寒假作业2/2
| 这个作业属于哪个课程 | 2021春软件工程实践|W班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 作业正文 | 再次阅读《构建之法》并提出问题、编写词频统计器的详细过程 |
| 其他参考文献 | ... |
目录:
1.再次阅读《构建之法》,提出疑问
问题一:大学中的团队是否不太适合MSF模式?
MSF模式中,充分的授权和信任是原则之一。但是,充分的授权和信任在大学的团队编程中有些时候并不会有好的效果,而是很多人都不自觉,写的代码也只是应付了事。书上提出了一个问题:是否团队中需要什么奖励机制来促进,或者完全靠成员的自觉?书上的讨论中提出了一个观点:如果项目没有商业价值,照搬商业软件的做法不合适。在之前的学期中有一个实践作业中,我们团队也遇到类似的问题,在实践中我们每个人有了特定分工,但是效率并没有得到提升,最后也是草率完成项目。我的疑问是大学中的团队是否不太适合MSF模式?
问题二:团队模式与团队开发模式中是否可以找到最合适的组合使得团队开发效率最高?
书中提到了团队模式主要有:主治医师模式、明星模式、社区模式、业余剧团模式、秘密团队模式、特工团队模式、交响乐团模式、爵士乐模式、功能团队模式、官僚模式;团队的开发模式主要有:写了再改模式、瀑布模式及其变形、老板驱动流程、渐进交付流程、敏捷流程;团队模式是团队组织的定性,团队的开发模式是团队进行软件开发使用的方法。我的疑问是团队模式与团队开发模式中是否可以找到最合适的组合使得团队开发效率最高?
问题三:创新在考虑到好的创意的同时还应该注意哪些因素,才更容易被大众所接受?
创新需要好的想法,但是好的想法并不足以让一个创新为所有人接受。以键盘为例,我们现在普遍使用QWERTY 键盘, 那么只有10% 的英语单词能在手指不离开 home Row (ASDF 的那一排) 的情况下敲出来。 但是如果使用 Dvorak 键盘布局, 你可以在home row
打出 60% 的单词(所有的元音都在 home row)!这样会减轻手指和相关肌肉的负担, 减少劳损, 同时加快打字速度。但是Dvorak键盘在如今并没有流行起来。我的疑问是:创新在考虑到好的创意的同时还应该注意哪些因素,才更容易被大众所接受?
问题四:为什么有些时候领域内的专家并没有领域外的创新者那么有创意?
在我们的认知中,创新大部分是该领域的专家才能做到的。但是,事实并非如此,很多创新者表示他们最成功的创新并不是自己最擅长的领域。例如,现在中国甚至全世界,B2B网站做的最好的阿里巴巴的创始人,并不是计算机相关领域的行家;Nokia公司在进入通信
领域之前只是一家做森林木材产品相关的企业;还有很多类似的例子,我的疑问是为什么有些时候领域内的专家并没有领域外的创新者那么有创意?是因为“不识庐山真面目,只缘身在此山中”吗?
问题五:技术创新是否是创新的关键?如果技术创新不是最关键的,那么什么因素是决定创新成败最关键的因素?
书中有提到一种名为“铱星计划”的手机,它凝聚了多种先进的技术,只要有66颗卫星覆盖地球表面,人们就可以随时随地打电话,这听起来是比现在的基站好太多了,但是这项计划不到一年就申请破产保护。这计划利用卫星电话,技术上确实有很大创新,但是最后却失败了。我的疑问是:技术创新是否是创新的关键?如果技术创新不是最关键的,那么什么因素是决定创新成败最关键的因素?
问题六:是否有更好的绩效评估方法,能正确评估团队中每个人真正的价值?
一个团队能不断迸发创作的热情,需要有绩效评估。绩效评估又有各种不同方面的评估,书中有提到按照角色来定位,但是这种方法又有些不足,不是所有人都会服从别人给自己的角色定位,他们往往会将自己放在对自己有利的角色定位上;也有一种说法是比资历,但是软件行业有赢者通吃的规律,并不是资历越老越有话语权;还有比效率、背靠背评比等方法。但是这些方法都不是最好的。还有二维绩效评估,这方法看似合理。我的疑问是:是否有更好的绩效评估方法,能正确评估团队中每个人真正的价值?
2.软件工程发展过程的冷知识和趣事
我们都知道,程序员在编程时必须定义程序用到的变量,以及这些变量所需的计算机内存,这些内存用比特位定义。一个16位的变量可以代表-32.768到32.767中间的值。而一个64位的变量可以代表−9.223.372.036.854.775.808到9.223.372.036.854.775.807中间的值。
1996年6月4日,阿丽亚娜5型运载火箭的首次发射点火后,火箭开始偏离路线,最终被逼引爆自毁,整个过程只有短短30秒。阿丽亚娜5型运载火箭基于前一代4型火箭开发。在4型火箭系统中,对一个水平速率的测量值使用了16位的变量及内存,因为在4型火箭系统中反复验证过,这一值不会超过16位的变量,而5型火箭的开发人员简单复制了这部分程序,而没有对新火箭进行数值的验证,结果发生了致命的数值溢出。发射后这个64位带小数点的变量被转换成16位不带小数点的变量,引发了一系列的错误,从而影响了火箭上所有的计算机和硬件,瘫痪了整个系统,因而不得不选择自毁,4亿美金变成一个巨大的烟花。
这一则故事告诉我们在计算机中,数值溢出的错误是非常严重的,在编程的时候要尽量给变量设置相对大的变量类型。
3.WordCount开发过程
1.Github项目地址
2.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 1200 | 1080 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 180 | 120 |
| • Design Spec | • 生成设计文档 | 60 | 60 |
| • Design Review | • 设计复审 | 60 | 30 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| • Design | • 具体设计 | 60 | 90 |
| • Coding | • 具体编码 | 300 | 320 |
| • Code Review | • 代码复审 | 120 | 140 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 140 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 90 | 60 |
| • Size Measurement | • 计算工作量 | 90 | 60 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 90 | 30 |
| 合计 | 1200 | 1080 |
3.解题思路
看到题目的要求,我就想将这两个打开文件输入文件和打开输出文件编写为两个函数。然后统计字符数、统计单词数、统计空行数、输出频数前十的单词数分别作为一个函数,供主函数调用,这样划分每个功能块比较独立。
划分上述功能块之后,主函数就比较简单,只要调用统计字符、统计单词数、统计行数、输出频数前十的函数。
4.代码规范
5.各个模块的设计与实现
此次作业的代码中含有两个类:WordCount 和Lib
Lib类中含有以下函数:
public class Lib {
public static BufferedReader openInputFile(String fileName) {
//打开输入文件
}
public static BufferedWriter openOutputFile(String fileName) {
//打开输出文件
}
public static void characterCount(String inputFile,BufferedWriter bufferedWriter){
//计算字符数
}
public static void lineCount(String inputFile,BufferedWriter bufferedWriter){
//计算行数
}
public static String [] wordCount(String inputFile,BufferedWriter bufferedWriter){
//计算单词数
}
public static void printWord(BufferedWriter bufferedWriter,String [] resultStr){
//输出词频前十的单词数
}
}
WordCount类中含有mian函数:
public class WordCount {
public static void main(String args[]){
String [] resultStr = null;
BufferedWriter bufferedWriter = Lib.openOutputFile(args[1]);
//调用各个模块对应的函数
try {
bufferedWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
文件读取和输出,我在查找资料以后决定用BufferedReader和BufferedWriter。这样做在文件较大的时候可以提高读取和存储效率。这两个函数较为简单,核心代码如下:
打开输入文件
BufferedReader bufferedReader = null;
bufferedReader = new BufferedReader(new FileReader(fileName));
打开输出文件
BufferedWriter bufferedWriter = null;
bufferedWriter = new BufferedWriter(new FileWriter(fileName));
统计字符数的的函数,我上网查询了如何从文件读取字符,在阅读了一些博客之后,用BufferedReader的read函数逐个读取字符,用count计数累加。核心代码如下:
while((temp = bufferedReader.read()) != -1){
count ++;
}
bufferedWriter.write("characters:"+count+'\n');
统计单词数的函数,我想到了正则表达式,可以匹配一定格式的字符串,那么问题就在读取文件中的字符并按照非字母数字为分隔符将文件中的字符串拆分开来,再拼接成新的字符串,再将所有字母转为小写,最后用正则表达式进行匹配,用totalcount来统计单词数。这个函数还返回了一个已经处理过的字符串数组,供输出单词频数使用,核心代码如下:
while((originStr = bufferedReader.readLine())!=null){
tempBuffer.append(originStr+" ");
}
bufferedReader.close();
tempStr = tempBuffer.toString().toLowerCase();
resultStr = tempStr.split("[^a-zA-Z0-9]+");
for (String s : resultStr) {
if (s.matches("[a-z]{4}[a-z0-9]*")) {
totalCount++;
}
}
bufferedWriter.write("Words:"+totalCount+'\n');
统计行数的函数,我用BufferedReader中的readline函数读取一行,再用正则表达式进行筛选,如果是空行,则统计行数的count不加一。核心代码如下:
while ((temp = bufferedReader.readLine()) != null) {
//如果读出来的行不是空行(包含只含有空格的行),行数加1
if(!temp.matches("[\\s]*")) count++;
}
bufferedReader.close();
bufferedWriter.write("lines:"+count+'\n');
输出频数前十的函数,首先我想到统计单词数的函数已经遍历过文件,并且找出来所有单词,那么可以让统计单词数的函数返回一个已经处理过的字符串,传给这个函数,然后统计该字符串中的单词,存入Map中。再将Map中的单词进行降序排列,如果频数一样按照字典序排列。核心代码如下:
for (String s : resultStr) {
if (s.matches("[a-z]{4}[a-z0-9]*")) {
if (resultMap.containsKey(s)) {
//containsKey()方法用于检查特定键是否在TreeMap中映射
count = resultMap.get(s);
resultMap.put(s, count + 1);
} else {
resultMap.put(s, 1);
}
}
}
//通过比较器实现排序
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(resultMap.entrySet());
//按降序排序
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
public int compare(Map.Entry<String, Integer> first, Map.Entry<String, Integer> second) {
if(second.getValue().compareTo(first.getValue()) == 0) {
//如果单词频数相同,返回字典序较大的单词
return second.getKey().compareTo(first.getKey());
}
//返回两个单词出现次数较多的那个单词的出现次数
return second.getValue().compareTo(first.getValue());
}
});
6.性能改进
1.在文件读取方面,由于提前查询 资料,了解到BufferedReader和BufferdWriter的读存效率更高,所以在读写方面在编写程序前已经做到了性能改进。
2.统计字符数和输出词频高的单词两个函数有一部分重复工作,因此在统计完单词数以后返回从文件读出并且划分成一个个单词的字符串数组。供输出单词频数前十的函数使用。
7.各种测试
7.1 单元测试
编写了一个LibTest类来测试,以下为部分测试代码:
@Test
public void characterCountTest(){
BufferedWriter bufferedWriter = Lib.openOutputFile("src/output1.txt");
int count = 7;
Assert.assertEquals(count,Lib.characterCount("src/input1.txt",bufferedWriter));
}
@Test
public void lineCountTest(){
BufferedWriter bufferedWriter = Lib.openOutputFile("src/output1.txt");
int count = 0;
Assert.assertEquals(count,Lib.lineCount("src/input1.txt",bufferedWriter));
}
characterCountTest()是关于统计字符的函数的测试,测试思路是先统计input1.txt文件总字符数,将count设置为该值,然后判断count是否与characterCount函数返回值相等,相等则正确。
lineCountTest()是关于统计行数的函数的测试,测试思路是先统计input1.txt文件的总有效行数,将count设置为该值,然后判断count是否与lineCount函数的返回值相等,相等则正确。
测试覆盖率截图:

优化覆盖率的方法:尽量设置合理的测试规则,多一些测试数据。
7.2 几个测试样例
(1)只包含6个回车键(Windows下回车视为"\r\n"两个字符)

(2)先输出6个'\n'到文件中,再用程序处理文件
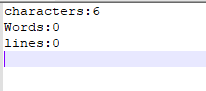
(3)测试例子中包含多个重复单词,这里的换行为"\r\n"
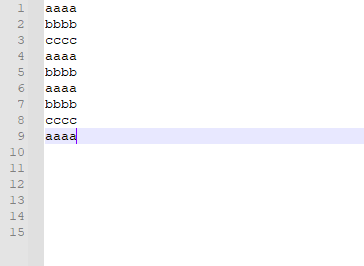
结果如下
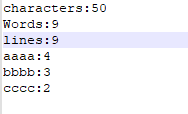
(4)一行中有多个单词,用一些非字母数字符号隔开

结果如下

(5)大量的字符数据
通过代码产生数据
结果如下

程序运行时间

以上为部分测试样例。在测试过程中,我发现我的程序处理一些量少的、较为特殊的样例的时候,效率还行,但是如果文件较大,相应的运行时间就偏长。
8.异常处理
本次作业中,没有编写独立的异常处理类,使用java中已有的IOException。在打开文件以及关闭文件出错的时候,程序会报错。
8.心路历程以及收获
做这个作业之前,我没有正确预估该作业需要花的时间,也没有先把作业中要求的程序划分模块,再一点点完成,最后完成得有点匆忙。我从中得到教训,做一个项目要将大项目拆分为多个小模块,再一步步完成每个项目,这样可以化难为易,也可以减轻作业负担。
在本次项目中,我复习了java语言的基础,对于java得文件读取和存储有了更深的了解。我还学习到了如何用github来管理项目。github在管理项目方面方便快捷,可以和他人共享开发的项目,也方便和他人合作编程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号