实验5
实验任务3
task3.py
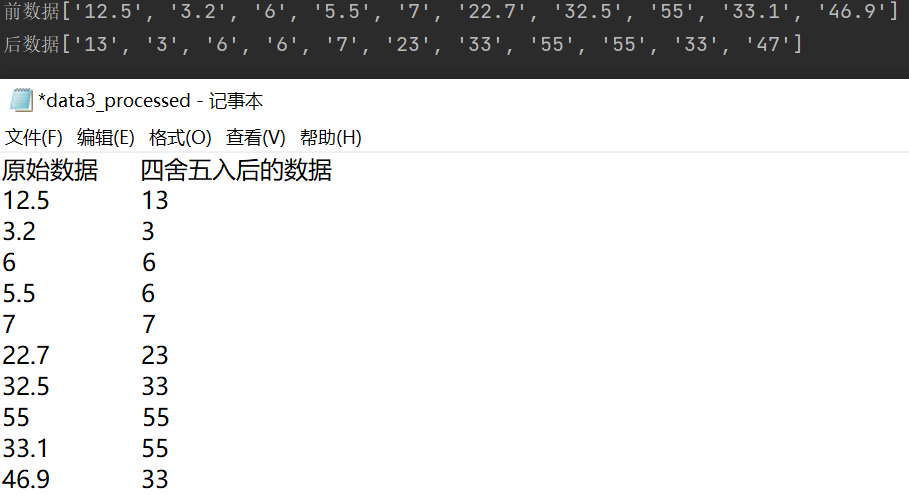
with open('data3.txt','r',encoding='utf-8') as f: l = f.readlines() ly = [] lx = ['四舍五入后的数据'] ls = [] for i in l: s = i.strip('\n') ly.append(s) for j in s: if j == '.': if s[-1]>='5': lx.append(str(int(s[:-2])+1)) if s[-1]<'4': lx.append(s[:-2]) if '.' not in s and s!='原始数据': lx.append(s) for i in range(len(l)): ls.append(ly[i]+''' '''+lx[i]+'\n') with open('data3_processed', 'w', encoding='utf-8') as f: for i in ls: f.write(i) print(f'前数据{ly[1:]}') print(f'后数据{lx[1:]}')
实验任务4
task4.py
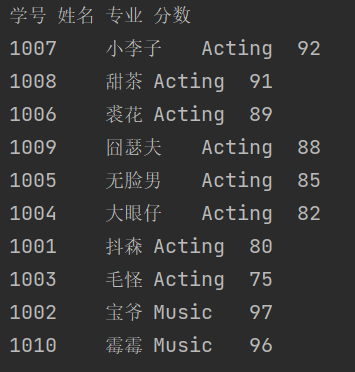
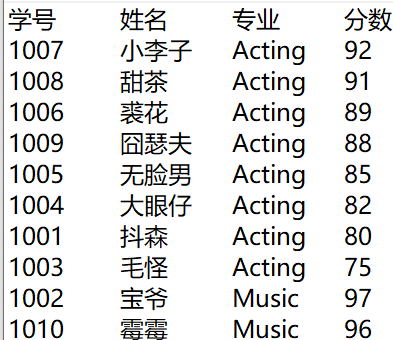
with open('data4.txt','r',encoding='utf-8') as f: data = f.readlines() l = [] for i in data: l.append(i.strip('\n').split('\t')) ls = l.pop(0) for i in l: l.sort(key=lambda i:(i[2],-int(i[-1]))) print('\t'.join(ls)) for i in l: print('\t'.join(i)) with open('data4_processed.txt','w',encoding='utf=8') as f: f.write('\t'.join(ls)) for i in l: f.write('\n') f.write('\t'.join(i))
实验任务5
task5.py
with open('data5.txt','r',encoding='utf_8') as f: l_text = f.readlines() text = ''.join(l_text) words = len(text.split()) space = 0 strings = len(text) lines = len(l_text) for s in text: if s == ' ': space+=1 print(f'行数:{lines}') print(f'单词数:{words}') print(f'空格数:{space}') print(f'字符数:{strings}') with open('data5_with_line.txt','w',encoding='utf-8') as f: n = 1 for i in l_text: f.write(str(n)+' '+i) n+=1



 浙公网安备 33010602011771号
浙公网安备 33010602011771号