第一次作业
作业①
1)、UniversitiesRanking实验
import urllib
import requests
from bs4 import BeautifulSoup
url="http://www.shanghairanking.cn/rankings/bcur/2020"
req=urllib.request.Request(url)
data=urllib.request.urlopen(req)
soup=BeautifulSoup(data, "lxml")
tags=soup.find_all("tr") # 爬取"tr"标签内的所有数据
str=[]
for tag in tags:
str.append(tag.text)
s=str[1:] # 去掉无用的str[0]
for i in s:
i = i.split()
print(i[0]+'\t\t'+i[1]+'\t\t'+i[2]+'\t\t'+i[3]+'\t\t'+i[4])# 实验要求为前五个文本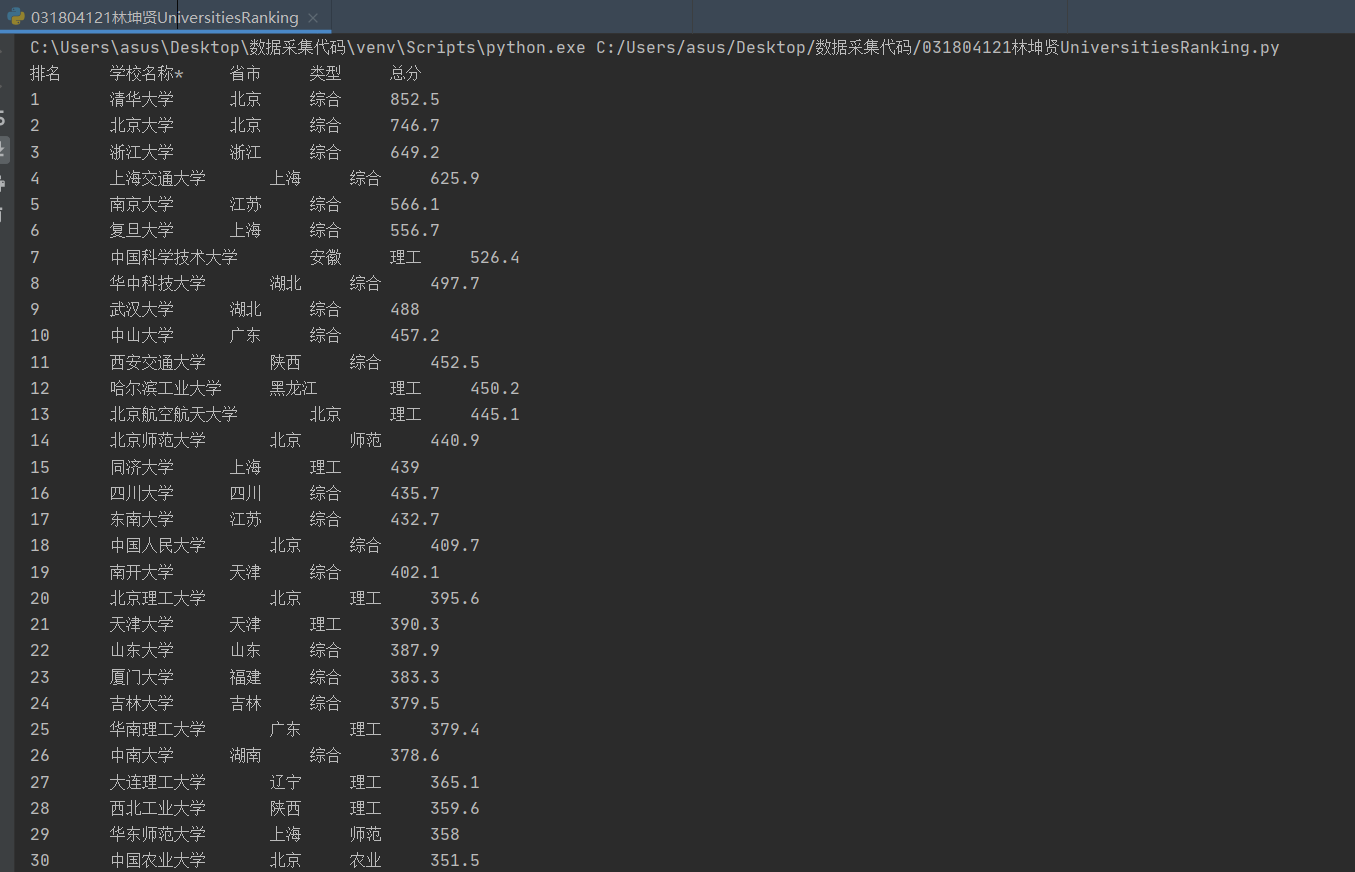
2)、心得体会
通过查看网站源代码寻找所要数据,从而确定寻找的标签是"tr",在获取文本后还要去掉一些与目标数据在相同位置但无用的文本,最后输出清洗过的文本即完成本次实验要求。
作业②
1)、GoodsPrices实验
import requests
import re
# 仿浏览器访问淘宝网址防止反爬
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
keyword = "书包" # 搜索关键词
url = 'https://s.taobao.com/search?q=' + keyword # 搜索接口
# 获得html文本
r = requests.get(url, timeout=30, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
html = r.text
# 存储数据
arr = []
# 正则
view_price = re.findall(r'"view_price":"[(\d.)]*"', html)
raw_title = re.findall(r'"raw_title":".*?"', html)
for j in range(len(view_price)):
price = eval(view_price[j].split(':')[1])
name = eval(raw_title[j].split(':')[1])
arr.append([price, name])
print("{:4}\t{:8}".format("价格", "商品名称"))
for a in arr:
print(a[0] + "\t" + a[1])
2)、心得体会
刚开始爬取没用header,直接就被反爬了...从而使我深刻意识到header对于爬取一些网站的重要性。打开网页源代码,我们需要的价格和商品名称分别在"view_price"和"raw_title"中,所以对这两个位置进行爬取。正则出来的数据还需要处理,只取':'后的文本(用split方法将数据从':'处切片,取后部分),分别存入arr数组内,最后输出arr即完成本次实验要求。
作业③
1)、JPGFileDownload实验
import re
import urllib
import requests
from bs4 import BeautifulSoup
import urllib.request
import os
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
def catch(url):
html = requests.get(url=url, headers=headers).text
soup = BeautifulSoup(html, "lxml")
tags1 = soup.find_all("img", attrs={"src": re.compile('jpg$')}) # 爬取以jpg结尾的图片
tags2 = re.findall("/attach.*?jpg", html)
tags3 = re.findall("/attach.*?JPG", html)
return tags1, tags2, tags3
def get_jpg(tags1, tags2, tags3):
jpg = []
name = []
for image in tags1:
# 判断图片链接是否为相对路径
if image["src"][0] == "/":
image["src"] = "http://xcb.fzu.edu.cn" + image["src"]
jpg.append(image["src"])
name.append(image["src"].split('/')[-1])
for image in tags2:
img = "http://xcb.fzu.edu.cn" + image
jpg.append(img)
name.append(img.split('/')[-1])
for image in tags3:
img = "http://xcb.fzu.edu.cn" + image
jpg.append(img)
name.append(img.split('/')[-1])
return jpg, name
# 存储在当前文件夹的path文件夹中
def save(path, jpg, name):
if not os.path.exists(path):
os.mkdir('picture') # 在当前文件夹创建文件夹
for i in range(len(jpg)):
urllib.request.urlretrieve(jpg[i], path + '/' + name[i]
try:
url = "http://xcb.fzu.edu.cn/" # 福大宣传部网站
save_path = r"picture" # 存储文件夹名
tags1, tags2, tags3 = catch(url)
jpg, name = get_jpg(tags1, tags2, tags3)
save(save_path, jpg, name)
except Exception as err:
print(err)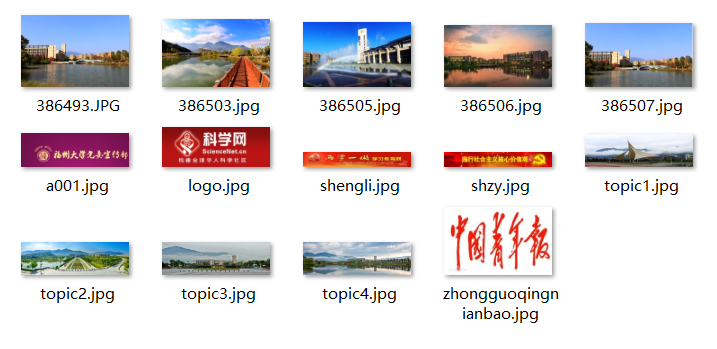
2)、心得体会
这次需要爬取的JPG文件中,分为三部分。第一部分通过正常爬取以jpg结尾的图片链接就行;第二部分需要判断图片链接是否为相对路径,如果是相对路径的话,还得在该图片链接前补充"http://xcb.fzu.edu.cn"才可使用;第三部分是网页中那五张校园风光的图片。因为它们跟其他图片的格式不一样,有的人在爬取的时候会漏掉它们。其中还有一张图片有个"小坑",是以"JPG"结尾而不是像另外四张一样是以"jpg"结尾。所以这部分的五张图片我用了两次findall爬取。我认为这次实验的难点就是这三部分图片的爬取,另外在图片名的存储以及存储位置这两个地方也需要花点心思。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号