C语言第十一次作业--函数嵌套调用
一、实验作业
1.1 PTA题目:递归法对任意10个数据按降序排序
设计思路
定义整型循环变量i,最小值下标min,中间变量t
若n==1,直接返回
否则
min=10-n 最小值下标赋初值
for i= 10-n to 10
若a[i]小于a[min]
交换下标min=i
利用中间变量
t=a[min]
a[min]=a[10-n]
a[10-n]=t
再次进入递归 sort(a,n-1)
代码截图

调试问题

刚开始我判断n时,直接if(n),提交后答案错误,才拿到dev里运行,发现他直接返回了。
这个错误是因为平时flag思维习惯了,认为if(n)等价于if(n==1)。但其实如果n为整型,if(n)判断n是否为0,如果是0执行else后语句,否则执行if后语句。也就是说只要n不为0,就执行if后的语句。所以会直接返回。
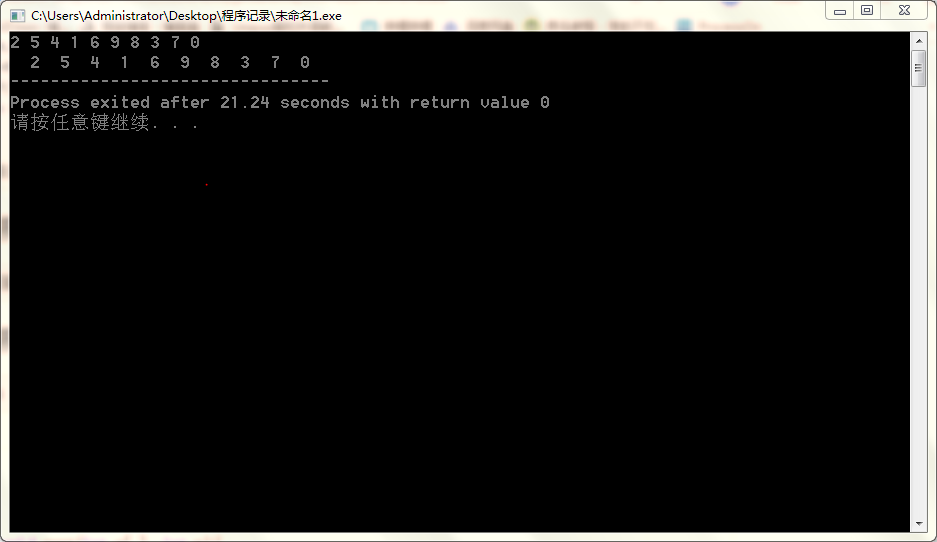
1.2 学生成绩管理系统
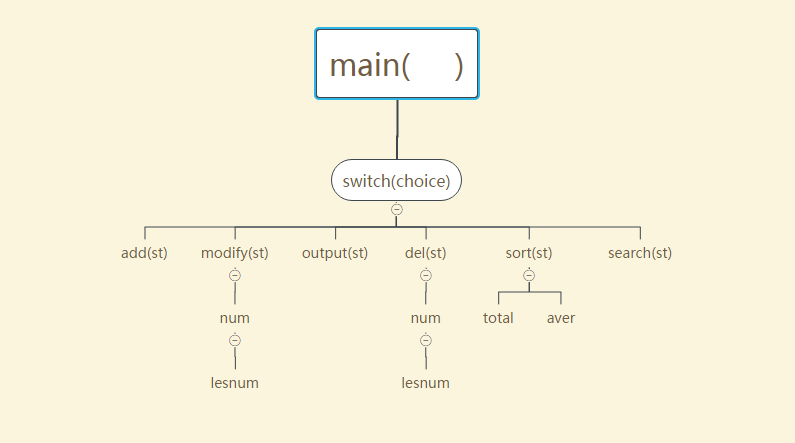
1.2.1 画函数模块图,简要介绍函数功能
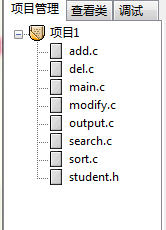
1.2.2 截图展示你的工程文件
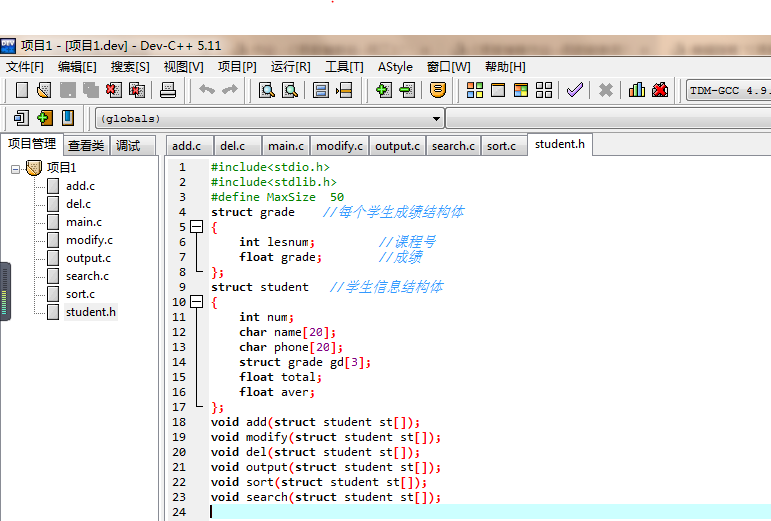
1.2.3 函数代码部分截图
本系统代码总行数:222
-
头文件
-
主函数
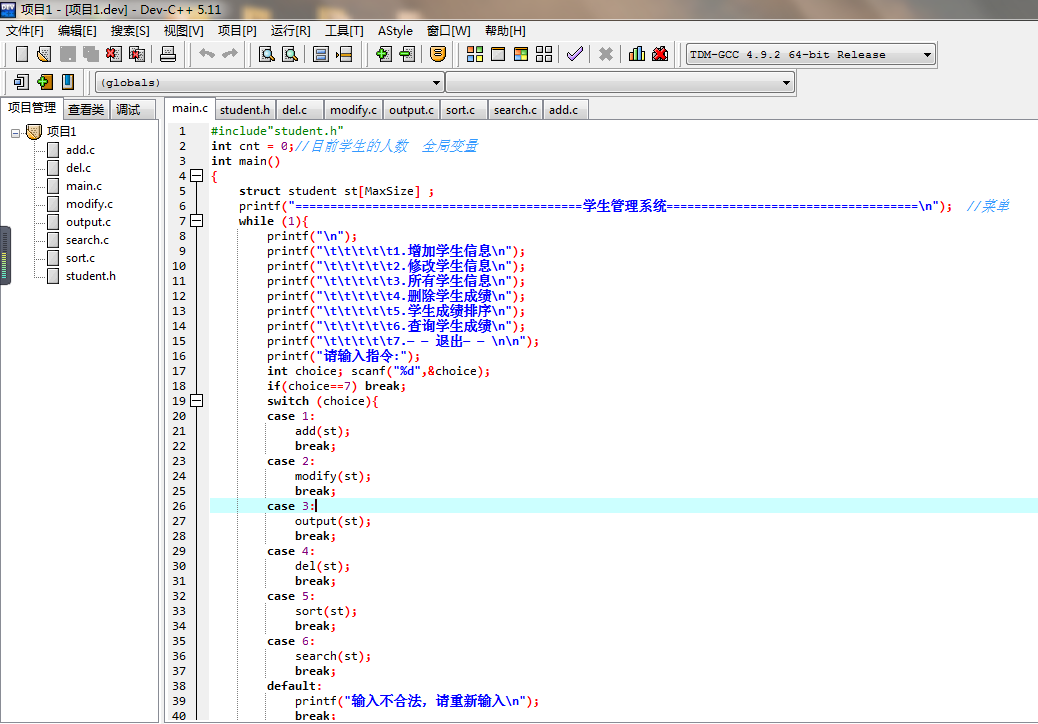
-
插入学生信息

-
学生成绩信息代码
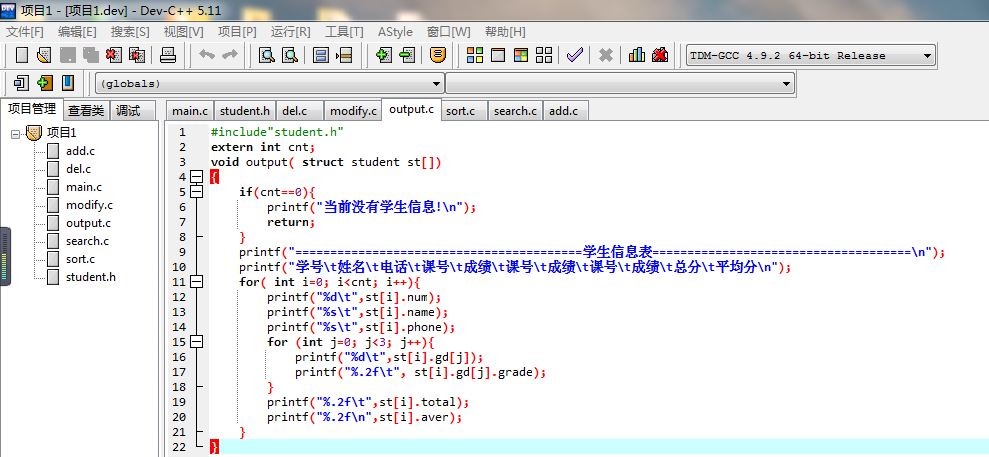
-
删除学生成绩信息代码
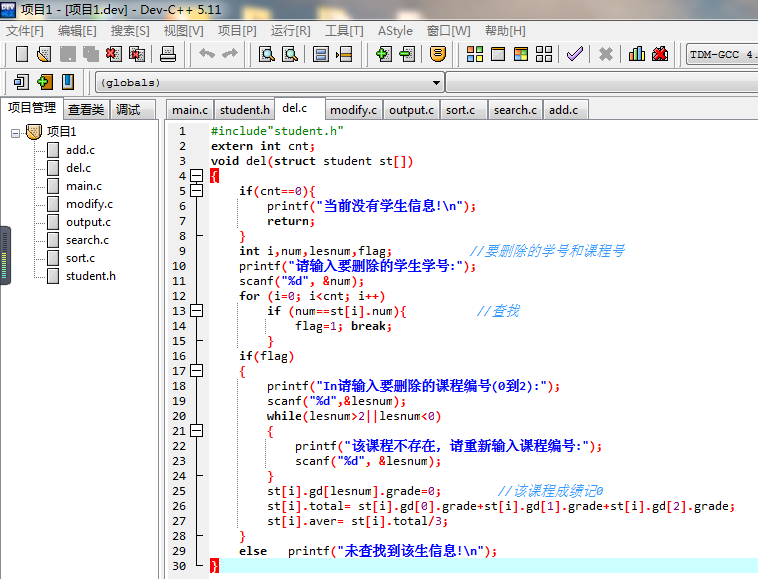
-
总分排序代码
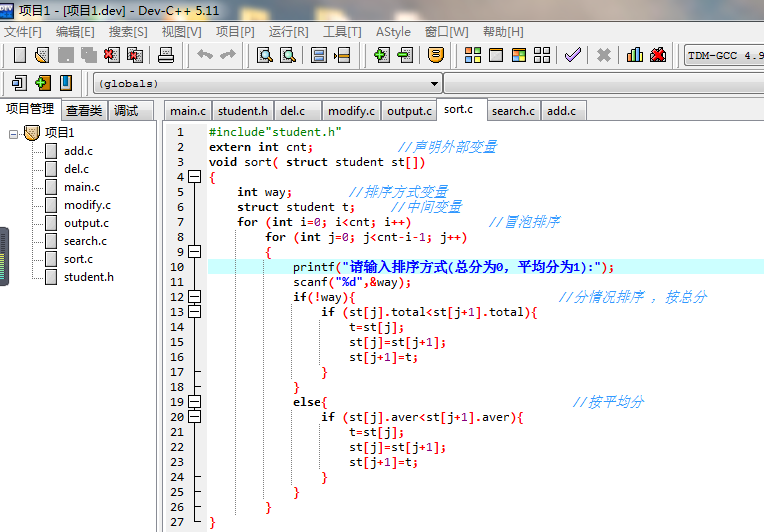
1.2.4 调试结果展示
未添加学生就进行操作的错误指令
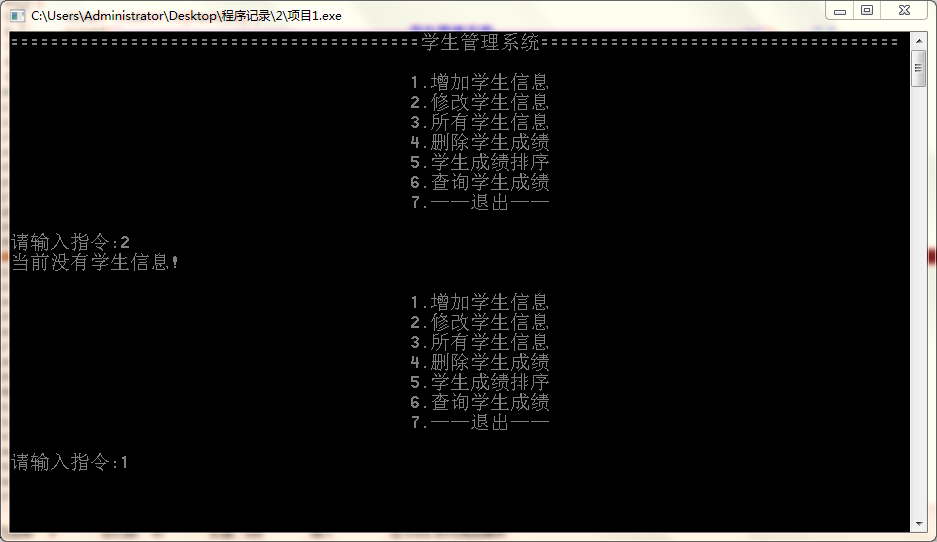
主菜单及添加学生信息
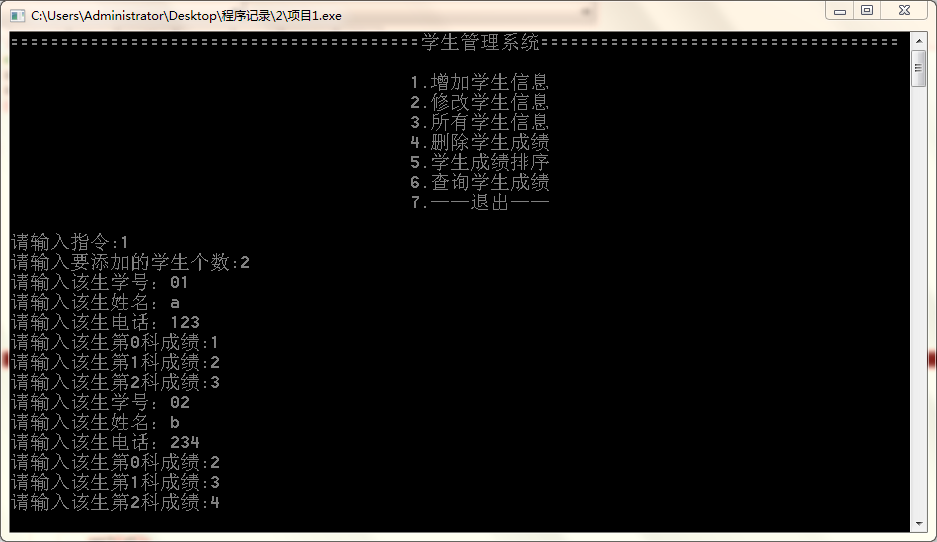
输出信息表
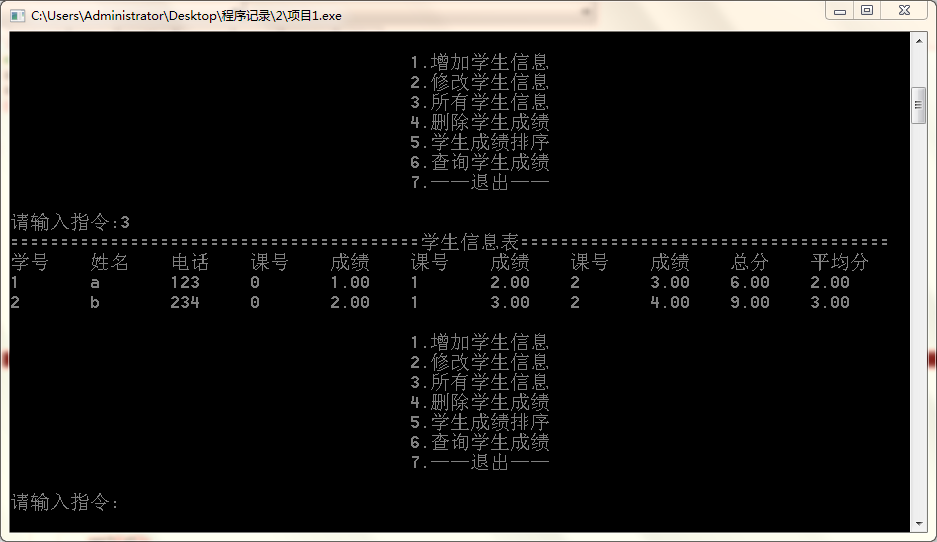
修改某位同学某课程的成绩

删除某位同学某个课程的成绩
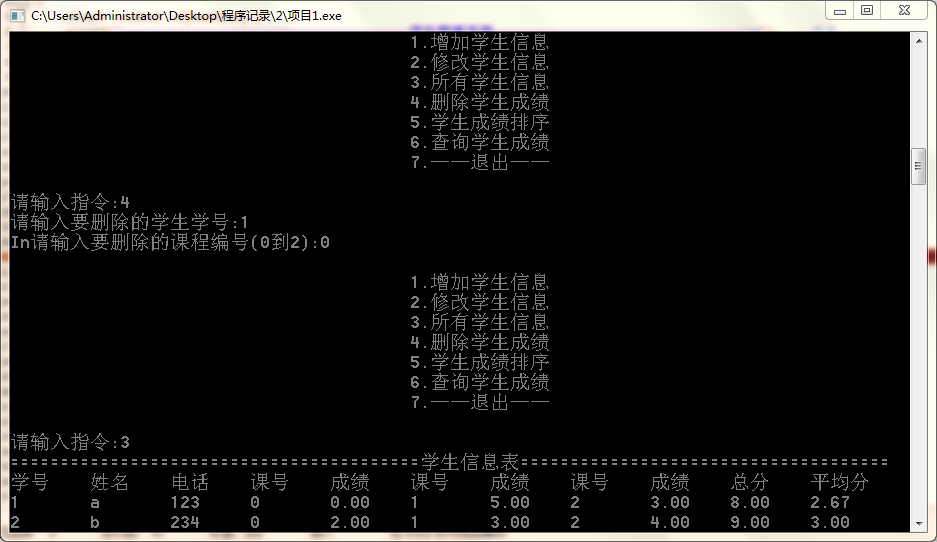
1.2.5 调试碰到问题及解决办法
- 1.建工程的过程中,错误太多了,但没有记录下来,其中印象最深的是头文件里加不加函数声明,我记得之前没加时它主函数哪里会提醒各种函数没声明的错误,但是刚刚又试了下去掉函数声明,竟然编译通过了,怀疑人生ing。
-
2.[Linker error] main.o:main.cpp:(.text+0x49): undefined reference to xxxx,我多次出现的这个编译错误特别没水平:是自己的工程没有把所有的相关文件放在一个工程里面,虽然都放在了一个文件夹下,但是是自己强行放在了一起,而不是建工程时一起建的文件夹,后来重新建工程就解决了。
-
3.还有一个困扰很久的的问题是:头文件里的变量被重复定义,后来问了同学,才搞清楚每个文件里都要加上头文件。还是对于建工程的细节不够明白。
总结:
- 头文件:头文件中不能有可执行代码,也不能有数据的定义,只能有宏、类型(typedef,struct,union,menu,class)数据和函数的声明。
- 头文件加#ifndef #endif可以防止它在同一编译单元被重复引用。
- 全局变量重复定义问题:写程序时,最好不要在头文件中定义全局变量。因为这时该头文件被多个源文件包含时,就会出现重复定义问题。全局变量的定义就应该放 某个源文件中,然后在别的源文件中使用前进行extern声明。
- 在用<>时,编译器查找顺序是:先在系统区域查找,再查找自定义区域。用”“时,编译器查找顺序相反。
二、截图本周题目集的PTA最后排名

三、阅读代码
斐波那契数列
#include <stdio.h>
int fib1(int n)
int fib2(int n);
int main()
{
int n=0;
printf("fibonacci数列下标:\n");
scanf("%d",&n);
printf("第n=%d的数列值是:%d\n",n, fib1(n));
return 0;
}
//非递归
int fib2(int n)
{
int a = 1;
int b = 1;
int c = a = b;
int i = 0;
for (i = 3; i <= n; i++)
{
c = a + b;
a = b;
b = c;
}
return c;
}
//递归
int fib1(int n)
{
if (n <= 2)
return 1;
else
return fib1(n - 2) + fib1(n - 1);
}
这道题是之前刚学习函数知识时的一道题,学了递归后就把它用递归思路简化了下。虽然递归思路不太好想,但是它代码更简洁清晰,可读性更好。但是递归它也有缺点:空间消耗要比非递归代码要大很多。所以递归空间和时间消耗都大。
四、本周学习总结
1.介绍本周学习内容
链表相关内容总结:
动态内存的分配:
- malloc函数
void* malloc ( unsigned int size )
char * a;
a=( char *)malloc( 10*( sizeof( char ) );
//申请一块10*( sizeof( char )这么大的动态内存,并返回这块内存的地址。
函数理解:在内存的动态存储区中分配一个长度为size的连续空间,其参数应该是一个无符号整数,返回值是一个系统所分配的,连续内存空间的起始地址。 若分配内存失败,则返回NULL。
PS:该函数仅针对指针使用。
- free函数
void * free( void * p)
char *a,*b;
a=( char *)malloc( 10*( sizeof( char ) );
b=a;
...
free(a);//释放其指向的动态内存
链表:

-
概念理解:链表这种数据结构是为了实现动态保存一串数据,这里的动态是指不需要预先分配内存空间,而是在需要时动态申请内存。整个数据串保存所需的空间可以根据需要扩大或缩小。它由若干个同一结构类型的“结点”依次串接而成。而且这各个结点在内存中可以使不连续存放的。
PS:数组是线性结构,链表时链性结构。 -
链表的节点结构:
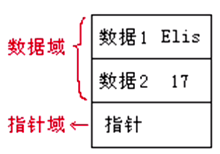
1.数据域:用来存储数据。
2.指针域:存储下一个节点元素的地址 。 -
用链表代替数组的优点:
1.不需要事先定义存储空间大小,可以实现动态分配内存,内存使用效率高。
2.插入删除新结点方便,操作效率高。
1.1易错点
-
编译预处理不是C语言的一部分,不占运行时间,不要加分号
-
函数的递归调用一定要记得有结束的条件
-
static int x;默认值为0。 int x;默认值为不定值
1.2宏定义
-
无参宏定义 #define 标识符 值 定义后,出现所定义的标识符的地方都 将以定义时指定的值来代替。
-
带参宏定义 #define 标识符(参数表) 值
#define S(x,y) x*y
int main( )
{
int a=3,b=4,c=5,d=6;
printf("a+b*c+d=%d\n" , S(a+b,c+d));
}
带参宏定义执行时是将a+b这样一个表达式代替x,c+d这样一个表达式代替y,所以S(a+b,c+d)进行的是a+bc+d的运算,而不是将a+b的值给x,c+d的值给y然后再做xy,这跟函数调用传递参数是不一样的。
- 常用预处理指令:
include 包含一个源代码文件
define 定义宏
undef 取消定义宏
if 如果条件为真,则编译下面的代码
endif 结束一个#if...#elif条件编译块
ifdef 如果已经定义了某个宏,则编译下面的代码
ifndef 如果没有定义某个宏,则编译下面的代码
1.3指针数组
- 定义指针数组:类型名 * 变量名[数组长度];
int * p[10];
- 指针数组的数组元素都是指针变量,是用来存放变量的地址的
1.4行指针
- 定义行指针变量: 类型名 (*变量名)[数组长度];
int (*p)[4],a[3][4];
p=a;
此时就可把p当成a来用。
1.5指向指针的指针:
- 定义: 类型名 ** 变量名;
int *p1;
int **p2;
int a=3;
- 指针变量也是一种变量,故在内存中也有对应的一个地址, 而要存放指针变量的地址,就要求助于用来存放指针变量的地址的指针变量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号