

Java基础知识(一)
一、Java的发展史
1、简介
Java为Java编程语言和其对应三大平台的总称,Java编程语言是sun公司开发的一门面向对象的网络编程语言,以前叫Oak编程语言。
2、三大平台
(1)J2SE
JavaSE为Java平台的标准版,主要用于开发桌面程序
(2)J2EE
JavaEE为Java平台的企业版,主要用于开发企业项目,一般为web项目开发
(3)J2ME
JavaME为Java平台的微型版,主要用于开发移动应用
3、版本区分
(1)JDK1.0-JDK1.4
(2)Java5
a.引入泛型;;b.自动装箱/拆箱;c.静态引入...
(3)Java6
a.支持脚本语言;b.引入JDBC4.0API;c.引入Java compiler API...
(4)Java7
a.支持switch语句块中对字符串的判断;b.支持一个try语句块可以捕获多个异常;c.支持动态语言...
(5)Java8
a.支持lambda表达式;b.增强了日期和时间API的功能;c.对垃圾回收作了改进...
(6)目前最新版本为2021年3月份发布的Java16,但是由于各种兼容性和稳定性问题,目前大部分企业基本上还是在使用Java8.
额外补充:调试和运行工具
(1)JRE:Java Running Environment,Java程序运行所需环境
(2)JDK:Java Development Kit,Java开发工具,其中包含了JRE,另外还有像Javac等等各种各样的调试开发工具
(3)Javac:java编译器,将.java代码文件编译成.class字节码文件
(4)Java:运行java程序
(5)Jar:打包工具
(6)Jconsole:进行系统监控和调试工具
二、Java的作用跟应用场景
1、作用特性
(1) 简单
(2)面向对象
(3)与平台无关
(4)安全
2、应用场景
(1)安卓APP
(2)服务器
(3)网站
(4)大数据
(5)嵌入式
三、面向对象特性
1.封装性
指所有具有共性的对象抽象为类,他们的特点和操作都分别封装到类的属性和方法里。
2.继承性
指子类可通过继承父类,获得父类的属性和方法。
3.多态性
分别为编译时的多态(方法重载:同方法名不同参数)和运行时的多态(方法重写:同方法声明不同方法实现)。
额外补充:权限优先级
public<default<protected<private
(1)public:所有类均能访问
(2)default:只有同包内的类以及包外的子类能访问
(3)protected:只有同包内的类能访问
(4)private:只能类内访问
四、基本数据类型
1.int:4B,范围为(-2的31次方~2的31次方-1),对应封装类为Integer
2.short:2B,对应封装类为Short
3.long:8B,对应封装类为Long
4.float:4B,数值后需带上“f”,对应封装类为Float
5.double:8B,数值后需带上“d”,对应封装类为Double
6.boolean:1B,对应封装类为Boolean
7.byte:1B,对应封装类为Byte
8.char:2B,字符需用单引号引用‘’,Java对字符采用了unicode,对应封装类为Character
五、异常
1.异常分类
Throwable父类分为
(1)Error子类
为程序无法处理的错误,例JVM运行时发生的错误,包括栈溢出和内存泄漏错误。
(2)Exception子类
a.运行时异常:为RuntimeException极其子类,例空指针异常、数组下标越界异常、类转换异常等等
b.非运行时异常(编译时异常):为RuntimeException之外的类,例IOException、SQLException等等
2.异常处理
(1)throws:当方法无法处理异常时,在方法定义处声明抛出异常给方法调用者处理
(2)throw:运用在方法体里,抛出异常语句后面的语句将不被执行,此异常会被对应catch捕抓到
(3)try-catch-finally:先try,后catch,finally总是被执行(一般用于资源的释放等等)
六、内部类
1.分类
(1)成员内部类:写在类内,作为类的一个成员,内部类可以无条件访问对应外部类任何权限的属性和方法
(2)局部内部类:写在方法内,作为方法的一个局部变量,没有权限声明
(3)匿名内部类:不需对象声明,一般用于接口回调,比如事件监听等
(4)静态内部类:写在类内,只不过多了static声明,不依赖于外部类
2.作用
(1)便于将具有相似逻辑关系的类写在一起,同时也可以很好对外界进行隐藏
(2)另一种层面上的多继承
(3)便于写事件驱动程序
七、注解
1.自定义注解
@Target(ElementType.FIELD) //指定注解的使用对象,使用在类上、方法上还是属性上等等
@Retention(RetentionPolicy.RUNTIME) //指定注解的生命周期
@Documented //表示该注解可以被文档化
public @interface FruitName { //注解声明和定义
String value() default ""; //注解的成员变量
}
2.常用注解
@Override 重写, 标识覆盖它的父类的方法
@Deprecated 已过期,表示方法是不被建议使用的
@Suppvisewarnings 压制警告,抑制警告
@Inherited 允许子类继承父类中的注解
八、序列化/反序列化和克隆
1.序列化/反序列化
(1)定义
序列化:将对象转化为字节流的过程;反序列化:将字节流转化为对象的过程
(2)作用
a.用于网络传输;b.用于存储
(3)实现
a.方法一:A类实现Serializable接口->通过ObjectOutputStream实现序列化方法->通过ObjectInputStream实现反序列化方法
b.方法二:A类实现Externalizable接口(继承于Serializable接口)->声明一个无参的public构造方法->重写writeExternal和readExternal方法
(4)其它
a.serialVersionID:序列化版本号,用于版本控制,序列化和反序列化需要一致的serialVersionID才可以;有两种定义方式,一种为赋值1L,另一种就是通过类名、接口名、方法名等等生成一个64位的哈希段
b.静态变量不能被实例化
c.一个变量被Transient声明,可以防止该变量被序列化到文件中
2.克隆
(1)定义
指的是把一个对象的内容复制到另一个对象中
(2)作用
实现内容的拷贝,常用于一些需临时对象存储的场景中
(3)分类
a.浅拷贝:只是涉及到一些非引用类型的属性赋值
b.深拷贝:包含了引用类型的赋值,即涉及了多层的拷贝
(4)实现
a.A类实现Cloneable接口->重写clone方法->调用clone方法返回拷贝对象
b.A类实现Serializable接口->自定义克隆方法deepClone(利用ByteArrayOutputStream和ObjectOutputStream把对象写到流中,然后利用ByteArrayInputStream和ObjectInputStream读取对象,最后将该对象返回)->调用自定义克隆方法返回拷贝对象即可
九、反射
1.定义
所谓反射,为通过Java的类加载原理获取到对应类的所有信息以及操作对应对象的属性和方法。封装保证了Java的安全性,反射让Java拥有了动态性即更加灵活,两者互不矛盾
2.作用/应用场景
a.JDBC连接数据库
b.Spring框架里通过xml解析为Bean
...
3.使用
(1)类对象的获取
a.Class a=Class.forName("类的全限定类名")
b.类.class属性
c.对象.getClass()
(2)常用方法
getName():获得类的完整名字。
getFields():获得类的public类型的属性。
getDeclaredFields():获得类的所有属性。包括private 声明的和继承类
getMethods():获得类的public类型的方法。
getDeclaredMethods():获得类的所有方法。包括private 声明的和继承类
getMethod(String name, Class[] parameterTypes):获得类的特定方法,name参数指定方法的名字,parameterTypes 参数指定方法的参数类型。
getConstructors():获得类的public类型的构造方法。
getConstructor(Class[] parameterTypes):获得类的特定构造方法,parameterTypes 参数指定构造方法的参数类型。
newInstance():通过类的构造方法创建这个类的一个对象。
属性Filed实例.set(类对象示例,参数):设置对象的属性指为指定参数
方法Method实例.invoke(类对象实例):调用对象的方法
十、泛型
1.定义
所谓泛型,即“类型参数化”,也就是定义的数据类型在编译时逻辑上是不确定的,但是在运行时是确定的也就是需要指定
2.作用
使得编码可以更加灵活,在运行中可以处理更多的可能性
3.使用
(1)分类
a.泛型类:在类名右边写上<泛型声明标识符T或E或K或V>,例class Student<T>{}
b.泛型接口:在接口名右边写上<泛型声明标识符T或E或K或V>,例interface StudentMapper<T>{}
c.泛型方法:在权限声明和返回值中间写上<泛型声明标识符T或E或K或V>,例public <T> String getName(T a)
(2)其它
a."?"为泛型通配符,它是一个实参!!!
b.不能创建一个确切的泛型数组
c.泛型上下界:<T extends 父类>,此处的T数据类型必须是指定“父类”的子类
十一、集合
1.定义
Java用于实现存储的工具或数据结构
2.分类
(1)Collection接口
A.List接口(实现类如下)
a1.LinkedList:链表;非同步非线性安全;增删查改快,查询慢
a2.ArrayList:数组;非同步非线性安全;查询快,增删查改慢
a3.Vector:矢量;同步线性安全;
a3-1.Stack:Vector的实现类
B.Set接口(实现类如下)
b1.HashSet:不可重复,且原顺序不变
b1-1.LinkedHashSet:不可重复,通过链表维护插入顺序
b2.TreeSet:顶层结构为二叉树,不可重复,且可排序
(2)Map接口
常见实现类如下:
A.Hashtable:键值对存储,线程安全
B.HashMap:键值对存储,底层结构为数组和链表(红黑树),线程非安全
b1.LinkedHashMap:顶层实现结构为双向链表和哈希表
b2.ConcurrentHashMap:线程安全
b3.WeakHashMap
C.TreeMap:顶层结构为二叉树,便于排序,存储键值对
3.其它
上述各种集合,要着重掌握各自的底层结构和存储原理、优缺点、安全性、使用场景等等!!
十二、IO
1.定义
输入输出流,java.io为java处理io的工具包,通过io可以实现数据的存储和网络传输
2.分类
(1)字节流
输入流:
A.InputStream
a.FileInputStream
b.ObjectInputStream
c.ByteArrayStream
d.FilterInputStream
d1.DataInputStream
d2.BufferInputStream
输出流:
A.OutputStream
a.FileOutputStream
b.ObjectOutputStream
c.ByteArrayOutputStream
d.FilterOutputStream
d1.DataOutputStream
d2.BufferOutputStream
d3.PrintStream(System.in,System.out)
(2)字符流
输入流:
A.Reader
a.BufferReader
b.InputStreamReader
c.StringReader
d.ByteArrayReader
输出流:
A.Writer
a.BufferWriter
b.OutputStreamWriter
c.StringWriter
d.CharArrayWriter
e.PrinterWriter
十三、多线程
1.进程与线程的区别
(1)程序:一段静态代码,本质为一组指令的集合
(2)进程:是程序的动态执行,是资源分配和调度的独立单位,一个进程可以包含多个线程
(3)线程:是CPU执行的基本单位,具有自身的生命周期
2.线程状态图
(1)创建:当一个线程被new出来时,此时它处于创建状态
(2)就绪:当一个线程调用start()方法或处于其它状态而此时满足了可执行条件时,此时它处于就绪状态
(3)阻塞:当一个线程调用sleep(),wait(),suspend()方法时,此时它处于阻塞状态
(4)运行:当一个线程拿到cpu执行时间片进入run方法时,此时它处于运行状态
(5)终止:当一个线程调用stop方法或run方法运行结束时,此时它处于终止状态
3.线程的实现
(1)继承Thread类
(2)实现Runnable接口以及重写run方法
(3)实现Callable接口以及重写call方法(该方式适用于需要返回值的情景)
4.线程的主要操作方法
(1)sleep(时间段):使线程主动进入阻塞状态,指定时间后进入就绪状态
(2)wait():线程进入阻塞状态,可通过调用notify()方法进行唤醒
(3)join():强制某个线程执行,期间其它线程不可执行
(4)yield():当前线程礼让其它线程执行
(5)interrupt():中断当前线程执行
(6)stop():停止运行
(7)setDaemon(true):设置后台线程即守护线程
(8)setPriority(等级):设置线程优先级
5.线程的同步(解决多线程共享内存时的读写冲突问题)
(1)同步代码块:synchronized(同步对象){ //同步代码 }
(2)同步方法:public synchronized void setxxx(){ }
(3)同步锁:通过手动调用lock()和unlock()加锁和释放锁,常见同步锁有ReentrantLock等等
(4)同步辅助类
a.Semaphore:一个计数信号量,本质为“共享锁”。线程可通过acquire()获取Semaphore的许可证,当未能提供时,该线程进行阻塞直到能得到许可证。线程可通过release()来释放掉它具有的许可证
b.CyclicBarrier:同步栅栏,它允许一组线程相互等待,直到所有线程都到达时即达到公共屏障点,线程方可执行。它可以通过释放等待线程以及重置计数器后进行重用,所以说它是可循环的
c.CountDownLatch:与同步栅栏CyclicBarrier类似,都需要设置公共屏障点,当线程调用countDown()达到公共屏障点时,可让线程退出阻塞状态。它的计数器不能通过重置进行复用
6.线程池的概念和作用
(1)线程池的概念:有个“池”的空间,里面有一些创建的线程,当有任务过来可以直接从里面去取,不用时进行归还
(2)线程池的作用
a.降低资源的损耗。通过对线程的重用,降低了不断的线程创建所带来的系统资源损耗
b.提高程序的响应速度。通过对线程的重用,避免了线程来回创建和释放占有过多的时间
c.便于对并发线程集合的管理。因为所用的线程都集中在“池”中,便于管理
d.提供了更强大的功能。比如定时线程池提供延时功能
7.线程池的实现
(1)原理
当线程池线程数量<corePoolSize即核心线程数时,将创建新线程去处理该任务;当线程数>=corePoolSize时,则把此任务放到缓存任务队列中,如果添加成功则等待有空闲线程从队列中取出任务执行,如果添加失败(一般指缓存队列已满),此时会创建新线程去处理该任务;当线程数达到maxmunPoolSize即最大线程数时,会才去拒绝策略;当线程数>corePoolSize时,如果线程存活时间达到了keepAliveTime时,该线程将终止,直至线程数不超过corePoolSize。
(2)任务阻塞队列的分类
a.有边界阻塞队列:ArrayBlockingQueue,需要指定大小
b.无边界阻塞队列:LinkedBlockingQueue,不指定的话一般默认大小为Integer.MAX_SIZE
c.直接提交队列:SynchoronousQueue,此队列不会对任务进行保存,而是会创建新的线程去执行该任务
(3)线程池的分类
接口:Executor 实现类:ThreadPoolExecutor
a.newSingleThreadExecutor:单线程池,使用的阻塞队列是LinkedBlockingQueue
b.newFixedThreadPool:固定数量线程池,corePoolSize等于maxmumPoolSize,使用的阻塞队列为LinkedBlocking
c.newCachedThreadPool:缓存线程池,corePoolSize为0,线程默认存活时间为60s,核心线程池最大为Integer.MAX_SIZE,使用阻塞队列为直接提交SynchoronousQueue
d.newScheduledThreadPool:定时线程池,执行周期分为两种,一种为根据频率执行,另一种是根据延时执行
(4)关闭线程池的方法
a.shutDown():当此方法被调用时,线程时并不会立即关闭,而时会等到任务队列的任务全部执行完才终止,并且此过程不会接收新的任务
b.shutDownNow():当此方法被调用时,会尝试去强行终止当前任务执行,并清空当前任务队列,返回尚未执行的任务
(5)手动创建线程池的注意点
a.任务之间要独立,否则可能会出现死锁
b.合理配置任务的阻塞时长,时长过长可能会大大降低线程池的性能
c.合理配置线程池的大小
d.合理选择阻塞队列
十四、设计模式
1.定义:设计模式是前人对代码设计思想的一个经验总结
2.作用:便于开发者写出可读性更强更完美的代码
3.遵循规则
(1)里氏替换原则:能用父类的地方,必定能用子类,即子类可以替代父类的功能
(2)依赖倒转原则:面向接口编程,依赖接口而不依赖类
(3)接口隔离原则:一个类尽可能实现多个接口,降低类与类之间的关联,即做到低耦合
(4)开闭原则:对扩展开放,对修改关闭,即在开发过程尽可能减少代码的修改
(5)内聚原则:一个类只需要关心自己的功能实现,而不需要考虑其它功能的实现,即功能明确做到高内聚
(6)合成复用原则:尽可能对代码进行复用,减少继承的使用
4.设计模式分类(23种)
(1)5种构建型(关注对象的实例化):工厂方法模式、抽象工厂模式、单例模式、构建者模式、原型模式;
(2)7种结构型(通过多对象来形成更大的结构):适配者模式、装饰模式、代理模式、外观模式、桥接模式、组合模式、享元模式
(3)11种行为型(关注对象之间的互动):模板方法模式
5.常用设计模式
(1)工厂方法模式:分为简单工厂方法和静态工厂方法(与前者类似,只不过是工厂方法改为静态的即工厂类不需要实例化),指通过参数的不同来实例化不同的对象。(实现:一个接口,不同实现该接口的实现类,一个工厂类以及一个工厂方法,工厂方法根据参数的不同来实例化不同的实现类)
(2)抽象工厂模式:工厂方法模式有个弊端就是,实例化依赖唯一工厂类,当要增加功能时就需要修改该类(违反了开闭原则),所以可以通过抽象工厂模式即创建多个工厂类解决该问题(实现:增加不同实现类的同时要增加对应的工厂类)
(3)单例模式:当某类在全局只需用到一个实例时可采取单例设计模式,该模式分为懒汉式(思想:不急于实例化,等到获取时采取实例化;实现:一个实例属性,一个无参无实现构造方法,一个static sychoronize getInstance方法{//判断实例是否为空,空去创建,然后返回实例即可})和饿汉式(思想:提前实例化,获取时直接返回;实现:一个直接实例化的实例属性,一个无参无实现构造方法,一个static getInstance方法{//判断实例是否为空,非空返回实例,空则返回空})
(4)构建者模式:通过多个子对象的实例化来构建一个复合对象,例一台电脑的构成包括CPU、输入/输出设备、磁盘等等(实现:多个类多个构造方法,一个复合类里的构造方法里分别调用这些类的构造方法)
(5)原型模式:以一个对象为原型,通过复制、克隆的方式来产生与其类似的对象。(实现:一个原型类,需实现Cloneable接口和重写clone方法,通过该方法实现对象克隆,如果需要深克隆则需通过序列化和IO对象流来实现)
(6)适配者模式:指一个类的接口要转换成客户端所需要的接口,避免出现类的兼容性问题。分为类适配(实现:一个类有一个方法,一个接口有一个与其同名的方法,定义一个类继承前者类和实现前者接口)、对象适配(实现:一个类一个方法,一个接口有一个与其同名的方法,定义一个类实现前者接口以及以前者类定义一个属性并且在构造方法里实例化它,重写接口同名方法并在接口里调用该类属性的对应方法)和接口适配(实现:借助一个抽象类,实现某个接口所有方法,然后再定义一个新类去继承该抽象类,只需重写我们需要的方法即可)。
(7)装饰模式:给一个对象动态增加一些功能。(实现:被装饰类和装饰类需要实现同一个接口,然后装饰类需要包含一个该接口的属性,然后重写该接口的方法并在该方法里调用此接口方法并在该方法里做其它代码修饰)
(8)代理模式:指的给一个被代理对象创建对应的代理对象,去为被代理对象去作一些操作(实现:被代理对象和代理对象需要实现同一接口,并且代理类里要定义代理类对应的属性并且调用其方法,使用时将代理对象构造值赋给接口声明)
(9)模板方法:父类的方法实现里只需要实现方法的步骤即各个方法的调用,然后子类需要把这些方法逐一实现
十五、网络编程
1.网络编程的定义
网络编程指的是通过编写的程序实现两个或多个互联网上的设备进行数据传输。
2.网络体系结构
(1)OSI参考模型
a.物理层(数据单元为比特串,主要为数据设备端提供数据通路)
b.数据链路层(数据单元为帧,主要实现网络中相邻结点间的可靠传输)
c.网络层(数据单元为分组,主要功能为路由选择、网络寻址、拥塞控制等等)
d.传输层(数据单元为报文,主要实现源端口到目的端口直接的数据传输)
e.会话层(负责应用程序间会话的创建、维持和中断)
f.表示层(只关注数据格式,负责把应用层的信息转换为能够共同理解的形式)
g.应用层(为应用进程提供服务)
(2)TCP/IP参考模型
a.网络接口层(对应于OSI参考模型的物理层和数据链路层)
b.网络层(IP层)
c.传输层(TCP层)
d.应用层(包含各种各样的应用协议,例如http、ftp、smtp等等)
3.网络协议
(1)IP协议
IP协议主要是保证了各种数据包准确无误地传给对方,准确无误性主要依赖于ip和mac地址。我们的ip地址是路由器分配的,上面也存有我们的mac地址,mac地址是具有全球唯一性的。IP地址是逻辑地址,mac地址是物理地址,ip地址好比小区地址,mac地址好比如楼房和房间号。
(2)TCP协议(HTTP、FTP、SMTP)
a.面向连接,可靠传输,面向字节流
b.TCP连接建立阶段为三次握手:客户端发起连接请求->服务端回复ack表示收到该请求->客户端进行连接
c.TCP连接释放阶段为四次挥手:客户端发起断开连接请求->服务端回复ack表示收到该请求->服务端发起连接断开->客户回复ack
(3)UDP协议(DNS、NFS)
a.无连接,不可靠,只是尽最大努力交付,面向用户数据包
(4)HTTP协议
a.超文本传输协议,无状态(下一次请求不会记住上一次请求的状态)
b.http/1.0默认为短链接(操作完后连接断开,下次发起请求要重新连接),http/1.1默认为长连接(操作完,会话连接不会断开除非连接保活时间到了,连接才会失效)
c.传输文本为明文,容易被攻击和窃取信息,所以该协议不适用传输一些敏感信息
(5)HTTPS协议
a.基于HTTP,在其底下多了一层SSL层(加密/身份验证层),具有安全性
b.HTTP默认端口为80,HTTPS默认端口为443
c.由于HTTPS的SSL会进行服务器身份验证以及对传输的数据进行加密,所以它很好的确保了安全性
4.socket编程的概述
socket为套接字,它不是一种协议,而是对TCP和UDP协议的封装,简单来说它是一个调用接口(API)
5.socket的通信流程
a.服务器创建服务器套接字ServerSocket,绑定某个服务端口(0~65536,0~1024是为特权服务保留的端口),然后监听该端口等待客户连接请求;
b.客户端创建套接字Socket,然后通过服务器ip/域名和端口向指定服务器发起连接请求;
c.服务器通过服务端口接收到客户连接请求,然后通过accept()返回的socket对象,结合InputStream和OutputStream工具进行数据读写
6.基于TCP和socket的C/S端编程
a.服务端

b.客户端

7.基于UDP和socket的C/S端编程
a.服务端
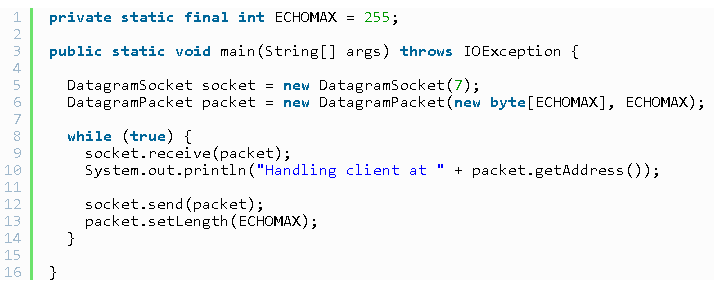
b.客户端


 浙公网安备 33010602011771号
浙公网安备 33010602011771号