


《机器学习》第一次作业——第一至三章学习记录和心得
第一章 模式识别基本概念
模式识别应用领域:计算机视觉领域(交通标志识别、动作识别、语音识别),医学领域(心跳异位搏动识别),网络领域(应用程序识别),金融领域(银行信贷识别、股票价格预测),机器人领域(机械手目标抓取点位姿),无人车领域(无人驾驶)。
模式识别:根据已有知识的表达,针对待识别模式,判别决策其所属的类别或者预测其对应的回归值,本质上是一种推理过程;从数学角度来看,它可以被看做一种函数映射。
模式识别可以划分为“分类”和“回归”两种形式:
分类:输出量是离散的类别表达,即输出待识别模式所属的类别,分为二类或多类。
回归:输出量是连续的信号表达,输出量是单个或多个维度。
回归是分类的基础,离散的类别值是由回归值做判定决策得到的。
输入空间:原始输入数据x所在的空间,其维度构成输入空间维度。
输出空间:输出的类别/回归值y所在的空间,类别的个数构成回归值的维度。
模型:用于分类,广义上的模型包括特征提取、回归器、判别函数,而狭义上的模型没有判别函数。
分类器由回归器和判别函数组成。

判别函数:使用一些特定的非线性函数来实现,通常记为函数g,通常判别函数固定,所以不把它归于模型的一部分。
sign函数用来进行二类分类,max函数用来进行多类分类。
特征:可以用于区分不同类别模式的、可测量的量,输入数据也可以看作原始特征表达。特征具有辨别能力,提升不同类别之间的识别性能。
鲁棒性:针对不同的观测条件,仍能够有效表达类别之间的差异性。
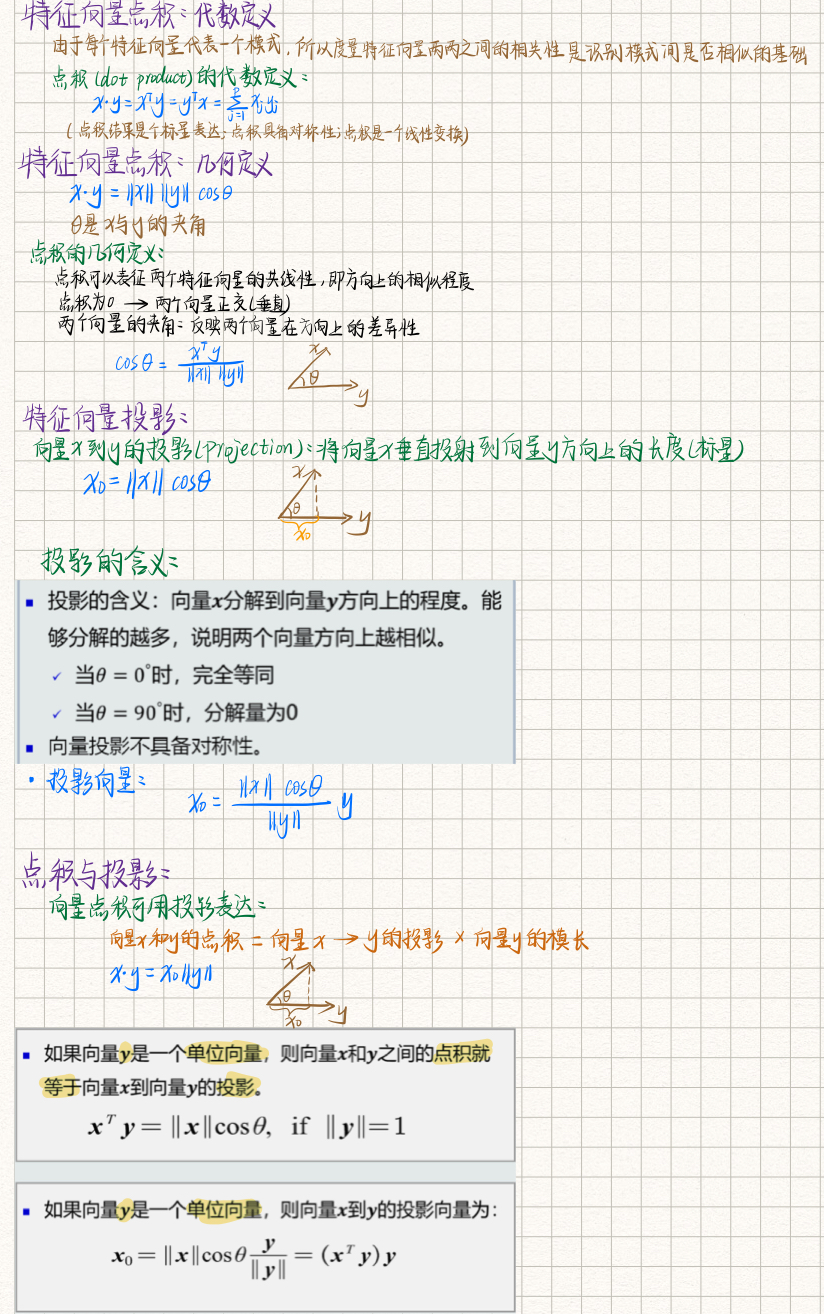
特征向量:多个特征构成的列向量,可以表达为模长x方向。

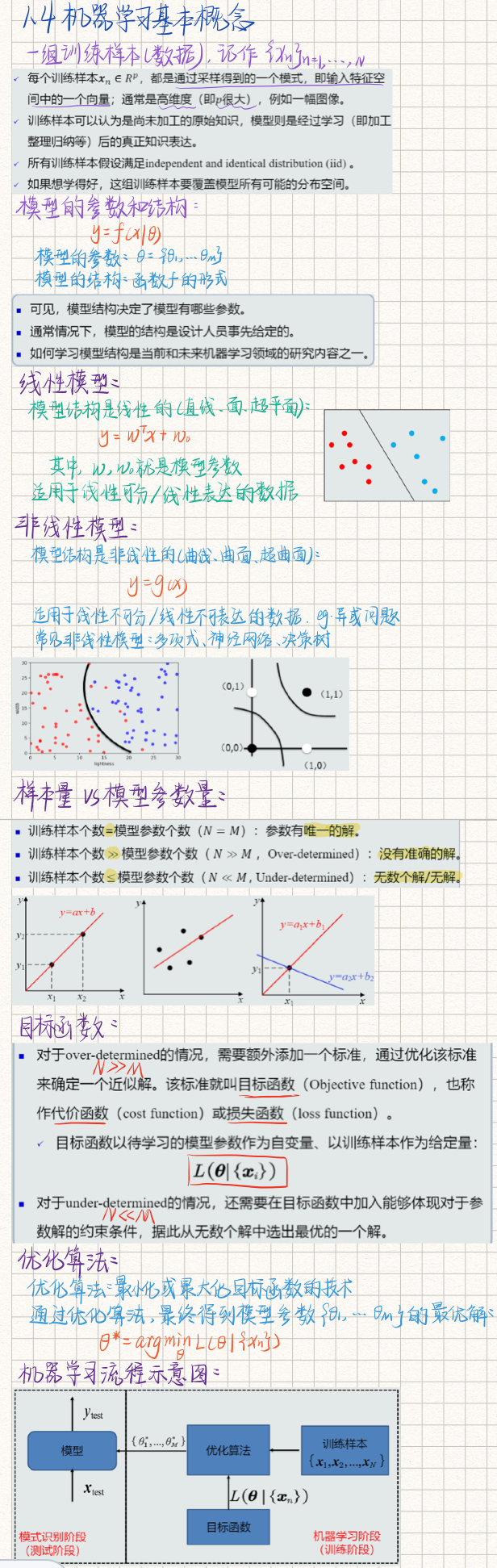
机器学习基于学习方式分类
(1) 监督学习(有导师学习):输入数据中有导师信号,以概率函数、代数函数或人工神经网络为基函数模型,采用迭代计算方法,学习结果为函数。
(2) 无监督学习(无导师学习):输入数据中无导师信号,采用聚类方法,学习结果为类别。典型的无导师学习有发现学习、聚类、竞争学习等。
(3) 强化学习(增强学习):以环境反惯(奖/惩信号)作为输入,以统计和动态规划技术为指导的一种学习方法。

评估方法:
(1)留出法
直接将数据集划分为两个互斥的集合,2/3-4/5。
划分原则:划分过程尽可能保持数据分布的一致性
方法缺陷:训练集过大,更接近整个数据集,但是由于测试集较小,导致评估结果缺乏稳定性;测试集大了,偏离整个数据集,与根据数据集训练出的模型差距较大,缺乏保真性。
(2)交叉验证法
将数据集划分为k个大小相似的互斥子集,每个子集轮流做测试集,其余做训练集,最终返回这k个训练结果的均值。
优点:更稳定,更具准确定;
缺单:时间复杂的较大
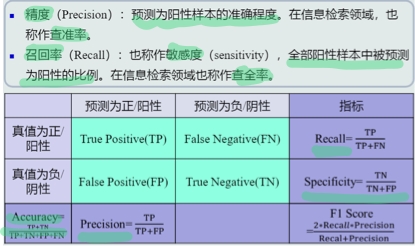
性能指标
精度、召回率


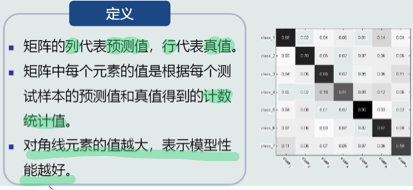
混淆矩阵
PR曲线
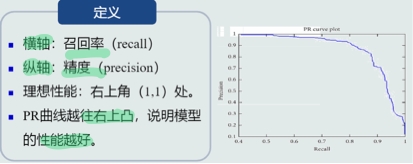
ROC曲线

PR曲线和ROC曲线比较
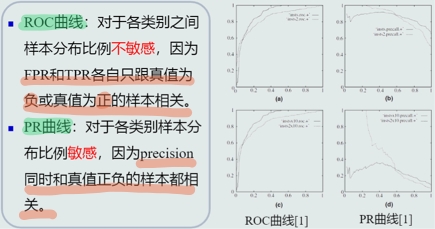
AUC

课上练习题

第二章 基于距离的分类器
MED分类器:把测试样本到每个类之间的距离作为决策模型,将测试样本判定为与其最近的类。
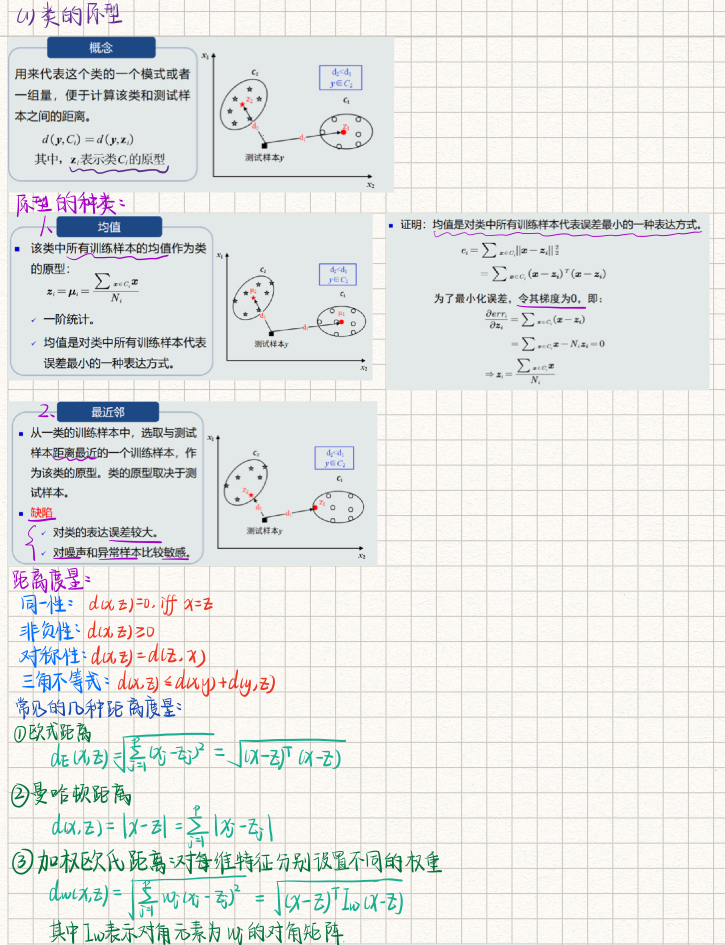
MED分类器

特征正交白化的目的


特征解耦

白化
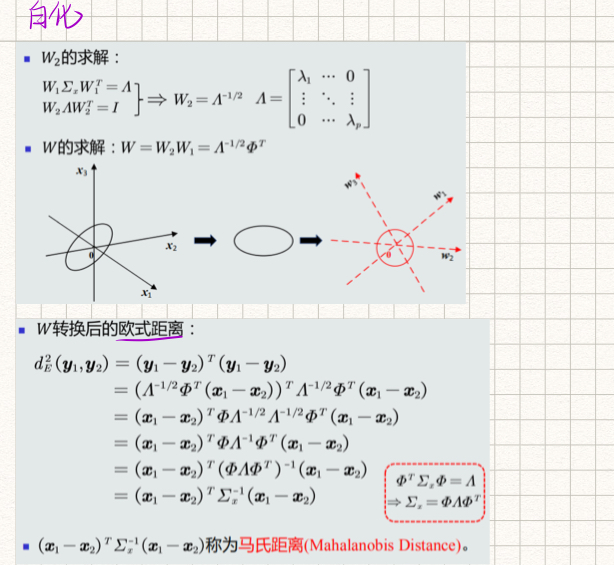
MICD分类器

第三章 贝叶斯决策与学习
3.1贝叶斯决策和MAP分类器
后验概率 p(Ci|x) 表达给定模式 x 属于类 Ci 的概率。
模式 x 属于类 Ci 的后验概率计算公式为:

MAP分类器:将测试样本决策分类给后验概率最大的那个类。判别公式:
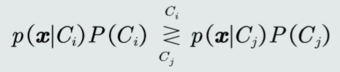
对于二分类问题,MAP分类器的决策边界:
单维空间:通常有两条决策边界。
高维空间:复杂的非线性边界。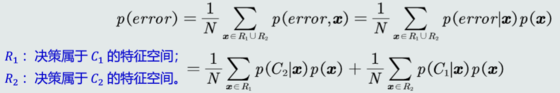
3.2决策风险和贝叶斯分类器
决策风险的概念:不同的决策错误会产生程度不同的风险。


贝叶斯分类器:
选择决策风险最小的类。
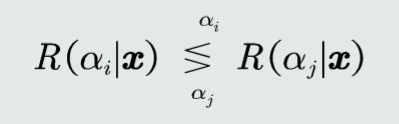
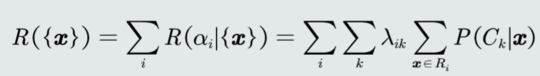

3.4最大似然估计
定义:
-
待学习的概率密度函数记为
p(x | θ),θ 是待学习的参数。 -
给定的 N 个训练样本都是从
p(x | θ)采样得到的,且满足iid条件,则所有样本的联合概率密度(似然函数)为: -
![]()
-
因此,学习参数 θ 的目标函数可以设计为:使该似然函数最大。
![]()

3.6贝叶斯估计
贝叶斯估计:给定参数 θ 分布的先验概率以及训练样本,估计参数 θ 分布的后验概率。
θ 的后验概率:

3.8KNN估计
给定 N 个训练样本,在特征空间内估计每个任意取值 x 的概率密度,即估计以 x 为中心,在极小的区域 R = (x, x+δx) 内的概率密度 p(x)

其中 k 为落入区域 R 的样本个数,V 为区域 R 的体积。
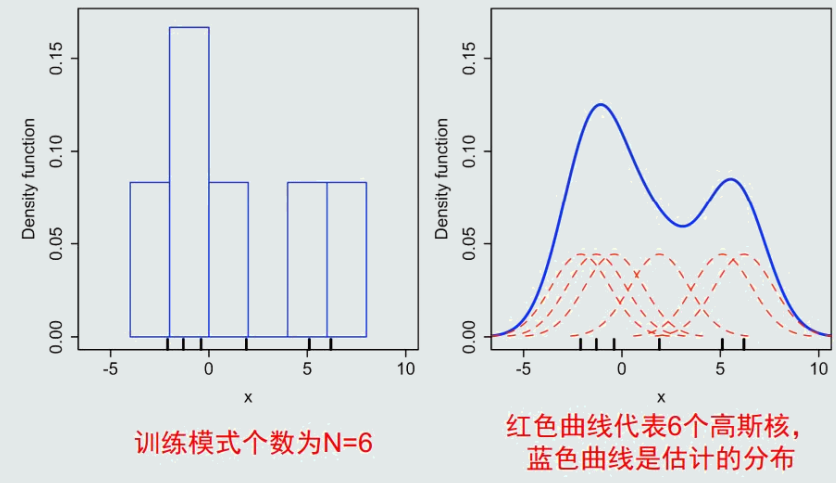
3.9直方图与核密度估计
直方图也是基于无参数概率估计的基本原理:p ≈ k/(NV)

给定任意模式,先判断它属于哪个区域,p(x) = ki/(NV), if x ∈ Ri
优点:
- 固定区域 R:减少由于噪声污染造成的估计偏差。
- 不需要存储训练样本。
缺点:
- 固定区域 R 的位置:如果模式 x 落在相邻格子的交界区域,意味着当前格子不是以模式 x 为中心,导致统计和概率估计不准确
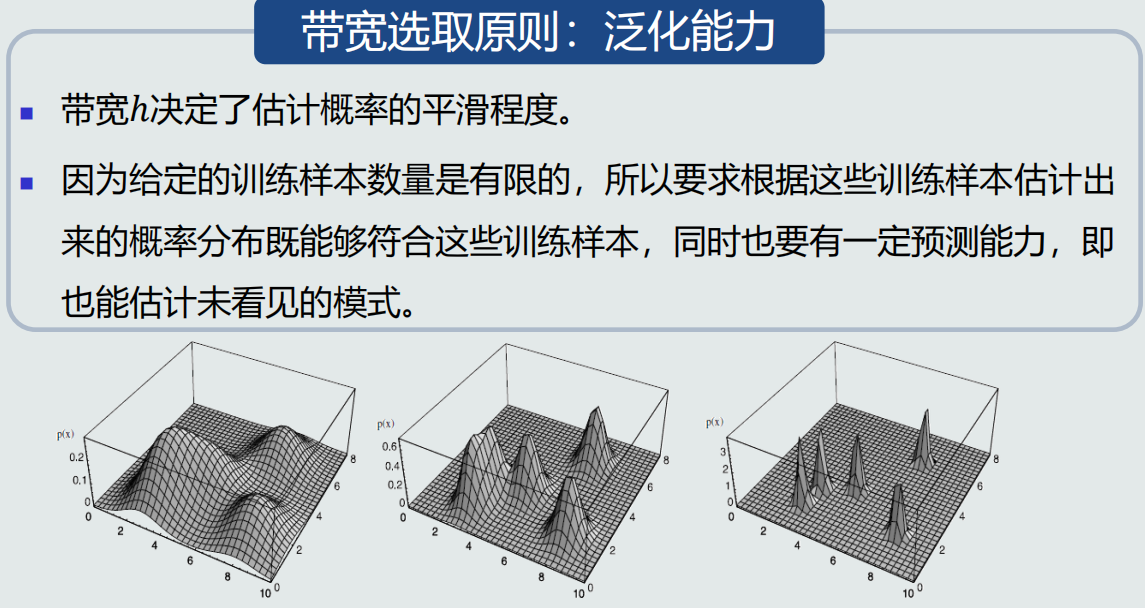
- 固定区域 R 的大小:缺乏概率估计的自适应能力,导致过于尖锐或平滑

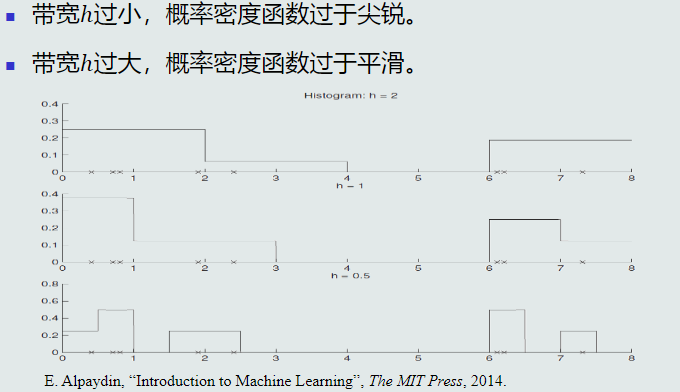
核密度估计

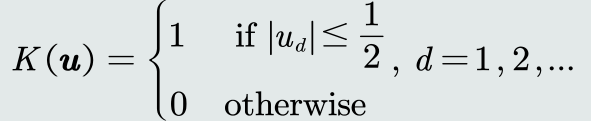



优点:
- 以待估计模式𝒙为中心、自适应确定区域𝑅的位置(类似KNN)。
- 使用所有训练样本,而不是基于第 𝑘 个近邻点来估计概率密度,从而克服KNN估计存在的噪声影响。
- 如果核函数是连续,则估计的概率密度函数也是连续的。
缺点:
- 与直方图估计相比,核密度估计不提前根据训练样本估计每个格子的统计值,所以它必须要存储所有训练样本。
直方图与核密度估计
学习总结与心得
各个章节不能单纯分开学习,要把章节与章节联系起来,不然在面对实际问题时就无法构建一个思路完整的求解方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号