实验一:决策树算法实验
实验一:决策树算法实验
| 名称 | 内容 |
|---|---|
| 姓名 | 李鸣 |
| 学号 | 201613331 |
【实验目的】
- 理解决策树算法原理,掌握决策树算法框架;
- 理解决策树学习算法的特征选择、树的生成和树的剪枝;
- 能根据不同的数据类型,选择不同的决策树算法;
- 针对特定应用场景及数据,能应用决策树算法解决实际问题。
【实验内容】
- 设计算法实现熵、经验条件熵、信息增益等方法。
- 针对给定的房贷数据集(数据集表格见附录1)实现ID3算法。
- 熟悉sklearn库中的决策树算法;
- 针对iris数据集,应用sklearn的决策树算法进行类别预测。
【实验报告要求】
- 对照实验内容,撰写实验过程、算法及测试结果;
- 代码规范化:命名规则、注释;
- 查阅文献,讨论ID3、5算法的应用场景;
- 查询文献,分析决策树剪枝策略。
【附录1】
| 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 | |
|---|---|---|---|---|---|
| 0 | 青年 | 否 | 否 | 一般 | 否 |
| 1 | 青年 | 否 | 否 | 好 | 否 |
| 2 | 青年 | 是 | 否 | 好 | 是 |
| 3 | 青年 | 是 | 是 | 一般 | 是 |
| 4 | 青年 | 否 | 否 | 一般 | 否 |
| 5 | 中年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 好 | 否 |
| 7 | 中年 | 是 | 是 | 好 | 是 |
| 8 | 中年 | 否 | 是 | 非常好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 老年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 好 | 是 |
| 12 | 老年 | 是 | 否 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 非常好 | 是 |
| 14 | 老年 | 否 | 否 | 一般 | 否 |
实验过程与步骤:
1.设计算法实现熵、经验条件熵、信息增益等方法:
# 导入需要的包
import numpy as np
import pandas as pd
from math import log
# 数据集和分类属性
def create_data():
datasets = [['青年', '否', '否', '一般', '否'], # 数据集
['青年', '否', '否', '好', '否'],
['青年', '是', '否', '好', '是'],
['青年', '是', '是', '一般', '是'],
['青年', '否', '否', '一般', '否'],
['中年', '否', '否', '一般', 否'],
['中年', '否', '否', '好', '否'],
['中年', '是', '是', '好', '是'],
['中年', '否', '是', '非常好', '是'],
['中年', '否', '是', '非常好', '是'],
['老年', '否', '是', '非常好', '是'],
['老年', '否', '是', '好', '是'],
['老年', '是', '否', '好', '是'],
['老年', '是', '否', '非常好', '是'],
['老年', '否', '否', '一般', '否'],]
labels = [u'年龄', u'有工作', u'有自己的房子', u'信贷情况', u'类别'] # 分类属性
return datasets, labels # 返回数据集和分类属性
# 将数据集转为DataFrame表格
datasets, labels = create_data()
train_data = pd.DataFrame(datasets, columns=labels)
计算数据集的熵:
"""
函数说明:计算给定数据集的熵
Parameters:
datasets - 数据集
Returns:
ent - 熵
"""
def calc_ent(datasets):
data_length = len(datasets)
label_count = {}
for i in range(data_length):
label = datasets[i][-1]
if label not in label_count:
label_count[label] = 0
label_count[label] += 1
ent = -sum([(p/data_length)*log(p/data_length, 2) for p in label_count.values()])
return ent
ent = calc_ent(datasets)
en
输出结果:

计算数据集的经验条件熵:
"""
函数说明:计算给定数据集的经验条件熵
Parameters:
datasets - 数据集
Returns:
conf_ent - 经验条件熵
"""
def cond_ent(datasets, axis=0):
data_length = len(datasets)
feature_sets = {}
for i in range(data_length):
feature = datasets[i][axis]
if feature not in feature_sets:
feature_sets[feature] = []
feature_sets[feature].append(datasets[i])
cond_ent = sum([(len(p)/data_length)*calc_ent(p) for p in feature_sets.values()])
return cond_ent
cond_ent = cond_ent(datasets)
cond_ent
输出结果:

计算数据集的信息增益:
# 信息增值
def info_gain(ent, cond_ent):
return ent - cond_ent
def info_gain_train(datasets):
count = len(datasets[0]) - 1
ent = calc_ent(datasets)
best_feature = []
for c in range(count):
c_info_gain = info_gain(ent, cond_ent(datasets, axis=c))
best_feature.append((c, c_info_gain))
print("特征(%s)的信息增益位:%.3f" % (labels[c], c_info_gain))
# 比较大小
best_ = max(best_feature, key=lambda x: x[-1])
return "特征%s的信息增益最大,选择为根节点特征" % (labels[best_[0]])
info_gain_train(np.array(datasets))
运行结果:

2.针对给定的房贷数据集(数据集表格见附录1)实现ID3算法:
ID3完整代码:
##利用ID3算法生成决策树
# 定义节点类 二叉树
class Node:
def __init__(self, root=True, label=None, feature_name=None, feature=None):
self.root = root
self.label = label
self.feature_name = feature_name
self.feature = feature
self.tree = {}
self.result = {'label:': self.label, 'feature': self.feature, 'tree': self.tree}
def __repr__(self):
return '{}'.format(self.result)
def add_node(self, val, node):
self.tree[val] = node
def predict(self, features):
if self.root is True:
return self.label
return self.tree[features[self.feature]].predict(features)
class DTree:
def __init__(self, epsilon=0.1):
self.epsilon = epsilon
self._tree = {}
# 熵
@staticmethod
def calc_ent(datasets):
data_length = len(datasets)
label_count = {}
for i in range(data_length):
label = datasets[i][-1]
if label not in label_count:
label_count[label] = 0
label_count[label] += 1
ent = -sum([(p/data_length)*log(p/data_length, 2) for p in label_count.values()])
return ent
# 经验条件熵
def cond_ent(self, datasets, axis=0):
data_length = len(datasets)
feature_sets = {}
for i in range(data_length):
feature = datasets[i][axis]
if feature not in feature_sets:
feature_sets[feature] = []
feature_sets[feature].append(datasets[i])
cond_ent = sum([(len(p)/data_length)*self.calc_ent(p) for p in feature_sets.values()])
return cond_ent
# 信息增益
@staticmethod
def info_gain(ent, cond_ent):
return ent - cond_ent
def info_gain_train(self, datasets):
count = len(datasets[0]) - 1
ent = self.calc_ent(datasets)
best_feature = []
for c in range(count):
c_info_gain = self.info_gain(ent, self.cond_ent(datasets, axis=c))
best_feature.append((c, c_info_gain))
# 比较大小
best_ = max(best_feature, key=lambda x: x[-1])
return best_
def train(self, train_data):
"""
input:数据集D(DataFrame格式),特征集A,阈值eta
output:决策树T
"""
_, y_train, features = train_data.iloc[:, :-1], train_data.iloc[:, -1], train_data.columns[:-1]
# 1,若D中实例属于同一类Ck,则T为单节点树,并将类Ck作为结点的类标记,返回T
if len(y_train.value_counts()) == 1:
return Node(root=True,
label=y_train.iloc[0])
# 2, 若A为空,则T为单节点树,将D中实例树最大的类Ck作为该节点的类标记,返回T
if len(features) == 0:
return Node(root=True, label=y_train.value_counts().sort_values(ascending=False).index[0])
# 3,计算最大信息增益 同5.1,Ag为信息增益最大的特征
max_feature, max_info_gain = self.info_gain_train(np.array(train_data))
max_feature_name = features[max_feature]
# 4,Ag的信息增益小于阈值eta,则置T为单节点树,并将D中是实例数最大的类Ck作为该节点的类标记,返回T
if max_info_gain < self.epsilon:
return Node(root=True, label=y_train.value_counts().sort_values(ascending=False).index[0])
# 5,构建Ag子集
node_tree = Node(root=False, feature_name=max_feature_name, feature=max_feature)
feature_list = train_data[max_feature_name].value_counts().index
for f in feature_list:
sub_train_df = train_data.loc[train_data[max_feature_name] == f].drop([max_feature_name], axis=1)
# 6, 递归生成树
sub_tree = self.train(sub_train_df)
node_tree.add_node(f, sub_tree)
# pprint.pprint(node_tree.tree)
return node_tree
def fit(self, train_data):
self._tree = self.train(train_data)
return self._tree
def predict(self, X_test):
return self._tree.predict(X_test)
# 创建决策树
datasets, labels = create_data()
data_df = pd.DataFrame(datasets, columns=labels)
dt = DTree()
tree = dt.fit(data_df)
tree
输出:

dt.predict(['老年', '否', '否', '一般'])
输出:
3.针对iris数据集,应用sklearn的决策树算法进行类别预测:
代码:
## 导包
# 数据集
from sklearn import datasets
# 分类器
from sklearn import tree
# 训练集测试集分割模块
from sklearn.model_selection import train_test_split
# 绘制决策树
import graphviz
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 自定义导入数据集函数
def get_data(total_data):
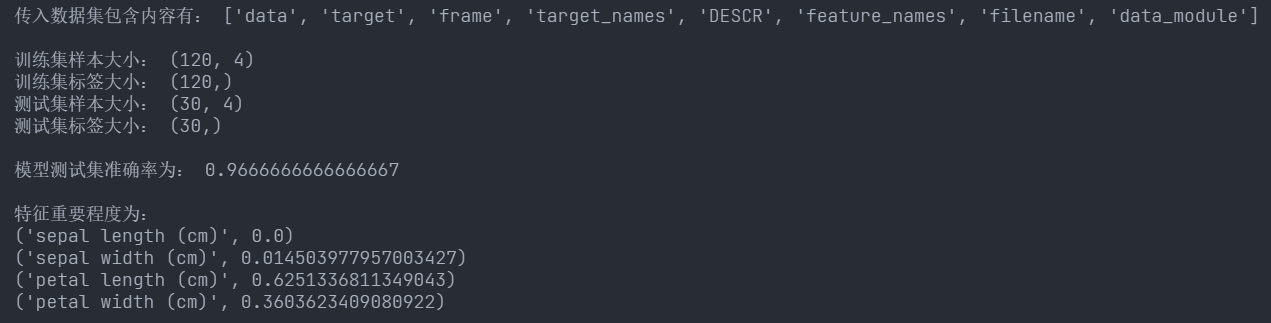
# 显示total_data包含的内容
print("传入数据集包含内容有:", [x for x in total_data.keys()])
# 样本
x_true = total_data.data
# 标签
y_true = total_data.target
# 特征名称
feature_names = total_data.feature_names
# 类名
target_names = total_data.target_names
return x_true, y_true, feature_names, target_names
# 定义主函数
def main():
# 利用自定义函数导入Iris数据集
total_iris = datasets.load_iris()
x_true, y_true, feature_names, target_names = get_data(total_iris)
# 分割数据集
rate_test = 0.2 # 训练集比例
x_train, x_test, y_train, y_test = train_test_split(x_true,
y_true,
test_size= rate_test)
print("\n训练集样本大小:", x_train.shape)
print("训练集标签大小:", y_train.shape)
print("测试集样本大小:", x_test.shape)
print("测试集标签大小:", y_test.shape)
# 设置决策树分类器
clf = tree.DecisionTreeClassifier(criterion="entropy")
# 训练模型
clf.fit(x_train, y_train)
# 评价模型
score = clf.score(x_test, y_test)
print("\n模型测试集准确率为:", score)
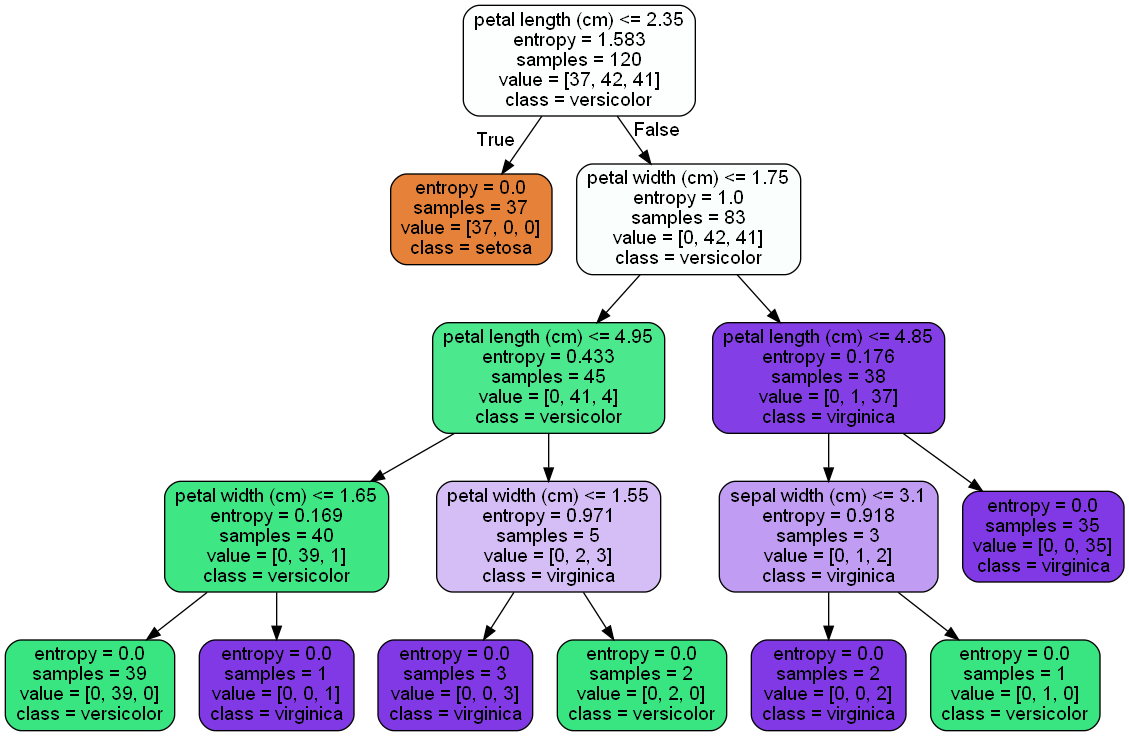
# 绘制决策树模型
clf_dot = tree.export_graphviz(clf,
out_file= None,
feature_names= feature_names,
class_names= target_names,
filled= True,
rounded= True)
# 显示绘制的模型,在当前目录下,保存为png模式
graph = graphviz.Source(clf_dot,
filename= "iris_decisionTree.gv",
format= "png")
graph.view()
# 显示特征重要程度
print("\n特征重要程度为:")
info = [*zip(feature_names, clf.feature_importances_)]
for cell in info:
print(cell)
# 调用主函数
if __name__ == "__main__":
main()
运行结果:
6. 查阅文献,讨论ID3、C4.5算法的应用场景,分析决策树剪枝策略。
-
ID3算法的应用场景:
它的基础理论清晰,算法比较简单,学习能力较强,适于处理大规模的学习问题,是数据挖掘和知识发现领域中的一个很好的范例,为后来各学者提出优化算法奠定了理论基础。ID3算法特别在机器学习、知识发现和数据挖掘等领域得到了极大发展。
-
C4.5算法的应用场景:
C4.5算法具有条理清晰,能处理连续型属性,防止过拟合,准确率较高和适用范围广等优点,是一个很有实用价值的决策树算法,可以用来分类,也可以用来回归。C4.5算法在机器学习、知识发现、金融分析、遥感影像分类、生产制造、分子生物学和数据挖掘等领域得到广泛应用。
-
决策树基本策略:
预剪枝:在决策树生成过程中,对每个节点在划分之前先进行估计,若当前节点的划分不能带来决策树泛化性能的提升,则停止划分,并将当前节点标记为叶节点。
后剪枝:先从训练集中生成一课完整的决策树,然后自底向上对非叶子节点进行考察,若将该节点对应的子树替换为叶子结点能带来决策树泛化性能的提升,则将该子树替换为叶节点。
实验小结
通过这次的实验了解了决策树算法的原理,掌握了决策树算法框架,理解了决策树学习算法的特征选择、树的生成和树的剪枝。知道了怎么根据不同的数据类型选择不同的决策树算法,可以针对不同的应用场景应用决策树算法去解决实际问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号