


大规模分布式存储系统
大规模分布式存储系统(2013版)
第一章 概述
无论是云计算、大数据还是互联网公司的应用,后台基础设施的目标都是低成本、高性能、可扩展、易用的分布式存储系统。
分布式存储系统的特性:
1. 可扩展:分布式存储系统可以扩展几百到上千台,同时性能线性增长。
2. 低成本:可以构建在普通PC机上。
3. 高性能:无论对于整个集群还是单台服务器,都要求具备高性能。
4. 易用:需要提供易用的对外接口,同时提供监控和运维工具。
5. 数据分布:如何将数据均匀分部到多台机器。
6:一致性:如何将数据的多副本复制到多个服务器,同时保持数据一致性。
7:容错:如何检测服务器故障,并将故障服务器的数据迁移到其他服务器。
8:负载均衡:如何保障负载均衡,数据迁移过程不影响已有服务。
9:事务与并发控制:如何实现分布式事务,并实现多版本控制。
10:易用性:如何使用对外接口容易使用,并将内部状态以方便的形式暴露给运维人员。
11:压缩/解压缩:如何根据数据特点进行压缩/解压缩。
分布式存储面临的数据分为三类:
1. 非结构化数据:文档、文本、图片、图像、音频和视频信息等。
2. 结构化数据:一般存储在关系型数据库中,可以用二维关系表结构来表示。模式和内容是分开的,需要先定义模式。
3. 半结构化数据:介于结构化和非结构化之间,如HTML。模式和内容混合没有明显区分。
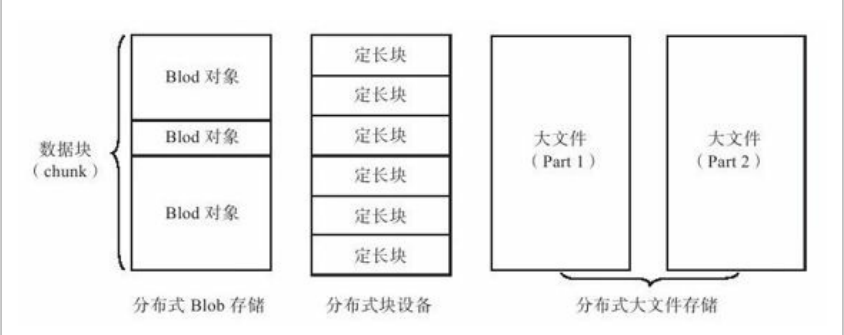
分布式文件系统:
如图片、照片、视频等非结构化数据,以对象的形式存储,一般称为Blob(Binary Large Object,二进制大对象)数据。
总体上,分布式文件系统存储:Blob对象、定长块、大文件。系统层面采用chunk来组织数据,如图1-1。
分布式j键值系统:
用于存储关系简单的半结构化数据,支持CRUD(create/read/update/delete)。
相对于传统哈希表,可以将数据分布到多个节点。作为分布式表格的简化实现,一般用于缓存,如:淘宝Tair,MemCache。
分布式表格系统:
用于存储较为复杂的半结构化数据,支持CRUD,同时支持扫描某个主键。

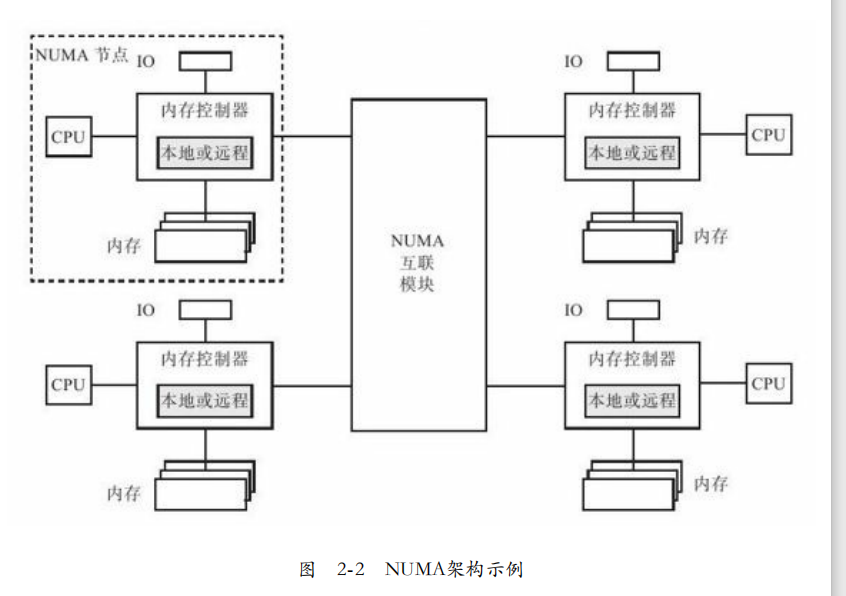
3. 由于SMP存在对前端总线的竞争,扩展能力有限。现在主流为NUMA(非一致存储访问)架构。具有多个NUMA节点,每个NUMA都有一个SMP结构。
如图2-2,每个节点可以直接访问本地内存,也可以通过NUMA互联互通模块访问其他节点的内存。

总线:如图2-3,intel x48采用南、北桥架构。北桥通过前端总线与CPU相连,内存模块以及PCI-E设备(如高端SSD设备)挂接在北桥。南桥与北桥通过DMI连接。网卡,硬盘,中低端固态盘等挂接在南桥。
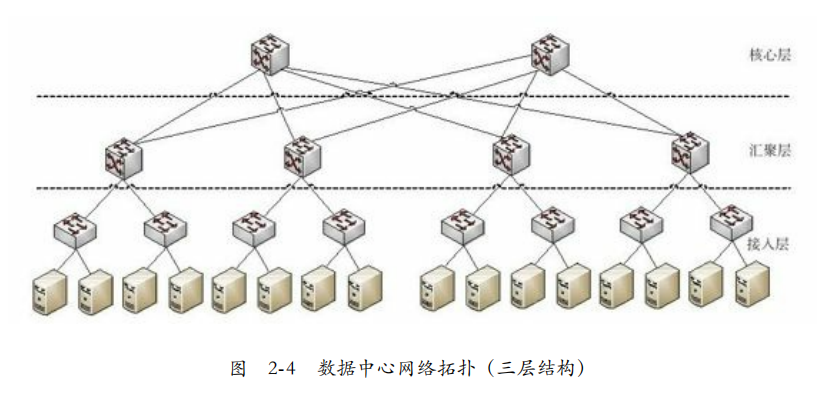
网络拓扑:图2-4为传统的数据中心网络拓扑:接入层有48个1Gb下行端口和4个10Gb的上行端口。汇聚层和核心层采用128个10Gb的端口。
但由于可能很多接入层涌入汇聚层,汇聚层涌入核心层,导致同一个接入层下的带宽为1Gb,不同接入层下的带宽不到1Gb。(因此HDFS,考虑有两个副本在一个机架就是在一个接入层)
Google推出来CLOS的网络架构,同一集群支持20480台服务器,任意两台带宽1Gb。网络一次来回延迟在1ms内。
对于不同数据中心延迟较大。如北京到杭州距离1300公里,光采用折射传输,假如折射距离为直线的1.5倍,那么延迟约为1300*1.5*2/3e8=13ms。实际测试大约40ms。
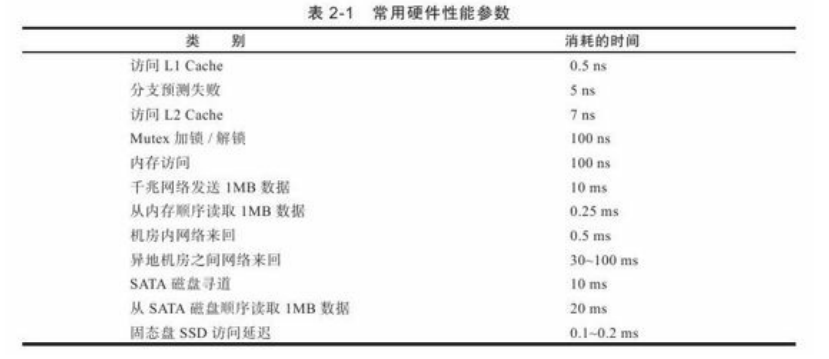
如表2-1,常见硬件的性能。
第二章 单机存储系统
单机存储引擎:作为存储系统的发动机,决定了存储系统的性能和功能。提供增、删、读(随机/顺序)、改。
哈希存储引擎作为哈希表的实现,提供增、删、该、随机读。不支持顺序读。对应的存储系统为键值存储系统。
B树存储引擎作为B树的实现,提供增、删、读(随机/顺序)、改。对应关系型数据库,当然也可以实现键值存储系统。
LSM-Tree类似B树存储引擎,通过批量转储规避磁盘随机写入问题。广泛用于互联网后台存储系统,如:Google BigTable,Google LevelDb,Facebook Cassandra。
哈希存储引擎
Bitcask是一个基于哈希表结构的键值存储系统,支持追加操作。每个文件大小有限制,写满后重新产生新文件,只有新文件会写入,旧文件只读。
数据结构:如图2-6.文件数据分为 主键(key),value内容(value),主键长度(key_sz),value长度(value_sz),时间戳(timestamp),crc校验值。
内存数据采用哈希表的索引数据结构。以便于通过主键快速定位value的位置。哈希表包含 文件编号(file id),value所在文件位置(value_pos),value长度(value_sz)。
内存中存了主键和索引信息,磁盘存储了主键和value的内容,因此适合value相对key较大情况,如:value 1KB,key 32字节,内存与磁盘比例1:32,32GB内存可以索引1TB的磁盘数据。

定期合并:对于删除和更新后,原始数据为垃圾数据,若一直保留,文件将无限膨胀下去,因此需要定期合并(Compaction),对于多个key保留最新的。
快速恢复:由于哈希表存储于内存,若不做额外工作,当重启哈希表时需要遍历一遍数据,非常好使,因此采用索引文件hint file来提高重建哈希表的速度。
索引文件就是将内存的哈希表转储到磁盘生成的文件。
B树存储引擎:不仅支持随机读取,还支持范围扫描。在Mysql InnoDB中,聚集索引将行的数据存储起来,成为B+树。
数据结构:Mysql InnoDB按照页(Page)来组织数据,每个页对应B+树的一个节点。叶子节点保存完整数据,非叶子节点作为索引。
查询:从根节点二分查询,对于不存在内存的页需要读出来,由于根节点常驻内存,磁盘IO次数为h-1次。对于修改操作需要先写入日志再修改内存内容,并在修改页面超过一定比率写入磁盘。
缓冲区管理:对于磁盘数据可以放到缓冲区(Cache),常采用LRU(按照访问时间构成链表,每次淘汰最后一个),LIRS(若做一次全表扫描,LRU就被污染了,可以做成多层LRU,常用的可以晋级)
LSM树存储引擎:将修改的增量保持在内存,到达指定大小后批量写入磁盘。读取时合并磁盘与内存中的数据。
存储结构:如图2-8所示,内存中又MemTable和Immutable MemTable。磁盘中:Current文件,清单文件(Manifest),操作日志(Log),SSTable文件。
当MemTable到达一定数据量,转为ImmuTable MemTable。后台会将Immutable MemTable转储到磁盘。文件采用层级结构。
文件内部包含最大最小主键,清单文件记录了这些元数据,包括属于那个层级,文件名,最小和最大主键。
随着Compaction进行,SSTable会产生新文件,同时旧文件也会失效,因此会形成新的清单文件,而Current文件记录哪个清单文件是有效的。
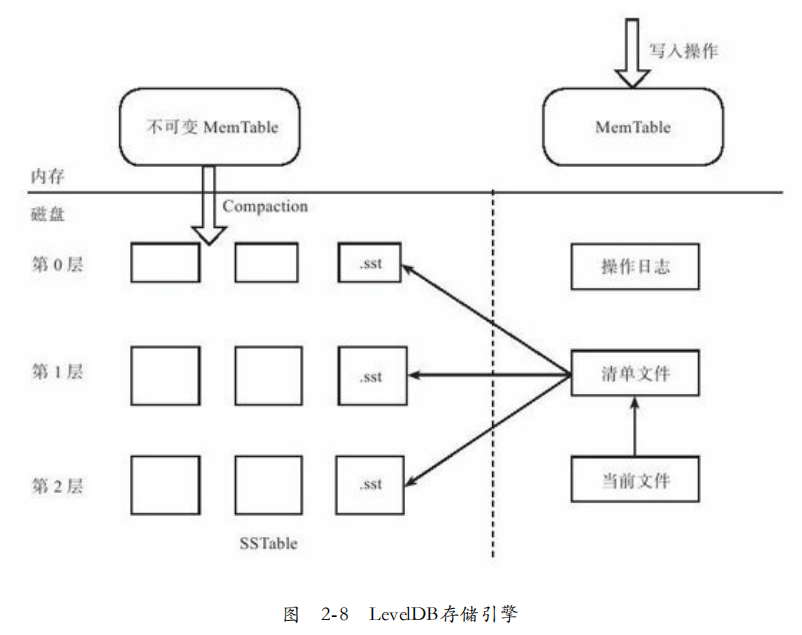
合并:分为Minor和Major。其中Minor指的是内存到磁盘。Major指的是磁盘中文件和下一级文件合并。
数据模型:如果说存储引擎是发动机,那么数据模型就是外壳。
1. 文件模型:文件系统以目录树的形式组织。POSIX则是访问文件系统的API标准。
主要接口如:Open/close、Read/Write、Opendir/closedir、Readdir等
POSIX保证读写并发,同时保证原子性(要么读到所有结果,要么都失败)。POSIX适合单机文件系统,分布式中性能原因不被考虑。
NFS允许客户端缓存文件数据,可能出现两个客户并发修改,导致后提交的覆盖前者。
对象模型类似文件模型,削弱了目录树的概念,要求对象一次写入,只能删除不能修改部分。
2. 关系模型:是一个表格,由多行多列构成。数据库语言SQL用于增、删、改等操作。
SQL如:FROM、WHERE、GROUP BY、HAVING、SELECT、ORDER BY
支持索引和事务,保证ACID特性。
3. 键值模型:大量NoSql系统采用l键值(Key-Value模型),每行包含主键和值。
操作:Put、Get、Delete。
由于Key-Value太过简单,常广泛应用表格模型。如:BigTable和HBase。
操作:Insert、Delete、Update、Get、Scan。
与关系模型区别如不支持多表关联,BigTable这样的还不支持二级索引。
非关系型数据库(NoSql,No Only SQL):有良好的扩展性,弱化数据库设计规范,弱化一致性要求,在一定程度解决海量数据和高并发问题。
关系型数据库的挑战:
1. 事务:需要满足ACID
2. 联表:常常需要满足范式要求。如第三范式一个关系中不能出现其他关系的非主键信息(为了防止冗余)。海量数据中为了防止多表关联,往往违反范式,所带来的收益远高于成本。
3. 性能:如关系型数据库B树存储引擎,更新性能远不如LSM树。只基于主键的增、删、改、查,也远不如专门定制的Key-Value存储系统。
NoSql的问题:
1. 缺少统一标准:关系型数据库已经由SQL这样的标准,Nosql每个不同,很难切换。
2. 使用运维复杂:缺乏专业的运维工具和运维人员。
每个事务使得数据库从一个一致的状态原子的转移到另一个一致的状态。
数据库事务具有原子性、一致性、隔离性、持久性,即ACID。多个事务对于并发执行后的结果和按照某个顺序一个接一个串行执行的结果一致,称为可串行化。
事务并发一般采取锁的机制。对于读高于写,可以采用写时复制(Copy On Write)或者多版本并发控制(MVCC)。
事务:
1. 原子性:对于事务要么全执行要么全不执行。
2. 一致性:要保证数据正确性、完整性、一致性。例如:余额不能是负数等。
3. 隔离性:对于并发执行事务,对某个事务执行完成前,对其他事务是可不见的。不能让其他事务看到中间状态。
4. 持久性:事务完成后,数据库的影响是持久的。
隔离级别:
1. RU:读取未提交的数据,作为最低级别。
2. RC:读取已提交的数据。同一次事务中,可能连续两次读取同一项的数据不同,第一次为另一个事务提交前,第二次为提交后。
3. RR:可重复读。在一次事务中,对同一项读取数据相同。
4. S:可序列化。可串行化,事务执行时如同没有其他事务一样。作为最高级别。
隔离降低可能导致的异常:
1. LU:第一类丢失更新,两个事务同时修改一个数据项,后者回滚可能导致前者丢失。
2. DR:一个事务读取另一个事务未更新的提交项。
3. NRR:一个事务对一个项多次读取不同值。
4. SLU:第二类丢失更新,并发事务同时读取修改数据项,后修改的导致前者修改丢失。
5. PR:事务执行中,有另外事务插入数据,导致出现之前未发现的数据。
如表2-3,看出隔离级别可能引发的异常。

并发控制:
1. 数据库的锁:分为读锁和写锁。同一个元素可以有多个读锁,但只能有一个写锁。写锁将堵塞读事务。元素可以是一行,一个数据块,一个表格。
解决死锁:可以为每个事务加一个超时时间,超时后自动回滚。
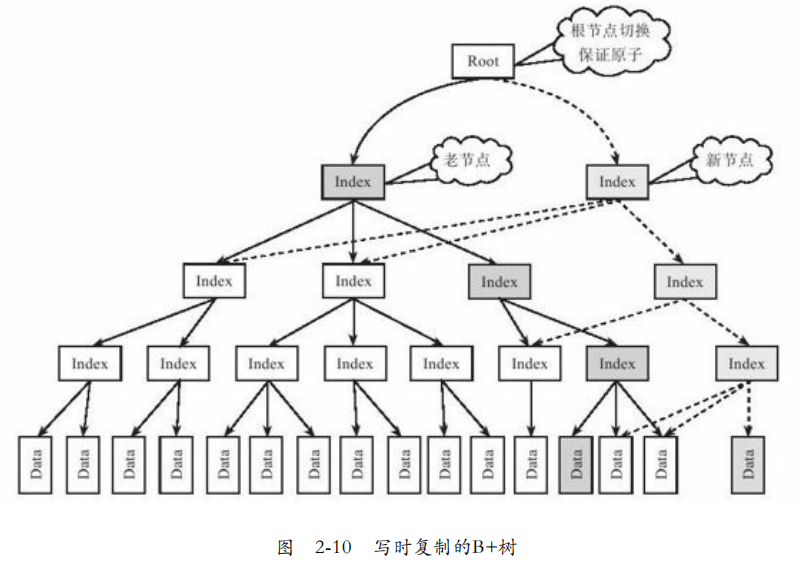
2. 写时复制:互联网业务中,很多应用写:读比例6:1甚至10:1.写时复制,读操作不需要加锁,极大的提高了读性能。
如图2-10,写时复制的B+树。
1. 拷贝:将叶子结点到根节点的所有节点拷贝出来。
2. 修改:对拷贝节点进行修改。
3. 提交:原子的切换根节点的指针,使其指向新的根节点。
3. 多版本并发控制:MVCC也可以让读事务不加锁。为每个事务分配一个递增的版本号。
SELECT:只返回修改的版本号小于该事务号,对于删除的版本号要么没定义要么大于该事务。
INSERT:行的修改版本号更新为该事务的号。
DELETE:将当前删除版本号设置为当前事务号,只是标记删除。
UPDATE:将原来行复制一份,并将当前事务号作为修改的版本号。
故障恢复:一般采用日志,操作日志如:回滚日志UNDO LOG,重做日志 REDO LOG,UNDO/REDO日志。对于记录修改前的日志为回滚日志,修改后的日志为重做日志。
操作日志:
对于初始值X=5,事务T执行X加10操作。
UNDO日志记录:<T, X, 5>
REDO日志记录:<T, X, 15>
UNDO/REDO日志记录:<T, X, 5, 15>
重做日志:
采用重做日志的写流程:
1. REDO日志以追加方式写入磁盘。
2. REDO日志的修改操作应用到内存。
3. 返回操作成功或者失败。
优化手段:
1. 成组提交:如果每个事务都要求日志立即刷入磁盘,系统的吞吐会很差。因此对于一致性要求不高的应用,可以设置不要求立即刷入,先写入缓冲区,定期刷入磁盘。
成组提交需要满足:日志缓冲区超过数据量一定大小,如512KB。距离上次刷入磁盘超过一定时间,如10ms。当满足某个,将数据刷入磁盘。
成组提交需要保证刷入磁盘才返回写成功,因此会牺牲一定写延迟,但提高了系统吞吐。
2. 检查点:如果数据都保存在内存,可能出现:故障时需要回放所有REDO日志,效率低。内存不够,很难缓存所有数据。
因此需要定期将数据转储(Dump)到磁盘,这种技术称为checkpoint(检查点)技术。
检查点流程:
2.1 日志记录“START CKPT”
2.2 数据以某种形式转储到磁盘。
2.3 日志记录END CKPT。
恢复流程: 将checkpoint加载到内存,将START CKPT后的日志回放。
对于 checkpoint中的数据一定不能包括START CKPT和END CKPT之间的数据,因为如Append操作不具有等幂性。
处理办法:checkpoint时停止写操作。checkpoint时做一次快照。
数据压缩:有损压缩,压缩比率高但是可能导致失真,常用于图片,音频等。
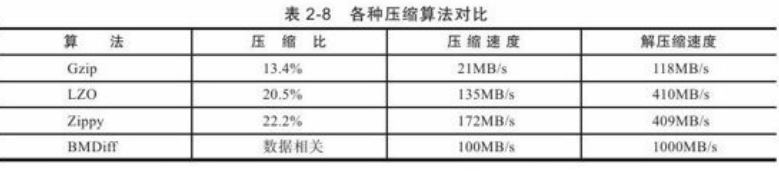
无损压缩,能够完全还原原始数据。当前仅讨论无损压缩,早期压缩以Huffman为代表,之后以LZ系列压缩算法几乎垄断了通用无损压缩领域。
压缩算法核心就是找重复数据。
压缩算法:
1. Huffman基于编码,要求任意字符的编码不能是另一个字符的前缀。(前缀也无法判断当前是否为结尾)
2. LZ系列压缩算法:对于重复的字符串保存第一个字符串的位置和长度即可,因此简化为二元组<匹配串的相对位置,长度>。
对于如何区分源信息还是压缩信息,采用一个bit来区分。如2个字节,1bit区别源和匹配,11位是匹配位置,4位是长度。因此,最大数据窗口为2048,重复串最大长度16字节。
对于匹配最长串可以采用哈希表,也可以只保存长度为3的子串,找到匹配后,再尽力往后匹配。
3. BMDiff与Zippy:在BigTable中发明,也称为Snappy属于LZ系列。压缩比率不高,但是速度较快。
相对LZ77,Zippy只匹配长度大于4的,而且只最后一个长度为4的字串位置。
如ABCDEABCDABCDE 压缩为 ABCDE<0,4><5,4>E而不是 ABCDE<0,4><5,5>
同时内部采用32KB的数据块,每块直接没有关联,只需要15位就可以表示相对位置。同时采用了可变长的表示方法。
Zippy以每b个字符为一个小段,因此长度N的字符串分为N/b大小的哈希表。但是对于b=4时,EABCDABCD变为了EABC, DABC, D因此无法压缩,但是对于重复长度大于2b-1一定可以压缩
列式存储:
传统的行式数据库,将数据按行存储在数据页,由于查询需要大量列,因此比较高效。一般称OLTP适合这种方式。
一个OLAP常查询几十万到几十亿行的数据,而关心的列仅仅几列。
因此列式数据库将同一个列中的数据放到一起。而某行的数据可能放到不同位置。
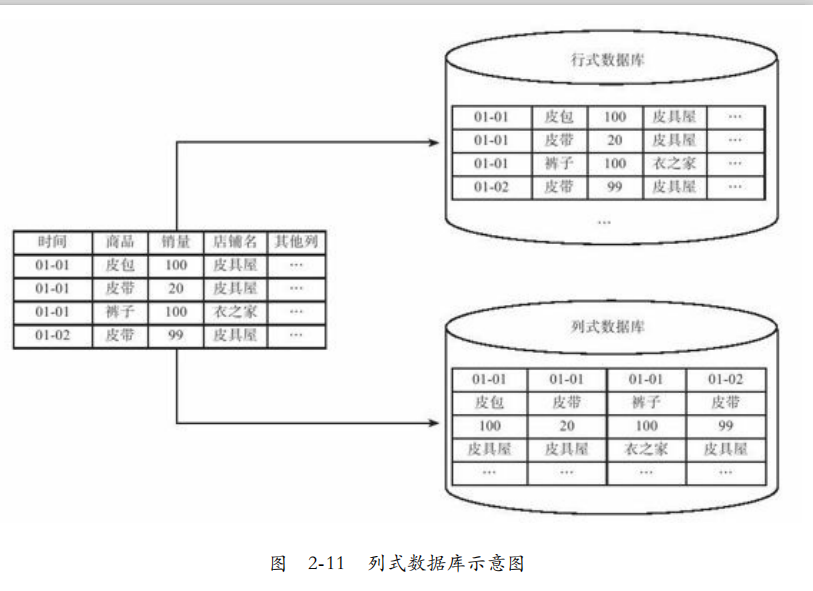
列式数据库常常支持列组,将常一起访问的列放到一起,减少了多个列的合并。
由于同一列的数据重复率很高,因此压缩时具有很大优势。BigTable对网页的压缩率可以达到15倍,对于性别可以采用位图的方式。
第三章 分布式系统
分布式系统理论知识如:数据分布、复制、一致性、容错性等。
其中Paxos用于多节点共识,如选出总控节点。两阶段提交用于保障操作的原子性。
异常:
通常一台服务器或一个进程称为一个节点。然而节点是不可靠的,网络也是不可靠的。
1. 异常类型:服务器宕机,可能是断电等,导致内存数据丢失。因此需要考虑持久化将数据进行恢复到宕机前某个一致的状态。
网络异常,可能出现网络分区,分区内节点通信正常,分区外无法通信。
磁盘故障,可能发生磁盘损坏和磁盘数据错误。磁盘损坏需要考虑数据在多个服务器,磁盘数据错误需要考虑用校验机制。
2. 超时:由于网络存在异常,分布式存储系统的请求分为三态:成功,失败,超时。对于超时很难判断是否执行成功。
一致性:
由于异常的存在,需要将数据冗余多份,每一份称为副本(replica/copy)。当某个节点故障,可以从副本读取数据。
可以从两个角度理解一致性:用户,客户端读写操作是否满足某个特性。存储系统,存储系统的副本之间是否一致,更新顺序是否相同。
存储系统:可以理解为一个黑盒子,为我们提供了可用性和持久性的保证。
客户端A:实现了从存储系统write和read操作。
客户端B和C:ABC互相独立,实现了对存储系统的write和read。
一致性包括:
1. 强一致性:A写入一个值到存储系统,ABC读的值都是最新值。对于写入超时的情况,成功与失败都有可能。
2. 弱一致性:A写入一个值到存储系统,不能保证ABC读到最新值。
3. 最终一致性:作为弱一致性的特例,A写入一个值后,如果不被覆盖,ABC最终一定会读到。
4. 读写一致性:A写入最新值,A可以读到,但BC可能稍后读到。
5. 会话一致性:要求客户端和存储系统在整个会话期间保持读写一致性,如果中途重建会话,不保证和原会话保持一致性。
6. 单调读一致性:如果A读到某个值,一定不会读到更旧的值。
7. 单调写一致性:A的写完成后,多个副本写的顺序保持一致。
副本的一致性包括:
8. 副本一致性:多个副本之间数据是否一致,
9. 更新顺序一致性:多个副本是否按照相同顺序更新。
衡量指标:
1. 性能:每秒处理的读操作数(QPS,Query peer second),写操作数(TPS,Transaction peer second)。相应延迟,通常用99.9%以上的最大延迟。
2. 可用性:往往指可以提供正常服务的能力,如停服的时间比率。往往体现了代码质量与容错能力。
3. 一致性:一般来说,越是强一致性用户用起来越简单。
4. 可扩展性:随着扩展服务的规模来提高容量、计算量、性能的能力。理想的系统可以线性扩展,即性能与数据呈线性关系。
数据分布:对于分布式系统数据需要分布到多个节点,常采用哈希分布,顺序分布。
哈希分布:根据数据某一特征值计算哈希值,将哈希值与服务器建立映射关系。
如果哈希函数的散列性很好,可以很均匀分布到集群中,而元信息也只需要记录哈希函数与机器个数即可。
但是很难找到很好的哈希函数,如果根据主键哈希,会导致同一用户id下,多条记录分散开来,如果根据用户id哈希,会导致数据倾斜,即某些大用户的数据量很大。
处理大用户可以手动标记,或者自动拆分。
传统哈希的另一个问题在于,当服务器上线下线后,N变化,导致数据映射大量被打乱,大量数据发送迁移。
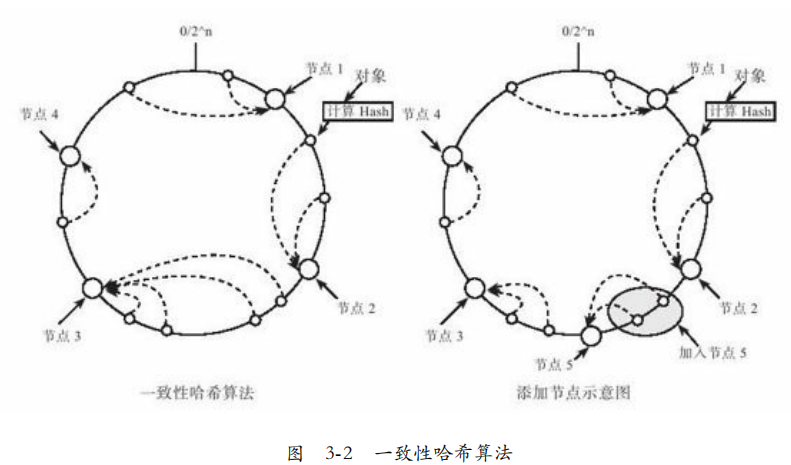
一致性哈希,给每个节点一个token,这些token构成环。在存放key时,按照环找到第一个大于等于该key的token的节点。如图3-2.
可以很大程度减少数据迁移。
对于查询服务器可以选择:1. O(1)位置,O(n)查询。2. O(logn)位置,O(logn)查询。3. O(N)位置,O(1)查询。
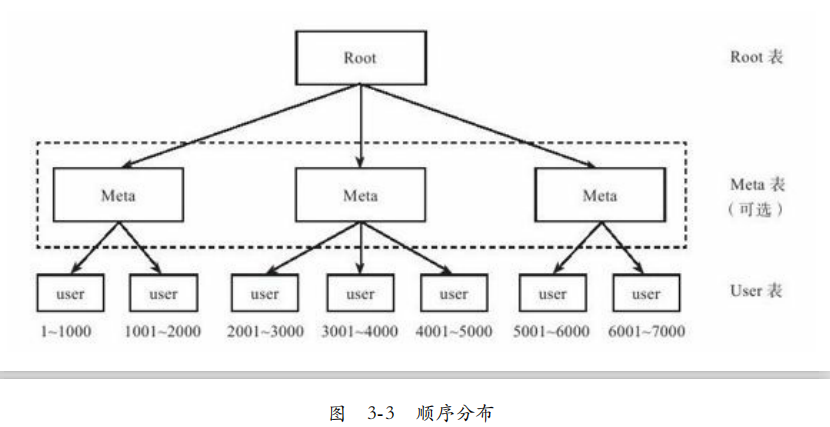
顺序分布:
由于哈希分布破坏了数据的有序性,只能支持随机读取,不能进行顺序扫描。
如BigTable:将索引分为两份,根表和数据表(Meta表),由Meta表维护User表的位置信息,由根表维护Meta表的位置信息。类似B+树,当子表超过阈值,自动分成两份。
负载均衡:
通常集群中有一个总控节点,其他节点为工作节点。总控节点负责全局负载,工作节点要发送自己的负载相关信息(如:CPU,内存,磁盘等)。
当总控节点算出工作节点负载,将需要迁移的数据生成迁移任务,放到迁移队列。对于负责均衡时需要保证对服务没有影响。
如:数据分片D的两个副本D1和D2分别在工作节点A1和A2,其中D1为主副本,提供读写服务。当D1需要迁移出去时。
1. D的分片从A1切换到A2,D2变成主副本。
2. 增加副本,选择节点B,增加D的副本,即从A2读取D2并保持同步。
3. 删除A1上的D1。
复制:
为了保证高可靠和高可用,一般采用多副本的方式,当某个节点故障,可以切换到另一个副本,从而自动容错。
同一份数据常用一个主副本,多个备副本,数据从主副本复制到备用副本。复制分为同步和异步,区别在于是否需要同步到备副本才返回成功。
如图3-4,客户端将请求发给主副本,主副本将请求发送给备副本。如同步操作日志,将日志同步到备副本,各个副本回放日志,完成后通知主副本,主副本修改本机,当所有操作成功,返回客户端成功。
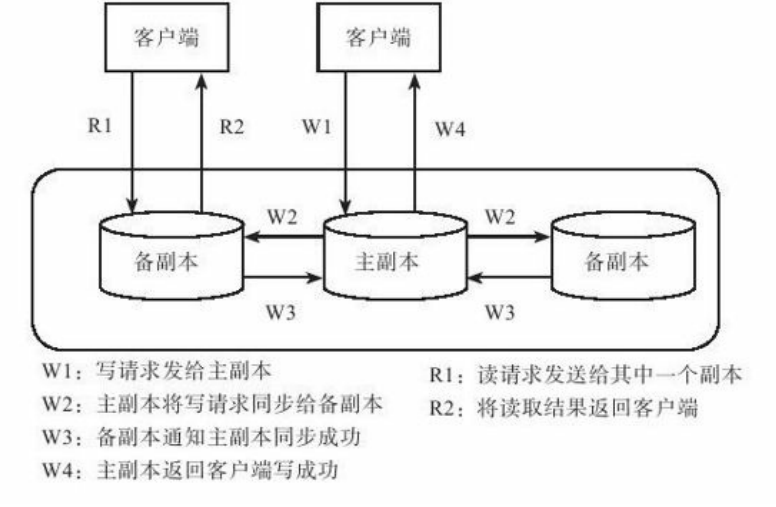
强同步,可以将日志并发的发给所有副本,当一个副本成功时就返回给客户端,这样即使主副本故障,至少一个存在数据。
异步复制,不需要等待副本的回应,只要本地成功,就可以返回客户端写入成功。异步复制好处在于可用性好,但一致性差。
对于主副本故障,需要选举一个新的主副本,可以采用Paxos。
主备之间一般通过日志进行复制,为了提高系统的并发能力,通常会积攒一定的操作日志,批量写入磁盘,也叫成组提交。如果每次故障都重放所有日志,很费事,因此采用checkpoint。
基于主副本的复制协议,还可以采用NWR复制协议,N为副本数,W为至少写入W个副本数,R为最多读取R个副本。W+R>N可以保障,一定可以读取到最新数据。
一致性与可用性:CAP
一致性:读操作总能读到之前写操作的结果,称为强一致性。(“之前”一般对同一客户端而言)
可用性:读写操作,在单机发生故障后,仍能正常执行。
分区可容忍性:机器故障,网络故障,机房停电等异常情况,仍能满足一致性和可用性。
分布式存储系统要求满足自动容错,即分区可容忍性,因此,一致性和写操作的可用性不能同时满足。若采用强同步复制,主副本之间网络故障,会导致写阻塞。若采用异步复制,无法做到强一致性。
因此一般在一致性和可用性之间做权衡:
Oracle数据库的DataGuard复制组件包括三种模式:
1. 最大保护模式:要保证日志至少复制到一个备库,才返回成功。
2. 最大性能模式:即异步模式,只有主库操作成功,就返回。
3. 最大可用模式:上述的折衷。正常情况采用最大保护模式,异常情况采用最大性能模式。
容错:随着集群规模变大,故障发生的概率也越来越大。机器需要能够自动处理。往往使用租约(Lease)的方式。
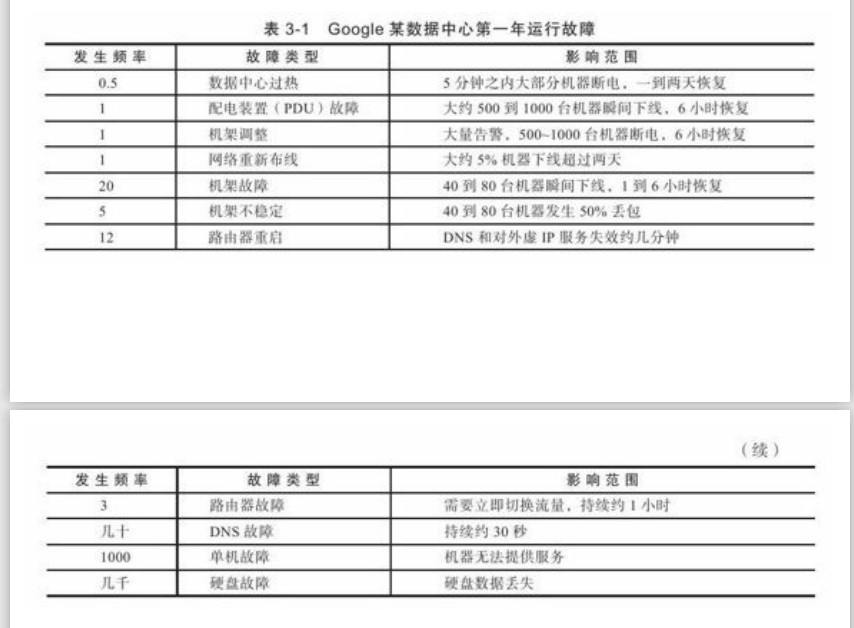
如表3-1,可以看出单机故障和磁盘故障发生率最高,几乎每天都有多起事故。
故障检测:容错处理的第一步就是故障检测,常用心跳的方式。如A向B发送心跳,如果B相应代表正常。如果B不响应,可能是B宕机,也可能是网络发生问题,或者太过繁忙无法响应。
由于B故障后,需要将B上面的服务迁移走,为了确保强一致性,还需要确保B不在继续提供服务,否则出现多台服务器同时服务一份数据。
实践中,我们总是假设A和B的机器时钟相差不大,比如比超过0.5秒,这样可以通过租约(Lease)机制,A给B一个超时时间,只有租约时间内才可以提供服务。
如10秒,这样即使不响应心跳,也可以等11秒后,迁移服务。
故障恢复:当检测到故障后,需要迁移数据。分布式存储系统分为两类:大部分为单层结构,数据维护多个副本。类BigTable为双层结构:数据维护多个副本,服务层只有一个副本提供服务。
单层结构,某个节点故障后,选其他副本提供服务。节点下线后分为两种情况:临时故障,节点将重新上线。永久故障,选择一个新的节点拷贝副本数据。
两层结构:会将数据持久化写入底层的文件系统,每个数据分片同一时刻只有一个提供服务的节点。切换节点后,只需要从分布式文件系统读取数据,加载内存。
总控节点也可能出现故障,为了实现总控的高可用性,可以将总控的状态同步到备机。故障后,选取备机中某个作为新总控节点。选主和维护全局重要信息,可以用Paxos。

可扩展性:如,将增加数据副本,提高读取能力。将数据分片,实现分布式处理。
总控节点:需要维护数据分部信息,数据定位,故障检测和恢复,负载均衡等工作。因此,可能成为瓶颈,影响可扩展性。
分布式文件系统的总控节点除了维护全局调度,还需要文件系统的目录树,因此内存容量会率先成为性能瓶颈。
如GFS,抛弃了小文件的支持,数据的读写权限也下放到ChunkServer,可以支持8000台以上的机器。
要是支持1万台,就需要采用二级架构。总控机和工作机之间增加一层元数据节点。每个元数据节点维护一部分元数据。
数据库扩容:通过垂直拆分和水平拆分将数据分布到多个存储节点。数据库先将不同的表垂直拆分到不同的DB,再通过哈希方式将每张表水平拆分到不同节点。
如果读取能力不够,可以增加副本,如果写入能力不够,可以重新拆分,通常为双倍扩容。
传统数据库扩展性的问题:扩展不够灵活很难做到按需,如增加1台。扩展不够自动化,数据迁移时间较长。增加副本时间长,需要拷贝大量数据。
异构架构:其中同构架构就是组内节点,数据完全相同,拷贝时从一个节点进行拷贝,很费时。
异构架构则是将数据进行分片,故障恢复时,从很多节点同时拷贝,集群越大,优势越明显。
分布式协议:如,租约机制、复制协议、一致性协议,其中两阶段提交和Paxos最具代表。两阶段提交用于保证多个节点操作的原子性,Paxos用于多个节点进行投票(如,选主),来达成一致。
两阶段提交:一类为协调者,通常只有一个。一类为事务参与者,通常有多个。每个节点都会将日志持久化。
阶段1:请求阶段,协调者通知参与者准备提交/取消 事务。参与者需要告知,同意(参与本事务),取消(事务参与者本地执行失败)。
阶段2:提交阶段,基于第一阶段的结果进行决策,提交或者取消。只有所有参与者都同意才会进行提交,否则告知所有参与者,取消该事务。
两阶段提交面临的故障:参与者发生故障,需要为参与者设置超时时间。协调者发生故障,需要备份操作日志到备用协调者。
两阶段提交作为阻塞协议,大部分分布式存储系统都敬而远之。
Paxos协议:用于阶段多个节点之间的一致性问题,通过日志同步数据。如果只有一个主节点很容易确保节点间日志一致性,但主节点出现故障后,需要选取新的主节点。
当主节点发生故障后,备用节点会提议自己成为新的主节点。出现网络分区时,可能出现多个备节点提议(Proposer)自己成为主节点。
对于只有一个proposer,需要发送accept给所有节点,如果超过一半节点同意,意味着提议已经生效。
但可能有多个proposer:
1. 准备,proposer选择一个提议号n给其他节点,节点收到后若提议号大于之前收到的,则将之前接收的提议回复给proposer,并承若不再接收低于该提议号n的提议。
2. 批准,proposer接收到节点回复后,进入批准阶段。选择回复的协议号最大的,否则生成一个新的批准号。
3. 确认,超过一半的节点接收,提议生效。
Paxos与2PC协议:Paxos用于保证,一个数据分片的多个副本之间的数据一致性。2PC用于保证多个分片上的操作的原子性。
Paxos可以用于:实现全局的锁,配置等,如Google Chubby,Apache Zookeeper。另一种用于用户数据复制到多个数据中心,如Google Megstore,Google Spanner。
跨机房部署:
1. 集群整体切换:两个机房保持独立,通过同步/异步方式将数据备份到备用机房。
如果采用异步模式,可能要忍受丢失数据的风险,或者服务等待主机房恢复。异步同步,切换一般是手动切换。
如果采用同步模式,可以用自动切换,当出现故障后,自动切换到备用机房。
2. 单个集群跨机房:上一种方案主副本都在同一机房,该方案则是主副本允许在不同机房。
因此,总控节点需要和所有机房的节点通信,所以尽量将备份分到多个机房,防止因为单个机房故障,而影响服务。
3. Paxos选主副本:前两种主控节点和工作节点需要lease租约机制。当工作节点出现故障,会自动切换节点。
如果采用Paxos协议选主副本,每个数据的多个分片构成一个副本组,当出现故障时,其他副本将尝试切换为主副本,Paxos保证只有一个副本会成功。
可以降低对总控节点的依赖。
第四章 分布式文件系统
分布式文件系统:主要功能为:存储文档、图像、视频之类的Blob类型数据。作为分布式表格系统的持久化层。
最著名的为GFS,除此之外还有TFS,Facebook Haystack。
Google 文件系统:构建在廉价的服务器上,将服务器故障视为正常现象,通过软件的方式容错。保障系统可靠性和可用性同时,降低了成本。
GFS是Google分布式存储的基石,其他存储系统,如 Google BigTable、Google Megstore、Google Percolator、均直接或间接构建在GFS上。MapReduce用GFS作为数据的输入输出。
系统架构:如图4-1所示,分为GFS Master(主控服务器),GFS ChunkServer(CS,数据块服务器)以及GFS客户端。
GFS文件被划分为固定大小的数据块Chunk,由主服务器分配一个64位全局唯一·的chunk句柄。CS以普通的Linux文件的形式将chunk存储在磁盘。为了可靠性,需要复制多份,默认3份。
主服务器维护了元数据,包括:文件和chunk的命名空间、文件到chunk之间的映射、chunk的位置信息。同时负责全局控制,如:chunk租约、垃圾回收无用chunk、chunk复制等。
主控服务器会定期与CS通过心跳交换信息。
客户端是GFS提供给应用程序的访问接口,不遵循POSIX规范。GFS客户端不缓存文件数据,只缓存从主控服务器获取的元数据。
关键问题:
1. 租约机制:GFS数据以追加的方式写入,每个记录几十KB到几MB不等。GFS通过租约机制将chunk的写操作授权给chunkserver。租约授权针对单个chunk,该chunk的写操作由主chunkserver负责。
GFS为chunk都设定了版本号,在租约更新时更新。为了防止某台服务器因为下线,导致该副本版本号太低。对于版本号太低可标记为删除,垃圾回收时进行回收。
2. 一致性模型:GFS为了追加而不是改写而设计的。一方面是改写需要少,而且可以通过追加来实现。另一方面追加写的一致性模型更简单。
如果不考虑异常,追加成功的记录在各个副本是确定,并严格一直的。如果考虑异常,追加失败将会重试,对于重复记录应用层会进行处理。
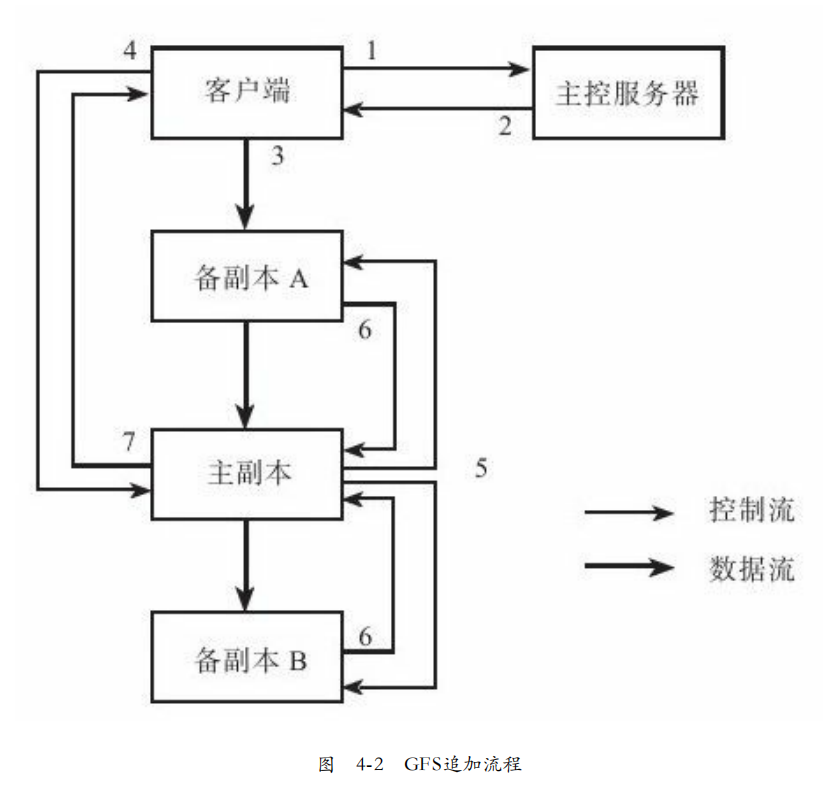
3. 追加流程:如图4-2,高效的追加,对实现BigTable至关重要。
3.1 客户端向Master请求chunk的副本所在chunkserver。如果没有cs持有租约,则master发起任务,将chunk租约发给某个cs。
3.2 Master返回主备副本Chunkserver的位置信息。客户端将进行缓存,不出现故障,之后都不需要请求master。
3.3 客户端追加的记录发给每一个副本,每个CS在内部LRU结构缓存数据。
3.4 当所有副本都确认数据后,客户端会发送写请求给主副本。主副本可能收到多个客户端对同一个chunk的并发追加操作,主副本需要确认顺序写入本地。
3.5 主副本将写提交发送给备副本,备副本根据主副本确认的顺序执行。
3.6 备副本成功完成后答应主副本。
3.7 如果主副本成功,备副本失败,客户端将重试。
4. 容错机制:Master容错,通过日志和checkpoint方式,并有一台Shadow Master作为实时热备。主要保存:命名空间、文件到chunk的映射、chunk副本的位置信息。
Master总是先写日志,再改内存,同时实时热备,修改操作到备份后才算成功。chunkserver位置不需要持久化,在cs汇报时获取。
ChunkServer容错,采用多副本实现容错,每个chunk存在不同chunkserver,必须副本都写入,才算写成功。同时采用校验和的方式检测。
Master设计:
1. 内存占用:Master维护了系统的元数据,其中文件及 chunk命名空间,文件到chunk的映射需要持久化,chunk的位置信息可通过chunk汇报。
Master的内存中,chunk的原信息包括全局唯一的ID、版本号、每个副本所在的chunkserver、引用计数等。
GFS中每个chunk64KB,每个chunk元数据小于64字节,那么1PB有效数据需要chunk元信息不超过1PB * 3 / 64MB * 64B = 3GB。
对于命名空间,Master进行了压缩,压缩后文件命名空间的元数据也不超过64字节。
2. 负载均衡:当创建一个chunk,会根据以下因素来选择副本的位置信息:新副本所在的CS的磁盘利用率低于平均水平。限制CS最近创建的数量。CS的副本不能在同一个机架。
重新创建chunk副本的原因:CS宕机、CS报告自己副本损坏、CS某个磁盘损坏、用户增加副本数量,等等。
创建chunk副本会用优先级,对于不同情况优先级不同。
3. 垃圾回收:GFS采用延迟删除的机制,对于删除的文件,会改成一个隐藏的名字,并设置删除时间戳。对于超过一定时间,会将其从元数据中删除,之后的chunkserver心跳中,告知以及不需要该chunk。
这时,chunkserver可以释放副本,减轻负担。
4. 快照:对源文件/目录进行一个快照操作。快照会增加该chunk的引用次数,当用户要写入数据时,会重新生成新chunk,并将操作落到新的chunk上。
对某个文件进行快照:通过租约机制,回收客户的写权限。Master拷贝文件名等元数据生成快照文件。对执行快照的文件所有chunk增加引用计数。
ChunkServer设计:
CS管理大小约为64MB的chunk,需要尽量保证chunk均匀分布到不同磁盘。CS作为一个磁盘和网络IO密集型应用,为了最大性能,需要尽量将磁盘和网络操作异步化。
Taobao File System
对于文档、图片、视频一般称为Blob数据,Blob数据一般比较大,而且相互之间没有关联。2007年淘宝数据量大增后,开始研发Blob存储系统Taobao File System (TFS)。
TFS考虑两个问题:
1. Metadata信息存储。由于图片量巨大,单机存不下元数据,如:每个图片元数据100B,100亿张就需要10G*0.1KB=1TB。
2. 减少图片的IO:对于Linux文件系统读取一个文件需要三次IO:首先读取目录元数据到内存,其次将inode节点装载到内存,最后读取文件内容。
由于小文件太多,无法将所有inode信息缓存到内存。
因此 TFS考虑将多个逻辑图片文件共享一个物理文件。
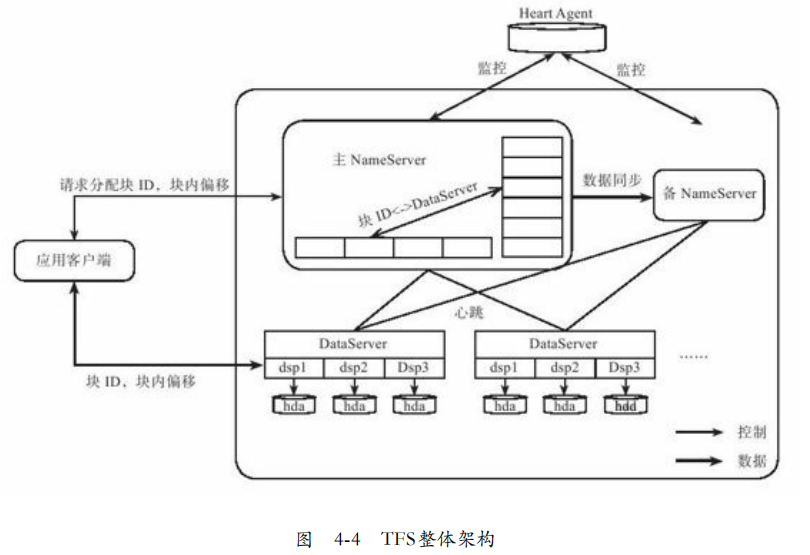
TFS系统架构:TFS集群由两个NamServer(一主一备)和多个DataServer构成。当主NameServer出现故障,会被心跳守护进行检测,切换到备NameServer。
每个DataServer上运行多个dsp进程,一个进程对应一个挂载点,一般是一个独立磁盘。
TFS中将大量小文件(实际数据文件)合并成一个大文件(Block),每个Block拥有唯一的编号(块ID),通过<块ID,块内偏移>可以确定唯一一个文件。
TFS中Block数据存储在DataServer中,一般大小64KB,存储三份。
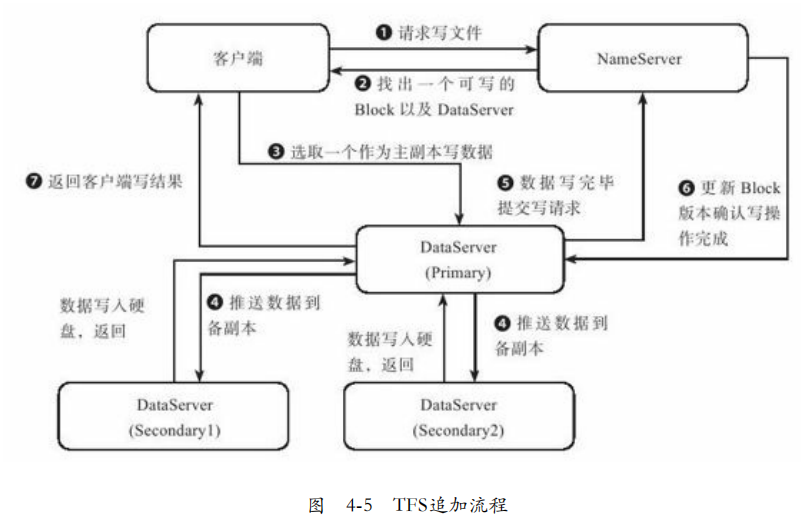
1. 追加流程:TFS作为少写多读应用,每次写操作都经过NameServer也不会有太大问题。同时每一时刻每个Block只能有一个写操作,多个客户端的写会被串行化。
客户端向NameServer发起写请求,需要根据DataServer上可写块、容量和负载选择一个Block,并在该block的多个DataServer中选出一个主。客户端会向主副本写入数据。
当都写入成功,会通知Master更新Block版本号,成功后返回客户端成功。
2. NameServer:NameServer功能有Block管理,包括创建、删除、复制、重新均衡。DataServer管理,包括心跳、DataServer加入退出。Block与DataServer映射。
FaceBook Haystack
目前存储了2600亿张照片,大小20PB,平均每张照片80KB。
系统架构:包含目录,存储,缓存。存储作为物理节点,以卷轴的方式组织,每个卷轴很大如100G,10TB也只需要100个物理卷轴。因此元数据比较小。
缓存用于解决对CDN过度依赖的问题。

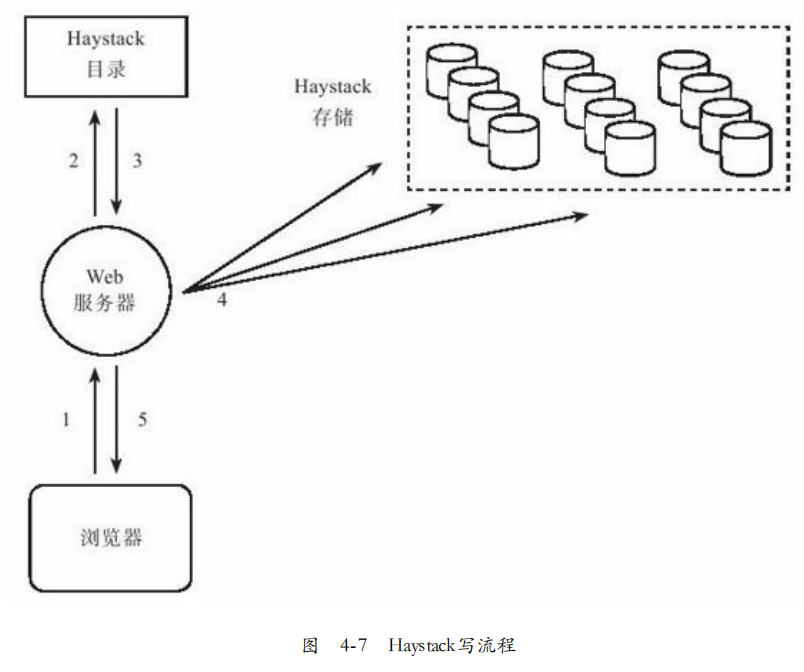
写流程:Web服务器先请求Heystack目录获取可写的逻辑卷轴, 生成照片唯一的id并将数据写入卷轴(备份一般为3)。当所有备份成功,操作成功。
Heystack一致性模型,保证写成功则逻辑卷对应的物理卷都会有有效的照片文件,但不同物理卷的偏移可能不同。
Heystack只支持追加操作,对于更新照片,会增加编号相同的照片到系统,元数据会更新为最新的逻辑卷轴,相同卷轴下,偏移大的为最新的。
容错管理:若检测到存储节点故障,所有物理卷对应的逻辑卷标记为只读,未完成的写操作全部失败。如果节点不可恢复,需要从其他副本节点拷贝数据。
Heystack目录用主备数据库做持久化存储,保障了目录的容错。
Heystack目录:提供逻辑卷到物理卷的映射,维护照片id到逻辑卷的映射。提供负载均衡,为写操作选择逻辑卷,读操作选择物理卷。
屏蔽CDN服务,某些照片直接走Heystack缓存。标记某些逻辑卷为只读。
Heystack存储:每个物理卷对应文件系统的一个物理文件。多个照片存放到一个物理卷轴,每个照片是一个Needle,包括实际数据和逻辑照片文件的元数据。
节点宕机后,需要恢复内存中的逻辑照片查找表,扫描整个卷轴时间太长,因此每个物理卷维护了一个索引文件,保存了元数据。
内容分发网络:CDN将网络内容发布到靠近用户的边缘节点,使得不同地方用户在访问页面时可以就近获取。改善网络性能。边缘节点是CDN服务商挑选出离用户最近的服务器节点。不需经过多个路由。
如图4-9,智能CDN选择了边缘节点的IP。
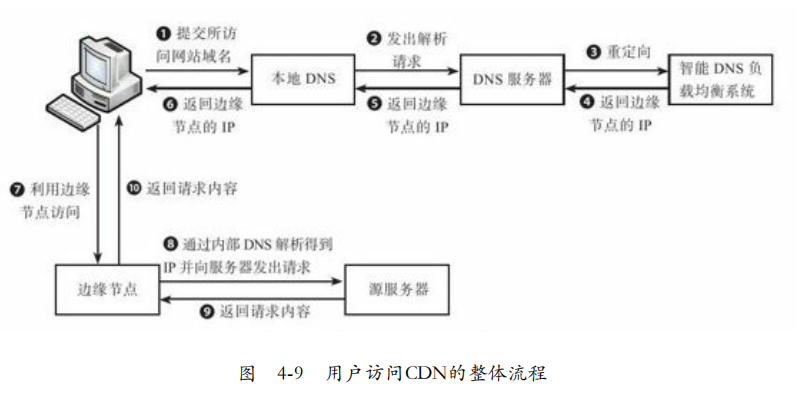
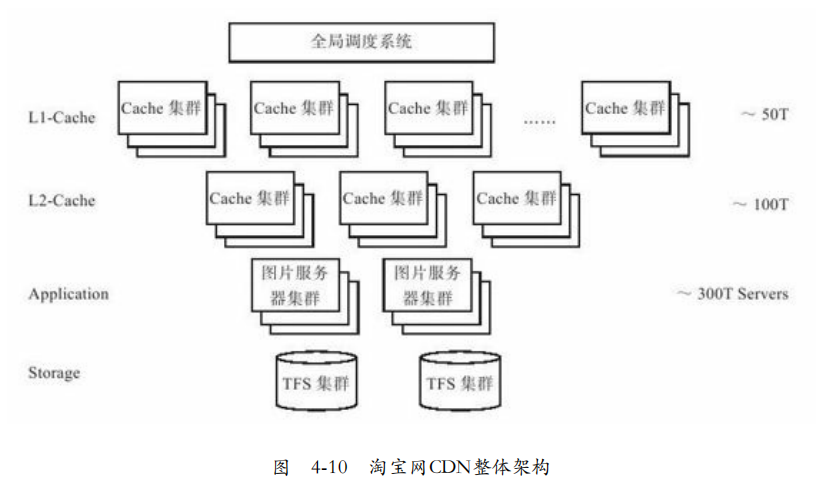
CDN架构:淘宝CDN用于支持用户购物,图片存储在后台的TFS集群,CDN系统将照片缓存到离用户最近的边缘节点。
CDN采用两层Cache,用户通过全局调度系统,调度到Cache L1节点,如果L1命中,直接返回数据到用户。否则请求L2,如果找到返回给L1,否则请求图片服务器,如果还不命中请求TFS。
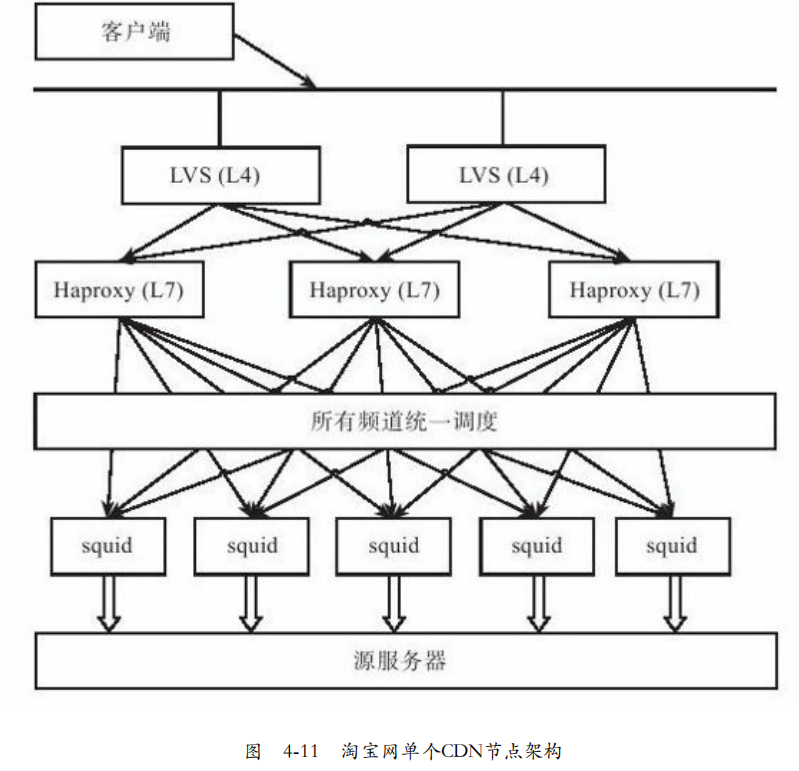
如图4-11,对于每个CDN节点,通过LVS+Haproxy方式进行负载均衡。LVS是四层负载均衡软件,Haproxy是7层负载均衡。可以将请求调度到不同Squid服务器。
分级存储是淘宝CDN的优势,由于数据局部性原理,随着热点迁移,最新的数据存储到SSD,中毒热点存储SAS,其次是SATA
低功耗作为另一个优势,CDN作为IO密集型而不是CPU密集型,因此采用定制的CPU低功耗服务器,降低了整体功耗。
第五章 分布式键值系统
分布式键值模型可以看成是分布式表格模型的一种特例。但只支持key-value的增、删、改、查操作。
Amazon Dynamo是分布式键值系统,Tair是淘宝开发的分布式键值系统,借鉴了Dynamo的思路,区别在于从P2P架构改完了有中间节点的架构。
Amazon Dynamo:
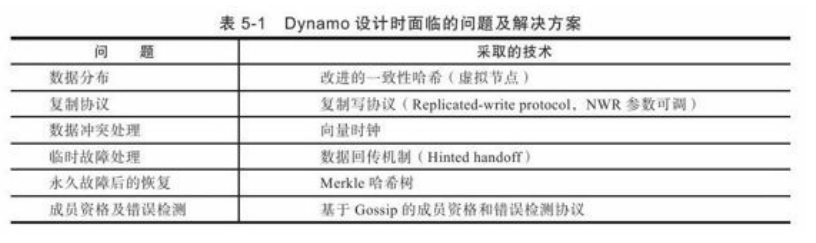
数据分布:采用一致性哈希算法,将数据分布到多个存储节点。一致性哈希算法:给系统中每个节点分配一个随机token,这些token构成一个哈希环。
插入数据时,根据主键算法唯一哈希值,找到第一个大于该哈希值的token节点,插入该数据。
考虑到不同节点性能有区别,可以根据节点的性能,差异分配多个token。每个token对应一个虚拟节点,虚拟节点拥有基本相同的处理能力。
为了找到数据所属节点,需要每个节点都保维护一定的集群信息用于定位。Dynamo系统每个节点维护了整个集群信息,客户端也进行了缓存,因此一般可以一步到位。
对于机器的加入和删除,为了保障每个节点都缓存最新的集群信息,需要定时(如:1秒)通过Gossip协议和任意节点通信,连接成功后交换信息。
Gossip协议用于P2P系统中节点自动协调对整个集群的认识,如:节点状态,负载情况等。
1. A告诉B自己管理的所有节点的版本。(管理应该就是掌握的意思)
2. B告诉A哪些版本,B自己的比较旧,哪些版本B有新的,然后将B有新的的节点发给A。
3. A将B中比较旧的发给B,同时接受B发来的信息做更新。
4. B收到A发来的消息,进行更新。
如有种子节点(应该就是总控),新节点加入可以与种子节点交换集群信息。DHT(一致性哈希表)环中其他节点也会定期与种子节点交换信息。
一致性与复制:为了处理节点失效(DHT环删除节点),需要对节点数据进行复制。
假设数据存储N份,DHT定位的数所属节点K,数据存储在K+i上(0<=i<N)。若其中一台K+i宕机,则需K+N进行替代。若K+i恢复,则需要K+N将数据归还,也叫回传。
K+i宕机时,所有读写落到[K,K+i) 和(K+i,K+N],如果K+i永久失效,机器K+N需要同步操作。一般判定失效时间不会太长,可以用Merkle树进行同步。
NWR是Dynamo的亮点,N是备份数,R是最少读取的节点数,W是最少写成功节点数。只要W+R>N,就可以保障一定能读到最新数据。
NWR看似完美,但但同一个节点无法保证多个节点顺序更新,因此引用了向量时钟来解决冲突。
采用[nodes, counter],其中nodes则是节点,counter是一个计数器,初始值为0。对Sx对某个对象操作时,产生新版本D1,D2。Sy和Sz同时对对应写操作,产生了两个版本。
最常见的解决办法,就是逻辑端选择时间戳最新的副本。但这需要集群内节点之间的时钟同步。
因此N+W>R只能保证读取时获得更新版本,但可能需要进行合并冲突。Dynamo只能保证最终一致性。如果多个节点更新顺序不同,可能客户端读不到期望的结果。

容错:Dynamo将异常分为临时异常(硬盘报修,机器报废),永久性异常(持续时间太长的临时异常)
数据回传,对于发生异常后在指定时间恢复并能提供服务,则需要将暂存的数据回传给机器。
Merkle树同步,如果超过时间T还异常,则作为永久性异常,需要借助Merkle树同步其他副本数据。
Merkle则是每个叶子节点对应一个文件的哈希值,非叶子结点则是所有叶子节点的哈希值。对于不匹配的文件,导致该叶子结点到根节点都不匹配,只需要同步不匹配的文件即可。
读取修复,对N=3,W=2,R=2,如果K宕机。三副本数据都不同,客户端读取时发现某些副本版本太老,则启动异步读取修复任务,结合多个副本的数据,使用结果更新副本,使副本数据一致。
负载均衡:Dynamo的负载均衡取决于给机器分配的token。分配token的方式:
随机分配,每台机器根据配置随机分配S个token,因为自然界数据大致随机,分配比较均衡。
但对于节点的加入与删除,每个节点都需要扫描所有节点更新数据归属节点。Merkle树也需要更新。增量归档/备份几乎不可能。
数据范围等分+随机分配。首先将哈希空间等分成Q=N*S份。每节点选S份作为token。这样每个节点都可以对每个范围维护一个逻辑的Merkle树,更新也只是这部分。
读写流程:写入:首先获取副本节点,发往所有副本,当有W个成功,返回成功。
读取:向至少R个副本读取,若返回结果不一致,合并多个副本的结果。


单机实现:Dynamo存储节点需要实现:请求协调,成员和故障检测,存储引擎。
Dynamo支持可插拔的存储引擎,如Berkerly DB(BDB),MySql Innodb等。用户可以选择存储引擎。
Dynamo设计无中心P2P设计,增加了扩展性,但带来了一致性问题。由于只保证了最基本的最终一致性,客户端很难预测操作结果。
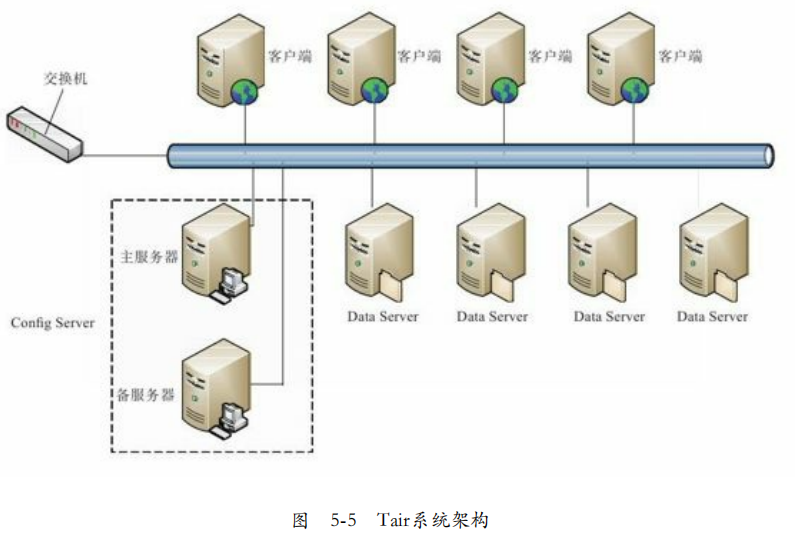
淘宝Tair:作为分布式键值存储引擎,分为持久化和非持久化。
由一个主控节点Config Server,和若干服务街店Data Server构成。Config Server负责管理Data Server,维护状态。Config Server作为控制点,采用一主一备的来保证可靠性。
关键问题:
1. 数据分布:根据主键计算哈希值后,分布到Q个桶。桶是负载均衡和数据迁移的基本单位,Config Server将桶分布到Data Server,Q需要远大于集群机器数。
2. 容错:当某台Data Server不可用,Config Server能够检测到。对于每个桶,由于有多个副本,如果本个是主副本,需要将其他副本中的一个设置为主副本,其次将再重新指定Data Server存储副本。
3. 数据迁移:机器加入或者负载不均衡会导致桶的迁移,对于迁移完成的请求转发到新机器,未完成的会执行,并发修改日志发送过去。
4. Config Server:客户端缓存路由表,大多数情况不需要访问Config Server,宕机也不影响客户端访问。Config Server每次会把新的配置信息发给Data Server。
客户端访问Data Server时,若被Data Server发现版本号太旧,则被告知去Config Server重新获取新的路由表。
5. Data Server:负责数据存储,可以方便添加存储引擎。
第六章 分布式表格系统
对外提供表格模型,每个表格多行构成,通过主键唯一标识,每行有多列。整个表格在系统有序存储。
Google BigTable作为分布式表格的鼻祖,采用双层结构,底层采用GFS。BigTable对外接口不够丰富,后续发开了Megastore构建在BigTable之上,Spanner支持多数据中心的数据事务。
BigTable:基于GFS和Chubby开发的分布式表格系统。支持海量结构化和半结构化数据。通过软件提供自动容错和线性可扩展能力。
内部有很多表格,每个表格很多行,每行通过主键(Row Key)唯一标识,每行很多列(Column)。每一行的某一列构成一个单元,每个单元有多个版本的数据。
内部将多个列组织称列族,列族作为访问的基本单位,需要预先定义个数有限。但列族内有哪些不需要预先定义可以任意多,适合表示半结构化数据。
行主键可以是任意字符串,最大不超过64KB。内部按照行主键排序。
架构:构建在GFS上,为文件系统增加一层分布式索引层。BigTable依赖Chubby进行服务器选举以及全局信息维护。
BigTable将大表划分为100~200M的子表,每个子表对应一个连续的数据范围。BigTable主要由:客户端程序库,主控服务器,多个子表服务器构成。

1. 客户端程序库(Client):提供BigTable程序的接口,通过客户端程序库对表进行增删改查。客户端通过Chubby锁服务获取控制信息。
2. 主控服务器(Master):管理子表服务器,包括分配子表给子表服务器,指导子表服务器进行子表的合并,接收子表分裂信息,监控子表服务器并进行负载均衡。
3. 子表服务器(Tablet Server):实现子表的装载/卸载,表格内容的读和写,子表的合并和分裂。
BigTable依赖Chubby锁服务实现:
1. 选取并保证同一时间只有一个主控服务器。
2. 存储BigTable系统引导信息。
3. 配合主控服务器发现子表服务器加入和下线。
4. 获取BigTable表格的schema信息以及访问控制信息。
Chubby作为分布式锁服务,底层的核心算法为Paxos。Chubby中一半节点不挂就能提供正常服务,一般采用两地三数据中心五副本。同城的两个数据中心分别部署两个副本,异地的一个数据中心部署一个。
BigTable的三种类型表格:用户表(User table)、元数据表(Meta Table)、根表(Root Table)。
用户表用于存储实际数据,元数据表存储用户表的元数据(子表位置,SST和日志文件编号,日志回放点)。
根表用来存储元数据表的元数据。
根表的元数据也就是根表的位置信息,又称为BigTable的引导信息,存放在Cubby中。
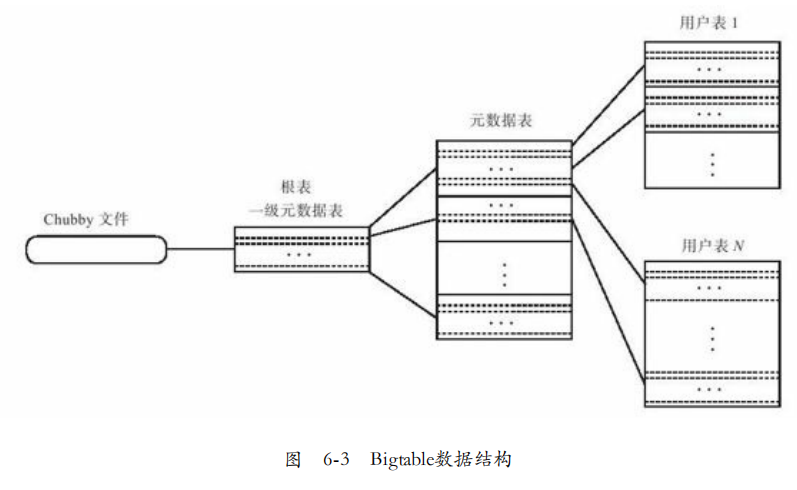
数据分布:BigTable中的数据在系统中切分为大小100~200M的子表,数据按照主键全局排序。内部包含两级元数据,元数据表和根表。子表分裂需要修改元数据表,元数据表的某些操作需要修改根表。
通过两级元数据,提高了系统支持的数据量,假如一个表128MB,每个子表的元数据1KB。那么一级元数据就能提供128MB * (128MB / 1KB)=16TB,两级能支持2048PB。
客户端查询,首先从Cubby读取根表位置,从根表获取元数据表位置,查询用户子表位置。为了减少访问开销,客户端使用缓存和预取技术。
复制与一致性:BigTable为了保证一致性,任一时刻,同一个子表只能被一个Tablet Server服务。通过Chubby互斥机制保证。
虽然GFS是弱一致性(每个数据可能存在重复),但是BigTable主要分为:操作日志,用于回放,内部有唯一序列号。SSTable数据,每次索引只需要最后一条。
容错:Master的监控是通过Chubby完成,Tablet Server初始化时会在Chubby获取独占锁,此时所有信息保存在Chubby中一个称为服务器目录的特殊目录中。
Mater会定期访问Tablet Server锁的状态,如果Tablet的锁丢失或者没有回应,可能是Chubby故障,或者Tablet故障。
之后去Chubby获取该锁,若失败说明Chubby故障,否则Tablet故障,并将其上的表移到其他Tablet上。
子表的持久化包括操作日志和SSTable,因为内存数据丢失需要回放操作日志,但为了提高性能没有为每一个子表准备一个操作日志,而是将其混在一起写入GFS。但同一子表日志连续存储。
负载均衡:子表是BigTable负载均衡的基本单位。Tablet Server会定期向Master汇报状态,当负载过重需要进行迁移。
迁移时,首先将原Tablet子表卸载,解除互斥锁后,新的子表获取互斥锁。子表迁移前会进行Minor Compaction,将内存数据转移到SStable文件,转储到GFS。
子表迁移时,需要有短暂的暂停服务,为了减少暂停时间,需要两次Minor Compaction。
1. 进行Minor Compaction,不暂停写服务。2. 暂停写服务,进行Minor Compaction(由于第一步比较快,所以本次数据较少会更快)
分裂与合并:随着数据不断写入,某些表变大,某些表变小,需要进行合并与分裂。顺序分布与哈希分布的区别在于,顺序分布是动态的需要进行分裂与合并。
BigTable每个子表的数据分为内存MemTable和GFS中的SST,由于一个子表之被一台Tablet Server服务,分裂时只需要将索引分成两份,即两个MemTable,生成不同范围SSTable。
分裂操作由Tablet发起,需要修改元数据表(若元数据表也分裂,需要修改根表)。分裂相当于元数据表增加一行,通过事务保障原子性,只要修改成功,分裂就算成功。
合并操作由Master发起,由于子表可能在不同Tablet Server上,第一步需要转移到同一个Tablet Server,接着进行合并。
单机存储:采用Merge-Dump方式。数据先写入日志,成功后应用到内存MemTable,写日志是顺序写的很好的利用了磁盘设备的特性。当内存到达一定大小,需要转储为SSTable文件。
由于数据可能存在与MemTable与多个SSTable,读取需要按照时间从旧到新进行合并数据。为了防止SSTable文件过多,可以定期进行合并。
BigTable分为三种Compaction:Minor,防止内存占用过多。Major,会合并所有SSTable文件和内存MemTable。Merging,生成的SSTable文件可能包含(删除、增加)操作。
数据按主键有序存储,每个SSTable由若干大小相近的数据块组成。缓存包括块缓存(Block)和行缓存(一行数据)。内部还支持布隆过滤器。
垃圾回收:Compaction生成新的SSTable后,原有的SSTable需要进行垃圾回收。必须避免删除刚生成还没写入元数据的SSTable文件。
GFS+BigTable:以优雅的方式结合了强一致性和可用性。
GFS作为弱一致性,可用性和性能很好。上层BigTable则通过多级分布式索引,对外体现为强一致性。同时支持线性扩展。
BigTable面临的问题:单副本服务,SSD的使用,架构的复杂性导致Bug定位复杂。
Google Megastore:BigTable将可扩展性做到了极致,Megastore则是在BigTable上提供了友好的数据库支持,增强易用性。Megastore是介于传统关系型数据库和NoSQL之间。
互联网数据往往可以通过用户拆分,同一用户需要保持强一致性,不同用户只需最终一致性,因此可以根据用户,将数据拆分到不同机器。
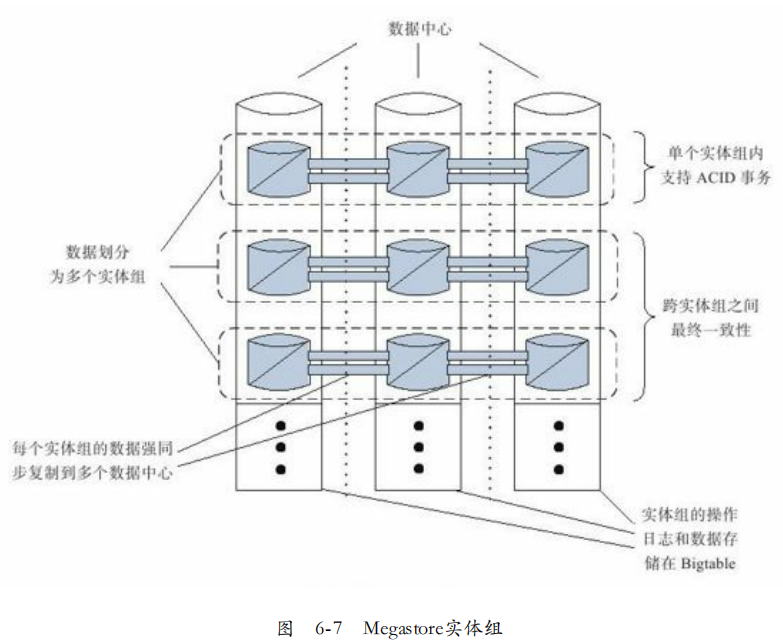
对于同一用户的所有数据构成一个实体组,而不同表分为 实体组根表,实体组子表。根实体表的一行数据为跟实体,除了存放用户数据,还需要存放Megastore事务/复制的元数据。
BigTable通过单行事务保障实体操作的原子性,即同一实体的元数据操作是原子的。由于同一实体组数据在BigTable连续存放,因此同一用户通常在BigTable同一子表下。
系统架构:
1. 客户端:提供应用程序接口,Megastore大部分功能集中在客户端,包括映射操作到BigTable,事务及并发控制,基于Paxos的复制,请求发给复制服务器,通过协调者实现快速读等。
2. 复制服务器:接收请求并转发到所在机房的BigTable实例,用于解决跨机房连接数过多的问题。
3. 协调者:存储每个机房的实体组是否为最新状态的信息,用于实现快速读。

实体组:总体上,数据拆分到不同实体组,每个实体组内操作日志基于Paxos的方式同步到多个机房,保证强一致性。实体组之间通过分布式队列的方式保证最终一致性或者两阶段提交实现分布式事务。
单集群实体组内部,同一个实体组满足ACID特性,通过REDO日志实现。
但集群实体组之间,通过分布式队列的方式提供最终一致性。如果需要多实体组的强一致性,需要实现分布式事务,通过两阶段提交加锁协调。

并发控制:
1. 读事务:分为:最新读取,快照读取,非一致性读取。
最新读取和快照读取是在单一实体组内。最新读取前需要保证提交的写操作生效。快照读取,取出已知最后一个完整提交的版本并读取该版本数据。不会读到未提交的事务。
非一致性读取忽略日志状态,直接读取最新值,可能读到不完整的事务。
2. 写事务:采用了预写日志的方式,只有日志记录后,才会对数据修改。
写事务总开始于最新读取,以便于确认一个可用的日志位置,将日志操作聚集到日志缓冲区,分配一个更高的时间戳,通过Paxos提交到下一个日志位置。
Paxos提供了乐观锁的机制,尽管有多个写操作尝试写一个日志,但只有一个能成功,其他失败会中止并重试。
写流程如下:
2.1 读取,获取最后一次提交的事务的时间戳和日志位置。
2.2 应用逻辑,将写操作聚集到日志缓冲区。
2.3 提交,将操作日志追加到多个机房,通过Paxos保证一致。
2.4 生效,应用操作日志,更新实体和索引。
2.5 清理,删除垃圾数据。
如两个事务对同一个实体组进行并发执行,只会保证一个成功,另一个只能重试。对同一个实体组的进行了串行化,由于同一实体组同时更新很少,所以事务冲突导致重试概率很低。
复制:多个集群之间日志同步,采用基于Paxos的复制机制。对于Master-Slave采用强同步机制,Master宕机后Slave需要如果要切换为Master需要先确认宕机,检测时需要停止写服务,保证数据一致性。
基于Paxos的复制机制,就是为了解决只是怀疑Master宕机时,Slave发起修改操作。
索引:局部索引,单个实体组内,用于加速单个实体组内部查找。映射到BigTable相当于增加了一些行
全局索引,横跨多个实体组。映射到BigTable相当于一张索引表。
STORING字句,该字段可以冗余一些常用的列字段,从而不需要查询基本表,减少一次查询操作。
可重复索引,由于某些字段可重复,因此一张数据可能对应多行索引。
协调者:快速读,Paxos协议要求读取至少一半以上的副本,但如果不出现故障基本每个副本都是最新的,因此为每个机房每个实体组引入协调者,记录该实体组数据是否最新。
如果最新,则只需要读取本地数据。当实体组有更新操作时,需要将协调者记录更改为无效状态,如果某个机房写入失败,需要将协调者状态失效后才返回客户端。
协调者的可用性,每次写入操作都涉及协调者,因此需要检测协调者是否因网络或主机故障不可用。
Megastore采用Chubby锁服务,启动时获取Chubby锁。一旦出现问题锁失效,就会恢复到一个默认的保守状态,认为任何实体组都是失效的。写操作可以将其忽略。
然而,从不可用到失效状态有一个短暂的(几十秒)的Chubby锁过期时间,此时写都会失败。
竞争条件,协调者从启动到退出为一个周期,每个周期有唯一序列号。
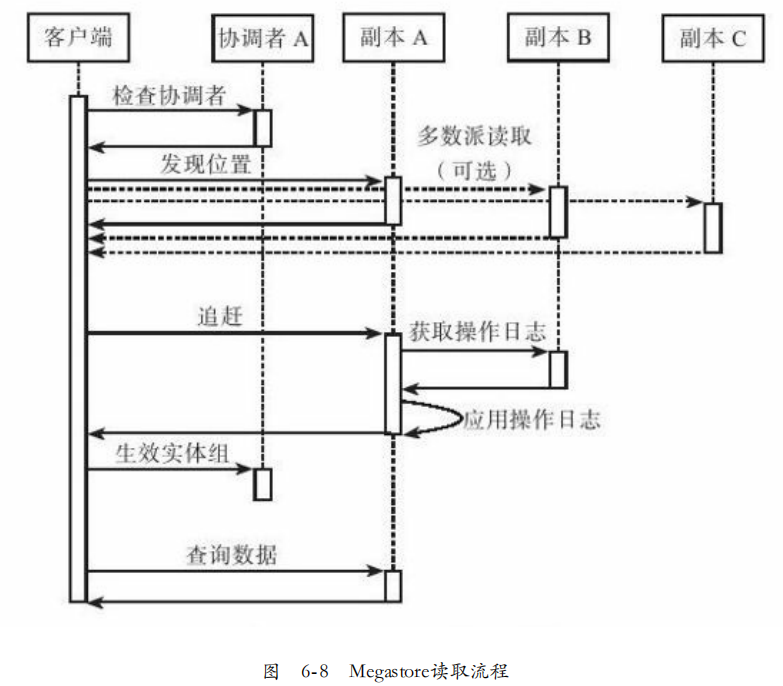
读取流程:
1. 本地查询,查询本地副本的协调者,判断该实体组是否最新。
2. 发现位置,确认一个最高的已经提交的操作日志位置,选择最新的副本。
本地读取,如果本地查询确认本地副本是最新的了,直接读取本地副本。
多数派读取,如果本地查询不是最新的,从多数派中读取最大日志位置,选取一个响应最快的副本。
3. 追赶,一旦某个副本被选中,就采用如下方式,将其追赶到最大位置处。
获取操作日志,对于所选择副本中所有不知道Paxos共识值的日志位置,从其他副本读取。对于不确定共识值的日志位置,发起一次无操作的写。
应用操作日志,顺序的应用所有已经提交但还没有生效的操作日志。
4. 使实体组生效,如果选择了本地副本,且原来不是最新的,需要发送一个生效信息给协调者,告知实体组已经最新。
5. 查询数据,在所选副本通过记录的时间戳读取某版本数据。
写入流程:(执行完一次完整的读操作后,下一个日志可用位置,写操作时间戳,主副本就都知道了)
1. 请求主副本接收,请求主副本将提议的共识值(日志)作为0号提议。(成功,跳到第三步)
2. 准备,所有副本运行Paxos协议准备阶段,在当前日志运行一个更高的提议号进行提议。将提议的共识值换为最高提议号的共识值。
3. 接收,请求副本接收主副本提议,大多数副本拒接,跳回第2步。由于多数情况主副本不会变好,可以跳过第2步,到达快速写。
4. 使实体组失效,如果某些副本不接受共识值,则让其协调者记录的实体组为失效。失效操作返回前,写操作不能返回客户端。
5. 应用操作日志,将共识值在尽可能多的副本生效,更新数据和索引。
分布式存储系统的目标:可扩展性,功能。
Megastore介于关系型数据库和NoSQL之间。
通过实体组,内部满足ACID,外部维持类似NoSQL的弱一致性。
通过Paxos实现高可用和高可靠。
Window Azure Storage:WAS是微软开发的云存储系统。Window Azure Blob/Table/Queue共享一套底层架构。
整体架构:WAS部署在多个数据中心,依赖Window Azure结构控制器(Fabric Controller)管理硬件资源。
结构控制器功能包括节点管理、网络配置、健康检查、服务启动、关闭、部署和升级。
1. 定位服务功能包括:管理存储区,管理用户到存储区的映射,手机存储区负载信息,分配新用户到负载轻的存储区。LS服务自身也分部在不同地狱来实现高可用。LS通过DNS使用户定位所属存储区。
2. 每个存储区是一个集群,10~20个机架构成,每个机架18个节点,提供大约2PB存储容量。存储区分为三层:文件流层,分区层,前端层。
3. 文件流层,类似GFS,提供分布式文件存储。文件流层一般不对外服务,需要通过服务分区层访问。
4. 分区层,类似BigTable,将对象划分到不同的分区。
5. 前端层,一系列无状态的Web服务器,可以将请求转发到不同的分区服务器。
WAS复制:
1. 存储区内复制,复制模式为强同步
2. 跨存储区复制,采用后台线程异步复制。
文件流层:提供接口供服务分区层使用,类似于文件系统的命名空间和API。但所有写操作只支持追加,支持接口:打开/关闭文件,改名,读取,追加到文件。
文件称为流,每个流包含一系列extent,每个extent由一系列block组成。如图,E1和E2,E3已经加封(sealed)不能追加数据,E4是未加封(unsealed)可以将追加操作。
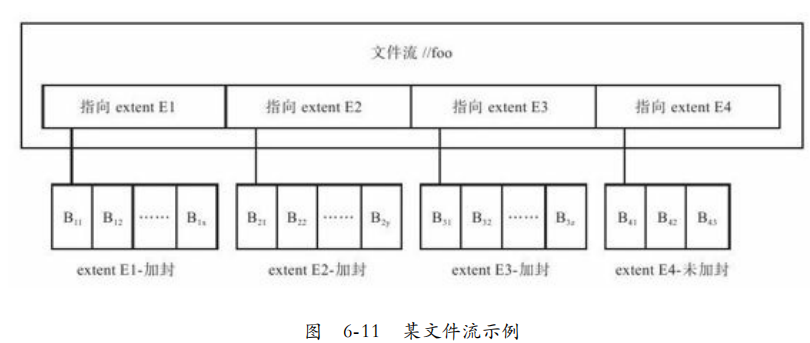
block是数据读写的最小单位,不超过4M,每个block保存校验和。类似GFS的record。
extent是数据复制,负载均衡的基本单位。类似GFS的chunk。
架构:
1. 流管理器SM:维护了元数据,包括命名空间,文件流与extent的映射,extent所在节点信息。同时负责全局控制。自身通过Paxos实现高可用。
2. extent存储节点EN:存储了extent副本,包含block及其校验和,以及每个block索引信息。通过相互通信拷贝客户端追加的数据。接收流管理器的命令:创建extent副本,垃圾回收指定extent。
3. 客户端库:提供给上层应用的访问接口,不遵循POSIX规范。
复制及一致性:只允许追加不允许修改,追加是原子的。以block为单位,多个block可以凑成一个缓冲区一起提交。可能追加重复数据,上层需要处理。
分层区分两种方式处理重复记录:对于元数据和操作日志,所有数据有唯一的事务编号,顺序读取时忽略编号相同的事务。对于表格的行数据流,只有最后一个数据才被引用。
WAS追加流程:
1. 如果客户端没有缓存extent信息,例如追加到新的流文件或者上一个extent已经缝合(sealed),客户端请求SM创建一个新的extent。
2. SM根据策略进行负载均衡。
3. 客户端将数据发送给主副本。主副本选择extent的位置。对于多个客户端发送同一个extent时,确定追加顺序。将数据块写入主副本。
4. 主副本将数据发送给各个备副本。
5. 备副本写成功后答应主副本。
6. 所有备副本应答成功,回复客户端成功。
如果追加失败,副本长度不同,SM缝合extent时选择最短长度的副本进行同步数据。
文件流程保证:只有响应客户端,任意副本都能读到数据。即使追加故障,任意副本都能读到相同数据。
存储优化:如果保证磁盘调度公平同时避免磁盘随机写操作。
很多磁盘牺牲了公平性来提高吞吐,导致随机读被顺序读写阻塞太长时间。因此设置100ms来避免阻塞太旧。
抹除码,对extent划分N个数据段,计算出M个纠错码,只要N+M中少于M个出错,就可以恢复所有。
分区层:构建在文件流层之上,提供Table、Blob、Queue等服务。提供强一致性保证事务操作顺序。
分区层提供对象表(OT)的数据架构,每个OT是一个最大可达若干PB的大表。对象被动态分配到连续的范围分区,分到多个分区服务器,每个服务器不重叠。
分区服务器有一个全局的schema表格。用于记录每个范围分区所在分区服务器。

架构:
1. 客户端程序库(Client):提供分区层接口,对不同数据表的数据单元进行增、删、改、查。通过映射表获取分区信息。
2. 分区服务器(Partition Server):PS实现分区的装载/卸出、分区内容的读和写,分区的合并和分裂。
3. 分区管理器(Partition Manager):管理PS,分配分区给PS,指导PS进行分裂和合并。PS之间负载均衡,故障恢复。
4. 锁服务(LockService):用于选主PM。每个PS与锁服务都持有租约。
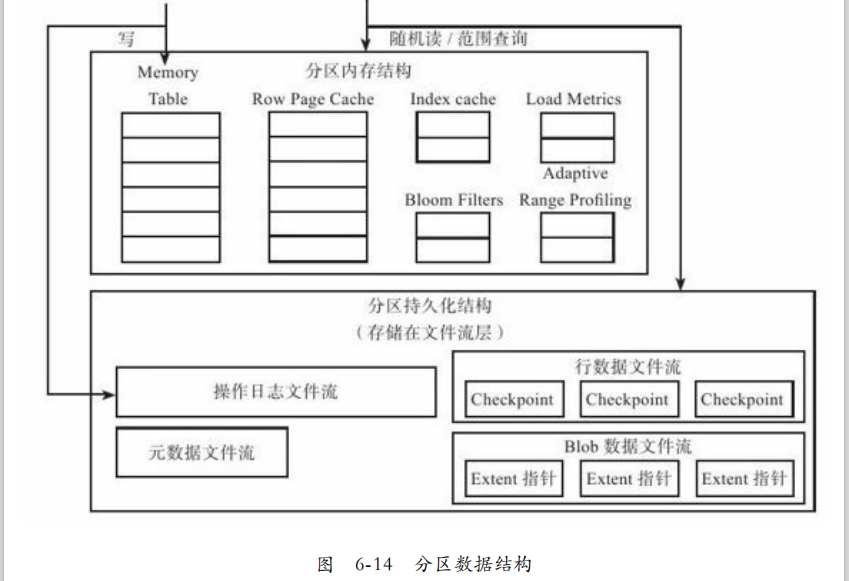
分区数据结构:类似BigTable,需要先写入日志,再更新内存。到达一定大小后执行快照。定期将小快照合并成大快照文件。
不同于BigTable,每个分区拥有专门的操作日志文件(BigTable则是一个Tablet Server所有子表共享一个日志文件)。分区维护各自元数据。引入Blob文件流支持Blob类型。
负载均衡:PM记录了PS及每个分区的负载。影响因素:每秒事务数,平均等待事务数,节流率,CPU使用率,网络使用率,请求延迟,每个分区数据大小。
PM与PS存在心跳。若PS负载过高,则会进行迁移。
负载均衡两个阶段:
1. 卸载:PM发送卸载指令给PS,PS执行快照。完成后,停止读写服务。如果PS出现异常,需要等待PS租约过期才可执行下一步。
2. 加载:PM发送加载指令给PS,同时更新PM的分区映射表。新的PS提供服务,回放卸载时快照的日志。
分裂与合并:分裂则是分区太大或负载过高。PM发起分裂,PS决定分裂点。
合并则是选择两个连续的负载较低的分区。
WAS整体借鉴了GFS+BigTable,不同于:
1. Chunk大小选择,GFS Chunk 是64MB,WAS extent是1GB,从而减少元数据。
2. 元数据层次,BigTable元数据包括根表和元数据表,WAS只有一级元数据表。
3. GFS多个chunk副本弱一致性,不保证每字节完全相同。WAS能保证。
4. BigTable Tablet Server所有子表共享一个日志,WAS 每个extent有不同日志。
第七章 分布式数据库
如:Oracle、Microsoft SQL Server,MySQL等广泛应用各行各业,但他们总假设运行在单机这一封闭系统上。
数据库中间层:扩展关系型数据库最常见的办法就是按照数据拆分为多个分片,分布到多个数据库节点,通过中间层来屏蔽后端拆分细节。
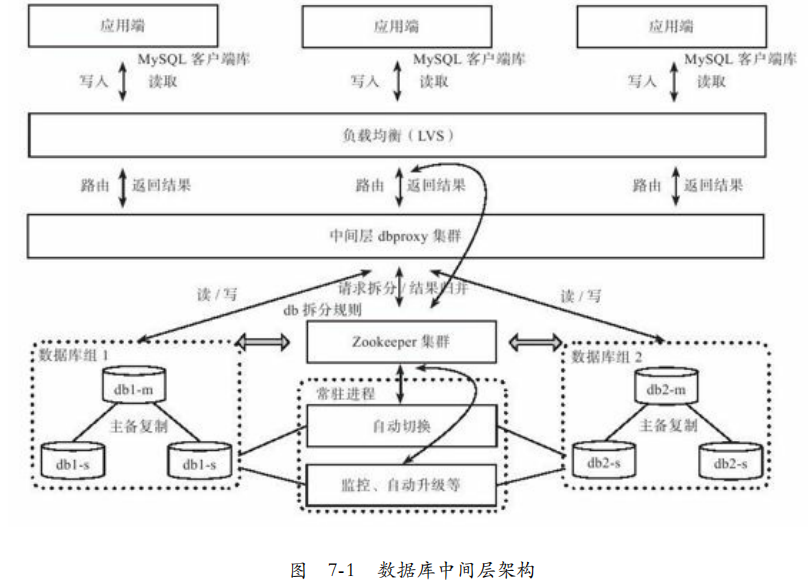
架构:以MySQL Sharding 架构为例,分为几个部分,中间dbproxy集群、数据库组、元数据服务器、常驻进程。
1. MySQl客户端库:通过原生的客户端与系统交互,支持JDBC,原有的单机访问数据库程序无缝衔接。
2. 中间层dbproxy:解析MySQL请求转发到后端。具体,解析MySQL、执行SQL路由、SQL过滤、读写分离、结果归并、排序分组等。由多个无状态的dbproxy构成。
在客户端层与中间层引入LVS对客户端负载均衡。引入LVS后,需要额外增加一层通信开销,因此可以在客户端配置中间层列表,由客户端进行负载均衡。
3. 数据库组dbgroup:每个dbgroup有N台数据库机器组成,其中一台为主机(Master),N-1台为备机(Slave)。主机负责强一致读事务,并将操作以binlog复制到备机,备机提供一定延迟的读事务。
4. 元数据服务器:负责dbgroup拆分,以及dbgroup选主。通过拆分规则确定SQL语句执行计划。本身也需要多个副本实现HA,常见采用Zookeeper实现。
5. 常驻进程agents:部署在每台机器的常驻进程,用于实现监控、单点切换、安装、卸载程序等。
假设数据库按照用户哈希分区,那么同一个用户数据分布到同一个数据库组,转到相应数据库组并返回结果。如果多个用户需要转发到多个数据库组,将返回结果进行合并。
扩容:假设对于用户id哈希分区。
当集群容量不够,一般采用双倍扩容。假如只有两个组:主A0,备A1。主B0,备B1。采用奇偶分区。
1. 等待A0和B0将数据备份到备用服务器,A1和B1。
2. 停止写服务,等待主备完全同步后,解除A0与A1、B0与B1之间的主备关系。
3. 修改映射关系,将%4为1的映射到A1,%4为3的映射到B1。
4. 开启写服务,id哈希值为0,1,2,3分别到A0、A1、B0、B1。
5. 分别为A0、A1、B0、B1增加备机。
因此,扩容时需要停一会服务,扩容期间若发生故障,会变得非常复杂。
如果单个用户数据量很大,需要进行拆分到多个dbgroup,并维护相应信息。
Microsoft SQL Azure是微软的云关系型数据库,后端存储称为SQL Server。
逻辑模型:将数据划分多个分区,限制事务只能在一个分区执行来回避分布式事务。通过主备复制保证高可用性。
一个逻辑数据库称为一个表格组,既可以是有主键也可以是无主键的(本文只讨论有)。有主键的必须保证每个表格都有一个主键列。
划分主键不一定是每个表格的唯一主键。如图7-2,Id是顾客表的唯一主键但不是订单表的唯一主键。
只读事务可以跨越多个行组,但事务隔离级别只支持读取已提交。
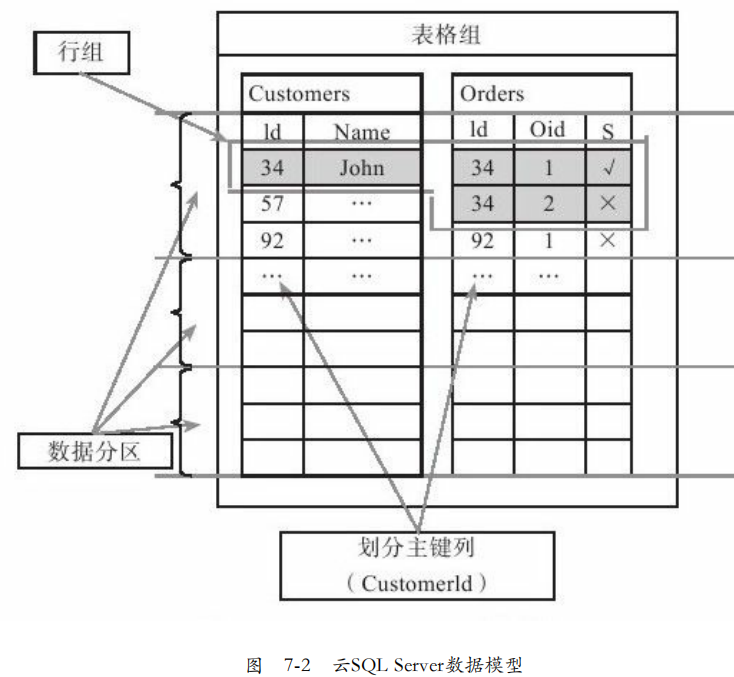
物理模型:每个主键的表格根据主键列划分多个分区,每个分区不重叠,但覆盖所有主键,保证每行属于唯一一个分区。
分区是复制、迁移、负载均衡的基本单位。每个副本存储在一台物理SQL Server上。单台SQL Server存在容量上限。
如果某个分区超过分区上限,将会分裂为两个分区。每个分区都会进行分裂为两段,并在分裂后迁移。

架构:云SQL Server分为:SQL Server 实例、全局分区管理、协议网关、分布式基础部件。
1. SQL Server实例,运行一个SQL Server的物理进程。每个物理数据库包含多个子数据库,互相隔离。子数据库是一个分区,包含用户数据以及schema信息。
2. 全局分区管理器,维护分区映射表信息,包括分区的主键范围,副本所在服务器,每个副本状态。同时进行负载均衡,副本拷贝操作。
3. 协议网关:负责将用户的数据库连接请求转发到相应的主分区上,通过全局分区管理器获取分区所在的SQL Server实例,后续的读写事务在网关与SQL Server实例进行。
4. 分布式基础部件:维护机器上下线,检测故障,并进行选主,在每台服务器上运行一个守护进程。
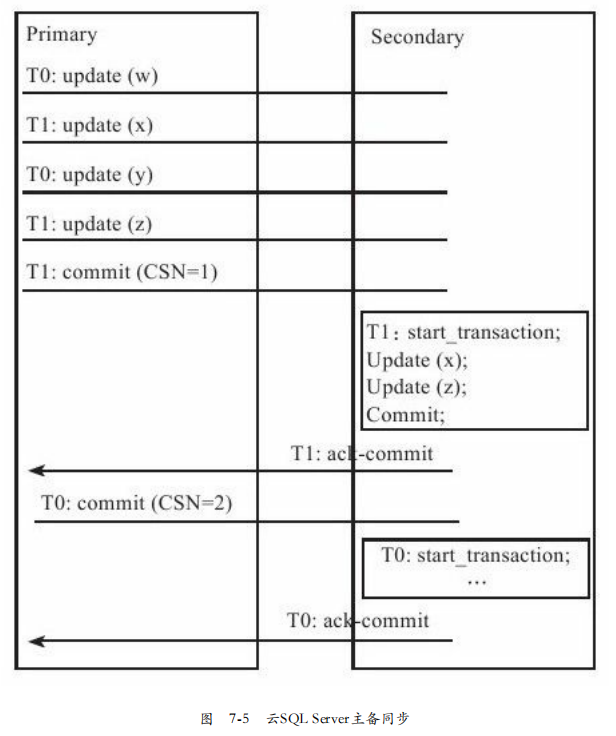
复制与一致性:云SQL采用Quorum Commit协议,用户三副本,至少两个写成功才返回成功。
如图7-5.事务T的主副本分区发生操作日志给备副本。如果T回滚,主副本发送Abort给备副本,如果T提交,发送commit给备副本,并带上顺序号。
备副本成功后返回ACK。获得一半ACK返回客户端成功。
备副本发生故障恢复后,会将最后一次顺序号给主副本,主副本判断若相差不多就发送日志,否则发送一个快照。
容错:如果某个节点故障,需要启动宕机恢复过程。每个SQL Server最多650个逻辑分区。内部存在主副本和备份本。 全局分区管理统一调度,每次选择一个分区重新配置。
如果分区为备副本,则选择一个负载较低的服务器,从主副本拷贝数据。如果是主副本则先选择一个备副本作为主副本,然后选择负载低的服务器拷贝数据。
全局分区管理器会考虑优先级,如主副本丢失,会先选择备副本切换为主。某个数据只有一个副本,需要优先复制。
负载均衡:副本迁移,主备副本切换。新节点加入时,分区会迁移到新节点,但也要控制频率,防止整体性能突然下降。如果主副本所在服务器负载过高,可以将某个备副本切换为主,不需要迁移数据。
多租户:云存储系统,多个用户相互干扰,因此要限制使用的系统资源。
1. 操作系统资源限制,比如CPU、内存、写入速度等。
2. 数据库容量限制。
3. 物理数据库大小限制。
云SQL Server与单机SQL Server仍有区别:
1. 不支持的操作:比如USE,因为不同的逻辑数据库可能位于不同物理机器。
2. 观念转变:连接除了失败、成功还有不确定态。
Google Spanner
作为全球级的分布式数据库,可以扩展数百个数据中心,数百万台机器,上万亿行记录。
数据模型:Spanner的表是层次化的,最底层的表是目录表。目录相当于Megastore的实体组,存储时会将同一目录数据放到一起。只有目录不太大,同一个目录的每个副本都会分配同一台机器。
因此,针对同一目录的读写事务,一般不会跨机器。
架构:架构在下一代分布式文件系统Colossus上。Colossus是GFS的延续,相对GFS主要改进点在于实时性,支持海量小文件。
Universe。一个Spanner实例称为一个Universe,全世界有3个,一个发开,一个测试,一个线上。Universe支持多数据中心部署,多个业务共享一个Universe。
Zones。每个Zone属于一个数据中心,一个数据中心可能有多个Zone。内部通信代价低,Zone之间通信代价高。
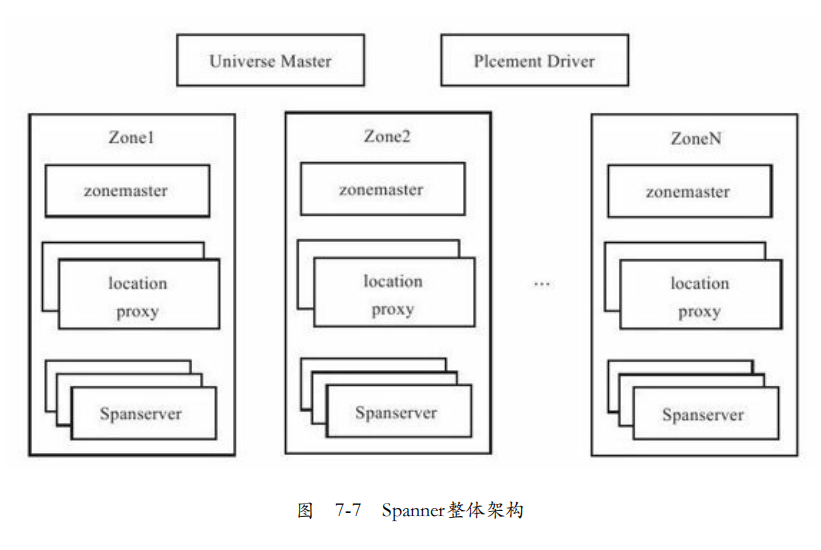
Spanner的系统组件:
1. Universe Master:监控Zone的状态信息。
2. Placement Driver:提供跨Zone数据迁移功能。
3. Location Proxy:提供数据位置信息服务,客户可以查询到数据在哪个SapnServer服务。
4. SpanServer:提供存储服务。相当于BigTable的Tablet。
每个Spanserver有多个子表,每个子表多个目录。
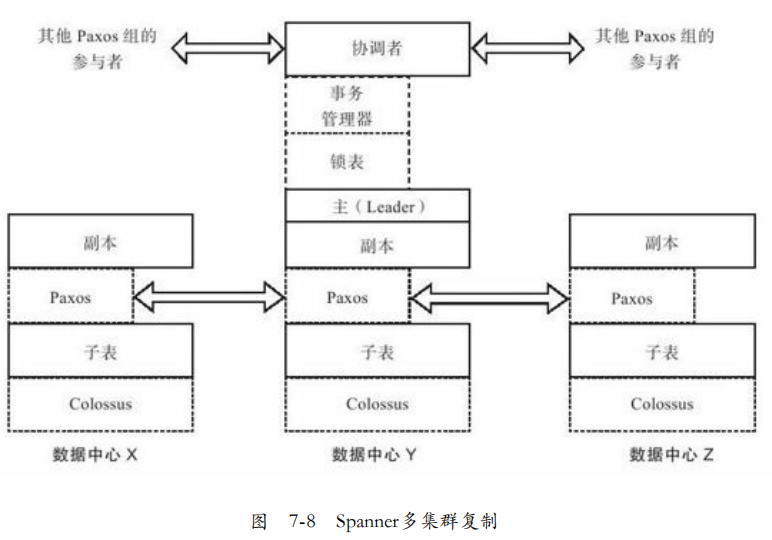
复制与一致性:每个数据中心一个Colossus,每个机器有100~1000个子表,每个子表在多个数据中心部署多个副本。为了同步系统的操作日志,每个子表运行一个Paxos。Paxos会选一个作为主副本。
通过Paxos实现了,跨数据中心的多副本一致性。主副本还会实现锁用于并发控制。
每个主副本还有一个事务管理器,如果在一个Paxos组,可以绕过事务管理器。若是多个Paxos组,则需要事务管理器进行协调。
TrueTime:为了并发控制,需要为每个事务提供全局唯一的事务id。采用Google Percolator的做法,专门部署一个Oracle生成全局唯一id。或者全球时钟同步机制TrueTime。
TrueTime提供一个本地时钟接口,会返回一个时间戳和误差。
每个数据中心需要部署一些主时钟服务器(Master),其他机器上部署一个时钟进程(Slave),从主时钟服务器同步时钟信息。有的主时钟服务器采用GPS或者原子钟。
并发控制:
不考虑TrueTime的影响:
写事务:
1. 获取系统时间戳
2. 执行读写操作,获取第一步的时间戳作为版本号。
读事务:
1. 获取当前的时间戳,作为读事务的版本号
2. 读取小于该版本号的事务操作结果。
快照读和读事务的区别在于,快照会指定读的版本号。
如果读写的事务设计多个Paxos组,需要执行一次两阶段提交协议。
1. Prepare:将数据发往多个Paxos组的主副本,协调者发起prepare协议,请求参与者主副本锁住需要操作的数据。
2. Commit:主副本发起commit协议,参与的主副本解除prepare协议,协调者的主副本将当前时间作为版本号,发给每个主副本。
考虑TrueTIme,即需要考虑误差因素,因此采用延迟提交的策略。如果事务T1时间戳为t-commit。则在t-commit + 误差e之后再提交,
数据迁移:Paxos组负载太大,将数据移到离用户更近的地方,经常访问的目录放到同一个Paxos组。
第八章 OceanBase 架构初探
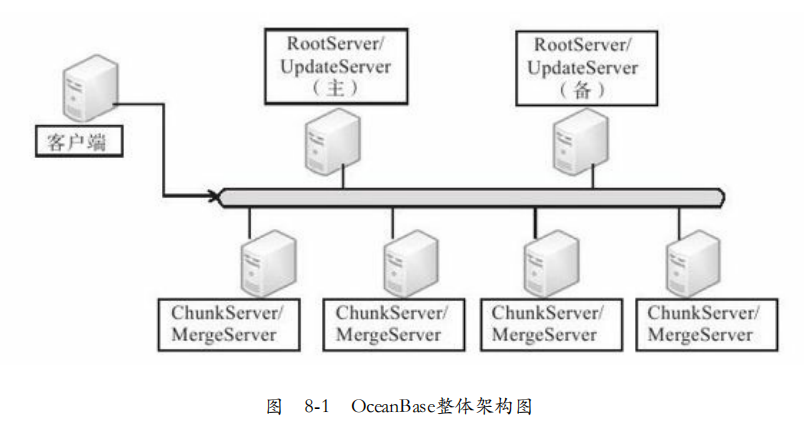
从模块划分:主控服务器RootServer,更新服务器UpdateServer,基线数据服务器ChunkServer,合并服务器MergeServer。
OceanBase内部按照时间线将数据划分为基线数据和增量数据,基线数据是只读的,修改是增量的,内部定期将增量数据融合到基线数据。
设计思路:OceanBase目标是支持数百万TB的数据量以及数十万TPS,数百万QPS的访问量。
单台关系型数据库根本无法承受,即使对其水平拆分仍会产生:添加机器操作负载,需要人工。有些访问可能需要所有分区。不能充分发挥SSD特性。
另一种参考分布式表格BigTable,但只能支持单行事务。
直接的做法可以在BigTable的开源(HBase或Hypertable)的基础上引入两阶段提交支持分布式事务,如Percolate。然而Percolate平均响应时间2~5秒。
因此,需要定制系统。淘宝业务的数据量很庞大,但是修改量不多,因此采用单台服务器记录最近修改量,而之前的保持不变,作为基线数据。
系统架构:
1. 客户端:用户使用OceanBase的方式和MySQL数据库完全相同,支持JDBC、 C客户端访问。
2. RootServer:管理所有服务器,子表数据分布以及副本管理。分为一主一备,采用强同步。
3. UpdateServer:存储增量数据,采用一主一备,可以配置不同的同步模式。
4. ChunkServer:存储基线数据,两份或者三份。
5. MergeServer:接收并解析用户请求,如果在多个ChunkServer还需要合并。
OceanBase支持部署多个机房,每个机房一个包含RootServer,MergeServer,ChunkServer,UpdateServer的完整集群。各自RootServer负责负载均衡等。
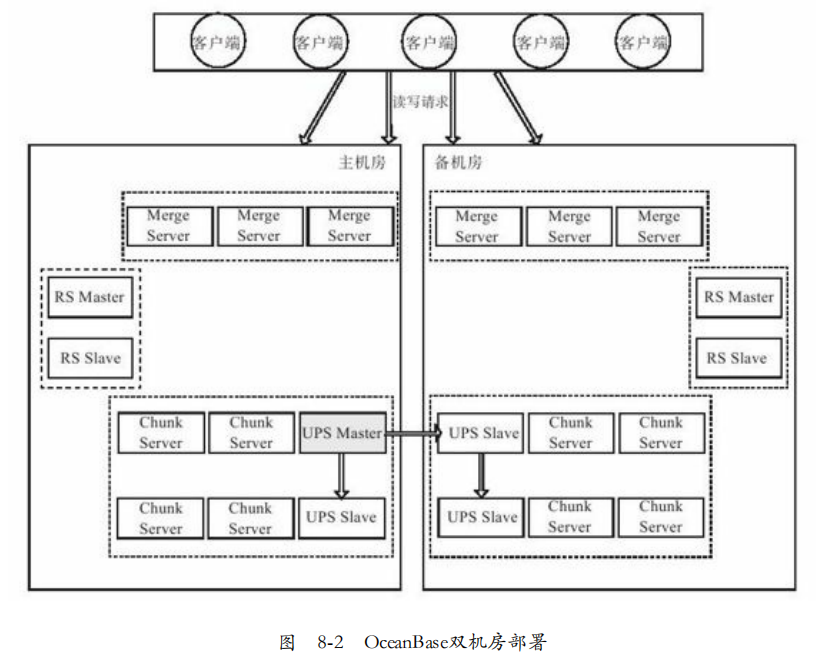
客户端:OceanBase客户端与MergeServer通信,主要支持如下:
1. MySQL客户端:兼容MySQL协议,以及相关工具。
2. Java客户端:提供对MySQL标准JDBC Driver的封装,提供流量分配、负载均衡、MergerServer异常处理的功能。
3. C客户端:类似Java客户端。
OceanBase有多个MergeServer,地址都存储在服务器中。因此,客户端首先通过服务器端获取MergeServer地址列表,并按照策略将读写请求发往MergeServer
1. 请求RootServer获取MergeServer。
2. 按照策略选择一个MergeServer发送读写请求。
3. 如果请求失败,则重新选择一个MergeServer。
RootServer:用于集群管理、数据分布、副本管理。
管理所有MergeServer、ChunkServer、UpdateServer。每个集群内部同一时刻只允许一个UpdateServer提供写服务,通过牺牲了一定的可用性换取了强一致。
OceanBase内部采用主键对表格的数据排序和存储。数据分布类似BigTable顺序分布,并采用根表的一级索引。
MergeServer:用于协议解析、SQL解析、请求转发、结果合并、多表操作。
OceanBase与MergeServer采用MySQL协议,MergeServer会解析MySQL协议,提取SQL语句。
MergeServer缓存了子表分布信息,将请求发到子表所在的ChunkServer。
ChunkServer:存储多个子表、提供读取服务,定期合并以及数据分发。
OceanBase将表分为256M的子表,每个子表由一个或多个SSTable组成,每个SSTable由多个块组成,数据在SSTable中有序存储。
查询时首先从SSTable获取基线数据,然后从UpdateServer获取增量数据,将融合后作为结果。
UpdateServer:唯一能接受写入的模块,每个集群只有一个主UpdateServer。
数据首先写入内存,超过一定值后转储到SSD。快照文件的组织方式与SSTable类似。由于数据行的有些列没有更新,因此数据行是稀疏的。
为了保证可靠性,数据会首先写入到日志,并同步到备UpdateServer。
由于集群中只有一台主UpdateServer提供写服务,因此OceanBase很容易实现跨行表事务。但其性能变的至关重要。
OceanBase集群通过定期合并和数据分发两种机制,将UpdateServer的增量源源不断分散到ChunkServer。
定期合并&数据分发:
1. UpdateServer冻结当前活跃的内存数据,生成冻结表,并开启新的内存活跃表。
2. 通知RootServer数据版本发生变化,之后RootServer会通知每台ChunkServer。
3. 每台ChunkServer启动定期合并或者数据分发,从UpdateServer获取每个子表对应的增量进行更新。
数据分发中ChunkServer只会将冻结表的增量缓存到本地,而定期合并会将ChunkServer本地数据与冻结表的数据进行多路归并,往往安排在低峰期执行。
虽然定期合并时间可能不同,但不影响读取服务,对于未完成的子表合并,会读取旧子表+冻结内存表+活跃内存表,否则读取新子表+活跃内存表。
查询结果 = 旧子表 + 冻结内存表 + 新的活跃内存表
= 新子表 + 新的活跃内存表
一致性选择:根据CAP理论指出,一致性和可用性不可兼得,虽然互联网大多数选择弱一致性,但带来了很多麻烦。因此OceanBase采用强一致性和跨行跨表事务。
OceanBase的UpdateServer采用主备高可用架构,修改操作如下:
1. 将修改操作日志(redo 日志)发到备机。
2. 将修改操作日志写入主机磁盘。
3. 将操作日志应用到内存表。
4. 返回写成功。
OceanBase要求日志同步到主备的情况下才返回成功,即使主故障,也能切换备,保证数据不丢失。
为了提供可用性,在主机同步时,如果失败,可以去RootServer申请从同步列表剔除该备机,后续如果主机故障,可以避免切换到不同步的备机上。
OceanBase的高可用性保证,主机,备机,备机与主机之间网络三者任意故障都不会有影响,如果两个出现故障,可用性会有影响但数据不会受影响。如果对可用性要求高,可以增加备机数量。
OceanBase主备同步也允许异步同步,一般用于异地容灾。
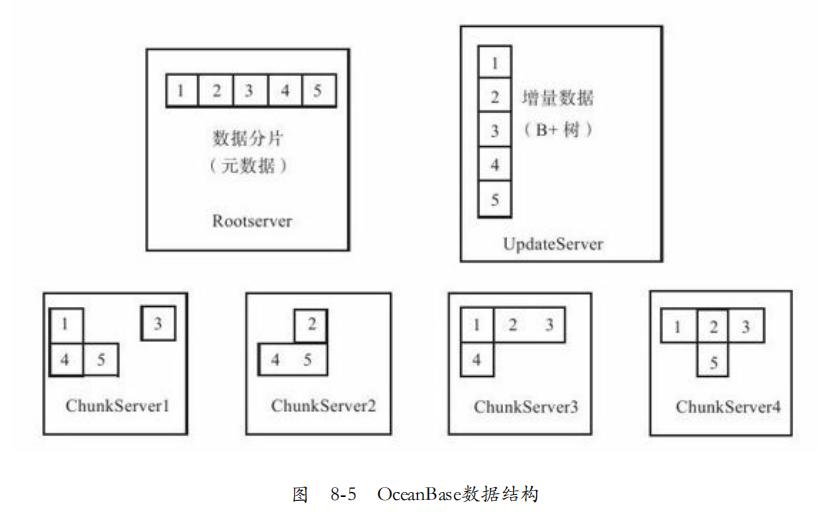
数据结构:如图8-5所示·,OceanBase分为基线数据和增量数据,每个子表的三副本分布到ChunkServer上。UpdateServer存储了所有子表的增量更新。
不考虑数据的复制,基线数据的数据结构:
1. 每个表格按照主键组成一颗分布式B+树,主键由若干列构成。
2. 每个叶子结点包含表格一个前开后闭的主键范围(rk1, rk2]内的数据。
3. 每个叶子结点称为一个子表(tablet),包含一个或者多个SSTable。
4. 每个SSTable内部按照主键范围有序划分为多个块并内建块索引。
5. 每个块大小通常4~64KB并内建行索引。
6. 数据压缩以块为单位,压缩算法由用户指定并可以随时变更。
7. 叶子结点可能合并或者分裂。
8. 所有叶子结点基本上是均匀的,随机分布到ChunkServer机器。
9. 通常每个叶子结点有2~3个副本。
10. 支持布隆过滤器。
增量数据的数据结构:
1. 按照时间从旧划分为多个版本。
2. 最新版本的数据为一颗内存中的B+树,称为活跃MemTable。
3. 用于修改写入活跃MemTable,到达阈值后,原先活跃MemTable冻结,并生成新的活跃MemTable。
4. 冻结的MemTable以SSTable形式转储到SSD。
5. 每个SSTable内部按照主键范围有序划分为多个块并构建块索引,每个块大小4~8KB并构建行索引。
6. UpdateServer支持主备,增量数据通常为2个副本,每个副本支持RAID1存储。
可靠性与可用性:
分布式系统需要处理各种故障:软件故障、服务器故障、网络故障、数据中心故障、地震、火灾。OceanBase通过冗余的方式保障高可靠和高可用性。
1. OceanBase在ChunkServer保存了基线数据的多个副本。
2. OceanBase在UpdateServer中保存了增量数据的多个副本。
3. ChunkServer的多个副本可以同时提供服务。
4. UpdateServer为热备,可以迅速切换。
5. OceanBase存储多个副本没带来太多成本。
读写事务:
对于读写请求都会发送给MergeServer,首先解析语法等。对于只读事务会发送给ChunkServer并合并结果,写事务预处理后发送给UpdateServer。
只读事务流程:
1. MergeServer解析SQL语句,词法分析,语法分析,预处理,最后生成逻辑执行计划和物理执行计划。
2. 如果SQL语句只涉及单张表格,MergeServer将请求拆分后同时发送给多台ChunkServer并发执行,合并结果。
3. 如果SQL语句涉及多张表格,MergeServer还需要执行联表,嵌套查询等操作。
4. MergeServer将结果返回客户端。
读写事务执行流程:
1. 与只读事务一样首先解析SQL请求,得到物理执行计划。
2. MergeServer请求ChunkServer获取读取的基线数据,并将物理执行计划和基线数据一起传给UpdateServer
3. UpdateServer根据物理执行计划执行事务,并需要使用传入的基线数据。
4. 返回成功或失败。
单点性能:OceanBase优势在于支持跨行跨表事务,同时能够线性扩展。
通过内存容量,网络,磁盘等方面分析UpdateServer的读写性能。
1. 内存:对于大部分数据库每天修改次数有限,只有少量数据库每天才会频繁修改,而且数据量通常很小。假如,每天更新1亿次每次100字节,每天插入1000万次每次1000字节,修改量20GB。
数据结构碰撞两倍也只是40GB,主流服务器可以达到96GB,192GB,384GB甚至更高。
在双十一有可能会有内存占用过大,因此可以手动将内存数据转出到SSD,同时通过定期合并和数据分发将其分散到ChunkServer上。
2. 网络:假设每秒读取20万次,每次100字节,带宽是20MB,远远没有达到千兆网卡上限。而且可以为UpdateServer设置多块千兆网卡或者万兆网卡。
3. 磁盘:事务首先将日志写入磁盘,一块SAS磁盘每秒的IOPS很难超过300,因此可以配置一个带有缓存模块的RAID卡,RAID卡带有电池,即使UpdateServer故障也能写入数据。
SSD支持:SSD进展很快。
数据正确性:
数据丢失和错误对于存储系统都是一场灾难。
1. 数据存储校验。每个存储记录同时保存64位CRC校验码,数据被访问时,重新计算和比对校验码。
2. 数据传输校验。每个传输记录同时传输64位CRC校验码,数据接收后,重新计算和比对校验码。
3. 数据镜像校验。主备UpdateServer会校验MemTable。
4. 数据副本校验。ChunkServer在定期合并生成子表时,会生成校验码发给RootServer进行校验。
分层结构:
OceanBase对外提供与关系型数据库一样的SQL操作接口,内部却是一个分布式系统。
OceanBase一期只做了分布式存储引擎。
1. 支持分布式数据结构,基线数据结构上构成一颗分布式B+树,增量数据为内存B+树。
2. 目前支持所有分布式特性,包括数据分部、负载均衡、主备同步、容灾、自动增加/减少服务器。
3. 支持主键更新、插入、删除、随机读取一条记录,支持主键范围顺序查找一段记录。
OceanBase二期将提供SQL支持
1. 支持SQL语句以及MySQL协议。
2. 支持读写事务。
3. 支持多版本并发控制。
4. 支持读事务并发控制。
第九章 分布式存储引擎
分布式存储引擎负责处理分布式系统的各种问题:数据分布、负载均衡、容错、一致性等。与其他分布式存储系统类似,支持主键更新、插入、删除、随机读取以及范围查询,数据库功能构建在分布式存储引擎层上。
分布式存储引擎层包括三个模块:RootServer用于整体控制。UpdateServer用于存储增量数据。ChunkServer用于存储基线数据。
OceanBase包含一个公共模块,包含其他模块需要的公共类,例如:数据结构,内存管理,锁,任务队列,RPC框架,压缩/解压等。
公共模块:公共数据结构、内存管理、锁、任务队列、RPC框架、压缩/解压缩等
内存管理:OceanBase内部有一个全局的定长内存池,维护了64KB大小的定长内存块组成的空闲链表。工作原理:
如果申请的内存不超过64KB,则从空闲链表返回一个64KB的内存块,链表为空则向操作系统申请64KB的内存加入空闲链表。
如果超过64KB,则直接调用Glibc的内存分配(malloc)函数,释放时直接用free。
全局内存池实现简单,但不适合管理小块内存,如UpdateServer的MemTable等,都会获取内存后放到各自的专用内存池。每个线程会先从局部缓存申请内存。
全局内存池的意义:
1. 可以统计每个模块的内存使用,如果内存泄漏可以快速定位。
2. 全局内存池可用于辅助调试,例如可以将申请到的内存块按字节填写非法值(如:0xFE),内存越界很容易差错。
基础数据结构:
1. 哈希表:为了提高随机读取性能,会采用哈希表LightyHashMap。采用链式冲突处理方式。将冲突放到一个哈希桶。
insert:根据key的哈希值获取桶号,并放入桶中。
get:根据key获取桶号,遍历链表。
erase:根据key获取桶号,遍历链表,找到并删除与key相同的节点。
LightyHashMap设计用来存储几千万甚至上亿元素,与传统哈希表区别在于:
1.位锁:对于每个桶只需要一位,可以判断是否有冲突。
2. 初始化延迟:由于桶非常多,即使对桶做一次memset也很费时,因此以65536为一组。当操作发现某组没有初始化时,先进行初始化操作
2. B树:可以支持Put、Get、Scan。支持多线程并发修改。
对于同时修改不同索引的节点,不会有冲突,对于同一索引的节点其中一个会失败并重试。
为了提高读写并发能力,采用写时复制,修改节点时先将其拷贝出来,最后原子的修改父亲指针与拷贝节点。
3. 锁:为了并发控制需要对行记录加入共享锁或互斥锁。
对于获取共享锁,需要将共享锁引用加一。
对于获取互斥锁,需要记录当前互斥锁用户。并且获取前要等待共享锁用户都释放。如果本次超时时间没有全部释放共享锁,则获取互斥锁失败。
4. 任务队列:生产者加入队列,消费者去获取。由于获取全局任务队列需要获取锁,导致操作系统上下文切换,因此采用一定策略选择一个任务队列加入。
如:根据当前等待任务数%线程数获取应该去第几个线程等待任务被执行。
如果某个任务处理时间很长,可能导致任务不均,因此对于空闲线程会主动去其他队列尝试获取任务。
除此之外,还可以通过LightyQueue解决全局任务锁冲突。
任务加入队列(push)操作,占据下一个push槽位,加入该槽位,唤醒在该槽位等待任务的工作线程。
工作线程获取任务(pop)操作,占用下一个pop槽位,如果有任务则返回,否则等待唤醒。
5. 网络架构:服务端接收客户端发送的网络包,交给handlePacket处理函数。默认情况会加入到全局队列,工作线程会获取网络包,并进行处理。
客户端发送包分为 异步和同步。异步请求时,客户端请求包放入网络发送队列后立即返回。同步请求,会阻塞直到接收到服务器的应答包。
6. 压缩与解压:LZO与Snappy等。
RootServer实现机制:作为集群对外窗口,客户端通过RootServer获取集群内其他模块信息,功能:
1. 管理ChunkServer上下线。
2. 管理UpdateServer,实现选主。
3. 管理子表数据分布,发起子表复制、迁移以及合并。
4. 与ChunkServer保持心跳,接收ChunkServer汇报,处理子表分裂。
5. 接收UpdateServer汇报的大版本冻结消息,通知ChunkServer定期合并。
6. 实现主备RootServer,数据强同步,支持RootServer宕机自动切换。
数据结构:存储了子表数据分布的有序表格,称为RootTable。每个子表存储信息包括:子表主键范围,子表副本所在ChunkServer编号,子表各个副本的数据行数,占用磁盘空间,CRC校验,基线数据版本。
RootTable是一个读多写少的数据结构。只有子表迁移、复制以及合并需要修改RootTable,其余只需读取。
向RootTable添加子表信息时:首先拷贝出一个新的RootTable,然后子表信息加入新的RootTalbe,最后原子的修改指针使服务指向新的RootTable。
子表复制和负载均衡:RootServer两种操作会触发子表迁移:子表复制与负载均衡。
每台ChunkServer记录了子表迁移的信息,包括:子表的数量和大小,正在迁入迁出的子表数量以及迁移任务列表。
RootServer有专门线程,用于查看子表复制和负载均衡。
子表复制,扫描RootTable的子表,如果发现副本少于阈值,则选一个ChunkServer作为源,一个作为目的,进行迁移。
负载均衡:扫描RootTable的子表,如果发现某个子表数超过平均与可容忍数之和,则选择进行迁移。
迁移任务不会立即执行,会放入迁移任务列表。会有一个后台线程,扫描所有ChunkServer,限制最大迁入和迁出数量,防止新上线机器负载过高。
子表分裂与合并:子表分裂由ChunkServer定期执行,如何保证每个副本分裂点一致成为问题的关键。
由于每个副本的基线数据一致,定期合并过程中冻结的增量数据也完全相同,只要分裂规则一致,分裂后的子表范围也一定相同。
子表合并相对较麻烦:
1. 合并准备:选取若干个主键范围连续的小子表。
2. 子表迁移:将若干个小子表迁移到相同的ChunkServer机器。
3. 子表合并:往ChunkServer机器发送子表合并命令,生成合并后的子表范围。
UpdateServer选主:为了确保一致性,RootServer要保证整个集群只有一台UpdateServer。
RootServer通过租约机制实现UpdateServer选主,主UpdateServer必须持有RootServer的租约才能提供写服务,租约的有效期一般为3~5秒。
RootServer频繁升级,升级过程中UpdateServer的租约将很快过期,因此在升级退出前,会给UpdateServer超长租约,如半个小时。
RootServer主备:每个集群一般部署一主一备两台RootServer,主备强同步,操作先同步到备机,接着修改主机,最后返回成功。
RootServer同步:子表分布信息,ChunkServerManager中记录的ChunkServer机器变化信息以及UpdateServer机器信息。
UpdateServer实现机制:用于存储增量数据。包括:
1. 内存存储引擎:内存中存储修改增量,支持冻结以及转储操作。
2. 任务处理模型:包括网络框架,任务队列,工作线程,针对小数据包做了专门优化。
3. 主备同步模块:将数据更新以日志的方式同步到备UpdateServer。
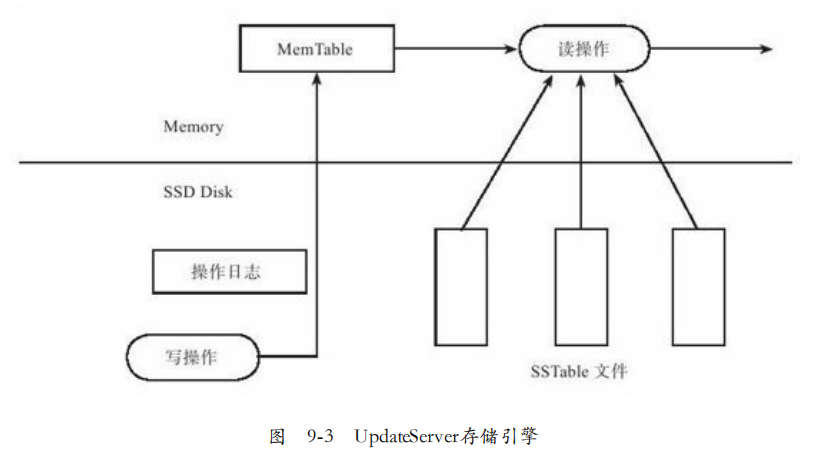
存储引擎:如图9-3.与BigTable不同之处:
1. 只存储了增量修改数据,基线数据以SSTable形式存储在ChunkServer。BigTable同时存储基线数据和增量数据。
2. UpdateServer内部所有表格公用MemTable以及SSTable,而BigTable每个子表的MemTable和SSTable分开存储。
3. UpdateServer的SSTable存储在SSD磁盘,而BigTable的SSTable存储在GFS。
UpdateServer存储引擎主要包括:
1. 操作日志:有专门的提交线程确定事务的顺序,并将操作追加到日志缓冲区,将日志缓冲区内容写入日志文件。
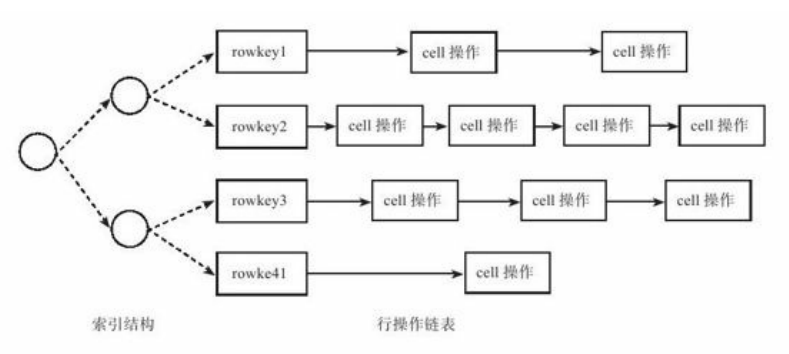
2. MemTable:高性能的内存B+树,每个节点代表一行数据,key为行主键,value为操作链表的指针。每行操作按时间顺序构成操作链表。
如三个Cell为:<update,购买人数,100>、<delete,*>以及<update,商品名,“女鞋”>。
对于修改等操作也只是追加一个标记。
同时为了优化性能提供了:哈希索引,针对随机读取应用。内存优化,采用变长编码。
3. SSTable:当活跃的MemTable超过一定大小或者管理员发送冻结命令,MemTable将被冻结,并转出到SSD。
与ChunkServer不同在于,每个列不一定存在,因为某些列可能不需要修改。
任务模型:包括网络框架,任务队列,工作线程,UpdateServer最初基于淘宝网实现的Tbnet实现,但难以发挥UpdateServer收发小数据包的特点,后采用Libeasy。
1. Tbnet:本质是生产者消费者模型,网络读写线程和超时检查线程。
网络读写线程执行事件,当服务端有可读事件时,回调函数读取请求数据包,生成任务,放入队列。工作线程从中获取任务。超时检查线程将超时请求移除。
问题在于,多工作线程在队列获取任务时,需要加锁互斥。
2. Libeasy:为了解决小数据包带来的上下文切换问题,采用多网络线程收发包,增强了网络收发能力,每个线程收到包后立即处理,减少了上下文切换。
由于需要通过监听套接字来获取网络读写事件,每个套接字分配给一个网络线程。
主备同步:采用强一致性同步,日志回放线程拉取主UpdateServer的日志文件和日志缓冲区的数据。
ChunkServer实现机制:
用于存储基线数据,主要部分:
1. 管理子表,实现子表分裂,配合RootServer实现子表的迁移、删除、合并。
2. SSTable,根据主键有序存储基线数据。
3. 基于LRU实现块缓存和行缓存。
4. 实现Direct IO,磁盘IO与CPU并行化。
5. 通过定期合并和数据分发获取UpdateServer的冻结数据,从而分散到集群。
子表管理:每台ChunkServer服务于多个子表,一般几千到几万。
子表操作:增加子表、删除子表、删除表格、升级版本号、读取子表并加引用计数、合并子表。

SSTable:数据按照主键连续存放在数据块中,块间有序。并存储数据块的索引,由每个块最后一行主键构成。之后存放布隆过滤器和Schema信息。最后,存放固定大小的Trailer以及Trailer的偏移位置。
查找SSTable,会先获取Trailer位置,以及信息。找出块的索引和大小偏移。从而将索引加载进去。并根据索引二分找到block,将块加载到内存。
本质上,SSTable是两级索引结构,块索引和行索引。而ChunkServer则是三级索引结构,子表索引、块索引和行索引。
SSTable分为两种格式,稀疏格式以及稠密格式。对于稀疏格式,某些列可能不存在,只存储实际包含列的内容,因此是<列ID,列值>。而稠密则不用列ID,直接查schema即可。
同时SSTable支持列组,同一列组存储在一起。数据按照[表格ID,列组ID,行主键]有序存储。
对于定期合并和数据分发,将会产生新的SSTable不断追加数据。
缓存的实现:块缓存(访问较热的数据块),行缓存(访问较热的数据行),块索引缓存(最近访问过的块索引)。
底层实现:哈希表与LRU链表,每次将访问的元素移到头部,避免被快速淘汰。
1. OceanBase一次分配1M的连续内存块,内部包含多个缓存项(item)
2. 内部没有LRU链表,仅仅维护了访问次数和最近频繁访问的时间。如果最近时间访问次数超过一定值,更新最近频繁访问时间。淘汰时按照最近频繁访问时间排序,进行淘汰。避免了链表的移动。
3. 每个内存块维护了引用计数,引用为0时,可以进行回收。
惊群效应:对于多个工作线程都需要发现同一个行缓存失效时,需要竞争锁去读取该数据。增加了锁的负担。
因此,对于第一个发现该行缓存失效时,向缓存加入一个fake标记,其他发现者会等待一段时间,直接读取缓存。
缓存预热:如果大量请求同时读取新SSTable,会使性能急剧下降,因此会主动根据键值读取新数据。
IO实现:采用Direct IO,支持磁盘IO与CPU并行化。
ChunkServer采用Linux的Libaio实现异步IO,通过双缓存机制实现磁盘预读与CPU处理并行化。
1. 分配当前以及预读的两个缓冲区。
2. 使用缓冲区读取数据,发动异步读取。
3. 异步读取后,将缓冲区返回给上层执行CPU计算。
4. 重复3直到数据读完。
双缓冲区广泛应用于生产者消费者模型,采用了双缓冲区异步预读的技术,生产者为磁盘,消费者为CPU。
双缓冲区包括的状态:
1. 都在使用的状态:多数情况,生产者和消费者都处于读写状态。
2. 单个缓冲区空闲:由于速度有差异,需要等待另一个。
3. 缓冲区的切换:切换数据。
定期合并&数据分发:RootServer将UpdateServer上的版本变化通知ChunkServer后,ChunkServer将执行定期合并和数据分发。
如果UpdateServer执行了大版本冻结,ChunkServer则执行定期合并。唤醒若干个合并线程。
1. 加锁,获取下一个需要定期合并的子表。根据子表的主键范围读取UpdateServer中的修改操作。
2. 将每行的基线数据和增量数据合并后,产生新的基线数据写入新的SSTable。
3. 更新子表索引信息,指向新的SSTable。
等ChunkServer更新完,会向RootServer汇报,RootServer更新子表版本信息。一般定时在业务低峰期执行(凌晨1点)
如果UpdateServer执行了小版本冻结,ChunkServer则执行数据分发。只是将数据发到ChunkServer,并不会生成新的SSTable,压力不大。
定期合并限速:由于合并期间压力较大,需要控制速度,避免影响正常服务。
1. ChunkServer:ChunkServer定期合并过程,没合并完成若干行数据就查看本机负载。负载过高,则合并线程转入休眠。负载过低,则唤醒更多合并线程。
RootServer将UpdateServer冻结的大版本通知所有ChunkServer,每台会随机等待一会时间开始,防止所有ChunkServer同时发送请求给UpdateServer。
2. UpdateServer:定期合并过程,需要从中读取数据,为了防止定期合并任务满带宽影响用户,采用多个优先级,用户级别高,定期合并级别低。
消除更新瓶颈:UpdateServer看起来像是OceanBase的软肋,但目前增加机器还是可以让其稳定服务。但也提供了一些优化。
读写优化回顾:UpdateServer相当于一个内存数据库,类似最快的MemSQL,能够支持每秒数百万次单行读取操作。
1. 网络框架优化:不优化,每秒接受的数据包10万,libeasy优化后达到50万,万兆网卡则超过100万。
2. 高性能内存数据结构:底层采用B树,为了发挥多核优势,多数情况做到无锁。
3. 写操作日志优化:成组提交,多个写操作聚合到一起。降低日志缓冲区锁冲突,可以先占位然后再拷贝。日志并发写入,由于缓冲区很小,可能很快要写入磁盘,可以同时写入不同磁盘。
4. 内存容量优化:通过编码方式优化内存格式,当内存容量到达一定阈值,执行分发操作。
数据旁路导入:对于OLAP应用,定期导入的大量数据可能仍有问题。
OceanBase内部数据全局有序,第一步将数据通过 Hadoop-MapReduce这样的工具排好序,并划分范围作为SSTable文件。最后拷贝到ChunkServer。
数据分区:随着使用场景的广泛,需要实现节点的可扩展。
可以将数据划分多个分区,不同分区被不同UpdateServer服务。同一用户划分同一分区,保证同一用户下的读写操作,不同用户采用两阶段提交的方式。
第十章 数据库功能
数据库功能构建在分布式存储引擎层之上。对于使用者来说OceanBase和MySQL没什么区别。
整体结构:
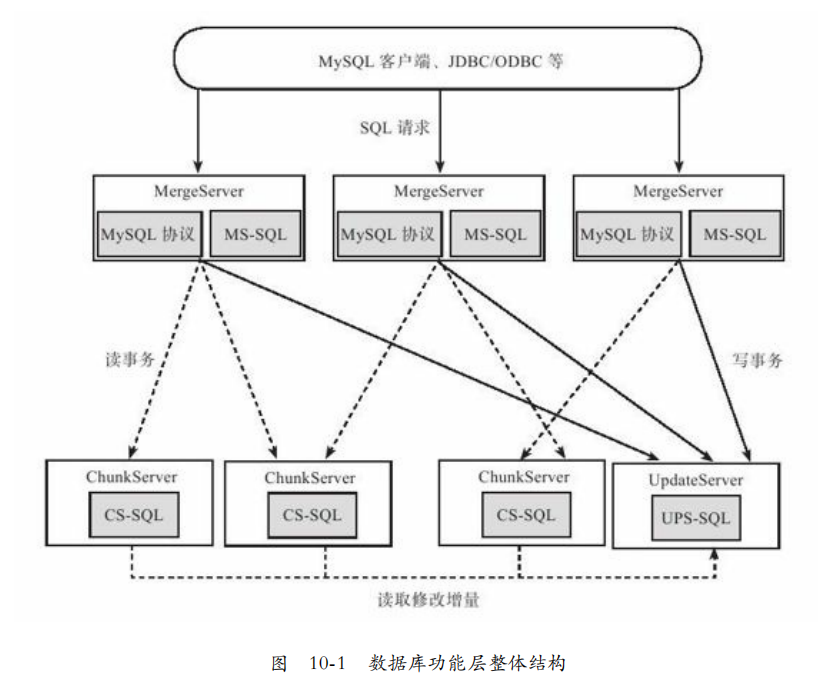
CS-SQL:针对单个子表的SQL查询,包括表格扫描,投影,过滤,排序,分组,分页,支持表达式计算,聚焦函数。
UPS-SQL:实现写事务,支持多版本并发控制,操作日志多线程并发回放。
MS-SQL:SQL语句解析,包括词法分析,语法分析,预处理,生成执行计划,按照子表范围合并多个ChunkServer返回的部分结果。执行联表,子表查询等。
只读事务:
2. 解析语法树,生成逻辑执行计划ObSelectStmt。ObSelectStmt结构中记录了SQL语句扫描的表格名(t1),投影列(c1,c2),过滤条件(id=1),分组列(c1)以及排序列(c2)
3. 根据逻辑执行计划生成物理执行计划。ObSelectStmt只是表达了一种意图,但并不知道实际如何执行,ObTransformer类的generate_physical_plan将ObSelectStmt转化为物理执行计划
单表SQL执行,多表SQL执行----P358~359
单表操作:
1. TableScan:扫描表格,MergeServer将请求发送子表所在ChunkServer,并将合并结果作为数据。
2. Filter:针对每行数据判断是否满足过滤条件。
3. Projection:对每行输入,根据表达式,输出结果
4. GroupBy:按列进行聚焦,计算值(count,sum,min....)
5. Sort:进行排序。
6. Limit:返回某些范围的行。
7. Distinct:消除重复行。
多表操作:
物理操作符主要为Join,分为内连接,左外连接,基本都是等值连接。多表连接都是前两张表生产临时表与下一张连接,以此类推。
等值连接分为:基于排序算法,基于哈希算法。
------------------------------------------------------- TODO 367~387----------------------------------
第十一章 质量保证、运维及实践
测试
----------------------------------------------------TODO 388~427-----------------------------------------
第十二章 云存储
云存储:有良好的扩展性、对用户透明、按需分配、负载均衡。特点:
1. 超大规模:单个系统存储的数据可达到千亿级甚至万亿级。2011年Q4 Amazon S3存储的对象个数已经7600亿个。
2. 高可扩展性:可以动态伸缩,满足数据规模增长的需求。可扩展性包括两个维度,可以动态增加服务资源来应对数据增长。
运维可扩展,随着系统规模的增加,不需要增加太多运维人员。
3. 高可靠性和可用性:通过多副本复制以及节点故障自动容错等技术,提供了可靠性和可用性。
4. 安全:通过用户鉴权,访问权限控制,保障安全性。
5. 按需服务:云存储是一个庞大的资源池,用户按需购买。
6. 透明服务:以统一接口提供服务,节点故障对用户透明。
7. 自动容错:能够自动处理节点故障。
8. 低成本:云存储的重要目标。
云存储由大量的廉价存储设备组成,核心则是分布式存储。
与传统存储的优势在于:
1. 可扩展性:传统存储在数据量增加时,需要管理员手动执行操作。
2. 利用率:传统存储的资源利用率非常低,资源分配通常是静态的,导致存储资源处于闲置状态。
3. 成本:传统存储的投资成本和管理成本十分昂贵,很难提前预测业务的增长量,提前购买设备会造成浪费,产生了投资浪费。
4. 服务能力:传统存储容易出现由意外故障而导致服务中止的现象。
5. 便携性:传统存储属于本地存储,保存在本地设备,导致数据有较差的便携性。
云存储的产品形态:
Amazon S3作为对象存储服务。接口如下:
1. List Bucket:列出桶中所有对象。若超过1000,下次以是本次最后一个对象为起点。
2. Put Bucket:创建一个桶,可以选择,所在的数据中心。
3. Delete Bucket:删除一个桶,需要确保内部对象已经被删除。
4. Head Bucket:判断桶是否具有访问权限。
5. Put Object:创建对象加入桶,或修改对象加入桶。如果采用多版本,自动生成唯一版本号。
6. Get Object:读取对象的数据以及元数据(对象长度、哈希值、创建时间)。
7. Delete Object:删除对象。
8.Head Object:获取对象元数据。
S3 支持几GB甚至TB的对象,如果对象过大,提供多次上传接口。
1. Initial Multipart Upload:初始化多次上传,获取多次上传编号
2. Upload Part:上传部分数据,带上上传编号以及本次上传序号。连续两次相同序号,后一次上传将会覆盖。
3. Complete Multipart Upload:完成多次上传,S3会将上传的部分数据链接为大对象。
4. Abort Multipart Upload:中止多次上传请求。

云储存技术:
云存储包括云端+终端。云端即云存储服务器。终端包括PC机、手机、移动多媒体设备等。需要多种技术支持。
1. 摩尔定律:每过18~24个月性能提升一倍。最明显例子为cpux86芯片性能已经是30年前8086的1000倍。
2. 宽带网络:公有云存储是多区域分布是公用系统。现在任何用户可以在任何时间地点都连接到互联网,享受云存储服务。
3. Web技术:Web核心是分享,用户已经可以通过Web享受服务。
4. 移动设备:手机功能越来越完善,降价快,可以拥有多个。
5. 分布式存储、CDN、P2P技术:实现了多存储设备的协同合作。
6. 数据加密、云安全:数据加密使得数据不会被无权限用户访问。
云平台整体架构:
云计算按照服务类型分为三类:基础设施即服务(Iass)、平台即服务(Paas)、软件即服务(SaaS)。
Iaas将硬件等基础设施封装成虚拟机给用户使用。PaaS进一步抽象硬件资源,提供用户应用程序的运行环境。SaaS将特定某些软件封装成服务。
Amazon云平台:AWS是Amazon构建的一个云计算平台的总称。提供了一系列云服务。
1. 计算类:核心产品为弹性计算云EC2。通俗的将,就是提供虚拟机。
2. 存储类:对象存储,表格存储,分布式关系型数据库。
3. 工具支持:提供多种开发语言。
Google 云平台:
是一种Paas服务,使得外部开发者可以通过Google期望的方式使用它的基础设施服务。
GAE云平台包括:
1. 前端服务器:负载均衡、路由。前端服务器将静态内容转发到静态文件服务器。
2. 应用服务器:装载应用代码,并处理接收到的内容请求。
3. 应用管理节点:调度应用服务器,将应用服务器的变化通知前端。
4. 存储区:持久化数据在DataStore,MemCache用于缓存,BlobStore是DataStore的补充,用于存储大对象。
5. 服务区:除了必备的应用服务器以及存储区以外,还包含很多服务。
提供了两种工具:
1. 本地开发环境:GAE中有很多私有API,因此提供了本地开发的Sandbox环境以及SDK工具。
2. 管理工具:提供Web管理工具,用于管理并监控状态。
GAE核心组件为应用服务器托管用户应用程序,存储区提供云存储服务。
1. 应用服务器:GAE不提供虚拟机服务,因此不同应用将受限制“”沙盒“”环境中,应用程序无法执行以下操作:
写入到本地文件系统,必须持久数据到存储区。打开套接字或直接访问其他主机,只能提供网站服务。生成子进程或线程,只能在单个线程几秒处理完。进行其他类型系统调用。
2. 存储区:核心为存储,采用Google Metastore系统。
Microsoft云平台:
1. 计算服务:每个实例是一台虚拟机。
2. 存储服务:Blobl,存储二进制数据。Talbe,存储结构化数据。Azure,将关系形数据库转移来,提供SQL。
3. 连接服务:提供点对点通信。
4. 工具支持:支持多种语言。
-------------------------------- TODO 453~466--------------------------------------
大数据:
MapReduce解决了海量数据离线分析问题,但对于实时性越来越高,流式计算和实时分析系统得到越来越广泛的应用。
大数据概念:
1. 数据量爆发增加:有一个趋势叫新摩尔定律。根据IDC指出的预测,数据每年50%速度增长,每两年加一倍,相当于2年的数据量是之前所有数据量之和。
2. 大数据表示为社会化趋势:社交软件兴起,用户生成的非结构化数据出现。
3. 物联网的数据量更大:收集用户信息,如位置、生活信息等。
大数据的特点:
1. Volume:传统处理级别为GB、TB。当前数据量超过PB级。
2. Variety:数据类型多,出现了图片、声音、视频等非结构化数据。
3. Velocity:数据增长迅速,实时处理。
4. Value:价值密度低。如视频监控,有用的可能只有几秒。
MapReduce:
主控进程Master用于执行任务、调度、任务之间的协调。Map和Reduce工作进程,执行Map和Reduce任务
流程:
1. 从用户提交的程序fork出主控进程,主控进程启动后将任务切分,并选择机器fork出Map或者Reduce进程。
2. 将切分好的任务分配给Map和Reduce进程,任务切分和分配可以并行执行。
3. Map进程执行Map任务,读取文件,将每一个<key, value>执行Map任务。
4. 将输出数据分为R份,之后让Reduce进程获取。
5. Map进程通过心跳向主控汇报,主控进一步将信息通知Reduce。Reduce向Map请求中间结果。这个过程为Shuffle,当获取完所有中间结果后,需要排序。
6. Reduce执行Reduce任务,并将结果写到最终位置,GFS或BigTable。
优化:
1. 尽量将任务分配给离输入文件最近的Map进程。
2. 备份任务,如果某个Map或者Reduce执行太长时间,将会将任务的备份给另一个空闲进程同时执行,防止拖后腿现象。
MapReduce扩展:
Google Tenzing:基于MapReduce构建SQL执行引擎。
Microsoft Dryad:从一个简单的两步工作流,扩展任何函数集的组合,通过有向无环图表示函数之间的工作流。
Google Pregel:用于图模型迭代计算,性能好于MapReduce。
Google Tenzing:构建在MapReduce之上,支持SQL。
整体架构:分布式Worker池,查询服务器,客户端接口,元数据服务器。

1. 查询服务器:连接客户端和worker池的中间桥梁,解析SQL语句并进行优化,发送给Worker池执行。
2. 分布式Worker池:作为执行系统,内部进程会一直运行,随时执行MapReduce任务。
内部包含master和worker节点,worker节点拥有Map和Reduce进程,另外还有master监听者获取master信息。
3. 元数据服务器:存储和获取表格schema、访问控制列表等全局元数据。使用BigTable作为持久化的后台存储。
4. 客户端接口:提供三类客户端接口,包括API,命令行(CLI),Web UI。
5. 存储:worker池执行任务时,需要读取存储服务器。
查询流程:
1. 通过Web UI,CLI或API向查询服务器提交查询。
2. 查询服务器将请求解析为一个中间语法树。
3. 查询服务器从元数据服务器获取元数据,然后建立完整的中间格式。
4. 优化器进行优化。
5. 优化后的物理查询计划由一个或多个MapReduce构成。
6. 空闲worker从master拉取已就绪任务,Reduce会将其写入一个中间存储区域。
7. 查询服务器监控中间存储区域,收集结果,返回给客户端。
SQL运算符映射到MapReduce
1. 选择和投影:Map对元素t如果满足条件,产生(t, t),Reduce直接输出。
2. 分组和聚合:对关系R(A, B, C)求A同一分组下B的和。Map获取(a,b)。Reduce将同一a下b取和。
3. 多表连接:对于R(A, B) S(B, C)进行B相同连接。Map将R都转为(B,(R,a) ) S转为 (B, (S, c))。将相同B放到同一Reduce。 Reduce将其组合。
对于两个表都很大,大小接近采用Sort Merge Join比较好。但要是差距较大,可以采用Hash Join,将每个分区都做一个MR任务,对于MR任务都将小表读入内存即可。
Microsoft Dryad:微软的项目,提供分布式并行计算的平台。
Google Pregel:用于图模型迭代计算,
流式计算:MapReduce处理了离线批处理问题,但无法保证实时性。对于实时性较高的,可以采用流式计算。
原理:MapReduce启动时,数据已经准备好,一般在分布式文件系统上。而流式计算一般数据都没准备好。
流式计算更注重延迟而不是吞吐。
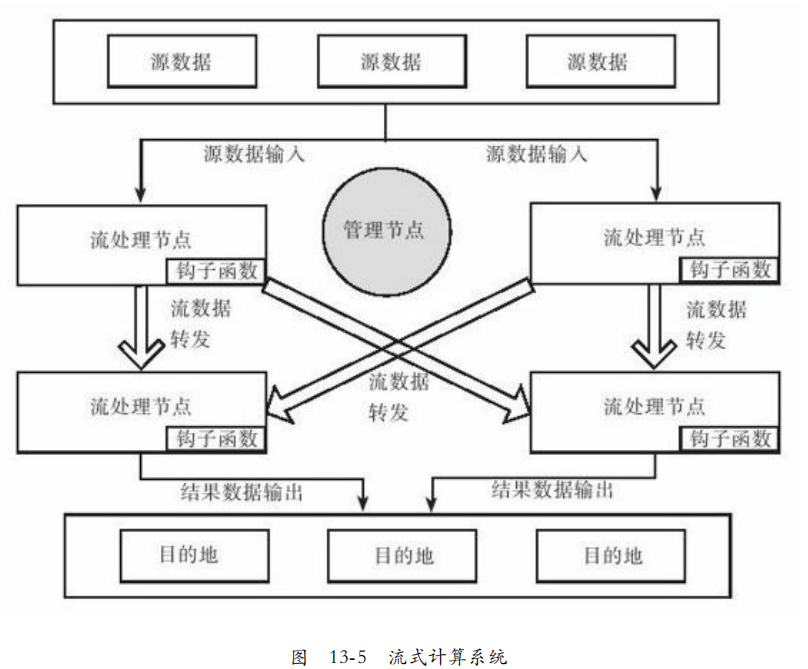
源数据写入流处理节点,流处理节点内部运行用户自定义的钩子函数,处理完发送给下游的流处理节点。系统往往还有管理节点,处理节点的状态。
典型钩子函数:聚合函数,过滤函数。
如果机器故障,下游可能选择等待机器恢复,也可以继续处理,等到恢复以后进行修正。
流处理节点可以选择主备同步,但代价很高,一般流式处理系统对错误有一定的容忍度。
Yaho S4
最初用于提高搜索广告有效点击而开发的一个流式处理系统。
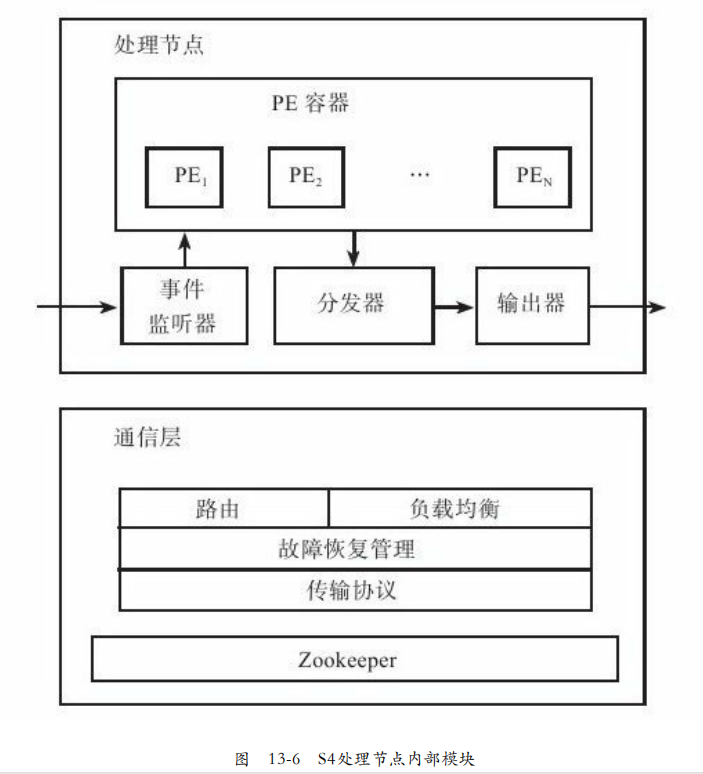
S4的每一个流处理节点称为一个处理节点PN,用于监听事件,当事件到达处理单元PE开始处理。如果PE有输出需要调用通信层接口进行事件的分发和输出。
事件监听器负责监听事件,并转交给PE容器(PEC),由PEC交给合适的PE。
通信层负责集群路由、负载均衡、故障恢复管理、逻辑节点到物理节点的映射。
Twitter Storm
广泛使用的流失计算系统。

Nimbus:负责资源分配、任务调度、监控状态。
Supervisor:负责接收分配的任务,启动和停止worker进程。
Worker:运行spout/bolt组件的进程。
Spout:运行元数据组件
Bolt:接收数据,然后执行处理。
实时分析:对于查询模式单一,可以采用MapReduce预处理导入到在线系统。对于复杂的模式,只能通过并行数据库+云计算来分析结果。
并行数据库往往采用MPP架构。作为不共享结构,每个节点运行自己的操作系统,数据库。每个节点CPU不能访问其他节点内存,只能网络交互。
常见的数据分布算法:
1. 范围分区:按照范围划分数据。
2. 哈希分区:根据哈希函数将元组分配给节点。
Merge操作符:用于合并节点。
EMC Greenplum
Greenplum是EMC公司的一款采用MPP架构的OLAP产品。
架构:包含Master服务器和Segment服务器。
每个表分布在所有节点。Master服务器对表的某个或多个列进行哈希,分布到Segment服务器中。
支持SQL和MapReduce访问。
并行查询优化器:负责将用户的SQL或者MapReduce请求转换为物理执行计划。
除了传统物理计算符,包括表格扫描、过滤、聚集、排序、联表,生成并行计算符。
广播:每个计算节点将目标数据发送给其他节点。
重新分布:类似shuffle,将数据哈希后分配给其他节点。
汇总:将目标数据发送给某个节点。
HP Vetica
Google Drenel

 浙公网安备 33010602011771号
浙公网安备 33010602011771号