使用JMeter工具做性能测试
使用Jmeter工具做性能测试
JMeter执行原理
JMerer通过线程组来驱动多个(也可以理解为LR⼯具⾥⾯的虚拟⽤户)运⾏测试脚本对⽬标服务器发起⼤量的⽹络请求,在每个客户端上可以运⾏多个线程组,也就是说⼀个测试计划⾥⾯可以包含N个线程组。
线程数
⼀个线程可以理解为对应模拟⼀个⽤户,所以线程数越多,那么也就认为可以模拟的⽤户数越多。
Ramp-Up时间(秒)
该属性指的是所有线程从启动到开始运⾏的时间间隔,单位是秒,也就是说所有线程在多⻓时间内开始执⾏,如线程数设置50,设置的时间为5秒,那么计算的公式为:每秒执⾏线程数=线程数/Ramp-Up
具体如: 如设置的线程数为50,Ramp-up的时间为10,那么也就是说开启执⾏后,每秒会启动5个线程,如果Ramp-Up设置为0,那么开始执⾏后,50个线程会⽴刻启动。
首先在性能测试下添加一个HTTP请求(对百度发送请求),填写百度地址(有多少个线程数就发送多少个请求)
1.在线程组下添加一个监听器下的查看结果树
查看结果是在监听器中,它的组件具体如下:
a.查看结果树:查看发送网络请求后返回的信息
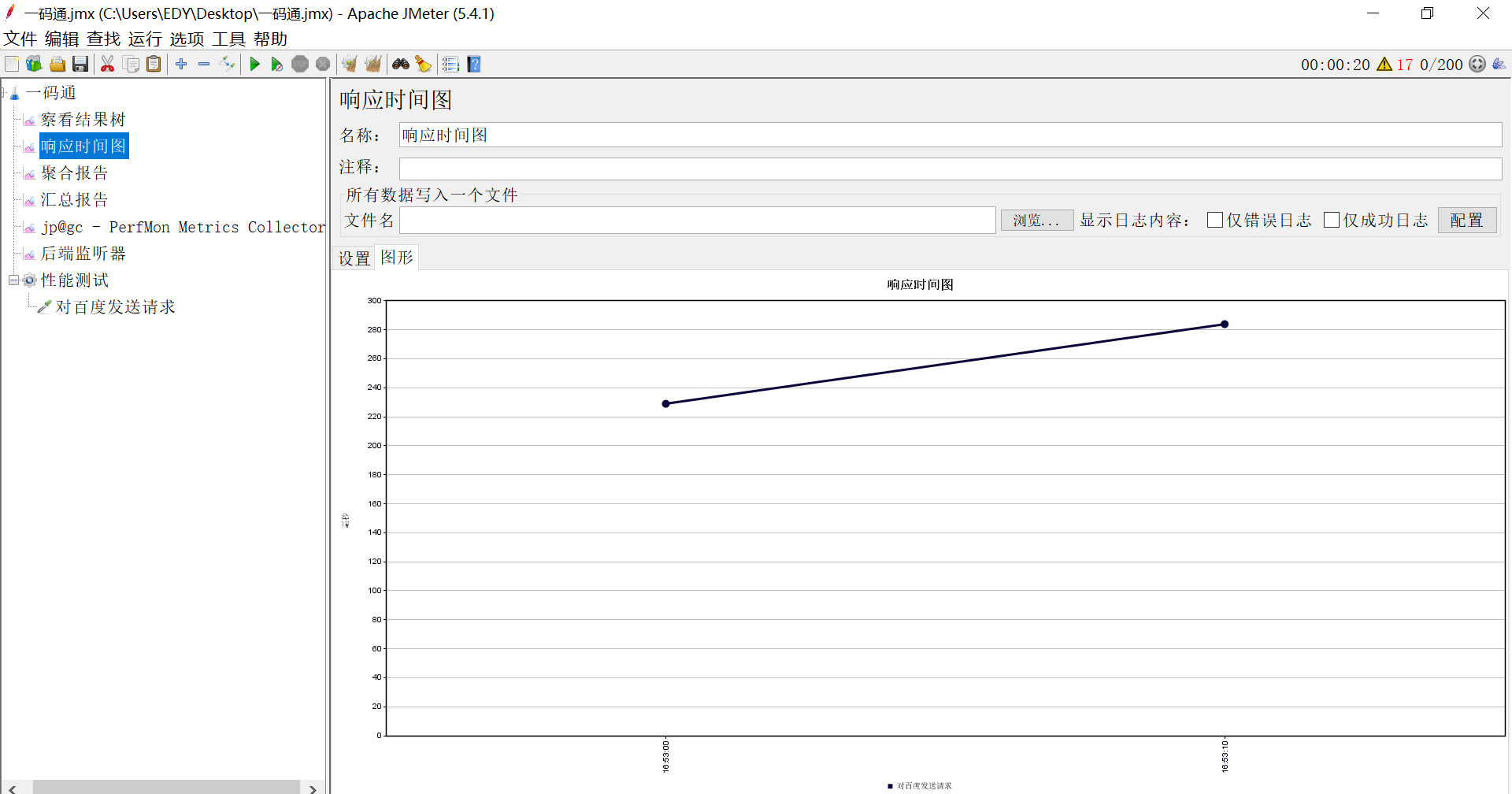
b.响应时间图:发送N次请求过程中响应时间的趋势图
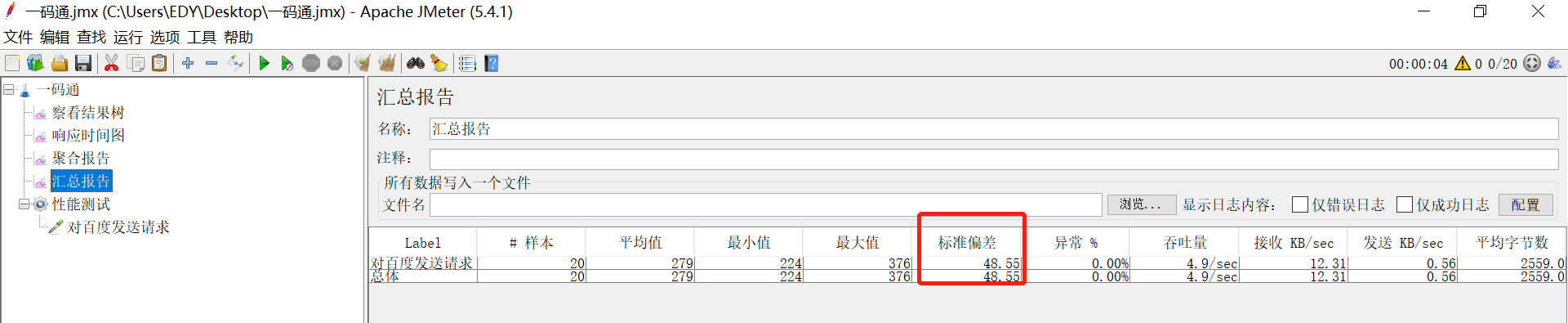
c.聚合报告:里面可以看到吞吐量,最小响应时间,最大响应时间,平均响应时间 ,中位数,90,95,99
在查看结果树当中点击开始按钮,点击任意一个请求查看响应数据,再将text更改成Browser或HTML,就可以看见百度的首页。


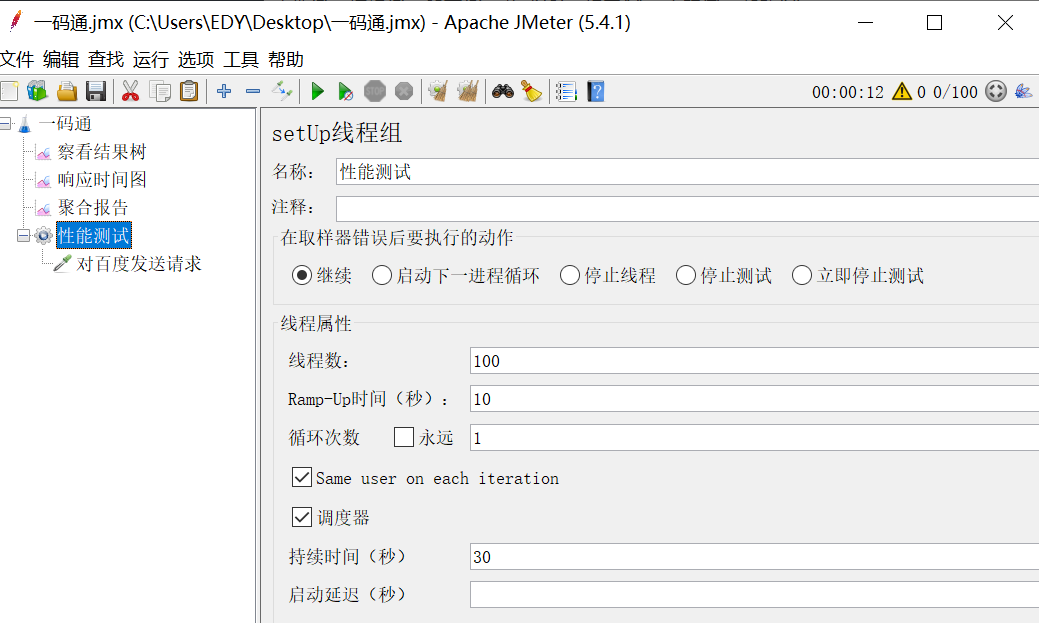
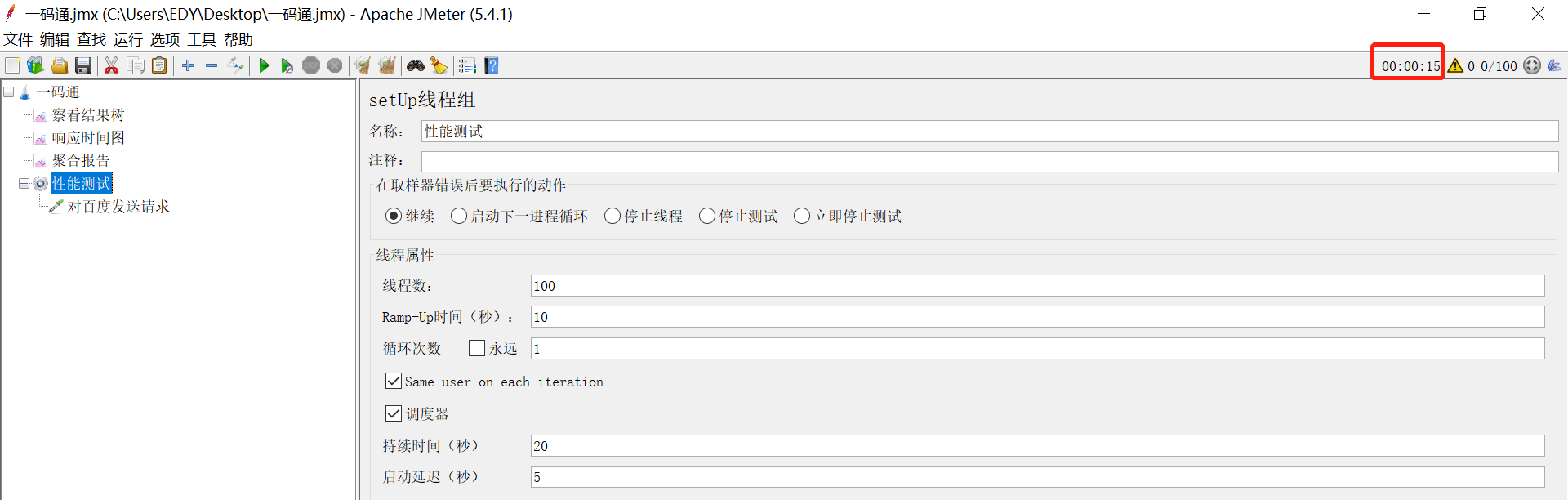
调度器:
持续时间:指的是所有的任务执行完成后,任务再接着执行N秒,目的是验证被测服务的稳定性
例如以下访问百度,100个用户理想效果是10秒执行完,但由于网络等情况实际上10秒内没有执行完,那么我们给它持续上30秒,可以看到右上角实际执行完的时间是12秒。

5.添加PerfMon插件:
1、我们在性能测试的过程中,需要收集被测目标服务器的终端的系统资源
A、在目标服务器部署serveragent(功能就是收集数据)
B、在JMeter连接serveragent,把收集的数据展示出来
没有PerfMon插件需要在选项中安装插件,再添加
ServeAgent的下载和使用
通过ServeAgent收集系统资源的数据,一般是放在被测的目标服务器上,例如我们现在测的是百度,将它放在百度的服务器上不现实,所以放在本地
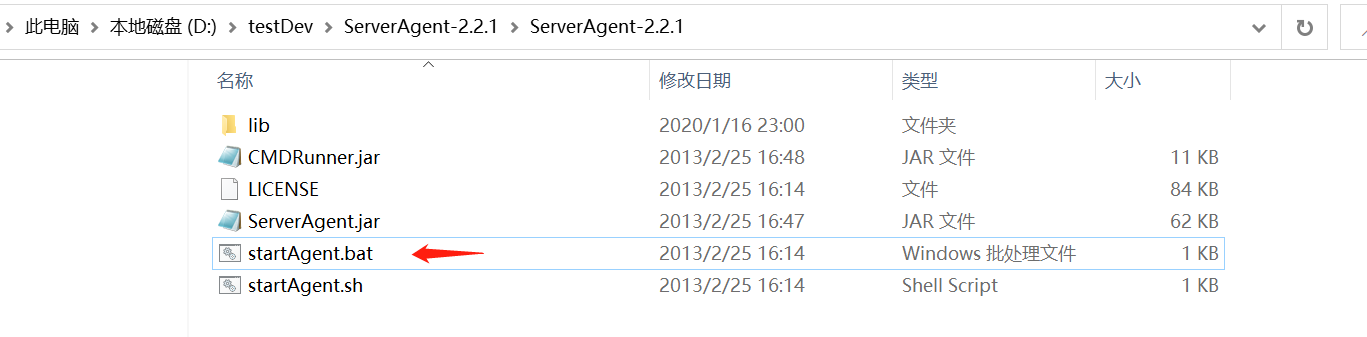
1.下载ServeAgent并解压,我存放在D:\testDev\ServerAgent-2.2.1目录下,点击startAgent.bat启动

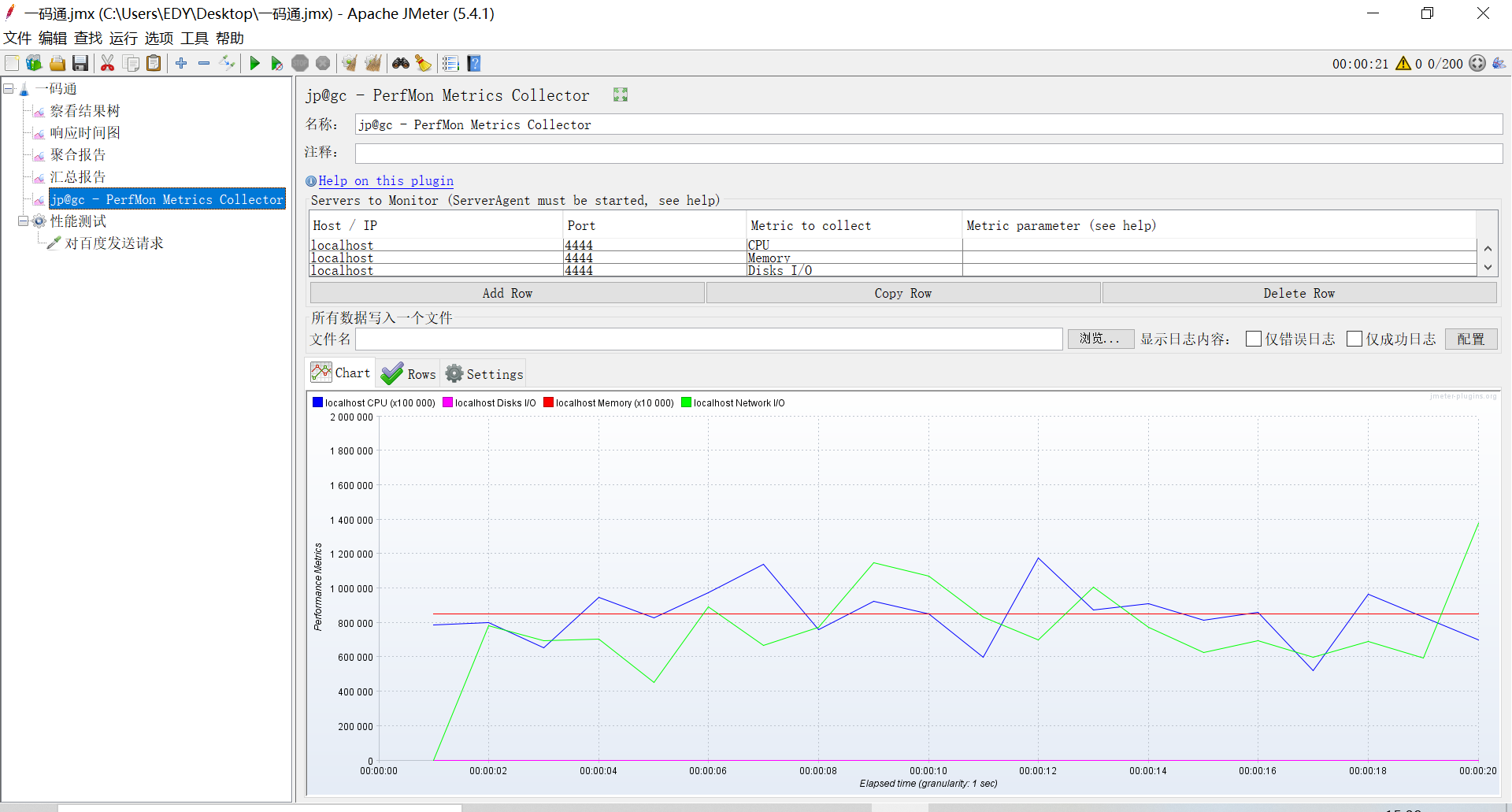
2.启动serveAgent之后,在jmeter中发送请求,打开PerfMon就可以看见监听到的数据(CPU和内存、磁盘、网络等)

Grafana地址:http://47.95.142.233:3000/d/Z6Jz03i7k/apache-jmeter-dashboard?orgId=1&refresh=5s
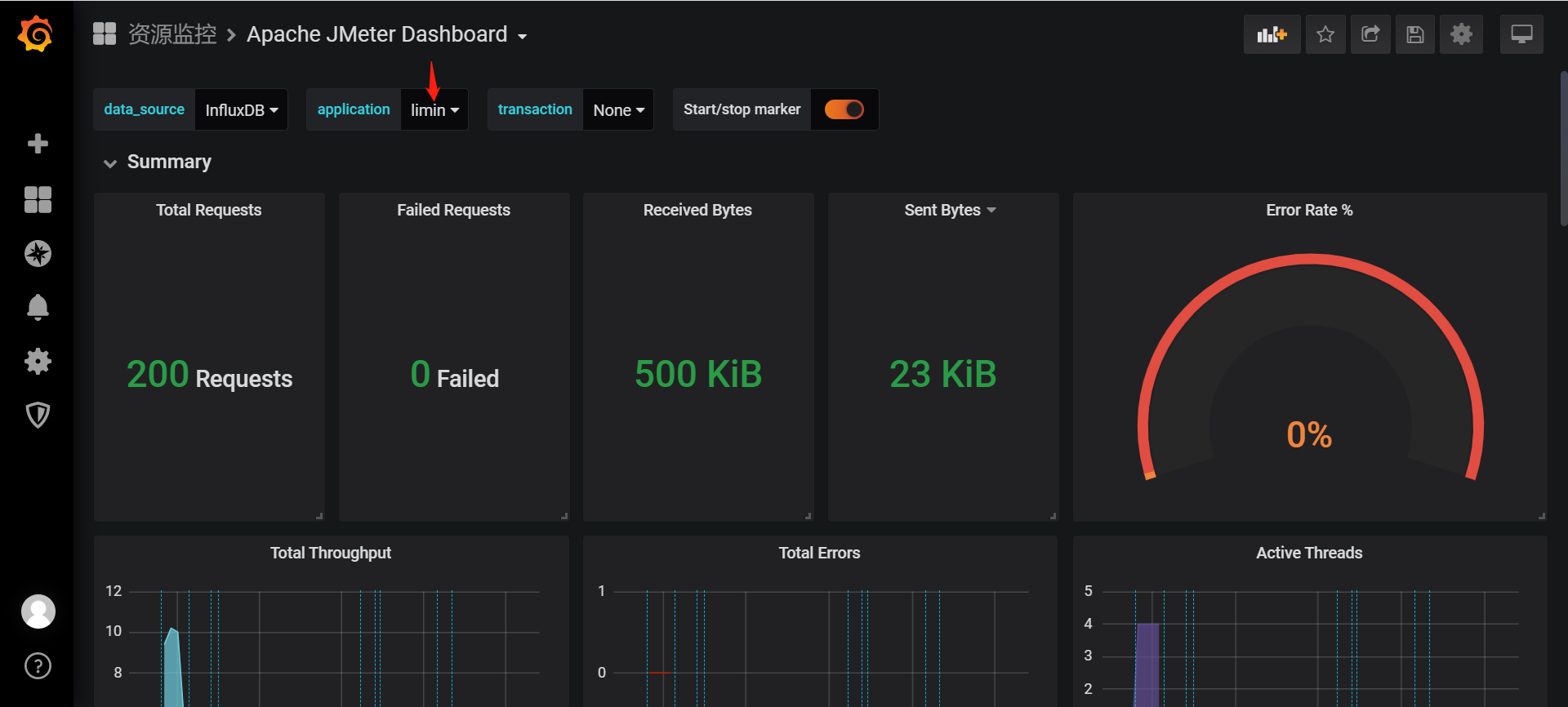
输入账户和密码登录,在Jmeter中将端口地址修改,将application name 修改为自己的名字,再打开Grafana,在application处选择自己的名字就可以看见自己的数据
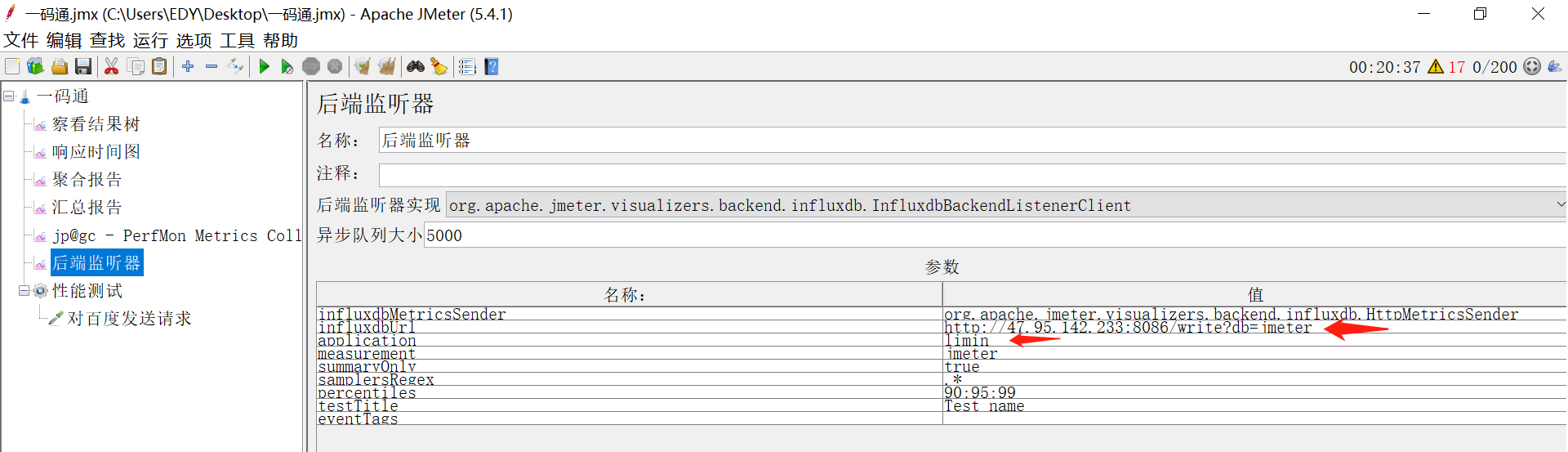
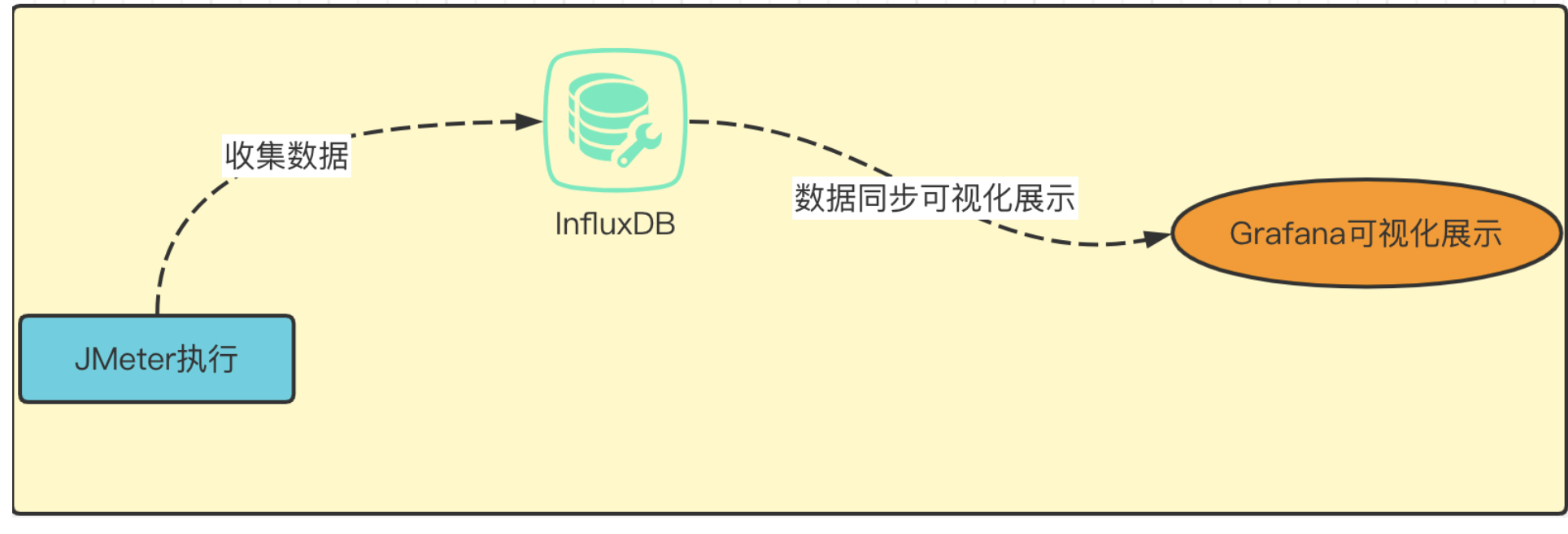
监控的原理:
1.收集数据(数据源:InfluxDB,prometheus)
2,在Grafana的平台展示数据
目前企业使用的都是分布式以及微服务的架构,所以我们在工作里面性能测试大多数时候时候测试的都是服务。
新增一个HTTP请求(登录测试),填写路径
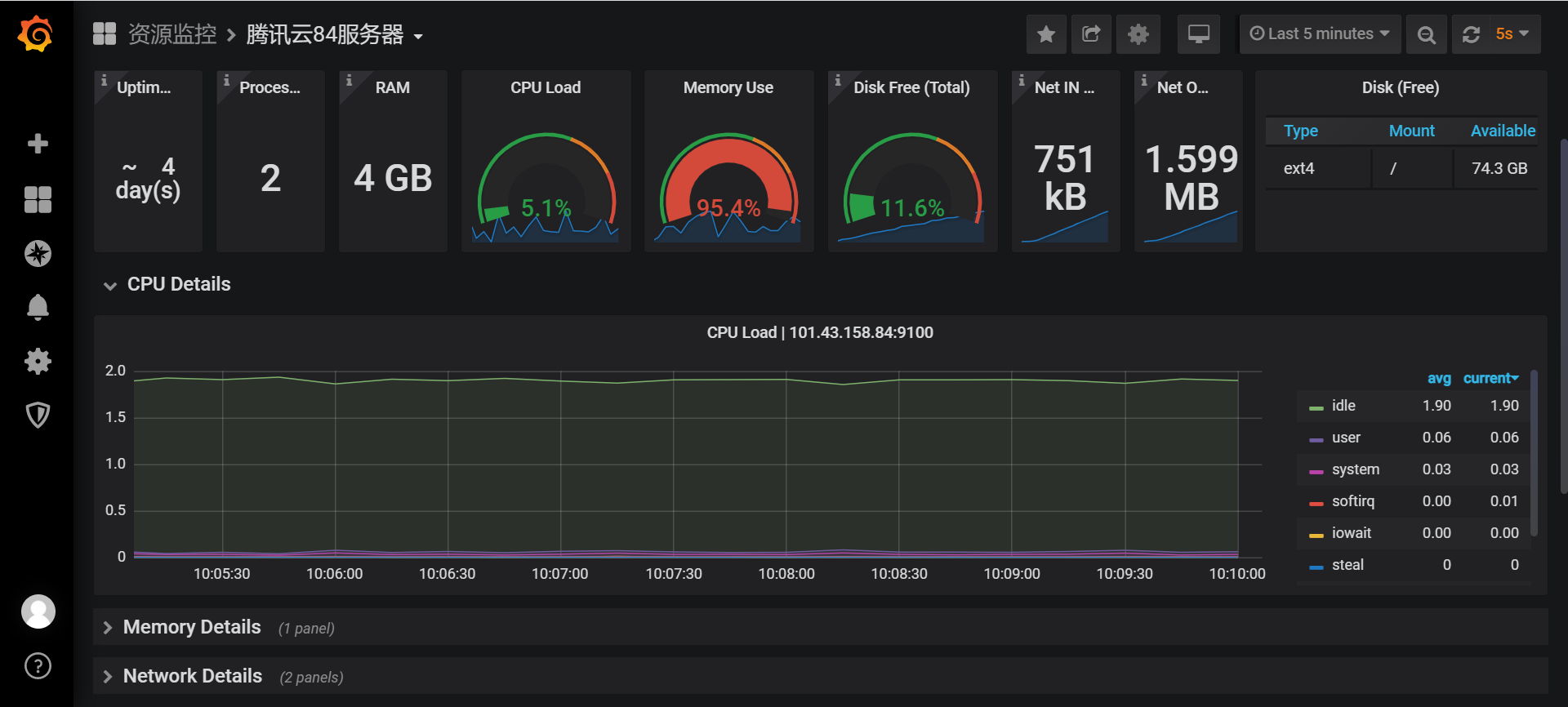
1、它是什么类型的程序?
cpu密集型
cpu密集型:大部份时间用来做计算、逻辑判断等CPU动作
IO密集型:特点是任务执行期间,99%的时间都花在IO的读写操作上
2、C PU最大是多少?
5.2%
3、CPU增长率是多少?
计算方式:最大的数据—之前的/之前的
5.2-1.8/1.8
4、内存最大是多少
5、内存增长率是多少
6、吞吐量是多少?
7、响应时间是多少
8、总的用户数是多少?
9、每秒并发几个用户?
10、什么时候开始收集资源?什么时候截止?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号