_capital['num'] * auth_capital['ex_rate'] 60 data_clean['auth_capital'].head() 61 62 data.day_per_week.unique() 63 64 data_clean.loc[data['day_per_week'] == '2天/周', 'day_per_week'] = 2 65 data_clean.loc[data['day_per_week'] == '3天/周', 'day_per_week'] = 3 66 data_clean.loc[data['day_per_week'] == '4天/周', 'day_per_week'] = 4 67 data_clean.loc[data['day_per_week'] == '5天/周', 'day_per_week'] = 5 68 data_clean.loc[data['day_per_week'] == '6天/周', 'day_per_week'] = 6 69 70 data.num_employee.unique() 71 72 data_clean.loc[data['num_employee'] == '少于15人', 'num_employee'] = '小型企业' 73 data_clean.loc[data['num_employee'] == '15-50人', 'num_employee'] = '小型企业' 74 data_clean.loc[data['num_employee'] == '50-150人', 'num_employee'] = '小型企业' 75 data_clean.loc[data['num_employee'] == '150-500人', 'num_employee'] = '中型企业' 76 data_clean.loc[data['num_employee'] == '500-2000人', 'num_employee'] = '中型企业' 77 data_clean.loc[data['num_employee'] == '2000人以上', 'num_employee'] = '大型企业' 78 data_clean.loc[data['num_employee'] == '5000人以上', 'num_employee'] = '大型企业' 79 data_clean.loc[data['num_employee'].isna(), 'num_employee'] = np.nan 80 81 data.time_span.unique() 82 83 mapping = {} 84 for i in range(1,19): 85 mapping[str(i) + '个月'] = i 86 print(mapping) 87 88 data_clean['time_span'] = data['time_span'].map(mapping) 89 data_clean.head(3) 90 91 data['wage'].sample(5) 92 93 94 data_clean['average_wage'] = data['wage'].str.extract('([0-9.]+)-([0-9.]+)/天', expand=True).astype('int').mean(axis = 1) 95 data_clean['average_wage'].head() 96 97 data['est_date'].sample(5) 98 99 100 data_clean['est_date'] = pd.to_datetime(data['est_date'].str.extract('成立日期:([0-9-]+)', expand=False)) 101 data_clean['est_date'].sample(5) 102 103 104 data['job_deadline'].sample(5) 105 106 data_clean['job_deadline'] = pd.to_datetime(data['job_deadline']) 107 108 data['released_time'].sample(5) 109 110 data_clean['released_time'] = data['released_time'].str.extract('[0-9-]+(\w+)前', expand=False).map( 111 {'分钟':'newest', '小时':'newest', '天':'new', '周':'acceptable', '月':'old'}) 112 data_clean['released_time'].sample(5) 113 114 data['update_time'].sample(5) 115 116 data_clean['update_time'] = pd.to_datetime(data['update_time']) 117 118 119 data['city'].unique() 120 121 data_clean.loc[data_clean['city'] == '成都市', 'city'] = '成都' 122 data_clean.loc[data_clean['city'].isin(['珠海市', '珠海 深圳', '珠海']), 'city'] = '珠海' 123 data_clean.loc[data_clean['city'] == '上海漕河泾开发区', 'city'] = '上海' 124 125 data_clean['city'].value_counts().nlargest(10).plot(kind = 'bar') 126 127 list(data['com_class'].unique()) 128 129 def get_com_type(string): 130 if string == None: 131 return np.nan 132 elif ('非上市' in string) or ('未上市' in string): 133 return '股份有限公司(未上市)' 134 elif '股份' in string: 135 return '股份有限公司(上市)' 136 elif '责任' in string: 137 return '有限责任公司' 138 elif '外商投资' in string: 139 return '外商投资公司' 140 elif '有限合伙' in string: 141 return '有限合伙企业' 142 elif '全民所有' in string: 143 return '国有企业' 144 else: 145 return np.nan 146 147 com_class = data['com_class'].str.split(':', expand = True) 148 com_class['com_class'] = com_class[1].apply(get_com_type) 149 com_class.sample(5) 150 151 data_clean['com_class'] = com_class['com_class'] 152 153 data_clean = data_clean.reindex(columns=['com_fullname', 'com_name', 'job_academic', 'job_links', 154 'tag','auth_capital', 'day_per_week', 'num_employee', 'time_span', 155 'average_wage', 'est_date', 'job_deadline', 'released_time', 156 'update_time', 'city', 'com_class', 'com_intro', 'job_title', 157 'com_logo', 'industry']) 158 data_clean.to_csv('/Users/apple/Desktop/shixiseng/data_clean.csv', index = False) 159 160 data_clean.sample(3) 161 162 data_clean.info() 163 164 city = data_clean['city'].value_counts() 165 city[:15] 166 167 bar = pyecharts.Bar('城市与职位数量') 168 bar.add('', city[:15].index, city[:15].values, mark_point=["max"]) 169 bar 170 171 city_pct = (city/city.sum()).map(lambda x: '{:,.2%}'.format(x)) 172 city_pct[:15] 173 174 (city/city.sum())[:5].sum() 175 176 data_clean.loc[data_clean['city'] == '杭州', 'com_name'].value_counts()[:5] 177 178 def topN(dataframe, n=5): 179 counts = dataframe.value_counts() 180 return counts[:n] 181 182 data_clean.groupby('city').com_name.apply(topN).loc[list(city_pct[:15].index)] 183 184 data_clean['salary'] = data_clean['average_wage'] * data_clean['day_per_week'] * 4 185 data_clean['salary'].mean() 186 187 salary_by_city = data_clean.groupby('city')['salary'].mean() 188 salary_by_city.nlargest(10) 189 190 top10_city = salary_by_city[city_pct.index[:10]].sort_values(ascending=False) 191 top10_city 192 193 bar = pyecharts.Bar('北上广深杭等城市平均实习工资') 194 bar.add('', top10_city.index, np.round(top10_city.values, 0), mark_point=["max"], is_convert=True) 195 bar 196 197 top10_city_box = data_clean.loc[data_clean['city'].isin(top10_city.index),:] 198 sns.violinplot(x ='salary', y ='city', data = top10_city_box) 199 200 job_academic = data_clean['job_academic'].value_counts() 201 job_academic 202 203 pie = pyecharts.Pie("学历要求") 204 pie.add('', job_academic.index, job_academic.values) 205 pie 206 207 data_clean.groupby(['job_academic'])['salary'].mean().sort_values() 208 209 sns.boxplot(x="job_academic", y="salary", data=data_clean) 210 211 data_clean['industry'].sample(5) 212 213 industry = data_clean.industry.str.split('/|,|,', expand = True) 214 215 industry_top15 = industry.apply(pd.value_counts).sum(axis = 1).nlargest(15) 216 217 bar = pyecharts.Bar('行业与职位数量') 218 bar.add('', industry_top15.index, industry_top15.values, 219 mark_point=["max","min","average"], xaxis_rotate=45) 220 bar 221 222 data_clean.groupby('com_name').salary.agg(['count', 'mean']).sort_values(by='count', ascending = False)[:15] 223 224 data_clean['num_employee'].value_counts() 225 226 data_clean.groupby('num_employee')['salary'].mean() 227 228 data_clean['time_span'].value_counts() 229 230 data_clean['time_span'].mean() 231 232 est_date = data_clean.drop_duplicates(subset='com_name') 233 import warnings 234 warnings.filterwarnings('ignore') 235 est_date['est_year'] = pd.DatetimeIndex(est_date['est_date']).year 236 num_com_by_year = est_date.groupby('est_year')['com_name'].count() 237 line = pyecharts.Line("每年新成立的公司数量变化") 238 line.add("", num_com_by_year.index, num_com_by_year.values, mark_line=["max", "average"]) 239 line 240 241 scale_VS_year = est_date.groupby(['num_employee', 'est_year'])['com_name'].count() 242 scale_VS_year_s = scale_VS_year['小型企业'].reindex(num_com_by_year.index, fill_value=0) 243 scale_VS_year_m = scale_VS_year['中型企业'].reindex(num_com_by_year.index, fill_value=0) 244 scale_VS_year_l = scale_VS_year['大型企业'].reindex(num_com_by_year.index, fill_value=0) 245 246 line = pyecharts.Line("新成立的企业与规模") 247 line.add("小型企业", scale_VS_year_s.index, scale_VS_year_s.values, is_label_show=True) 248 line.add("中型企业", scale_VS_year_m.index, scale_VS_year_m.values, is_label_show=True) 249 line.add("大型企业", scale_VS_year_l.index, scale_VS_year_l.values, is_label_show=True) 250 line 251 252 E_data = data_clean.loc[(data_clean['city'] == '深圳') & 253 (data_clean['job_academic'] != '博士') & 254 (data_clean['time_span'].isin([1,2,3])) & 255 (data_clean['salary'] > 3784) & 256 (data_clean['released_time'] == 'newest'), :] 257 E_data['com_name'].unique() 258 259 data.loc[E_data.index, ['job_title', 'job_links']]
五,总结
1,经过对数据的分析与可视化,可以得到以下结论
- 首先,由于这篇文章的目的是给小E分析数据挖掘、机器学习算法实习生的需求情况,并且只爬了“实习僧”这一个网站,所以数据量比较小
- 不过,数据的清洗和分析的套路还是差不多的
- 由于前段时间了解到pyecharts这个画图神器,所以想在这里用一下。pyecharts画出来的图确实漂亮,不过总体感觉现在它跟pandas还是结合地不够好,用起来稍微有点繁琐,希望后面会越来越好越来越方便吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号