

学习笔记
2.13~15
使用率:使用的百分比
饱和率:排队的占比
vmstat:虚拟内存和物理内存
mpstat:cpu使用情况 【打印所有cpu信息 => mpstat -p ALL 1 】
prstat:查询物理内存和虚拟内存使用情况。
iostat:磁盘使用情况
netstat:网络接口统计
sar:各种各样统计
dtrace:分析IO的栈跟踪
uptime: 机器最近的负载
dmseg:查询内存等问题
pmap: 进程的内存段和使用统计
strace:分析进程系统调用的CPU消耗
tcpdump:网络跟踪包
pidstat:每个进程的线程资源使用
taskset:绑定进程在某几个cpu
/proc:进程信息
/sys:系统信息
7.18号
(1)路由,NAT
对于一个ICMP的以太网报文格式: |目的MAC|源MAC|目的IP|源IP|ICMP包|
当主机A发送ICMP包到主机B。假设源为 A-IP,目的为 B-IP。源MAC为 A-MAC,目的为B-MAC。
但A和B不在一个网段,因此A需要将其发送到网关,其中网关的MAC地址为 WG-MAC-A。
因此A需要将其发送到网关格式为:| WG-MAC-A |A-MAC| B-IP | A-IP | ICMP |
路由器在接口A处接收,并判断需要从B口发出。| B-MAC | WG-MAC-B | B-IP | A-IP | ICMP |
最终主机B收到后,进行返回发送。
因此,数据跳转过程中,改变的是MAC,IP始终不变。(二层网络通过MAC交互,三层网络通过IP交互)
NAT作为网络地址转换:
如图所示,同一个路由器下,私网IP不同,但不同路由器下可能存在相同情况。
若主机HOSTA(IP:192.168.1.2),访问 XX-IP时,到达路由器的格式:|MACRA|HOSTA| XX-IP |192.168.1.2|ICMP包
但如果路由器继续使用192.....的IP发到公网,由于很多路由器下都存在该IP,很难找到源头。
NAT则是将地址进行转换,将源IP替换为WAN口的IP。同时记录NAT转换信息,保证回复的数据能不丢失,即SNAT。同理DNAT则是更改目的地址IP。
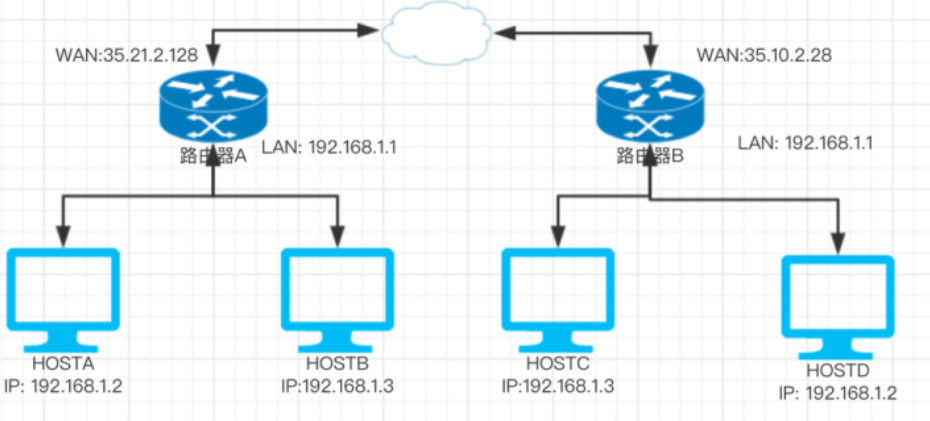
参考(关于路由):https://zhuanlan.zhihu.com/p/28289080
7.12号
(1)vim配置
vim的配置:https://github.com/humiaozuzu/dot-vimrc
let g:go_version_warning=0 // 防警告
:colorscheme evening // 设置背景,此外还有很多
colorscheme ron // 在.vimrc 里直接设置成自动
参考:https://www.zhihu.com/question/20151659/answer/29926050
7.6号
(1)git复习
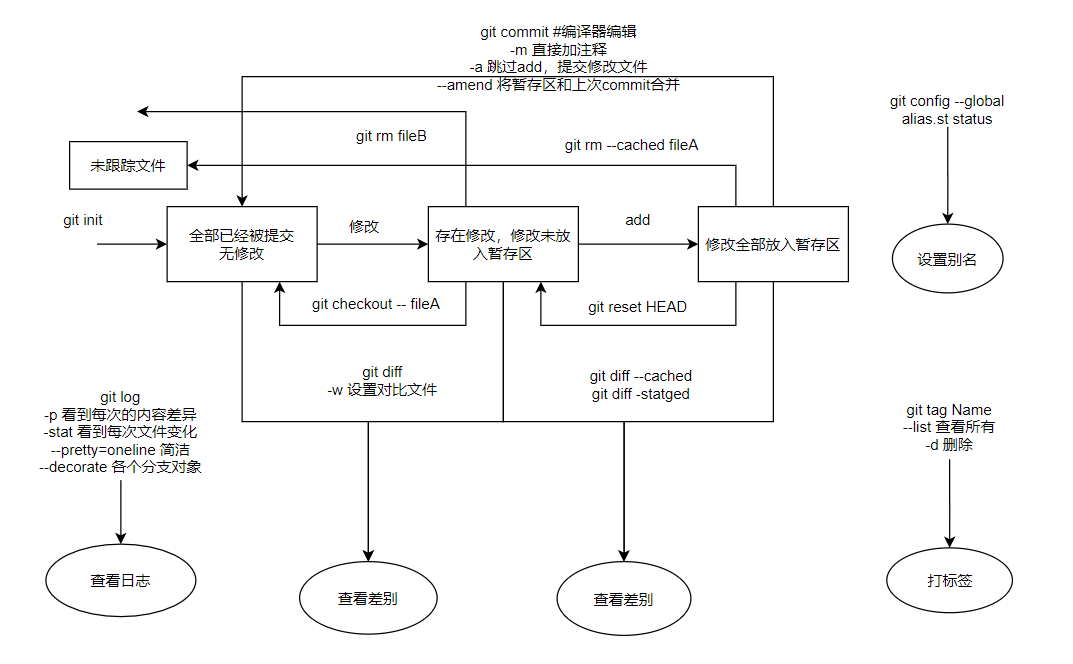
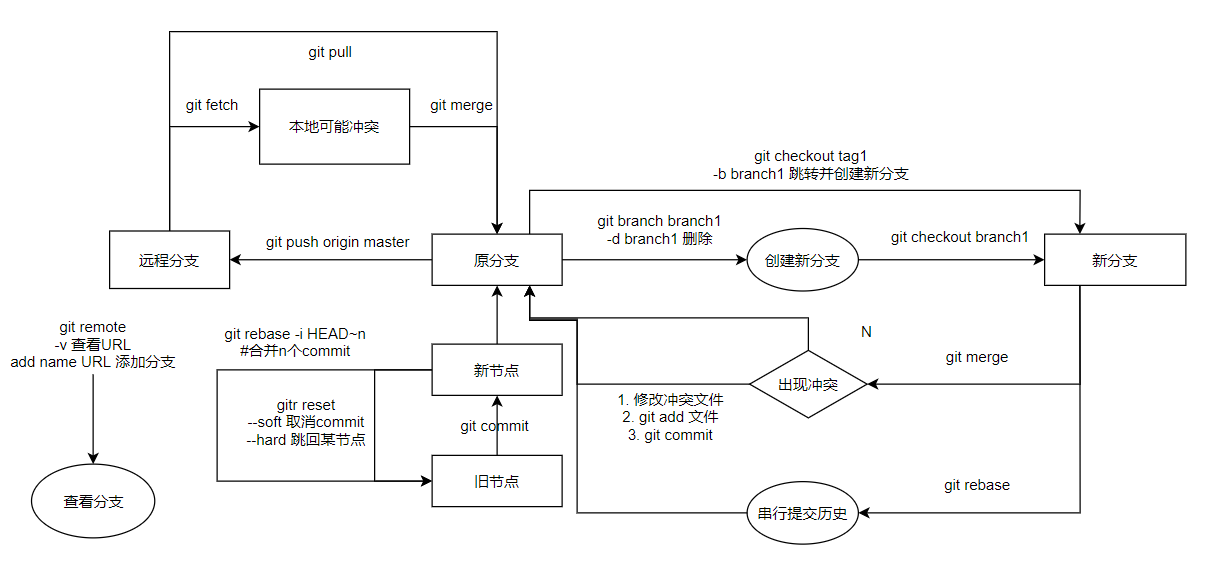
参考《pro git》:https://git-scm.com/book/zh/v2
7.1号
(1)overlay fs
overlay fs作为堆叠文件系统。不直接参与磁盘的划分,而是在将源文件系统进行“合并”。
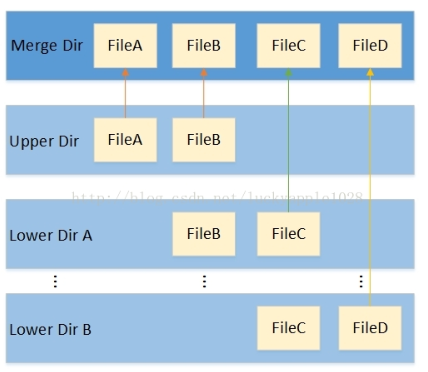
overlay fs基本结构
如图,多个Lower Dir和一个Upper Dir可以来自不同的目录,最终“合并”后以Merge Dir展示出来。(Merger 下无法辨别属于Lower 或者 Upper)(Lower 可以只有一个)
对于Lower DIr和Upper Dir存在层级关系,Upper>Lower Lower内部自定义层级高低。相同文件名时,低层级文件被隐藏。相同目录下自动合并内部文件。
对于各层级中只有Upper是可读写,其余只可读。当Merger dir读写Upper 时,自动修改Upper。当Merger dir下读写Lower时,自动复制到Upper下,并进行修改。(此时Lower文件内容没变,只是被隐藏)
因此,overlaysf的基本特性:同名目录合并,高层隐藏底层同名文件,lower dir文件写时拷贝。
应用:
对于用户A和B同时使用共享文件,可以将共享文件设置为lower,私有文件为upper,防止共享文件被篡改。
对于容器,可以将镜像层(image layer)设置为lower,容器层(container layer)作为upper,挂载到容器merge挂载点。
用法:
mount -t overlay -o <options> overlay <mount point>
<mount point>:作为最终挂载点,即操作的目录。
<options>包括:
lowerdir=<dir>:需要挂载的lowerdir目录,支持多个,用“:”间隔,优先级从高到低。
upperdir=<dir>:挂载的upperdir目录。(如果没有upper只有lower,那么挂载merge后只有只读属性)
workdir=<dir>:用于存放临时和间接文件的目录。
default_permissions:
redirect_dir=on/off:开启/关闭Redirect directory特性,开启后支持merge和lower目录使用rename/renameat系统调用。
index=on/off:开启或关闭index特性,开启后可避免hardlink copyup broken问题。
如:mount -t overlay -o lowerdir=lower,upperdir=upper,workdir=work overlay merge
lower目录包括:lower。upper目录为 upper。临时work目录为work。最终挂载点为merge。
对于删除lower下的文件,会在upper下创建一个Whiteout文件,Whiteout文件会屏蔽底层的同名文件,该文件在merge下不可见。
work的用途:可以保证一些操作的原子性。
如删除一个upper和lower同时存在的文件,为了防止upper删完,却未添加whiteout。先在work下添加whiteout,然后与upper交换删除的文件名,之后删除work下的文件即可。
参考(overlay fs原理):https://blog.csdn.net/qq_15770331/article/details/96699386
参考(overlay fs操作):https://www.cnblogs.com/arnoldlu/p/13055501.html
(2)硬链接与软链接
文件:在Linux分为用户数据(user data),元数据(metadata)。用户数据是记录文件真实内容的地方。元数据则是文件的附加属性,如文件大小、创建时间、所有者信息等。元数据的inode号作为文件的唯一标识。
硬链接:拥有相同inode仅仅文件名不同的文件,删除链接文件不影响其他相同inode的文件。
ln oldfile newfile
软链接:存放的是路径名的指向,拥有独立的inode号以及用户数据块。删除软链接不影响原文件,删除原文件后软链接为死链。
ln -s old.file soft.link
参考(Linux、inode、硬链接-软链接):https://www.ibm.com/developerworks/cn/linux/l-cn-hardandsymb-links/index.html
(3)squashfs
squashfs 是一个只读文件系统,可以将文件系统压缩在一起,存放到设备。
用法:
mksquashfs dir dir.squashfs -e command/hello.c(将dir压缩起来,变成只可读的dir.squashfs。其中-e可以排除不想挂载的文件)
mount -o loop dir.squashfs /mnt/squash/ (查看时再将dir.squashf 挂载到一个目录如:/mnt/squash/下)
参考(squashfs用法):http://blog.yixinu.com/archives/1150.html
5.13号
(1)python httpserver获取远程文件
python -m SimpleHTTPServer 8114 // 开启8114端口,作为服务器 wget http://127.0.0.1:8114/ // 就可以获取启动服务器目录下的文件
5.5号
(1)CMakeLists.txt文件
CMakeList.txt用于生成makefile。
cmake_minimum_required( VERSION 2.8 ) // 要求cmake最低版本,不是必要的 PROJECT(project_name) // 定义工程名称,同时隐式的定义了<projectname>_BINARY_DIR以及<projectname>_SOURCE_DIR路径为当前路径 SET(CMAKE_C_COMPILER g++) // 定义了编译器 message( "what you want to print" ${HELLO_BINARY_DIR}) // 用于输出,用${}引用变量 include_directories(${HELLO_SOURCE_DIR}/include) // 定义非标准库头文件要搜索的路径,用于包含头文件 // 子项目可以用于生成库 SET(LIBRARY_OUTPUT_PATH ${HELLO_SOURCE_DIR}/lib) // HELLO项目,设置库输出路径为HELLO_SOURCE_DIR/lib ADD_LIBRARY(libname [SHARED|STATIC|MODULE] // 定义生成库的名字为libname,类型为shared/static/module,需要的文件为source..... [EXCLUDE_FROM_ALL] source1 source2 ... sourceN) target_sources(<target> // 添加源文件 <INTERFACE|PUBLIC|PRIVATE> [items1...] [<INTERFACE|PUBLIC|PRIVATE> [items2...] ...]) // 主项目生成可执行文件. SET(SRC_LIST main.cpp) // 定义变量 link_directories(${HELLO_SOURCE_DIR}/lib) // 定义了库文件所在位置,用于查找库的目录。 ADD_EXECUTABLE(hello ${SRC_LIST}) // 生成可执行文件 target_link_libraries(${HELLO_SOURCE_DIR}/lib) // 定义链接时需要的库文件。


参考(包含上述举例):http://www.cppblog.com/Roger/archive/2011/11/17/160368.html
参考(含有较全命令):https://www.jianshu.com/p/aaa19816f7ad
5.4号
(1)makefile
makefile的由来:对于一个项目很多文件,编译成库时,我们需要先挨个编译成.o。然后链接起来。
每次都要挨个编译很麻烦,因此可以写成.sh的形式,每次运行.sh即可。
但是通常有时仅仅改了部分文件,.sh每次会把所有文件重新编译(当然可以设置,旧文件不编译,很麻烦),因此采用makefile。
如下图sample1,定义了依赖。如:foo.o依赖foo.c,只要依赖的文件没改就不需要重新编译。最后将其链接起来。


如下图sample2所示:定义了宏,减少了不必要的重复代码。
如下图sample3所示:$@定义了依赖的对象,$^代表被依赖对象。
如下图sample4所示:通过通配符,进一步减少代码。



如下图sample5所示:根本不需要自己定义上面一堆,gnumake已经准备好了。
wildcard作为扩展通配符,$(wildcard *.c)可以获得当前工作目录下所有.c文件

举例场景:foo.h代表foo.c的对外接口,bar.h代表bar.c的对外接口,main.c使用了foo.h和bar.h,common.h作为通用接口提供给所有.c文件使用。
该场景下sample1有误,因为main.c还需要依赖foo.h,当foo.h更改时,main.o也需要重新编译
如下图sample4+所示:$<代表依赖对象只有列表的第一个文件。
但如此更改,每当引用头文件改变,就需要更新makefile。幸好这个复杂的依赖关系,编译器都知道。
当执行gcc -MM foo.c,自动生成foo.o:foo.c foo.h comon.h。如下图sample5所示,先生成依赖,再根据依赖生成文件。
其中.d为生成的依赖文件,include将依赖文件扩展到makefile,-include代表可以包含不存在的文件


为了解决跨平台问题,通常设置如下图左。但这个事情跟makefile本质没有关系,因此通常采用如下图右,configure自动配置参数。


参考:https://zhuanlan.zhihu.com/p/29910215
4.28
(1)gtest简单代码测试。
// hello.h 文件,声明了函数 #include<stdio.h> int mul(int x, int y); int add(int x, int y); int wrong_add(int x, int y); // hello.cpp 文件,实现了函数 #include<stdio.h> #include"hello.h" int mul(int x, int y) // 乘法 { return x*y; } int add(int x, int y) // 加法 { return x+y; } int wrong_add(int x, int y) // 错误加法 { return -1; } // hello_test.cpp 文件,实现了hello文件的测试 #include "hello.h" #include "gtest/gtest.h" TEST(TESTMUL, TRUE) { // 测试乘法 EXPECT_EQ(10, mul(2, 5)); } TEST(TESTADD, TRUE) { // 运行时理应正常 EXPECT_EQ(10, add(4, 6)); } TEST(TESTADD, WRONG) { // 运行时理应会出错 EXPECT_EQ(10, wrong_add(4, 6)); } int main(int argc, char** argv) { testing::InitGoogleTest(&argc, argv); return RUN_ALL_TESTS(); }
通过命令进行编译、执行:g++ -o demo hello_test.cpp hello.h hello.cpp -lgtest -lpthread
上文测试,由于会出错,结果如左下图。如果去除EXPECT_EQ(10, wrong_add(4, 6))程序就不会出错,结果如右下图
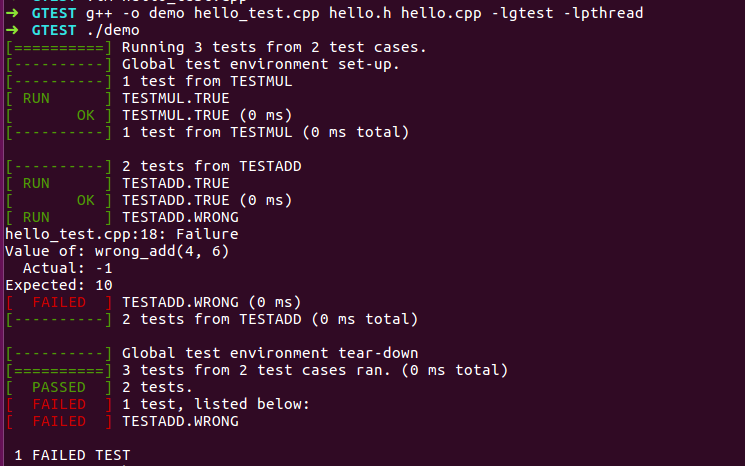
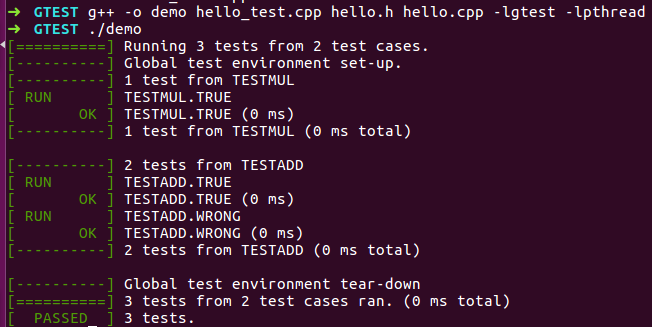
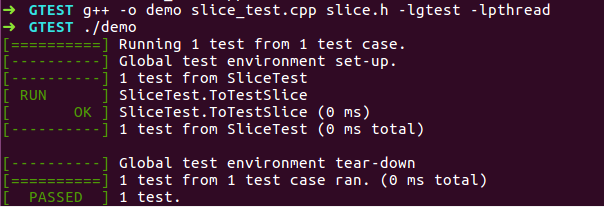
(2)TEST_F
对于某些对象,想进行多次测试,可以通过创造夹具,进行测试。
// slice.h 文件,创建了一个类似string的类 #include <string.h> #include <string> class Slice{ public: Slice() : data_(""), size_(0){} Slice(const char* s, size_t n) : data_(s), size_(n) {} const char* data() { return data_; } size_t size() { return size_; } private: const char* data_; size_t size_; }; // slice_test.h 文件,用于测试slice.h #include "gtest/gtest.h" #include "slice.h" class SliceTest : public testing::Test { public: Slice slice_; }; TEST_F(SliceTest, ToTestSlice) // 第一个参数使得每个测试都拥有了相同的配置 { ASSERT_TRUE(slice_.size() == 0); } int main(int argc, char** argv) { testing::InitGoogleTest(&argc, argv); return RUN_ALL_TESTS(); }
4.27号
(1)gtest
用于测试类或者函数。
通过断言,来判断结果是否符合预期。
其中ASSERT若失败,是直接退出。EXPECT失败,仍然继续执行。


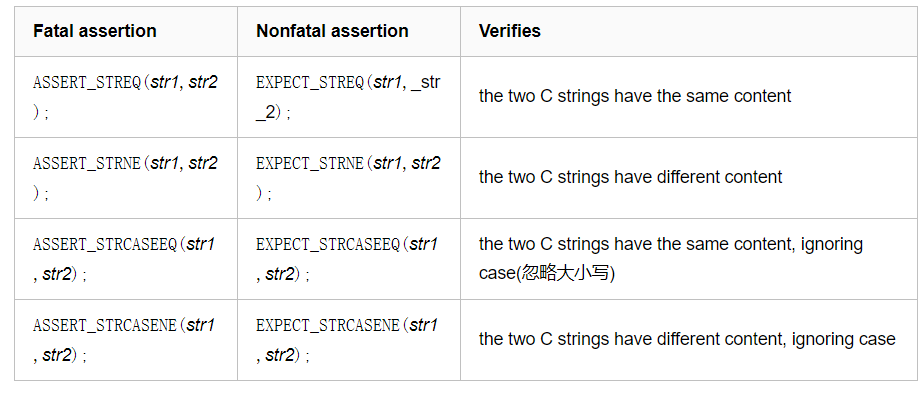
参考(ubuntu安装方式): https://www.cnblogs.com/Jessica-jie/p/6704388.html
参考(内涵测试代码):https://blog.csdn.net/qq_36251561/article/details/85319547
参考:https://www.cnblogs.com/kex1n/p/8981552.html
4.1号
(1)Nginx
Nginx:高性能的HTTP和反向代理服务器。
代理分为:
1. 正向代理:对于某些不能直接访问的目标(如:谷歌),需要通过某个能访问该目标的服务器进行传达。特点是:服务器知道来自哪个代理服务器,但不知道是哪个客户端。正向代理隐藏了客户信息。
2. 反向代理:对于某些服务器经常被访问而采用了分布式部署。特点是:屏蔽了服务器的信息。通过反向代理服务器优化负载。
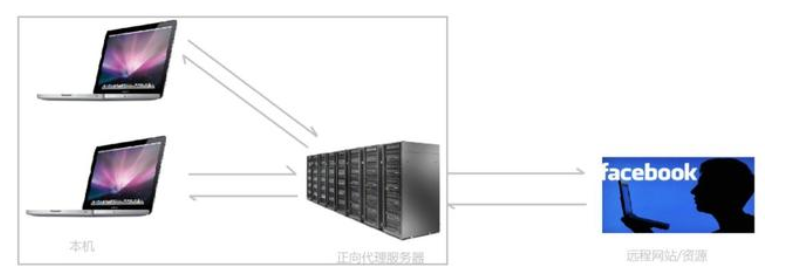
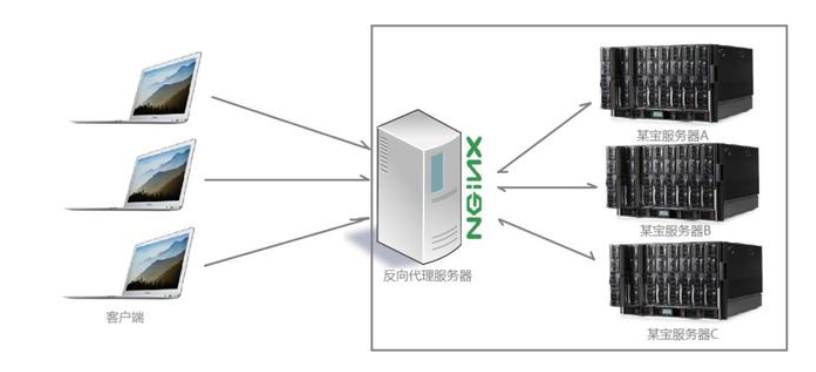
负载均衡:根据规则来分发请求。
硬件负载均衡:也叫硬负载,稳定性安全性好,但成本较高很少使用。
软件复杂均衡:也叫软负载。
1. 轮询:将请求按顺序逐一发给后端服务器,若后端服务器出现宕机可以立即将其剔除出队列。同时可以为服务器分配权重,来调整不同服务器上的分配率。
2. ip_hash:将请求根据hash结果分配给服务器。
3. fair:智能调整,根据后端处理时间来调整。
4. url_hash:根据url进行hash分配给服务器。
参考:https://baijiahao.baidu.com/s?id=1652608869911988442&wfr=spider&for=pc
3.29号
(1)vmware共享文件
1. 虚拟机关机
2. 虚拟机-设置-选项-共享文件夹-自己选择主机文件位置。
3. 将主机所有共享文件夹放到目录(/home/lmh/Share下) sudo /usr/bin/vmhgfs-fuse .host:/ /home/lmh/Share -o subtype=vmhgfs-fuse,allow_other
3.26号
(1)cgroups
包含三个组件:
1. 控制组:提供一套机制用于对一组进程的资源控制。资源的限制定义在控制组上,但某个进程加入控制组,则自动受到该控制组上面限制的规则(增加subsystem的参数配置)。
2. 子系统(subsystem):作为资源控制器,可以通过lssubsys -a查看内核支持哪些资源的控制。用来设定限制。
3. 层级树(hierarchy):将cgroups串成树形结构,使其可以做到继承。(通过虚拟文件系统的方式暴露给用户)
三者的联系:
1. 创建层级树后,所有进程都会加入到层级树的cgroup的根节点。
2. 一个subsystem只能附加在一个hierarchy上。
3. 一个hierarchy可以附加多个subsystem。
4. 一个进程可以作为多个cgroup成员,但必须在不同层级树下。
5. fork出的子程序默认在父进程的cgroup,但可以进行移动。
参考:https://zhuanlan.zhihu.com/p/61155161
3.25号
(1)mysql
ubuntu安装Mysql
sudo apt-get install mysql-server // 服务端
sudo apt-get install mysql-client // 客户端
sudo apt-get install libmysqlclient-dev // 程序编译时链接的库
mysql -u root -p // 登录 -u作为用户名 -p之后为密码
mysql -h 127.0.0.1 -P 3306 -uroot -p // -h为远程IP,-P为端口号(默认3306)
参考:https://www.cnblogs.com/lfri/p/10437694.html
3.24号
(1)VLAN
VLAN即 虚拟局域网:作为一个广播域,发送的广播只有同VLAN的成员才能听到。减少了不必要的广播风暴,提升了不同工作组的安全性。
广播风暴:若不划分VLAN,任何一个机器发送广播,所有客户机都能收到,影响整体网络的传输性能。
因此划分VLAN可以限制广播范围。
因此不同VLAN之间传播就需要“VLAN间路由”。可以是 普通路由器,也可以是三层交换机。
VLAN的划分方式:
1. 静态VLAN:基于端口,需要将每个端口与VLAN映射记录。若机器改变端口,就要改变映射,机器过多,操作无比繁杂。
2. 动态VLAN:分为基于MAC、子网、用户。
基于MAC:记录某个端口连接的计算机上的MAC地址,将该MAC划分到相应VLAN下(不关心端口,即使端口改变,这个MAC的划分也不变)。
基于子网:根据IP地址来划分。只要ip地址不变,vlan就不变。
基于用户:根据windows的用户名。
不同VLAN之间采用汇聚连接,交换机只发送同一VLAN下,但汇聚链接端口可以转发多个不同VLAN的通信。
同一VLAN下通信:A发送ARP请求,交换机接收到,发现是同一VLAN,获取B所在端口,将数据帧转发给B。
不同VLAN下通信:A根据IP地址发现不在同一网段,因此先获取路由的MAC地址。将MAC设为路由器地址,IP为目标B地址发送给路由器。交换机将请求发送给路由器。由于路由器能转发多个不同VLAN
数据,因此可以直接从B所在VLAN接口转发即可,同时MAC地址也转为B的MAC地址。最终B收到数据帧。
可以看出,对于VLAN间通信,即使在同一台交换机,也需要经过:发送方 -> 交换机 -> 路由器 -> 交换机 -> 接收方
参考(VLAN,VLAN间转发):https://baijiahao.baidu.com/s?id=1628398215665219628&wfr=spider&for=pc
(2)拓扑 两层/三层 架构
指网络结构中,按照逻辑拓扑结构进行分类。
三层架构指:核心层、汇聚层(两层架构没有本层)、接入层。
两层:只是将未知MAC的数据包进行广播,在大规模网络架构会产生网络风暴。一般仅限于局域网。
三层(三层交换机):可以通过IP实现跨网段通信。核心层作为数据传输的通道。汇聚层连接网络的核心层和接入的应用层,并能够划分VLAN。接入层作为用户的终端。
参考:https://blog.csdn.net/q235990/article/details/88178963
3.23号
(1)CPU Cache
用于对内存数据的缓存,速度在 内存与寄存器之间。分为 L1 Cache, L2 Cache, L3 Cache。对于指令部分放在I-Cache,对于数据部分放在D-Cache。
从延迟上看,做一次乘法需要3个指令周期,而一次内存访问需要167个指令周期。
CPU接收到命令后会依次寻找,L1,L2,L3,内存,磁盘。
cache写机制:Write through和Write back。(硬盘也存在这两个机制)
1. Write through:数据会写Cache以及后端存储。操作简单,数据确保安全,但速度慢。
2. Write back:数据只写到Cache,只在Cache被换出时,再写到后端,速度快,但如果发送掉电,数据可能丢失。
cache替换策略:最近最少使用,FIFO,随机替换等等等。
cache映射:
1. 直连:每个主存块只能拷贝到Cache的一个位置上(如:取模的方式)硬件简单,命中率低,空间利用率低。
2. 全相连:每个主存块可以放到任意Cache。命中率高,利用率高,硬件复杂,成本高。
3. 组相连:将主存块存储到唯一Cache组的任意一行。(对应组是确定的,组内不确定)
缓存的结构:
1. 缓存分为S个组。
2. 每组有E个缓存行Cache line。
3. 每行有一位标记是否是dirty,t位用来辅助缓存地址的定位,标识缓存块的唯一地址,有一个B个字节的缓存快block。
4. 高速缓存的大小C = B*E*S。
因此,查找时,先进行组选择,再进行行匹配,最后根据B位,计算出所在块的偏移。
参考:https://zhuanlan.zhihu.com/p/60843893
参考:https://www.cnblogs.com/jokerjason/p/10711022.html
(2)内存缓存
将部分内存空间用作缓存。
(3)限流
对于特定场景,限制一定时间内只允许执行一定次数。(如:鼠标一次移动可能产生无限个位置状态,如果中间每个状态都切换,可能cpu卡死在鼠标上了)
1. 计数器算法:如1分钟只处理100个。按照每分钟开始计算有多少了,
但如果精度不够,可能导致超出。如前一分钟最后一秒,和后一分钟第一秒之和可能就会超限。
可以采取 滑动窗口:将每次操作放入队列,队列容量100个,如果队首跟本个时间 超过1分钟,则执行并队首出队。
2. 令牌算法:桶内定期放置令牌,对于请求必须现申请令牌才能执行,执行后删除令牌。
3. 漏铜算法:对于超出的进行丢弃。
3.22号
(1)TCMalloc
用于替代系统的内存分配。
TCMalloc将虚拟内存空间划分为n个同等大小的Page,每个page默认8KB。又将连续的n个page称为一个Span。
PageHeap类用来处理申请内存的操作,并提供一层缓存。以span为单位申请,申请到的span可能有一个到多个page。
TCMalloc将内存分配分为3类:
1. 小对象分配,(0, 256KB]
2. 中对象分配,(256KB, 1MB]
3. 大对象分配,(1MB, +∞)
小对象分配
Size Class:对于256KB以内的分配,按照大小划分了88个类别,如8字节,16字节.....。对于申请时将内存向上取整。碎片控制在12.5%
ThreadCache:对于每个线程,TCMalloc都为其保存了一份单独的缓存,称为ThreadCache。每个ThreadCache对于每个Size Calss都有一个独立的FreeList,缓存了空闲对象。
小对象的分配直接从相应FreeList中返回一个空闲对象,回收也直接放回对应的FreeList。由于单线程使用,所以不需要加锁。
CentralCache:对于ThreadCache的空闲对象来自CnetralCache。CentralCache中每个size class都有一个独立链表来缓存空闲对象,供各个线程从中取用空闲对象。由于所有线程公用,因此需要加锁。
PageHeap:CentralCache中的空闲对象来自PageHeap。当CentralCache空闲对象不够用,需要向PageHeadp申请一块内存。
PageHeadp对于申请内存块span大小采取两种策略:128个page以内的span,每个大小用链表记录。超过128个page的span,用set保存。
内存回收:当free或delete时,小对象直接插入ThreadCache中对应的Class Size。只有特定情况会返回CentralCache甚至还给PageHeap再还给系统。

中对象分配:超过256KB不超过1MB(128个page)
对于申请的内存,向上取整到page (可能产生1B~8KB的内部碎片)
如需要k个page,从 k page开始找到非空链,并将多余k page的部分放回链中。若找不到则按大对象处理。
大对象分配:超过1MB
对于超过128page的span,缓存在按照page个数大小有序的set中。
如需要k个page,则二分找到第一个大于k个的page,若找不到则通过sbrk或mmap向系统申请。

参考(TCMalloc安装使用,以及原理):https://zhuanlan.zhihu.com/p/51432385
参考(TODO):https://www.jianshu.com/p/11082b443ddf
3.21号
(1)NFS
让不同机器,操作系统通过网络共享文件。
对于NFS服务器设置好的共享文件,拥有访问NFS服务器权限的客户端,就可以将其挂载在自己文件系统的某个挂载点。
NFS只提供了基本文件处理功能,不提供TCP/IP数据传输功能。因此需要RPC协议实现TCP/IP数据传输功能。
RPC:正常情况客户端服务器通信需要自己利用套接函数编写完整的网络通信协议。若使用RPC,双方仅需用调用RPC接口函数就可以实现通信。
调用RPC启动时,会开启端口为客户端服务。由于端口号不固定,因此需要RPC提供查询端口的方式,通过端口映射器,固定监听UDP 111端口。客户端通过访问该端口,查询服务器所使用的端口。
NFS服务器主要进程:
1. rpc.nfsd:管理客户端能否接入NFS服务器进行数据传输。监听TCP/UDP 2049端口
2. rpc.moutd:管理和维护NFS文件系统,根据设定的权限决定是否允许客户端挂载指定共享目录。
3. rpc.lockd:提供文件锁,防止多个客户端写一个文件。
4. rpc.statd:负责检查数据一致性。
5. rpcbind:端口映射进程,监听UDP 111端口。

参考:https://zhuanlan.zhihu.com/p/31626338
(2)HDFS
作为GFS的实现。Hadoop的核心项目。分布式数据存储的基础。
优势:高容错性,可构建在廉价机器。适合批量处理。适合大数据处理。流式文件访问。
局限:不支持低延迟访问。不适合小文件存储。不支持并发写。不支持修改。
HDFS架构:
1. HDFS客户端:提供命令来管理,访问HDFS。
与DataNode交互,读写数据。读取时根据NameNode获取数据位置。写入数据,Client将数据分为多个Block,进行存储。
2. NameNode:即Master。
管理HDFS名称空间。管理Block映射信息。处理副本策略。处理客户端读写请求。
3. DataNode:即Slave。NameNode下达命令,DataNode来执行。
存储实际的数据块。执行读写操作。
4. Secondary NameNode:并非NameNode的热备。当NameNode挂掉,不能立马顶替NameNode。
辅助NameNode,分担工作量。定期合并fsimage和fsedits,并推送给NameNode。帮助恢复NameNode。
扩展:
Hive与Hbase的数据一般都存储在HDFS上。HDFS为他们提供了高可靠性的底层存储支持。
Hive:不支持修改数据的操作,基于数据仓库,提供静态数据的动态查询。使用类SQL语言,底层编译成MapReduce,运行在Hadoop上,数据存储在HDFS。
Hbase:即Hadoop数据库,适合非机构化存储。基于列式存储,利用HDFS作为文件存储系统。(如BigTable基于GFS)
参考:https://www.jianshu.com/p/f1e785fffd4d
(3)Ceph
作为分布式文件系统,提供文件存储(Ceph FS),块存储(RBD)和对象存储(RGW)。如下图左
RADOS层次作为对象存储系统,进入Ceph的数据都由RADOS负责存储到OSD。RADOS层提供了LIBRADOS接口供上层调用。
PG:作为Pool最基本的单位,实现冗余策略,数据迁移,灾难恢复等功能。
Pool:Ceph对PG进行逻辑划分,每类将存储到各自默认存储池,以便更好的管理数据。
OSD:数据存储和维护,并与Monitor通信。
Monitor:接收信息,维护整个系统状态。
以对象存储为例:客户端写入 RGW object >> RADOS object >> Pool >> PG >> OSD 如下图右
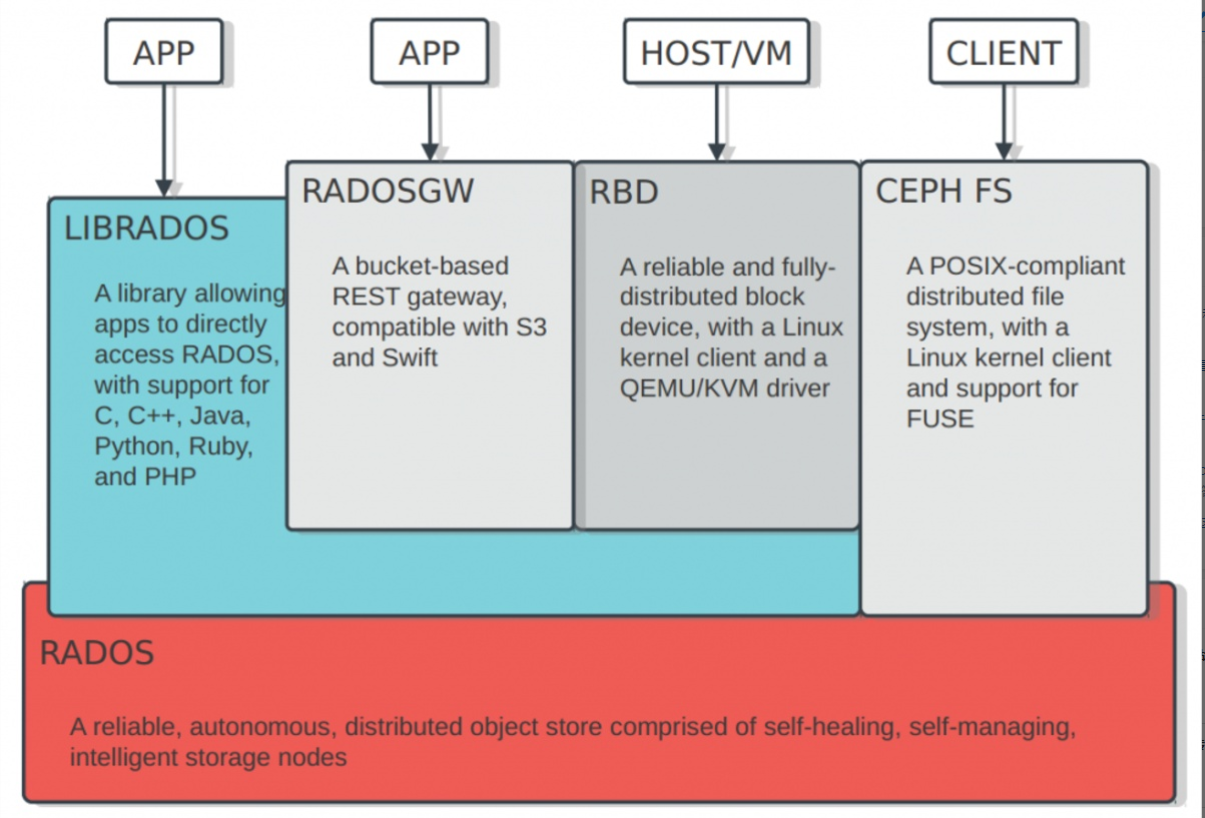

特点:
1. 高性能:采用CRUSH算法,数据均衡,并行度高。提供容灾的隔离。支持上千节点的规模。
2. 高可用性:副本数可以灵活控制。故障分隔,数据强一致性。故障自动修复。无单点故障。
3. 高可扩展性:去中心化,扩展灵活,随着节点线性增长。
4. 功能丰富:提供块存储,文件存储,对象存储。支持自定义接口。
参考:https://www.zhihu.com/question/50803995/answer/468830791
参考:https://www.cnblogs.com/zzzynx/p/11010870.html
3.20号
(1)EXT4历史
MINIX文件系统:用于早期非常小的类 Unix 系统。
最多能处理 14 个字符的文件名,并且只能处理 64MB 的存储空间。
EXT文件系统:在Linux首次发布1年后发布。
可以处理高达 2 GB 存储空间并处理 255 个字符的文件名。
EXT2文件系统:提供了 GB 级别的最大文件大小和 TB 级别的文件系统大小。
但当数据写入到磁盘的时候,系统发生崩溃或断电,数据将发生损坏。同时单个文件存储多个地方(碎片),会使性能发生损失。
EXT3文件系统:由于EXT2若发生断电等行为,会产生不一致状态(事情完成一半),因此采用了日志的方式。 Linux 内核中实现了三个级别的日志记录方式
日志(journal):最低风险,将数据和元数据提交给文件系统之前,写入日志。
顺序(ordered):多数Linux默认模式,将元数据写入日志,写入数据,将元数据更新到文件系统
回写(writeback):最不安全,类似顺序模式只有元数据写入日志,但元数据写日志与写数据的顺序不固定(根据性能最优来)。
使用了16位内部寻址,对于 4K 块大小的 ext3 在最大规格为 16 TiB 的文件系统中可以处理的最大文件大小为 2 TiB。
EXT4文件系统:与EXT3出现了很多明确的差别。
1. 向后兼容:尽可能向后兼容EXT3,使得EXT3可以原地升级为EXT4.
2. 大文件系统:使用 48 位的内部寻址,可分配 16 TiB 大小的文件,文件系统大小可达1 EiB
3. 分配方式的改进:对于存储块写入前对存储块的分配进行了改进。可以提升读写性能。
区段:一系列连续的物理块,用利于减少给定文件所需的inode数量,显著减少碎片。
多块分配:EXT3对每一个新分配块调用一次分配器,多个写同时打开分配器很容易产生碎片。因此EXT4采用延迟分配,允许合并写入。
持久的预分配:为文件预分配磁盘空间时,大部分文件系统要写入0。EXT4允许使用fallocate(),保证了可用性,不用先写入。
延迟分配:允许等待分配,直到数据准备好要提交到磁盘。(EXT3即使数据正在往缓存写,也会立即分配)
4. 无限的子目录:EXT3仅限制32000个,EXT4彻底无限。采用HTree 索引来减少大量子目录的性能损失。
5. 日志校验:对于控制器或自带缓存的磁盘可能脱离写入顺序,从而破坏日志顺序。虽然可以采用障碍(barrie),但仍存在为了性能不遵守写入障碍的可能。
因此通过日志校验,来判断某些条目是无序或无效的。
6. 快速文件系统检查:EXT3会在fsck调用时检查整个文件系统(包括删除或空文件)。EXT4标记了inode表示未分配的块和扇区,减少了运行fsk的时间。
7. 改进的时间戳:EXT3采用了一秒的粒度。EXT4采用了纳秒的粒度。
8. 在线碎片整理:EXT2只能在文件系统未挂载时脱机运行。EXT3甚至可能导致数据损坏。
参考(EXT的历史):https://zhuanlan.zhihu.com/p/44267768
3.19号
(1)VFS文件系统
四种对象:
1. superbook:文件系统基本的元数据。文件系统类型,元数据等。
保存了文件系统基本的元数据,一般存储在设备的开头。挂载后会读取superbook,并常驻内存。
由于Linux可以支持多个文件系统,因此可以通过superbook链表连接多个文件系统。
2. index node(inode):一个文件相关的元数据,但不包括文件名。
创建文件时生成,并存储在存储设备上,记录了文件系统元数据。内存中使用inode来管理文件对象。
3. directory entry(dentry):文件/目录的名称和具体inode的关系,实现了目录与文件的映射关系。同时缓存经常访问的文件/目录。
用来记录文件名与inode的对应关系。用来实现硬链接,多级树形文件系统。
文件系统拥有一个没有父dentry的根目录(root dentry),这个dentry会被superblock引用,用来作为进行树形结构的查找入口。
其余的所有dentry都是有唯一的父dentry,并可以有若干个孩子dentry。
4. file:一组逻辑上相关联的数据。
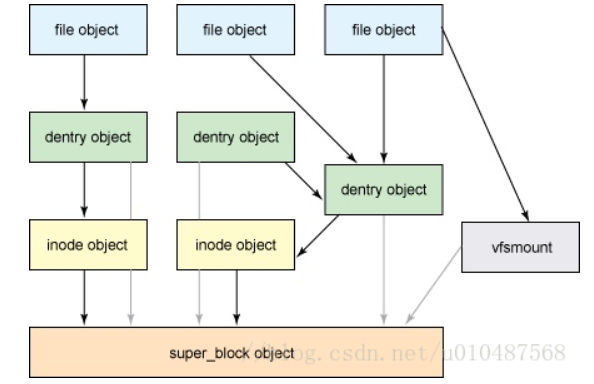
参考:https://blog.csdn.net/jinking01/article/details/90669534
参考:https://zhuanlan.zhihu.com/p/34875559
3.18号
(1)虚拟化
x86给出的等级从最高级Ring 0到Ring 3。操作系统需要读取内存修改页表等,需要最高级权限Ring 0。对于用户想访问硬盘等,需要用户态到内核态的切换等。
计算虚拟化:
1. CPU虚拟化:多个VM共享CPU资源。由于宿主机要运行在Ring 0。用户运行在Ring 3。因此需要VM进行截获,不直接访问到宿主机
CPU全虚拟化技术:Trap-and-emulation,陷入和模拟仿真。将OS需要的特权指令捕获,模拟执行后再返回。
对于x86下部分敏感指令不是特权指令,因此出现了二进制翻译技术,VMware通过二进制翻译技术对其进行了完全虚拟化。
让VMM运行在最高级的Ring 0,Guest OS运行在Ring 1, 用户运行在Ring 3。使得Guest OS的核心指令无法直接下达到计算机系统硬件执行,需要通过VMM。
半虚拟化:修改操作系统内核,替换掉不能虚拟化的指令。
硬件辅助虚拟化:对于特权指令修改模式。

2. 内存虚拟化:多个VM共享物理内存,但需要隔离。
因此内存虚拟化需要进一步进行映射。VM应用程序获得的虚拟地址(VA),需要转到Guest OS中的中间物理地址IPA。再次转化为真正的物理地址PA。
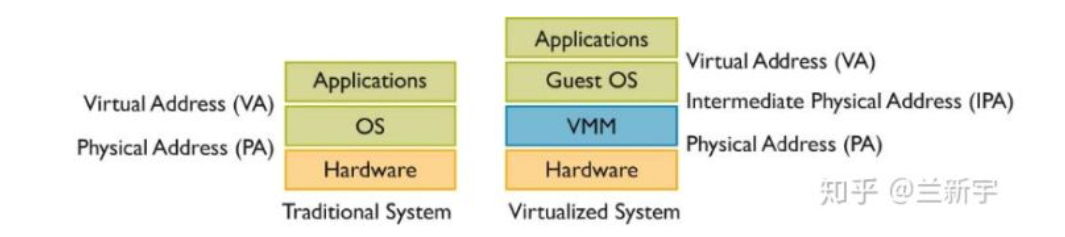
3. I/O虚拟化:多个VM共享设备,如磁盘等。
参考(虚拟内存):https://zhuanlan.zhihu.com/p/69828213
3.17号
(1)Socket
俗称套接字,用于计算机之间的一种通信。
socket起源于Unix,而Unix/Linux基本哲学之一就是“一切皆文件”,都可以用“打开open –> 读写write/read –> 关闭close”模式来操作。
因此Socket则是一种特殊文件,一些socket函数可以对其读写。
网络的通信需要三元组(ip地址,协议,端口),进而识别主机,识别应用。
例如:TCP的三次握手:
1. 开始客户端通过socket创建套接字(此时没有连接,因为处于CLOSED状态)。服务端启动LISTEN,来监听是否有连接。
2. 客户端通过connect()函数发送请求。
3. 服务端收到请求,返回ACK。
4. 客户端收到确认消息,连接建立。
5. 服务器也收到消息,确认了连接已经建立。
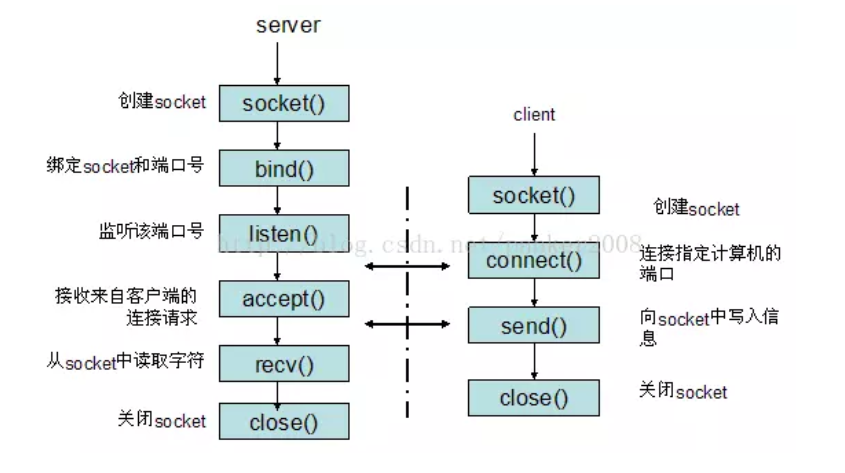
参考:https://www.jianshu.com/p/066d99da7cbd
(3)DMA
Direct Memory Access 直接内存存取:允许不同速度的硬件沟通,而不依赖CPU的大量操作。
因此实现DMA,需要在CPU使用总线后,将总线控制权交给DMA控制器,并在DMA控制器使用完再交给CPU。
(3)零拷贝
避免CPU拷贝数据从一个存储区域到另一个存储区域。
避免数据拷贝:1. 操作系统内核缓冲区的拷贝
2. 操作系统内核缓冲区和用户空间的拷贝
3. 用户程序可以避开操作系统直接访问硬件存储。
零拷贝的好处:1. 避免不必要的拷贝,减少CPU占用
2. 减少内存带宽的占用
3. 减少用户空间和内核空间的上下文切换。
4. 需要操作系统支持 ( 如下文的sendfile )
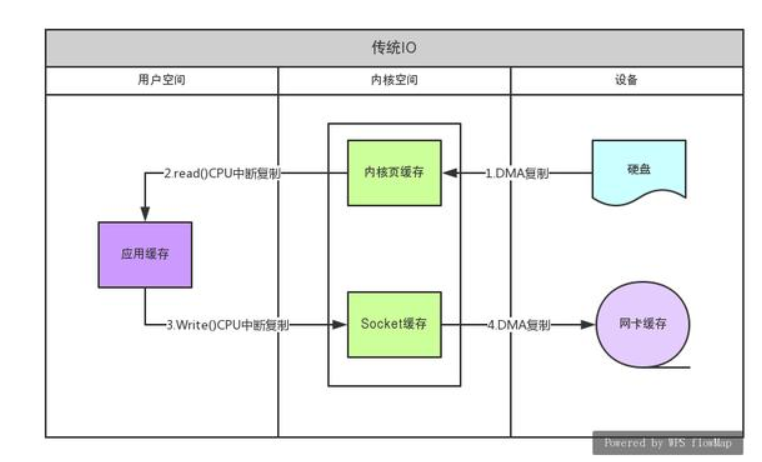
如传统的IO流实现数据的发送:如上图左
1. 用户调用read(),上下文切换到内核。DMA把数据复制到内存的缓冲区
2. read()返回,上下文切换到用户,CPU把数据复制到用户空间
3. write()上下文切换到内核,CPU把数据复制到内核socket缓存
4. write()返回,上下文切换到用户
5. DMA将socket缓存数据复制到网卡。
一共经历了4次上下文切换,4次拷贝。
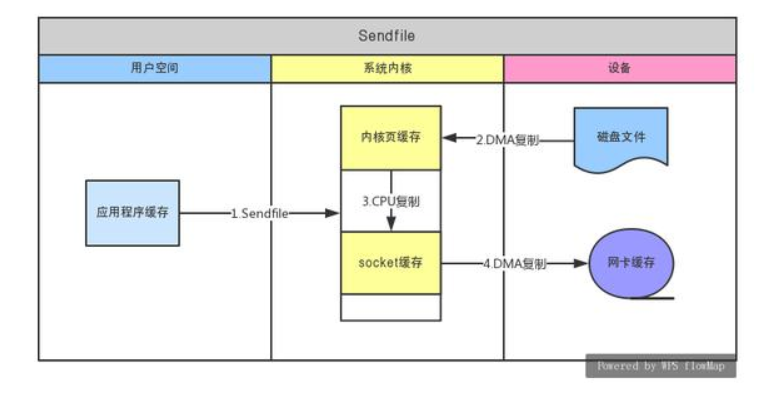
采用sendfile实现零拷贝:如上图右
1. 发送sendfile系统调用,上下文切换到内核。
2. 通过DMA将磁盘数据拷贝到内核空间
3. DMA发起终断,CPU执行,将数据从内核缓冲空间拷贝到内核中socket空间,上下文切换回用户空间。
4. DMA将socket空间数据拷贝到网卡
一共经历了2次上下文切换,3次拷贝。
参考:http://www.360doc.com/content/19/0528/13/99071_838741319.shtml
3.16号
(1)RMDA:(Remote Direct Memory Access) 远程直接内存访问

传统网络传输数据,需要将数据从用户空间,复制到内核空间的Socket Buffer,并在内核空间封装(如:TCP,IP,UDP,ICMP等)
RDMA:网络传输数据不需要内核参与,全部给交网卡,不需要额外的数据复制。
RDMA的三种硬件实现:InfiniBand、iWarp(internet Wide Area RDMA Protocol)、RoCE(RDMA over Converged Ethernet)。
InfiniBand:支持RDMA的新一代网络协议。
Roce:允许在以太网执行的RDMA。其中v1是采用IB实现的传输层,v2采用UDP/+IP实现的传输层。
iWarp:允许TCP执行RDMA,但丧失了大量优势。


RDMA提供了基于消息队列的点对点通信。通讯双方建立Channel连接,其首尾是两对Queue Pairs(QP),Qp由Send Queue(SQ)和Receive Queue(RQ)构成,QP会被映射到应用的
虚拟地址空间,使得应用直接通过它访问RNIC网卡。除QP外还提供一种队列Complete Queue(CQ)
同时提供了软件传输接口Work Request(WR),当需要传输时WR通知QP中的某个队列Work Queue(WQ)。在WQ中用户的WR被转化为Work Queue Element(WQE)的格式,
等待RNIC的异步调度解析并发送。
RDMA 单边操作:RDMA READ,RDMA Write。特点是不需要远程应用参与。
RDMA读操作(RDMA READ):如A读取B
1. A与B连接,QP建立并初始化。
2. 数据存到B的buffer地址VB。(VB需要被提前注册到B的RNIC,同时获得local key即操作权限)
3. 这时将VB和key传给A。同时B在WQ处注册WR,用于接收返回的状态。
4. A获得VB和key后,RNIC会将自身存储地址VA封装到RDMA READ发送给B,此时B的数据就会存储到VA的虚拟地址。
5. A存储后,将给B发送传输状态。
RDMA写操作(RDMA Write):如A写到B
1. A与B连接,QP建立并初始化。
2. 数据存储目标为B的buffer地址VB。(VB需要被提前注册到B的RNIC,同时获得local key即操作权限)
3. B将VB和key发送给A,相当于给A操作权,同时B在WQ处注册WR,用于接收返回的状态。
4. A获得VB和key后,RNIC会将自身发送地址VA封装到RDMA Write发送给B,此时A的数据就发送给B的虚拟地址VB。
5. A存储后,将给B发送传输状态。
RDMA双边操作:需要双方参与,类似Buffer Pool,RDMA优势在于零拷贝。:如A向B
1. A和B建立好QP,CQ
2. A和B分别向WQ中注册WQE。对于A中WQ=SQ,WQE描述了等待被发送的数据。对于B中WQ=RQ。WQE描述指向存储数据的Buffer,WQE描述用于存储数据的Buffer。
3. A的RNIC异步调度的A的WQE后,发现是SEND消息,从Buffer向B发数据。数据到达B的RNIC后,WQE被消耗,并将数据存储到WQE指向的位置。
4. AB通信后,A从CQ产生完成消息CQE。B的CQ产生完成消息,表示接受完成,每个WQ中WQE完成后都产生一个CQE。

参考:https://blog.csdn.net/qq_21125183/article/details/80563463
3.15号
(1)TCP/IP
TCP/IP作为协议族,内部包含TCP,IP,FTP,HTTP,IMCP等。
链路层:以太网规定接入的设备必须有以太网卡,拥有唯一MAC地址。
网络层:
IP:每台计算机必须有一个IP才能发送数据,IPV4中地址长度32bit,地址分为5类(都是网络号+主机号,常用B类)
ARP协议:可以根据IP地址获取MAC地址,通过广播的形式。当发现查找自己时,会给对方自己的MAC地址。
路由协议:对于同一子网内,可以通过ARP协议查找对方,对于不同子网,以太网会将其发给本子网的网关,让其进行路由。(网关是子网与子网之间的桥梁),最终在其子网内用ARP协议找到MAC地址。
传输层:链路层定义了MAC,网络层定义了IP,因此可以找到对方主机了,但无法知道是哪个应用的数据,因此引出了端口。
UDP:定义了端口,主机每个应用都需要一个唯一的端口。但UDP没有确认机制,因此可靠性较差。
TCP:面向连接的、可靠的、基于字节流的通信协议,TCP需要先建立一个通道,才能通信。
TCP包包含16位的源和目的端口(Socket四元组:源IP地址+目的IP地址+源端口+目的端口),Seq为序列号保证顺序,ACK用来确认已收到的序号
TCP Flag:NS(隐藏保护),CWR(拥塞控制减少标志,表明收到ECE标志的包)ECE(TODO 没看懂)URG(紧急指针字段重要),ACK(确认字段重要),PSH(要求把缓冲数据推送)
RST(重置连接),SYN(同步序号),FIN(发送方最后一个数据包)。
TCP流量控制由窗口控制(Window Size),因此最大不过65536。Checksum作为校验值。Urgent Point紧急指针。

TCP 传输:对于收到数据不会立即发送ACK,会等待200ms尽量与下一个数据包一起发送(捎带ACK)。
Nagle算法用于对小分组传输(如有时只需要传几个字节)的控制,保证只能同时一个小分组传输,多的去排队,等待时,小分组很大可能会多个进行合并。防止小分组导致网络拥塞。
Retransmission:应对数据丢失,采用的重传机制。
超时重传(根据往返时间(RTT)计算,超过RTO时间则重传),比较严重
快速重传(收到了3个重复ACK,因为数据包可能乱序,这时会发送最小未收到的数据),这时将这个数据包直接传送。
滑动窗口:用于代表,可以接受数据的大小。如果接收方窗口大小为0,则停止发送。
因此从左往右可以分为:已经发送且接收ACK。已经发送等待ACK。没有发送但在窗口之内,因此可以发送。在窗口外所以不能发送。
TCP拥塞控制:慢启动,拥塞避免,快速重传和快速恢复
慢启动和拥塞避免:cwnd(发送方最大限制),ssthresh(慢启动阈值)。开始传输时,cwnd=1每次增加SMSS字节。当拥塞发送ssthresh设置当前窗口一半。
若采用慢启动,则cwdn设置为1,每次为2倍(指数增长),当到达ssthresh时转为拥塞避免算法(线性增长)。
快速重传和快速恢复:若收到乱序数据,则返回ACK代表收到乱序,并且自己期望收到的序号。当发送方收到三次相同ACK,由于不是超时重传因此可能是数据绕路。
采用快速恢复,将ssthresh减半,将cwnd=ssthresh+重复ACK报文段大小。
应用层:以上三层数据已经可以完整传输到对应主机,但由于是字节流操作性较差。
HTTP:基于TCP/IP来传递数据,如HTML文件,图片等。
基于B/S架构,浏览器作为客户端,通过URL,向HTTP服务器(Web服务器)发送请求。步骤:1. DNS解析为IP地址 2. TCP建立连接 3. 发送HTTP请求 4. 相应HTTP请求 5. 获得了相应HTML
HTTP中账号密码为明文不安全,因此出现HTTPS通过SSL证书进行加密。步骤:1.HTTPS请求2. 返回证书(公钥)3. 产生随机(对称)密钥 4. 通过证书加密密钥并发送 5. 通信用对称密钥加密
HTTPS由于多次握手,耗时较多。HTTPS缓存没有HTTP高效。SSL证书需要钱,SSL也会耗费CPU资源。
FTP:文件传输协议
DNS域名:由于IP地址不容易记住,采用域名的方式。DNS域名服务器负责将域名翻译成IP地址。
参考:https://zhuanlan.zhihu.com/p/61987654
3.13号
(1)IP
公网IP:全球唯一,也叫外网IP。
私网IP:在局域网内可以用,但访问互联网必须用公网IP。
NAT:当访问互联网时,通常要经过路由器或者具有NAT的主机。通过NAT将私网IP切换公网IP,并分配一个端口号给用户,当接收到数据时,通过映射表查询请求是哪个用户的。
交换机:
二层转发:通过MAC地址转发。以同一Vlan主机通信为例,A ping B。
1. 经过IP与子网掩码与运算,判断A和B在一个网段。
2. A通过ARP表查找MAC地址(第一次需要进行ARP广播,广播时目标MAC地址为全F,交换机也会更新FDB表,并在交换机内部发送,B发现是自己IP,并回应A)
3. 由于都有映射,因此A将请求发送给交换机,交换机将请求发送给B
三层转发:通过IP地址转发。跨越了不同Vlan的主机通信
1. 通过检测发现不在同一网段,需要经过网关(交换机三层接口)来转发,因此需要查找网关的MAC地址。
2. 向Vlan 1发送ARP(因为不可知,所以目标地址为0)请求获取网关MAC地址。交换机检查到是需要自己MAC地址,发送给A
3. A将请求发送给网关,网关发现源和目的IP不在同一网段,直接提交到第三层。查找映射表,由于第一次通信,查找失败,转到CPU进行软件路由处理。
4. CPU查找软件路由映射表,若匹配到网段,再通过ARP表查找到对应MAC可以直接软件路由转发。
5. 若没有找到MAC在该网段进行ARP,目标发现查找自己回复自己的地址,下次也可以直接通信了。
参考:https://blog.csdn.net/Apollon_krj/article/details/82086174
(2)vmstat:Virtual Meomory Statistics(虚拟内存统计)
由于内存空间不够用,因此将部分磁盘空间虚拟成内存,将内存部分数据放到磁盘中。磁盘中虚拟出的内存称为虚拟内存(Swap Space)。
vmstat n k可以n的时间间隔,记录k次信息。
Procs(进程): r: 运行队列中进程数量 b: 等待IO的进程数量 Memory(内存): swpd: 使用虚拟内存大小 free: 可用内存大小 buff: 用作缓冲的内存大小 cache: 用作缓存的内存大小 Swap: si: 每秒从交换区写到内存的大小 so: 每秒写入交换区的内存大小 IO: bi: 每秒读取的块数 bo: 每秒写入的块数 系统: in: 每秒中断数,包括时钟中断。【interrupt】 cs: 每秒上下文切换数。 【count/second】 CPU(以百分比表示): us: 用户进程执行时间(user time) sy: 系统进程执行时间(system time) id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。 wa: 等待IO时间
参考:https://www.cnblogs.com/ftl1012/p/vmstat.html
(3)valgrind
用于查找内存泄漏。安装指令:
wget http://www.valgrind.org/downloads/valgrind-3.14.0.tar.bz2 // 获取资源 tar xjvf valgrind-3.12.0.tar.bz2 // 解压 xzvj也有可能 cd valgrind-3.12.0 //进入解压出的文件夹 ./autogen.sh ./configure --prefix=/where/you/want/it/installed make make install
包含多个工具包:Memcheck,Cachegrind,Helgrind, Callgrind,Massif等。
1. Memcheck:检查如下
使用未初始化的内存 (Use of uninitialised memory)
使用已经释放了的内存 (Reading/writing memory after it has been free’d)
使用超过 malloc分配的内存空间(Reading/writing off the end of malloc’d blocks)
对堆栈的非法访问 (Reading/writing inappropriate areas on the stack)
内存泄漏,指向一块内存的指针永远丢失 (Memory leaks – where pointers to malloc’d blocks are lost forever)
malloc/free/new/delete申请和释放内存的匹配(Mismatched use of malloc/new/new [] vs free/delete/delete [])
src和dst的重叠(Overlapping src and dst pointers in memcpy() and related functions)
2.Callgrind:
3.Cachegrind:模拟一级缓存和二级缓存,指出对的Cache命中和丢失。
4.Helgrind:检查多线程的竞争问题
5.Massif:堆栈分析器,它能测量程序在堆栈中使用了多少内存
如:valgrind --tool=memcheck --leak-check=full ./demo 通过Memcheck工具检查,--leak-check=full代表检查内存泄漏, demo是被检查的可执行文件。
参考:https://zhuanlan.zhihu.com/p/75416381
3.12号
(1)perf
常用的性能分析工具。
perf的安装(apt-get了一堆...............还好最后好使了)
sudo apt-get install linux-source // 这个花费时间最长,好像还没啥用.... sudo apt-get install linux-tools-common sudo apt-get install linux-tools-4.15.0-76-generic // perf --version用来查看是否安装成功
原理:简单情况采用tick 中断采样,在tick触发时收集上下文。如某个函数特别耗时,那么按照时间间隔采样一定会大量分部到该函数。若收集Cache miss触发采样,可以发现哪部分程序经常cache miss。
perf list可以获得所有的采样事件:
1. Hardware Event 是由 PMU 硬件产生的事件,比如 cache 命中
2. Software Event 是内核软件产生的事件,比如进程切换
3. Tracepoint event 是内核中的静态 tracepoint 所触发的事件
对于test.c文件
gcc – o demo – g test.c // 获取demo可执行文件,-g 会加入符号表等 perf stat ./demo // 获取各种信息
perf stat获得的各类信息:
1. Task-clock-msecs:CPU 利用率,该值高,说明程序的多数时间花费在 CPU 计算上而非 IO。
2. Context-switches:进程切换次数,记录了程序运行过程中发生了多少次进程切换,频繁的进程切换是应该避免的。
3. Cache-misses:程序运行过程中总体的 cache 利用情况,如果该值过高,说明程序的 cache 利用不好
4. CPU-migrations:表示进程 t1 运行过程中发生了多少次 CPU 迁移,即被调度器从一个 CPU 转移到另外一个 CPU 上运行。
5. Cycles:处理器时钟,一条机器指令可能需要多个 cycles,
6. Instructions: 机器指令数目。
7. IPC:是 Instructions/Cycles 的比值,该值越大越好,说明程序充分利用了处理器的特性。
8. Cache-references: cache 命中的次数
perf record && perf report精确定位性能瓶颈:
perf record -F 50000 -e cpu-clock ./demo // -F代表采样频率,为了防止采样不够多,导致部分函数信息不存在,这样使得数据更逼真。 perf report // 打印报告
perf report第一行可以看到:分别是采样数(Samples),事件类型(event),事件总数量(Event count)。同时存在多个列:
1. Overhead :是该符号的性能事件在所有采样中的比例,用百分比来表示
2. Command:命令
3. Shared Object:是该函数或指令所在的动态共享对象(Dynamic Shared Object)。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
4. Symbol 是符号名:也就是函数名。当函数名未知时,用十六进制的地址来表示。
perf record的其他参数:
1. -f:强制覆盖产生的.data数据
2. -c:事件每发生count次采样一次 // 上述每个时钟记录一次
3. -p:指定进程
4. -t:指定线程
perf top:可以用来观察当前系统。
参考:http://www.brendangregg.com/perf.html
参考:https://www.cnblogs.com/zhaoxinshanwei/p/8298493.html
(2) Sar
性能分析工具
用法: sar [ 选项 ] [ <时间间隔> [ <次数> ] ] 主选项和报告: -b I/O 和传输速率信息状况 -B 分页状况 -d 块设备状况 -I { <中断> | SUM | ALL | XALL } 中断信息状况 -m 电源管理信息状况 -n { <关键词> [,...] | ALL } DEV 网卡 EDEV 网卡 (错误) NFS NFS 客户端 NFSD NFS 服务器 SOCK Sockets (套接字) (v4) IP IP 流 (v4) EIP IP 流 (v4) (错误) ICMP ICMP 流 (v4) EICMP ICMP 流 (v4) (错误) TCP TCP 流 (v4) ETCP TCP 流 (v4) (错误) UDP UDP 流 (v4) SOCK6 Sockets (套接字) (v6) IP6 IP 流 (v6) EIP6 IP 流 (v6) (错误) ICMP6 ICMP 流 (v6) EICMP6 ICMP 流 (v6) (错误) UDP6 UDP 流 (v6) -q 队列长度和平均负载 -r 内存利用率 -R 内存状况 -S 交换空间利用率 -u [ ALL ] CPU 利用率 -v Kernel table 状况 -w 任务创建与系统转换统计信息 -W 交换信息 -y TTY 设备状况 -o {<文件路径>} 将命令结果以二进制格式存放在指定文件中
测试网络
sar -n DEV 2 10 代表对网卡每2秒进行一次检测,一共检测10次。
输出项说明:
IFACE:就是网络设备的名称;
rxpck/s:每秒钟接收到的包数目;
txpck/s:每秒钟发送出去的包数目;
rxbyt/s:每秒钟接收到的字节数;
txbyt/s:每秒钟发送出去的字节数;
rxcmp/s:每秒钟接收到的压缩包数目;
txcmp/s:每秒钟发送出去的压缩包数目;
txmcst/s:每秒钟接收到的多播包的包数目。
rxbyt/s:1296.46 txbyt/s:1177.78
监控CPU
sar -u 1 3 代表对cpu每1秒检测一次,一共检测3次。
输出项说明:iowait过高说明长时间等待IO,IO可能存在瓶颈。idle过低说明CPU处理能力较弱。idle高但响应慢,可能是等待内存分配,应增加内存。
1. %user #用户空间的CPU使用;
2. %nice 改变过优先级的进程的CPU使用率;
3. %system 内核空间的CPU使用率;
4. %iowait CPU等待IO的百分比; // 说明IO可能存在瓶颈
5. %steal 虚拟机的虚拟机CPU使用的CPU;
6. %idle 空闲的CPU; // 说明CPU使用率过高
检测内核表状态
sar -v 1 3 查看文件和其他内核表的信息
1. dentunusd:目录高速缓存中未被使用的条目数量
2. file-nr:文件句柄(file handle)的使用数量
3. inode-nr:索引节点句柄(inode handle)的使用数量
4. pty-nr:使用的 pty 数量
检测内存
kbmemfree:空闲空间。 kbmemused:占用空间。如:buffer 和 cache 的空间。 memused:这个值是 kbmemused 和内存总量(不包括交换出去的内存)的一个百分比。 kbbuffers: buffer占用量
kbcached:cache占用量 kbcommit:保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM + 交换到磁盘的数据量) commit:这个值是 kbcommit 与内存总量(包括 swap)的一个百分比 Kbactive:活动内存量(以千字节计算)(最近使用的内存,通常不会被收回,除非绝对必要) kbinact:不活动内存量(以千字节计算的内存(最近使用的内存),更有资格被用于其他目的)。 kbdirty:以KB为单位的内存量等待写入磁盘
......TODO 还有很多.....
怀疑 CPU 存在瓶颈,可用sar -u和sar -q等来查看
怀疑内存存在瓶颈,可用sar -B、sar -r和sar -W等来查看
怀疑 I/O 存在瓶颈,可用sar -b、sar -u和sar -d等来查看
参考(详细举例每种命令):https://www.cnblogs.com/mrwuzs/p/11543829.html
参考:https://baijiahao.baidu.com/s?id=1641470971297653890&wfr=spider&for=pc
(3)iostat
用法(类似sar):iostat [ 选项 ] [ <时间间隔> [ <次数> ]]
-c :用来显示CPU信息
-d:显示磁盘信息
-k/-m:以kB/mB为单位,而不是扇区
-x:输出详细的io设备信息
interval/count:时间间隔,以及次数。不带次数则循环输出
3.11号
(1)线性一致性(linearizability)
如果将所有用户在所有机器读取数据的时间平铺到一条时间轴,保障写数据生效之前读取的数据为旧数据,写操作生效后为新数据。
Serializability:数据库中四种隔离级别中的一种,确保对并发事务的结果,和按照某一种顺序调度事务的结果一直。
参考:https://yq.aliyun.com/articles/98608?commentId=18843
(2)infiniband(IB)
无限带宽技术:拥有极高吞吐量和极低延迟
1. TCP/IP具有转发丢失数据包的特性,网络不良时要不断地确认与重发。而IB使用基于信任的、流控制的机制来确保连接的完整性,数据包极少丢失
2. 使用IB协议,除非确认接收缓存具备足够的空间,否则不会传送数据。消除了由于数据包丢失而重发带来的延迟。
3. 同时IB是有序交互,不需要重排数据包。
4. infiniband通过交换机在节点之间直接创建一个私有的、受保护的通道,进行数据和消息的传输,无需CPU参与远程直接内存访问(RDMA)和发送/接收由InfiniBand适配器管理和执行的负载。

RDMA是内存块远程传输的接口,传输由硬件完成分片重组校验的 CPU被释放。底层实现可以是IB硬件,也可以是以太网(ROCE)。
-
RoCE v1是一种链路层协议,允许在同一个广播域下的任意两台主机直接访问。
-
RoCE v2是一种Internet层协议,即可以实现路由功能。(因此v1,v2的区别就是能不能路由)
RDMA的优势:1. 零复制,网卡直接与内存交互数据。2. 内核旁路,不需要内核调度。3. 不需要占用CPU
3.10号
(1)读写分离
对于某些业务场景,存在少量写,大量读,因此读存在瓶颈。读写分离(主从复制),将一个服务器进行写入更新删除操作,其他服务器只接受查询读取操作,并不断同步主服务器的数据。
主库:log dump线程,用来给从库的io线程传binlog日志
从库:启动io线程不断从主库获取binlog写到relay log(中继日志) 文件中。同时启动Sql线程,读取relay log文件中的日志,分析操作,实现主从操作一致,达到数据一致性。
劣势在于,从库采用异步复制主库数据,可能会有旧数据。因此读写分离适用于读远大于写,如果读写均匀可以采用双主互复制。

Mysql解决办法:
1. 半同步复制(semi-sync复制):主库将数据写到binlog以后,立即传给从库,从库写入relay log,至少一个从库返回ACK之后,才能返回写成功。
2. 并行复制:从库开启多个线程,并行读取relay log中不同库的日志,然后并行重放不同库的日志。
参考:https://zhuanlan.zhihu.com/p/60455737
(2)分布式锁
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。
可以采用专门服务器来进行共享资源的分配,当其他服务器想要获取共享资源,来专门服务器获取锁。
redis:Redis在获取网络请求时是单线程,之后若想要获取锁可以采用 setnx key value。(设置key 对应为value,若key不存在返回1,存在返回0)
因此若setnx key value返回1说明获取锁成功,当释放锁时只需要del key即可。
(但如果获取锁的机器宕机,会让锁无法释放,因此可以为key分配一个超时时间,让Redis管理。或者将超时时间放到value中,当其他程序访问到该value存储的时间超时,主动del。)
zookeeper:用于分布式服务如:文件系统+监听通知机制。而文件系统中肯定不允许相同文件名的出现。
持久性节点:即使客户端断开,数据也要保留。临时性节点:客户端断开后就不用继续保持。临时顺序性节点,创建节点时自动为其编号。临时持久性节点同理。
因此在获取锁时,只需要去创建文件,当其他服务器创建文件就会失败。
为了避免获取锁的机器宕机,可以采取创建临时性节点,因此宕机以后数据失效。为了避免其他服务器都来获取,采用临时顺序性节点,让每个节点只监听前面序号的节点。
(3)Protobuf(Protocol Buffers )
Protocol Buffers 是一种语言无关、平台无关、可扩展的序列化结构数据的方法,它可用于(数据)通信协议、数据存储等。
Protocol Buffers 是一种灵活,高效,自动化机制的结构数据序列化方法-可类比 XML,但是比 XML 更小(3 ~ 10倍)、更快(20 ~ 100倍)、更为简单。
通过序列化,减少存储空间或网络传输,在必要时通过反序列化进行恢复。
// XXX.proto定义数据结构 message xxx { // 字段规则:required -> 字段只能也必须出现 1 次 // 字段规则:optional -> 字段可出现 0 次或1次 // 字段规则:repeated -> 字段可出现任意多次(包括 0) // 类型:int32、int64、sint32、sint64、string、32-bit .... // 字段编号:0 ~ 536870911(除去 19000 到 19999 之间的数字) 字段规则 类型 名称 = 字段编号; } // 需要进行序列化与反序列化时 // $SRC_DIR: .proto 所在的源目录 // --cpp_out: 生成 c++ 代码 // $DST_DIR: 生成代码的目标目录 // xxx.proto: 要针对哪个 proto 文件生成接口代码 protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/xxx.proto
参考(go代码举例):https://www.cnblogs.com/zhaohaiyu/p/11826162.html
// 对于存储键值对{price:150} // json : 大约11字节 {price:150} // xml: 大约36字节 <some> <name>price</name> <value>150</value> </some> // Protobuf : 3字节 对于表示方法为: message Test { optional int32 price = 1; } 物理存储:08 96 01 第一个字节存储key:field_number << 3 | wire_type (1<<3|0=08) 96 01则是通过边长编码(1. 每个字节低7位有效,高位0代表本个数字结束,2.采用大端存储)(具体大小端不太确定...) 对于150二进制位:1001 0110 7位为一组,分为两组 : 000 0001 001 0110 大端存储(高位低字节): 001 0110 000 0001 之后最后一个高位为0,其余为1 :1001 0110 0000 0001 (16进制为96 01)
3.9号
(1)git
当本地与远程出现两条不同的路,需使用git pull拉取并合并,甚至git pull -rebase将起点也更新掉,但可能会发生冲突
1. git rebase --abort 一切恢复到 git pull 之前的模样
2. git rebase --skip 将产生冲突的自己文件删除
3. git rebase --continue 冲突合并,需自己手动解决冲突。
参考:https://www.cnblogs.com/chenjunjie12321/p/6876220.html
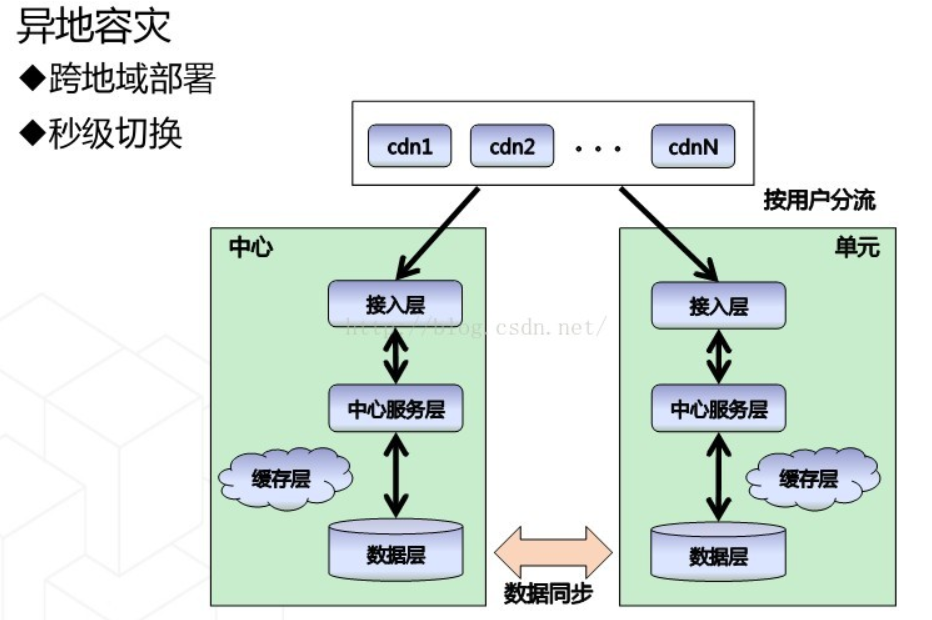
(2)异地多活
指在不同城市建立数据中心,防止因为一个数据中心出现故障,而整体不可用。
软件状态:如果一个软件不需要登录就能读写说明系统是无状态的,不登录只能读,登录才能写说明是有状态的。
难点:
1. 速度:由于距离太远,如1000km,即使光速也要10ms一般50ms左右,延迟太高。
2. 一致性:要保证数据在任何地域读取都是一致的。
阿里解决办法:单元化,让所有操作都在一个机房完成,就不存在延迟。因此对于一组也为称为一个单元。
单元化的难点:路由一致性:要保证一个用户进入以后,之后的操作都在这个城市的数据中心操作,而不能切换(切换到其他城市,数据可能不一致)
数据延迟:对于异地需要同步,仍有数据延迟。
多活的一致性:可能让一致性出现问题。
数据一致性:不同单元之间需要数据同步。
参考:https://blog.csdn.net/u013793650/article/details/49358507
(3)灾备
两地三中心:对于两个中心在同一个城市,实时做数据同步,因此可以同时提供服务。
对于第三个中心在其他城市,采用异步传输,并且不提供服务。
同城双活:对于应用层是双活,对于存储层采用主备方式
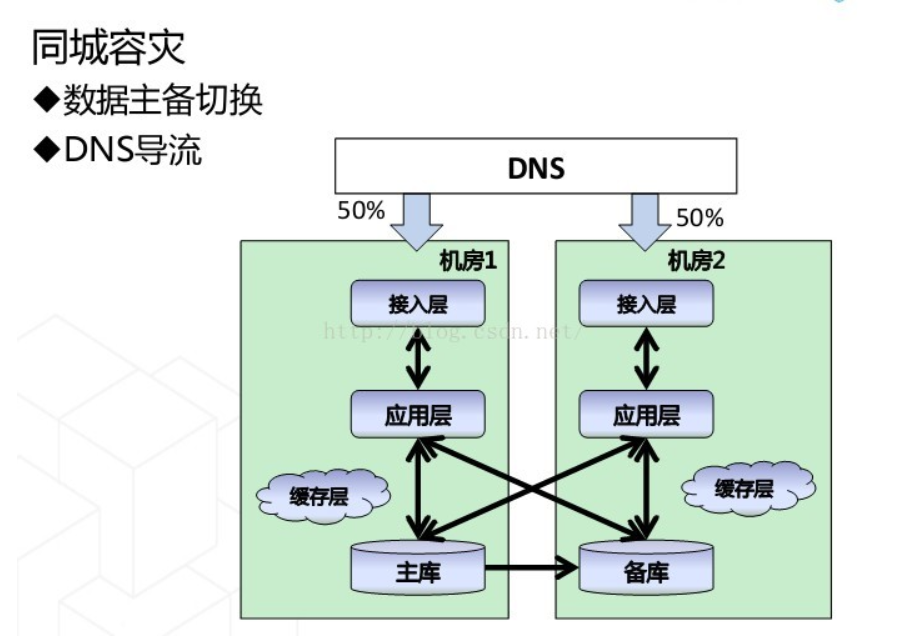
异地只读冷备份:对于异地若写延迟可能过高,因此采用异地只读取。
灾备指标:RTO(Recovery TimeObjective)恢复时间目标:从灾难发生,到恢复服务最短时间。针对服务丢失。
RPO(Recovery PointObjective)恢复点目标:所能忍受的数据丢失数量,若为0,说明无丢失。针对数据丢失。
3.8号
(1)FTP
用于远程主机直接文件共享。
1. 更新源列表:sudo apt-get update
2. 安装:sudo apt-get install vsftpd
3. 启动:sudo service vsftpd start
4. 新建目录作为uftp用户主目录 :sudo mkdir /home/uftp
5. 创建uftp用户:sudo useradd -d /home/uftp -s /bin/bash uftp (-d作为该用户的主目录, -s作为使用的shell)
sudo passwd uftp (设置密码)
sudo chown uftp /home/uftp (将该目录权限交给uftp)
6. 修改配置文件/etc/vsftpd.conf(结尾加入即可)
userlist_deny=NO userlist_enable=YES userlist_file=/etc/allowed_users seccomp_sandbox=NO local_enable=YES pasv_promiscuous=YES write_enable=YES
7. 本地测试:另起终端,ftp 127.0.0.1
输入uftp ,以及uftp密码
get file 获取uftp的文件
put file 将file文件传送过去
bye 退出
8. FTP后续:service vsftpd stop 关闭FTP服务。
service vsftpd restart 重启FTP服务
参考(成功):https://www.cnblogs.com/dybk/p/11647894.html
参考(失败,卡在莫名地方:500 OOPS: cannot change directory):https://blog.csdn.net/always_and_forever_/article/details/81357261
(2) 快照
快照的定义:指定数据集合的一个完全可用拷贝,该拷贝包括相应数据在某个时间点(拷贝开始的时间点)的映像。快照可以是其所表示的数据的一个副本,也可以是数据的一个复制品。
使用场景:对于数据的保护措施,当数据出错可以进行回滚。可以当做一份可用的副本。
快照实现的技术:
1. 写时拷贝(Copy On Write,COW):也叫写前拷贝。创建快照以后,如果源卷数据发生变化,快照数据会将源卷数据拷贝到快照卷,并对源卷进行改写。同时映射表记录更改数据的位置,以及新数据位置。
读取快照数据时,首先读取映射表,查询是否有该数据,有则直接读取快照卷,否则回到源卷读取。
快照回滚,将快照卷的数据覆盖源卷数据。
快照删除,直接删除快照卷和映射表。
2. 写重定向(Redirect On Write,ROW):创建快照后,对于写操作写入快照卷,因此只需要写一次。(和COW区别在于,COW对旧数据存储到新空间,ROW对新数据存储新空间)
读当前数据时,对于旧数据去快照(源卷)读,新数据去映射表查询读取(快照卷)
快照回滚,直接删除快照卷和映射表。
快照删除,需要将快照卷的数据写回到源卷。
3. Clone or split-mirror 克隆或分割镜像快照:全部复制,因此优势在于Clone快照高可用,但是很耗时。
4. Copy-on-write with background copy 后台拷贝的复制写快照:结合了COW和Clone。首先创建COW,并在后端不断Clone整个数据。
5. 增量快照( Incremental ):对于第一份数据为全量快照,对于之后数据都是和前一个数据的差值。
删除快照,只需要将本快照和下一个快照合并即可。
(3)备份
对了应对数据损坏,将数据复制到其他存储设备。
通常采用将数据复制到远端。
快照与备份区别在于,备份空间需要占用两份,而快照只取决于数据变动情况。
参考:https://www.jianshu.com/p/74007799313d
(4)重删与压缩
备份通常占用大量空间,因此数据缩减技术应运而生。
重删:对于多个相同的数据,只需要保存一份,其他的通过引用指向这份即可。
对于存储新数据时,可以判断是否已经有过该数据(根据块计算hash值,根据hash重复情况判断。可以采用 指纹 技术,将数据生成唯一值,如Sha算法,可以快速将2^64数据转为160位不重复数据)
定长重删:对于数据,按照固定长度分片,对于相同的片进行删除,记录第一个相同数据的位置即可。
变长重删:对于定长重删,如果开头加入一个字符,都会使整体发生改变。而变长更加灵活。效率也更高。
常用于备份场景,对于主存更追求低延迟,增加重删可能会增加延迟响应。
存在风险,一旦源数据丢失,指向的所有数据都丢失。
压缩:对于常出现的字符串,采用更少的字符特殊记录,从而节省空间。
由于采用压缩数据大小会发送变化,因此在压缩的实现上,存储架构一般采用ROW,即对于新数据重新分配空间。
按字节压缩,如Huffman编码。
参考:https://blog.51cto.com/13559412/2057144
3.7号
(1)Redis的哨兵(sentinel)
用来监控master是否故障,若出现故障,自动将slave作为master。
多个哨兵,同时ping其他哨兵,以及master和slave。当某个哨兵发现故障,发起投票成为领导者,然后自动完成主从转移。
(2)副本冗余
常采用3副本:当写入数据时,会先写入primary节点,primary传递写入secondary节点。当都写完之后返回用户,才算数据写成功。此时磁盘利用率只有1/3.
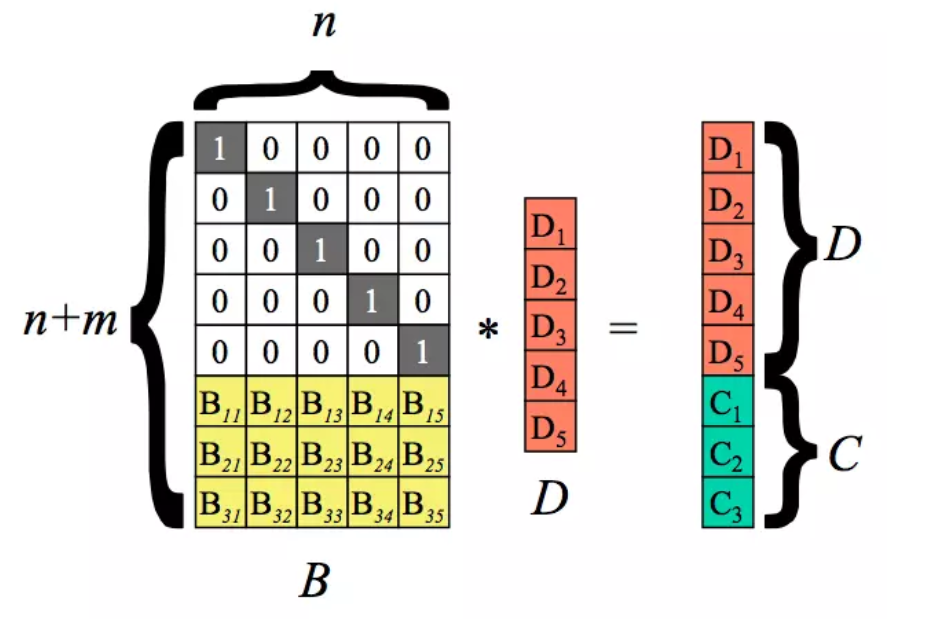
纠删码(EC):将原始数据编码得到冗余,并将数据和冗余共同存储。对于n块数据,计算出m块数据(校验码),对于n+m块数据,任意出错m块数据,整体都可以得到恢复。磁盘利用率n/(n+m)
相对3副本,计算开销,网络开销和恢复耗时较多,而且恢复时需要所有数据一同进行。因此一般对于热数据仍使用多副本,对于冷数据使用EC。
Read-Solomon(RS)码:作为最常用的纠删码。RS(n, m)代表n块数据,m块校验。
通过(n+m)*n的矩阵 乘以 n * 1矩阵 计算出 (n+m)* 1 矩阵。其中D1~D5为数据块,C1~C3为校验块。B矩阵的生成与范德蒙行列式有关。
当丢失任意小于3块数据时,将B矩阵和结果矩阵相应行删除(如:丢失D1,D4,C2)。并计算B的逆矩阵,通过B逆与Survivors计算出D矩阵,从而得到全部数据。

参考:https://www.jianshu.com/p/4abf65ad03af
(3) 线程
线程作为比进程更小的单位,可以更有效的利用处理器和多核计算机。
线程共享资源:地址空间,全局变量,打开的文件,子进程,闹铃,信号以及信号服务程序,记账信息。
线程独享资源: 程序计数器,寄存器,栈,状态字。
由于多线程贡献大量资源,可能导致出现不必要的麻烦,因此需要线程同步。
竞争:多个线程需要同一资源。
临界区:可能造成竞争的资源。
互斥:任何时刻只能让一个线程进入临界区。
锁:为了保持线程同步,通过加锁,让其他线程无法进入临界区。
对于释放锁,仅需要一步。对于获取锁,需要判断锁状态,再加锁,因此这两个操作需要是原子的。
睡觉与唤醒:当无法获取锁时,去睡觉,等持有者释放时顺便来唤醒
信号量:通过计数判断当前是否可以获得资源。如将数值减一若扔大于0,则去执行,否则数值加一。释放时将数值加一。
管程(Monitor):将需要监管的代码 上下假如 Monitor的begin 和end。使得任何时候只有一个线程执行该代码。
消息传递:线程互发消息来实现,通过send和receive。
栅栏:对于先到达栅栏的线程必须停止,等待所有线程到达后,才能继续推进。用于对一组线程协调。
死锁:原因在于对资源的竞争,但又无法获得所有资源。
死锁的定义:如果有一组线程,每个线程都在等待一个事件的发生,而这个事件只能有该线程里面的另一线程发出,则称这组线程发生了死锁。
死锁的必要条件:
1. 资源有限:一个系统中资源数据有限,无法同时满足所有线程。
2. 持有等待:一个线程在请求新的资源时,已经获得的资源不释放。
3. 不可抢占:不能抢占其他线程的资源。
4. 循环等待:A等B,B等C..... N等A
哲学家就餐问题:多个人环形坐,每个人左右各有一个叉子,只有同时拿起左手和右手的才能进食。若所有人都拿起左手,导致所有人都在等右面人放下叉子。
应对死锁的策略:
1. 允许死锁发生,之后对死锁进行检测和恢复。需要通过:资源分配矩阵,资源等待矩阵,系统资源总量,系统当前可用资源数量。
死锁的恢复需要允许抢占,通过kill线程,并回滚的方式。
2. 死锁的动态避免,在资源分配同时,确保不会进入死锁或潜在死锁。
3. 死锁的静态避免,清除发生死锁的土壤。
清除资源独占条件:增加资源到所有线程满足的资源需求。很难实现。
清除资源保持和请求条件:一个线程一次必须申请所有资源。
清除非抢占:允许抢占其他线程的资源。
清除循环等待:约定资源使用顺序。
银行家算法:采用动态避免的方式,分配之前判断是否安全。
(4)Linux启动流程
1. BIOS初始化,检查CPU,内存,硬件设备等。选择启动设备的顺序,以及由哪个设备启动开机。从该设备读取MBR(主引导目录)读取Boot Loader(启动引导程序 Linux默认为GRUB)并执行。
2. MBR位于磁盘0磁道0柱面1扇区。记录了引导程序GRUB(446B)以及分区表(64B)结束符(2B),分区表64B记录了每个分区起始中止位置以及使用量和总量(单个需要16B),因此最多4个分区。
启动引导程序要能加载操作系统内核。同时对于多系统的情况,可以引导其他系统加载。
3. 内核加载后,可以进行二次自检,并替代BIOS完成Linux启动。
参考:http://c.biancheng.net/view/1013.html
3.6号
(1)分布式调度
自动执行给定的任务,任务调度直接影响着实时性能。
linux原生的定时调度有crontab(进程调度),Quartz(线程调度)
但在任务较多时,无法统一管理。若采用分布式调度,则可以统一管理,并根据依赖进行操作,同时可以进行监控。
基于Raft算法,第一个发现master故障的,向其他哨兵发起投票,在成为领导者时,完成主从自动切换任务。
如阿里巴巴的分布式调度引擎tbschedule。
应用场景如:定时将一份数据进行备份。若采用单机速度慢,而且机器宕机就会失败。因此,采用将任务分片,分发到多个机器,每个机器获得调度器(线程组,含有多个线程),若一个机器宕机,可以将任务发给其他机器。
XXL-JOB:
参考(阿里巴巴的分布式调度引擎tbschedule):https://zhuanlan.zhihu.com/p/98350912
(2)负载均衡
对于将请求等分配到多个节点或操作单元,解决单点故障,高可用的方式。
而负载均衡服务器的核心在于负载均衡算法,但由于服务器的处理能力不同,同时可能出现故障,因此也衍生了各类算法。
静态负载均衡算法:
轮询:将请求依次分配给每个服务器。 (若发现某个服务器故障,将其取出并不参与之后的轮询,直到该服务器恢复正常。)
比率:将请求附加一个加权值,进行分配给服务器。
优先级:为服务器分组,每组存在优先级,每次将请求发到高优先级的组,直到该组服务器都故障,再分配到较低优先级的组。组内采用轮询或者比率的方法。实际可以看做一种热备份。
动态负载均衡算法:
最少的连接方式:将连接发送给目前连接数最少的服务器。
最快模式:将连接发送给响应最快的服务器。
观察模式:同时平衡连接数量以及响应时间。
预测模式:根据当前服务器的指标进行预测。
动态性能分配:收集应用程序和服务器的指标,进行流量划分。
动态服务补充:服务器集群内由于故障,导致服务器数量减少,将备份服务器补充到主服务器。
服务质量:按优先级对数据流分配。
服务类型:按照服务类型进行分配。
规则模式:根据数据流设置分配。
参考:https://zhuanlan.zhihu.com/p/50769487
参考:https://www.cnblogs.com/fanBlog/p/10936190.html
(3)进程
进程管理,内存管理,文件管理是操作系统三大核心功能。
CPU的多道编程,为了提高CPU利用率,同时让每个程序都认为自己独占CPU。
由于多个程序并行运行,因此程序通过时间片轮转,在就绪态和运行态切换,若运行时有读取磁盘等阻塞行为会进入阻塞态,并当数据到达时回到就绪态。
对于程序的创建:1. 分配 PCB。 2. 初始化寄存器。 3. 初始化页表。 4. 将代码从磁盘读到内存。 5. 处理器切换到用户态。 6. 跳转到起始地址,设置程序计数器。
由于CPU资源宝贵,从而进程调度也显得很重要
1. 先来先服务(FIFO):让进程排队,很公平。但可能导致,小任务也要等较长时间。
2. 时间片轮转:为每个程序分配时间片,周期性切换。当程序多时,时间片就小。程序少时,时间片就长一些。
3. 短任务优先:分为抢占式和非抢占式。
非抢占式则等待当前进程执行完,估计每个程序执行时间,时间短先执行。
抢占式则直接判断目前哪个进程执行时间较短,短的先执行。
4. 优先级调度算法:为每个程序分配优先级,每次让优先级高的进行调度。
5. 混合调度算法:将程序分为多类,没类之间存在优先级采用优先级调度,每类中采用时间片轮转的方式。
进行调度的过程:1. 当前进程由于中断或挂起等原因,OS获得CPU控制权。2. OS在就绪进程中根据某种算法选出一个执行的程序。3. 将程序的环境布置好(寄存器,栈指针,状态字等)。 4.跳到该进程。
进程通信
管道:一个进程向存储空间一端写入,另一个进程从存储空间另一端读出。创建管道需要调用管道创建的系统调用,让系统划分空间,让一个进程有写权限,另一个有读权限。
套接字(Socket):可以在不同应用,跨网络通信。需要通讯双方创建一个套接字,一方作为服务方,另一方作为客户方。服务方创建的套接字需要时刻监听,当客户方发送连接请求时,完成点对点的连接。
信号:发送方将数据填好,发送软中断,OS将其发送到接收方。
信号量:对于一个整数,用不同数值代表不同状态。如同步时常用的锁。
共享内存:程序A将创建一块内存空间,程序B将其映射到自己的(虚拟)地址空间,程序A进行读写时便是与B进行通信。
这种方式必须在同一物理机。
消息队列:一段有头有尾的消息排列,新来的放到队尾,读消息从队头开始。不需要指定进程,可以支持多进程,但只能在内存实现。
3.5号
(1)内存管理
内存是操作系统需要管理的重要资源之一。(除此之外还有CPU)
内存管理的目标:地址保护(程序不能访问其他程序的地址),地址独立(程序发出的地址与物理地址无关)
虚拟内存:由于内存空间有限,对部分暂不适用的数据放到磁盘,等待程序需要使用时,从磁盘取出。
会让内存空间增大,而且速度有所提升。但磁盘的速度必然很慢,若频繁交换数据会使得速度下降,并产生抖动(如死机等情况)。
单道编程的内存管理:即内存只有用户程序和操作系统程序。操作系统程序空间固定,因此用户的内存空间也是固定的。
因此可以在运行前将物理地址计算出来,也叫静态地址翻译。(只能用在物理地址固定的情况下
多道编程的内存管理:程序无法加载到固定的地址上,只有加载以后才能计算出物理地址,因此叫动态地址翻译。
用户程序的虚拟地址通过地址翻译器(MUU)转为物理地址。
多道编程内存管理的策略:
1. 固定分区:内存划分成多个固定大小的分区,每次分配一个足够大的空闲分区。用户程序都在共享队列里排队等待分区。
程序大小可能和分区大小不一致,导致小空间占用大空间,大空间也无法使用小空间,因此可以让不同大小使用不同的队列排队,但若有空闲分区,但程序不在该分区排队,仍可能无法运行。
2. 非固定分区:对于OS之外的空间,当程序需要占用时划分一个大小相等的,时刻记录好空闲分区。
对于程序空间存在增加(例如 递归),可以将程序存到磁盘,再转到内存(称为 交换),因此可以分成一段一段相对完成的单元,依次执行(成为 重叠)
但随着交换内存,内存将变得碎片化,同时由于磁盘的交换效率变低。
闲置空间的管理:管理内存时,OS需要知道空闲内存有多少。
可以为每个单位赋予一位,记录该单位是否空闲。
通过链表将分配单元连接起来,每个节点记录是否被程序占用(若是,需要指出哪个程序),起始地址,长度,下一个空间。
分页内存管理:将虚拟内存和物理内存都划分成大小相同的页,如 4KB,16KB等。每次按照页作为空间分配的最小单位,程序的一个页可以在任何一个物理页里。
由于采用页分配,克服了外部碎片,解决了空间浪费。
程序大小受限,仅因为程序需要全部加载到内存才运行,因此可以让程序无需全部加载就运行,将需要的页放到内存。
虚拟地址:由页面号+页内偏移构成,32位寻址中,若页大小4K,则页面号20位,页内偏移12位。
虚拟地址到物理地址,需要查询页表,内部还要记录是否在内存等。
因此不会有外部碎片,同时可以页面共享(如:copy on write,复制内存可以在修改时再复制过去)
缺页中断:由于虚拟内存可能在磁盘,因此CPU发出的虚拟地址不在内存,将产生缺页中断,需要将虚拟页面加载到内存。
页面置换算法:降低之后发生缺页的概率。
1. 随机更换算法:随机产生页面号进行更换。效果很差。
2. 先进先出算法:按照进入内存时间排序,替换出最早进入内存的。
3. 第二次机会算法:在先进先出的基础上,若发现队首的页在之后仍查询过,将其放到队尾。
4. 时钟算法:作为环形,每个都有访问为,若访问位为0代表上次检查之后没有访问过,则将其置换出去,否则访问位清0,直到有一个访问位为0.
与第二次机会算法类似,但第二次算法采用链表,其采用索引并用页表存储,无需额外空间。
同时可以改进时钟,同时又访问位和修改位,因而有四种组合方式,每次查找第一圈不做修改,找(0,0),第二圈找(0,1),对于跳过的访问位置0。因此, (1,1)->(0,1) -> (0,0) <- (1,0)。
作为公平算法,使得没有考虑不同页面调用频率的不同。
5. 最近未被使用(NRU):选择一个最近一段时间没有使用的页面进行替换。
6. 最近最少使用(LRU):不仅要考虑最近是否使用,同时考虑使用的频率,需要计数域记录次数,因此代价较大,一般商业操作系统不会采纳LRU。
7. 工作集算法:记录最近k次访问时需要的页。这样对于切换程序时,上个程序经常使用的页因为现在不用可以被切换出去。
8. 工作集时钟算法:工作集按照时钟方式组织起来。
有利于和页表结合,空间开销较小,常被商业使用。
由于一个程序仅能占有一个虚拟空间,导致最多只能和虚拟空间一样大,引发了段式管理。
段式管理:将程序按照逻辑单元分为多段程序,每段有自己的虚拟地址空间。
使得编写的程序的空间增长,同时节省空间。
段页式管理:将程序分多个段,每段进行分页。通过段表查找页表,进而查找物理页。
参考(内存管理上/中/下):https://www.cnblogs.com/edisonchou/p/5090315.html
3.4号
(1)Paxos
强一致性,高可用的去中心化分布式协议。
Paxos有三种角色,实践中每个节点可以有多个角色。
Propeser:提案者。可以有多个,对于提案的value可以是任何操作,如:设置某个值为某个值,设置primary为某个节点等。但对于同一轮Paxos过程,只有一个提案可以被通过。
Acceptor:批准者。N个,只有获得超过半数(N/2+1)的Acceptor批准,提案才能通过。
Learner:学习者。学习被通过的提案(理解为提交)。
Propeser的流程:
1. 向所有Acceptor发送消息 “Prepare(b)” (b指的是当前轮数)
2. 若收到任何一个Accceptor发送的Reject(B),说明有更高的轮数开始了,本次提案失败,设置b=B+1,跳回第一步。
3. 若收到Acceptor的Promise(b, v_i)达到(N/2+1)个。(v_i为Acceptor最近一次在i轮中批准过v)
3.1 若v都为空,Propeser选择一个value,向所有Acceptor广播Acceptor(b,v)。
3.2 选择i最大的value,向所有Acceptor广播Acceptor(b,v)。
4. 如果收到Nack(B),设置b=B+1,跳回第一步。
Acceptor流程: (B为该Acceptor收到最大的Paxos轮数的编号,V为value)
1. 接收到Propeser的消息Prepare(b)
1.1 如果b>B,回复Promise(b, V_B),设置B=b,表示不会接受小于b的提案。
1.2 否则拒绝,回复Reject(B)
2. 接收Acceptor(b, V)
2.1 如果b<B, 回复Nack(B),暗示Propeser有更大编号的提案被接收了
2.2 否则设置V=v,表示批准的Value是v,广播该消息。
批准如同抢占锁,只有获得超过半数的锁才能获得批准,但可以发现容易出现活锁,即当A发出b=1的请求,所有Acceptor都同意,此时B发出b=2的请求,使得A再次请求批准时又失败了,只能再次更新b=3.
3.3号
(1)两阶段提交
在分布式数据库中,同一数据库的各个副本运行在不同节点,副本数据要求完全一致。
作为数据库,由于操作都为事务(一系列读/写),需要满足ACID。事务的状态必须是提交(操作都成功)或失败(操作都不成功)。
在单机采用日志或MVCC等方式。
两阶段提交的思路:节点分为1个协调者和多个参与者,协调者询问所有参与者是否可以提交该事务,仅当所有参与者都同意,该事务才能全局提交。
协调者的流程:
1. 本地日志写入“begin_commit”
2. 向所有参与者发送"prepare“消息
3.1. 若有参与者拒绝(收到"vote-abort"),则日志写入“global-abort”进入ABORT状态抛弃该事务,并向所有参与者发送"global-abort"
3.2. 若所有参者者同意(收到"vote-commit"),则写入“global-commit”, 进入COMMIT状态,并向所有参与者发送"global-commit"
4. 等待参与者对"global-abort"或"global-commit"的确认响应消息,当收到所有确认消息,写入"end-transaction"
参与者流程:
1.写入日志“init”
2.等待协调者发送"prepare“
3.1.若可以参与本次事务,本地日志写入"ready",并发送"vote-commit",并等待消息。
3.1.1若收到"global-abort"则写入“abort“,发送“global-abort”
3.1.2若收到"global-commit"则写入"commit",进入COMMIT状态,并发送"global-commit"
3.2 若无法提交,本地写入"abort",并发送"vote-abort"
4. 任何时候在收到“global-abort”和“global-commit”时都要发送确认消息。
但由于交互次数过多,而且每次交互只能进行阻塞,若发送网络等异样,容错能力较差,因此工程实践很少用。
(2)MVCC
MVCC则是多版本数据实现并发技术,为每次事务准备一个新版本,从而在读取数据时对不同版本进行读取
SVN版本控制思想基本采用了MVCC思想。为了事务修改时不影响真正数据:
1. 将全部数据拷贝出来,进行修改。
2. 记录更新操作,读数据时将更新操作应用的基础版本计算结果(类似SVN的增量提交)。
基于MVCC的分布式事务:为事务分配编号,节点记录更新操作及事务编号,所有节点事务完成后,在全局信息记录本次事务编号。
读取数据时,获取元数据事务最大编号,再去各个节点进行读取数据。
3.2号
(1)Redo Log,Check Point,No Undo/No Redo Log(0/1 目录)
Redo Log更新过程
1. 更新操作写入磁盘
2. 内存中进行更新
3. 返回更新成功
若出现宕机,恢复只需要把日志内容操作一遍即可。
Check Point是为了应对redo 日志过多,加载时效率低下,采用将内存中数据用易于加载的方式Dump到磁盘的方式。
Check Point 流程
1. 提交记录“Begin Check Point”
2. 将内存数据用易于加载的方式Dump到磁盘
3. 提交记录“End Check Point”
恢复时
1. 将dump到磁盘的数据加载到内存。
2. 从尾部开始扫描日志文件,找到第一个End Check Point
3. 从对应Begin Check Point开始恢复之后日志数据
上述check point,需要操作具有等幂性(操作做多次和单次是一样的,如set x=1,但append操作就不具备等幂性)
应对非等幂性,方法一则是Dump时,进行停机。方法二则是采用快照,快速生成内存快照,Dump快照数据。
No Undo/No Redo Log(0/1 目录)
采用0目录和1目录,并用Master record记录当前生效目录是哪个。
当到来事务时(即一批更新操作,同时生效,或者都不生效),让非生效目录进行操作,当更新成功,原子操作Master record更改生效目录记录。
(2)存储指标
1. 延迟 : 通常指发出请求,到数据返回所消耗的时间。
2.IOPS:每秒IO次数,为 队列深度/延迟。
3. 吞吐:也称为带宽,为 (平均IO SIZE )* IOPS。
4. 长尾 :长尾请求指明显高于均值的一小部分请求,如P99标准则代表,99%的请求满足一定耗时,1%会大于耗时,这部分则为长尾。
5. 可靠性:一般为持久性,即包括,数据完好,磁盘故障但有RAID/副本/备份等方式进行恢复,否则就为丢失,不可靠。
6. 可用性:能够提供服务的能力,关键在于组件失效时,系统能多久恢复并提供服务。
7. 扩展性:增加硬件来提某方面指标的能力。
8. CAP :
C 强一致性(任何节点数据完全一致)
A 高可用性(节点不能因为等待数据而阻塞请求)
P 分区容忍性(允许网络存在不能通信的状态,但目前的网络都是不可靠的,存在丢包,因此P必须保留,除非是单机)
若同时保证CAP,可能发生数据未同步完全,收到请求,由于高可用必须发送数据,则数据可能是旧数据,从而不保证强一致性,无法进行服务 。
参考:https://zhuanlan.zhihu.com/p/34305823
参考:https://zhuanlan.zhihu.com/p/35516682
3.1号
(1)磁盘内部视频
机械硬盘:https://www.sohu.com/a/321580340_115785
机械硬盘与固态硬盘:https://v.qq.com/x/page/d0516umdly7.html
(2)HDD,SATA SSD,NVMe SSD, Optance
HDD(Hard Disk Drive):机械硬盘,容量从80G~几T不等。接口分为PATA,SATA,SCSI等。特点:容量大价格较低,但性能相对较差。
SSD(Solid State Drive):固态硬盘,若采用SATA理论上是500MB/s以上,M.2本质为PCIe插槽,读的速率可以达到3200MB/s,写的速率可以达到2000MB/s
接口:SATA,M.2,PCIe
协议:AHCI(6 GBps),NVMe(32 GBps)
由于固态硬盘的速度已经超过SATA接口的极限,而NVMe可以利用PCIe通道,有效提升读写上限。
Optance : 作为超高速内存新技术,兼容了NVMe协议。据(百度百科)说存储速度提高1000倍,存储密度是DRAM的10倍。提供了128G,256G,512G,而传统内存条范围为4G~32G。
应用:作为缓存技术,对HDD和SSD进行提速。(通过参考测试可以看到,Optance+HDD在读测试远高于HDD在写测试也略快一些,并且与SSD相比性能也差别不大,但价格缺降低很多)
相对于NAND SSD而言,采取了3DX Point技术
(3)Flash(闪存)
分为NAND Flash,NOR Flash
NOR Flash:有很好读写性能,以及随机访问,但单盘容量较小
NAND Flash:有优秀的读写性能,容量大,性价比低,但不具备随机访问。
Flash不支持覆盖,只能擦出为空,再进行写入,每块擦出的次数有限。
SSD采用了NAND Flash,写入以Page为单位,擦除以Block为单位(大于Page)
内部通过映射表来映射物理地址与逻辑地址
同时采用垃圾回收将Block内有效数据转移
并采用磨损平衡,使得每部分被擦除次数近乎相同。
参考(Optance+HDD 与 HDD 以及 SSD对比图):http://api.xiaoheihe.cn/maxnews/app/share/detail/12899
参考:https://www.cnblogs.com/Christal-R/p/7230304.html
(4)Lease机制
保证数据正确(即不是脏数据),数据可用。
需要分布式下节点时间一致,当中心服务器发出lease时,代表lease有效期内,服务器不会更改值,一旦lease超时就可以删除数据。
当中心服务器获得更新数据时,将会阻塞所有读请求,并等待所有颁布的lease超时,然后更新数据。
但因此会产生一些可用性的问题,对于等待所有lease超时时,不能给节点新的lease,避免不断有持有lease而产生活锁,但可以对于读请求仅返回数据,不发布lease,甚至可以发布为已发布lease中最大有效期。
优化二:主动通知持有lease的节点放弃lease即可。
Lease的简单定义:发送方给出一个时间限制内的承诺,无论接收方是否成功接收,发送方都会严守承诺。接收方来说,在时间限制内可以使用承诺,超过时限,承诺不可再使用。
对于主从(primary-secondary)协议中,确保节点可用,则需要一定的机制。
常常采用心跳的方式,即向master发送心跳,但有可能存在primary仅仅与master通信异常等情况。这时若直接重新选择primary会导致双主的问题。
若采用lease机制,为primary分配lease时间,这样可以在lease超时后重新选primary。
lease在工程中通常为10s。
2.29号
(1)分布式一致性
强一致性:任何时刻任何节点都可以读到最近更新成功的数据。
单调一致性:任何用户在读到某个数据某次更新后的值时,这个用户就不会读到更旧的值。
会话一致性:任何用户在某一次会话读到某个数据某次更新后的值时,这个用户在这次会话就不会读到更旧的值。
最终一致性:一旦更新成功,各个副本最终会达到一致状态,但不保证时间。用户若一直读取一个副本则可以保证单调一致性,但切换副本后则什么也不能够保证。
弱一致性:更新成功后,不能确保用户读到,即使读到不能确保下一次能读到,实际中基本不会使用。
(2)数据分布
哈希方式:常常通过数据与机器个数取模进行映射,基本可以较为均匀分部到集群中,但扩展性差需要数据迁移,常常乘倍扩展使得只迁移一半数据。如果某一哈希数据特征值严重不足,可能导致数据倾斜。
数据范围分部:按照域进行划分,动态划分区域,使得数据量相近,但需要保存元数据。
按照数据量分部:将数据划分成数据块,同样需要元数据。
一致性哈希:在闭环中随机生成位置,每个点负责保存该点到下一个点之前的所有数据,但在增加节点时,仅能减轻一个节点的压力。删除使得一个节点压力倍增。可以引入虚节点,每个节点管理多个虚节点 , 类似元数据
2.28号
(1)对象存储OSS (Object Storage Service,OSS)
对象由 元数据,数据,唯一key组成,通过key查找该对象,元数据存储如删除创建时间等。
只能创建对象,追加和删除。对于追加,需要特定接口,且与之前类型有所区别。对于修改,只能删除并创建,将重新上传整个Object。
可以提供强一致性,写入返回即代表冗余数据也已经写完,可以查询。
常常用于存储文件,音视频等。
参考:https://help.aliyun.com/product/31815.html?spm=a2c4g.11186623.6.540.1145392cRvvmWb
(2)表格存储TableStore
Nosql数据库,提供PB级存储,千万TPS以及毫秒级延迟。
海量并发写入。提供主键查询,多元索引,全局二级索引。保证数据强一致性,返回即三副本都写完。
适合元数据,大数据,消息数据,时序数据等。
2.26号
(1)go的Test
文件名需要以”_test.go”结尾
放置在测试模块的相同目录下
func TestXxx(*testing.T) // 函数名用Test开头,内部用testing.T go test -run Foo //运行用go test。 -run 可以进行筛选执行某个函数
参考:https://blog.csdn.net/muxxpkq/article/details/53911640
2.25号
(1)go语言的reflect(反射)
package main import "reflect" import "fmt" type Student struct { name string id int } func (stu *Student) SayName() { fmt.Println("My name is ",stu.name) } func (stu *Student) SayId() { fmt.Println("My id is ",stu.id) } // 如何操作一个未知的类型 -> 反射 func Print(x interface{}) { v := reflect.ValueOf(x) t := v.Type() fmt.Println("value = ",v,"type = ",t); // 输出 value = &{Xiao Ming 1} type = *main.Student // 获得方法个数,遍历每个方法,一般可以放到map中,方便之后反射 for i :=0; i < v.NumMethod(); i++ { fmt.Println("Method name :",t.Method(i).Name," Method type:",v.Method(i).Type()) // 输出 Method name : SayId Method type: func() v.Method(i).Call([]reflect.Value{}) // 输出 My id is 1 } } func main() { fmt.Println("Hello, world!") stu := &Student{} stu.name="Xiao Ming" stu.id=1 stu.SayName() // 输出 My name is XiaoMing stu.SayId() // 输出 My id is 1 Print(stu) }
运行 : go run main.go
(2)go语言select
select { case <- ch1: // 从ch1读取到数据,则走本条路 case ch2 <- x: // 数据成功写入到ch2,则走本条路 default: // 若都未成功则走本条路 } /* 若case中有未阻塞的则走任意未阻塞的case 若都阻塞,则有default就走default,否则一直阻塞 */
参考:https://www.cnblogs.com/yang-2018/p/11133047.html
2.24号
(1)go语言的方法
方法需要在func与函数名之间声明接受者 type Circle struct { radius float64 } //该 method 属于 Circle 类型对象中的方法 func (c Circle) getArea() float64 { return 3.14 * c.radius * c.radius }
2.22号
(1)kotlin
用于在java虚拟机上运行,可以编译成java字节码,方便在没有JVM环境运行。
// 主函数 fun main(args: Array<String>) { println("Hello World!") } // 例如一个Add函数 fun add(a: Int, b: Int): Int { return a + b } //可变长参数函数 fun vars(vararg v:Int){ for(vt in v){ print(vt) } } //匿名函数 val sum: (Int, Int) -> Int = {x,y -> x+y} println(sum(1,2)) // for循环 val items = listOf("apple", "banana", "kiwi") for (item in items) { // item作为对象 println(item) } for (index in items.indices) { //index作为索引 println("item at $index is ${items[index]}") } //continue/break/return/while 与C无区别 //常量与变量则是val/var val a: Int = 10000 var max: Int
参考:https://www.runoob.com/kotlin/kotlin-tutorial.html
(2)go语言
interface{}则可以看做C语言中void*
2.21号
(1)docker与kubernete
容器目的在于不让程序被干扰,或干扰其他程序,并且资源固定,拥有了独立的运行环境。
在用Dockerfile制作容器时,分层有利于并发
而kubernete则是容器的编排系统。
用于自动化部署,并且扩展收缩容器,并存在副本。
参考:http://dockone.io/article/932
参考:https://www.zhihu.com/question/37498459
2.20号
(1)innodb
数据每16k作为一个页。
会以主键创建B+树作为聚簇索引,如果查找时不以主键的列作为搜索信息,可以创建二级索引,二级索引的叶子结点不包含完整信息,仅包含主键信息,并回到聚簇索引查询完整信息。
参考(细致讲解插入一条数据后的存储格式):https://www.cnblogs.com/zslli/p/8855634.html
参考(索引):https://www.cnblogs.com/zslli/p/8932371.html
2.19号
(1)关闭回显的办法
-------------方法一---------------
#define TTY_PATH "/dev/tty"
#define STTY_CLOSE "stty raw -echo -F "
#define STTY_OPEN "stty -raw echo -F "
system(STTY_CLOSE TTY_PATH);
getchar(); //看不见
system(STTY_OPEN TTY_PATH);
-------------方法二---------------
system("stty -echo");
getchar(); //看不见
system("stty echo");
参考:https://blog.csdn.net/wangwenwen/article/details/8862235
(2)NVMe
简单来说,NVMe仅仅是接口规范。
类似的接口规范有:SATA,M.2,PCle。
NVMe下的带宽:读3200MB/s,写1200MB/s。读IOPS大约50万。(IOPS*每次平均数据大小=带宽)
如以往的SATA,计算机与存储设备仅有一个队列,传送数据仅有一条通路,导致数据堵塞。
NVMe最多可以有64k个队列,因此并发程度大大提升。
参考:https://baijiahao.baidu.com/s?id=1637421199219751340&wfr=spider&for=pc
2.17号
(1)auto关键字
int z=10; auto z1=z; // z1在编译期,自动识别为int类型。
// auto类型在定义时,必须初始化。
const int zz=10;
auto z2=zz; // const/volatile会自动被去除。z2的类型为int;
auto &z2=zz; // 带上&则不会去除const语义。
参考:https://www.cnblogs.com/KunLunSu/p/7861330.html
(2)typeid
#include<typeinfo> typeid(x).name() //可获得x的变量类型
(3) 编译原理,高级语言如何转为汇编语言
1. 词法分析:生成<标识, 值>。全部变成最小单独项。
2.语法分析:生成语法树,构造符号表,并从0开始分配空间。等程序编译好之后,当真正运行时获取真正可以执行内存地址后,只需要将其作为偏移即可。
3.语义分析:检查程序是否和语言定义的语义一致,类型检查等。
4.中间代码生成:作为中间代码,为之后代码优化做准备。
5.代码优化:将中间代码进行优化。
6.生成代码:生成汇编代码。

参考:https://www.cnblogs.com/LittleHann/p/4754446.html
参考(缺点:没有图片了):https://blog.csdn.net/qq_42899794/article/details/97939199
2.16号
(1)malloc与new
malloc不会调用构造函数,free时也不会调用析构函数
参考:https://www.csdn.net/gather_24/NtDaggwsMjEtYmxvZwO0O0OO0O0O.html
2.7号
(1)公钥私钥-RSA
为了保证其他人发送数据不被窃取,将自己的公钥给其他人,其他人通过公钥与加密公式进行加密,发送数据,自己通过私钥与解密公式将数据解密。
公钥私钥生成过程:
1. 选择两个不同质数p,q(越大越难破解)
2.计算n=p*q
3. 计算n的欧拉函数,phi(n)=phi(p)*phi(q)=(p-1)*(q-1)
4. 随意选 1 <e <phi(n) (常用65537)
5. 找出d 使得e*d%phi(n)=1
6. (n,e)为公钥 (n,d)为私钥
由于只公布了n,e。而计算出d的公式 e*d%phi(n)=1则必须计算phi(n)。而phi(n)必须知道n的因子,但对于大数因子很难计算。
公钥与私钥的使用规则:
1. 对于传输m, 公钥为(n, e)
2. 通过m^e%n=c计算出c,将c传输
3. 通过c^d%n=m计算出m,获得数据。
参考:https://blog.csdn.net/u014044812/article/details/80866759
2.5号
(1)C++ 时间获取
time_t now_time = time(0); // 获取秒级别时间 clock_t now_time = clock(); //获取CPU计时单元个数 CLOCKS_PER_SEC // CPU每秒计时单元个数
2.4号
(1)B树
插入节点,若关键字个数过多,
将关键字分成两份作为两个节点,中间关键字上升为父亲节点的关键字。
删除节点,若关键字个数过少
若非叶子结点,先找到后继第一个节点,替换到该节点上。
若叶子结点个数过少,则先看兄弟节点是否有富余,有则将用其将父亲节点替换下来,父亲节点归自己。没有则需要两孩子节点与父亲的关键字合并成新孩子节点。
(2)B+树
插入节点,若关键字个数过多,
将关键字分成两份作为两个节点,右节点第一个关键字同时作为父亲节点的关键字。
删除节点,一定为叶子结点,若关键字个数过少
则先看兄弟节点是否有富余,有则将其关键字归自己,并替换掉父亲关键字。没有则需要两孩子节点合并成新孩子节点,并剔除父亲节点内划分俩节点的关键字。
(3)程序被系统kill
命令:dmesg | egrep -i -B100 'killed process' 用于查看最近被kill掉的原因
2.3号
(1)Bitcask模型
特点:写入=磁盘顺序写入+内存操作。读取=内存获取key+读取一次相应文件。 需要key相对value很小,否则hash表很难存下。
数据采用顺序写入磁盘,并在内存建立hash表,记录每个key对应value的位置。写入只需要磁盘顺序写入,并更新hash表,查找只需要hash表中找到key就能知道value所在文件以及位置,并读取相应value。
定期merger,减少磁盘数据冗余。
参考:https://blog.csdn.net/chdhust/article/details/77801890
参考:https://cloud.tencent.com/developer/article/1083737
(2)bazel
编译构建工具,类型makefile
参考:https://blog.csdn.net/u013510838/article/details/80102438
(3)core文件
/proc/sys/kernel/core_pattern内部设置core文件所在位置
%e 文件名
%p 进程pid
%t 时间
(4)g++ -L
默认库的搜索路径为/usr/lib, 设置 -L ./ 则可以把当前目录也作为库的搜索路径
1.27号
(1) CAP原理
C:Consistency(强一致性)指的是任何节点数据完全一致。
A:Availability(高可用性)指的是在有限时间内能返回
P:Partiton tolerence(分区容忍性)允许网络不可靠。目前只有在一个区内才能保证通信可靠,但这样的话,就不算一个分布式系统了。
参考:https://www.jianshu.com/p/482ba491a760
1.19号
(1) __attribute__((visibility("default")))
与之相对应的是:hidden
default:其定义的符号表将被导出
hidden:其定义的符号表不会被导出,并且不能被其他对象引用
参考:https://blog.csdn.net/fengbingchun/article/details/78898623
1.17号
(1)std::this_thread::sleep_for 和 std::this_thread::yield
std::this_thread::yield : 将当前线程时间片交出去,然后重新与其他线程竞争cpu
std::this_thread::sleep_for:休息固定时间,在此期间不参与竞争
(2)constexpr 常量表达式
被修饰的表达式说明在编译器就可以求值,例如:
constexpr int x =10; constexpr int z= sizeof(int);
1.16号
(1)std::memory_order
memory_order_relaxed:保证了原子操作,
memory_order_release:类似Unlock,保证在此之前的读写操作,无法排到该操作之后
memory_order_acquire:类似Lock,保证在此之后的读写操作,无法排到该操作之前(加上release的原子变量,acquire可以确保获得所有release之前的写操作)
memory_order_consume:对读取的内存施加release,确保之后的读写操作排在该操作之前
memory_order_acq_rel:对读写施加release-acquire
memory_order_seq_cst:对于读施加require,对于写施加release
参考:https://www.cnblogs.com/lizhanzhe/p/10893016.html
(2)string convert char*
c_str()
(3) access
判断文件是否存在
(4)emplace_back 替代push_back
push_back在插入数据时,会先进行拷贝,然后将构造的对象移入容器
emplace_back 会直接将对象移入容器
1.14号
(1)noexcept 关键字
告诉程序不会抛出异常,有助于编译器优化。
若确实有异常会直接终止程序
(2)形参中的 && --右值引用
对于这种情况: string str= string("h") + "l" + "l"+"o"; 每次调用operator "+"都会重新分配一个string,因为他不知道源字符串是左值还是右值。 因为源字符串可以在其他地方被引用,因此不得被修改。
通过右值引用,该右值不得被其他地方引用
(3)static类成员函数
不能访问非static类成员,代表所有类调用都一样
1.13号
(1)可以变参数的函数
第一个参数(__printf__):代表形如printf的规则
第二个参数(2):第几个参数是格式化字符串,如同printf中的第一个"%s+%d"这种类型
第三个参数(3):第几个参数开始是形式化字符串的参数
__attribute__((__format__(__printf__, 2, 3)))
extern void myprint(const char *format,...) __attribute__((format(printf,1,2))); 用法类似于 printf
myprint("My name is %s", name);
extern void myprint(const char *format,...) __attribute__((format(printf,1,2)));
用法如下:
myprint(x, "My name is %s", name);
(2) va_list
帮助处理函数参数个数不确定
va_strat帮助va_list指向第一个参数
va_end帮助结束参数获取
void Log(Logger* info_log, const char* format, ...) { if (info_log != nullptr) { va_list ap; // 定义va_list va_start(ap, format); // 将va_list指向format第一个参数 info_log->Logv(format, ap); // 抛入下一个函数 va_end(ap); // 获取参数结束 } }
(3) protect与private区别
子类可以访问父类protect的变量,而private的不可以访问
1.12号
(1)python-tkinter-GUI
top = tkinter.Tk() //显示主界面
tkinter.Toplevel() // 显示窗口
// 显示滑轮
scroll_bar = tkinter.Scrollbar(temp)
scroll_bar.pack(side=tkinter.RIGHT, fill=tkinter.Y)
list_box = ttk.Treeview(temp, show="headings") // 通过 ttk.Treeview来制表格
list_box.config(yscrollcommand=scroll_bar.set)
list_box.pack(expand=1, fill=tkinter.BOTH)
scroll_bar.config(command=list_box.yview, width=16)
// 获取excel表格
workbook = xlrd.open_workbook(excel_file) //读取文件
table = workbook.sheets()[0] //获取第一页的表格
// 写入Excel表格
data = xlrd.open_workbook(excel_file)
names = data.sheet_names()
table = workbook.add_sheet(name)
table.write(x, y, now_data)
workbook.save(excel_file)
e = tkinter.Entry(top, width=27, show=None) //设置显示框
tkinter.Entry(top, width=7, show=None) // 设置输入框
tkinter.Button(top, text="修改", command=update).place(x=100, y=150, anchor='nw') // 设置按钮并调用相应函数
top.mainloop() // 主界面显示
(2)python-read/write-file
with open(location, 'rb') as file: # 打开文件 # data=json.load(file) # 读取json data = pickle.load(file) # 读取文件 file.close() # 关闭文件
pickle.dump(data, file) # data 写入文件
1.11号
(1) python-GUI-tkinter
博客:https://www.cnblogs.com/shwee/p/9427975.html
(2)python程序打包成exe
1. 安装pyinstaller
pip install pyinstaller
2. 打包
pyinstall -F main.py
2. 如果需要改exe成型的图标下载图片(可以略过)
下载图片: https://www.easyicon.net
图片改为ico: http://www.ico.la/
输入命令 pyinstaller -F -i "demo.ico" main.py
3. 如果不想要命令框
pyinstall -F -w main.py
参考:https://www.cnblogs.com/onemorepoint/p/7002852.html
1.7号
(1)define
有时define里面会嵌套do{...}while(0),看起来没什么用。
#define Make() Open(); Insert(); 这样在使用Make时就会出现结尾没有分号,看起来很不规整
1.4号
(1) find 忽略部分目录
find . -type f 查找当前目录下所有文件 -path build -prune -o 将 build目录排除 find . -path build -prune -o -type f -print 查找除了build目录下的所有文件 ~ | xargs cat | wc -l 可以将所有文件连接,算出总行数
1.3号
(1)堆/栈
堆上分配的需要自己释放。
栈分配的函数结束自动释放。
静态存储区域:如全局变量,整个程序运行时都会存在。
(2) O_CLOEXEC
O_CLOEXEC: 原子操作
不使用O_CLOEXEC : 会调用 fcntl 设置FD_CLOEXEC,非原子操作,多线程下存在竞争。
参考:https://blog.csdn.net/ubuntu_hao/article/details/51393632
1.2号
(1) virtual 类的函数,结尾有const = 0 的含义
const代表函数内部不能改变类的值
=0 代表其函数的纯虚函数,其类是抽象类,不能被实例化,即创建对象。
1.1号
(1)include头文件书写书顺序
Google Style: global to local
1. cpp 对应的h 文件
2. C 语言头文件
3. C++ h 文件
4. 其他组件(lib)的h文件
5. 本模块的 h 文件
(2)define换行必须加\
#ifndef XXX
#define XXX \
do{
}while(1)
#endif
(2)md5sum与sha1sum
校验文件内容生成校验码
12.25号
(1)锁
GUARDED_BY:代表该数据成员被给定的监护权保护。读时要有共享的访问权,写时要有独占的访问权。
REQUIRES / EXCLUSIVE_LOCKS_REQUIRED:代表需要独享的监护权。
REQUIRES_SHARED / SHARED_LOCKS_REQUIRED : 代表需要共享的监护权。
12.23号
(1)cmakelist
include_directories可以使所有文件从一个目录下开始查找
对于一个项目下不同目录文件之间调用,不用 include"项目路径/port/XXX" 而是直接 include"port/XXX"
对于在build下编译src下的源码
PROJECT_BINARY_DIR=项目路径/build
PROJECT_SOURCE_DIR=项目路径/src
12.17号
(1)const
const定义是修饰一个变量只能读不能写的。
const int a; // a是一个int 常量,不能改int值。
const int* a; // 指针a指向的是int 常量。
int const* a; // 同上。
int* const a; // 指针a是一个常量,只能固定指向一个int变量,不能指向其他变量,但变量的值可以改。
const int* const a; // 指针a是一个常量,指向的也是一个int常量。说明都不能改。
int const* const a; // 同上。
(2)大/小端模式
大端模式:高地址存高位,低地址存低位。
小端模式:高地址存低位,低地址存高位。
12.16号
(1)重载运算符
//重载括号很方便进行一些操作,例如比较操作。
#include<stdio.h> struct CMP { operator()(const int& aa, const int& bb) { if(aa>bb) return 1; else if(aa<bb) return -1; else return 0; } }cmp; int main() { printf("%d\n",cmp(10,20)); }
(2)哑元
对于函数的哑元,只定义了类型,没有形参,更是无法使用。但为之后的兼容做了准备。
(3)函数指针
如:int(*p)(int, int);
定义了一个指向 有两个整形参数返回一个整形的函数 的指针。
#include<stdio.h> int add(int x,int y) { return x+y; } int main() { int(*p)(int,int); p=add; printf("%d\n",(*p)(2,3)); }
(4) leveldb的编码
由于int占用4个字节,但很多时候数字没有那么大,高字节是0会很浪费空间。因此采用了压缩。
而压缩若直接把高字节是0的去掉会导致解析时无法判断每个int直接的切分点在哪里,因此会把压缩前的数字按位,每7为一组,高字节都是0的组舍掉。然后把除最后一组的每组前面加一个0位,最后一组加1个1位。这样每次读取根据读到最高位为1时则是一个切分点。
12.15号
(1)初始化类的const类型
对于const类型我们知道是不可以进行改变的,因此对其初始化可以采用 初始化列表进行。
class stu { public: const char* school; stu():school("Hrbust") {} // 可以接不止一个参数,如: stu():var1(x),var2(y),var3(z)...{} void from() { printf("my school is %s\n",school); } };
但有个特点就是,初始化顺序只跟定义顺序有关。其先与构造函数执行。
参考:https://blog.csdn.net/tqs_1220/article/details/78621092
(2) vim指令
:sp 可以横向打开一个相同窗口(vsp是纵向)
ctrl+w 可以切换窗口
:e file 可以切换到file这个文件
通过上述可以从一个文件复制到另一个文件
12.14号
(1)类型
size_t :定义于cstddef.h,应为unsigned int,在64位系统中为long unsigned int。
uintptr_t:定义于cstdint.h中,unsigned long int的别名
(2)gdb
gdb调试core时能用i locals看栈变量、函数行(即不出现No symbol table info available)的必要条件:https://blog.csdn.net/stpeace/article/details/52013413
12.13号
(1) 四种类型转换
1. static_cast 将基类和子类互相转换,由于没有检查所以不安全。将普通类型进行转换。将void* 进行转换。
2. const_cast 将const类型转为非const类型。
3. dynamic_cast 将基类和子类互相转换,在基类转为子类时进行检测,因此变得安全。
4. reinterpret_cast 指针类型的相互转换。引用之间的转换。所能容纳的整数类型的转换。
参考:http://blog.sina.com.cn/s/blog_94a1fe540102yoaj.html
(2) new关键字
char* p1=new ..
char* p2 = new(p1)...
那么p2就会直接用p1的地址
参考:https://www.cnblogs.com/lustar/p/10717502.html
(3) virtual关键字
1. 修饰函数
无virtual关键字时,调用函数会直接调用基类的函数,而加上virtual时会看实例化的对象是基类还是派生类。
2. 虚拟继承
参考:https://www.cnblogs.com/Allen-rg/p/11394598.html
12.12号
(1)Cmake
参考:https://blog.csdn.net/qq_34654240/article/details/85706231
(2) TODO
// TODO 还是不明白为什么db下的文件调用util下的文件使用 include "util/***"而不是 include "../util/***"
12.11号
(1)C++模板(template)
简言就是为了应付相同功能但不同类型或者方式(如:排序方式不同)的代码。
#include<iostream> template<typename Type> Type add(Type aa,Type bb) { return aa+bb; } int main() { std::cout<<add(1,2)<<std::endl; std::cout<<add(1.3,2.4)<<std::endl; } /* 3 3.7 */
(2)atomic
代表原子操作,其load,store等操作需接一个形参为 std::memory_order
主要应对编译乱序与cpu乱序所采用不同需求下的同步强度
参考博客:https://www.cnblogs.com/the-tops/p/6347584.html?utm_source=itdadao&utm_medium=referral
参考博客:https://www.cnblogs.com/haippy/p/3412858.html
(3)函数后const含义
如: int add(int x,int y)const;
1. 不能对类的成员做改动
2. const型类对象只能调用const函数
12.10号
(1)配置vim
一些默认配置可以直接写到 ~/.vimrc 下,例如 set number等。
安装YouCompleteMe可以自动补全
首先安装插件管理器Vundle
1:git clone https://github.com/gmarik/Vundle.vim.git ~/.vim/bundle/Vundle.vim
2:在vimrc下保存
set nocompatible
filetype off
set rtp+=~/.vim/bundle/Vundle.vim
call vundle#begin()
Plugin 'VundleVim/Vundle.vim'
"在此增加其他插件"
call vundle#end()
filetype plugin indent on
3:在添加处加入 Plugin 'Valloric/YouCompleteMe'
4: vim +PluginInstall
5: 进入 ~/.vim/bundle/YouCompleteMe
6: 执行git submodule update --init --recursive
7:执行 ./install.sh
参考博客: https://harttle.land/2015/07/18/vim-cpp.html
参考博客:https://blog.csdn.net/weixin_44638957/article/details/91985270
(2) leveldb分析
参考博客:https://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html
(3)头文件
C/C++文件在编译和链接时会查找系统默认的include,link路径
系统默认路径:/usr/local/include
#include< >会直接去系统目录下查找头文件
#include" "会现在当前目录进行寻找,之后去系统目录查找。
12.9号
(1)编译指令
-std=c++11,支持C++11标准;
-std=gnu++11,支持C++11标准和GNU扩展特性;
-pthread 代表了有线程函数
-lleveldb 代表引用率leveldb的静态库(libleveldb.a)或者动态库(libleveldb.so)
参考:https://www.cnblogs.com/skynet/p/3372855.html
12.7号
(1)预写式日志(Write-Ahead Logging (WAL))
在数据写入之前先写到日志中,防止由于崩溃导致数据丢失。也不用每次都把数据写入到磁盘中,可以数据足够多时一起刷到磁盘。然而日志必须写入到磁盘,但日志都是追加写入,比数据的随机写入开销小很多。
参考:https://blog.csdn.net/kevinsqlserver/article/details/7762572
12.4号
(1)拷贝构造函数
拷贝构造函数用于类对象的拷贝。
#include<stdio.h> class stu { public : int id; char* name; // 构造函数 stu(int myid,char* myname) { id=myid; name=myname; } // 拷贝构造函数 stu(const stu & stu1) { id=stu1.id; name=stu1.name; } // void call() { printf("My name is %s, id = %d\n",name,id); } // 析构函数 ~stu() { printf("%s:Bye!!!\n",name); } }; int main() { stu xm(1,"xiaoming"); stu xl(2,"xiaoli"); xm.call(); xl.call(); stu xm2(xm); xm2.call(); }
(2) default和delete关键字(仅针对 特殊成员函数)
对于拷贝构造函数,如果不设置或者设置成default既可以默认使用
如果设置成delete则被禁止使用拷贝构造函数
stu(const stu & stu1)=delete; // 禁止使用拷贝构造函数
12.3号
(1)6.828 Lab6
DMA 允许外部设备直接访问内存,而不需要CPU参与
只需要分配一块内存用于发送描述符队列即可。
参考:https://www.cnblogs.com/gatsby123/p/10080311.html
(2) LSM
levelDb和rocksDb都是实现了LSM,而rocksDb不仅用了多线程,而且支持将多个Put进行Merge。
其瓶颈主要在于写放大,对于写入数据以后可能存在多次compaction,而每次合并都需要把下一等级的某个block数据都读取出来。
levelDb源码解析参考:https://blog.csdn.net/xuxuan_csd/article/details/72965459
(3)explicit(表明该类不允许隐式构造)
explicit关键字的作用就是防止类构造函数的隐式自动转换.
若允许隐式构造:对于只有一个参数的类构造函数,可以直接用等于来构造赋值。
#include<stdio.h> class stu { public: char *myname; stu(char *name) { myname=name; } void hi() { printf("My name is %s\n",myname); } }; int main() { stu stu1="xm"; stu1.hi(); //输出 My name is xm }
参考:https://www.cnblogs.com/rednodel/p/9299251.html
11.22号
(1)6.828 Lab5
磁盘最小粒度 512B,文件系统最小粒度 4KB。
File结构体
struct File { char f_name[MAXNAMELEN]; // filename off_t f_size; // file size in bytes uint32_t f_type; // file type (目录、文件) // Block pointers. // A block is allocated iff its value is != 0. uint32_t f_direct[NDIRECT]; // direct blocks (直接存储的block位置) uint32_t f_indirect; // indirect block(间接存储的block位置,用1个block来存,可以存储1024个block位置) // Pad out to 256 bytes; must do arithmetic in case we're compiling // fsformat on a 64-bit machine. uint8_t f_pad[256 - MAXNAMELEN - 8 - 4*NDIRECT - 4]; } __attribute__((packed)); // required only on some 64-bit machines
file_block_walk(struct File *f, uint32_t filebno, uint32_t **ppdiskbno, bool alloc): 将文件 f 中第filebno个块地址存在ppdiskbno中,如果indirect没有分配可以根据alloc判断是否分配。
file_get_block(struct File *f, uint32_t filebno, char **blk):将文件 f 中第filebno个块地址对应的虚拟地址存放在 blk中。
walk_path(const char *path, struct File **pdir, struct File **pf, char *lastelem):解析路径path,将所在目录结构存在 pdir, 所在文件结构存在 pf中。
dir_lookup(struct File *dir, const char *name, struct File **file):查找目录dir下为name的文件,存在file中。
dir_alloc_file(struct File *dir, struct File **file):查找目录dir下没有分配的File结构,存储到file中。
file_create(const char *path, struct File **pf):创建路径path文件,存储在pf中。
file_open(const char *path, struct File **pf):打开path文件,存储在pf中。
file_read(struct File *f, void *buf, size_t count, off_t offset):读取文件f里offset为起始的count个字符。
file_write(struct File *f, const void *buf, size_t count, off_t offset):将buf后count个字符,写入到文件f里offset为起始的地方。
(2)cmake版本更新
sudo apt-get autoremove cmake // 卸载,其他卸载指令根本不好使 sudo apt-get install build-essential wget http://www.cmake.org/files/v3.4/cmake-3.4.1.tar.gz // 可以去网址获取其他版本的.tar.gz tar xf cmake-3.4.1.tar.gz // 解压 cd cmake-3.4.1 ./configure make sudo make install
11.21号
(1)6.828 Homework:xv6 locking
acquire两次会发生死锁,产生panic
lk->pcs 代表返回地址
lk->cpu 代表被持有的cpu
若lock置为0以后再清除,可能导致其他cpu已经占用这时把后者cpu的数据给清除掉。
(2)6.828 Homework:User-level threads
uthread.c : 创建2个线程,频繁让出cpu给其他线程(调度策略:每次找一个runnalbe的其他线程,否则看自己是否runnable)
(3)6.828 Homework :HW barrier
pthread_cond_wait : 等待条件到达再被激活。采用该函数可以选择释放一个锁,当被唤醒时再获取那个锁
pthread_cond_signal():用来激活等待该条件的线程。
barrier(屏障):只有所有线程都到达一个点以后才能从这个点往下执行。
构成屏障的方法,非最后一个线程等待被唤醒,只有最后一个线程用来唤醒其他线程进入下一个工作区域。
11.20号
(1)阅读xv6-第六章 文件系统
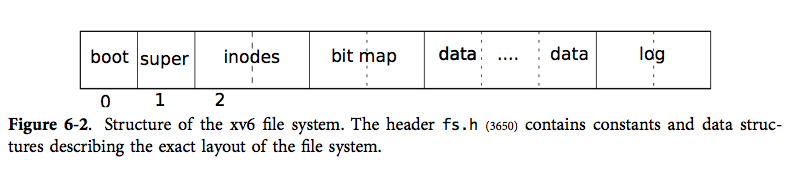
第0块不能被使用,因为存储bootloader
第1块成为超级块,存储了文件系统的元信息(如文件系统的总块数,数据块块数,i 节点数,以及日志的块数)
从第2块开始存储 i节点,一个块能存储多个i节点
接下来是空闲块的位图
接下来大部分都是数据块
最后是日志块。
块缓冲层:采用LRU,将磁盘数据放到快缓冲区,每个块同一时间只有一份拷贝在缓冲区。通过bread和bwrite来和磁盘进行交互。
对于调用者,会把数据先读到快缓冲区,然后标记为busy表示在使用,对于修改以后标记为dirty表示在释放前需要写入到磁盘。
日志:会在写数据之前先把写操作的描述包装成日志写在磁盘中,只有在日志中写完才会将数据写入文件系统,只有在数据操作都完成以后才会删除日志。
块分配器:通过位图查找待分配的块。
(2)mysql日志
重做日志(redo log): 用来防止有脏数据没写入盘。事务执行过程会写入redo log,当脏数据写入磁盘redo log使命结束。
回滚日志(undo log): 用来保证事务发生之前的一个版本。事务提交以后,undo log会被放入待清理链表,purge线程判断是否有事务在使用上一个版本来决定是否清理。
二进制日志(bin log):从库用其重播主库的操作。mysqlbinlog解析过后就会成为sql语句。会在事务提交以后写入。
11.19号
(1)阅读xv6-第四章 锁
锁:0为没被获取,非0是被获取。
xchg:原子操作,交换两个数的值。用来获取锁。
(2)6.828-lab4-partB
在执行fork时,第一种是直接把父进程的内存内容复制给子进程一份,这样比较耗时。另一种是Copy-on-Write Fork,开始只把页目录和页表复制过去,内容只在修改时进行复制。
(3)6.828-lab4-partC
进程间通讯:消息包含两部分,分别是32位值和可选的页映射关系。
(4)协程coroutine
轻量级用户态线程,采用非抢占式调用。只有在无法继续执行时(等待数据到达),会主动释放cpu。
缺点:对于一个cpu密集没有io的协程,导致从不释放资源,其他协程得不到执行。
参考:https://www.jianshu.com/p/2782f8c49b2a
11.18号
(1)阅读xv6-第三章 中断,陷入和驱动程序
中断:可能与当前进程无关,由于设备引起(exception:发生错误,如:除0. interrupt:希望引起注意)
陷入:当前cpu上运行的进程导致的。
特权:0(内核,特权最高)~3(用户,特权最低)
处理中断的程序在中断描述符表中定义(IDT)
当要处理中断时,则会把eflags...压栈,如果要存在特权转换(例如:用户特权太低,需要转为内核),则ss和esp也要入栈。
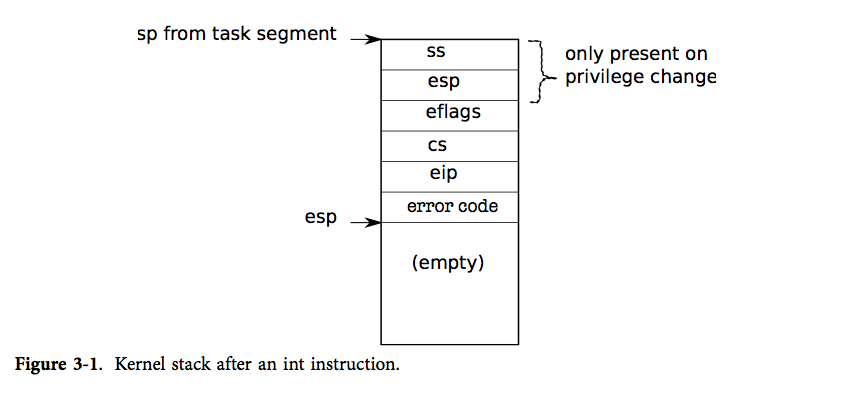
发生中断时,处理程序会产生一个中断帧。先判断是否是系统调用,之后判断是否是硬件中断,都不是则认为中断来自于用户程序。
系统调用:工具函数argint,argptr,argstr
argint : 获取第n个参数的地址作为指针,由于esp为调用结束的返回地址,所以esp+4+4*n是第n个参数的地址。需要判断参数的地址是否是用户内存空间的一部分,如果不是他自己私有的,则会杀死进程。
argptr : 获取第n个参数作为整数获取,并看做指针,类似argint,但需要在获取指针时判断一次,获取到指针以后对指针的地址再次判断。
argstr : 获取第n个参数解析为指针,并且它一定以NULL为结尾的字符串。整个字符串都在用户空间。
驱动程序:如同设备的接口,提供设备相关的中断程序,操纵设备完成操作等。
由于磁盘操作是毫秒级,所以轮询对于cpu是漫长的,因此采用磁盘完成操作以后,产生一个中断。
对于高宽带的设备通常采用DMA(会让CPU把总线控制权交出),直接从主存读取或者写入。
(2)“数据归纳法悖论”
问题. https://blog.csdn.net/zhouzx2010/article/details/84724862
解答. https://www.iteye.com/blog/zhou-yuefei-2220360
「大声说出来」跟「彼此心照不宣」有着决定性的区别
球与花瓶悖论


http://tieba.baidu.com/p/4964457981
(3)6.828-lab4-partA
在多cpu处理器下,首先会有一个启动内核的cpu(BSP),初始化以后会启动其他cpu(AP),由于可能会多个cpu同时中断,所以需要进行分配每个cpu的内核栈。
由于存在多cpu,用锁来防止冲突必不可少。
自旋锁:如果没有获得就不断请求
sleep锁:没有获得就先sleep,这样可以先去执行其他线程,防止空转。
Unix提供fork()系统调用创建新的进程,fork()拷贝父进程的地址空间和寄存器状态到子进程。
父进程从fork()返回的是子进程的进程ID,而子进程从fork()返回的是0。父进程和子进程有独立的地址空间
11.15号
(1)6.828 Homework: Threads and Locking
对于多线程编程要考察好每一个点,因为你永远不知道他在哪一科会切换线程。
static void
insert(int key, int value, struct entry **p, struct entry *n) // 插入key/value到链表,p存储链表的头地址,n是第一个地址 //假设当前第一个地址是p->A...
{
struct entry *e = malloc(sizeof(struct entry)); //分配空间 //节点B
e->key = key; //插入key/value
e->value = value;
e->next = n; //头插法,指向原本第一个节点 //B->A...,p->A...
*p = e; //更改第一个节点的地址 //若在执行本指令之前,切换线程,导致第一个地址又更改成C(p->C->A...),而执行完本指令变成p->B->A...,则丢失C数据
}
(2) xv6 a simple, Unix-like teaching operating system
英文:https://pdos.csail.mit.edu/6.828/2018/xv6/book-rev11.pdf
中文:https://th0ar.gitbooks.io/xv6-chinese/content/content/chapter1.html
11.14号
(1)内联汇编
对于内部寄存器使用:
r :Register(s) // 自动分配原则,从输出到输入,从左到右,一次从 %0,%1~%n
a :%eax, %ax, %al
b :%ebx, %bx, %bl
c :%ecx, %cx, %cl
d :%edx, %dx, %dl
S :%esi, %si
D :%edi, %di
asm [ volatile ] ( //asm和__asm__一样,volatile和__volatile__一样 assembler template //汇编代码。通常分行编写 [ : output operands ] //输出操作数 [ : input operands ] //输入操作数 [ : list of clobbered registers ] //可能会破坏的寄存器 );
参考资料:https://www.cnblogs.com/rain-blog/p/gnu-gcc-insert-asm.html
(2) 6.828-lab3-partB
解救学渣:https://github.com/gatsbyd/mit_6.828_jos_2018
(3)6.828 HW xv6 CPU alarm
参考资料:https://blog.csdn.net/yuchunyu97/article/details/78364091
11.13号
(1)重新学习6.824-lab2,以及Raft
开始,所有节点不断循环状态,以及是否commit。
循环状态时,如果长时间没有收到RPC请求(拉票/心跳,数据)超时,则变成Candidate,并拉取投票,当投票过半则成为Leader。
作为Leader会记录每个点接下来需要的日志序号,并把后面的日志全部发送过去,如果一个日志超过一半的节点都已经收到了,那么状态机就可以执行。
笔记 https://www.cnblogs.com/lmhyhblog/p/11850177.html
(2)操作6.824-lab3
为client添加请求代码,每次找到leader并发送请求。
leader获得请求添加到日志,当状态机可以执行以后,就去执行。
11.12号
(1) 为什么下载速度大于上传速度
通常用户都发送请求消耗的资源 < 请求获得的资源, 所以用户的需求就是下载 > 上传
而测速时下载 > 上传也仅仅是运营商来满足需求,对于上传的资源再卖给机房的企业客户等。而且加速器也更偏向去加速下载速度。
资料 https://wap.zol.com.cn/ask/details_2841185_2178596_4.html
(2)6.828下的 HW 需要单独下载。。。。
https://pdos.csail.mit.edu/6.828/2018/homework/xv6-boot.html
(3)HW lazy page allocation
当用户在malloc时,系统不会直接分配内存,只有当用户真正要去用这里时,才会进行分配。
(4)6.828-lab3
env_init : 初始化Env表,都是free状态
env_setup_vm : 分配一块空间作为页目录
region_alloc : 为用户分配物理空间,分配到虚拟地址上
load_icode :将用户的ELF binary 解码
env_create : 根据用户的ELF binary创建env
env_run : 将当前running的env改成runable状态,并且把给定的env作为running
调试: make qemu-gdb、 make gdb
发生中断以后,为了保存状态,需要将这些压入栈
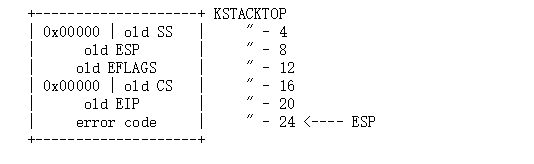
对于发生嵌套异常和中断,由于堆栈不用更改,所以就不用保存 SS和ESP
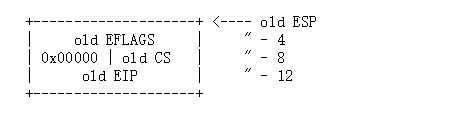
参考代码:http://www.mamicode.com/info-detail-2493874.html
(5)gdb断点设置方式
1. 根据函数名
例如 : b func
2. 根据代码所在行
例如: b /home/lmh/test.c:34 // 断点设在34行
3. 根据运行时地址
例如 : b *0x5859c0
11.11号
(1) Raft
Raft动画 http://thesecretlivesofdata.com/raft/ // 很棒
Raft论文 英文:https://pdos.csail.mit.edu/6.824/papers/raft-extended.pdf 中文:https://github.com/maemual/raft-zh_cn/blob/master/raft-zh_cn.md
主要解决 分布式系统下共识的问题
每个节点有三个状态: Follower(追随者), Candidate(候选人), Leader(领导者)
两种RPC:RequestVote(请求投票),AppendEntries(追加log,作为心跳包)
以及两个超时设置来控制选举:election timeout(选举超时,会随机在150~300ms),heartbeat time(心跳时间)
开始所有节点都在Follower状态,开始等待选举超时,对于先超时的节点会成为候选人,给自己发送投票同时会发送请求投票给其他节点(),当节点没有给其他节点投票过时,就会投票给候选人,并且重置选举超时时间。当某个候选人获得大多数投票,就会成为领导者。领导者会发送日志给其他追随者以心跳时间,追随者会响应追加的日志,领导者收到响应以后会进行值的更改。
(2)6.824 lab2
挠头git pull以后也没有labrpc
好难啊!求一个手把手教学的博客
论文的Figure2 https://blog.csdn.net/Miracle_ma/article/details/80030610
参数讲解 https://www.cnblogs.com/lushilin/p/9268969.html
11.7号
(1) 6.824-lab1-part3/4/5
par3-4
1. 通过增加sync.WaitGroup,最后Wait 判断任务是否完成
2. 每次将序列号分给worker
part5
mapF函数:将输入的文件名对应内容,拆分成,每个单词对应文件名
reduceF函数:将相同单词对应的文件名放在map中去重,然后用数据排好序,将字符串连接并返回
11.6号
(1) go语言
首先是不同的定义方式,int在后面,这样a/b/c都是Int类型,当然也不需要分号结尾 var a, b, c int 函数定义, 开始看的只有num2还以为打错了,结果竟然也是一起定义成了int类型 func max(num1, num2 int) int { ... }
声明长度为10的float32类型数组,名为balance。如果要初始化直接在后面加个大括号即可。
var balance [10] float32
int型指针, 用法同c语言
var ip *int
结构体
type Books struct {
title string
author string
subject string
book_id int
}
切片, 类似vector可以不指定容量,指定的话也只是长度,可以扩展
s :=[] int {1,2,3}
s :=make([]int,3,5) // 长度3,容量5
len(s) cap(s) // 分别计算长度,与容量
s[l:r] // 获取闭区间l到开区间r的切片
append // 用于追加
range进行遍历。对于遍历数组nums,i是序列号,num是值。如果遍历map,则是key与value。
for i, num := range nums {
if num == 3 {
fmt.Println("index:", i)
}
}
map,创建map的两种方式,以及初始化的方式
var countryCapitalMap map[string]string /*创建集合 */
countryCapitalMap = make(map[string]string)
countryCapitalMap [ "France" ] = "巴黎"
类型转换
var z int;
float32(z); //转换为float32
通过go 关键字开启新线程,实现并发
例如:say是一个输出字符串的函数
go say("world")
say("hello")
则会没有先后顺序的输出world 和 hello
通道。可用来同步运行和通讯。
ch := make(chan int)
ch <- v // 把 v 发送到通道 ch
v := <-ch // 从 ch 接收数据 并把值赋给 v
通道缓冲区。与通道唯一区别就是,而发送端可以把数据发送到缓冲区,若缓冲区满了,就会如同不带缓冲区一样一直阻塞
ch := make(chan int, 100)
:=与=的区别
:=会直接把类型赋值过去
=只会把值赋值过去
defer 延迟语句
会在函数返回之前,按照defer逆序顺序执行,防止文件忘记关闭等等
(2) 6.824-lab1-part1
mapReduce实现流程:
1. 提供了map函数,reduce函数,reduce的数量(nReduce)。
2. 建立一个master结点,启动rpc进程,等待worker来注册,可用以后调用schedule来将任务分配给worker,并解决failures。
3. master认为每个输入文件,对应一个map任务,map任务至少执行一次doMap,并产生nReduce个文件。
4. master为每个reduce至少调用一次doReduce, 并产生nReduce个结果文件。
5. master节点调用mr.merge函数将结果文件整合成1个文件。
6. master节点发送1个Shutdown的RPC调用到每个worker,来关闭它们的RPC server。
doMap函数:
1. 读取inFile文件转为key/value
2. 通过hash函数将其放到对于切片中
3. 通过json编码
doReduce
1. 获取key/value 并进行排序
2. 将key相同的value通过reduceF()合并
3. 将新的key/value写入文件
查找属于哪个库的太难了。。。
go库 https://studygolang.com/pkgdoc
(3) 6.824-lab1-part2
mapF:根据空格分隔成字符串,转成:字符串->1 的key/value
reduceF : 将value相加,返回
参考资料:
https://www.cnblogs.com/sindy/p/10767535.html
https://www.jianshu.com/p/2292f4dc85af
11.5号
(1)6.828 Lab2-part2/3
x86系统地址转换: 虚拟地址->线性地址->物理地址
其中我们的CR3寄存器保存了表的首地址.
页目录表: 也称为PDE,而页表称之为PTE.
CPU会通过虚拟地址,当作下表.去页目录表中查询.然后查到的结果再去页表中查询.这样就查到对应的物理地址了.
PDE表的大小:
页目录表,存储在一个4K字节的物理页中,其中每一项是4个字节.保存了页表的地址.
而最大是1M个页.
PTE表的大小.
PTE的大小也和PDE一样的.
对于32位虚拟地址,前10位与CR3的表首地址找到页表地址,再结合之后10位算出页表项,取出地址与最后12位结合作为物理地址。
为了绕过MMU的线性地址转换机制,JOS将虚拟地址0xf0000000映射到物理地址0x0处。
物理地址(pa)转为虚拟地址(va),可以通过KADDR(pa), 反过来就是PADDR(va)
struct PageInfo的pp_ref字段记录了引用次数,当次数为0,代表可以释放
填充函数:
pgdir_walk() : 查找页表项。通过页目录地址和虚拟地址找到页表地址,要是没有就根据create来判断是否创建,并将页表地址与虚拟地址结合返回页表项。
boot_map_region():将虚拟地址与物理地址进行映射。获取每一个页表项,存储相应物理地址。
page_lookup():查找物理地址对应的PageInfo结构地址。通过结合虚拟地址查找页表项,获取物理地址,转为PageInfo
page_remove():获取页表项,将其引用次数减少,并根据情况判断是否释放。
page_insert():获取页表项,将其映射到当前要求的物理地址。

基本照着抄。。。 https://www.e-learn.cn/content/linux/1318600
(2) 6.824 序
11.4号
(1)6.828 Lab2-part1
填充函数
boot_alloc: 分配内存。 end是kernel结束的位置,所以第一次内存分配需要初始化到kernel之后,用nextfree来记录当前分配到的位置,并且需要对齐。
mem_init:内存初始化。实现了为pages数组分配空间。
page_init:将pages数组进行初始化,对于未分配的插入到链表头(page_free_list)。
物理内存主要分成这三个部分
- 0x00000~0xA0000:这部分叫做basemem,是可用的。
- 接着是0xA0000~0x100000:这部分叫做IO Hole,不可用。
- 再接着就是0x100000以上的部分:这部分叫做extmem,可用。
已经分配:pp_ref=1,pp_link=NULL
未分配:pp_ref=1,pp_link=page_free_list
page_alloc: 分配page,记得转换到虚拟地址
参考资料:https://www.e-learn.cn/content/linux/1318600
11.3号
(1)6.828 HW: Boot xv6
操作系统启动 https://blog.csdn.net/DorMOUSENone/article/details/89431931
从0x7c00 (the boot loader 开始)到0x0010000c (内核开始) https://blog.csdn.net/a747979985/article/details/94830777
达到kernel的步骤
1. BIOS启动 :系统检查及初始化,寻找boot sector将控制权转移给BootLoader
2. BootLoader:实模式转为保护模式,读取kernel代码,并把控制权转给kernel。
在磁盘的第一个sector,存储并操作了boot.s和boot.c
boot.s 转为32位模式,启动boot.c
boot.c 读取内核到内存,并将控制权给内核
3. kernel (0X0010000C)
(2) gdb调试
gdb各种参数 https://blog.csdn.net/zdy0_2004/article/details/80102076
(3)shell
6.828-Homework: shell(锻炼写一些命令) https://pdos.csail.mit.edu/6.828/2018/homework/xv6-shell.html
可执行命令:例如:获取的ls命令。将其拼接为 /bin/ls, 通过execv 来取代进程内的内容。
11.2号
(1)通过6.828再次学习汇编
PC及汇编 https://pdos.csail.mit.edu/6.828/2018/lec/l-x86.pdf
ebp为当前栈的栈底,esp为栈顶。 栈会随着栈底到栈顶,地址从高到底。
(2)制作cmake
学习资料 : https://blog.csdn.net/robinhjwy/article/details/78856454
大佬实现:https://www.jianshu.com/p/64385b80210b
难点在于制作CMakeLists.txt 文件 (前置工作:写好.cpp/.h文件。后续工作:cmake 文件所在位置, make)
// CMakeLists.txt 文件
cmake_minimum_required( VERSION 2.8 ) // 要求最低版本 project( LMH ) // 项目名 没用 add_library( ADD_shared SHARED A.cpp ) // 生成库 add_executable( My my.cpp ) // 可执行代码 my.cpp就是主函数所在位置, My就是最终执行代码 target_link_libraries( My ADD_shared ) // 链接
(3)库
静态链接库:libXXX.a // 编译时库的内容会和源文件一同生成可执行文件,因此编译以后不需要读取库的内容了。缺点:若库要升级,需要重新编译
动态链接库(共享库): libXXX.so // 编译时只记录了路径,名字等少量信息,因此并没有整合到可执行文件,只在执行时进行读取,因此库升级也不需要重新编译。缺点:库不能随意删除或者移动。
(4)自己制作makefile
cmake的产生是由于文件过多时,手写makefile会比较麻烦。
my:A.o my.o gcc A.o my.o -o my my.o: gcc -c my.cpp -o my.o A.o: gcc -c A.cpp -o A.o clean: rm -rf *.o
C源文件到可执行文件会经历4个过程:
1. 预处理:主要做加载头文件、宏替换、条件编译。生成 .i 文件。
2. 编译:生成中间代码或者汇编代码。生成 .S 文件。
3. 汇编:转为2进制目标代码。生成 .o 文件。
4. 链接:将目标文件,启动代码,库文件链接成可执行文件。生成 .exe 文件。
10.11号
(1)继续学习6.828的lab1-part3
辅助学习6.828的资料 https://www.jianshu.com/p/af9d7eee635e
(2)理解函数调用栈
对于调用fun函数
C++
void fun(int,int);
int main()
{
fun(1,2);
return 0;
}
汇编
pushl %ebp //将之前ebp(基址指针寄存器)的值入栈 (为fun做准备) movl %esp, %ebp //将当前指针位置作为下一个函数的ebp subl $8, %esp //两个int形参数,所以留出2*4的位置,‘-’是由于栈从上往下 movl $2, 4(%esp) //导入参数 2 movl $1, (%esp) //导入参数 1 call fun //调用fun函数 movl $0, %eax //返回0做准备 leave //相当于push和mov的逆操作 ret // 本个函数返回
10.10号
(1)OLTP与OLAP区别
业务类系统主要供基层人员使用,进行一线业务操作,通常被称为OLTP(On-Line Transaction Processing,联机事务处理)。(比如Mysql,Oracle等产品)
数据分析的目标则是探索并挖掘数据价值,作为企业高层进行决策的参考,通常被称为OLAP(On-Line Analytical Processing,联机分析处理)。(比如Hive Hbase等)
个人理解:直接进行sql之类的操作就是OLTP,对于积累的大量数据进行深入分析就是OLAP
(2)行式存储与列式存储的区别
如图,一个按照行依次存储一个按照列。

行式存储的优势在于每次写入一行数据,都是连续写入,但对于列式存储就要将一条数据拆分多个单列分别写入。
对于读取数据,通常行式存储会把所有列都读取出来,在内存中进行消除冗余列。而列式存储每次读取选取列。
在数据存储时,由于同一列的数据是同一类型,因此数据解析压缩也会更容易。同时对于例如性别这类只有 ‘男’/‘女’ 可以用位图来表示更容易压缩。
(3)6.828 lab1的part2
boot.S文件https://blog.csdn.net/weixin_33947521/article/details/91890683
main.c文件 https://blog.csdn.net/weixin_33895516/article/details/91890674
(4) gdb
x/nfu addr 查看addr地址之后n个以f形式展示的u类型的数据
n:数据个数
f:‘x’, ‘d’, ‘u’, ‘o’, ‘t’, ‘a’, ‘c’, ‘f’, ‘s’
u:b(字节) ,h(半个字), w(一个字), g(两个字)
gdb手册 https://sourceware.org/gdb/current/onlinedocs/gdb/Memory.html
gdb手册 https://www.cnblogs.com/zlcxbb/p/6441356.html
阅读资料
6.828 lab1的资料 https://blog.csdn.net/a747979985/article/details/94334901
行式存储和列式存储区别 :https://blog.csdn.net/qq_43295093/article/details/85226756

 浙公网安备 33010602011771号
浙公网安备 33010602011771号